
Multi-Attention-Guided Cascading Network for End-to-End Person Search

Abstract
:1. Introduction
- “In this paper, we propose a novel method termed Multi-Attention-Guided Cascading Network (MGCN), which can integrate multiple discriminative information with coarse-to-fine features from people to be retrieved for end-to-end person search tasks. By this unified framework, the trusted bounding box and person discriminant information can be exploited effectively”.
- “Moreover, we explore the attention maps of different clues to extract the person’s semantic regions, which promotes the network attention to different salient information from pedestrians. In addition, in order to reduce the interference of background information in the scene, we design the alignment module in our end-to-end network”.
- “Experiments on two challenging datasets confirm that MGCN markedly outperforms other person search methods and the proposed multi-attention module has significant advantages”.
2. Related Works
2.1. Person Re-Identification
2.2. Person Search
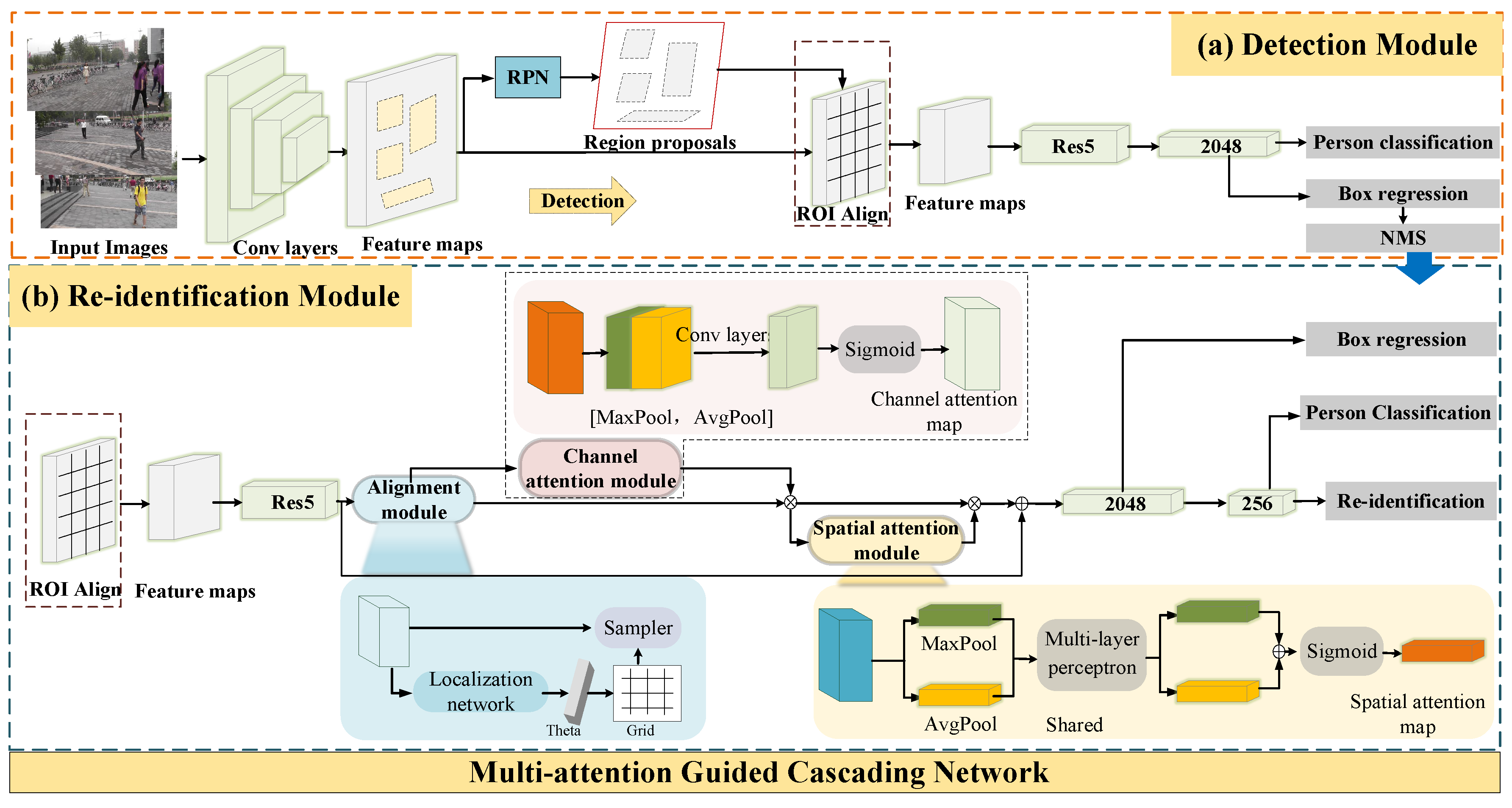
3. Proposed Method
3.1. Trustworthy Bounding Box Regression
3.2. Multi-Attention-Guided Re-Id Network
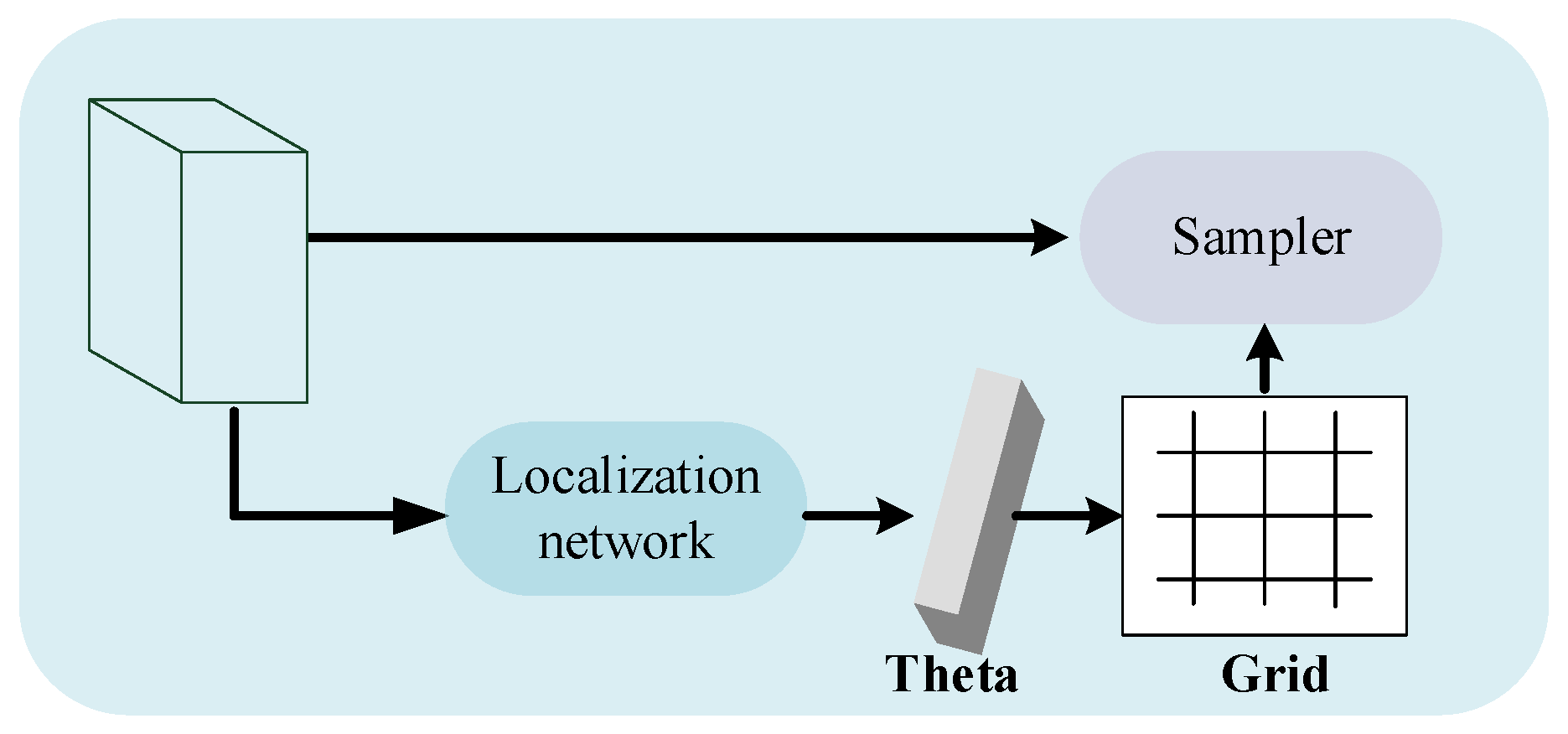
3.2.1. Aligning Module
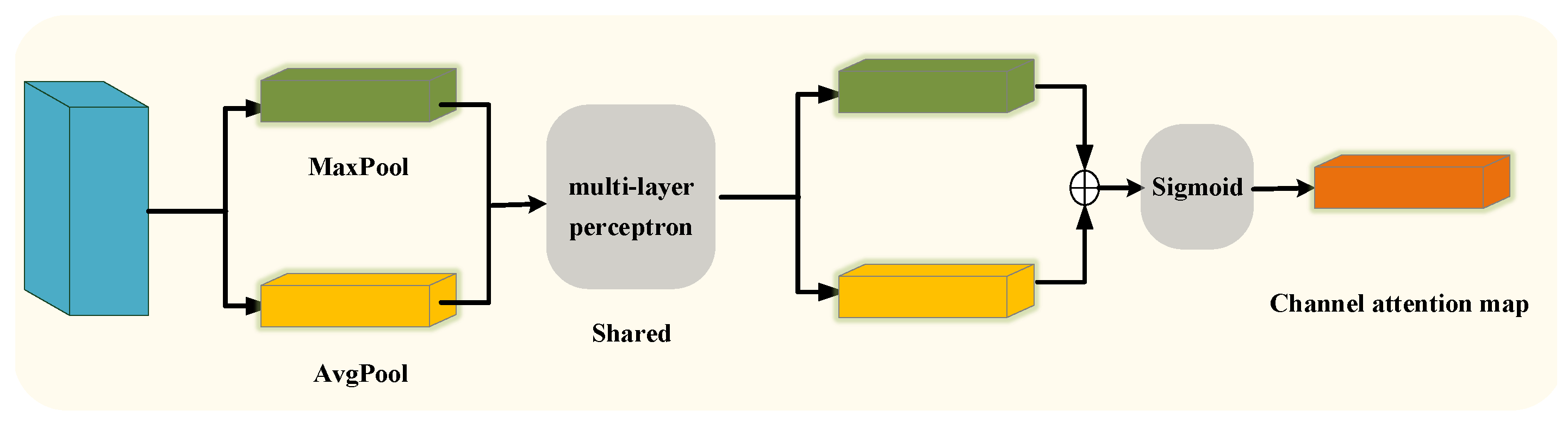
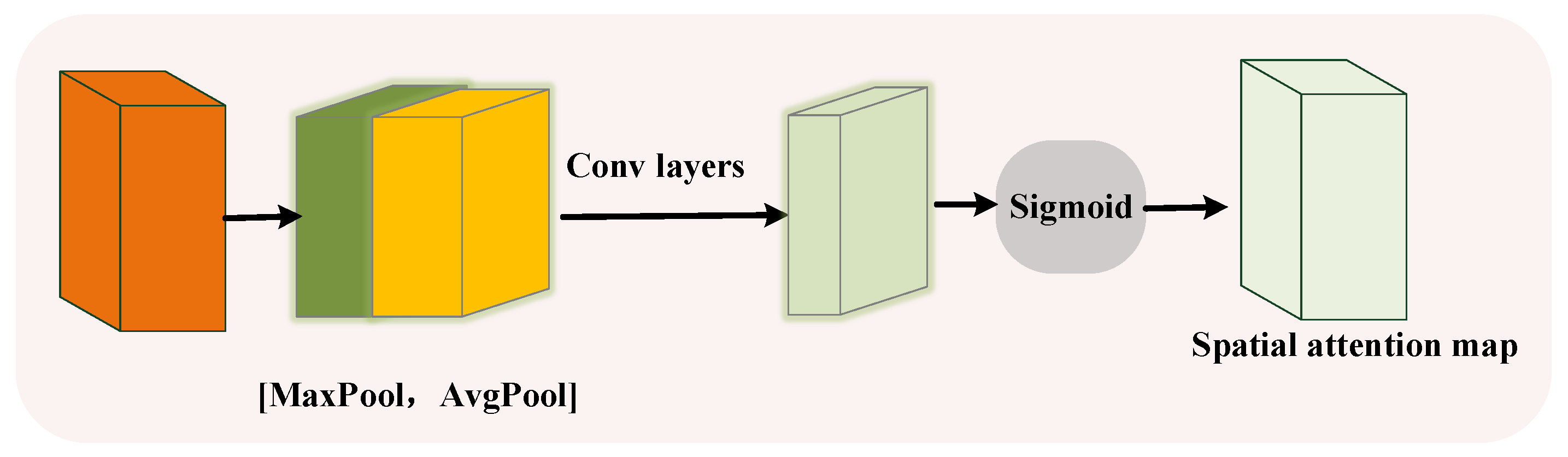
3.2.2. Multi-Attention-Guided Module for Person Search
3.3. Loss Function
| Algorithm 1 Algorithm of MGCN |
| Require: Person search dataset; |
| Ensure: Most similar person in each gallery image; |
|
4. Experiment
4.1. Datasets and Evaluation Protocols
4.1.1. Evaluation Metrics
4.1.2. Implementation Details
4.2. Experiment Results on Two Datasets
4.2.1. Evaluation on CUHK-SYSU
4.2.2. Evaluation on PRW
4.3. Ablation Study
Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Wang, Y.; Zhang, Z.; Fu, X.; Zhuo, L.; Xu, M.; Wang, M. Kernelized multiview subspace analysis by self-weighted learning. IEEE Trans. Multimed. 2020, 23, 3828–3840. [Google Scholar] [CrossRef]
