
JSUM: A Multitask Learning Speech Recognition Model for Jointly Supervised and Unsupervised Learning

Abstract
:1. Introduction
2. Related Work
2.1. Multilingual Pretraining of Speech Recognition
2.2. Joint CTC-Attention Architecture
2.3. Unsupervised Adversarial Training
3. Methods
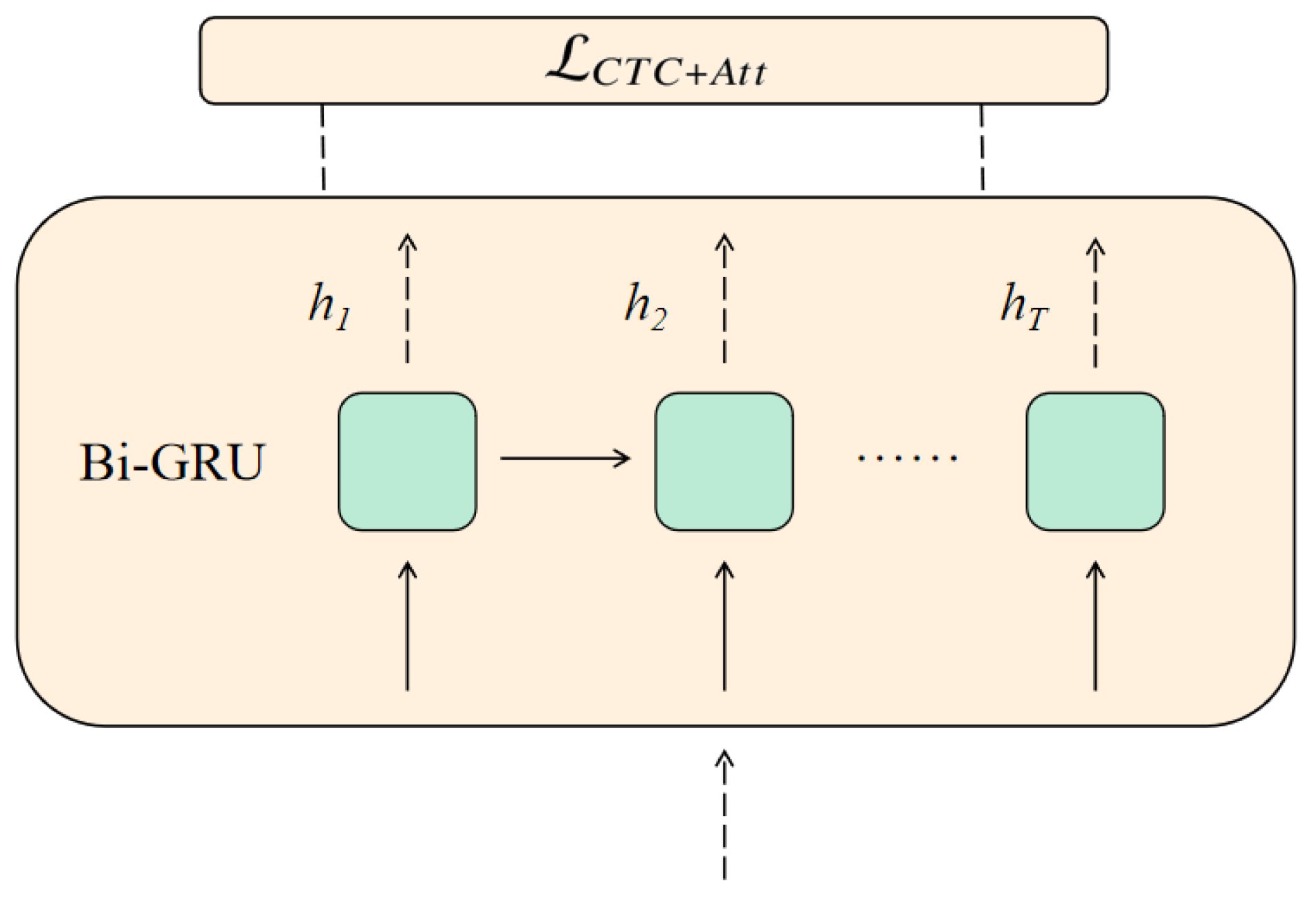
3.1. Model
3.2. Loss Function
3.2.1. Joint CTC-Attention Loss
- (1)
- (2)
- (3)
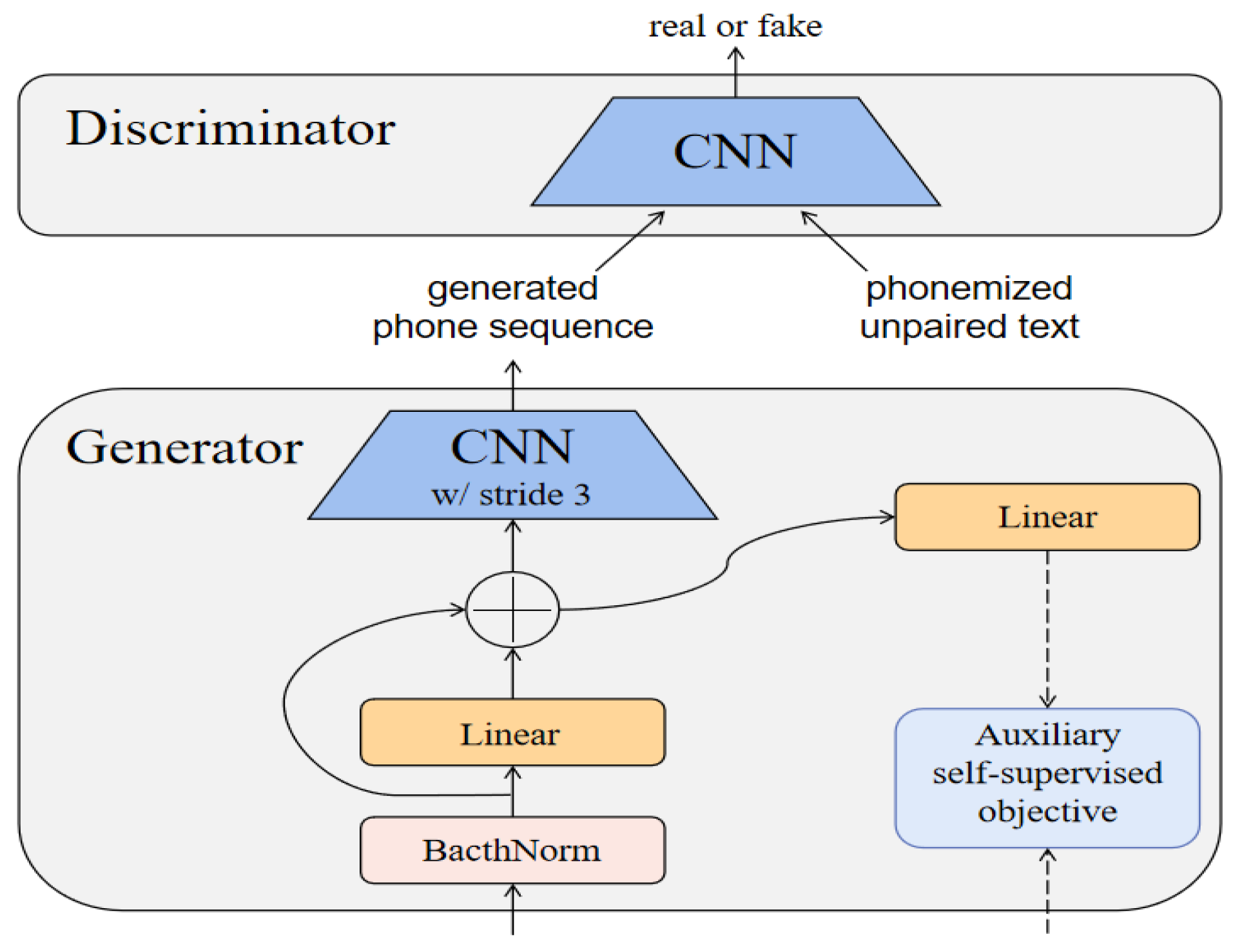
3.2.2. Generative Adversarial Loss
3.2.3. Multitasking Learning Loss
4. Experimental Setup
4.1. Datasets
4.2. Model Configuration
4.3. Unsupervised Pre-Training
4.4. Phonemized Unlabeled Text
5. Results
5.1. Multitasking Learning Based on TIMIT
5.2. The Effect of Unsupervised Cross-Linguistic Representation Learning on JSUM in Shared Encoders
5.3. Speech Recognition for Kazakh under Low Resource Conditions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Q.; Lu, H.; Sak, H.; Tripathi, A.; McDermott, E.; Koo, S.; Kumar, S. Transformer transducer: A streamable speech recognition model with transformer encoders and rnn-t loss. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7829–7833. [Google Scholar]
- Moritz, N.; Hori, T.; Le, J. Streaming automatic speech recognition with the transformer model. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6074–6078. [Google Scholar]
- Kahn, J.; Lee, A.; Hannun, A. Self-training for end-to-end speech recognition. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7084–7088. [Google Scholar]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; PMLR: London, UK, 2014; pp. 1764–1772. [Google Scholar]
- Miao, Y.; Gowayyed, M.; Metze, F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 167–174. [Google Scholar]
- Yao, Z.; Wu, D.; Wang, X.; Zhang, B.; Yu, F.; Yang, C.; Peng, Z.; Chen, X.; Xie, L.; Lei, X. Wenet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit. arXiv 2021, arXiv:2102.01547. [Google Scholar]
- Pham, N.Q.; Nguyen, T.S.; Niehues, J.; Müller, M.; Waibel, A. Very deep self-attention networks for end-to-end speech recognition. arXiv 2019, arXiv:1904.13377. [Google Scholar]
- Rossenbach, N.; Zeyer, A.; Schlüter, R.; Ney, H. Generating synthetic audio data for attention-based speech recognition systems. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7069–7073. [Google Scholar]
- Yeh, C.F.; Wang, Y.; Shi, Y.; Wu, C.; Zhang, F.; Chan, J.; Seltzer, M.L. Streaming attention-based models with augmented memory for end-to-end speech recognition. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8–14. [Google Scholar]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 675–684. [Google Scholar]
