1. Introduction
Distance Metric Learning (DML), usually referring to learning a Mahalanobis matrix from the given side information, has been an active studying field for the last two decades [
1,
2,
3,
4]. Compared to those off-the-shelf distance functions, e.g., Euclidean distance, DML takes the correlations and weights of the features into distance consideration, thus being more appropriate for various downstream tasks. Its efficiency has been validated by a large spectrum of applications [
5,
6,
7], for example, few-shot learning [
8,
9], face recognition [
9,
10], and fault detection [
11,
12]. Despite the success of existing DML methods, they rely on massive side information constructed by labeled information [
13]. However, manually labeling the data is a labor-consuming task [
14], and sometimes it needs domain knowledge [
15,
16] to provide meaningful labeling information, e.g., labeling the checkup samples of patients.
To solve this issue, researchers have devoted themselves to Semi-Supervised Distance Metric Learning (SSDML). SSDML intends to learn a Mahalanobis matrix from limited labeled data as well as a large amount of unlabeled data, such that under this metric, similar instances are brought closer together whereas dissimilar ones are pushed farther away. Inspired by the unsupervised dimensionality reduction methods, which aim to preserve some properties in the original data space, a lot of SSDML approaches based on manifold-based regularization terms have been proposed in the last decades [
1,
17,
18,
19,
20,
21,
22]. For example, Wang [
1] proposed to project the data into a new space, where labeled data has the maximum margin constraint, and the unlabeled data has the maximum variance. Similarly, Baghshah and Shouraki [
18] constructed a novel SDML method by retaining locally linear relationships between close data points in the transformed space and proposed a regularization term based on Locally Linear Embedding (LLE) [
23]. The above regularization terms cannot boost the discriminative ability of the model. There are also some SSDML methods based on the Laplacian graph [
19,
21,
22,
24,
25,
26,
27], i.e., Laplacian Regularized Metric Learning (LRML) [
17] utilized the graph Laplacian to preserve the neighbor relationship of the original space. However, the above graph Laplacian construction process does not take the labeled information into consideration. To mitigate this issue, Dutta and Sekhar [
21] proposed to utilize Markov random walk technology to transform the strong limited labeled information into a Laplacian matrix. Ying et al. [
20] also took the density information of each instance into the Laplacian graph construction process. However, these methods rely on a default metric to determine the affinities among the samples, which contradicts the goal of metric learning. If the default metric is an appropriate metric, why should we still strive to search for another metric? There are also a few works that do not depend on manifold-based regularization. For example, Semi-Supervised Metric Learning Paradigm with Hyper Sparsity (SERAPH) [
28] and Semi-Supervised Regularized Large Margin Distance Metric Learning (S-RLMM) [
29]. SERAPH is an information-theoretic metric learning method, and it maximizes the entropy on the labeled data while minimizing the entropy on the unlabeled data. However, the time complexity of these methods is at least quadratically dependent on the number of training instances (Table 4 provides a brief time complexity analysis of some representative methods), which means these methods can hardly scale to large-scale datasets. Moreover, these methods rely on a fixed metric to mine the information similarities between samples, which contradicts the goal of learning a metric from data.
To solve this issue, in this paper, we propose an efficient SSDML method called ISMLP; rather than building the probability model via the instance–instance distance parameterized by the learned Mahalanobis matrix, we propose to learn a set of proxy vectors and transform the instance–instance relationship as the instance–proxy relationship. We minimize the labeled instances and their corresponding proxy vectors to efficiently mine the information of the unlabeled data; inspired by the SERAPH, we incorporate entropy regularization. Importantly, the Mahalanobis matrix is constricted as a hierarchical form to further boost training efficiency. An Alternating Direction Method (ADM) technology is adopted to seek a feasible solution for ISMLP, and the sub-problem concerning the Mahalanobis matrix can be efficiently solved by an iterative method on the product space of two Riemannian manifold. The merits of using proxy vectors lie in two folds: on the one hand, the time complexity of ISMLP is linearly dependent on the number of instances, thus can be easily extended to large-scale datasets; on the other hand, the instance–instance distances may be corrupted because of the noise instances in the dataset. The proxy vectors can be considered as aggregating the class/local information of the dataset, therefore, it is more stable than SERAPH.
We propose a novel information-theoretic-based SSDML method called ISMLP, which simultaneously learns multiple proxy vectors as well as the Mahalanobis matrix. Specifically, we adopt the entropy regularization to mine the discriminant information of the unlabeled data.
