

Constructing Features for Screening Neurodevelopmental Disorders Using Grammatical Evolution


Abstract
:Featured Application
Abstract
1. Introduction
2. Background Information
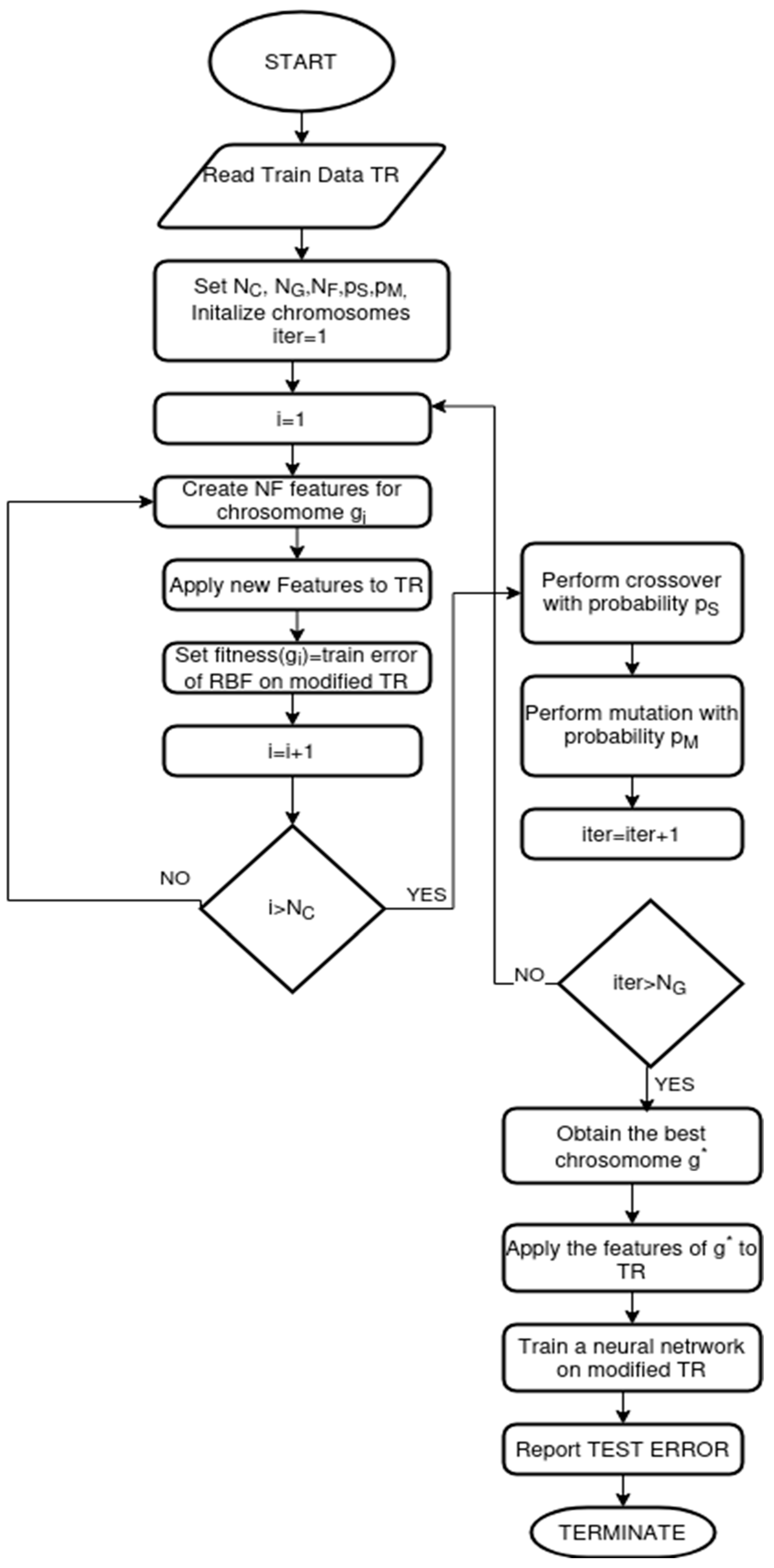
2.1. The Proposed Method
| Algorithm 1. The main steps of the used method |
Initialization Step
|
2.2. Comparative Methods
3. Materials and Methods
- Fixation count (FC), i.e., the total number of fixations in an AOI;
- Time to first fixation (TTFF), i.e., the time needed after an AOI is visible until the first fixation is counted on it;
- The total duration of fixations (TS), i.e., the total time that an individual spends looking at a specific AOI.
4. Experiments
4.1. Experimental Datasets, Methods, and Parameter Details
- RBF—an RBF neural network with H processing nodes.
- MLP BFGS—an artificial neural network with H hidden nodes, trained with the BFGS optimization method.
- MLP PCA—an artificial neural network with H hidden nodes and trained with the BFGS method. The neural network is applied on two constructed features produced by the PCA method.
- FC2RBF—an RBF network with 10 processing nodes applied on two artificial features constructed by the proposed method.
- True positive (TP)—the individual in question does in fact have NDs and our prediction was accurate that the individual does have NDs.
- True negative (TN)—the individual in question does not in fact have NDs and our prediction was accurate that the individual does not have NDs.
- False positive (FP)—although the individual in question does not in fact have NDs, our prediction was inaccurate that the individual does have NDs. The term for this kind of error is a Type 1 error.
- False negative (FN)—although the individual in question does in fact have NDs, our prediction was inaccurate that the individual does not have NDs. The term for this kind of error is a Type 2 error.
