
Multi-Label Classification Based on Associations
 ,
,  ,
,  , , and
, , and
Abstract
:1. Introduction
2. Literature Review
2.1. MLC Overview
2.2. Utilizing AC in MLC
2.3. CBA and msCBA Algorithms
| Algorithm 1 CBA algorithm. |
| 1: ; |
| 2: ; |
| 3: ; |
| 4: for do |
| 5: ; |
| 6: for each data case do |
| 7: =ruleSubset(,d); |
| 8: for each candidate do |
| 9: c.condsupCont++; |
| 10: if then |
| 11: c.rulesupCount++; |
| 12: end if |
| 13: end |
| 14: end |
| 15: ; |
| 16: ; |
| 17: ; |
| 18: end for |
| 19: ; |
| 20: ; |
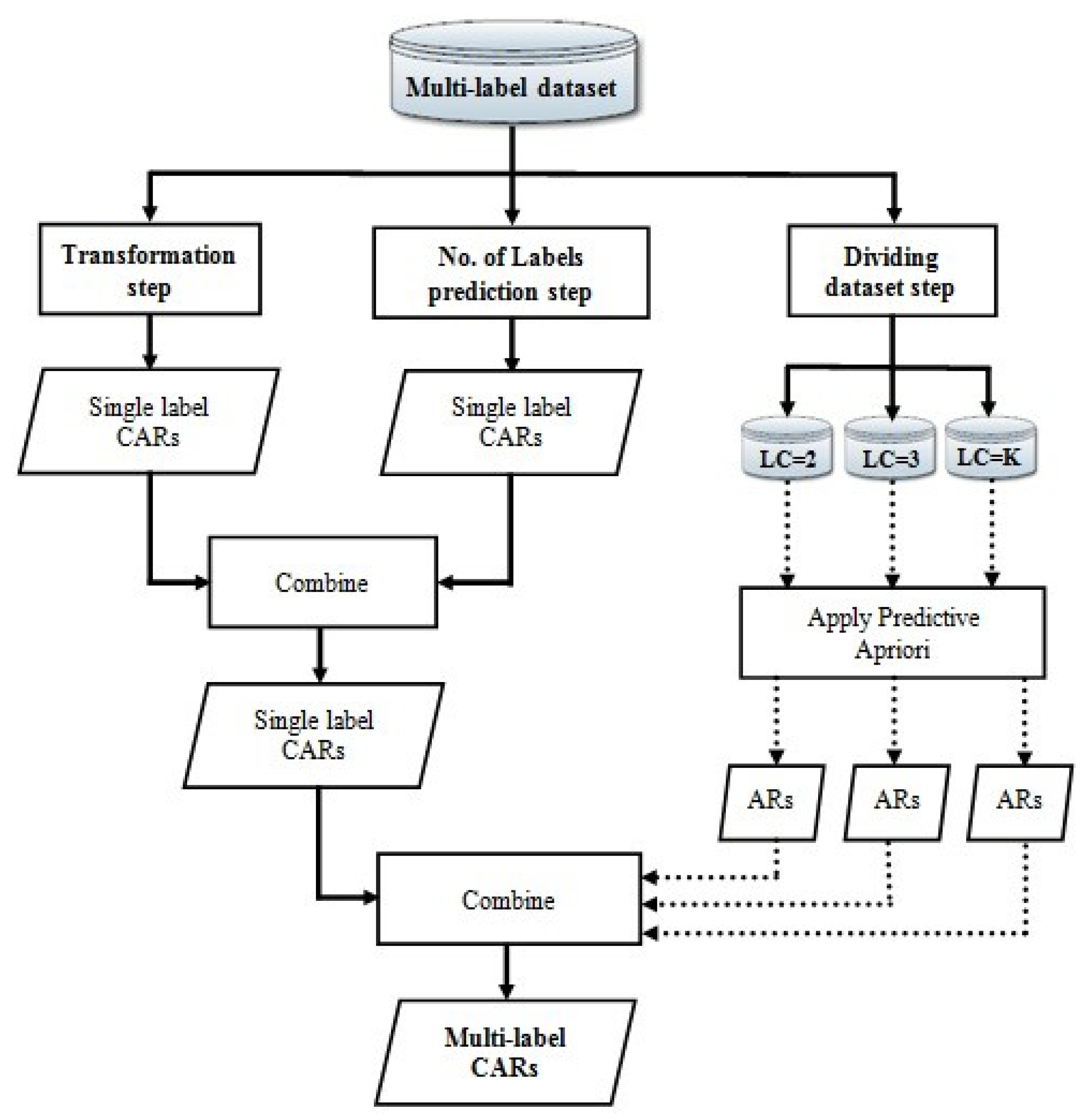
3. ML-CBA Algorithm
| Algorithm 2 ML-CBA algorithm. |
| Input: Multi-label dataset ( D), minsup, minconf, minacc. |
| Output: Multi-label CARs |
| begin: |
| Step 1: |
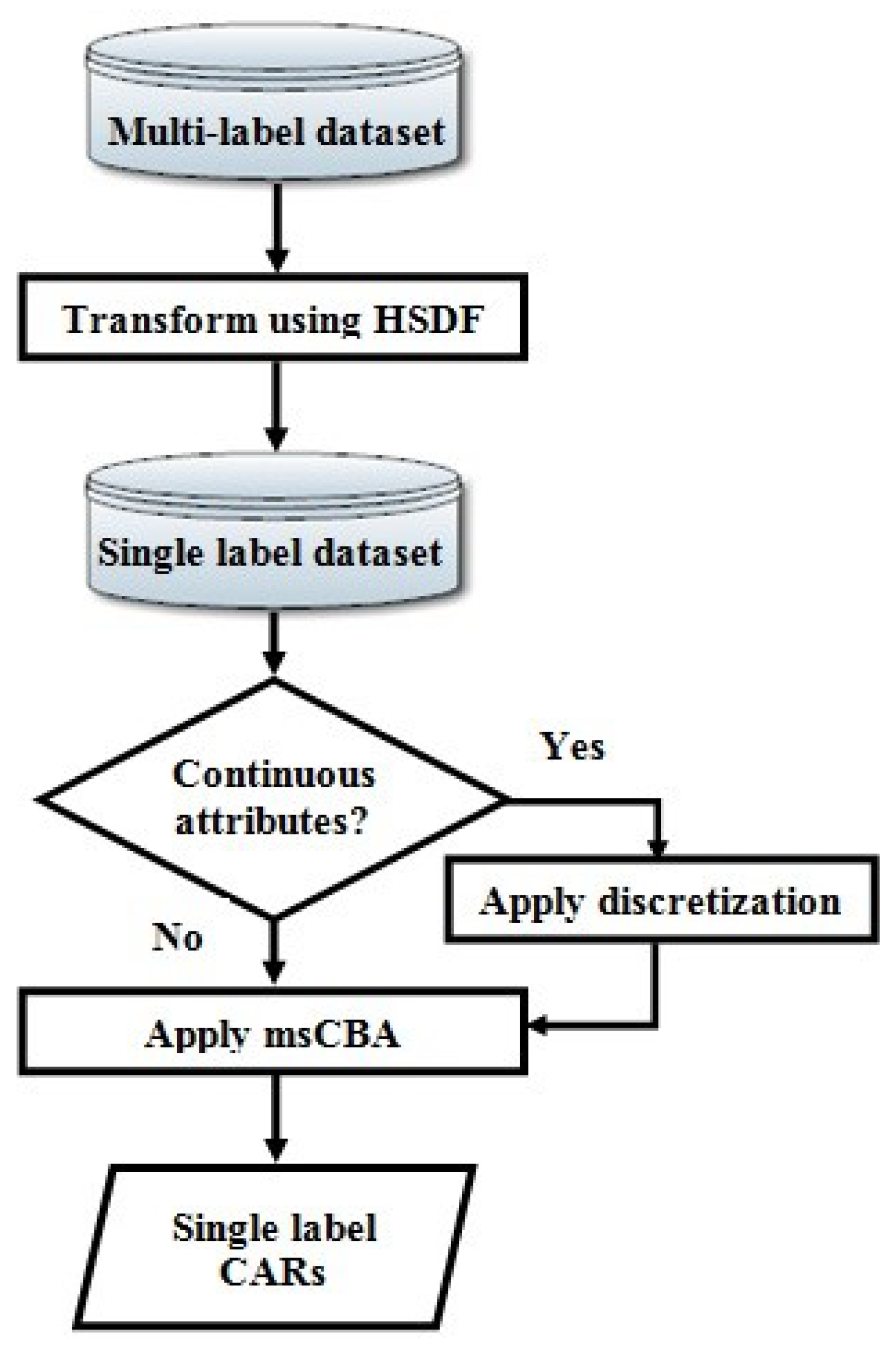
| 1.1 Transform (D) into single label dataset (S) using HSDF. |
| 1.2 Convert continuous attributes (if any) into categorical attributes, by applying Bayesian-D discretization technique. |
| 1.3 Construct the single label CARs for the transformed dataset that satisfy minsup and minconf thresholds, by applying the msCBA algorithm. |
| Step 2: |
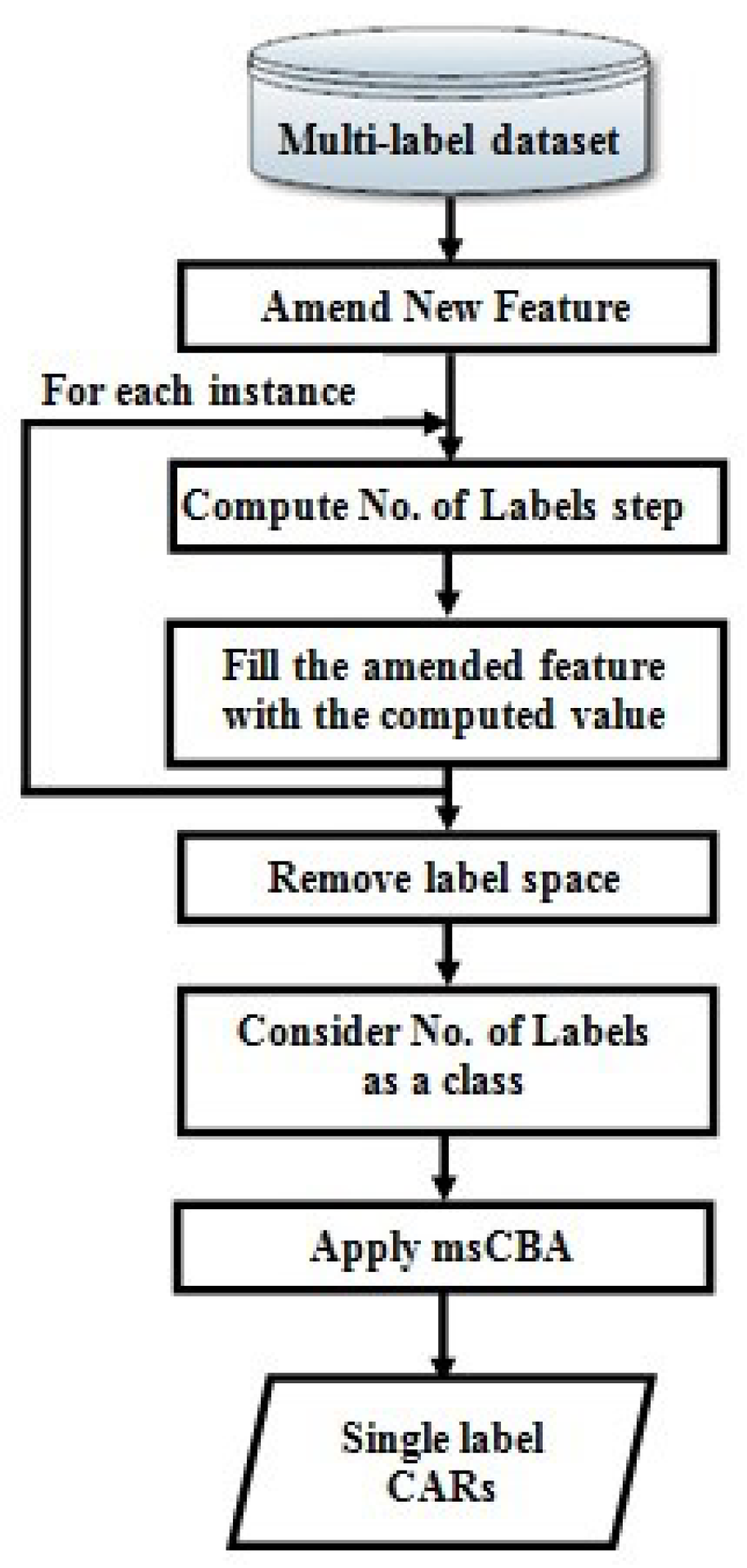
| 2.1 Amend a new feature to the dataset to represent the total number of labels associated with each instance. |