The merits of the proposed ISMLP lie in two folds: on the one hand, compared to those manifold-based SSDML methods, ISMLP does not rely on manifold assumptions. Thus, it can be applied to border scenes; the time complexity of ISMLP is linear with respect to the number of training instances, and thus can be easily extended to large-scale datasets.
Extensive experimental results on classification and retrieval experiments can validate the superiority performance and in the meantime can be trained more efficiently than those compared methods.
The rest of this paper is organized as follows: In
Section 2, we briefly introduce the SERAPH framework. Then, we introduce the construction process of the proposed method in
Section 3, followed by the extensive numerical experiment in
Section 5. Finally, in
Section 6, we make a conclusion and provide a possible future direction of the proposed ISMLP.
4. Optimization for ISMLP
There are three types of parameters to be estimated in the objective function of ISMLP. In this section, an alternating-direction technology is proposed to seek a feasible solution. More specifically, we keep the other variables fixed to update the current variable until the stop condition meet.
Fix , to solve and : the sub-problem concerning
and
can be expressed as the following Riemannian manifold-based optimization problem.
The above minimization problem can be solved via the product space of the Stiefel and SPD manifold. According to [
39], the Stiefel and SPD manifolds are locally homogeneous spaces, and their product space should also follow the smoothness and differentiability. Therefore,
can contain a Riemannian structural.
Theorem 1.
The set with the following equivalence relationand Riemannian metricforms a Riemannian quotient manifold. Proof. We first prove that the equivalence relation hold:
, since the following equation holds:
Therefore, the equivalence relation holds. To prove
is a valid quotient manifold, one can follow the proof in [
40]. Lastly, as for the Riemannian metric, interested readers can refer to [
37].
To perform the Riemannian gradient descent on
, we usually follow the “projection and retraction” procedures. More specifically, firstly, one can transform the Euclidean gradient as the Riemannian gradient, and then perform the gradient descent step; then, map the intermediate solution back to the manifold [
39]. For the Stiefel manifold, the Riemannian gradient can be computed as:
As for the PSD manifold, its Riemannian gradient has the following form:
where
and
denote the Euclidean partial gradient of
w.r.t
and
, respectively.
As for the quotient manifold , the tangent space at is divided into two complementary parts, namely a horizontal part and a vertical one . Importantly, the tangent space of (denoted as ) can be uniquely identified as it horizontal part.
The horizontal vector in the horizontal tangent space of the proposed quotient manifold can be identified as:
where
is the solution of the following equation [
37]:
For the retraction operation, it can be organized in the following form:
where
, and
denotes the matrix exponential operation.
Lastly, the only missing component is
and
, and they can be calculated by:
with
.
For
, it can be expressed as:
with
.
Fix and to solve : The sub-problem with respect to
can be stated as:
Firstly, we can update the proxy assignment of each instance by recalculating Equation (
5). Then, we can solve the proxy vector one by one. More specifically, for the
k-th proxy vector
, by taking the derivative of
with respect to
, we can get:
where for the given similar pair
,
denotes the probability of
choosing
as the proxy vector computed by Equation (
6).
, and
.