- Wang, H.; Yao, M.; Jiang, G.; Mi, Z.; Fu, X. Graph-Collaborated Auto-Encoder Hashing for Multiview Binary Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Qian, B.; Wang, Y.; Yin, H.; Hong, R.; Wang, M. Switchable Online Knowledge Distillation. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Wang, H.; Peng, J.; Chen, D.; Jiang, G.; Zhao, T.; Fu, X. Attribute-guided feature learning network for vehicle reidentification. IEEE Multimed. 2020, 27, 112–121. [Google Scholar] [CrossRef]
- Wang, H.; Jiang, G.; Peng, J.; Deng, R.; Fu, X. Towards Adaptive Consensus Graph: Multi-view Clustering via Graph Collaboration. IEEE Trans. Multimed. 2022, 1–13. [Google Scholar] [CrossRef]
- Wang, H.; Peng, J.; Zhao, Y.; Fu, X. Multi-path deep cnns for fine-grained car recognition. IEEE Trans. Veh. Technol. 2020, 69, 10484–10493. [Google Scholar] [CrossRef]
- Qian, X.; Fu, Y.; Jiang, Y.G.; Xiang, T.; Xue, X. Multi-scale deep learning architectures for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5399–5408. [Google Scholar]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance matters: Exemplar memory for domain adaptive person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 598–607. [Google Scholar]
- Luo, H.; Jiang, W.; Fan, X.; Zhang, C. Stnreid: Deep convolutional networks with pairwise spatial transformer networks for partial person re-identification. IEEE Trans. Multimed. 2020, 22, 2905–2913. [Google Scholar] [CrossRef]
- Wang, H.; Peng, J.; Jiang, G.; Xu, F.; Fu, X. Discriminative feature and dictionary learning with part-aware model for vehicle re-identification. Neurocomputing 2021, 438, 55–62. [Google Scholar] [CrossRef]
- Peng, J.; Jiang, G.; Wang, H. Adaptive Memorization with Group Labels for Unsupervised Person Re-identification. IEEE Trans. Circuits Syst. Video Technol. 2023, early access. [Google Scholar] [CrossRef]
- Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Yang, Y.; Tian, Q. Person re-identification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1367–1376. [Google Scholar]
- Chen, D.; Zhang, S.; Ouyang, W.; Yang, J.; Tai, Y. Person search via a mask-guided two-stream cnn model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. Joint detection and identification feature learning for person search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3415–3424. [Google Scholar]
