
Knowledge-Aware Enhanced Network Combining Neighborhood Information for Recommendations


Abstract
:1. Introduction
- 1
- We propose KCNR, a knowledge-aware enhanced network combining neighborhood information, which is an end-to-end model. KCNR effectively utilizes users’ prior information and the rich associative semantic information in the KG, and greatly enhances user and item representations, by designing a user representation layer (URL) and item representation layer (IRL), to alleviate the data sparsity problem of the RS.
- 2
- We design an ICM, to enable information sharing and complementarity between items in the RS and related entities in the KG. The model generalization capability is improved, based on further enriching the item embedding representation.
- 3
- We conduct experiments in three realistic recommendation scenarios, and the results show that KCNR outperforms the baseline approach.
2. Related Work
3. Our Approach
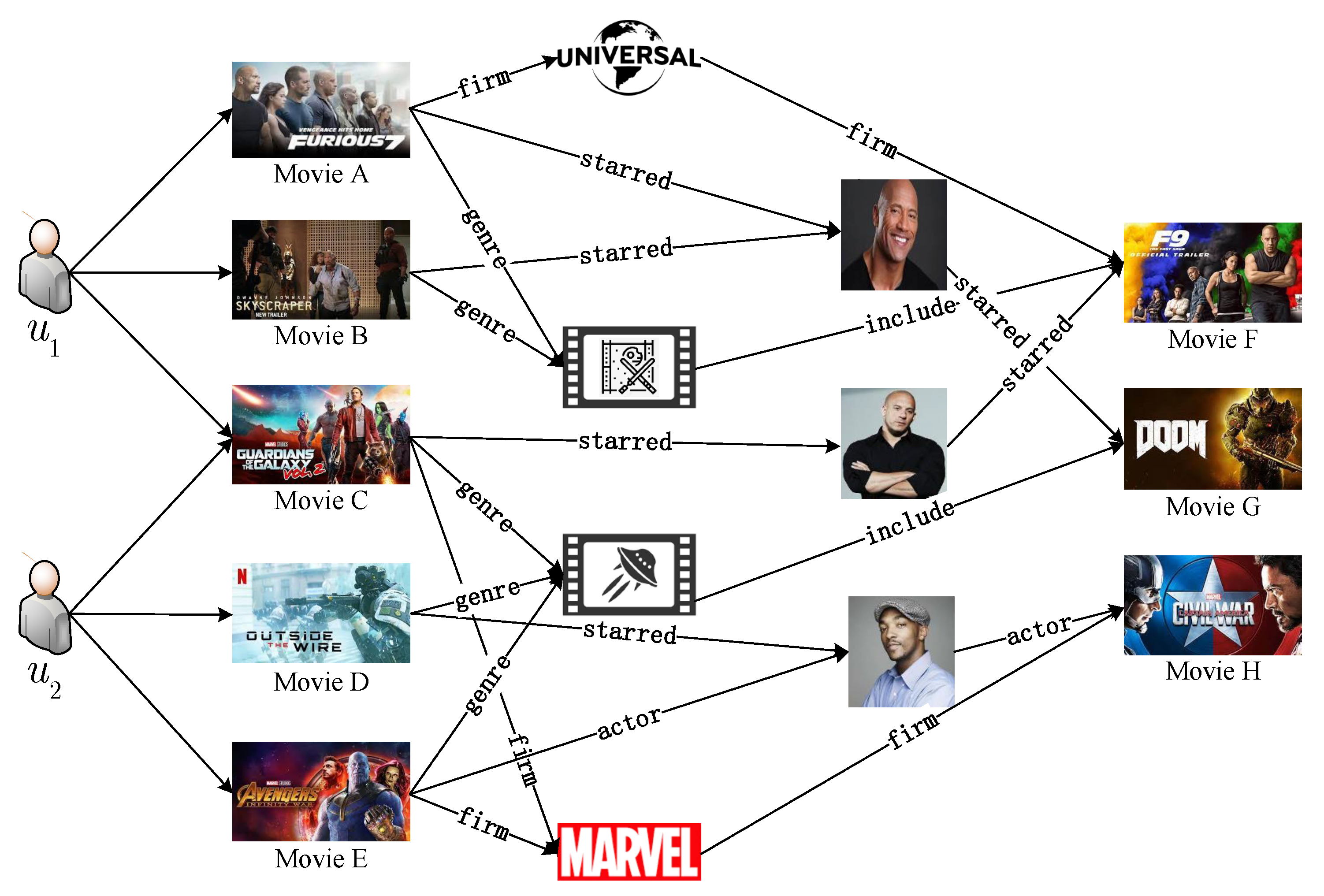
3.1. Problem Definition
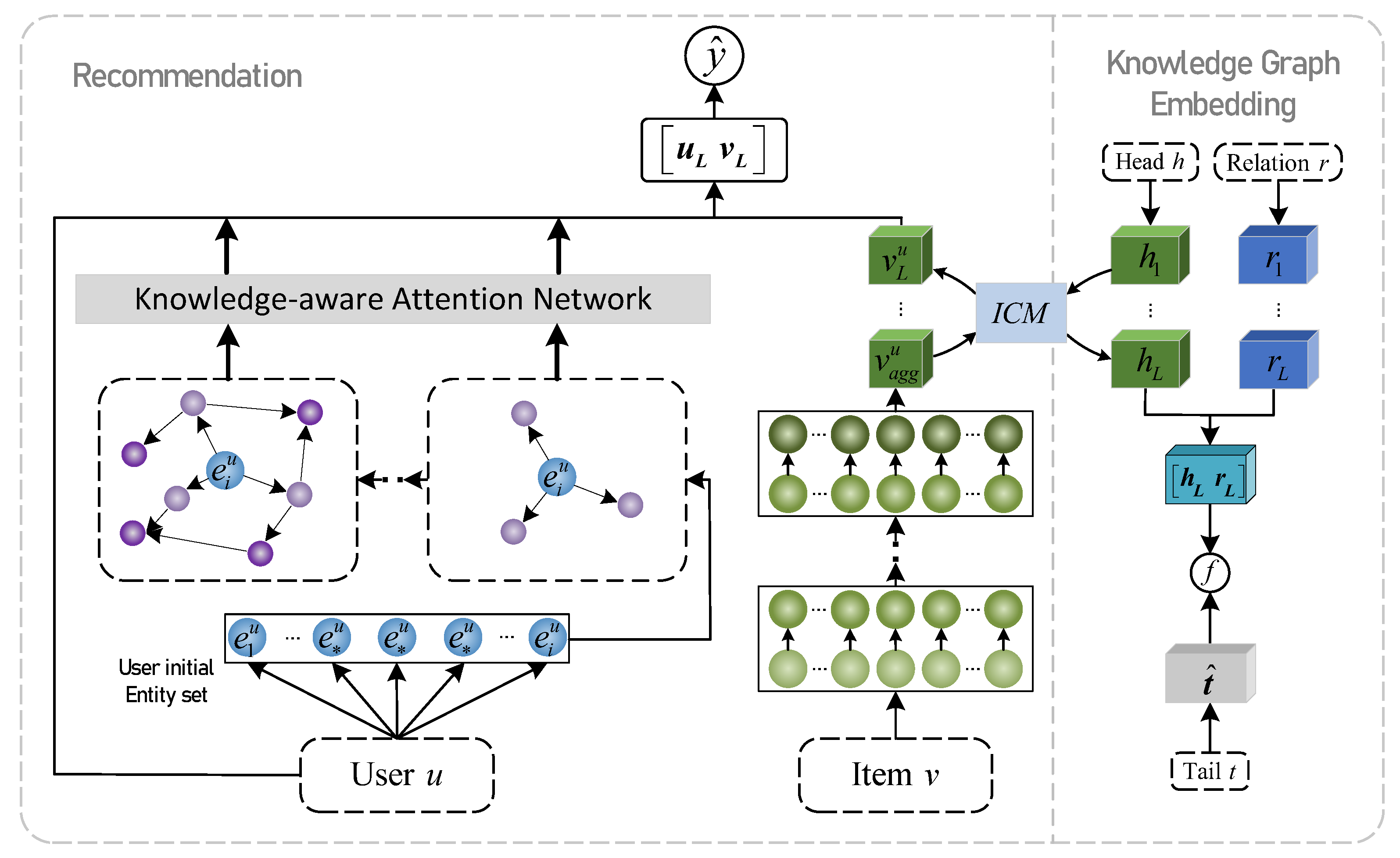
3.2. Model Framework
3.3. Recommendation Module
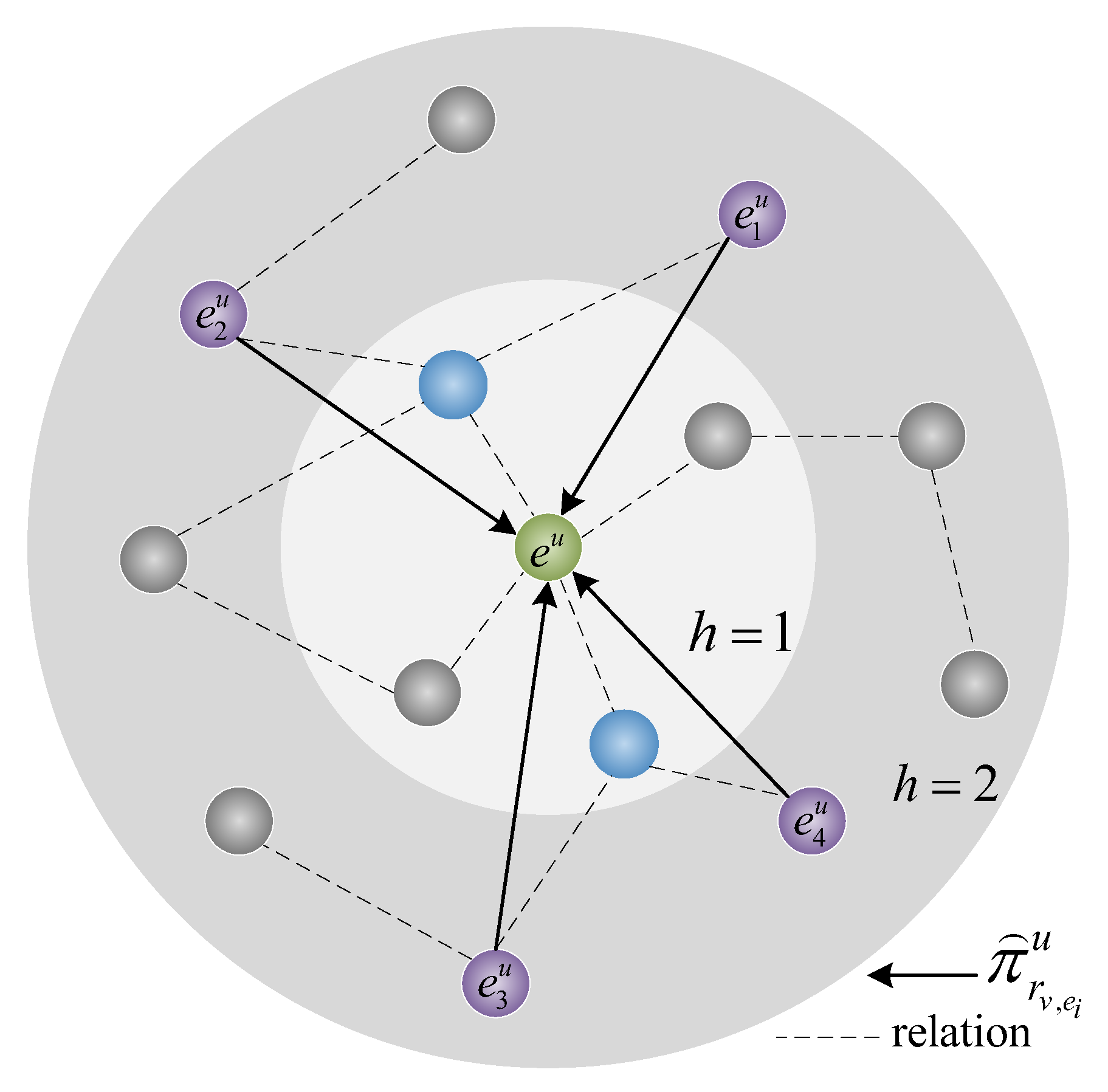
3.3.1. URL
3.3.2. IRL
- Summation aggregator [27] directly sums v and , and then goes through a nonlinear layer, which is defined as follows:
- Concat aggregator [28] concatenates v and before going through the nonlinear layer, which is defined as follows:
- Bi-interaction aggregator [30] considers two information interactions of v and , defined as follows:
3.3.3. Prediction Layer
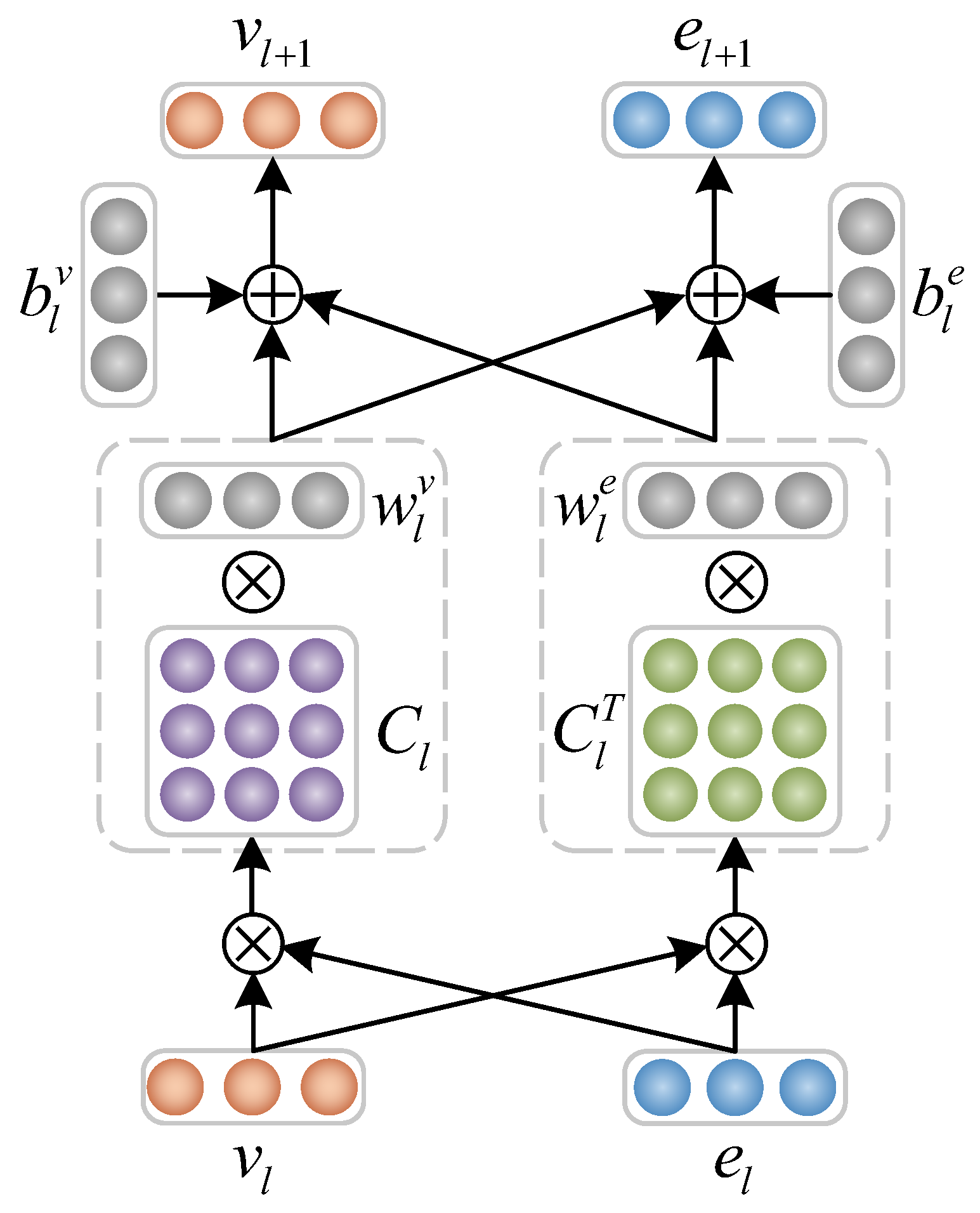
3.4. ICM
3.5. KGE Module
3.6. Learning Algorithm
4. Experiments
4.1. Datasets
- MovieLens-1M, https://grouplens.org/datasets/movielens/1m/, (accessed on 20 September 2022) is the more widely utilized movie recommendation dataset in recommendation systems. In the dataset, 6040 favorite movies of users are reflected as ratings from 1 to 5.
