1. Introduction
As a large coal-producing country, China’s annual coal production is up to billions of tonnes, but the gangue content of the mined raw coal is as high as 10% to 30%. The low carbon content and high ash characteristics of gangue cause a decline in the quality of raw coal, thus affecting the use value and economic value of coal [
1]. In addition, in the main coal flow transport system, the presence of large gangue may lead to longitudinal tears, surface scratches, and other damage to the conveyor belt of the belt conveyor system, and if these problems are not detected and dealt with promptly, the damage may further expand or even lead to the occurrence of major accidents [
2]. Thus, the efficient sorting of gangue is the first important link in the deep processing of coal.
Manual gangue sorting is gradually being eliminated due to high labor intensity, poor working environment, and low efficiency [
3]. To change the above gangue sorting method and enhance the level of coal mine intelligence, many scholars have conducted in-depth research on an automatic gangue sorting system. Dou et al. [
4] used machine vision as a means of identifying gangue and then utilized a high-pressure air gun to reject it. An intelligent sorting system for gangue based on an embedded artificial intelligence development platform was proposed by Wang et al. [
5]. Image acquisition and processing were completed by the intelligent vision systems. After aligning the camera coordinate system with the robot coordinate system, the robot arm was controlled to pursue and classify the gangue. A near-infrared camera was used with a visible light camera to build a multi-level fusion recognition system by Ding et al. [
6] to provide a new idea for the robot to automatically sort coal and gangue. Sun et al. [
7] established a smart visual coal gangue separation framework on the basis of CoppeliaSim, modeled the raw coal and gangue blends, manipulator control system, material conveyor belt, and image recognition system, and restored the actual working conditions of gangue splitting. Feng et al. [
8] integrated machine vision with robotics to construct a gangue robotic sorting system, and optimized the robot controller to improve control precision.
In the coal gangue automatic sorting system, as only the precise identification of coal and gangue can control the subsequent actuators to sort coal and gangue, the precise identification of coal and gangue is particularly important. With the advancement of computing power and the development of intelligent algorithms, research on coal gangue recognition technology shows a clearly deepening trend. Currently, the mainstream recognition methods include visible light-imaging-based image recognition technology and transmission-imaging-based image recognition technology.
Image recognition technology based on visible light imaging uses a camera to image the flow of coal on the conveyor belt and adopts machine learning algorithms to classify coal and gangue based on the different textures, grey values, and other feature information presented on the digital image. Hu et al. [
9] proposed the idea of combining infrared images with convolutional neural networks (CNN) to distinguish coal and gangue. Li et al. [
10] proposed an image-based deep learning framework for coal and gangue stratification detection, which provided a solution to the problem of multi-scale extraction of image features and the difficulty of recognizing multiple randomly located targets. Su et al. [
11] raised a way of accessing an improved LeNet5 model to identify coal gangue, which could automatically extract coal gangue image features and precisely classify them. Based on the idea of transfer learning and VGG16, Pu et al. [
12] constructed a CNN model to distinguish between coal and gangue images, which had a good recognition effect. In addition, the single-stage approach represented by a series of YOLO algorithms, which did not need to generate the area suggestion network in advance, could directly obtain the category and coordinate information of the target object [
13], and had a faster detection speed and powerful target detection capability, thus the algorithm has been favored by many researchers. Zhang et al. [
14,
15] proposed an approach of combining segmentation networks with YOLOv5, which enabled the network to take into account both target segmentation and target detection and achieved integrated multi-task detection. They used this method and studied the belt conveyor runout faults, and enhanced the network’s capability to detect straight lines by combining the outputs of the improved YOLOv5 network, thus solving the problem of fast feature extraction and deviation judgment of conveyor belt edges in complex backgrounds. Yan et al. [
16] improved the YOLOv5 model and put forward an approach to classify coal gangue on the basis of multispectral imaging techniques and object detection. Not only could it achieve the precise identification of the gangue, but it also obtained information about the relevant locations of the gangue, which could be applied to the target detection task of the gangue. Sun et al. [
17] studied the classification and location of coal and gangue, proposed a dynamic object detection approach in view of CG-YOLO, and used robots to grab irregularly shaped gangue to form a complete separation system. Luo et al. [
18] improved the backbone and neck of YOLOv5, implemented a deep lightweight target inspection network, and ensured speed and precision in detecting multiple types of materials on belt conveyors. Xu et al. [
19] studied the issues of remote sensing object detection and proposed a new remote sensing object detection model using YOLO-v3 to raise the precision and real-time performance of remote sensing object detection. Mao et al. [
20] added a lightweight non-parametric attention mechanism based on YOLOv7 and introduced deep separable convolution in the backbone network to achieve efficient recognition of foreign objects. It is worth mentioning that the precision of the image-based recognition method is easily affected by the downhole lighting conditions, material surface, working environment, and camera exposure time, in addition to the camera’s mounting angle, height, and focal length settings which will also have an impact on the recognition efficiency.