4.2. Experimental Results
5. Discussion—Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders, 5th ed.; American Psychiatric Association: Washington, DC, USA, 2013; ISBN 978-0-89042-555-8. [Google Scholar]
- Thapar, A.; Cooper, M.; Rutter, M. Neurodevelopmental Disorders. Lancet Psychiatry 2017, 4, 339–346. [Google Scholar] [CrossRef]
- Toki, E.I.; Tatsis, G.; Tatsis, V.A.; Plachouras, K.; Pange, J.; Tsoulos, I.G. Applying Neural Networks on Biometric Datasets for Screening Speech and Language Deficiencies in Child Communication. Mathematics 2023, 11, 1643. [Google Scholar] [CrossRef]
- Harris, J.C. New Classification for Neurodevelopmental Disorders in DSM-5. Curr. Opin. Psychiatry 2014, 27, 95–97. [Google Scholar] [CrossRef]
- Wong, J.; Cohn, E.S.; Coster, W.J.; Orsmond, G.I. “Success Doesn’t Happen in a Traditional Way”: Experiences of School Personnel Who Provide Employment Preparation for Youth with Autism Spectrum Disorder. Res. Autism Spectr. Disord. 2020, 77, 101631. [Google Scholar] [CrossRef]
- Young, S.; Adamo, N.; Ásgeirsdóttir, B.B.; Branney, P.; Beckett, M.; Colley, W.; Cubbin, S.; Deeley, Q.; Farrag, E.; Gudjonsson, G. Females with ADHD: An Expert Consensus Statement Taking a Lifespan Approach Providing Guidance for the Identification and Treatment of Attention-Deficit/Hyperactivity Disorder in Girls and Women. BMC Psychiatry 2020, 20, 404. [Google Scholar] [CrossRef]
- Abi-Jaoude, E.; Naylor, K.T.; Pignatiello, A. Smartphones, Social Media Use and Youth Mental Health. CMAJ 2020, 192, E136–E141. [Google Scholar] [CrossRef]
- American Phychiatic Association. DSM-5 Intellectual Disability Fact Sheet. Am. Psychiatr. Assoc. 2013, 2. Available online: https://www.psychiatry.org/File%20Library/Psychiatrists/Practice/DSM/APA_DSM-5-Intellectual-Disability.pdf (accessed on 4 December 2023).
- Merrells, J.; Buchanan, A.; Waters, R. “We Feel Left out”: Experiences of Social Inclusion from the Perspective of Young Adults with Intellectual Disability. J. Intellect. Dev. Disabil. 2019, 44, 13–22. [Google Scholar] [CrossRef]
- Chadwick, D.; Ågren, K.A.; Caton, S.; Chiner, E.; Danker, J.; Gómez-Puerta, M.; Heitplatz, V.; Johansson, S.; Normand, C.L.; Murphy, E. Digital Inclusion and Participation of People with Intellectual Disabilities during COVID-19: A Rapid Review and International Bricolage. J. Policy Pract. Intellect. Disabil. 2022, 19, 242–256. [Google Scholar] [CrossRef]
- Fletcher, J.M.; Miciak, J. The Identification of Specific Learning Disabilities: A Summary of Research on Best Practices; Meadows Center for Preventing Educational Risk: Austin, TX, USA, 2019; Available online: https://texasldcenter.org/files/resources/SLD–Manual_Final.pdf (accessed on 4 December 2023).
- Filippello, P.; Buzzai, C.; Messina, G.; Mafodda, A.V.; Sorrenti, L. School Refusal in Students with Low Academic Performances and Specific Learning Disorder. The Role of Self-Esteem and Perceived Parental Psychological Control. Int. J. Disabil. Dev. Educ. 2020, 67, 592–607. [Google Scholar] [CrossRef]
