

An Intuitionistic Fuzzy-Rough Set-Based Classification for Anomaly Detection

Abstract
:1. Introduction
- First of all, a formula for correlation coefficient of IFSs is defined.
- Finally, a classification-based hybrid algorithm (IFRSCAD) consisting of both IFS and RS is proposed to generate the certain and possible fuzzy rules.
2. Related Works
3. Problem Definitions
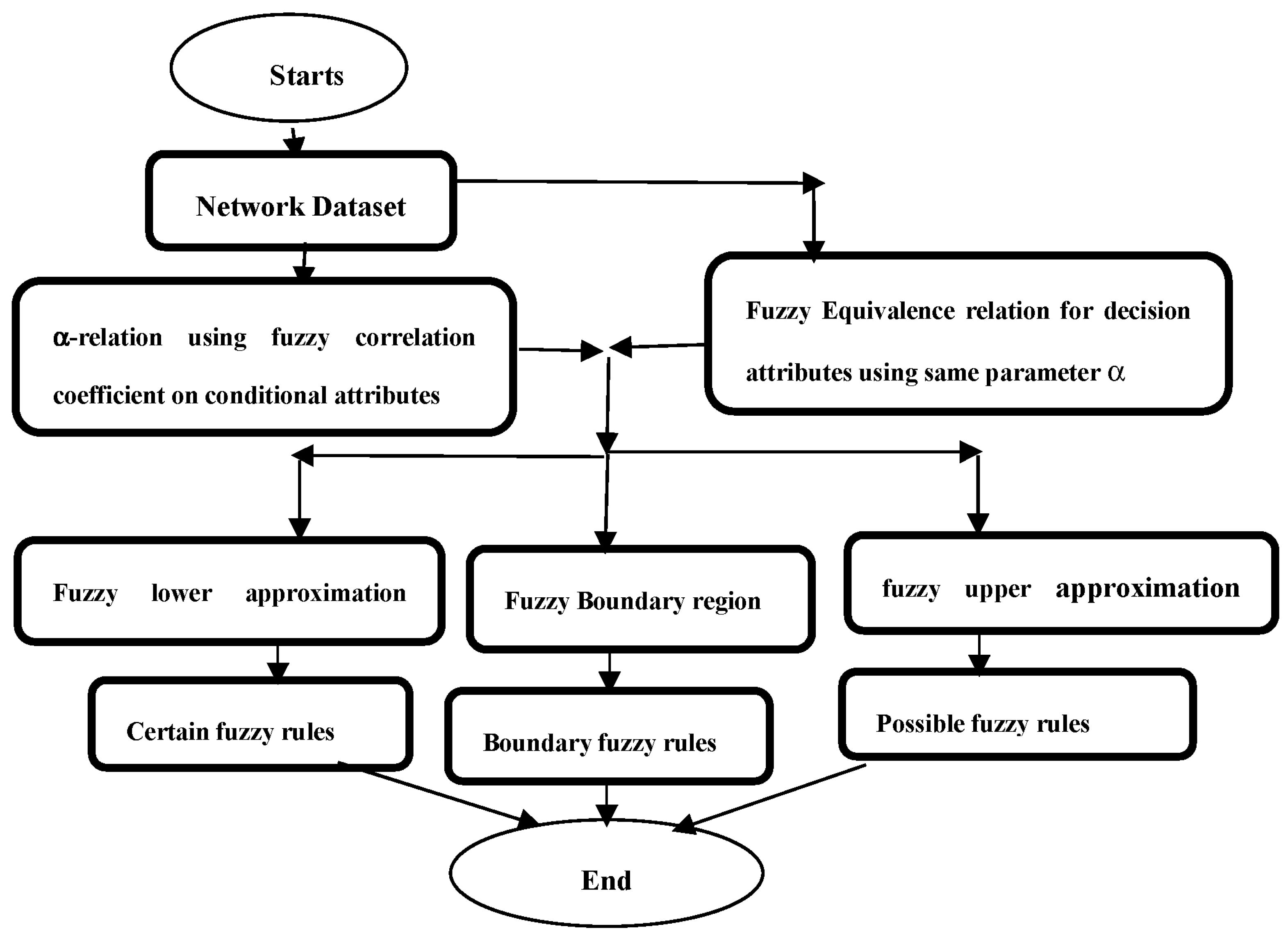
4. Proposed Algorithm
| Algorithm 1: IFRSCAD | |
| 1: | Input (U, C∪D), α//C, the conditional fuzzy attributes, D, the decision fuzzy attributes |