Image recognition technology based on transmission imaging relies on high-energy rays (e.g., gamma rays, X-rays) to conduct transmission imaging of the raw coal flow on the conveyor belt and to differentiate between coal and gangue mixture on the basis of the fact that coal and gangue have different densities. Zhang et al. [
21] developed a coal gangue-identifying system according to natural gamma ray technology, which achieved the automation of coal and gangue identification. Zhou et al. [
22] combined dual-energy X-ray with Geant4 simulation image processing technology, and used the R-value method to effectively identify coal and gangue of various shapes and thicknesses. Abbasi et al. [
23] proposed a linear function fitting method as a basis for obtaining atomic numbers of uncertain materials, which provided the possibility of separating the atomic numbers of substances with unit resolution. Wang et al. [
24] combined the receptive field module with the U-Net model to provide a reference to address the issue of gangue clinging or obscuring impacting the precision of intelligent recognition.
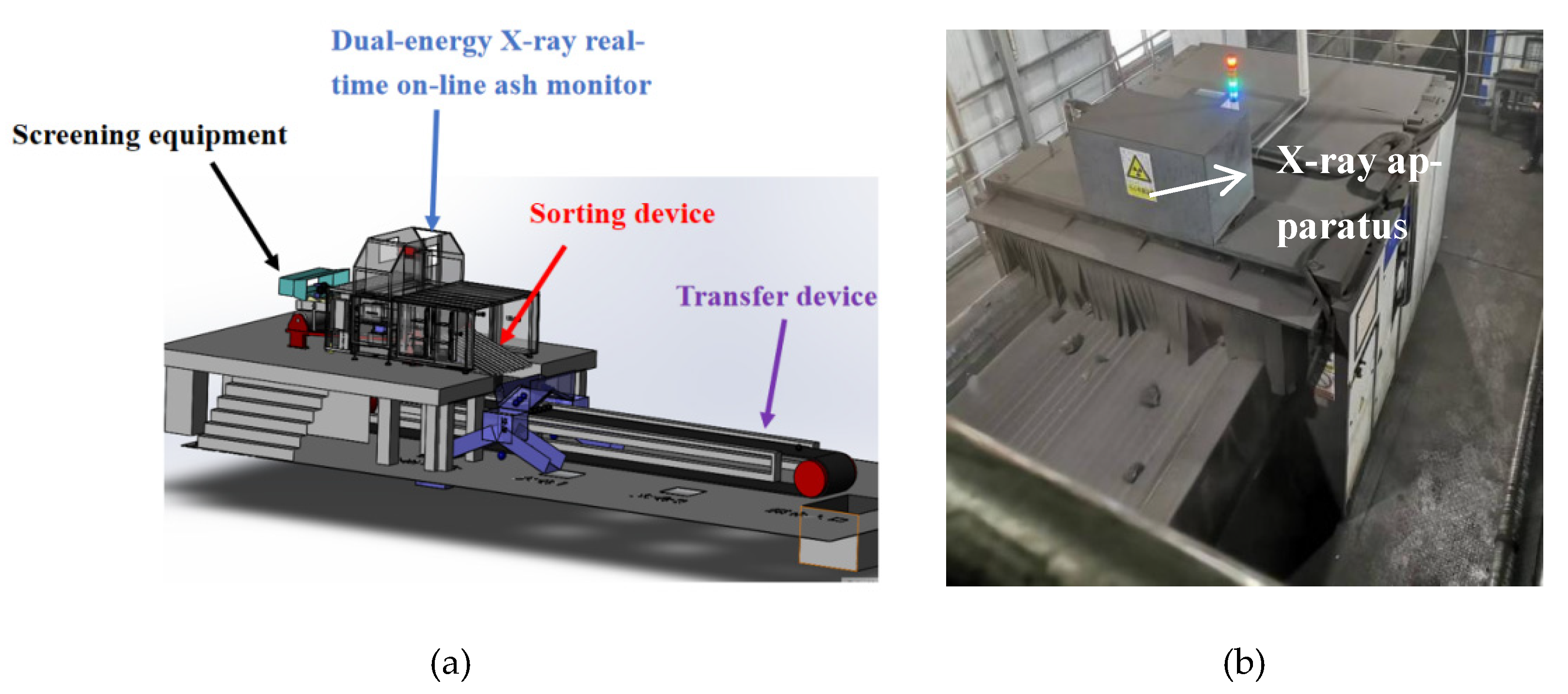
The above scholars have made great progress in the research of automatic gangue sorting systems and gangue identification methods, but there are still shortcomings. Most of the research on automatic gangue sorting systems is in the experimental stage, which has limited ability to sort gangue with large particle size and dense distribution, and cannot overcome the influence of the poor underground environment. In the field of coal gangue recognition, the gangue recognition method based on industrial camera images can capture more gangue features, however, this method has difficulty achieving ideal recognition results for coal gangue that is seriously wrapped by coal sludge in the coal mine. In addition, although the image recognition method based on projected imaging is not easily disturbed by the complex environment of coal mines, a series of algorithms represented by the R-value method mostly have complex calculation, difficultly in determining the threshold value, and rely on a large amount of manual experience, which greatly limits the application of this method in the actual scene. Therefore, to meet the demand for efficient and intelligent sorting in coal mines and to maximize the recognition precision and sorting efficiency of coal gangue, this paper combines the advantages of YOLOv5 precision