- Haft, S.L.; Greiner de Magalhães, C.; Hoeft, F. A Systematic Review of the Consequences of Stigma and Stereotype Threat for Individuals with Specific Learning Disabilities. J. Learn. Disabil. 2023, 56, 193–209. [Google Scholar] [CrossRef]
- Kwame, A.; Petrucka, P.M. A Literature-Based Study of Patient-Centered Care and Communication in Nurse-Patient Interactions: Barriers, Facilitators, and the Way Forward. BMC Nurs. 2021, 20, 158. [Google Scholar] [CrossRef]
- Rice, C.E.; Carpenter, L.A.; Morrier, M.J.; Lord, C.; DiRienzo, M.; Boan, A.; Skowyra, C.; Fusco, A.; Baio, J.; Esler, A.; et al. Defining in Detail and Evaluating Reliability of DSM-5 Criteria for Autism Spectrum Disorder (ASD) Among Children. J. Autism Dev. Disord. 2022, 52, 5308–5320. [Google Scholar] [CrossRef]
- Kou, J.; Le, J.; Fu, M.; Lan, C.; Chen, Z.; Li, Q.; Zhao, W.; Xu, L.; Becker, B.; Kendrick, K.M. Comparison of Three Different Eye-tracking Tasks for Distinguishing Autistic from Typically Developing Children and Autistic Symptom Severity. Autism Res. 2019, 12, 1529–1540. [Google Scholar] [CrossRef]
- Alam, S.; Raja, P.; Gulzar, Y. Investigation of Machine Learning Methods for Early Prediction of Neurodevelopmental Disorders in Children. Wirel. Commun. Mob. Comput. 2022, 2022, 5766386. [Google Scholar] [CrossRef]
- Vakadkar, K.; Purkayastha, D.; Krishnan, D. Detection of Autism Spectrum Disorder in Children Using Machine Learning Techniques. SN Comput. Sci. 2021, 2, 386. [Google Scholar] [CrossRef]
- Iwauchi, K.; Tanaka, H.; Okazaki, K.; Matsuda, Y.; Uratani, M.; Morimoto, T.; Nakamura, S. Eye-Movement Analysis on Facial Expression for Identifying Children and Adults with Neurodevelopmental Disorders. Front. Digit. Health 2023, 5, 952433. [Google Scholar] [CrossRef]
- de Barros, F.R.D.; da Silva, C.N.F.; de Castro Michelassi, G.; Brentani, H.; Nunes, F.L.; Machado-Lima, A. Computer Aided Diagnosis of Neurodevelopmental Disorders and Genetic Syndromes Based on Facial Images-a Systematic Literature Review. Heliyon 2023, 9, e20517. [Google Scholar] [CrossRef]
- Andrés-Roqueta, C.; Katsos, N. A Distinction Between Linguistic and Social Pragmatics Helps the Precise Characterization of Pragmatic Challenges in Children With Autism Spectrum Disorders and Developmental Language Disorder. J. Speech Lang. Hear. Res. 2020, 63, 1494–1508. [Google Scholar] [CrossRef]
- Schulte-Rüther, M.; Kulvicius, T.; Stroth, S.; Wolff, N.; Roessner, V.; Marschik, P.B.; Kamp-Becker, I.; Poustka, L. Using Machine Learning to Improve Diagnostic Assessment of ASD in the Light of Specific Differential and Co-Occurring Diagnoses. J. Child Psychol. Psychiatry 2023, 64, 16–26. [Google Scholar] [CrossRef]
- Manjur, S.M.; Hossain, M.-B.; Constable, P.A.; Thompson, D.A.; Marmolejo-Ramos, F.; Lee, I.O.; Skuse, D.H.; Posada-Quintero, H.F. Detecting Autism Spectrum Disorder Using Spectral Analysis of Electroretinogram and Machine Learning: Preliminary Results. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; IEEE: New York, NY, USA, 2022; pp. 3435–3438. [Google Scholar]