- Atapour-Abarghouei, A.; Breckon, T.P. To complete or to estimate, that is the question: A multi-task approach to depth completion and monocular depth estimation. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec, QC, Canada, 16–19 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 183–193. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-task deep neural networks for natural language understanding. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6084–6088. [Google Scholar]
- Miao, H.; Cheng, G.; Gao, C.; Zhang, P.; Yan, Y. Transformer-based online CTC/attention end-to-end speech recognition architec-ture. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6084–6088. [Google Scholar]
- Deng, K.; Cao, S.; Zhang, Y.; Ma, L. Improving hybrid ctc/attention end-to-end speech recognition with pre-trained acoustic and language models. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 76–82. [Google Scholar]
- Stolcke, A.; Grezl, F.; Hwang, M.-Y.; Lei, X.; Morgan, N.; Vergyri, D. Cross-domain and cross-language portability of acoustic features estimated by multilayer perceptrons. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech, and Signal Processing ICASSP, Toulouse, France, 14–19 May 2006. [Google Scholar]
- Burget, L.; Schwarz, P.; Agarwal, M.; Akyazi, P.; Feng, K.; Ghoshal, A.; Glembek, O.; Goel, N.; Karafiat, M.; Povey, D.; et al. Multilingual acoustic modeling for speech recognition based on subspace Gaussian mixture models. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 4334–4337. [Google Scholar]
- Heigold, G.; Vanhoucke, V.; Senior, A.; Nguyen, P.; Ranzato, M.A.; Devin, M.; Dean, J. Multilingual acoustic models using distributed deep neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 8619–8623. [Google Scholar]
- Huang, J.T.; Li, J.; Yu, D.; Deng, L.; Gong, Y. Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 7304–7308. [Google Scholar]
- Li, X.; Dalmia, S.; Black, A.W.; Metze, F. Multilingual speech recognition with corpus relatedness sampling. arXiv 2019, arXiv:1908.01060. [Google Scholar]
- Conneau, A.; Baevski, A.; Collobert, R.; Mohamed, A.; Auli, M. Unsupervised cross-lingual representation learning for speech recognition. arXiv 2020, arXiv:2006.13979. [Google Scholar]
- Gupta, A.; Chadha, H.S.; Shah, P.; Chhimwal, N.; Dhuriya, A.; Gaur, R.; Raghavan, V. Clsril-23: Cross lingual speech representations for indic languages. arXiv 2021, arXiv:2107.07402. [Google Scholar]