and efficiency with the weak environmental sensitivity of the projection recognition method, and proposes a target detection algorithm for coal gangue based on the combination of dual-energy X-rays and the improved YOLOv5 model (DX-YOLOv5), together with the design of a new type of intelligent gangue sorting system which can sort the gangue with high precision and efficiency without the intervention of human beings and can overcome the harsh underground conditions without being influenced by the temperature, dust, and hazardous gases.
The principal contributions of this paper are as follows. First, dataset construction: given that there is no publicly available dataset of dual-energy X-ray images of coal and gangue, this paper creates a customized dataset for learning and testing by collecting coal mine data in the field and combining it with LableImg. Second, backbone network: to address the fact that the network parameters and calculation complexity of CSPDarknet consume a large amount of computing resources of hardware devices, in this paper, EfficientNetv2, a lightweight network, is used as the backbone network of YOLOv5-S to enhance computational productivity and precision. Third, neck design: to achieve further network performance enhancement by lightweighting the network, this paper designs a LPAN in the neck instead of the original PAN module, and seamlessly integrates the CBAM into the feature fusion module to maximize the learning effect. Fourth, detection head optimization: to promote the multi-scale target inspection performance of the algorithms presented by this paper, this paper adds the L2 output block to achieve the detection of small targets with a resolution of 160 × 160. Fifth, modification of the loss function: to achieve a higher rate of convergence and optimized positioning, this paper chooses the EIOU-loss to substitute the CIOU-loss in the previous network architecture to improve regression precision. Sixth, the design of a new type of intelligent gangue sorting system, which can overcome the harsh environment of coal mines and achieve high-speed and high-efficiency sorting of coal gangue with a large range of particle size.
The remainder of this article is as follows.
Section 2 presents the process flow of the coal gangue sorting system designed in this paper and the principle of dual-energy X-ray identification.
Section 3 describes the structure of YOLOv5 and the main points of creativity in this paper.