| 2: | Step1. Create α-relation on C using correlation coefficient. |
| 3: | Step2. Create the fuzzy equivalence relation for D. |
| 4: | Step3. Apply ‘infimum’ operator on the fuzzy granules of records of U brought up by C. |
| 5: | Step4. Construct separately nano lower approximation space Nano upper approximation space for D and the result of fuzzy granules after applying ‘infimum’ to C. |
| 6: | Step5. Find boundary regions. |
| 7: | Step6. Generate certain fuzzy rules from nano lower approximation space, possible fuzzy rules from nano upper approximation, and boundary rules from boundary region. |
5. Complexity Analysis
6. Experimental Analysis and Results
6.1. Datasets
6.2. Experimental Results and Analysis
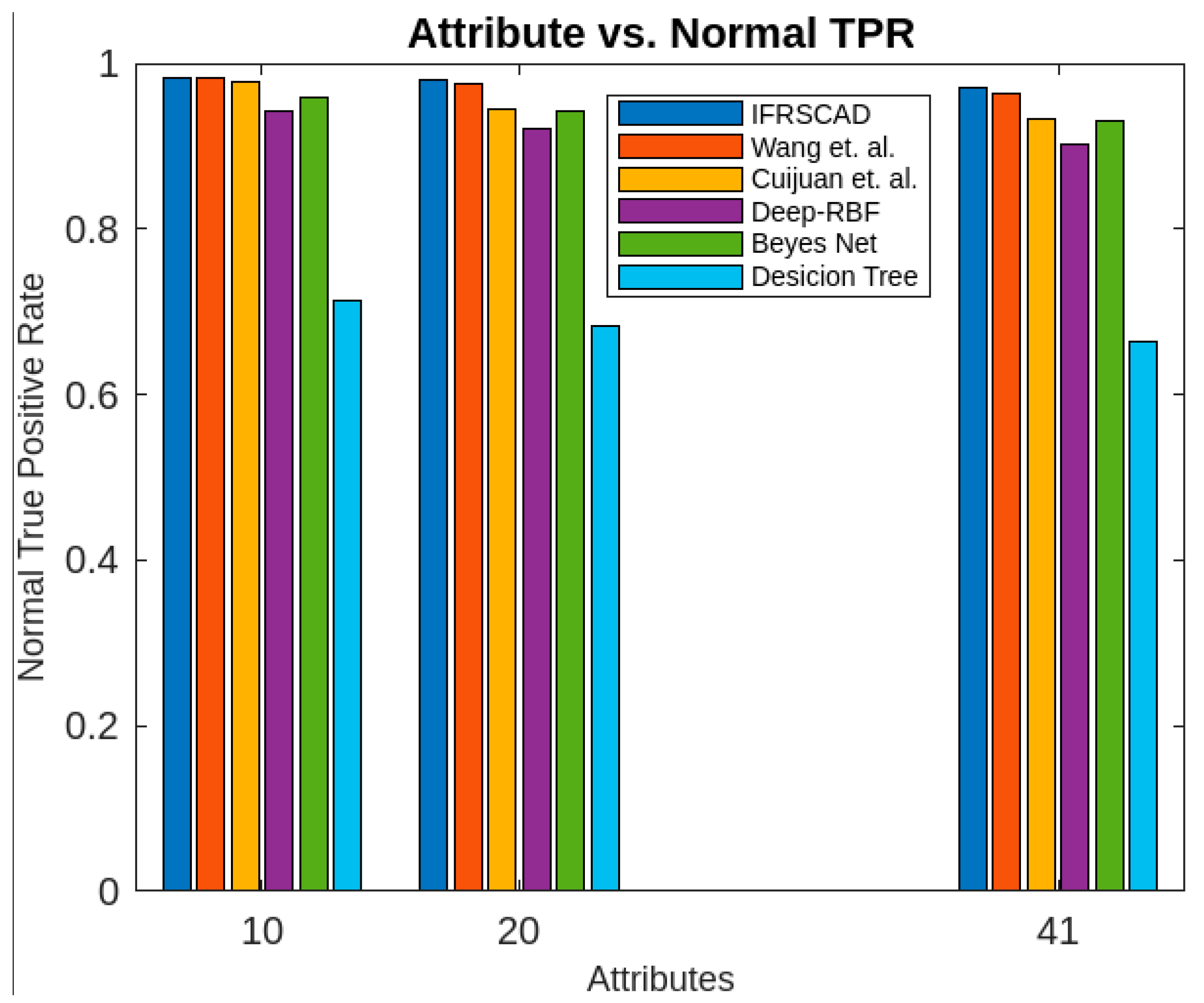
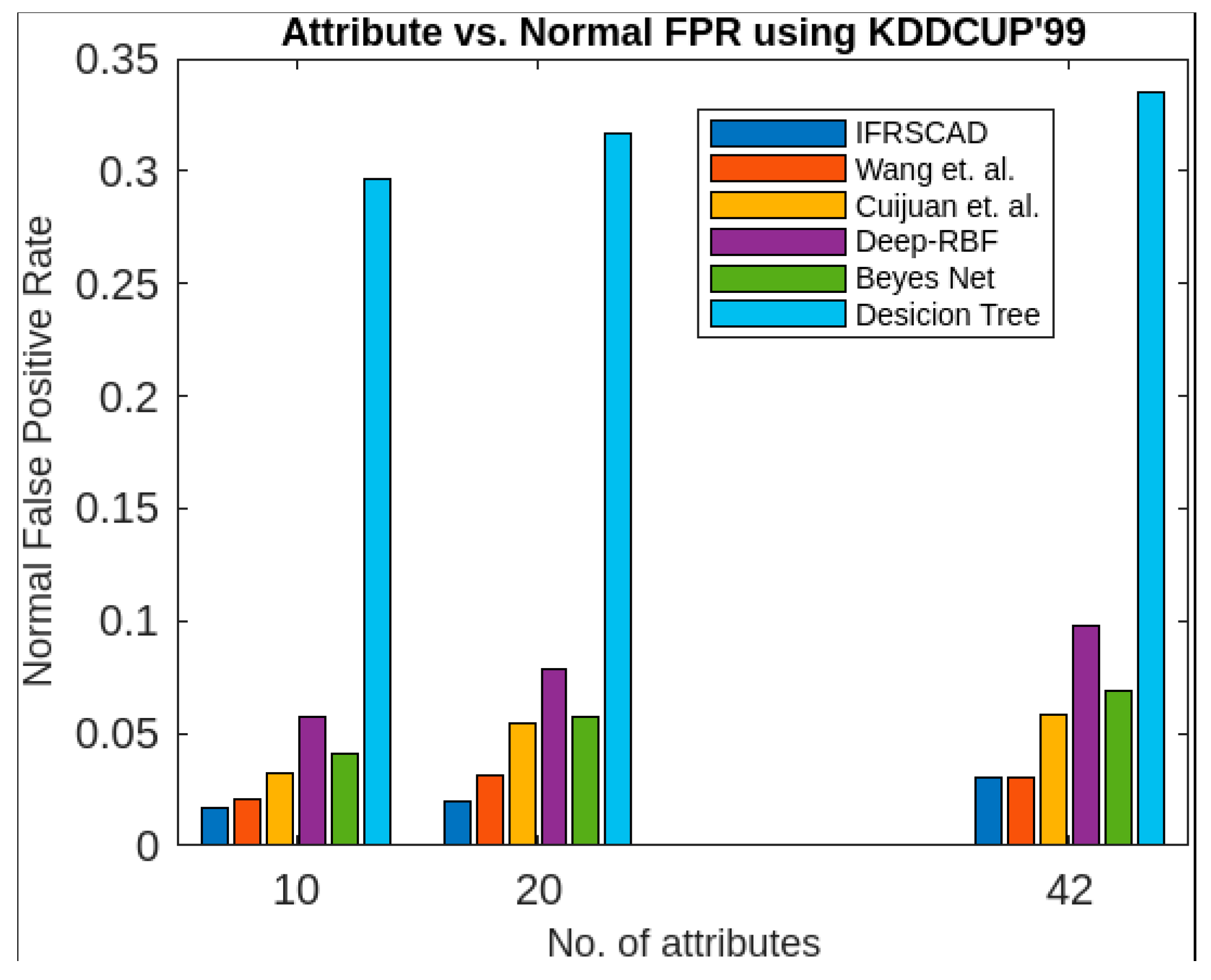
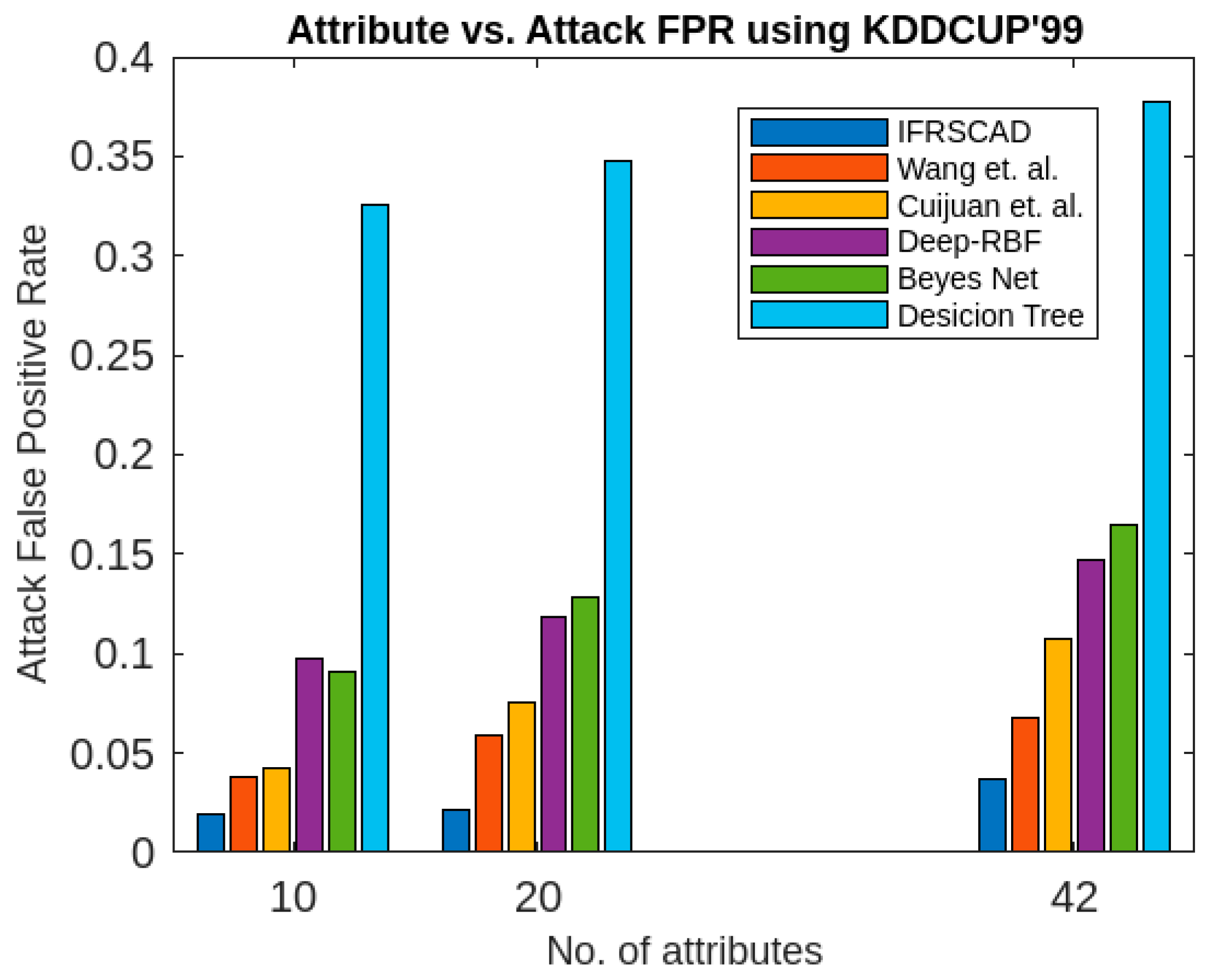
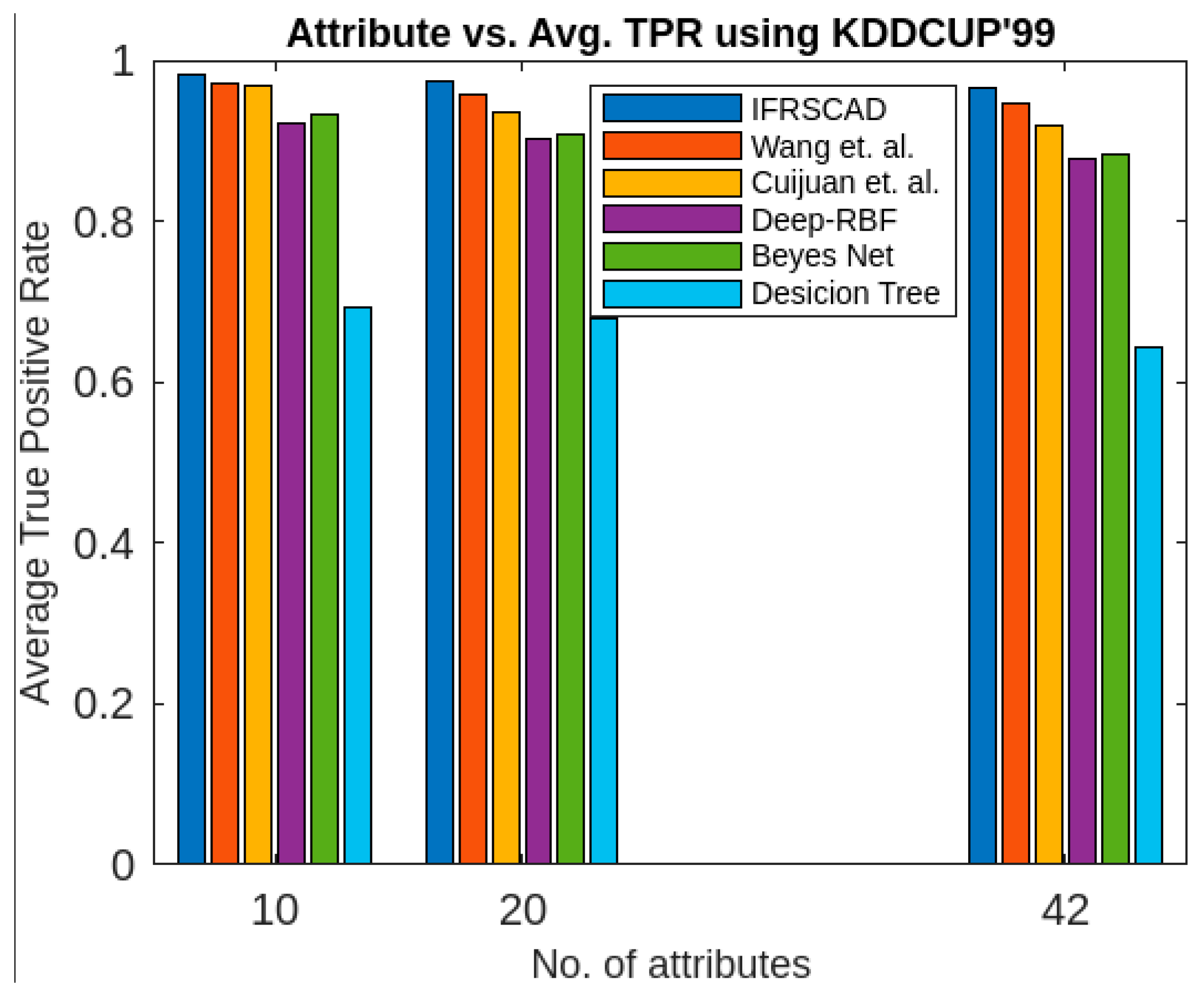
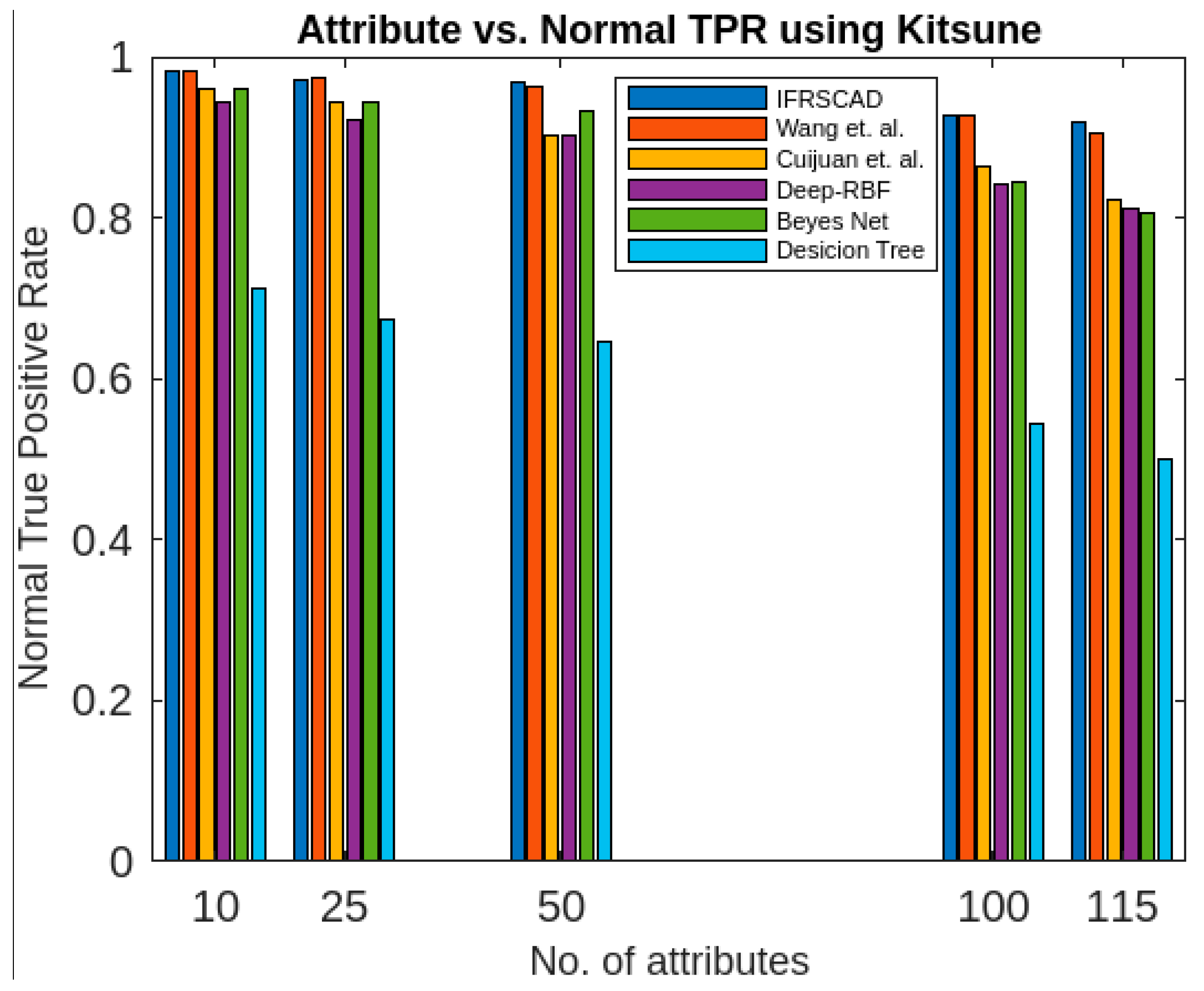
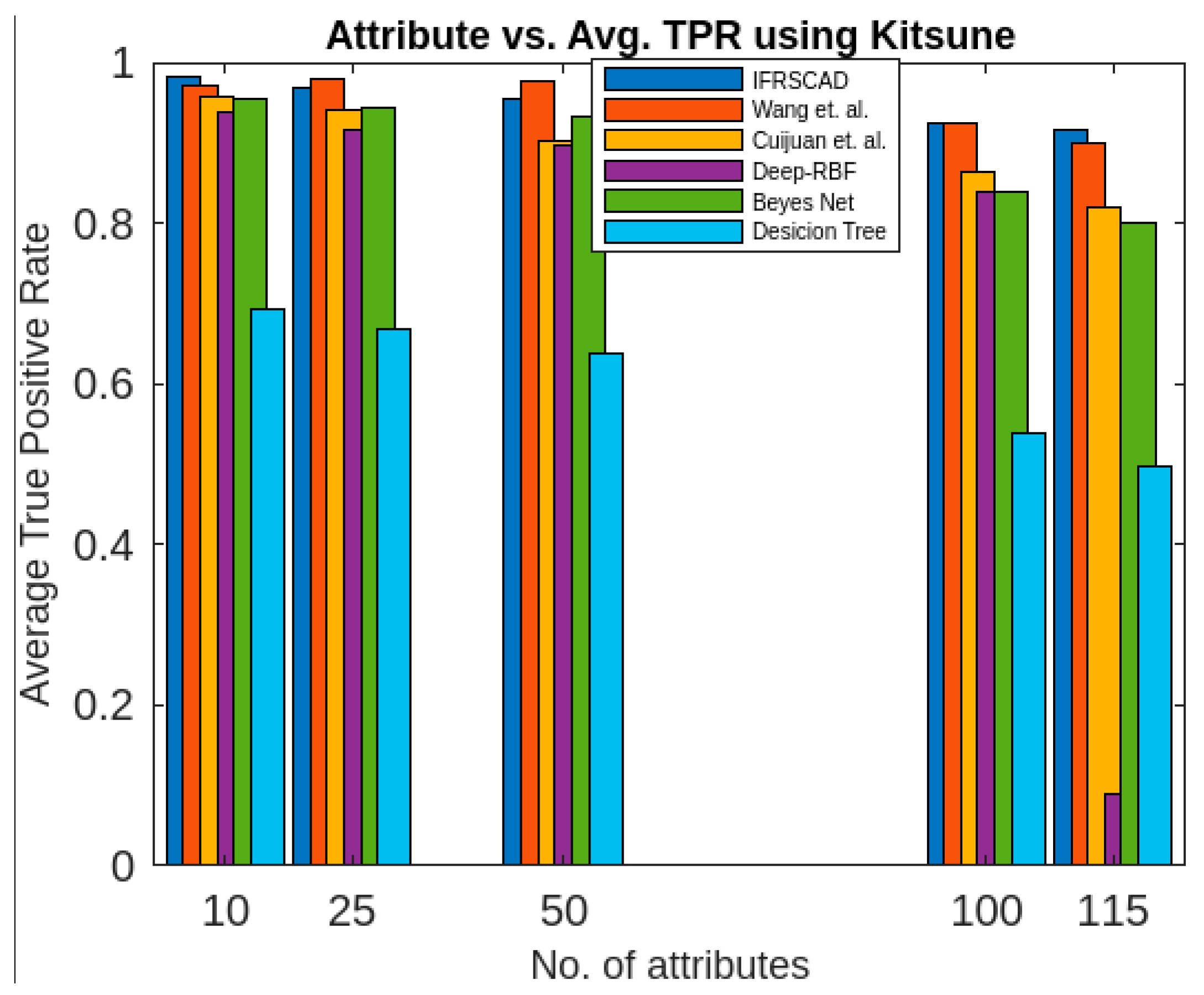
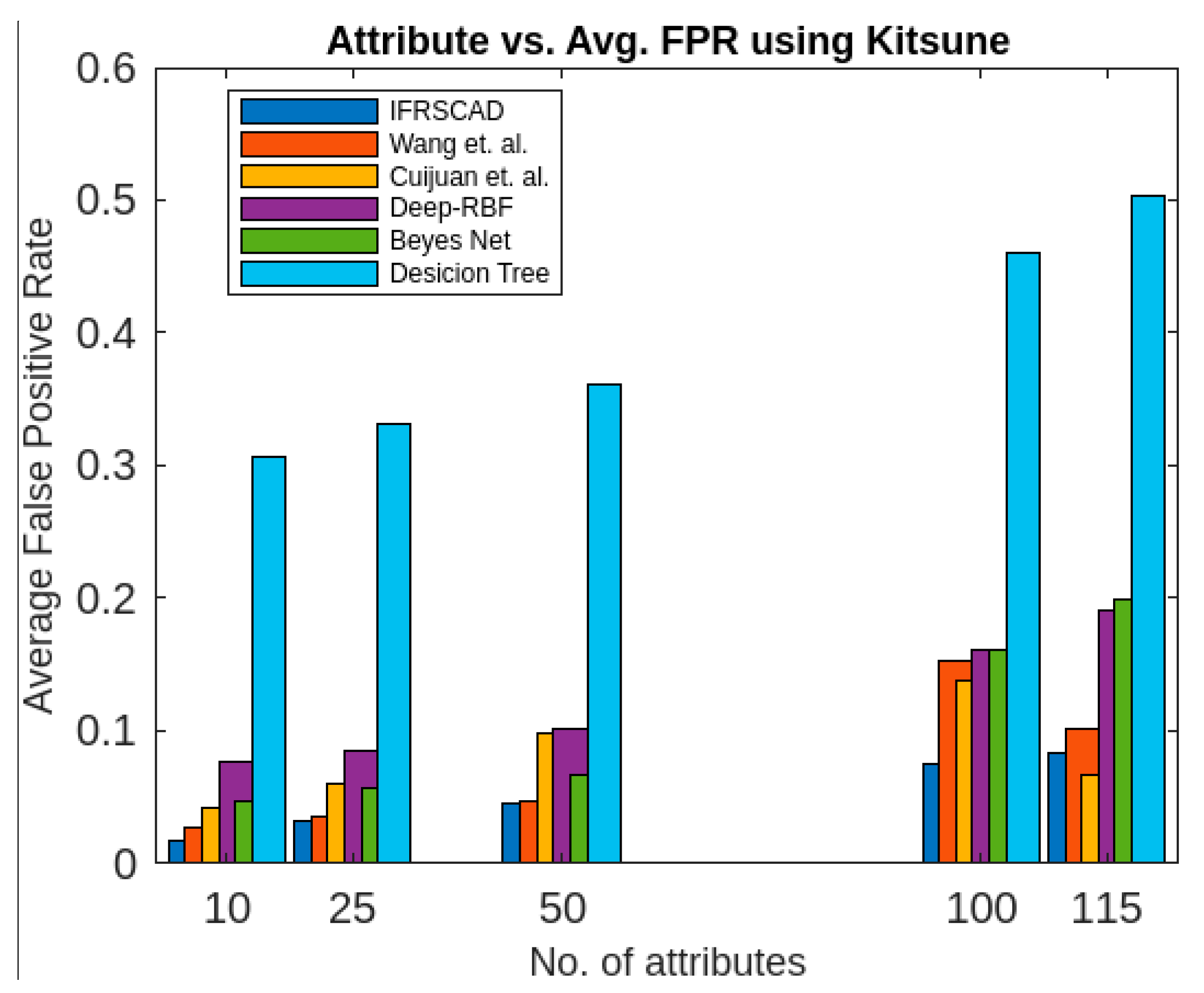
- The decision-tree-based algorithm [14] has the poorest detection rate. It has 71.31–66.49% of normal TPR, 67.44–62.23% of attack TPR, 29.69–33.51% of normal FPR, and 32.56–37.71% of attack FPR for ascending order of attribute sizes (from 10–41) of the dataset KDDCUP’99 [52]. Similarly, it has 71.31–50.12% of normal TPR, 67.44–49.34% of attack TPR, 28.69–49.88% of normal FPR, and 32.56–50.56% of attack FPR for ascending order of attribute sizes (from 10–115) of the dataset Kitsune [53]. It shows that the algorithm has the poorest performances, which decreases with the increase in dimension size of the dataset.