By setting
to zero, Equation (
25) is simply a linear equation:
where
and
:
we can get the closed-form solution of
:
where
is a small positive number to make
a positively defined matrix. In the experiment, we empirically set it as
, which works fine. □
To sum up, we propose an alternating direction strategy to solve the minimization of Equation (
11). The sub-problems concerning
and
are updated on the product manifold of the Stiefel and SPD manifold via the Riemannian gradient descent algorithm [
41]. The sub-problem concerning
has a closed-form solution. The main procedure of ISMLP is documented in Algorithm 1. It should be noted that we utilize a Gaussian Mixture Model (GMM) to initialize the set of proxy vectors which are the means of the corresponding components. We also document the variations of objective function values with respect to iterations on three datasets in
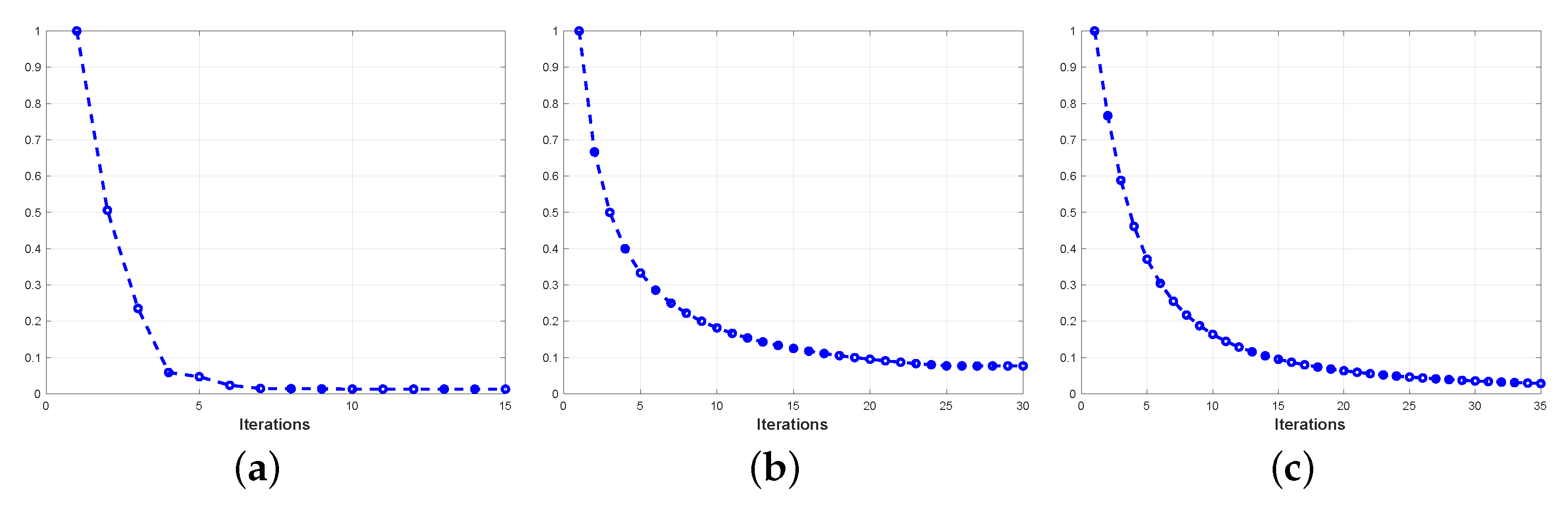
Figure 1. Clearly, the loss decreases as the iterations and inclines become stable after several iterations, which proves that the proposed algorithm can converge within limited iterations.
| Algorithm 1: The optimization strategy of ISMLP. |
- Input:
The labeled and unlabeled datasets and , the similar constraint set , , the number of proxy vectors m, , and the dimensionality of the embedding space p;
- 1
Initialize as a column orthonormal matrix, and setting as the identity matrix ; - 2
Initialize the set of proxy vectors via the Gaussian mixture model by setting the number of components as m; - 3
while not converged do
Output: The projection matrix and low-dimensionality Mahalanobis matrix ; |
Time Complexity of ISMLP
In this section, we provide a brief analysis of the time complexity of the proposed ISMLP. Recall that the number of labeled and unlabeled data is and , respectively. The dimensionality of the original and the reduced data is denoted as d and p. The number of proxy vectors is denoted as m. The main procedures of ISMLP consist of the following main steps: (1) Evaluating the loss function; (2) Computing the Euclidean gradient of the loss function with respect to and ; (3) Projecting the Euclidean gradient of and to the tangent space and then retracing them back to the manifold; (4) Updating the set of the proxy vectors.
Since the time complexity of solving the inverse of a
matrix costs
, evaluating the objective function in Equation (
11) takes
.
Computing the Euclidean gradient of the loss function with respect to
by using Equation (
22) takes
, and computing
via Equation (
23) costs
.
According to [
37], projecting the Euclidean gradient of the loss function with respect to
and
by using Equations (
17) and (
18) costs
. Retracting the Riemannian gradient back to the manifold via Equation (
21) costs
.
Solving all the proxy vectors by using Equation (
29) cost
, where
is the number of labeled data.
Considering the usual case of large-scale semi-supervised metric learning is , the time complexity of the proposed ISMLP is about , and the main cost lies in evaluating the Euclidean gradient of . To sum up, the time complexity of the proposed ISMLP has a linear dependence on the number of n; therefore, it can be effectively and efficiently extended to large-scale datasets.