| 2.2 For each instance in the training set, compute the total number of labels associated with this instance, and amend it to the new feature. |
| 2.3 Remove the label space from the dataset, and consider the last feature as a class. |
| 2.4 Classify the dataset using msCBA algorithm. |
| Step 3: |
| 3.1 Extract the label space of the input multi-label dataset. |
| 3.2 Divide the extracted label space into (K) subsets, where k = the maximum number of labels that are associated with the instances - 1. |
| 3.3 For each subset, capture all the positive local correlations among labels, with respect to the HSDF transformation order, and the minacc threshold (50%)these correlations are considered as local; since they have been captured among a smaller subset of the dataset, and used only when the predicted number of class labels matches the subset with this number of class labels. |
| 3.4 For each label, merge all the captured positive local correlations in the previous step, with respect to the Accuracy of the association rules. |
| Step 4: Amend all classes that have significant positive associations with the class under processing, to the consequent of the selected single label CAR, with respect to the predicted number of labels. |
| Step 5: Sort the new multi-label rules according to Algorithm 3. |
| Step 6: Use the sorted multi-label rule resulted from Step 5 to classify any new instance. |
| End. |
| Algorithm 3 Rules ordering algorithm. |
| Input: Set of multi-label CARs |
| Output: Sorted multi-label CARs |
| For any two given rules r1 and r2, r1 precedes r2 if: |
| 1. The confidence of r1 is higher than that of r2. |
| 2. Both rules have the same confidence value, but the average accuracy of association rules that form the consequent of r1 is higher than that of r2 |
| 3. Both rules have the same confidence value, and the same association rules accuracy average, but r1 has a higher support than that of r2. |
| 4. Both rules have the same confidence value, the same association rules accuracy average, the same support value, but r1 has a lower cardinality than that of r2. |
| 5. Chose randomly when the four previous conditions are the same for r1 and r2 |
3.1. Classification Phase in ML-CBA
3.2. Evaluation of the Proposed ML-CBA Algorithm
- Zi: the predicted label set
- Yi: the ground truth label set
- q: total number of labels
- t: total number of instances.