- The deep-RBF-network-based algorithm [16] is better than the decision-tree-based algorithm [14] and it has 94.25–90.25% of normal TPR, 90.23–85.25% of attack TPR, 5.75–9.75% of normal FPR, and 9.75–14.75% of attack FPR for ascending order of attribute sizes (from 10–41) of the dataset KDDCUP’99 [52]. Similarly, it has 94.25–81.21% of normal TPR, 93.11–80.56% of attack TPR, 5.75–18.79% of normal FPR, and 6.89–19.44% of attack FPR for ascending order of attribute sizes (from 10–115) of the dataset Kitsune [53].
- The Bayes-network-based algorithm [15] is better than the decision-tree-based algorithm [14] and the deep-RBF-network-based algorithm [16] in terms of detection rates. It has 95.87–93.13% of normal TPR, 90.87–83.49% of attack TPR, 4.13–6.87% of normal FPR, and 9.136–16.51% of attack FPR for ascending order of attribute sizes (from 10–41) of the dataset KDDCUP’99 [52]. Similarly, it has 95.87–80.55% of normal TPR, 94.8–79.53% of attack TPR, 4.13–19.45% of normal FPR, and 5.20–20.47% of attack FPR for ascending order of attribute sizes (from 10–115) of the dataset Kitsune [53]. Although the algorithm is quite efficient, its performance decreases with the increase in the dimension of the datasets.
- Cuijuan et al.’s algorithm [17] is better than all the previous three algorithms as far as detection rate is concerned. It has 97.75–93.25% of normal TPR, 95.25–89.25% of attack TPR, 3.20–5.80% of normal FPR, and 4.25–10.75% of attack FPR for ascending order of attribute sizes (from 10–41) of the dataset KDDCUP’99 [52]. Similarly, it has 95.95–82.32% of normal TPR, 95.75–81.42% of attack TPR, 4.05–18.232% of normal FPR, and 4.25–18.58% of attack FPR for ascending order of attribute sizes (from 10–115) of the dataset Kitsune [53]. Its performance also decreases proportionately with the increase in the dimension of the datasets.
- Wang et al.’s algorithm [35] is the most efficient in comparison with all the aforesaid algorithms. It has 98.21–96.25% of normal TPR, 96.21–93.25% of attack TPR, 2.12–3.02% of normal FPR, and 3.79–6.75% of attack FPR for ascending order of attribute sizes (from 10–42) of the dataset KDDCUP’99 [52]. Similarly, it has 98.21–90.44% of normal TPR, 96.21–89.33% of attack TPR, 1.79–9.56% of normal FPR, and 3.79–10.67% of attack FPR for ascending order of attribute sizes (from 10–115) of the dataset Kitsune [53]. Its performance also decreases proportionately with the increase in the dimension of the datasets.
- The proposed algorithm (IFRSCAD) has 98.342–96.99% of normal TPR, 98.04–96.29% of attack TPR, 1.658–3.01% of normal FPR, and 1.96–3.71% of attack FPR for ascending order of attribute sizes (from 10–42) of the dataset KDDCUP’99 [52]. Similarly, it has 98.342–91.989% of normal TPR, 98.04–91.289% of attack TPR, 1.658–8.011% of normal FPR, and 1.96–8.711% of attack FPR for ascending order of attribute sizes (from 10–115) of the dataset Kitsune [53]. Its performance also decreases proportionately with the increase in the dimension of datasets. It is clear from the data that the proposed algorithm has more TPR and less FPR. The difference between normal TPR and attack TPR and normal FPR and attack FPR is also less in comparison with other methods. The performance decrement is less with the increase in dimensions. Obviously, the IFRSCAD has more average TPR and less average FPR than others.
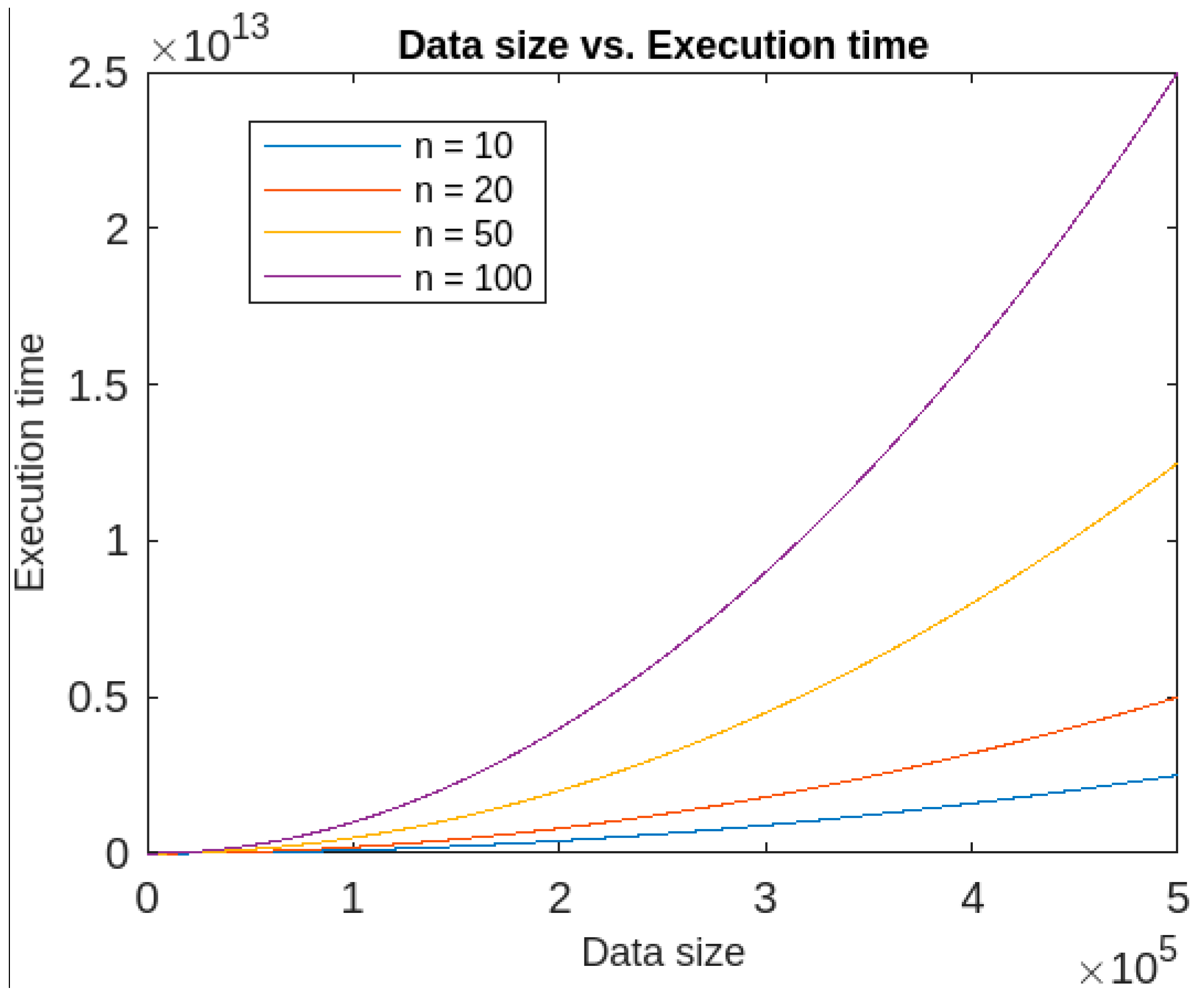
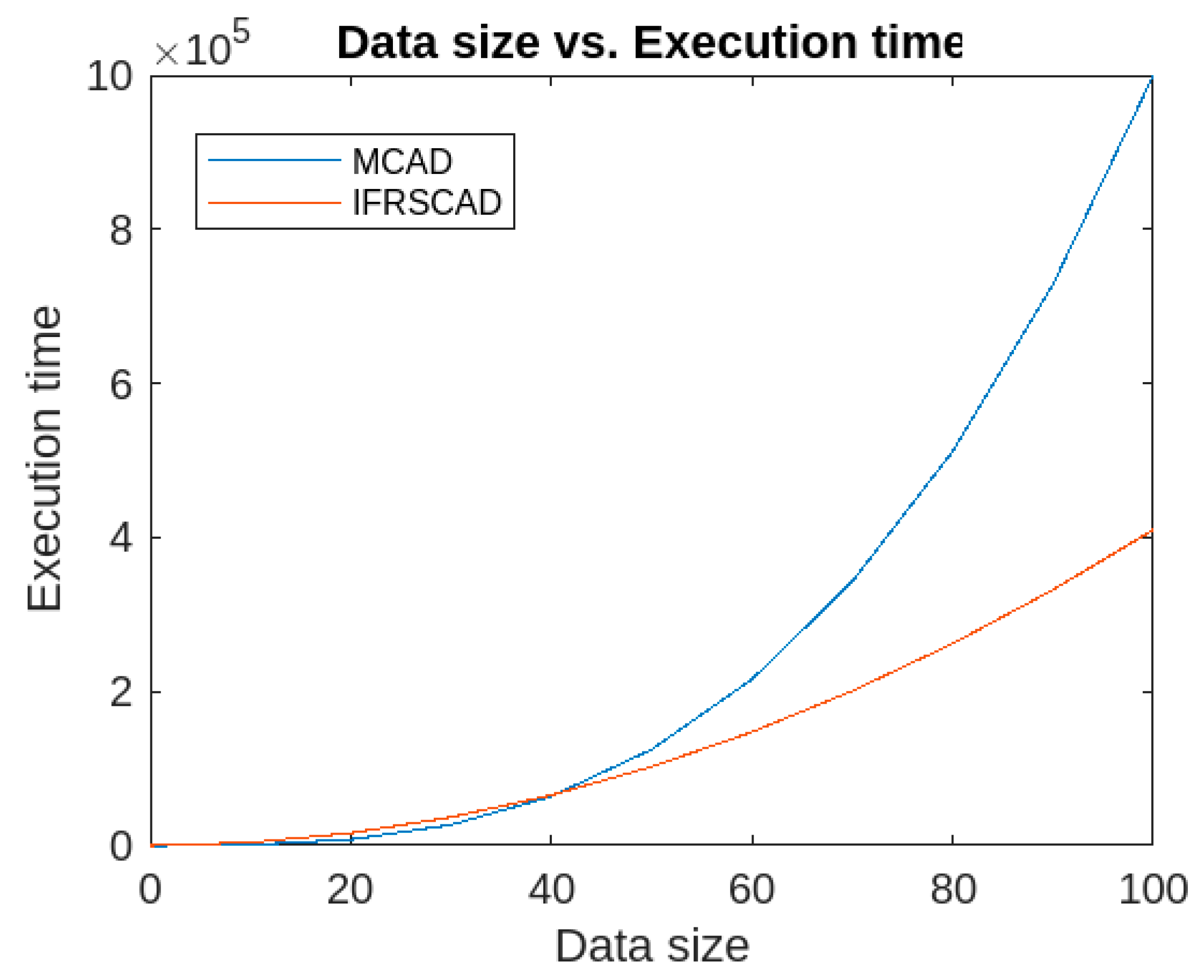
- In addition, the execution time of the IFRSCAD depends upon two factors, namely, dimension and size of the datasets. It was found that if the dimension is kept constant, the algorithm has quadratic execution time, whereas if the data size is kept constant, it runs in linear time. Therefore, the proposed algorithm’s time complexity is more dependent on the data size than the number of attributes. The time-complexity graphs for constant dimension and constant data size are given, respectively, in Figure 14 and Figure 15.
7. Conclusions, Limitations, and Lines for Future Work
7.1. Conclusions
7.2. Limitations and Lines for Future Work
- An effective method can be designed for anomaly detection in high-dimensional data.
- An effective method can be designed for anomaly detection from datasets with continuous attributes.
- An effective method can be designed for real-time anomaly from heterogeneous data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, V.; Banejee, A.; Chandola, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar]
- Hodge, V.; Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef]
