1. Introduction
In the last decade, the rise of bot accounts has filled the ecosystem of social network websites with fake news and misinformation [
1,
2]. The problem with the involvement of such accounts in different world events has consequences in real life [
3]. For example, the COVID-19 pandemic witnessed the role of bots in spreading misinformation [
4]. Additionally, social bot accounts are involved in increasing polarization between different parties in elections worldwide [
5,
6]. The impacts of bot accounts are not limited to political events, but also affect financial [
7] and health-related [
8] events, in addition to others.
Bot designs increasingly adapt to the changes that social networks put in place. For example, Twitter has updated its rules to eliminate automation behavior from its users [
9,
10]. Despite these rules, bots work in an orchestrated manner to avoid being detected [
11]. Therefore, it is important to reveal such hidden relationships between botnet members using graph neural networks, as they have proven to be successful at extracting such hidden information.
Since the beginning of social network platforms, researchers have recognized these accounts as sources of spam and viruses [
12,
13,
14]. An increasing amount of research has been conducted using machine learning algorithms after the increased use of these accounts to inflate the social networks [
2,
15]. Due to the lack of sufficient labeled data, including sufficiently large samples of bots, supervised learning algorithms are unable to keep up with the rapidly developing feature sets and behaviors of modern bots. The performance of any algorithm generally depends on the quality of the training sample. If such an algorithm obtains a low generalization error on a large subset of training data, it does not provide sufficient evidence that the function is learnable. For this reason, we specify that the algorithm must be adaptable to a wide variety of training datasets in order to be considered learnable. A function is learnable if there is an algorithm that, with a high probability, yields a good generalization error when trained on a randomly selected training set.
One of the popular theoretical definitions of learnability is PAC learnability. PAC (probably approximately correct) learning is a mathematical analytical framework [
16]. A PAC learner attempts to learn a concept (about correct) by selecting a hypothesis with a low generalization error from a set of hypotheses. In the context of machine learning, a problem is PAC-learnable if there exists an algorithm A that, given some independently drawn samples, would provide a hypothesis with a small error and a high probability for any distribution D and any concept C. It may not be possible to develop a perfect hypothesis with zero error; thus, the objective is to find a consistent hypothesis that can make approximately accurate predictions with an error upper bound.
As a consequence, detecting social bots in a stream-based manner is essential to mitigating their impact within a short period. In this paper, we propose a stream-based evolving bot detection framework (SEBD). Our framework was built using “following” links and a few profile features to identify bot accounts in a stream-based manner, using our trained model in [
17] and the setup outlined in [
18]. The following links are defined when account A follows account B. In [
17], the model was built using a multi-view graph attention network via a transfer learning approach using both following links and interaction links. The model was able to achieve an accuracy score of 97.8%, an F1 score of 0.9842, and an MCC score of 0.9481. The graph attention mechanism with multi-view was able to reveal the hidden representations of nodes.
In SEBD, we used only fellowship links to reduce the complexity costs of online processing. Our goal was to examine the model’s ability to identify bot accounts in a stream environment and predict them correctly. The results were saved to perform offline evaluation. Then, a PAC learning framework was applied to ensure the confidence and accuracy levels of our framework, and generalize our model. This will maintain good classification rates, and lower the misclassification error for bot and human classes. Thus, we ensured that our model is adaptive to different training samples to perform the task of classifying Twitter accounts into humans and bots in a stream-based manner.
Our contributions are as follows:
We propose a stream-based evolving bot detection (SEBD) framework using multi-view graph attention networks, Apache Kafka, and the Twitter API.
We conducted a stream prediction phase and, then, apply PAC learnability in an offline phase to measure the accuracy and confidence levels of our model’s learning.
We evaluated SEBD via cross-domain evaluation methods using test holdout with cross-validation, a benchmark dataset, a baseline tool, and machine learning classifiers. We collected our data based on scenarios and hashtags with random training samples to ensure the generalization of our model.
The rest of this paper is organized as follows. Related work is presented in
Section 2. In
Section 3, we present the methodology.
Section 4 discusses the proposed framework results.
Section 5 highlights the remaining challenges in this domain and considers future directions for research efforts that aim to address this problem.