- Munjal, B.; Amin, S.; Tombari, F.; Galasso, F. Query-guided end-to-end person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 811–820. [Google Scholar]
- Wang, F.; Zuo, W.; Lin, L.; Zhang, D.; Zhang, L. Joint learning of single-image and cross-image representations for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 1288–1296. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning discriminative features with multiple granularities for person re-identification. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 274–282. [Google Scholar]
- Yao, H.; Zhang, S.; Hong, R.; Zhang, Y.; Xu, C.; Tian, Q. Deep representation learning with part loss for person re-identification. IEEE Trans. Image Process. 2019, 28, 2860–2871. [Google Scholar] [CrossRef] [PubMed]
- Bai, X.; Yang, M.; Huang, T.; Dou, Z.; Yu, R.; Xu, Y. Deep-person: Learning discriminative deep features for person re-identification. Pattern Recognit. 2020, 98, 107036. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, H.; Liu, S.; Xie, Y.; Durrani, T.S. Part-guided graph convolution networks for person re-identification. Pattern Recognit. 2021, 120, 108155. [Google Scholar] [CrossRef]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-driven deep convolutional model for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3960–3969. [Google Scholar]
- Zhao, H.; Tian, M.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle net: Person re-identification with human body region guided feature decomposition and fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1077–1085. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2285–2294. [Google Scholar]
- Sun, J.; Li, Y.; Chen, H.; Zhang, B.; Zhu, J. Memf: Multi-level-attention embedding and multi-layer-feature fusion model for person re-identification. Pattern Recognit. 2021, 116, 107937. [Google Scholar] [CrossRef]
- Han, C.; Ye, J.; Zhong, Y.; Tan, X.; Zhang, C.; Gao, C.; Sang, N. Re-id driven localization refinement for person search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9814–9823. [Google Scholar]