- Jyothsna, V.; Prasad, K.M. Anomaly-Based Intrusion Detection System. In Computer and Network Security; BoD – Books on Demand: Paris, France, 2019; pp. 1–15. [Google Scholar]
- Jabez, J.; Muthikumar, B. Intrusion Detection System (IDS): Anomaly Detection using Outlier Detection Approach. Procedia Comput. Sci. 2015, 48, 338–346. [Google Scholar] [CrossRef]
- Díaz-Verdejo, J.; Muñoz-Calle, J.; Estepa Alonso, A.; Estepa Alonso, R.; Madinabeitia, G. On the Detection Capabilities of Signature-Based Intrusion Detection Systems in the Context of Web Attacks. Appl. Sci. 2022, 12, 852. [Google Scholar] [CrossRef]
- Al Mamun, S.M.A.; Valimaki, J. Anomaly Detection and Classification in Cellular Networks Using Automatic Labeling Technique for Applying Supervised Learning. Procedia Comput. Sci. 2018, 140, 186–195. [Google Scholar] [CrossRef]
- Dasgupta, D.; Majumdar, N.S. Anomaly detection in multidimensional data using negative selection algorithm. In Proceedings of the 2002 Congress on Evolutionary Computation, CEC, Honolulu, HI, USA, 12–17 May 2002; Volume 2, pp. 1039–1044. [Google Scholar]
- Taha, A.; Hadi, A.S. Anomaly Detection Methods for Categorical Data: A Review. ACM Comput. Surv. 2019, 52, 1–35. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, H.; Zhang, X.; Tian, L. An efficient framework for unsupervised anomaly detection over edge-assisted internet of things. ACM Trans. Sens. Netw. 2023; just accepted. [Google Scholar] [CrossRef]
- Mozaffari, M.; Doshi, K.; Yilmaz, Y. Self-Supervised Learning for Online Anomaly Detection in High-Dimensional Data Streams. Electronics 2023, 12, 1971. [Google Scholar] [CrossRef]
- Angiulli, F.; Fassetti, F.; Serrao, C. Anomaly detection with correlation laws. Data Knowl. Eng. 2023, 145, 102181. [Google Scholar] [CrossRef]
- Pujari, A.K. Data Mining Techniques; University Press (India) Pvt. Ltd.: Telangana, India, 2001. [Google Scholar]
- Mazarbhuiya, F.A. Detecting Anomaly using Neighborhood Rough Set based Classification Approach. ICIC Express Lett. 2023, 17, 73–80. [Google Scholar]
- Panasov, V.L.; Nechitaylo, N.M. Decision Trees-based Anomaly Detection in Computer Assessment Results. J. Phys. Conf. Ser. 2021, 2001, 012033. [Google Scholar] [CrossRef]
- Dufraisse, E.; Leray, P.; Nedellec, R.; Benkhelif, T. Interactive Anomaly Detection in Mixed Tabular Data Using Bayesian Networks. In Proceedings of the 10th International Conference on Probabilistic Graphical Models (PGM 2020), Aalborg, Denmark, 23–25 September 2020. [Google Scholar]
- Burruss, M.; Ramakrishna, S.; Dubey, A. Deep-RBF Networks for Anomaly Detection in Automotive Cyber-Physical Systems. Auton. Driv. Assur. Auton. 2021, 55–60. [Google Scholar] [CrossRef]
- Liu, C.; Li, Y.; Qin, Y. Research on Anomaly Intrusion Detection Based on Rough Set Attribute Reduction. In Proceedings of the 2nd International Conference on Computer Application and System Modeling (2012), Paris, France, 27–29 July 2012; Atlantis Press: Amsterdam, The Netherlands; pp. 607–610. [Google Scholar]
- Şengönül, E.; Samet, R.; Abu Al-Haija, Q.; Alqahtani, A.; Alturki, B.; Alsulami, A.A. An Analysis of Artificial Intelligence Techniques in Surveillance Video Anomaly Detection: A Comprehensive Survey. Appl. Sci. 2023, 13, 4956. [Google Scholar] [CrossRef]
- Fan, Z.; Wang, G.; Zhang, K.; Liu, S.; Zhong, T. Semi-Supervised Anomaly Detection via Neural Process. IEEE Trans. Knowl. Data Eng. 2023, 1–13. [Google Scholar] [CrossRef]
- Mazarbhuiya, F.A.; AlZahrani, M.Y.; Georgieva, L. Anomaly Detection Using Agglomerative Hierarchical Clustering Algorithm. In ICISA 2018; Lecture Notes on Electrical Engineering (LNEE); Springer: Hong Kong, China, 2019; Volume 514, pp. 475–484. [Google Scholar]
- Linquan, X.; Wang, W.; Liping, C.; Guangxue, Y. An Anomaly Detection Method Based on Fuzzy C-means Clustering Algorithm. In Proceedings of the Second International Symposium on Networking and Network Security, Jinggangshan, China, 2–4 April 2010; pp. 089–092. [Google Scholar]
- Mazarbhuiya, F.A.; AlZahrani, M.Y.; Mahanta, A.K. Detecting Anomaly Using Partitioning Clustering with Merging. ICIC Express Lett. 2020, 14, 951–960. [Google Scholar]
- Retting, L.; Khayati, M.; Cudre-Mauroux, P.; Piorkowski, M. Online anomaly detection over Big Data streams. In Proceedings of the 2015 IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015. [Google Scholar]
- Alguliyev, R.; Aliguliyev, R.; Sukhostat, L. Anomaly Detection in Big Data based on Clustering. Stat. Optim. Inf. Comput. 2017, 5, 325–340. [Google Scholar] [CrossRef]
- Alghawli, A.S. Complex methods detect anomalies in real time based on time series analysis. Alex. Eng. J. 2022, 61, 549–561. [Google Scholar] [CrossRef]