3. Methodology
3.1. SEBD Architecture and Framework Phases
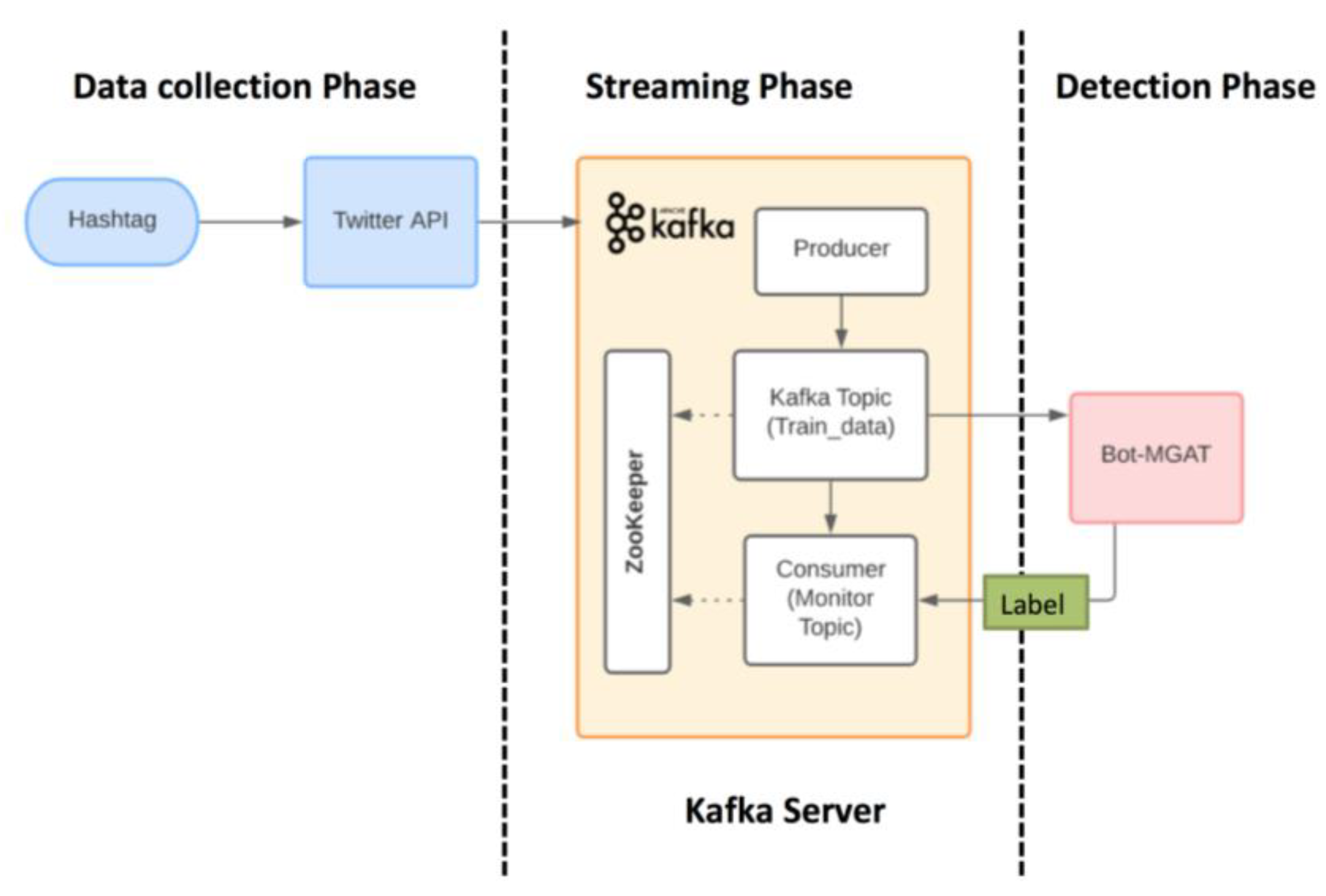
Figure 1 depicts the SEBD architecture. There are three phases for the framework. The first is the data collection phase. It starts by entering a hashtag to the Twitter API. The Twitter platform has developed an application-programming interface (API) to retrieve recent and popular tweets for research and development purposes. The API will fetch the required data about users’ accounts and filter the collected tweets using queries. Queries are keywords that help in retrieving the tweets of interest. From these tweets, we can collect different information regarding the owner of the tweet, the date of its creation, and any interactions that happen with it (replies, retweets, quoting, favorites, etc.) [
18].
The second phase is the streaming phase. We used Apache Kafka, which is an open-source, fault tolerant, and distributed publish–subscribe messaging system for handling stream data [
43]. It has been used by different popular social media platforms (Twitter and Netflix) due its scalability, manner of data distribution, and high availability [
44]. The main parts of the Apache Kafka server in the streaming phase are shown in
Figure 1. The collected data are sent to a Kafka topic through the Kafka producer.
The producer is responsible for publishing messages to Kafka topics. A Kafka topic is considered a container for storing messages and can comprise several partitions. Consumers subscribe to different topics and consume the messages by pulling them. Zookeeper software is used to manage and synchronize the information between different brokers (Kafka servers) in the Kafka cluster. On the other hand, Kafka consumers subscribe to topics and retrieve the relevant data.
