
MFPCDR: A Meta-Learning-Based Model for Federated Personalized Cross-Domain Recommendation


Abstract
:1. Introduction
- (1)
- We propose MFPCDR, a federated personalized cross-domain recommendation model based on meta-learning that employs a federated learning technique to keep user data on the client computer in order to secure the user’s private data effectively.
- (2)
- We use meta-networks in the meta-recommendation module to learn personalized transferable embeddings of cold-start users, enabling personalized transfer of user preferences across domain recommendations to solve the user cold-start problem.
- (3)
- We used an attention mechanism in the local embedding module to mine the source domain for transferable features that contribute to knowledge transfer and better obtain item embeddings.
- (4)
- We conducted extensive experiments on real-world datasets to demonstrate the effectiveness of our approach in terms of recommendation performance and privacy preservation.
2. Related Work
2.1. Meta-Learning
2.2. Cross-Domain Recommendation
2.3. Federated Learning for Recommendation System
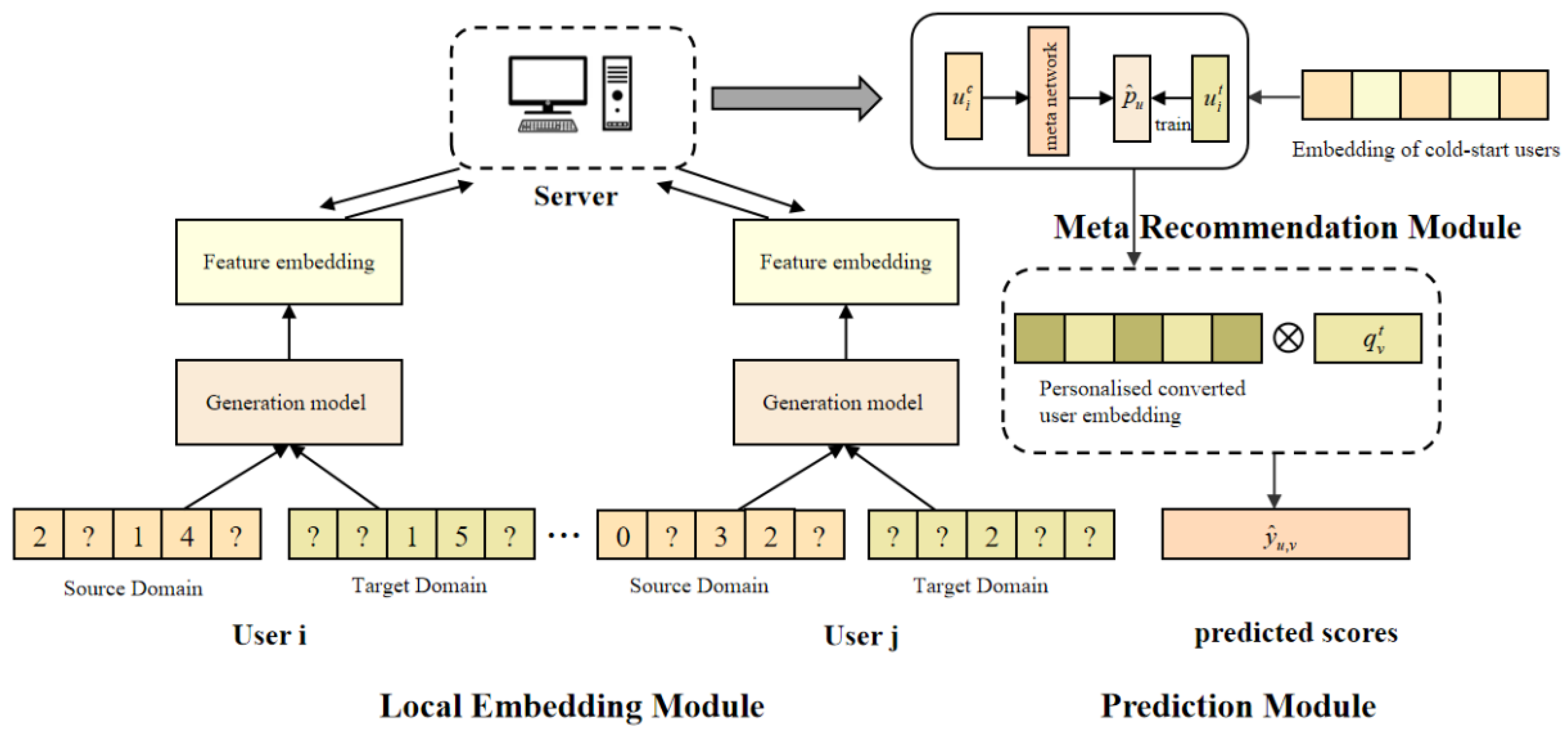
3. Model
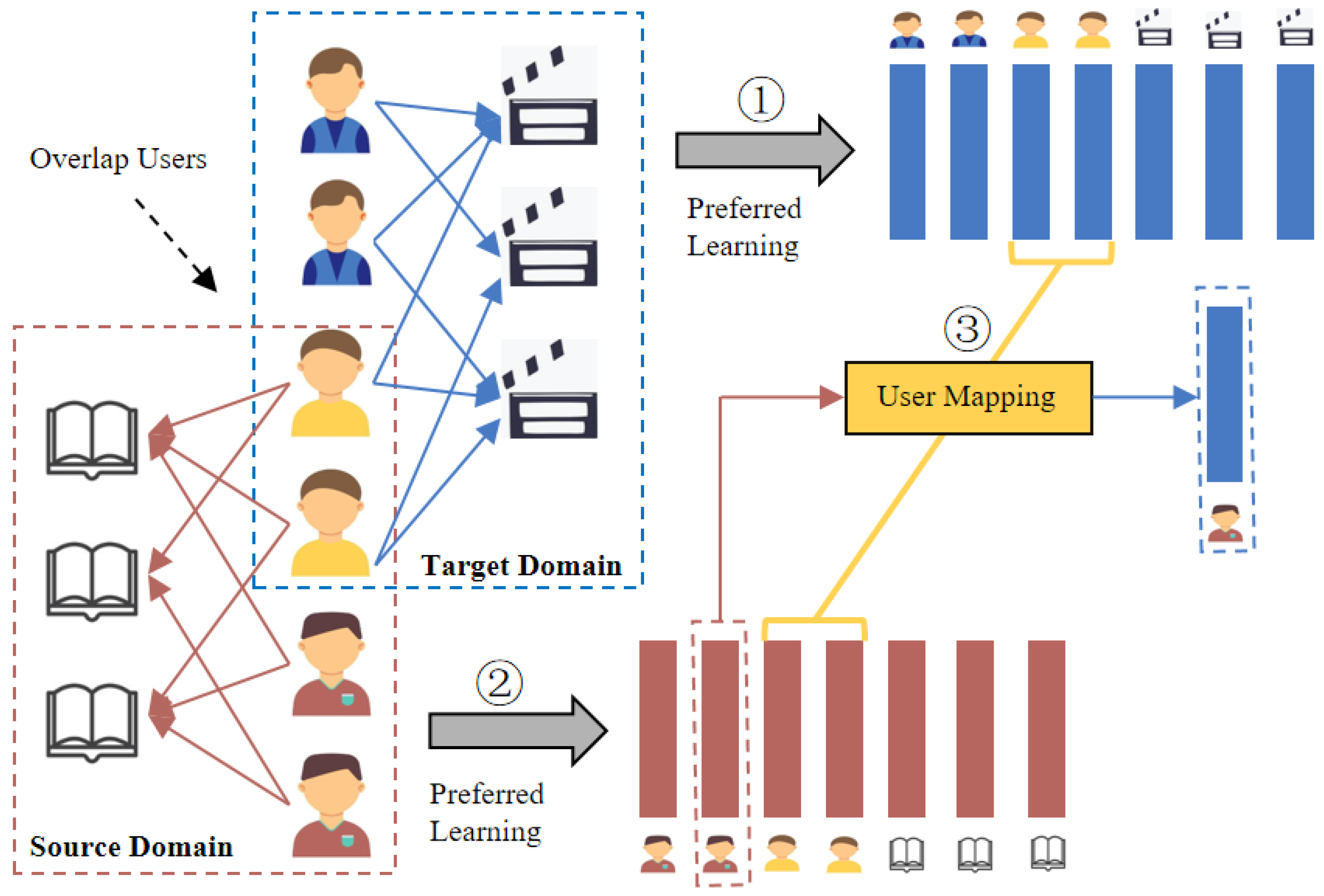
3.1. Problem Formulation
3.2. Local Embedding Module
3.3. Meta-Recommendation Module
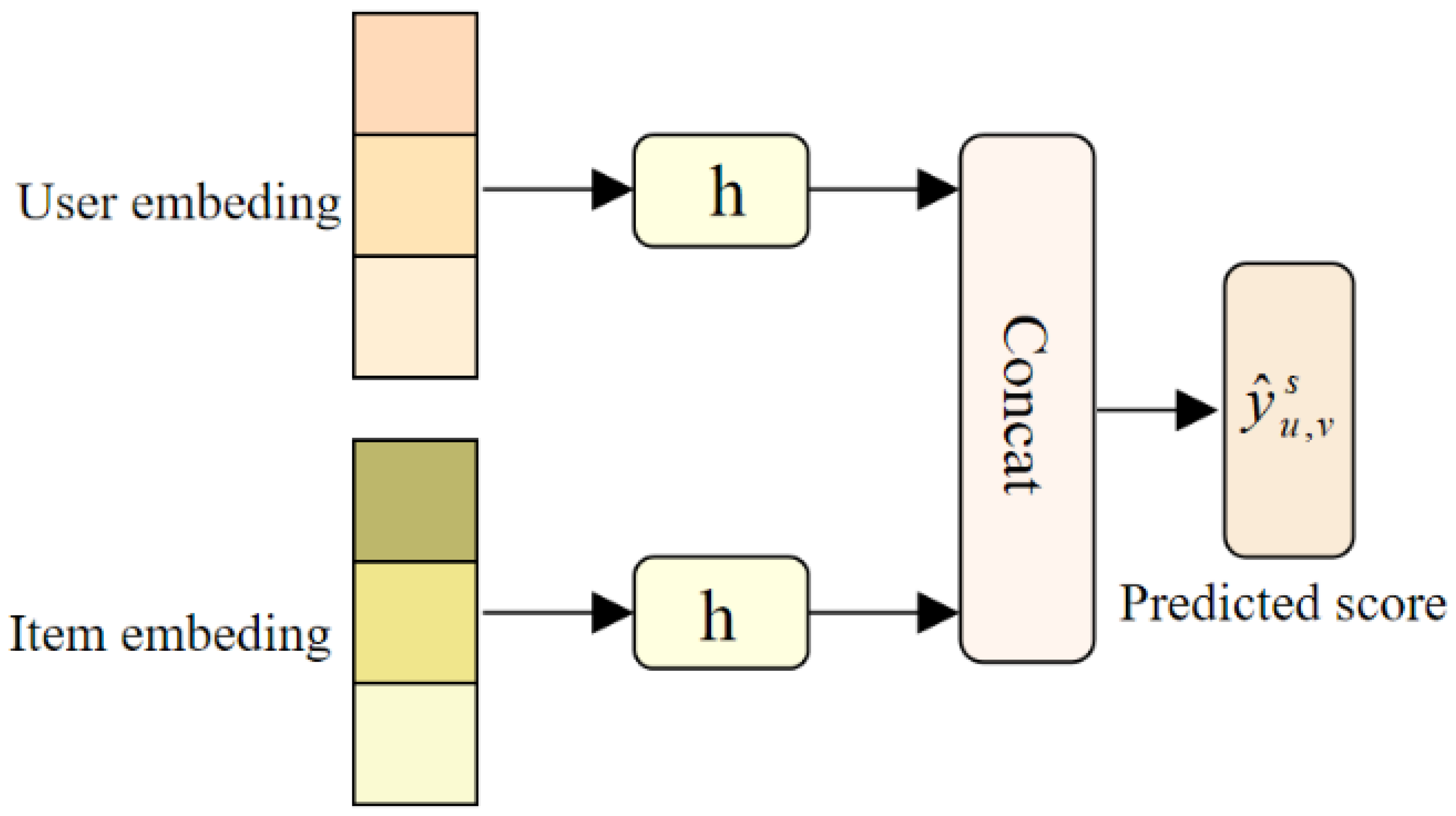
3.4. Prediction Module
3.5. Loss
3.6. Overall Procedure
| Algorithm 1: A meta-learning-based model for federated personalized cross-domain recommendation. |
| Input: |
| Output: |
| Local Embedding Module: |
|
|
| Meta-Recommendation Module: |
|
| Prediction Module: |
|
4. Experiments
4.1. Datasets
4.2. Baseline Methods
- CMF: A migration learning method that uses other relational data related to the predicted relationship to improve prediction performance when doing relational learning tasks.
- EMCDR: A framework for cross-domain mapping and recommendation that uses a multi-layer perceptron to capture non-linear mapping functions across domains, followed by the learning of mapping functions using entities with adequate data to enhance robustness.