3.2.1. An Analysis of the Proposed ML-CBA Algorithm Utilizing Datasets of Typical Size
3.2.2. Evaluation of the Proposed ML-CBA Algorithm on the Large-Sized Datasets
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hadi, W.; Al-Radaideh, Q.A.; Alhawari, S. Integrating associative rule-based classification with Naïve Bayes for text classification. Appl. Soft Comput. 2018, 69, 344–356. [Google Scholar] [CrossRef]
- Zeng, C.; Zhou, W.; Li, T.; Shwartz, L.; Grabarnik, G.Y. Knowledge guided hierarchical multi-label classification over ticket data. IEEE Trans. Netw. Serv. Manag. 2017, 14, 246–260. [Google Scholar] [CrossRef]
- Huang, J.; Li, G.; Wang, S.; Xue, Z.; Huang, Q. Multi-label classification by exploiting local positive and negative pairwise label correlation. Neurocomputing 2017, 257, 164–174. [Google Scholar] [CrossRef]
- Mohana, G.; Chitra, S. Design and development of an efficient hierarchical approach for multi-label protein function prediction. Biomed. Res. Health Sci. Bio Converg. Technol. Ed. II 2017, 370–379. Available online: https://www.semanticscholar.org/paper/Design-and-development-of-an-efficient-hierarchical-MohanaPrabha-Chitra/a8b4c905f2d083801b2a7b06356eed9ad49be797 (accessed on 11 February 2023).
- Sousa, R.; Gama, J. Multi-label classification from high-speed data streams with adaptive model rules and random rules. Prog. Artif. Intell. 2018, 7, 177–187. [Google Scholar] [CrossRef]
- Xu, S.; Yang, X.; Yu, H.; Yu, D.J.; Yang, J.; Tsang, E.C. Multi-label learning with label-specific feature reduction. Knowl.-Based Syst. 2016, 104, 52–61. [Google Scholar] [CrossRef]
- Gamallo, P.; Almatarneh, S. Naive-Bayesian Classification for Bot Detection in Twitter. In Proceedings of the CLEF, Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Almatarneh, S.; Gamallo, P.; ALshargabi, B.; Al-Khassawneh, Y.; Alzubi, R. Comparing traditional machine learning methods for COVID-19 fake news. In Proceedings of the 2021 22nd International Arab Conference on Information Technology (ACIT), Muscat, Oman, 21–23 December 2021; IEEE: New York, NY, USA, 2021; pp. 1–4. [Google Scholar]
- Lin, Q.; Man, Z.; Cao, Y.; Wang, H. Automated Classification of Whole-Body SPECT Bone Scan Images with VGG-Based Deep Networks. Int. Arab. J. Inf. Technol. 2023, 20, 1–8. [Google Scholar] [CrossRef]
- Alazaidah, R.; Thabtah, F.; Al-Radaideh, Q. A multi-label classification approach based on correlations among labels. Int. J. Adv. Comput. Sci. Appl. 2015, 6, 52–59. [Google Scholar] [CrossRef]
- Gibaja, E.; Ventura, S. A tutorial on multilabel learning. ACM Comput. Surv. 2015, 47, 1–38. [Google Scholar] [CrossRef]
- Suri, J.S.; Bhagawati, M.; Paul, S.; Protogerou, A.D.; Sfikakis, P.P.; Kitas, G.D.; Khanna, N.N.; Ruzsa, Z.; Sharma, A.M.; Saxena, S.; et al. A powerful paradigm for cardiovascular risk stratification using multiclass, multi-label, and ensemble-based machine learning paradigms: A narrative review. Diagnostics 2022, 12, 722. [Google Scholar] [CrossRef]
- Hegazy, H.I.; Tag Eldien, A.S.; Tantawy, M.M.; Fouda, M.M.; TagElDien, H.A. Real-time locational detection of stealthy false data injection attack in smart grid: Using multivariate-based multi-label classification approach. Energies 2022, 15, 5312. [Google Scholar] [CrossRef]
- El-Hasnony, I.M.; Elzeki, O.M.; Alshehri, A.; Salem, H. Multi-label active learning-based machine learning model for heart disease prediction. Sensors 2022, 22, 1184. [Google Scholar] [CrossRef] [PubMed]
- Abdelhamid, N.; Jabbar, A.A.; Thabtah, F. Associative classification common research challenges. In Proceedings of the 2016 45th International Conference on Parallel Processing Workshops (ICPPW), Philadelphia, PA, USA, 16–19 August 2016; IEEE: New York, NY, USA, 2016; pp. 432–437. [Google Scholar]
- Abdelhamid, N.; Thabtah, F. Associative classification approaches: Review and comparison. J. Inf. Knowl. Manag. 2014, 13, 1450027. [Google Scholar] [CrossRef]
- Li, B.; Li, H.; Wu, M.; Li, P. Multi-label Classification based on Association Rules with Application to Scene Classification. In Proceedings of the 2008 The 9th International Conference for Young Computer Scientists, Hunan, China, 18–21 November 2008; pp. 36–41. [Google Scholar] [CrossRef]