In the last phase, the detection phase, we used our pre-trained model (Bot-MGAT) to predict the label of each account. These labels will be sent to another Kafka topic. A console consumer can be run on that topic to observe the labels in an online manner, as shown in Algorithm 1. Bot-MGAT is built using graph attention networks (GATs), which are a form of graph neural network in which nodes are assigned varying weights on the graph’s edges to reflect their relative significance. Self-attention is used to perform the weighting, which combines nodes’ and neighbors’ embeddings and applies a linear transformation [
45]. Multiple perspectives can be taken on the same set of nodes in a multi-view graph, which is a type of relational graph (or, technically, multiple graphs with the same nodes, but different edges). Bot-MGAT is a model that performs relation-wise self-attention. This means that an attention mechanism is applied to each view of the graph and the resultant nodes’ embeddings are combined to perform classification tasks [
22]. We trained Bot-MGAT using Twi-Bot20 [
46], a benchmark dataset that is recent and diverse.
| Algorithm 1: SEBD Framework. |
| #Data Collection Phase |
| Input to Twitter API: hashtag |
| Output user features Uf, follower edges Ufollower, following edges Ufollowing, follower features featfollower, following features featfollowing |
| | #Streaming Phase |
| 1 | If hashtag == ‘done’: |
| 2 | Data ← (Uf, Ufollower, Ufollowing, featfollower, featfollowing) |
| 3 | KafkaProducer.send (topic = ‘train_data’, value = Data) |
| 4 | Else: |
| 5 | Continue Data Collection Phase |
| | #Detection Phase |
| 6 | Message ← KafkaConsumer.poll (topic = ‘train_data’) |
| 7 | Proc_message ← pre_process (Message) |
| 8 | Model ← load_pretrained (Bot-MGAT) |
| 9 | Label ← Model (Proc_message) |
| 10 | KafkaProducer.send (topic = ‘monitor’, value = Label) |
| | #Result Monitoring |
| 11 | ConsoleConsumer.poll (topic = ‘monitor’) |
3.2. Data Acquisition and Preprocessing
The data collection process was performed over two different durations and time periods. We aimed to evaluate the performance of our model using two different groups of samples. The first sample group was used to evaluate the general performance in stream prediction using offline evaluation and a benchmark dataset. The second sample was used to evaluate the model confidence using PAC parameters to ensure learnability. The data were collected using the Twitter API.
For the first dataset collection (group 1) that took place during late September 2022, we chose 6 hashtags of different interests, as shown in
Table 1. For each hashtag, we collected information on 50 users. For each user, we extracted information on 10 followers and 10 followings (friends). This helped in constructing the follower–following relationship graph to which we would apply our model. The reason for choosing such a small dataset was the rate limit of the Twitter API, which causes it to wait for a certain period of time after several API requests (
https://developer.twitter.com/en/docs/twitter-api/rate-limits, accessed on 30 December 2022). The total estimated number of accounts was 6300
but we obtained data from 4705 accounts. This is because some of the accounts were either suspended (removed) or protected (you must follow them to retrieve their information).
For the second dataset collection (group 2), which took place on December 2022 and January 2023, we choose different scenarios to evaluate how the model was performing based on local or worldwide trends, the domain, used keywords, etc.
Table 2 shows a summary of the collected hashtags based on domain. We collected data for three trending hashtags/keywords based on specific locations to compare them to worldwide trends. The estimated number of accounts for each hashtag or keyword was
, except for the first three hashtags in
Table 2, for which the estimated number was
. These three hashtags/keywords were collected one after another; therefore, we decreased the number of accounts.
3.3. Selected Features
For each user, follower, and followed account, we extracted only the profile features. These profile features proved to be optimal in identifying social bot account [
17,
27,
47]. Thus, the goal of using fewer profile features, in addition to their performance, was to minimize the requirements for preprocessing and encoding, in order to speed up the learning process. This would reduce the memory space requirements and computational costs of stream prediction. Therefore, we selected 6 numerical features and 4 categorical features.
Numerical features: These profile features have numerical values. They are described below:
Follower count: the number of users who are following this user account.
Favorite count: the number of tweets a user has liked since the account creation date.
Status count: the total number of tweets and retweets issued by the user.
Friend count: the total number of accounts this user is following.
Age in days: the total number of days since the account was created as of the date of retrieving the data.
Screen name length: the total number of characters (digits) in the screen name.
Categorical features: These profile features have Boolean values. They are described below:
Verified: Indicates that the user has a verified account.
Default profile: A true value means that the user has not altered the theme or background of their profile.
Default profile image: A true value means that the user has not uploaded a profile image and the default image is used.
Geo enabled: A true value denotes that the current user attaches geographical data when tweeting or retweeting.
Before using these features, the numerical features were normalized to eliminate bias. For the categorical features, true values were converted to 1 and false values to 0.