- Gui, A.; Bussu, G.; Tye, C.; Elsabbagh, M.; Pasco, G.; Charman, T.; Johnson, M.H.; Jones, E.J. Attentive Brain States in Infants with and without Later Autism. Transl. Psychiatry 2021, 11, 196. [Google Scholar] [CrossRef]
- Wei, Q.; Xu, X.; Xu, X.; Cheng, Q. Early Identification of Autism Spectrum Disorder by Multi-Instrument Fusion: A Clinically Applicable Machine Learning Approach. Psychiatry Res. 2023, 320, 115050. [Google Scholar] [CrossRef]
- Lin, Y.; Yerukala Sathipati, S.; Ho, S.-Y. Predicting the Risk Genes of Autism Spectrum Disorders. Front. Genet. 2021, 12, 665469. [Google Scholar] [CrossRef]
- Abdelhamid, N.; Thind, R.; Mohammad, H.; Thabtah, F. Assessing Autistic Traits in Toddlers Using a Data-Driven Approach with DSM-5 Mapping. Bioengineering 2023, 10, 1131. [Google Scholar] [CrossRef]
- El Mouatasim, A.; Ikermane, M. Control Learning Rate for Autism Facial Detection via Deep Transfer Learning. Signal Image Video Process. 2023, 17, 3713–3720. [Google Scholar] [CrossRef]
- van Rooij, D.; Zhang-James, Y.; Buitelaar, J.; Faraone, S.V.; Reif, A.; Grimm, O. Structural Brain Morphometry as Classifier and Predictor of ADHD and Reward-Related Comorbidities. Front. Psychiatry 2022, 13, 869627. [Google Scholar] [CrossRef]
- Chen, T.; Tachmazidis, I.; Batsakis, S.; Adamou, M.; Papadakis, E.; Antoniou, G. Diagnosing Attention-Deficit Hyperactivity Disorder (ADHD) Using Artificial Intelligence: A Clinical Study in the UK. Front. Psychiatry 2023, 14, 1164433. [Google Scholar] [CrossRef]
- Ahire, N.; Awale, R.; Wagh, A. Electroencephalogram (EEG) Based Prediction of Attention Deficit Hyperactivity Disorder (ADHD) Using Machine Learning. Appl. Neuropsychol. Adult 2023, 1–12. [Google Scholar] [CrossRef]
- Aggarwal, G.; Singh, L. Comparisons of Speech Parameterisation Techniques for Classification of Intellectual Disability Using Machine Learning. In Research Anthology on Physical and Intellectual Disabilities in an Inclusive Society; IGI Global: Hershey, PA, USA, 2022; pp. 828–847. [Google Scholar]
- Nilsson Benfatto, M.; Öqvist Seimyr, G.; Ygge, J.; Pansell, T.; Rydberg, A.; Jacobson, C. Screening for Dyslexia Using Eye Tracking during Reading. PLoS ONE 2016, 11, e0165508. [Google Scholar] [CrossRef]
- Gran Ekstrand, A.C.; Nilsson Benfatto, M.; Öqvist Seimyr, G. Screening for Reading Difficulties: Comparing Eye Tracking Outcomes to Neuropsychological Assessments. Front. Educ. 2021, 6, 643232. [Google Scholar] [CrossRef]
- Chawla, M.; Panda, S.N.; Khullar, V. Assistive Technologies for Individuals with Communication Disorders. In Proceedings of the 2022 10th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 13–14 October 2022; IEEE: New York, NY, USA, 2022; pp. 1–5. [Google Scholar]