- Kim, B.; Alawami, M.A.; Kim, E.; Oh, S.; Park, J.; Kim, H. A Comparative Study of Time Series Anomaly Detection, Models for Industrial Control Systems. Sensors 2023, 23, 1310. [Google Scholar] [CrossRef]
- Wang, B.; Hua, Q.; Zhang, H.; Tan, X.; Nan, Y.; Chen, R.; Shu, X. Research on anomaly detection and real-time reliability evaluation with the log of cloud platform. Alex. Eng. J. 2022, 61, 7183–7193. [Google Scholar] [CrossRef]
- Halstead, B.; Koh, Y.S.; Riddle, P.; Pechenizkiy, M.; Bifet, A. Combining Diverse Meta-Features to Accurately Identify Recurring Concept Drit in Data Streams. ACM Trans. Knowl. Discov. Data, 2023; just accepted. [Google Scholar]
- Habeeb, R.A.A.; Nasauddin, F.; Gani, A.; Hashem, I.A.T.; Amanullah, A.M.E.; Imran, M. Clustering-based real-time anomaly detection—A breakthrough in big data technologies. Trans. Emerg. Telecommun. Technol. 2022, 33, e3647. [Google Scholar]
- Mazarbhuiya, F.A.; Shenify, M. A Mixed Clustering Approach for Real-Time Anomaly Detection. Appl. Sci. 2023, 13, 4151. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, F.; Zhu, J.; Chen, J. Searching Density-increasing Path to Local Density Peaks for Unsupervised Anomaly Detection. IEEE Trans. Big Data 2023, 1–12. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy Sets as Basis of Theory of Possibility. Fuzzy Sets Syst. 1978, 1, 3–28. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Eulalia, S.; Kukier, M. Atanassov’s Intuitionistic Fuzzy Sets in Classification of Imbalanced and Overlapping Classes. Intell. Tech. Tools Nov. Syst. Archit. 2008, 109, 455–471. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, H.; Xu, J.; Li, H.; Zhu, H.; Chao, S.; Zheng, C. Using Intuitionistic Fuzzy Set for Anomaly Detection of Network Traffic from Flow Interaction. IEEE Access 2018, 6, 596–601. [Google Scholar] [CrossRef]
- Gerstenkorn, T.; Manko, J. Correlation of Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1991, 44, 39–43. [Google Scholar] [CrossRef]
- Zadeh, L.A. Similarity relations and fuzzy orderings. Inf. Sci. 1971, 3, 177–200. [Google Scholar] [CrossRef]
- Kannan, S.R.; Mohapatra, R.K. New notions for fuzzy equivalence using α-cut relation. IOP Conf. Ser. J. Phys. Conf. Ser. 2019, 1344, 012040. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Robert, R. Nowicki, Rough Set Based Classification Systems; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Maroune, E.L.M.; Elhoussaine, Z. A fuzzy neighborhood rough set method for anomaly detection in large scale data. Int. J. Artif. Intell. 2020, 9, 1–10. [Google Scholar] [CrossRef]
- Li, Y.; Wei, S.; Liu, X.; Zhang, Z. A Novel Robust Fuzzy Rough Set Model for Feature Selection. Conplexity Hindawi 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Sangeetha, T.; Mary Amlanathan, G. Outlier detection in neutrosophic sets by using rough entropy based weighted density method. CAAI Trans. Intell. Technol. 2020, 5, 121–127. [Google Scholar] [CrossRef]
- Sangeetha, T.; Mary Amlanathan, G. A fuzzy proximity relation approach for outlier detection in the mixed dataset by using rough entropy-based weighted density method. Soft Comput. Lett. 2021, 3, 100027. [Google Scholar] [CrossRef]
- Yuan, Z.; Chen, B.; Liu, J.; Chen, H.; Peng, D.; Li, P. Anomaly detection based on weighted fuzzy-rough density. Appl. Soft Comput. 2023, 134, 109995. [Google Scholar] [CrossRef]
- Thivagar, M.L.; Richard, C. On nano forms of weakly open sets. Int. J. Math. Stat. Invent. 2013, 1, 31–37. [Google Scholar]
- Thivagar, M.L.; Priyalatha, S.P.R. Medical diagnosis in an indiscernibility matrix based on nano topology. Cogent Math. 2017, 4, 1–9. [Google Scholar]
- Al Shumrani, M.A.; Topal, S.; Smarandache, F.; Ozel, C. Covering-Based Rough Fuzzy, Intuitionistic Fuzzy and Neutrosophic Nano Topology and Applications. IEEE Access 2019, 7, 172839–172846. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Rough fuzzy sets and fuzzy rough sets. Int. J. Gen. Syst. 1990, 17, 191–209. [Google Scholar] [CrossRef]
- Maji, P.; Pal, S. Fuzzy–Rough Sets for Information Measures and Selection of Relevant Genes from Microarray Data. IEEE Trans. Syst. Man Cybern.—Part B Cybern. 2009, 40, 741–752. [Google Scholar] [CrossRef]
- Chimphlee, W.; Abdulla, H.; Noor, M.H.M.; Srinoy, S. Anomaly-based intrusion detection using Fuzzy-Rough Clustering. In Proceedings of the 2006 International Conference on Hybrid Information Technology; Washington, DC, USA, 9–11 November 2006, IEEE Explore: Piscataway, NJ, USA, 2006. [Google Scholar]
- KDD Cup’99 Data. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 15 January 2020).