- Book-Crossing, http://www2.informatik.uni-freiburg.de/cziegler/BX/, (accessed on 12 October 2022) is used for book recommendations, and it consists of 90,000 user ratings from 0 to 10, for 1,149,780 books.
- Last.FM, https://grouplens.org/datasets/hetrec-2011/, (accessed on 6 September 2022) is a dataset for music recommendation, which contains music interaction information from 2000 users.
4.2. Baseline Model
- LibFM [31] is used in the CTR recommendation scenario, and it does not use KG.
- PER [12] is a path-based recommendation method that regards the KG as a heterogeneous information network.
- CKE [13] introduces various types of heterogeneous data for the RS, combined with the initial item representation, to improve the recommendation quality.
- Wide&Deep [32] combines a deep model and linear model, to obtain more information, to improve the recommendation effect.
- RippleNet [10] proposed to use the user’s prior information to propagate in the KG, to capture the user’s personalized preferences.
- KGCN [15] propagates item entities in the KG and has a bias to aggregate the item’s neighbor information to complement the item embedding.
- MKR [14] is a multi-task recommendation model trained by combining the recommendation task and the KGE task.
- FairGo [33] uses adversarial learning techniques to consider the fairness of graph recommendation.
- CAKR [34] improves the interaction unit of MKR, to better capture characteristic interactions between entities.
4.3. Experimental Setup
4.4. Experimental Results
- Compared with other baseline models, the performance of PER is relatively poor, because the design of artificial paths often requires more professional domain knowledge, resulting in its inability to use the information in the KG efficiently.