- Jacob, S.; Wolff, J.J.; Steinbach, M.S.; Doyle, C.B.; Kumar, V.; Elison, J.T. Neurodevelopmental Heterogeneity and Computational Approaches for Understanding Autism. Transl. Psychiatry 2019, 9, 63. [Google Scholar] [CrossRef]
- Bardoloi, P.S. Management of Aggressive Behaviors in Neurodevelopmental Disorders-Role of α 2 Agonists. Acta Sci. Neurol. 2023, 6, 20–25. [Google Scholar] [CrossRef]
- Moreau, C.; Deruelle, C.; Auzias, G. Machine Learning for Neurodevelopmental Disorders. In Machine Learning for Brain Disorders; Colliot, O., Ed.; Humana: New York, NY, USA, 2023; ISBN 978-1-07-163194-2. [Google Scholar]
- Jacobs, G.R.; Voineskos, A.N.; Hawco, C.; Stefanik, L.; Forde, N.J.; Dickie, E.W.; Lai, M.-C.; Szatmari, P.; Schachar, R.; Crosbie, J.; et al. Integration of Brain and Behavior Measures for Identification of Data-Driven Groups Cutting across Children with ASD, ADHD, or OCD. Neuropsychopharmacology 2021, 46, 643–653. [Google Scholar] [CrossRef]
- Toki, E.I.; Tatsis, G.; Tatsis, V.A.; Plachouras, K.; Pange, J.; Tsoulos, I.G. Employing Classification Techniques on SmartSpeech Biometric Data towards Identification of Neurodevelopmental Disorders. Signals 2023, 4, 401–420. [Google Scholar] [CrossRef]
- Toki, E.I.; Tatsis, G.; Pange, J.; Plachouras, K.; Christodoulides, P.; Kosma, E.I.; Chronopoulos, S.K.; Zakopoulou, V. Can Eye Tracking Identify Prognostic Markers for Learning Disabilities? A Preliminary Study. In Proceedings of the New Realities, Mobile Systems and Applications; Springer: Cham, Switzerland, 2022; pp. 1032–1039. [Google Scholar] [CrossRef]
- Kim, H.H.; An, J.I.; Park, Y.R. A Prediction Model for Detecting Developmental Disabilities in Preschool-Age Children Through Digital Biomarker-Driven Deep Learning in Serious Games: Development Study. JMIR Serious Games 2021, 9, e23130. [Google Scholar] [CrossRef]
- Pandria, N.; Petronikolou, V.; Lazaridis, A.; Karapiperis, C.; Kouloumpris, E.; Spachos, D.; Fachantidis, A.; Vasiliou, D.; Vlahavas, I.; Bamidis, P. Information System for Symptom Diagnosis and Improvement of Attention Deficit Hyperactivity Disorder: Protocol for a Nonrandomized Controlled Pilot Study. JMIR Res. Protoc. 2022, 11, e40189. [Google Scholar] [CrossRef]
- Rello, L.; Baeza-Yates, R.; Ali, A.; Bigham, J.P.; Serra, M. Predicting Risk of Dyslexia with an Online Gamified Test. PLoS ONE 2020, 15, e0241687. [Google Scholar] [CrossRef]
- Toki, E.I.; Zakopoulou, V.; Tatsis, G.; Plachouras, K.; Siafaka, V.; Kosma, E.I.; Chronopoulos, S.K.; Filippidis, D.E.; Nikopoulos, G.; Pange, J.; et al. A Game-Based Smart System Identifying Developmental Speech and Language Disorders in Child Communication: A Protocol Towards Digital Clinical Diagnostic Procedures. In New Realities, Mobile Systems and Applications; Auer, M.E., Tsiatsos, T., Eds.; Lecture Notes in Networks and Systems; Springer International Publishing: Cham, Switzerland, 2022; Volume 411, pp. 559–568. ISBN 978-3-030-96295-1. [Google Scholar]