3.4. Hashtag Selection Criteria
There are many factors that can impact a trending hashtag or keywords. For example, the domain of interest (political or sports) is one of the factors of a trending hashtag. Spatial information on the event of a trending hashtag was noted, as some trends remain trending for hours and end up in the worldwide trending list. Therefore, to evaluate how our model adapted to different hashtags based on location or trending status and domain, we used the following hashtag criteria to collect different hashtags:
Not trending and trending.
Trending in a specific location vs. worldwide.
In a specific domain vs. multiple domains at once.
An individual hashtag vs. a group of hashtags in a similar location and a similar domain.
Thus, using this variety of hashtag statuses/domains/locations, the expected performance of our model was determined. This would help to evaluate its performance with regard to PAC learning parameters to ensure the accuracy and confidence of our model.
5. Conclusions
In this paper, we propose a stream-based evolving bot detection framework (SEBD). Our framework is built based on graph attention networks that integrate multiple views of fellowship links. It integrates Apache Kafka and the Twitter API to predict whether the account should be labeled as bot or human in a stream-based manner. SEBD utilizes fellowship links with few profile features to classify account types in the stream. Using few profile features to detect social bots is supported by a recent study [
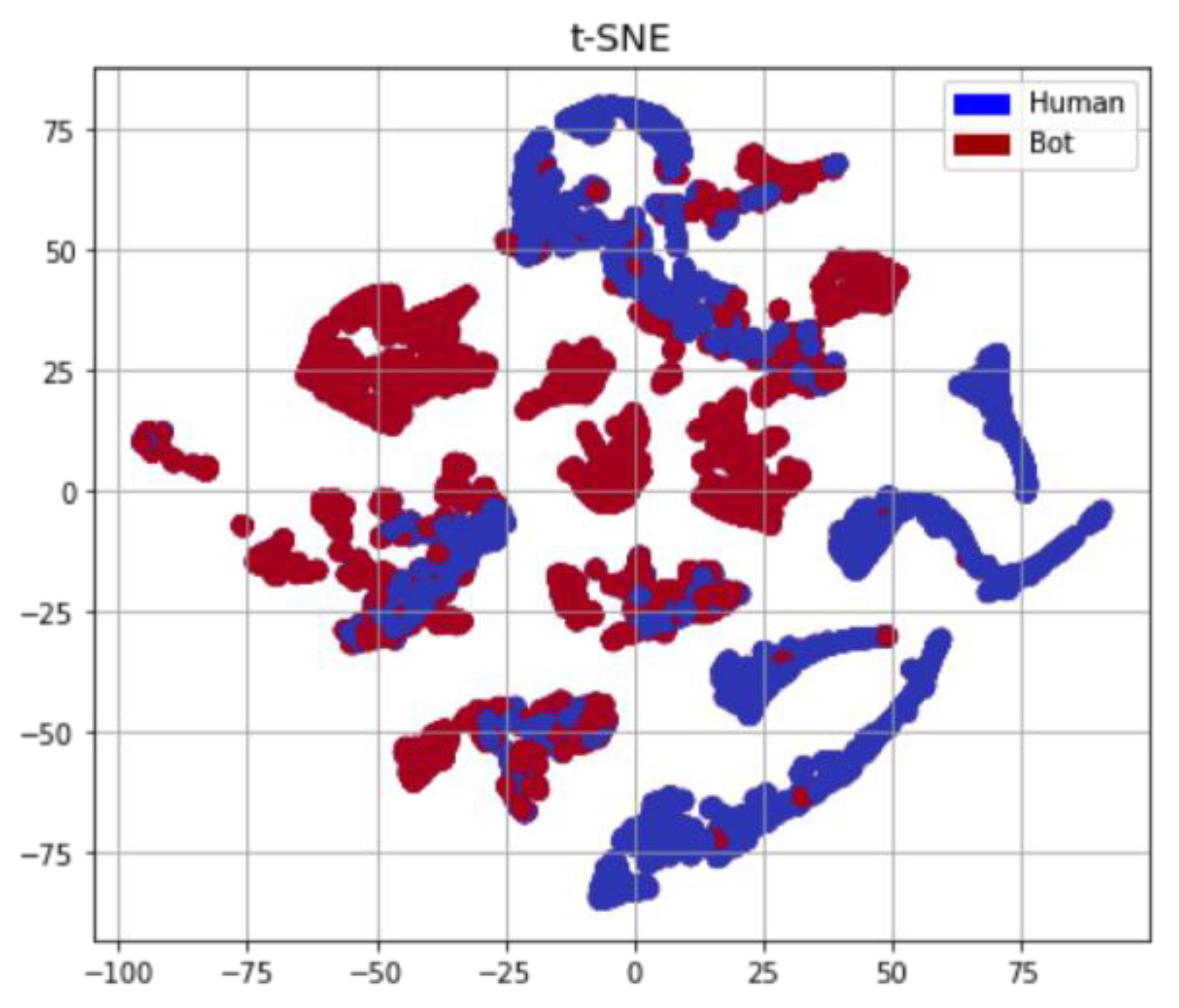
55]. Using such few profile features will decrease the computational costs of stream detection. It is obvious that detecting social bots in a stream-based way while evolving in hashtags is very effective. This is due to the fact that they work in an orchestrated manner as they are probably parts of botnets and they have similar features that make them distinguishable (see
Figure 7). Recent studies support that bot accounts are very active in hashtags [
56,
57,
58].