- Liu, B.; Ma, Y.; Wong, C.K. Improving an association rule based classifier. In Proceedings of the Principles of Data Mining and Knowledge Discovery: 4th European Conference, PKDD 2000, Lyon, France, 13–16 September 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 504–509. [Google Scholar]
- Alazaidah, R.; Ahmad, F.K.; Mohsen, M.F.M. A comparative analysis between the three main approaches that are being used to. Int. J. Soft Comput. 2017, 12, 218–223. [Google Scholar]
- Massidda, L.; Marrocu, M.; Manca, S. Non-intrusive load disaggregation by convolutional neural network and multilabel classification. Appl. Sci. 2020, 10, 1454. [Google Scholar] [CrossRef]
- Wu, X.; Gao, Y.; Jiao, D. Multi-label classification based on random forest algorithm for non-intrusive load monitoring system. Processes 2019, 7, 337. [Google Scholar] [CrossRef]
- Alluwaici, M.; Junoh, A.K.; Alazaidah, R. New problem transformation method based on the local positive pairwise dependencies among labels. J. Inf. Knowl. Manag. 2020, 19, 2040017. [Google Scholar] [CrossRef]
- Alluwaici, M.; Junoh, A.K.; Ahmad, F.K.; Mohsen, M.F.M.; Alazaidah, R. Open research directions for multi label learning. In Proceedings of the 2018 IEEE Symposium on Computer Applications & Industrial Electronics (ISCAIE), Penang Island, Malaysia, 28–29 April 2018; pp. 125–128. [Google Scholar] [CrossRef]
- Dimou, A.; Tsoumakas, G.; Mezaris, V.; Kompatsiaris, I.; Vlahavas, I. An empirical study of multi-label learning methods for video annotation. In Proceedings of the 2009 Seventh International Workshop on Content-Based Multimedia Indexing, Crete, Greece, 3–5 June 2009; IEEE: New York, NY, USA, 2009; pp. 19–24. [Google Scholar]
- Peters, S.; Denoyer, L.; Gallinari, P. Iterative annotation of multi-relational social networks. In Proceedings of the 2010 International Conference on Advances in Social Networks Analysis and Mining, Odense, Denmark, 9–11 August 2010; IEEE: New York, NY, USA, 2010; pp. 96–103. [Google Scholar]
- Wang, J.; Neskovic, P.; Cooper, L.N. Improving nearest neighbor rule with a simple adaptive distance measure. Pattern Recognit. Lett. 2007, 28, 207–213. [Google Scholar] [CrossRef]
- Trohidis, K.; Tsoumakas, G.; Kalliris, G.; Vlahavas, I.P. Multi-label classification of music into emotions. In Proceedings of the ISMIR, Philadelphia, PA, USA, 14–18 September 2008; Volume 8, pp. 325–330. [Google Scholar]
- Barutcuoglu, Z.; Schapire, R.E.; Troyanskaya, O.G. Hierarchical multi-label prediction of gene function. Bioinformatics 2006, 22, 830–836. [Google Scholar] [CrossRef]
- Elisseeff, A.; Weston, J. A kernel method for multi-labelled classification. In Advances in Neural Information Processing Systems 14 (NIPS 2001); Dietterich, T., Becker, S., Ghahramani, Z., Eds.; The MIT Press: Cambridge, MA, USA, 2001; Volume 14. [Google Scholar]
- Skabar, A.; Wollersheim, D.; Whitfort, T. Multi-label classification of gene function using MLPs. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; IEEE: New York, NY, USA, 2006; pp. 2234–2240. [Google Scholar]
- Chan, A.; Freitas, A.A. A new ant colony algorithm for multi-label classification with applications in bioinfomatics. In Proceedings of the 8th Annual Conference on Genetic and Evolutionary Computation, Seattle, WA, USA, 8–12 July 2006; pp. 27–34. [Google Scholar]
- Diplaris, S.; Tsoumakas, G.; Mitkas, P.A.; Vlahavas, I. Protein classification with multiple algorithms. In Proceedings of the Advances in Informatics: 10th Panhellenic Conference on Informatics, PCI 2005, Volas, Greece, 11–13 November 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 448–456. [Google Scholar]
- Kawai, Y.; Fujii, Y.; Akimoto, K.; Takahashi, M. Evaluation of Serum Protein Binding by Using in Vitro Pharmacological Activity for the Effective Pharmacokinetics Profiling in Drug Discovery. Chem. Pharm. Bull. 2010, 58, 1051–1056. [Google Scholar] [CrossRef]
- Krohn-Grimberghe, A.; Drumond, L.; Freudenthaler, C.; Schmidt-Thieme, L. Multi-relational matrix factorization using bayesian personalized ranking for social network data. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; pp. 173–182. [Google Scholar]