5. Experiment
In this section, extensive visual classification and retrieval experiments are conducted to verify the efficacy and efficiency of the proposed ISMLP. Firstly, we provide a detailed description of the datasets and evaluation index, and compared methods used in the experiments. Then, the experimental results are provided.
5.1. Datasets, Evaluation Protocol and Compared Methods
Datasets: a total of five datasets are utilized, including MNIST [
42], Fashion-MNIST [
43], Corel 5K [
44], CUB-200 [
45], and Cars-196 [
46]. The MNIST contains 70,000 grayscale handwritten digital images from ten classes, whereas Fashion-MNIST consists of 70,000 images from ten fashion objects. MNIST and Fashion-MNIST are wildly used in the field of semi-supervised learning. The latter two datasets CUB-200 and Cars-196 are two fine-grained visual recognition datasets. The detailed information on the datasets is listed in
Table 1.
The pixel value of MNIST and Fashion-MNIST datasets are served as the image feature, which provides us with a 784-dimensional feature. As for the other datasets, the VGG-19 network [
47] pre-trained on ImageNet is utilized to extract the features. Since the dimensionality of the features is extremely high, PCA is adopted to reduce the dimensionality of each feature to a 150-dimensional subspace.
Evaluation protocol: Given that each dataset comes with a default partition of training/testing set, we adopt the same strategy for consistency. Additionally, for each dataset, we set aside 1000 instances from the training data to form the validation set (Since Corel 5K has a default partition of the validation set, we exclude it). The specific number of instances used for validation can be found in
Table 1. For the MNIST and Fashion-MNIST datasets, we adopt 3-nearest neighbors to quantify the performance of each compared method, whereas, for the CUB-200 and Cars-196 datasets, we report the Recall@K (abbreviation as R@K) performance, where R@K reflects the proportion of the correct samples in the return
K samples. More specifically, R@1, R@2, R@4, and R@8 index is utilized to measure the performance of each method.
We report the R@K of each method under different labeling rates, namely 5%, 10%, and 30%, the rest samples in the training set serve as the unlabeled data.
Compared methods: We compare the proposed ISMLP with several state-of-the-art semi-supervised metric learning methods including, LSeMML [
22], SERAPH [
28], S-RLMM [
29], LRML [
33], SLRML [
19], APIT [
21], CMM [
1], and APLLR [
21]. One supervised metric learning method LMNN [
48], one deep semi-supervised metric learning entitled as SSML-DR [
49], the Euclidean distance denoted as EUCLID is also adopted for a baseline method. The hyper-parameters of all the methods are tuned on the validation set and we choose those parameters that achieve the best results on the validation set. For example, for LMNN, we tune
from the set
. As for the proposed method, we empirically set
p as 50, and choose
from the range
, and tune the
from the range
, the number for the proxy vector is chosen from
. For SSML-DR, to make a fair comparison, a three-layer full-connected neural network whose nodes are
is incorporated as the backbone network by SSML-DR. The batch size is set as 100, and the number of epochs is set as 50.
5.2. Classification Experimental Result on MNIST and Fashion-MNIST Datasets
In this section, we test the classification performance of the compared methods based on 3-nearest neighbors on MNIST and Fashion-MNIST datasets. To mitigate the influence of the random partition of the dataset, we repeat each task 30 times, and the mean accuracy and standard deviation are recorded to quantify the performance of each method.
Table 2 and
Table 3 record the mean error rate and standard deviation of all the methods on MNIST and Fashion-MNIST datasets, respectively.
It is readily seen that the metric learning methods can boost the performance of k-nearest neighbors classification, and all the methods can benefit from the amount of labeled data. The performance of the supervised metric learning method LMNN shows inferior performance compared to those semi-supervised methods, which can prove the necessity of utilizing the information of unlabeled data during the metric learning process. Both SERAPH and ISMLP utilize entropy regularization to preserve the discriminative information of the unlabeled data. Unlike SERAPH, ISMLP adopts a set of proxy vectors to substitute the sample–sample probability assigning procedure, which is more robust than SERAPH. As a result, its performance surpasses SERAPH on all the tasks. Compared to those Laplacian-graph-based methods (i.e., LSeMML, SLRML, and APIT), ISMLP is free from the untrustable Laplacian-graph construction process; thus, it usually can achieve better performance. ISMLP obtains the best performance on tasks. It is curious to see that CMM achieves the worst performance among all the semi-supervised methods; we surmise its manifold-based regularization term may cause this. CMM intends to find a projection direction where the unlabeled data has the maximum variance, which may not increase the discriminative ability of the model. Owing to the powerful nonlinear feature extraction ability of the deep neural network, the performance of SSML-DR consistently surpasses those shallow Laplacian graph-based methods; however, it still falls behind the proposed ISMLP. We believe that this can be attributed to the two-stage construction processes of the Laplacian graph.