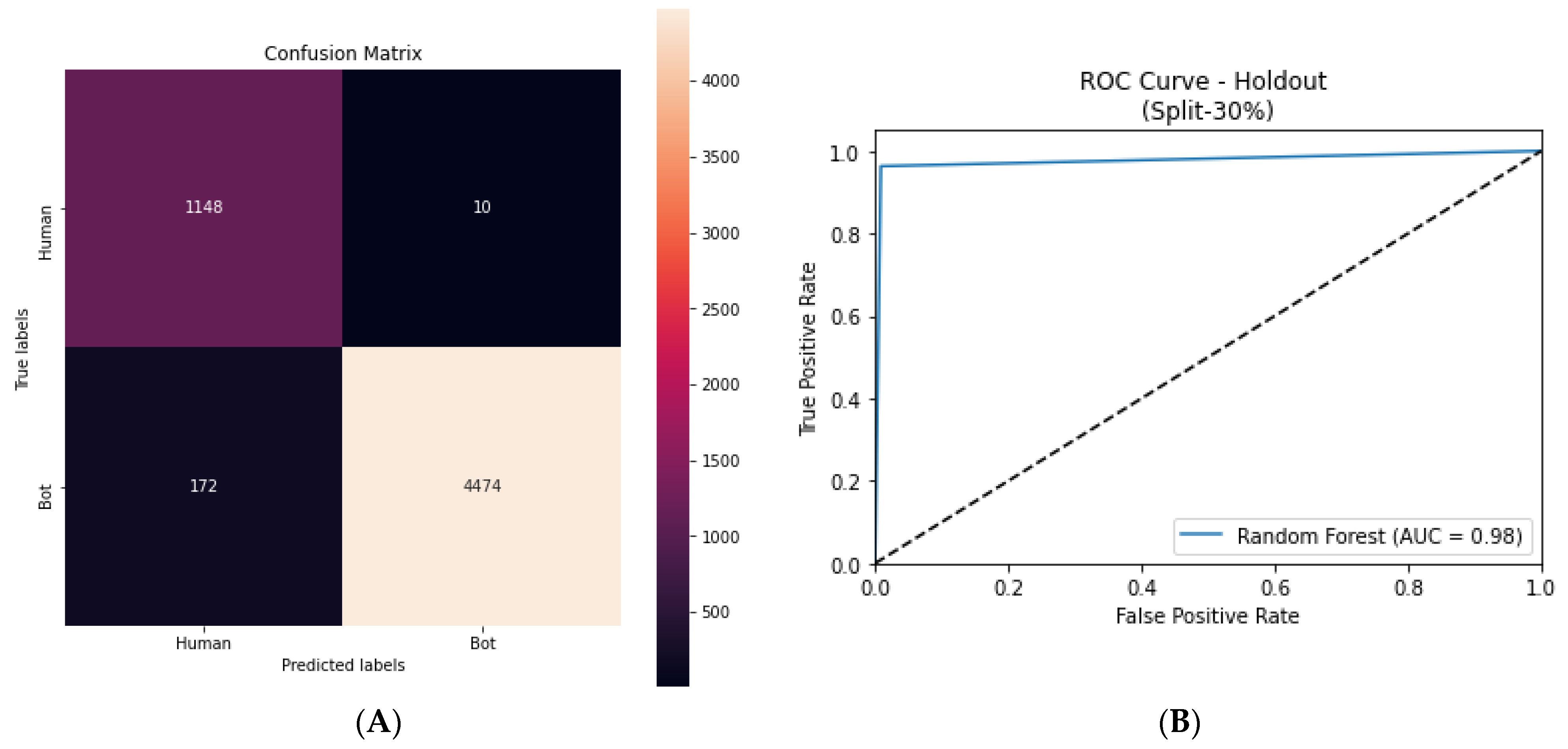
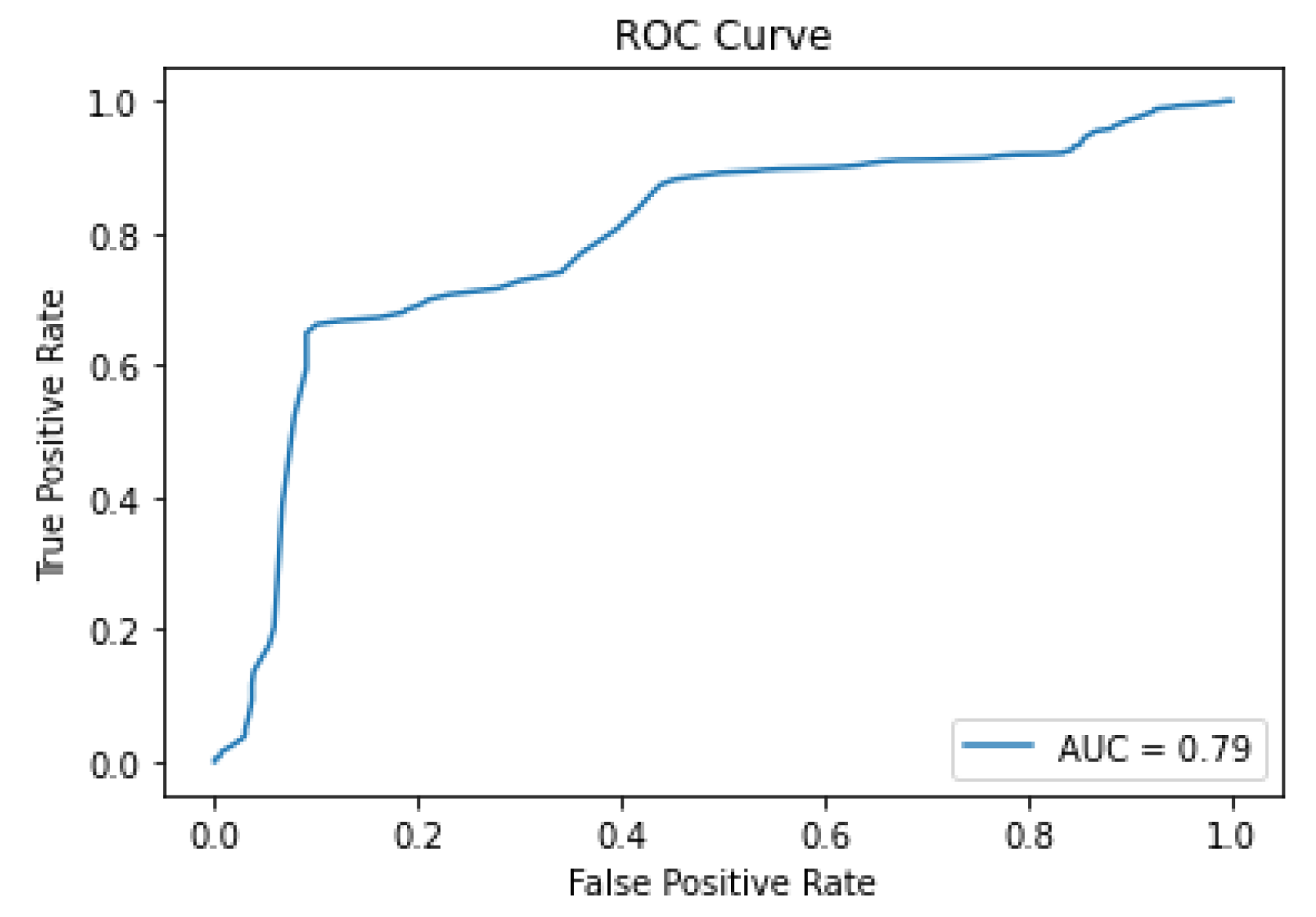
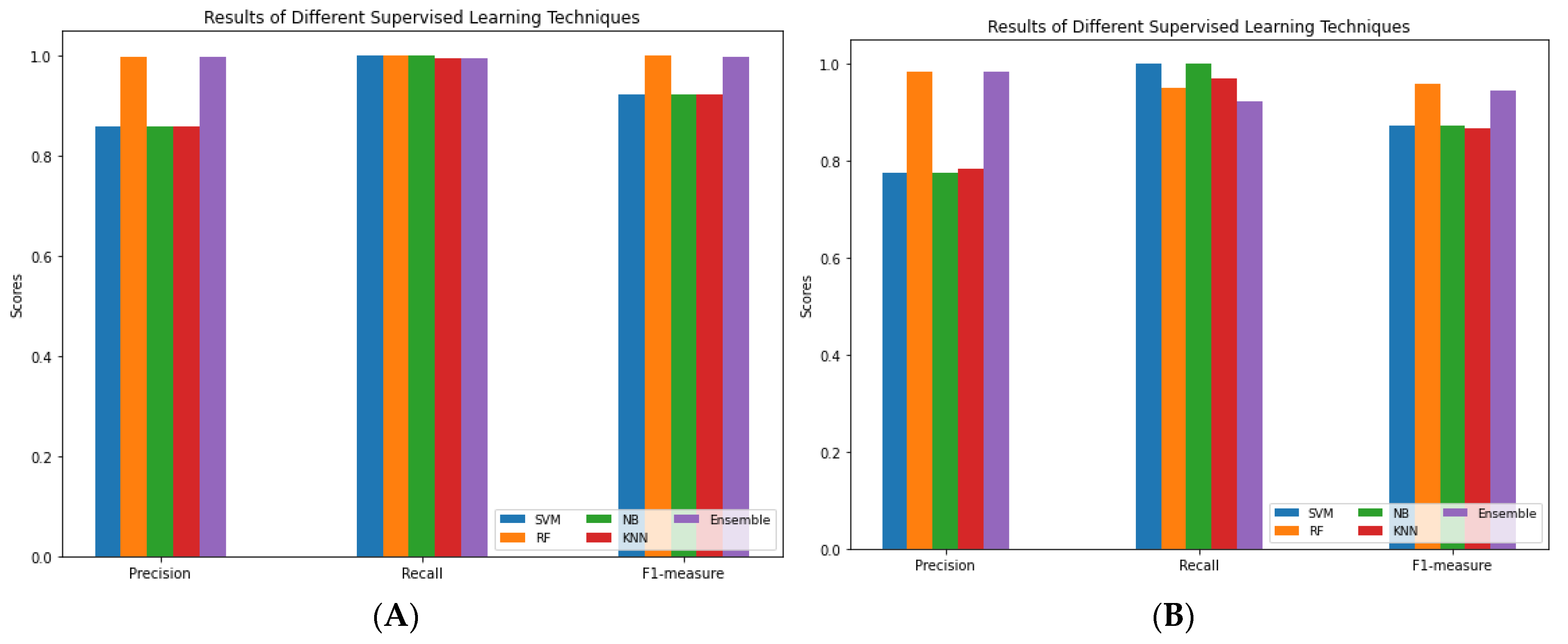
The multi-view graph attention network model has a more powerful representation of the data, allowing for better accuracy in predictions. The cross-domain evaluation of SEBD demonstrates its ability to effectively identify bot accounts using baseline comparison, a ground truth dataset and machine learning classifiers. SEBD achieved an AUC score of 0.98 using the holdout method and a mean