- Tang, L.; Liu, H. Community Detection and Mining in Social Media; Morgan & Claypool Publishers: San Rafael, CA, USA, 2010. [Google Scholar]
- Soonsiripanichkul, B.; Murata, T. Domination dependency analysis of sales marketing based on multi-label classification using label ordering and cycle chain classification. In Proceedings of the 2016 5th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), Kumamoto, Japan, 10–14 July 2016; IEEE: New York, NY, USA, 2016; pp. 1048–1053. [Google Scholar]
- Nassar, O.A.; Al Saiyd, N.A. The integrating between web usage mining and data mining techniques. In Proceedings of the 2013 5th International Conference on Computer Science and Information Technology, Amman, Jordan, 27–28 March 2013; IEEE: New York, NY, USA, 2013; pp. 243–247. [Google Scholar]
- Quinlan, J.R. Combining instance-based and model-based learning. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 July 1993; pp. 236–243. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. Multilabel neural networks with applications to functional genomics and text categorization. IEEE Trans. Knowl. Data Eng. 2006, 18, 1338–1351. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Zhang, M.L.; Peña, J.M.; Robles, V. Feature selection for multi-label naive Bayes classification. Inf. Sci. 2009, 179, 3218–3229. [Google Scholar] [CrossRef]
- Thabtah, F.A.; Cowling, P.; Peng, Y. MMAC: A new multi-class, multi-label associative classification approach. In Proceedings of the Fourth IEEE International Conference on Data Mining (ICDM’04), Brighton, UK, 1–4 November 2004; IEEE: New York, NY, USA, 2004; pp. 217–224. [Google Scholar]
- Alazaidah, R.; Ahmad, F.K. Trending challenges in multi label classification. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 127–131. [Google Scholar] [CrossRef]
- Abdelhamid, N.; Ayesh, A.; Hadi, W. Multi-label rules algorithm based associative classification. Parallel Process. Lett. 2014, 24, 1450001. [Google Scholar] [CrossRef]
- Veloso, A.; Meira, W.; Gonçalves, M.; Zaki, M. Multi-label lazy associative classification. In Proceedings of the Knowledge Discovery in Databases (PKDD 2007: 11th European Conference on Principles and Practice of Knowledge Discovery in Databases, Warsaw, Poland, 17–21 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 605–612. [Google Scholar]
- Li, X.; Qin, D.; Yu, C. ACCF: Associative classification based on closed frequent itemsets. In Proceedings of the 2008 Fifth International Conference on Fuzzy Systems and Knowledge Discovery, Shandong, China, 18–20 October 2008; IEEE: New York, NY, USA, 2008; Volume 2, pp. 380–384. [Google Scholar]
- Liu, B.; Hsu, W.; Ma, Y. Integrating classification and association rule mining. In Proceedings of the Kdd, New York, NY, USA, 27–31 August 1998; Volume 98, pp. 80–86. [Google Scholar]
- Abdelhamid, N.; Ayesh, A.; Thabtah, F.; Ahmadi, S.; Hadi, W. MAC: A multiclass associative classification algorithm. J. Inf. Knowl. Manag. 2012, 11, 1250011. [Google Scholar] [CrossRef]
- Alazaidah, R.; Almaiah, M.A. Associative classification in multi-label classification: An investigative study. Jordanian J. Comput. Inf. Technol. 2021, 7. Available online: https://www.proquest.com/openview/9a1e4545ef6dd7deea31b808f011119c/1?pq-origsite=gscholar&cbl=5500744 (accessed on 11 February 2023). [CrossRef]
- Huang, S.J.; Zhou, Z.H. Multi-label learning by exploiting label correlations locally. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, US, 22–26 July 2012; Volume 26, pp. 949–955. [Google Scholar]
- Alazaidah, R.; Ahmad, F.K.; Mohsin, M. Multi label ranking based on positive pairwise correlations among labels. Int. Arab J. Inf. Technol. 2020, 17, 440–449. [Google Scholar] [CrossRef]
- Liu, H.; Setiono, R. Feature selection via discretization. IEEE Trans. Knowl. Data Eng. 1997, 9, 642–645. [Google Scholar]
- Triguero, I.; González, S.; Moyano, J.M.; García López, S.; Alcalá Fernández, J.; Luengo Martín, J.; Fernández Hilario, A.L.; Jesús Díaz, M.J.D.; Sánchez, L.; Herrera Triguero, F.; et al. KEEL 3.0: An Open Source Software for Multi-Stage Analysis in Data Mining. 2017. Available online: https://digibug.ugr.es/handle/10481/49780 (accessed on 15 September 2022).