- Ensarioğlu, K.; İnkaya, T.; Emel, E. Remaining Useful Life Estimation of Turbofan Engines with Deep Learning Using Change-Point Detection Based Labeling and Feature Engineering. Appl. Sci. 2023, 13, 11893. [Google Scholar] [CrossRef]
- Ding, C.; Peng, H. Minimum Redundancy Feature Selection from Microarray Gene Expression Data. J. Bioinform. Comput. Biol. 2005, 3, 185–205. [Google Scholar] [CrossRef]
- O’Neill, M.; Ryan, C. Grammatical Evolution. IEEE Trans. Evol. Comput. 2001, 5, 349–358. [Google Scholar] [CrossRef]
- Ryan, C.; O’Neill, M. Grammatical Evolution: Solving Trigonometric Identities. Available online: https://www.semanticscholar.org/paper/Grammatical-Evolution%3A-Solving-Trigonometric-Ryan-O%E2%80%99Neill/7d4bd6c4f2532d17272f36cef016fdf5b59eb4d1 (accessed on 30 November 2023).
- de la Puente, A.O.; Alfonso, R.S.; Moreno, M.A. Automatic Composition of Music by Means of Grammatical Evolution. In Proceedings of the 2002 Conference on APL: Array Processing Languages: Lore, Problems, and Applications, Madrid, Spain, 22–25 July 2002; pp. 148–155. [Google Scholar]
- Sabar, N.R.; Ayob, M.; Kendall, G.; Qu, R. Grammatical Evolution Hyper-Heuristic for Combinatorial Optimization Problems. IEEE Trans. Evol. Comput. 2013, 17, 840–861. [Google Scholar] [CrossRef]
- Gavrilis, D.; Tsoulos, I.G.; Dermatas, E. Selecting and Constructing Features Using Grammatical Evolution. Pattern Recognit. Lett. 2008, 29, 1358–1365. [Google Scholar] [CrossRef]
- Tzallas, A.T.; Tsoulos, I.; Tsipouras, M.G.; Giannakeas, N.; Androulidakis, I.; Zaitseva, E. Classification of EEG Signals Using Feature Creation Produced by Grammatical Evolution. In Proceedings of the 2016 24th Telecommunications Forum (TELFOR), Belgrade, Serbia, 22–23 November 2016; IEEE: New York, NY, USA, 2016; pp. 1–4. [Google Scholar]
- Tsoulos, I.G.; Tzallas, A.T.; Tsalikakis, D. Prediction of COVID-19 Cases Using Constructed Features by Grammatical Evolution. Symmetry 2022, 14, 2149. [Google Scholar] [CrossRef]
- Christou, V.; Tsoulos, I.; Arjmand, A.; Dimopoulos, D.; Varvarousis, D.; Tzallas, A.T.; Gogos, C.; Tsipouras, M.G.; Glavas, E.; Ploumis, A.; et al. Grammatical Evolution-Based Feature Extraction for Hemiplegia Type Detection. Signals 2022, 3, 737–751. [Google Scholar] [CrossRef]
- Tsoulos, I.G. QFC: A Parallel Software Tool for Feature Construction, Based on Grammatical Evolution. Algorithms 2022, 15, 295. [Google Scholar] [CrossRef]
- Park, J.; Sandberg, I.W. Universal Approximation Using Radial-Basis-Function Networks. Neural Comput. 1991, 3, 246–257. [Google Scholar] [CrossRef]
- Yu, H.; Xie, T.; Paszczynski, S.; Wilamowski, B.M. Advantages of Radial Basis Function Networks for Dynamic System Design. IEEE Trans. Ind. Electron. 2011, 58, 5438–5450. [Google Scholar] [CrossRef]
- Giveki, D.; Rastegar, H. Designing a New Radial Basis Function Neural Network by Harmony Search for Diabetes Diagnosis. Opt. Mem. Neural Netw. 2019, 28, 321–331. [Google Scholar] [CrossRef]