- From the experimental results, LibFM, Wide&Deep, and CKE, achieved better experimental results than PER, indicating that they can utilize the rich auxiliary information in the KG to improve the recommendation performance.
- RippleNet shows excellent performance, suggesting that obtaining auxiliary information by propagating user preferences in the KG is effective in improving the recommendation effect. However, by comparing the experimental results of the three datasets, RippleNet performs poorly on the dataset with greater data sparsity, indicating its strong dependence on data sparsity.
- For both MKR, CAKR, and KGCN, MKR and CAKR outperform all baseline methods on the Book-Crossing dataset, suggesting that the cross-compression unit in MKR and CAKR can learn more additional information, to alleviate the data sparsity problem in recommendation scenarios with high sparsity. KGCN, on the other hand, is the least effective on the Book-Crossing dataset, which is also due to the fact that data sparsity causes KGCN to easily introduce noise, degrading the model performance when aggregating neighbor information.
- Overall, the KCNR model proposed in this paper outperformed all baseline models on all three datasets. On the MovieLens-1M dataset, the AUC increased by 0.7%. On the Book-Crossing dataset, the AUC increased by 0.6%. On the Last.FM dataset, the AUC increased by 1.1%. It can be seen that KCNR utilizes the rich semantic information in the KG, and the special network structure of the KG, to enhance the embedded representation of users and items. This also alleviates the data sparsity problem of the recommendation system, to a certain extent.
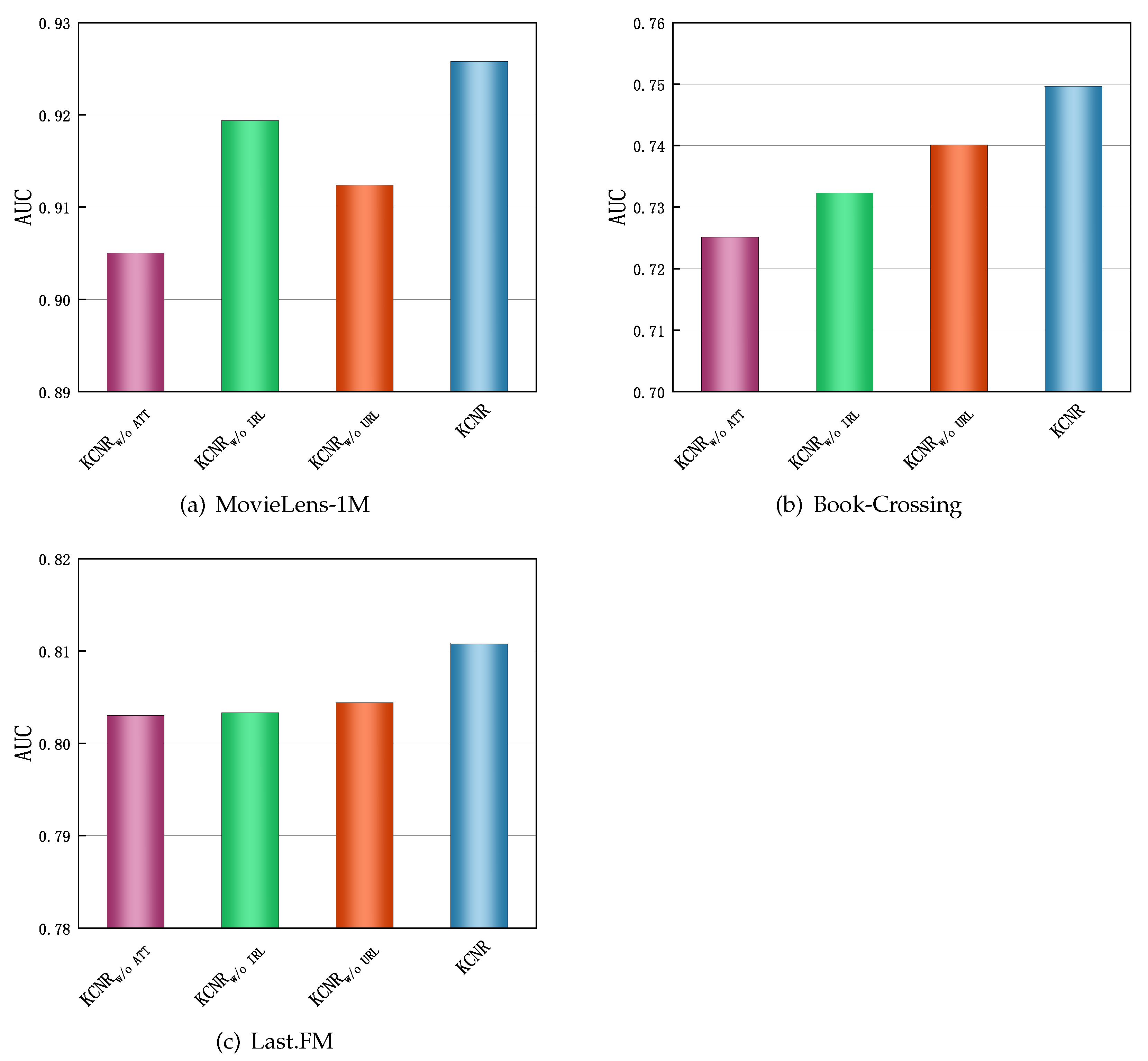
- The last four rows in Table 3 show the results of KCNR using four different aggregators, when aggregating item neighbors. It can be observed that KCNR has the worst performance, because it uses only the information of the item’s neighbors to represent the item, losing the original information of the item. This information is important for the item. KCNR and KCNR achieve better results than KCNR, because they consider the importance of the item’s original information and neighboring entities’ information. Based on KCNR, KCNR adds additional feature interaction between the item’s original information and the neighboring entities’ information, to supplement the information further. So it achieved better results. This also shows that the information disseminated in the KG is sensitive to the association between and v. It is also demonstrates that the rich semantic information in the KG can enhance user and item embedding representations and effectively improve the recommendation quality.