- Fürnkranz, J.; Hüllermeier, E.; Loza Mencía, E.; Brinker, K. Multilabel classification via calibrated label ranking. Mach. Learn. 2008, 73, 133–153. [Google Scholar] [CrossRef]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Vlahavas, I. Random k-labelsets: An ensemble method for multilabel classification. In Proceedings of the Machine Learning (ECML 2007): 18th European Conference on Machine Learning, Warsaw, Poland, 17–21 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 406–417. [Google Scholar]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef]
- Read, J.; Pfahringer, B.; Holmes, G. Multi-label classification using ensembles of pruned sets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: New York, NY, USA, 2008; pp. 995–1000. [Google Scholar]
- Wu, X. A Bayesian discretizer for real-valued attributes. Comput. J. 1996, 39, 688–691. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Instances | Attributes | Labels | LCard |
|---|---|---|---|---|
| Yeast | 2417 | 103 | 14 | 4.327 |
| Scene | 2712 | 294 | 6 | 1.074 |
| Emotions | 593 | 72 | 6 | 1.868 |
| Flags | 194 | 19 | 7 | 3.392 |
| Genbase | 662 | 1186 | 27 | 1.252 |
| TMC2007 | 28,596 | 500 | 22 | 2.16 |
| Correlations Type | Approach | Algorithm | Yeast | Scene | Emotions | Flags |
|---|---|---|---|---|---|---|
| ML-CBA | 0.584 | 0.977 | 0.744 | 0.694 | ||
| BR | 0.52 | 0.643 | 0.551 | 0.576 | ||
| 1st Order | ML-KNN | 0.52 | 0.691 | 0.366 | 0.555 | |
| Global Correlations | BP-MLL | 0.185 | 0.212 | 0.276 | NG | |
| 2nd Order | CLR | 0.514 | 0.695 | 0.557 | NG | |
| High Order | LP | 0.53 | 0.735 | 0.584 | NG | |
| RAKEL | 0.493 | 0.694 | 0.592 | NG | ||
| CC | 0.521 | 0.736 | 0.584 | NG | ||
| PS | 0.533 | 0.751 | 0.599 | NG | ||
| ECC | 0.299 | 0.27 | 0.282 | NG | ||
| EPS | 0.537 | 0.751 | 0.599 | NG | ||
| BR+ | 0.4838 | 0.5744 | 0.5537 | NG | ||
| Local Correlations | ML-LOC | 0.51 | NG | 0.497 | 0.568 | |
| LPLC | 0.542 | NG | 0.565 | 0.607 |
| Correlations Type | Approach | Algorithm | Yeast | Scene | Emotions | Flags |
|---|---|---|---|---|---|---|
| ML-CBA | 0.078 | 0.006 | 0.09 | 0.118 | ||
| BR | 0.193 | 0.009 | 0.188 | 0.274 | ||
| 1st Order | ML-KNN | 0.193 | 0.085 | 0.262 | 0.284 | |
| Global Correlations | BP-MLL | 0.322 | 0.057 | 0.433 | NG | |
| 2nd Order | CLR | 0.226 | 0.101 | 0.214 | NG | |
| High Order | LP | 0.206 | 0.09 | 0.198 | NG | |
| RAKEL | 0.207 | 0.095 | 0.186 | NG | ||
| CC | 0.211 | 0.1 | 0.197 | NG | ||
| PS | 0.205 | 0.084 | 0.192 | NG | ||
| ECC | 0.619 | 0.47 | 0.63 | NG | ||
| EPS | 0.207 | 0.085 | 0.193 | NG | ||
| BR+ | 0.222 | 0.258 | 0.226 | NG | ||
| Local Correlations | ML-LOC | 0.193 | NG | 0.21 | 0.262 | |
| LPLC | 0.202 | NG | 0.197 | 0.279 |
| Correlations Type | Approach | Algorithm | Yeast | Scene | Emotions | Flags |
|---|---|---|---|---|---|---|
| ML-CBA | 0.276 | 0.97 | 0.638 | 0.513 | ||
| BR | 0.146 | 0.617 | 0.307 | 0.076 | ||
| 1st Order | ML-KNN | 0.189 | 0.643 | 0.143 | 0.098 | |
| Global Correlations | BP-MLL | 0.185 | 0.212 | 0.276 | NG | |
| 2nd Order | CLR | NG | NG | NG | NG | |
| High Order | LP | 0.194 | 0.696 | 0.351 | 0.123 | |
| RAKEL | 0.163 | 0.662 | 0.341 | NG | ||
| CC | 0.196 | 0.669 | 0.349 | NG | ||
| PS | 0.258 | 0.717 | 0.367 | NG | ||
| ECC | 0.243 | 0.007 | 0.022 | 0.191 | ||
| EPS | 0.253 | 0.715 | 0.366 | NG | ||