- Wang, C.; Ma, B.; Chang, H.; Shan, S.; Chen, X. Tcts: A task-consistent two-stage framework for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11952–11961. [Google Scholar]
- Chen, D.; Zhang, S.; Ouyang, W.; Yang, J.; Tai, Y. Person search by separated modeling and a mask-guided two-stream cnn model. IEEE Trans. Image Process. 2020, 29, 4669–4682. [Google Scholar] [CrossRef]
- Chang, X.; Huang, P.Y.; Shen, Y.D.; Liang, X.; Yang, Y.; Hauptmann, A.G. Rcaa: Relational context-aware agents for person search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 84–100. [Google Scholar]
- Yan, Y.; Li, J.; Qin, J.; Bai, S.; Liao, S.; Liu, L.; Zhu, F.; Shao, L. Anchor-free person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7690–7699. [Google Scholar]
- Li, Z.; Miao, D. Sequential end-to-end network for efficient person search. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 2011–2019. [Google Scholar]
- Cao, J.; Pang, Y.; Anwer, R.M.; Cholakkal, H.; Xie, J.; Shah, M.; Khan, F.S. PSTR: End-to-End One-Step Person Search With Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9458–9467. [Google Scholar]
- Yu, R.; Du, D.; LaLonde, R.; Davila, D.; Funk, C.; Hoogs, A.; Clipp, B. Cascade Transformers for End-to-End Person Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7267–7276. [Google Scholar]
- Yang, Q.; Yu, H.X.; Wu, A.; Zheng, W.S. Patch-based discriminative feature learning for unsupervised person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3633–3642. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, D.; Zhang, S.; Yang, J.; Schiele, B. Norm-Aware Embedding for Efficient Person Search and Tracking. Int. J. Comput. Vis. 2021, 129, 3154–3168. [Google Scholar] [CrossRef]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. Pattern Recognit. 2019, 95, 151–161. [Google Scholar] [CrossRef]
- Wang, Y. Survey on deep multi-modal data analytics: Collaboration, rivalry, and fusion. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–25. [Google Scholar]