Section 4 gives the relevant experiments of this paper’s methodology on the self-built dataset and the performance is compared with that of other classically based algorithms. Finally,
Section 5 gives the conclusion.
4. Experiments and Discussions
4.1. Experimental Configuration Framework
In this study, we utilized the YOLOv5-3.1 code base as our starting point, and the network was trained using the AdamW optimizer with an incipient learning incidence of 0.01. To enhance training, we used a cyclic learning rate of 0.2 and a weight decay of 0.0005. Throughout the experiment, we ran 200 epochs with batch sizes of 8. During the warm-up stages, the momentum was set to 0.8 and then changed to 0.937. All picture input sizes were changed to 640 × 640 by web preprocessing. For the sake of equitable comparison, we employed the default data augmentation method and did not use any pre-training models.
The computer setup utilized in this experiment consisted of a PC platform with an Intel Core i5-9300H CPU running at 2.4 GHz, -an NVIDIA GeForce GTX 1660 Ti GPU, 16 GB of memory, and the Windows 11 operating system. The development framework employed was PyTorch, specifically Python version 3.7.11 with Torch version 1.7.0 and Torchvision version 0.8.1.
4.2. Performance Evaluation
The purpose of this section is to assess the performance of the enhanced YOLOv5-S model compared with its baseline model YOLOv5-S using different performance metrics. We utilized precision (P), recall (R), and mean average precision (mAP) as indicators to assess the improvement. Specifically, we defined the formulas for
P and
R as follows:
In the given equation, the symbol denotes the quantity of the true positive instances, denotes the quantity of false positive samples, and denotes the quantity of false negative samples.
In the target detection task, mAP is the average of the average detection precision (AP) of all categories within all images and is used as a measure of the algorithm’s performance in predicting target locations and categories. The AP is denoted as the area enclosed by the horizontal and vertical coordinates of the curve in the P-R plot plotted with recall R as the horizontal axis and precision P as the vertical axis.
4.3. Ablation Experiment
To validate the effectiveness of the various improvements proposed in this study for the EfficientNetV2 backbone, the LPAN module, the CBAM module, the L2 detection head, and the EIOU_loss, comparative ablation experiments incorporating each of the different modules, as well as fusing all of them, were designed in this section using YOLOv5-S as the baseline. As indicated in
Table 2, the above experiments used the mAP at two different IOU thresholds, the number of parameters (Params), and the computed floating-point operations per second (FLOPs) as performance evaluation metrics.
Analyzing the experimental results, it was found that the conventional CSPDarknet was substituted by EfficientNetV2 as the backbone network. Compared with the original YOLOv5-S model, in the improved network architecture, mAP@.5(%) and mAP@.5:.95(%) indexes were increased by 7.5% and 11.3%, respectively, the number of parameters were reduced by 24.4%, and the computing complexity was reduced by 3.09 G, which not only enhanced the target detection precision but also achieved the lightweight of the network. This was due to the strong feature extraction capability of EfficientNetV2, which can mine more deep features to achieve improved precision, and the Fused-MBConv module, which combines multiple residual blocks into a single convolutional layer, which can further reduce the quantities of parameters in the model and the calculation complexity.
Further examination of the experimental data indicated that integrating the LPAN module enhanced the model’s performance on mAP@.5(%) and mAP@.5:.95(%)by 8.4% and 13.7%, respectively. It is worth noting that although the introduction of the LPAN module did not change the parameters of the model, it slightly increased the computational complexity of the model while keeping the number of model parameters unchanged, due to its introduction of hopping connections and feature reuse mechanisms in the network structure. It was a minor expense that was exchanged for a significant improvement in model performance.
In the YOLOv5 model, we introduced the CBAM module to process the feature maps to achieve adaptive feature refinement. The CBAM module computes the 1D channel and 2D spatial attention maps sequentially and then multiplies them with the input feature maps, which enhances the depiction of characteristics of obstructed targets on the maps and suppresses the expression of the irrelevant features, thus improving the precision of the model detection. From the results, it can be seen that this module improves the mAP@.5 (%), mAP@.5:.95 (%) metrics by 10% and 16%, respectively, which reduces the model’s parameter amount by 13.5% and the computational complexity by 2.1 G.