- Kim, S.; Hori, T.; Watanabe, S. Joint CTC-attention based end-to-end speech recognition using multi-task learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4835–4839. [Google Scholar]
- Liang, S.; Yan, W.Q. A hybrid CTC+ Attention model based on end-to-end framework for multilingual speech recognition. Multimed. Tools Appl. 2022, 81, 41295–41308. [Google Scholar] [CrossRef]
- Liu, D.R.; Chen, K.Y.; Lee, H.; Lee, L.S. Completely unsupervised phoneme recognition by adversarially learning mapping relationships from audio embeddings. arXiv 2018, arXiv:1804.00316. [Google Scholar]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S.; Dahlgren, N.L. The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus CDROM; Linguistic Data Consortium: Philadelphia, PA, USA, 1993. [Google Scholar]
- Wang, Y.H.; Lee, H.; Lee, L. Segmental audio word2vec: Representing utterances as sequences of vectors with applications in spoken term detection. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 6269–6273. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common voice: A massively-multilingual speech corpus. arXiv 2019, arXiv:1912.06670. [Google Scholar]
- Khassanov, Y.; Mussakhojayeva, S.; Mirzakhmetov, A.; Adiyev, A.; Nurpeiissov, M.; Varol, H.A. A crowdsourced open-source Kazakh speech corpus and initial speech recognition baseline. arXiv 2020, arXiv:2009.10334. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5206–5210. [Google Scholar]
- Riviere, M.; Joulin, A.; Mazaré, P.E.; Dupoux, E. Unsupervised pretraining transfers well across languages. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7414–7418. [Google Scholar]
- Rouzi, A.; Shi, Y.; Zhiyong, Z.; Dong, W.; Hamdulla, A.; Fang, Z. THUYG-20: A free Uyghur speech database. J. Tsinghua Univ. (Sci. Technol.) 2017, 57, 182–187. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N.E.Y.; Heymann, J.; Wiesner, M.; Chen, N.; et al. Espnet: End-to-end speech processing toolkit. arXiv 2018, arXiv:1804.00015. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A fast, extensible toolkit for sequence modeling. arXiv 2019, arXiv:1904.01038. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Bernard, M.; Titeux, H. Phonemizer: Text to phones transcription for multiple languages in python. J. Open Source Softw. 2021, 6, 3958. [Google Scholar] [CrossRef]