- Wang, Y.; Peng, J.; Wang, H.; Wang, M. Progressive learning with multi-scale attention network for cross-domain vehicle re-identification. Sci. China Inf. Sci. 2022, 65, 160103. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html (accessed on 9 March 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Lan, X.; Zhu, X.; Gong, S. Person search by multi-scale matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 536–552. [Google Scholar]
- Dong, W.; Zhang, Z.; Song, C.; Tan, T. Instance guided proposal network for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2585–2594. [Google Scholar]
- Xiao, J.; Xie, Y.; Tillo, T.; Huang, K.; Wei, Y.; Feng, J. IAN: The individual aggregation network for person search. Pattern Recognit. 2019, 87, 332–340. [Google Scholar] [CrossRef]
- Liu, H.; Feng, J.; Jie, Z.; Jayashree, K.; Zhao, B.; Qi, M.; Jiang, J.; Yan, S. Neural person search machines. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27–29 October 2017; pp. 493–501. [Google Scholar]
- Yan, Y.; Zhang, Q.; Ni, B.; Zhang, W.; Xu, M.; Yang, X. Learning context graph for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2158–2167. [Google Scholar]
- Chen, D.; Zhang, S.; Ouyang, W.; Yang, J.; Schiele, B. Hierarchical online instance matching for person search. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10518–10525. [Google Scholar]
- Zhong, Y.; Wang, X.; Zhang, S. Robust partial matching for person search in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6827–6835. [Google Scholar]
- Dong, W.; Zhang, Z.; Song, C.; Tan, T. Bi-directional interaction network for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2839–2848. [Google Scholar]
- Han, C.; Zheng, Z.; Gao, C.; Sang, N.; Yang, Y. Decoupled and memory-reinforced networks: Towards effective feature learning for one-step person search. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1505–1512. [Google Scholar]
- Kim, H.; Joung, S.; Kim, I.J.; Sohn, K. Prototype-guided saliency feature learning for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4865–4874. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CUHK-SYSU | PRW | ||
|---|---|---|---|---|