4.5. Influence of Different Modules
4.6. Experimental Parameter Analysis
4.6.1. Impact of Embedding Dimension
4.6.2. Impact of Item Perception Depth
4.6.3. Impact of Item Neighbor Sampling Size
4.6.4. Impact of the User’s Initial Entity Size
4.6.5. Impact of User Propagation Depth
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Cui, Z.; Xu, X.; Fei, X.; Cai, X.; Cao, Y.; Zhang, W.; Chen, J. Personalized recommendation system based on collaborative filtering for IoT scenarios. IEEE Trans. Serv. Comput. 2020, 13, 685–695. [Google Scholar] [CrossRef]
- Yu, X.; Jiang, F.; Du, J.; Gong, D. A cross-domain collaborative filtering algorithm with expanding user and item features via the latent factor space of auxiliary domains. Pattern Recognit. 2019, 94, 96–109. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, H. A deep graph neural network-based mechanism for social recommendations. IEEE Trans. Ind. Inform. 2020, 17, 2776–2783. [Google Scholar] [CrossRef]
- Yang, X.; Zhou, S.; Cao, M. An approach to alleviate the sparsity problem of hybrid collaborative filtering based recommendations: The product-attribute perspective from user reviews. Mob. Netw. Appl. 2020, 25, 376–390. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Qi, T.; Huang, Y. MM-Rec: Multimodal News Recommendation. arXiv 2021, arXiv:2104.07407. [Google Scholar]
- Zhu, Q.; Zhou, X.; Wu, J.; Tan, J.; Guo, L. A knowledge-aware attentional reasoning network for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6999–7006. [Google Scholar]
- Wang, X.; Wang, D.; Xu, C.; He, X.; Cao, Y.; Chua, T.S. Explainable reasoning over knowledge graphs for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; Volume 33, pp. 5329–5336. [Google Scholar]
- Shi, C.; Hu, B.; Zhao, W.X.; Philip, S.Y. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide WEB Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized entity recommendation: A heterogeneous information network approach. In Proceedings of the 7th ACM international Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 283–292. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Wang, H.; Zhang, F.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Multi-task feature learning for knowledge graph enhanced recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2000–2010. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 2020, 34, 3549–3568. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Wu, Y.; Yang, Y. Analogical inference for multi-relational embeddings. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2168–2178. [Google Scholar]