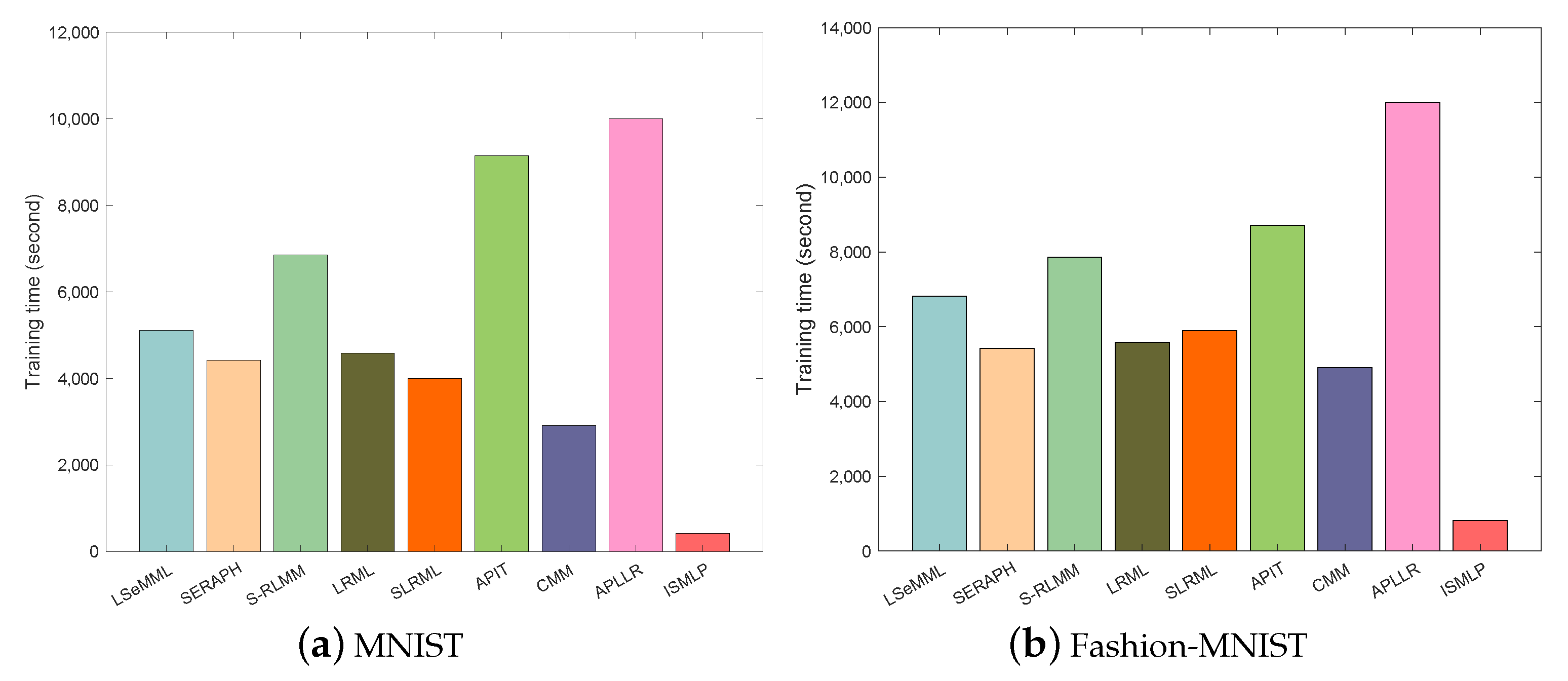
To systematically provide a comprehensive analysis of the time complexity of each method, we provide the time complexity of some representative methods in
Table 4. Clearly, the time complexity of the proposed ISMLP is linear with respect to the number of instances, whereas the other compared methods exhibit at least quadratic dependence on
n. Considering the usual case in the large-scale semi-supervised setting is
, the proposed ISMLP can be efficiently trained in a reasonable time. To verify this hypothesis, we also conduct experiments on MNIST and Fashion-MNIST to compare the training time of each method.