In order to provide the network with better performance in small target detection tasks, we added the L2 detection head to YOLOv5 for related experiments. The results showed that the separate introduction of the module traded off a 10.9% and 18.5% improvement in the mAP@.5 (%) vs. mAP@.5:.95 (%) metrics, respectively, at a cost of a 5.5% increase in the parametric count of the model and an 8.49 G rise in arithmetic complexity. Although the introduction of the small target detection layer increased the depth of the network increasing the number of network parameters and computational complexity, the method passed more shallow features to deeper features, and improved the ability of the network to learn multi-level feature information of the target, so that the network could detect the smallest target with a resolution of 160 × 160, which could re-detect a large number of the small targets that were originally missed, and effectively improve the target missing detection situation.
Finally, the in EIOU_loss directly minimized the difference between the width and height of the predicted frame and the true frame, resulting in faster convergence, greatly alleviating the problem of positive and negative sample imbalance in the CIOU, and, thus, without altering the model parameters and arithmetic complexity, led to a 3.8% increase in mAP@.5 (%) and a 7.4% increase in mAP@.5:.95 (%), while also enhancing the precision of regression.
By comparing the experimental results of this method and baseline ablation shown in
Table 2, it is evident that the incorporation of EfficientNetv2, LPAN, CBAM module, L2 detection head, and EIOU_loss enhanced the precision of the network, with most improvement achieved in the small target detection layer module. Compared with YOLOv5-S, mAP@.5 (%) and mAP@.5:.95 (%) increased by 19.2% and 32.4%, respectively, and the parameters and computational complexity reduced by 3.74 M and 2.49 G. When fusing multiple feature extraction methods, adjustments were necessary in the LPAN feature fusion module to match the output of EfficientNetV2. Specifically, some features with 512 channels were converted to 160 channels, which substantially diminished the parameter count and arithmetic complexity of fusing all methods. The experimental results verified the reliability of the enhanced algorithm in this paper, indicating that the modified model can efficiently and precisely identify coal and gangue.
4.4. Analysis of the Results
Figure 9 shows that the results of training YOLOv5-S and YOLOv5-S on the homemade dataset improve in this paper. As can be seen from the figure, the precision decreases with an increase in recall. This occurs because P represents the ratio of the predicted true positive samples to the total samples predicted as positive by all classifiers. When the recall increases, the model identifies more positive cases as positive, but it also misclassifies more negative cases as positive, leading to a decrease in precision. By conducting a comparison, it is evident that the enhanced network structure discussed in this article achieves significantly higher precision (vertical axis) and recall (horizontal axis) results compared with YOLOv5-S. It also presents specific AP test results for each specific category of object in the dataset. The revised model surpassed the original model in the region enclosed by the P-R curve, both horizontally and vertically, indicating superior generalization performance and stronger feature extraction capabilities. Consequently, mAP experienced a 19.2 percent improvement. Simultaneously, the detection precision for the two categories of gangue, and coal and gangue, was also enhanced. By referring to
Figure 9a, it is evident that the YOLOv5-S model exhibited superior identification capability for coal, with a precision as high as 0.926; the recognition performance for coal and gangue was moderate, with a precision of 0.716; and the recognition performance for gangue was the most inferior, with a precision of only 0.561. From
Figure 9b, it can be observed that the enhanced YOLOv5-S model presented the best recognition performance for coal and gangue, with a precision as high as 0.919; the recognition performance for coal was moderate, with a precision of 0.896; and the recognition performance for gangue was inferior, with a precision of 0.811.
To further validate the above indexes, the improved YOLOv5-S and YOLOv5-S were compared to detect the same batch of gangue materials in the actual production environment.