- Huang, J.; Zhao, W.X.; Dou, H.; Wen, J.R.; Chang, E.Y. Improving sequential recommendation with knowledge-enhanced memory networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 505–514. [Google Scholar]
- Yu, X.; Ren, X.; Sun, Y.; Sturt, B.; Khandelwal, U.; Gu, Q.; Norick, B.; Han, J. Recommendation in heterogeneous information networks with implicit user feedback. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 347–350. [Google Scholar]
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-graph based recommendation fusion over heterogeneous information networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 635–644. [Google Scholar]
- Hu, B.; Shi, C.; Zhao, W.X.; Yu, P.S. Leveraging meta-path based context for top-n recommendation with a neural co-attention model. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1531–1540. [Google Scholar]
- Qu, Y.; Bai, T.; Zhang, W.; Nie, J.; Tang, J. An end-to-end neighborhood-based interaction model for knowledge-enhanced recommendation. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, Anchorage, AK, USA, 5 August 2019; pp. 1–9. [Google Scholar]
- Wang, Z.; Lin, G.; Tan, H.; Chen, Q.; Liu, X. CKAN: Collaborative knowledge-aware attentive network for recommender systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 August 2020; pp. 219–228. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Memisevic, R.; Zach, C.; Pollefeys, M.; Hinton, G.E. Gated softmax classification. Adv. Neural Inf. Process. Syst. 2010, 23, 1603–1611. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1024–1034. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Rendle, S. Factorization machines with libfm. ACM Trans. Intell. Syst. Technol. 2012, 3, 1–22. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Wu, L.; Chen, L.; Shao, P.; Hong, R.; Wang, X.; Wang, M. Learning fair representations for recommendation: A graph-based perspective. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2198–2208. [Google Scholar]
- Huang, W.; Wu, J.; Song, W.; Wang, Z. Cross attention fusion for knowledge graph optimized recommendation. Appl. Intell. 2022, 52, 10297–10306. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
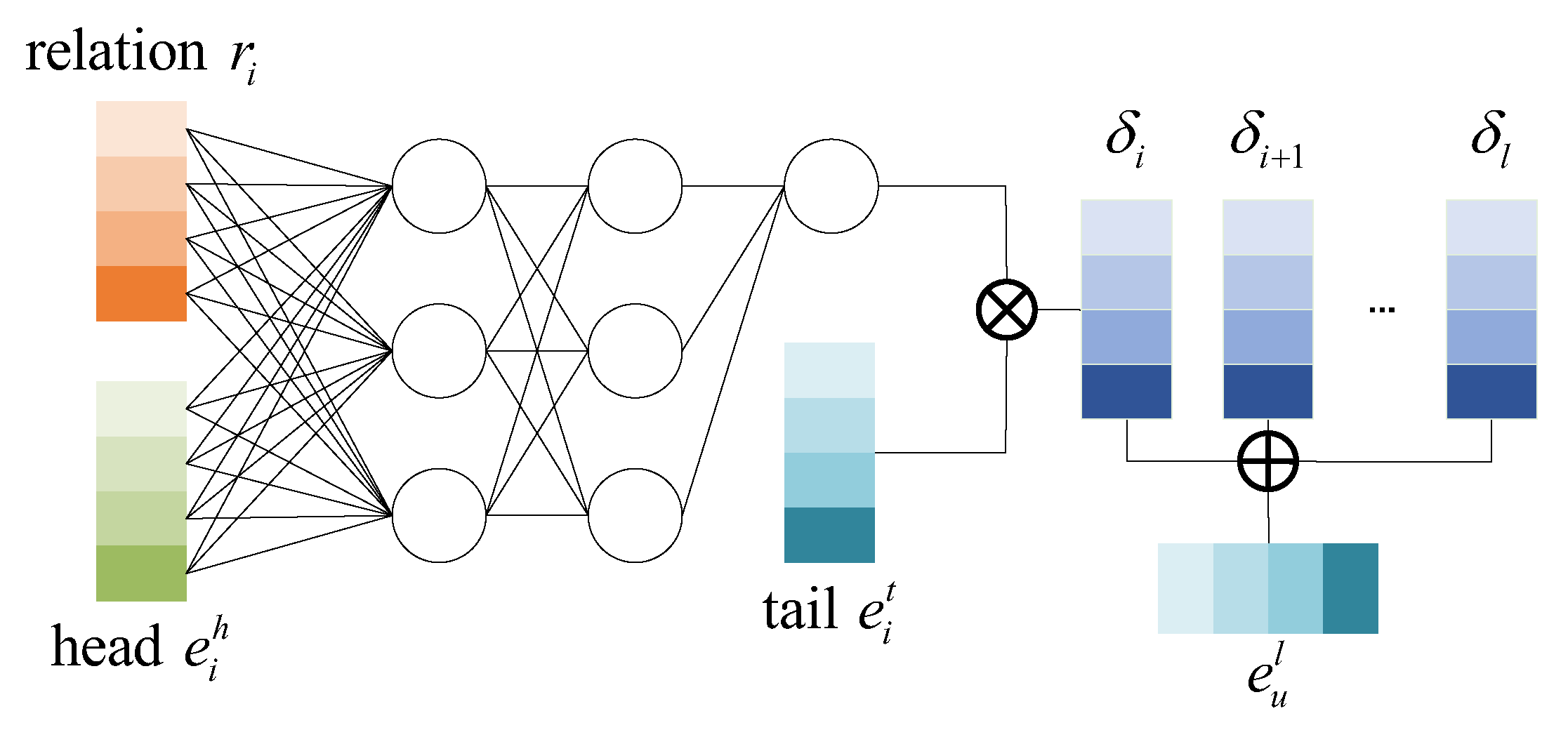{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MovieLens-1M | Book-Crossing | Last.FM | |
|---|---|---|---|
| #users | 6036 | 17,860 | 1872 |
| #items | 2445 | 14,910 | 3846 |
| #inter. | 753,772 | 139,746 | 42,346 |
| #entity | 182,011 | 77,903 | 9366 |
| #relation | 2,483,990 | 303,000 | 31,036 |
| #triplets | 20,195 | 19,793 | 15,518 |
| #sparsity | 0.9489 | 0.9994 | 0.9941 |
| Dataset | Parameters |
|---|---|
| MovieLens-1M | |
| Book-Crossing | |