- Kitsune Network Attack Dataset. Available online: https://github.com/ymirsky/Kitsune-py (accessed on 12 December 2021).
- Eman, E.G. An operation on intuitionistic Fuzzy Matrices. Filomat 2020, 34, 79–88. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Dataset Characteristics | Attribute Characteristics | No. of Instances | No. of Attributes |
|---|---|---|---|---|
| KDDCUP’99 Network Anomaly Detection dataset [44] | Multivariate | Numeric, categorical, temporal | 4,898,431 | 41 |
| Kitsune Network Attack dataset [45] | Multivariate, sequential, time series | Real, temporal | 27,170,754 | 115 |
| Algorithm | No. of Attributes | Normal TPR | Attack TPR | Normal FPR | Attack FPR | Avg. TPR | Avg. FPR |
|---|---|---|---|---|---|---|---|
| IFRSCAD | 41 | 0.9699 | 0.9629 | 0.03010 | 0.03710 | 0.9664 | 0.03360 |
| 20 | 0.97999 | 0.9789 | 0.02010 | 0.02110 | 0.974445 | 0.02060 | |
| 10 | 0.98342 | 0.9804 | 0.01658 | 0.01960 | 0.98191 | 0.01809 | |
| Wang et al. [35] | 41 | 0.9625 | 0.9325 | 0.0302 | 0.0675 | 0.9475 | 0.04885 |
| 20 | 0.9745 | 0.9415 | 0.0312 | 0.0585 | 0.9580 | 0.04485 | |
| 10 | 0.9821 | 0.9621 | 0.0212 | 0.0379 | 0.9721 | 0.02955 | |
| Cuijuan et al. [17] | 41 | 0.9325 | 0.8925 | 0.0580 | 0.1075 | 0.9175 | 0.08275 |
| 20 | 0.9445 | 0.9245 | 0.0540 | 0.0755 | 0.9345 | 0.06475 | |
| 10 | 0.9775 | 0.9575 | 0.0320 | 0.0425 | 0.9675 | 0.03725 | |
| Deep-RBF network | 41 | 0.9025 | 0.8525 | 0.0975 | 0.1475 | 0.8775 | 0.12250 |
| 20 | 0.9212 | 0.8812 | 0.0788 | 0.1188 | 0.9012 | 0.09880 | |
| 10 | 0.9425 | 0.9023 | 0.0575 | 0.0975 | 0.9225 | 0.07750 | |
| Bayes network | 41 | 0.9313 | 0.8349 | 0.0687 | 0.1651 | 0.8831 | 0.11690 |
| 20 | 0.9429 | 0.8720 | 0.0571 | 0.1328 | 0.9075 | 0.09255 | |
| 10 | 0.9587 | 0.9087 | 0.0413 | 0.0913 | 0.9337 | 0.05215 | |
| Decision tree | 41 | 0.6649 | 0.6223 | 0.3351 | 0.3771 | 0.6436 | 0.35610 |
| 20 | 0.6829 | 0.6520 | 0.3171 | 0.3480 | 0.6779 | 0.33255 | |
| 10 | 0.7131 | 0.6744 | 0.2969 | 0.3256 | 0.69375 | 0.31125 |
| Algorithm | No. of Attributes | Normal TPR | Attack TPR | Normal FPR | Attack FPR | Avg. TPR | Avg. FPR |
|---|---|---|---|---|---|---|---|
| IFRSCAD | 115 | 0.91989 | 0.91289 | 0.08011 | 0.08711 | 0.91639 | 0.08361 |
| 100 | 0.92766 | 0.92066 | 0.07234 | 0.07934 | 0.92416 | 0.07584 | |
| 50 | 0.9679 | 0.95116 | 0.04110 | 0.04884 | 0.95453 | 0.04497 | |
| 25 | 0.96999 | 0.96678 | 0.03010 | 0.03322 | 0.968385 | 0.03166 | |
| 10 | 0.98342 | 0.9804 | 0.01658 | 0.0196 | 0.98191 | 0.01809 | |
| Wang et al. [35] | 115 | 0.9044 | 0.8933 | 0.0956 | 0.1067 | 0.89885 | 0.10115 |
| 100 | 0.9277 | 0.9189 | 0.0723 | 0.0811 | 0.9233 | 0.1534 | |
| 50 | 0.9625 | 0.9425 | 0.0375 | 0.0575 | 0.9525 | 0.0475 | |
| 25 | 0.9745 | 0.9545 | 0.0255 | 0.0455 | 0.9645 | 0.0355 | |
| 10 | 0.9821 | 0.9621 | 0.0179 | 0.0379 | 0.9721 | 0.0279 | |
| Cuijuan et al. [17] | 115 | 0.8232 | 0.8142 | 0.18232 | 0.1858 | 0.8187 | 0.06703 |
| 100 | 0.8633 | 0.8621 | 0.1367 | 0.1379 | 0.8627 | 0.1373 | |
| 50 | 0.9025 | 0.9011 | 0.0975 | 0.0989 | 0.9018 | 0.0982 | |
| 25 | 0.9445 | 0.9345 | 0.0555 | 0.0645 | 0.9395 | 0.0600 | |
| 10 | 0.9595 | 0.9575 | 0.0405 | 0.0425 | 0.9585 | 0.0415 | |
| Deep-RBF network | 115 | 0.8121 | 0.8056 | 0.1879 | 0.1944 | 0.0885 | 0.19115 |
| 100 | 0.8411 | 0.8352 | 0.1589 | 0.1648 | 0.83815 | 0.16185 | |
| 50 | 0.9025 | 0.8933 | 0.0975 | 0.1067 | 0.8979 | 0.1021 | |
| 25 | 0.9212 | 0.9102 | 0.0788 | 0.0898 | 0.9157 | 0.0843 | |
| 10 | 0.9425 | 0.9311 | 0.0575 | 0.0689 | 0.9368 | 0.07750 | |
| Bayes network | 115 | 0.8055 | 0.7953 | 0.1945 | 0.2047 | 0.8004 | 0.1996 |
| 100 | 0.8432 | 0.8342 | 0.1568 | 0.1658 | 0.8387 | 0.1613 | |
| 50 | 0.9313 | 0.9349 | 0.0687 | 0.0651 | 0.9331 | 0.0669 | |
| 25 | 0.9429 | 0.9420 | 0.0571 | 0.0580 | 0.94245 | 0.05755 | |
| 10 | 0.9587 | 0.9480 | 0.0413 | 0.0520 | 0.95335 | 0.04665 | |
| Decision tree | 115 | 0.5012 | 0.4934 | 0.4988 | 0.5056 | 0.4973 | 0.5027 |
| 100 | 0.5434 | 0.5345 | 0.4566 | 0.4655 | 0.53895 | 0.46105 | |
| 50 | 0.6449 | 0.6323 | 0.3551 | 0.3677 | 0.6386 | 0.3614 | |
| 25 | 0.6729 | 0.6629 | 0.3271 | 0.3371 | 0.6679 | 0.3321 | |
| 10 | 0.7131 | 0.6744 | 0.2869 | 0.3256 | 0.69375 | 0.30625 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazarbhuiya, F.A.; Shenify, M. An Intuitionistic Fuzzy-Rough Set-Based Classification for Anomaly Detection. Appl. Sci. 2023, 13, 5578. https://doi.org/10.3390/app13095578
Mazarbhuiya FA, Shenify M. An Intuitionistic Fuzzy-Rough Set-Based Classification for Anomaly Detection. Applied Sciences. 2023; 13(9):5578. https://doi.org/10.3390/app13095578
Chicago/Turabian StyleMazarbhuiya, Fokrul Alom, and Mohamed Shenify. 2023. "An Intuitionistic Fuzzy-Rough Set-Based Classification for Anomaly Detection" Applied Sciences 13, no. 9: 5578. https://doi.org/10.3390/app13095578