F1 score of 0.96 using cross-validation for the trained model. The results obtained using a random forest classifier with a ground truth dataset support this finding. Additionally, SEBD was more successful in identifying bot accounts compared to the baseline tool. Random forest and ensemble classifiers perform well in the bot detection problem. The SEBD results show that bot accounts participate highly in hashtags on Twitter.
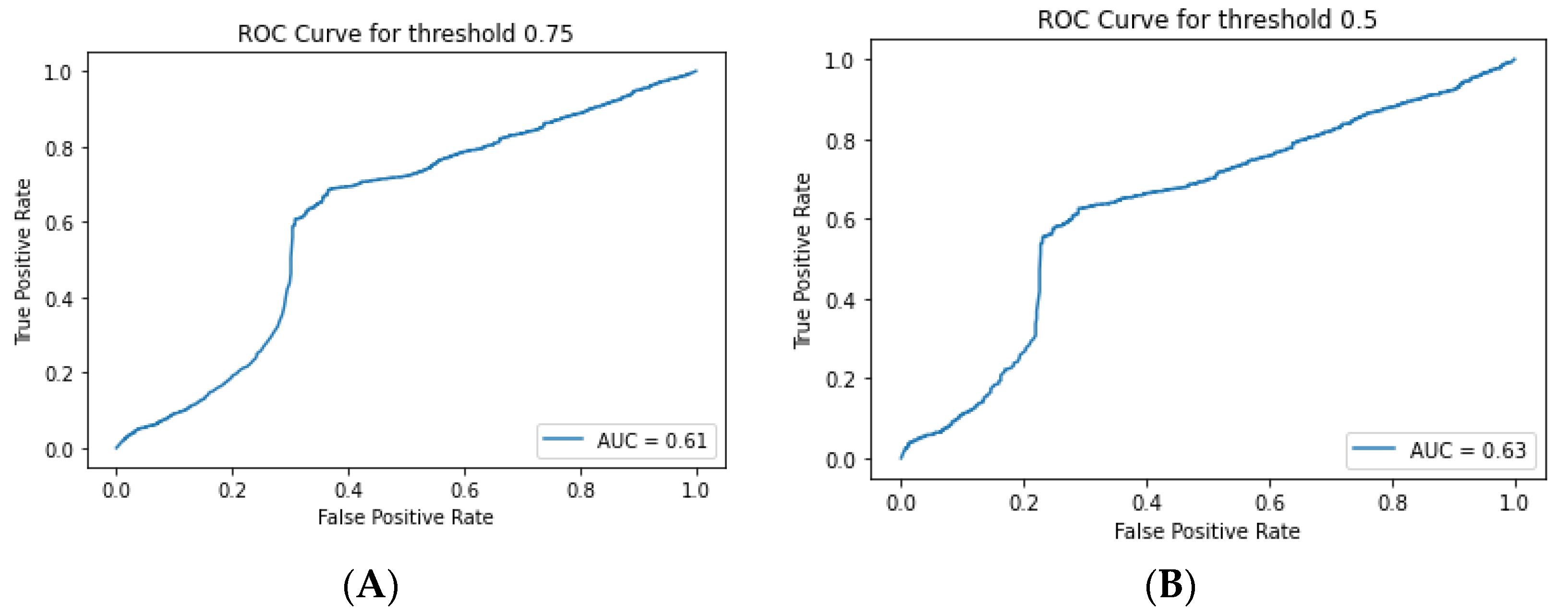
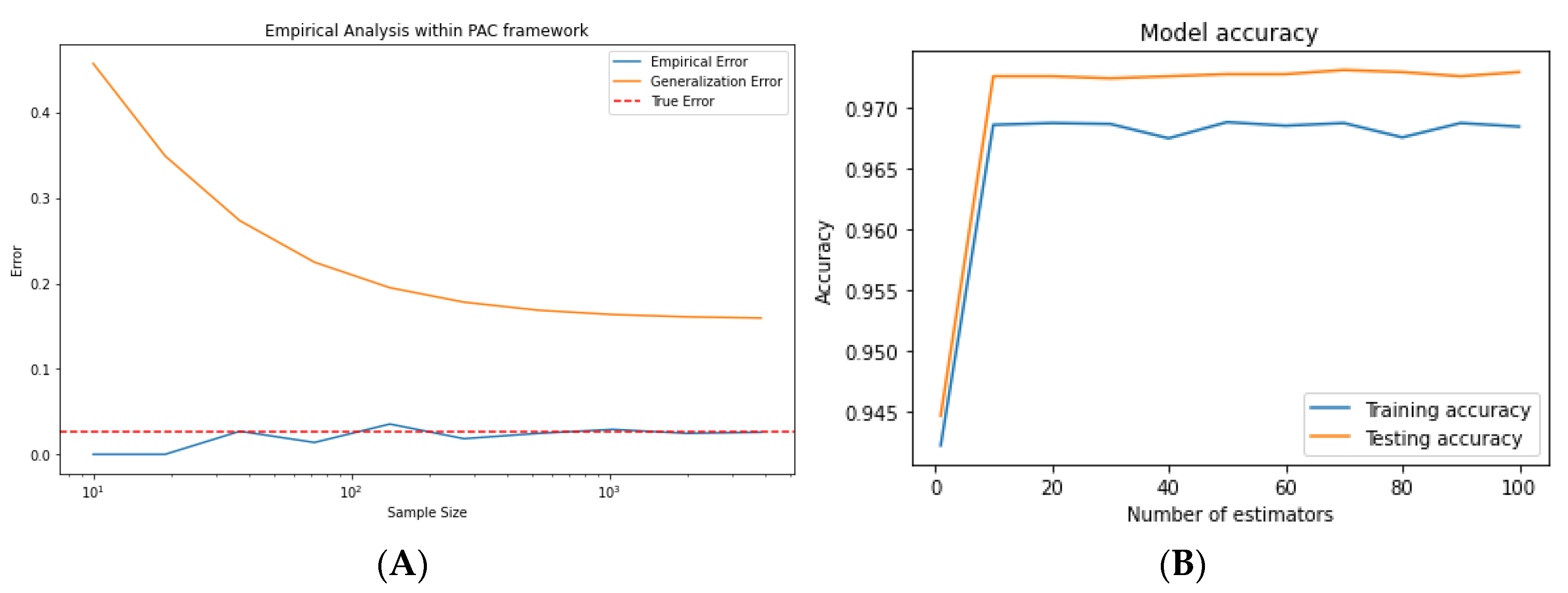
Furthermore, the SEBD results using the PAC learning framework indicate that our model meets the required accuracy and confidence levels in regard to the accuracy parameter (epsilon) and the confidence parameter (delta). The testing of different sample sizes shows that our results satisfy the PAC learning conditions for sample sizes > 2000 in terms of FNRs and FPRs. Additionally, the empirical error and true error show that the model is able to effectively generalize to unseen data.
Graph neural network models are powerful tools to extract hidden knowledge for classification tasks. Therefore, future studies should address looking for bot masters, as these bot accounts work as members of a botnet. In future work, SEBD will be examined using a trending hashtag (one active hashtag); an evaluation will be performed using one active hashtag over a longer period of time (e.g., days) to evaluate changes in predictions, and it will include concept drifts and window sliding.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}