| Local Correlations | ML-LOC | 0.199 | NG | 0.261 | 0.115 | |
| LPLC | 0.186 | NG | 0.303 | 0.123 |
| Correlations Type | Approach | Algorithm | Yeast | Scene | Emotions | Flags |
|---|---|---|---|---|---|---|
| ML-CBA | 0.258 | 0.009 | 0.123 | 0.145 | ||
| BR | 0.227 | 0.262 | 0.256 | NG | ||
| 1st Order | ML-KNN | 0.228 | 0.219 | 0.263 | NG | |
| Global Correlations | BP-MLL | 0.235 | 0.821 | 0.318 | NG | |
| 2nd Order | CLR | 0.241 | 0.323 | 0.291 | NG | |
| High Order | LP | 0.267 | 0.246 | 0.31 | NG | |
| RAKEL | 0.255 | 0.237 | 0.26 | NG | ||
| CC | 0.256 | 0.268 | 0.283 | NG | ||
| PS | 0.321 | 0.287 | 0.427 | NG | ||
| ECC | 0.685 | 0.775 | 0.802 | NG | ||
| EPS | 0.265 | 0.225 | 0.3 | NG | ||
| Local Correlations | ML-LOC | 0.216 | 0.179 | NG | NG | |
| LPLC | NG | NG | NG | NG |
| Correlations Type | Approach | Algorithm | Genbase | TMC2007 |
|---|---|---|---|---|
| ML-CBA | 0.978 | 0.685 | ||
| BR | 0.962 | 0.541 | ||
| 1st Order | ML-KNN | 0.948 | 0.531 | |
| Global Correlations | BP-MLL | 0.632 | 0.652 | |
| 2nd Order | CLR | 0.561 | 0.506 | |
| High Order | RAKEL | 0.982 | 0.549 | |
| ECC | 0.978 | 0.517 | ||
| EPS | 0.945 | 0.549 | ||
| Local Correlations | ML-LOC | NG | NG | |
| LPLC | NG | NG |
| Correlations Type | Approach | Algorithm | Genbase | TMC2007 |
|---|---|---|---|---|
| ML-CBA | 0.001 | 0.027 | ||
| BR | 0.001 | 0.071 | ||
| 1st Order | ML-KNN | 0.005 | 0.073 | |
| Global Correlations | BP-MLL | 0.004 | 0.098 | |
| 2nd Order | CLR | 0.004 | 0.068 | |
| High Order | RAKEL | 0.003 | 0.068 | |
| LIFT | 0.003 | NG | ||
| ECC | 0.002 | 0.068 | ||
| EPS | 0.007 | 0.069 | ||
| Local Correlations | ML-LOC | 0.001 | NG | |
| LPLC | NG | NG | ||
| LEAD | 0.002 | 0.063 |
| Correlations Type | Approach | Algorithm | Genbase | TMC2007 |
|---|---|---|---|---|
| ML-CBA | 0.978 | 0.52 | ||
| BR | 0.48 | 0.26 | ||
| 1st Order | ML-KNN | NG | NG | |
| Global Correlations | BP-MLL | NG | NG | |
| 2nd Order | CLR | 0.884 | 0.147 | |
| High Order | RAKEL | 0.964 | 0.256 | |
| LIFT | NG | NG | ||
| ECC | 0.592 | 0.233 | ||
| EPS | 0.894 | 0.26 | ||
| Local Correlations | ML-LOC | NG | NG | |
| LPLC | NG | NG | ||
| LEAD | NG | NG |
| Correlations Type | Approach | Algorithm | Genbase | TMC2007 |
|---|---|---|---|---|
| ML-CBA | 0.022 | 0.167 | ||
| BR | 0.037 | 0.342 | ||
| 1st Order | ML-KNN | 0.055 | 0.32 | |
| Global Correlations | BP-MLL | 0.368 | 0.445 | |
| 2nd Order | CLR | 0.439 | 0.425 | |
| High Order | RAKEL | NG | 0.253 | |
| LIFT | 0 | 0.213 | ||
| ECC | 0.001 | 0.232 | ||
| Local Correlations | ML-LOC | 0.004 | NG | |
| LPLC | NG | NG | ||
| LEAD | 0.007 | 0.226 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alazaidah, R.; Samara, G.; Almatarneh, S.; Hassan, M.; Aljaidi, M.; Mansur, H. Multi-Label Classification Based on Associations. Appl. Sci. 2023, 13, 5081. https://doi.org/10.3390/app13085081
Alazaidah R, Samara G, Almatarneh S, Hassan M, Aljaidi M, Mansur H. Multi-Label Classification Based on Associations. Applied Sciences. 2023; 13(8):5081. https://doi.org/10.3390/app13085081
Chicago/Turabian StyleAlazaidah, Raed, Ghassan Samara, Sattam Almatarneh, Mohammad Hassan, Mohammad Aljaidi, and Hasan Mansur. 2023. "Multi-Label Classification Based on Associations" Applied Sciences 13, no. 8: 5081. https://doi.org/10.3390/app13085081