- Karimi, N.; Kazem, S.; Ahmadian, D.; Adibi, H.; Ballestra, L.V. On a Generalized Gaussian Radial Basis Function: Analysis and Applications. Eng. Anal. Bound. Elem. 2020, 112, 46–57. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Tzallas, A.; Tsalikakis, D. Use RBF as a Sampling Method in Multistart Global Optimization Method. Signals 2022, 3, 857–874. [Google Scholar] [CrossRef]
- Haykin, S.S.; Haykin, S.S. Neural Networks and Learning Machines, 3rd ed.; Prentice Hall: New York, NY, USA, 2009; ISBN 978-0-13-147139-9. [Google Scholar]
- Bishop, C. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Liao, Y.; Fang, S.-C.; Nuttle, H.L.W. Relaxed Conditions for Radial-Basis Function Networks to Be Universal Approximators. Neural Netw. 2003, 16, 1019–1028. [Google Scholar] [CrossRef]
- Hery, M.A.; Ibrahim, M.; June, L.W. BFGS Method: A New Search Direction. Sains Malays. 2014, 43, 1591–1597. [Google Scholar]
- Christou, V.; Miltiadous, A.; Tsoulos, I.; Karvounis, E.; Tzimourta, K.D.; Tsipouras, M.G.; Anastasopoulos, N.; Tzallas, A.T.; Giannakeas, N. Evaluating the Window Size’s Role in Automatic EEG Epilepsy Detection. Sensors 2022, 22, 9233. [Google Scholar] [CrossRef]
- Christou, V.; Tsoulos, I.; Loupas, V.; Tzallas, A.T.; Gogos, C.; Karvelis, P.S.; Antoniadis, N.; Glavas, E.; Giannakeas, N. Performance and Early Drop Prediction for Higher Education Students Using Machine Learning. Expert Syst. Appl. 2023, 225, 120079. [Google Scholar] [CrossRef]
- Toki, E.I.; Zakopoulou, V.; Tatsis, G.; Pange, J. Exploring the Main Principles for Automated Detec????on of Neurodevelopmental Disorders: Findings from Typically Developed Children. J. Med. Internet Res. 2023, preprint. [Google Scholar] [CrossRef]
- Georgoulas, G.; Gavrilis, D.; Tsoulos, I.G.; Stylios, C.; Bernardes, J.; Groumpos, P.P. Novel Approach for Fetal Heart Rate Classification Introducing Grammatical Evolution. Biomed. Signal Process. Control 2007, 2, 69–79. [Google Scholar] [CrossRef]
- CMUSphinx 2022. Available online: https://cmusphinx.github.io/2022/10/release/ (accessed on 4 December 2023).
- Pantazoglou, F.K.; Papadakis, N.K.; Kladis, G.P. Implementation of the Generic Greek Model for CMU Sphinx Speech Recognition Toolkit. In Proceedings of the International Scientific Conference eRA-12, Piraeus, Greece, 24–26 October 2017. [Google Scholar]
- SeeSo: Eye Tracking Software 2022. Available online: https://www.seeso.io/ (accessed on 4 December 2023).
- Guo, H.-W.; Huang, Y.-S.; Lin, C.-H.; Chien, J.-C.; Haraikawa, K.; Shieh, J.-S. Heart Rate Variability Signal Features for Emotion Recognition by Using Principal Component Analysis and Support Vectors Machine. In Proceedings of the 2016 IEEE 16th International Conference on Bioinformatics and Bioengineering (BIBE), Taichung, Taiwan, 31 October–2 November 2016; IEEE: New York, NY, USA, 2016; pp. 274–277. [Google Scholar]
- Rahman, M.M.; Usman, O.L.; Muniyandi, R.C.; Sahran, S.; Mohamed, S.; Razak, R.A. A Review of Machine Learning Methods of Feature Selection and Classification for Autism Spectrum Disorder. Brain Sci. 2020, 10, 949. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type | Description—Examples |