Figure 10a shows the detection of gangue mixture material using the YOLOv5-S network, and
Figure 10b shows the detection of the same batch of mixture material using the improved YOLOv5-S with labeled target categories and confidence levels. It was observed that the improved YOLOv5-S network could identify and locate coal, gangue, and coal and gangue with higher confidence compared with the YOLOv5-S network, and had better identification results in the case of dense targets and many small targets. The YOLOv5-S network had a low confidence level, and the phenomenon of repeated recognition also occurred. Thus, the improved YOLOv5-S network had stronger target detection capability.
As seen in
Figure 11, the confidence level of 0.6 was considered as the reference point. Materials with a confidence level higher than 0.6 were identified as coal, while materials with a confidence level lower than 0.6 were classified as gangue. The DX-YOLOv5 recognition model analyzed the density, composition, and coordinates of the materials and transmitted this information to the host computer. According to the size of the gangue particles, the main computer determined the number of slide boards needed to track and separate the object gangue. It then sent a command to the intelligent slide board controller based on the time it took to identify the material and the velocity of the conveyor belt. When the object gangue reached the end of the belt, the control system activated the intelligent slide plate to extend, catch the gangue, and then retract. The gangue that was caught moved along the slide plate toward the gangue belt, while the coal pieces fell directly onto the coal belt. This process effectively separated the coal from the gangue.
4.5. Comparison with Other SOTA Models
To validate the enhanced YOLOv5-S algorithm, this study assessed its performance by conducting experiments on a custom dataset. The proposed method was compared with NanoDet-Plus, YOLOv5 series, and YOLOv7 under identical experimental conditions. The performance measures utilized in this study comprised parameters, FLOPs, mAP, latency, and model size. The specific results are showcased in
Table 3.
In analyzing the results of
Table 3, our method performed well at the same level as the YOLOv5 algorithm and reduced the model size, params and calculated complexity while successfully maintaining the model precision. This fully demonstrates the efficacy of the enhanced strategy in object inspection and recognition tasks. Since we have taken measures such as a lighter backbone network, depthwise separable convolutions, limiting the maximum number of channels, and introducing a small target detection layer, our model exhibits a substantial decrease in size, parameter count, and computational complexity in comparison with YOLOv7. At the same time, the precision is also significantly improved. Further analysis of YOLOv7’s mAP @.5 and mAP @.5:.95 scores did not reach the best level and reached the highest in terms of parameter number and calculation amount, which may be attributed to overfitting caused by the excessive size of the model. Compared with NanoDet-Plus, the improved YOLOv5-S is comparable in terms of parameter quantity. Although its computational complexity and detection speed are slightly inferior, our model is much larger than NanoDet-Plus in mAP, which shows the superiority of our model in handing small target detection tasks.
5. Conclusions
In this paper, a new gangue sorting system with dual-energy X-ray recognition and improved YOLOv5 algorithm was proposed, which improves the YOLOv5-S network model by five methods: using EfficientNetV2 for the backbone network; designing the LPAN module in the neck and embedding the CBAM into the BottleneckCSP of the YOLOv5 feature fusion module; adding the L2 detection header in the head layer; choosing EIOU_Loss to replace the CIOU_Loss in the original network; and improving the recognition precision and decreasing the computational complexity. After conducting experiments to validate the methodologies, the following verdict was reached: in comparison with the YOLOv5-S, the updated model showed a 19.2% increase in mAP@.5 and a 32.4% increase in mAP@.5:.95. Meanwhile, there was a 51.5% reduction in parameters, and a 14.7% reduction in computational complexity. In addition, the proposed method had better overall performance improvement as well as less resource consumption compared with other mainstream algorithms, which is more suitable for deployment and implementation on embedded devices. Specifically, the improved network architecture reduced 88.3%, 47.5%, and 86.4% in terms of model parameters, inference time, and computational cost, respectively, compared with YOLOv7 when the model size was only 7.10 MB. It is anticipated that the approach suggested in this study will be beneficial to a wider range of researchers in the identification and inspection of coal gangue on a conveyor belt, which holds significant practical application value for the intelligent sorting of coal gangue.
In our future endeavors, we will focus on optimizing test results for hardware devices with low computational power, i.e., high quality inference tests with limited computational power. Additionally, we will conduct in-depth research on image preprocessing techniques to minimize and avoid the impact of light artifacts.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}