- Fer, R.; Matějka, P.; Grézl, F.; Plchot, O.; Veselý, K.; Černocký, J.H. Multilingually trained bottleneck features in spoken language recognition. Comput. Speech Lang. 2017, 46, 252–267. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lang | kk | tr | ky | tt | du | zh | ru | it | es | fr |
|---|---|---|---|---|---|---|---|---|---|---|
| Unsup.pretrain (h) | 2 | 11 | 17 | 17 | 29 | 50 | 55 | 90 | 168 | 353 |
| Sup.train (h) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Evaluation (h) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Dataset | Duration | |||
|---|---|---|---|---|
| Train | Dev | Test | Total | |
| Librispeech | 960.9 | 10.7 | 10.5 | 982.1 |
| KSC | 318.4 | 7.1 | 7.1 | 332.6 |
| TIMIT | 2.9 | 0.3 | 0.2 | 3.4 |
| THUYG-20 | 20.2 | 1.1 | 2.4 | 23.7 |
| α1 | α2 | α3 | PER |
|---|---|---|---|
| 0.5 | 0.5 | 0 | 22.8 |
| 0.6 | 0.2 | 0.2 | 21.9 |
| 0.2 | 0.6 | 0.2 | 21.4 |
| 0.33 | 0.33 | 0.33 | 21.1 |
| 0.25 | 0.25 | 0.5 | 22.6 |
| Model | Language | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| kk | tr | ky | tt | du | zh | ru | it | es | fr | |
| Baselines from previous work (Unsupvised pretraining) | ||||||||||
| m-CPC [28] | - | 49.7 | 40.7 | 44.0 | 44.4 | 55.5 | 45.2 | 42.1 | 38.7 | 49.3 |
| m-CPC [28] | - | 47.3 | 41.2 | 42.0 | 42.5 | 55.0 | 43.7 | 40.5 | 38.0 | 47.1 |
| Fer et al. [37] | - | 43.4 | 38.7 | 42.5 | 47.9 | 54.3 | 45.2 | 39.0 | 36.6 | 48.3 |
| Our monolingual and multilingual models | ||||||||||
| Encoder | ||||||||||
| LS960h | 22.3 | 16.3 | 13.8 | 12.3 | 20.6 | 29.9 | 19.7 | 20.2 | 13.7 | 22.4 |
| ML960h-10 | 21.7 | 14.1 | 11.2 | 10.4 | 18.9 | 27.6 | 15.8 | 16.5 | 10.8 | 18.3 |
| α1 | α2 | α3 | Supervied Train | Unsupervied Train | PER |
|---|---|---|---|---|---|
| 0.5 | 0.5 | 0 | Kk-Sup2h | - | 22.8 |
| 0.33 | 0.33 | 0.33 | Kk-Sup2h | Kk-Sup2h | 21.7 |
| 0.33 | 0.33 | 0.33 | Kk-Sup2h | KSC-Unsup20h | 21.2 |
| 0.33 | 0.33 | 0.33 | Kk-Sup2h | THUYG-Unsup20h | 21.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yolwas, N.; Meng, W. JSUM: A Multitask Learning Speech Recognition Model for Jointly Supervised and Unsupervised Learning. Appl. Sci. 2023, 13, 5239. https://doi.org/10.3390/app13095239
Yolwas N, Meng W. JSUM: A Multitask Learning Speech Recognition Model for Jointly Supervised and Unsupervised Learning. Applied Sciences. 2023; 13(9):5239. https://doi.org/10.3390/app13095239
Chicago/Turabian StyleYolwas, Nurmemet, and Weijing Meng. 2023. "JSUM: A Multitask Learning Speech Recognition Model for Jointly Supervised and Unsupervised Learning" Applied Sciences 13, no. 9: 5239. https://doi.org/10.3390/app13095239