|---|---|
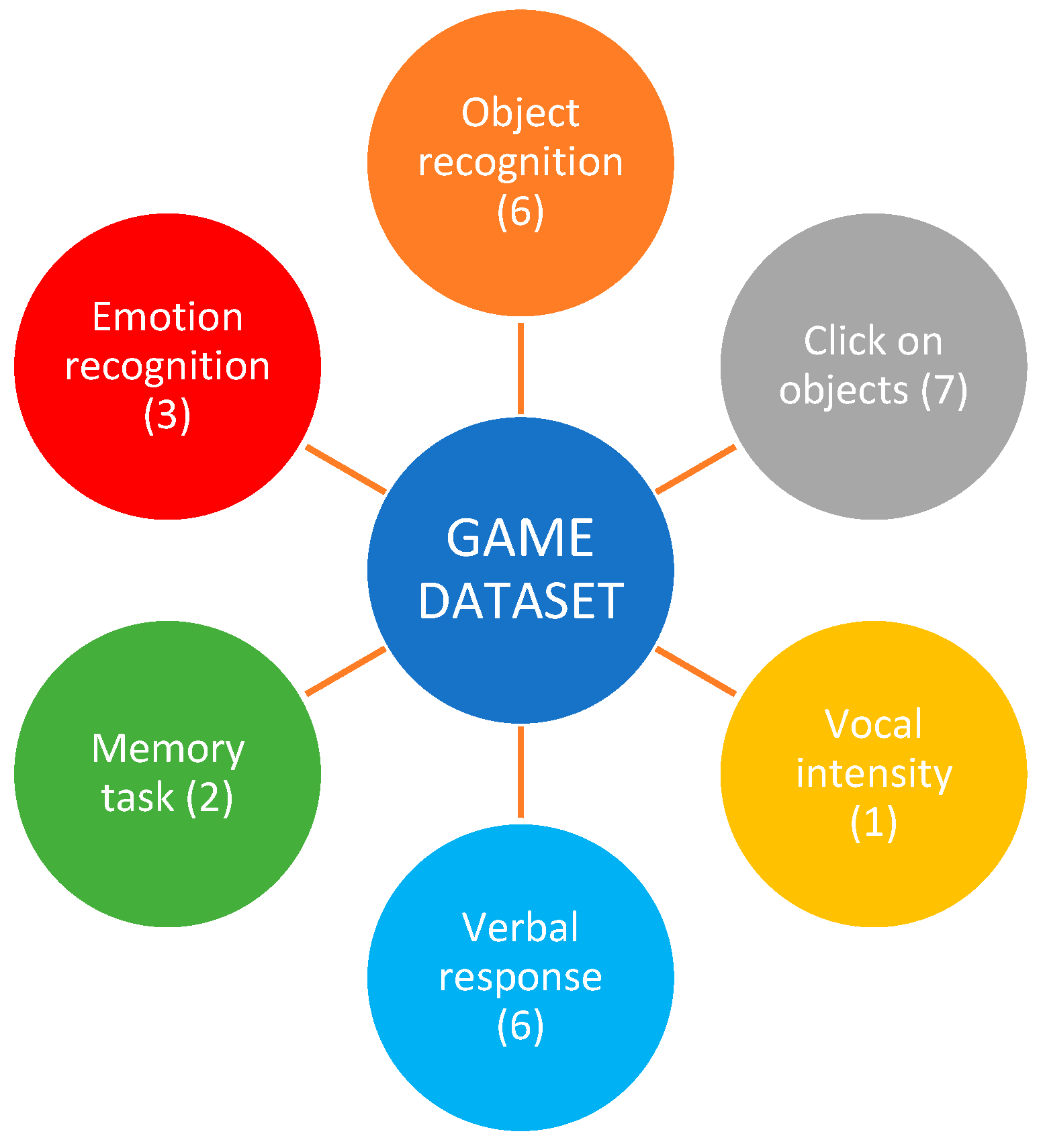
| Objects recognition | Identification of shadow (shape) Identification of object by acoustic stimuli Categorization (i.e., distinguishing fruits from vegetables) Time sequences (i.e., setting pictures to correct order) |
| Click on objects | Burst balloons Color sequences (i.e., fill bridge gap with colored boards) Pre-writing skills (i.e., move a teleferic with hand) Cognitive flexibility (i.e., lead character out of a maze) Sustained attention (i.e., catch thrown fruits in basket) Fine motor skills (i.e., solve classic puzzle with pieces) Sequences for size (arrange boards according to size) |
| Vocal intensity | Avoid clouds using voice intensity in a flying game |
| Verbal responses | Repeat a vocalization (word) Naming objects Answer questions Naming feelings |
| Memory tasks | Recall names of characters Remember object’s position in a grid |
| Emotion recognition | Color sequences (i.e., fill bridge gap with colored boards) |
| Parameter Name | Value | Parameter |
|---|---|---|
| NC | 500 | Chromosomes |
| NF | 2 | Number of constructed features |
| NG | 200 | Maximum number of generations |
| H | 10 | Processing nodes |
| pS | 0.10 | Selection rate |
| pM | 0.05 | Mutation rate |
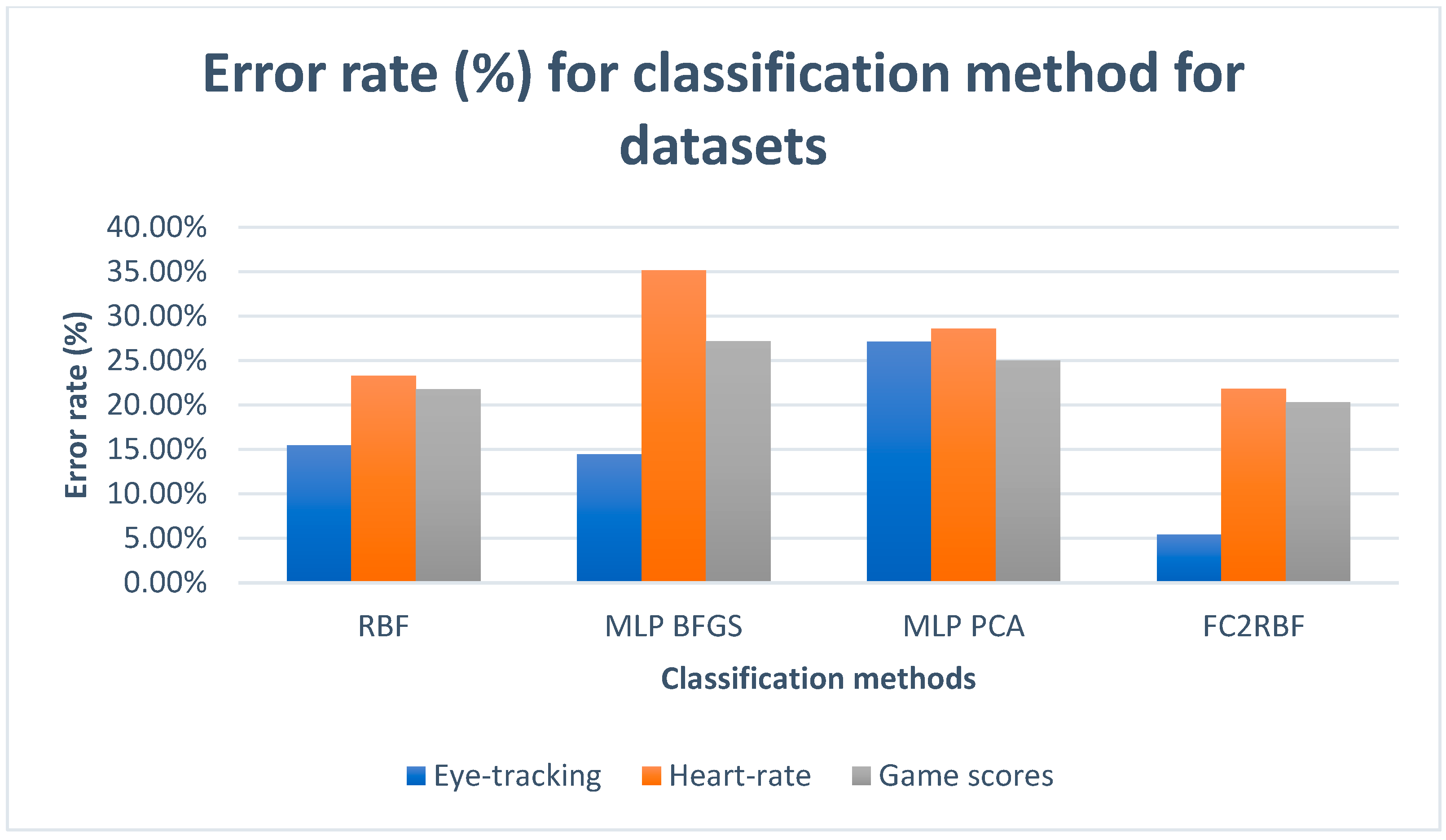
| Method | ||||
|---|---|---|---|---|
| FC2RBF | RBF | MLP BFGS | MLP PCA | DATASET |
| 5.41% | 15.48% | 14.45% | 27.16% | Eye-tracking |
| 21.85% | 23.28% | 35.19% | 28.58% | Heart rate |
| 20.33% | 21.81% | 27.20% | 25.04% | Game scores |
| Method | ||||
|---|---|---|---|---|
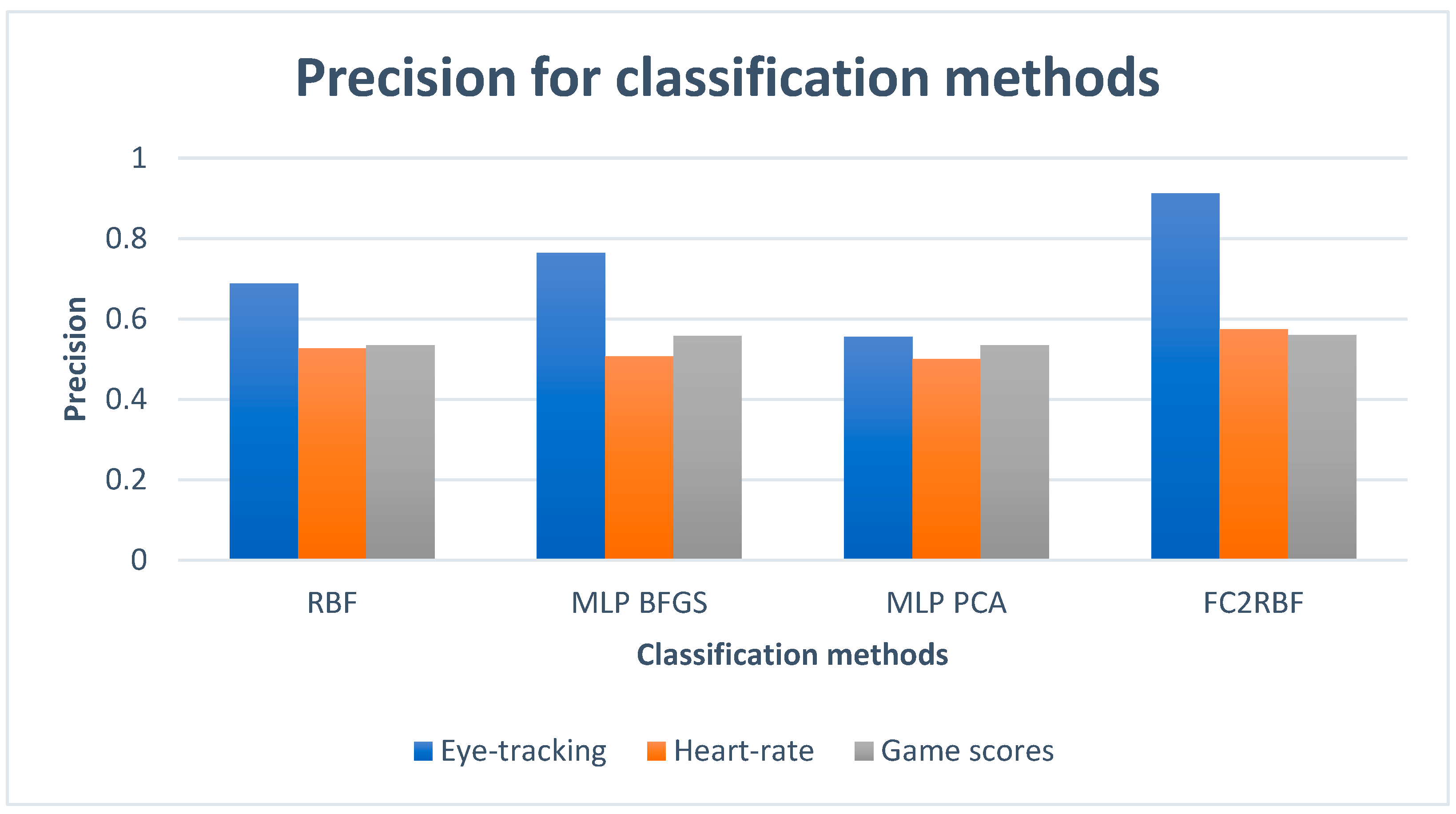
| FC2RBF | RBF | MLP BFGS | MLP PCA | DATASET |
| 0.9125 | 0.6887 | 0.7644 | 0.5558 | Eye-tracking |
| 0.5748 | 0.5264 | 0.5067 | 0.5006 | Heart rate |
| 0.5604 | 0.5344 | 0.5574 | 0.5344 | Game scores |
| Method | ||||
|---|---|---|---|---|
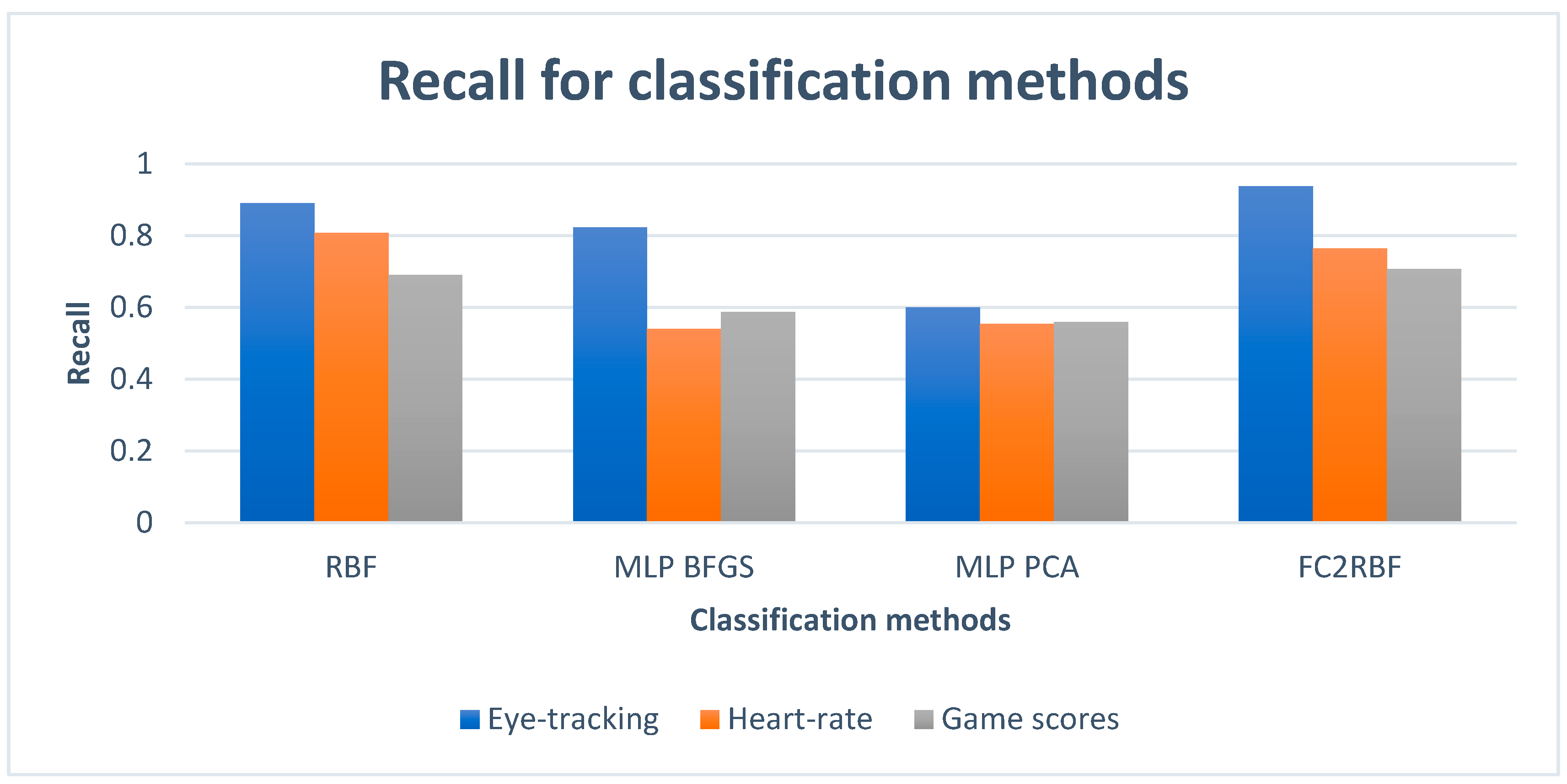
| FC2RBF | RBF | MLP BFGS | MLP PCA | DATASET |
| 0.9371 | 0.8906 | 0.8231 | 0.6004 | Eye-tracking |
| 0.7639 | 0.8076 | 0.5405 | 0.5545 | Heart rate |
| 0.7065 | 0.6905 | 0.5872 | 0.5598 | Game scores |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toki, E.I.; Tatsis, G.; Pange, J.; Tsoulos, I.G. Constructing Features for Screening Neurodevelopmental Disorders Using Grammatical Evolution. Appl. Sci. 2024, 14, 305. https://doi.org/10.3390/app14010305
Toki EI, Tatsis G, Pange J, Tsoulos IG. Constructing Features for Screening Neurodevelopmental Disorders Using Grammatical Evolution. Applied Sciences. 2024; 14(1):305. https://doi.org/10.3390/app14010305
Chicago/Turabian StyleToki, Eugenia I., Giorgos Tatsis, Jenny Pange, and Ioannis G. Tsoulos. 2024. "Constructing Features for Screening Neurodevelopmental Disorders Using Grammatical Evolution" Applied Sciences 14, no. 1: 305. https://doi.org/10.3390/app14010305