Figure 2 displays the results, and clearly, the training time of ISMLP is significantly less than the compared methods. More specifically, on the MNIST dataset, it takes about 400 s for SLP to train the model, a 6.5× improvement over the second-fastest approach CMM, which can prove the efficiency of the proposed ISMLP.
5.3. Retrieval Performance on Corel 5K Dataset
We also run a retrieval experiment on Corel 5K dataset with a labeling rate of 30%.
Figure 3 documents the performance of the proposed ISMLP and LSeMML. In the first sub-figure, it is evident that ISMLP can effectively capture the semantic meaning of the query image, leading to accurate retrieval of five relevant images. In contrast, LSeMML mistakes the “red” element as the key property of the query image and unsurprisingly gives the irrelevant images in the 4-th and 5-th nearest neighbors. The major difference between ISMLP and LSeMML lies in the utilization of the unlabeled regularization term, i.e., LSeMML utilizes the EUCLID metric to mine the manifold information of the unlabeled data. When the EUCLID metric is not appropriate to measure the correlations and weights of the features, the resulting graph will be an inferior one. Therefore, the sub-optimal results can be observed in the retrieval list. In contrast, the proposed ISMLP utilizes entropy regularization to mine the information of the unlabeled data, it makes no data distribution assumption; therefore, can be applied to broader scenes.
Similar results can also be found in the other sub-figures. Therefore, the retrieval experiment on Corel 5K dataset can verify the superiority performance over the compared LSeMML approach.
5.4. Classification Performance on CUB-200 and Cars-196 Datasets
We further conduct image recognition experiments on two fine-grained datasets to test the classification ability of the proposed ISMLP and its compared methods. The R@K index is utilized to quantify the performance of each method.
Table 5 and
Table 6 show the classification results on the CUB-200 and Cars-196 datasets, respectively.
We can draw the following conclusions from the figure: (1) All metric learning methods can benefit from the amount of labeled data; the more labeled data, the higher recognition performance. Since LMNN can only utilize the labeled data, when the labeling rate is low, LMNN can easily fall into the trap of over-fitting. Its performance is inferior to those semi-supervised metric learning methods under all tasks. This can prove the superiority of utilizing the unlabeled in metric learning. (2) Compared to those manifold-based semi-supervised approaches, the proposed ISMLP makes no assumptions about the smoothness or density of the data. Thus, ISMLP can be applied to broader scenes, and achieve better