| Last.FM |
| Model | MovieLens-1M | Book-Crossing | Last.FM | |||
|---|---|---|---|---|---|---|
| AUC | F1 | AUC | F1 | AUC | F1 | |
| LibFM | 0.892 | 0.763 | 0.685 | 0.618 | 0.777 | 0.710 |
| PER | 0.706 | 0.639 | 0.624 | 0.562 | 0.632 | 0.596 |
| CKE | 0.801 | 0.703 | 0.671 | 0.611 | 0.744 | 0.673 |
| Wide&Deep | 0.898 | 0.791 | 0.712 | 0.645 | 0.756 | 0.654 |
| RippleNet | 0.912 | 0.812 | 0.725 | 0.650 | 0.766 | 0.702 |
| MKR | 0.911 | 0.838 | 0.727 | 0.665 | 0.795 | 0.729 |
| KGCN | 0.908 | 0.834 | 0.690 | 0.634 | 0.798 | 0.718 |
| FairGo | 0.907 | 0.838 | 0.716 | 0.661 | 0.796 | 0.700 |
| CAKR | 0.919 | 0.844 | 0.744 | 0.648 | 0.800 | 0.725 |
| KCNR | 0.926 | 0.852 | 0.750 | 0.666 | 0.811 | 0.732 |
| KCNR | 0.926 | 0.851 | 0.743 | 0.661 | 0.808 | 0.732 |
| KCNR | 0.925 | 0.851 | 0.741 | 0.662 | 0.805 | 0.734 |
| KCNR | 0.924 | 0.851 | 0.738 | 0.654 | 0.805 | 0.734 |
| d | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|
| MovieLens-1M | 0.918 | 0.924 | 0.925 | 0.926 | 0.925 | 0.922 |
| Book-Crossing | 0.743 | 0.744 | 0.750 | 0.742 | 0.743 | 0.738 |
| Last.FM | 0.811 | 0.808 | 0.808 | 0.807 | 0.806 | 0.803 |
| h | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| MovieLens-1M | 0.924 | 0.926 | 0.923 | 0.923 |
| Book-Crossing | 0.742 | 0.750 | 0.740 | 0.735 |
| Last.FM | 0.807 | 0.808 | 0.811 | 0.806 |
| K | 2 | 4 | 6 | 8 | 16 | 32 |
|---|---|---|---|---|---|---|
| MovieLens-1M | 0.923 | 0.923 | 0.926 | 0.924 | 0.923 | 0.923 |
| Book-Crossing | 0.750 | 0.744 | 0.743 | 0.743 | 0.742 | 0.734 |
| Last.FM | 0.805 | 0.807 | 0.808 | 0.811 | 0.808 | 0.807 |
| s | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|
| MovieLens-1M | 0.906 | 0.910 | 0.916 | 0.920 | 0.926 |
| Book-Crossing | 0.743 | 0.750 | 0.744 | 0.743 | 0.739 |
| Last.FM | 0.808 | 0.809 | 0.811 | 0.807 | 0.807 |
| l | 1 | 2 | 3 |
|---|---|---|---|
| MovieLens-1M | 0.924 | 0.926 | 0.922 |
| Book-Crossing | 0.743 | 0.744 | 0.750 |
| Last.FM | 0.811 | 0.808 | 0.805 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Qin, J.; Deng, S.; Zeng, W. Knowledge-Aware Enhanced Network Combining Neighborhood Information for Recommendations. Appl. Sci. 2023, 13, 4577. https://doi.org/10.3390/app13074577
Wang X, Qin J, Deng S, Zeng W. Knowledge-Aware Enhanced Network Combining Neighborhood Information for Recommendations. Applied Sciences. 2023; 13(7):4577. https://doi.org/10.3390/app13074577
Chicago/Turabian StyleWang, Xiaole, Jiwei Qin, Shangju Deng, and Wei Zeng. 2023. "Knowledge-Aware Enhanced Network Combining Neighborhood Information for Recommendations" Applied Sciences 13, no. 7: 4577. https://doi.org/10.3390/app13074577