| mAP | top-1 | mAP | top-1 | |
| DPM [16] | - | - | 20.50 | 48.30 |
| MGTS [17] | 83.00 | 83.70 | 32.60 | 72.10 |
| CLSA [49] | 87.20 | 88.5 | 38.7 | 65.00 |
| RDLR [32] | 93.00 | 94.20 | 42.90 | 70.20 |
| IGPN [50] | 90.3 | 91.40 | 47.20 | 87.00 |
| TCTS [33] | 93.90 | 95.10 | 46.80 | 87.50 |
| MGCN | 94.28 | 94.97 | 47.11 | 86.39 |
| Method | CUHK-SYSU | PRW | ||
|---|---|---|---|---|
| mAP | top-1 | mAP | top-1 | |
| OIM [18] | 75.50 | 78.70 | 21.30 | 49.90 |
| IAN [51] | 76.30 | 80.10 | 23.00 | 61.90 |
| NPSM [52] | 77.90 | 81.20 | 24.20 | 53.10 |
| RCAA [35] | 79.30 | 81.30 | - | |
| CTXG [53] | 84.10 | 86.50 | 33.40 | 73.60 |
| QEEPS [19] | 88.90 | 89.10 | 37.10 | 76.70 |
| HOIM [54] | 89.70 | 90.80 | 39.80 | 80.40 |
| APNet [55] | 88.90 | 89.30 | 41.90 | 81.40 |
| BINet [56] | 90.00 | 90.70 | 45.30 | 81.70 |
| NAE [42] | 91.50 | 92.40 | 43.30 | 80.90 |
| NAE+ [42] | 92.10 | 92.90 | 44.00 | 81.10 |
| DMRNet [57] | 93.20 | 94.20 | 46.90 | 83.30 |
| PGS [58] | 92.30 | 94.70 | 44.20 | 85.20 |
| AlignPS [36] | 93.10 | 93.40 | 45.90 | 81.90 |
| AlignPS+ [36] | 94.00 | 94.50 | 46.10 | 82.10 |
| SeqNet [37] | 93.80 | 94.60 | 46.70 | 83.40 |
| MGCN | 94.28 | 94.97 | 47.11 | 86.39 |
| Aligning Module | Channel Attention | Spatial Attention | CUHK-SYSU | PRW | ||
|---|---|---|---|---|---|---|
| mAP | top-1 | mAP | top-1 | |||
| 🗸 | 94.24 | 95.03 | 46.83 | 87.07 | ||
| 🗸 | 🗸 | 93.97 | 94.38 | 45.51 | 82.84 | |
| 🗸 | 🗸 | 94.23 | 95.00 | 44.06 | 86.49 | |
| 🗸 | 🗸 | 94.01 | 94.62 | 44.12 | 81.67 | |
| 🗸 | 🗸 | 🗸 | 94.28 | 94.97 | 47.11 | 86.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Wang, X. Multi-Attention-Guided Cascading Network for End-to-End Person Search. Appl. Sci. 2023, 13, 5576. https://doi.org/10.3390/app13095576
Yang J, Wang X. Multi-Attention-Guided Cascading Network for End-to-End Person Search. Applied Sciences. 2023; 13(9):5576. https://doi.org/10.3390/app13095576
Chicago/Turabian StyleYang, Jianxi, and Xiaoyong Wang. 2023. "Multi-Attention-Guided Cascading Network for End-to-End Person Search" Applied Sciences 13, no. 9: 5576. https://doi.org/10.3390/app13095576