performance. (3) Both SERAPH and ISMLP utilize entropy regularization to mine the discrimination information of the unlabeled data; ISMLP adopts the proxy vectors to construct the probability model, which is more robust than SERAPH, and it obtains better performance across all the tasks on CUB-200 and Cars-196 datasets. (4) SSML-DR can obtain competing results due to its strong hierarchical feature extraction ability. (5) the proposed ISMLP can better mine the rich structural information of the unlabeled data; it achieves the best performance on 20 of all 24 tasks, which proves the efficiency of adopting the proxy vectors as surrogate points.
5.5. Sensitivity Analysis
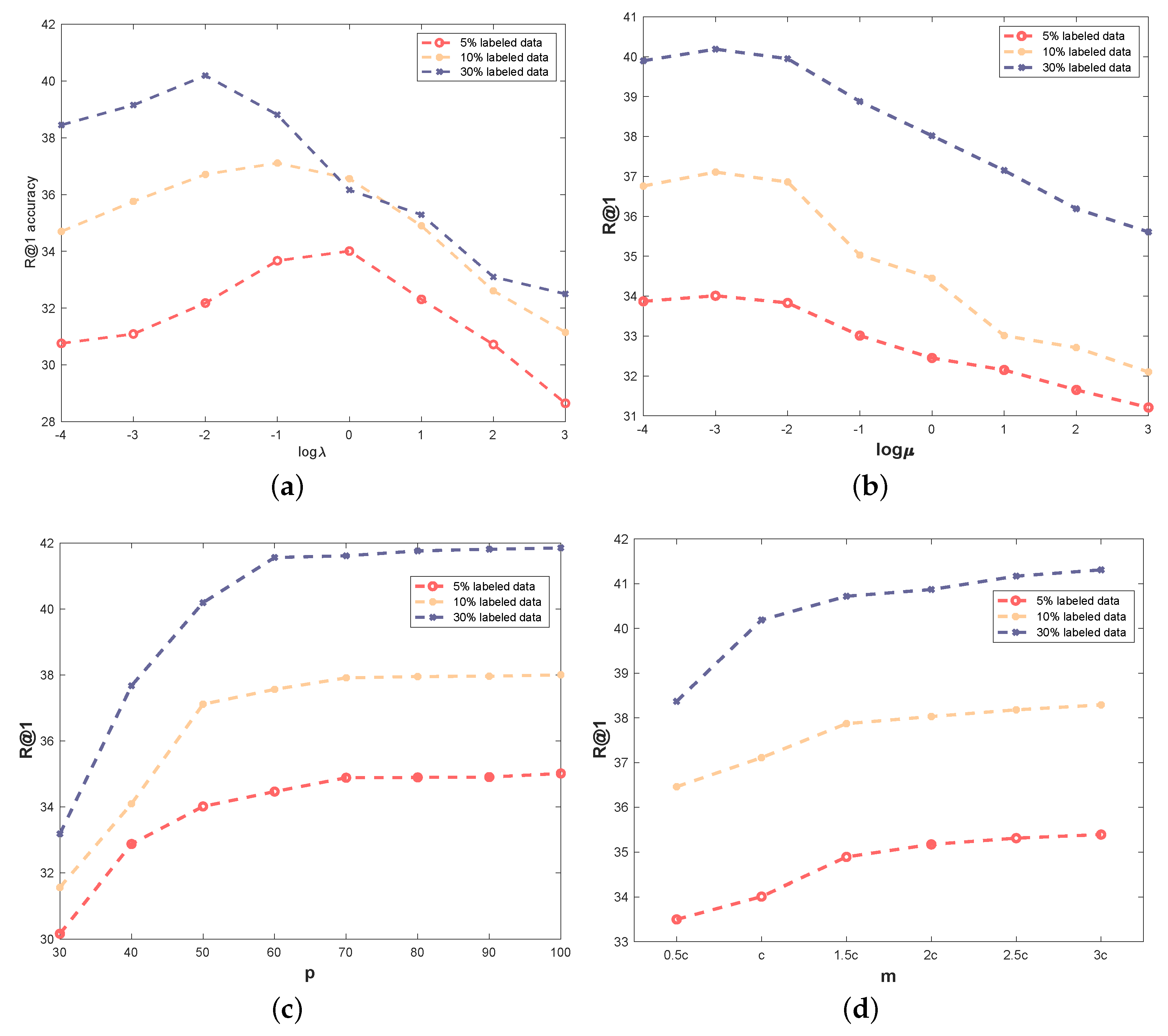
In this section, we conduct an experiment on the Cars-196 dataset to analyze the sensitivity of the proposed ISMLP on different hyper-parameters. To simplify the experiment, we keep the other parameters fixed when analyzing the current one.
Figure 4a depicts the R@1 accuracy of the proposed ISMLP with different
when we set
,
, and
, where c denotes the number of classes. One can observe that each curve has a turning point, and the fewer the amount of labeled data, the earlier the turning point appears. We gauge that this can be attributed to the utility of the entropy regularization; either an excessively large or a small
will lead to a biased model.
Figure 4b shows the sensitivity of ISMLP on
. We can see that ISMLP is insensitive to the change of
to some extent. However, setting a large
will impose the learned
close to the prior metric
, which prevents ISMLP to learn the correlations and weights of the feature in the reduced space.
Figure 4c documents the results on
p. Recall that
p is the dimensionality of the reduced space, and setting a small
p will lose a large amount of information of the original data. As a result, we can observe inferior results with small
p; however, as
p increases, the performance becomes stable. To compromise between accuracy and computational efficiency, we set
p as 50 in all experiments.
We further conduct an experiment to test the sensitivity of ISMLP on the number of proxy vectors and document the result in
Figure 4d. It has nearly the same tendency as
Figure 4c; when we learn a small number of proxy vectors, instances from the other classes will be mixed up together, which undoubtedly degrades the discriminative ability of the model. Increasing the number of proxy vectors will boost the performance to some extent, and it can help to discover the latent pattern within a class. Such an idea is also utilized in some cluster-based multi-metric learning methods [
30,
50]. However, allocating too many proxy vectors will cost additional computational resources.







{kind=link}
{kind=link}
{kind=link}
{kind=link}