- CDLFM [40]: The cross-domain latent feature mapping model takes into account the similarity link between users in terms of rating behavior and provides a matrix decomposition that includes user similarity and three similarity measures. A domain-based gradient boosting tree approach was used for cross-domain knowledge transfer. Mapping functions are learned for cold-start users utilizing latent attributes of users in the auxiliary domain with similar ratings to cold-start users.
- DFM [39]: A deep fusion model based on comments and content is utilized to preserve more semantic information by expanding the stacking noise reduction autoencoder and then transferring user latent factors across the two domains using a multi-layer perceptron.
- ANR [41]: A comprehensive aspect-based model that performs aspect-based representation learning on users and things using an attention-based component to describe the aspect process underlying the user’s evaluation strategy. After training the model on the target domain, related source domain comments are utilized to provide recommendations.
4.3. Experimental Setup
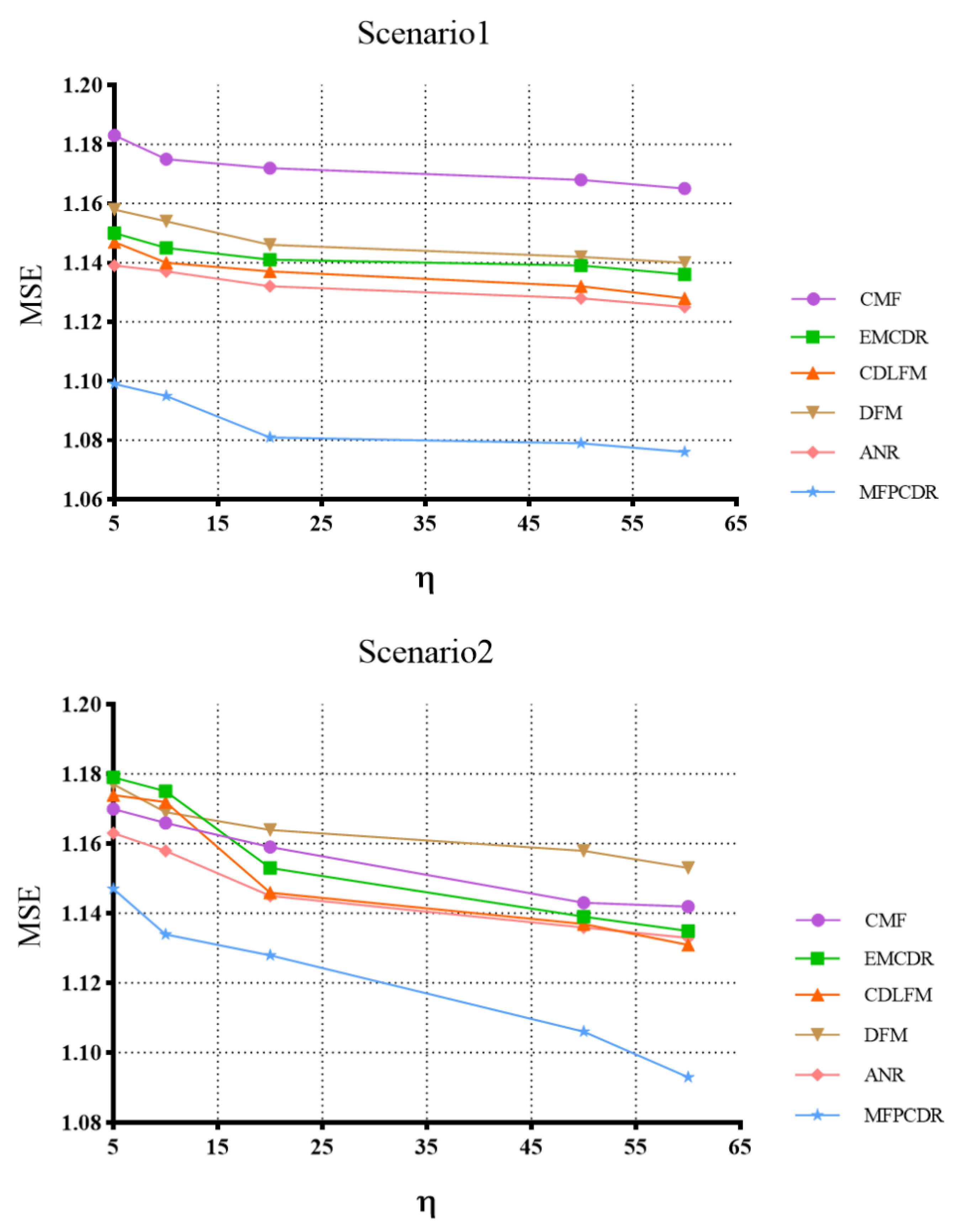
4.4. Model Comparison (RQ1 and RQ2)
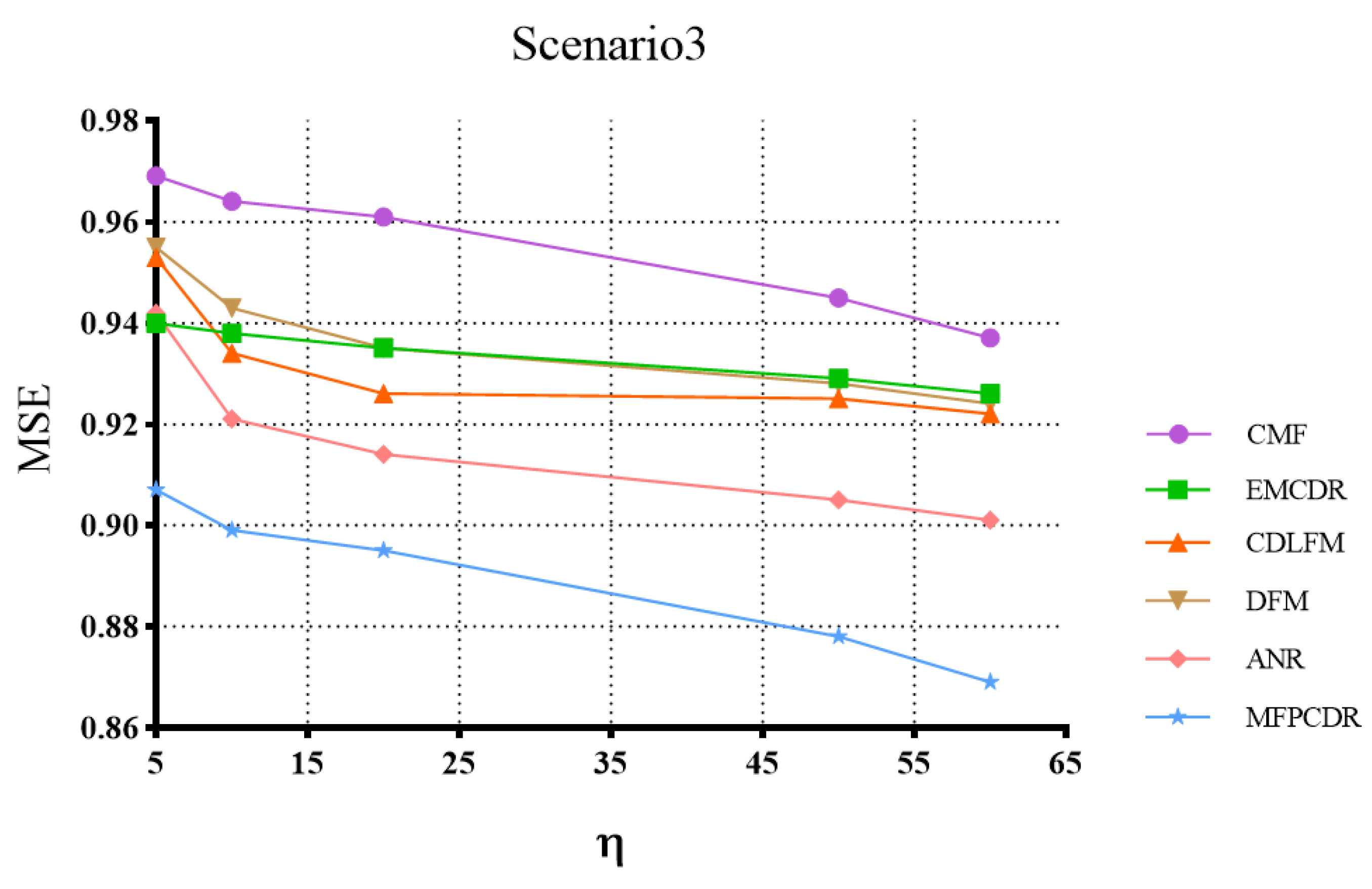
4.5. Impact of the Size of Overlapping Users (RQ3)
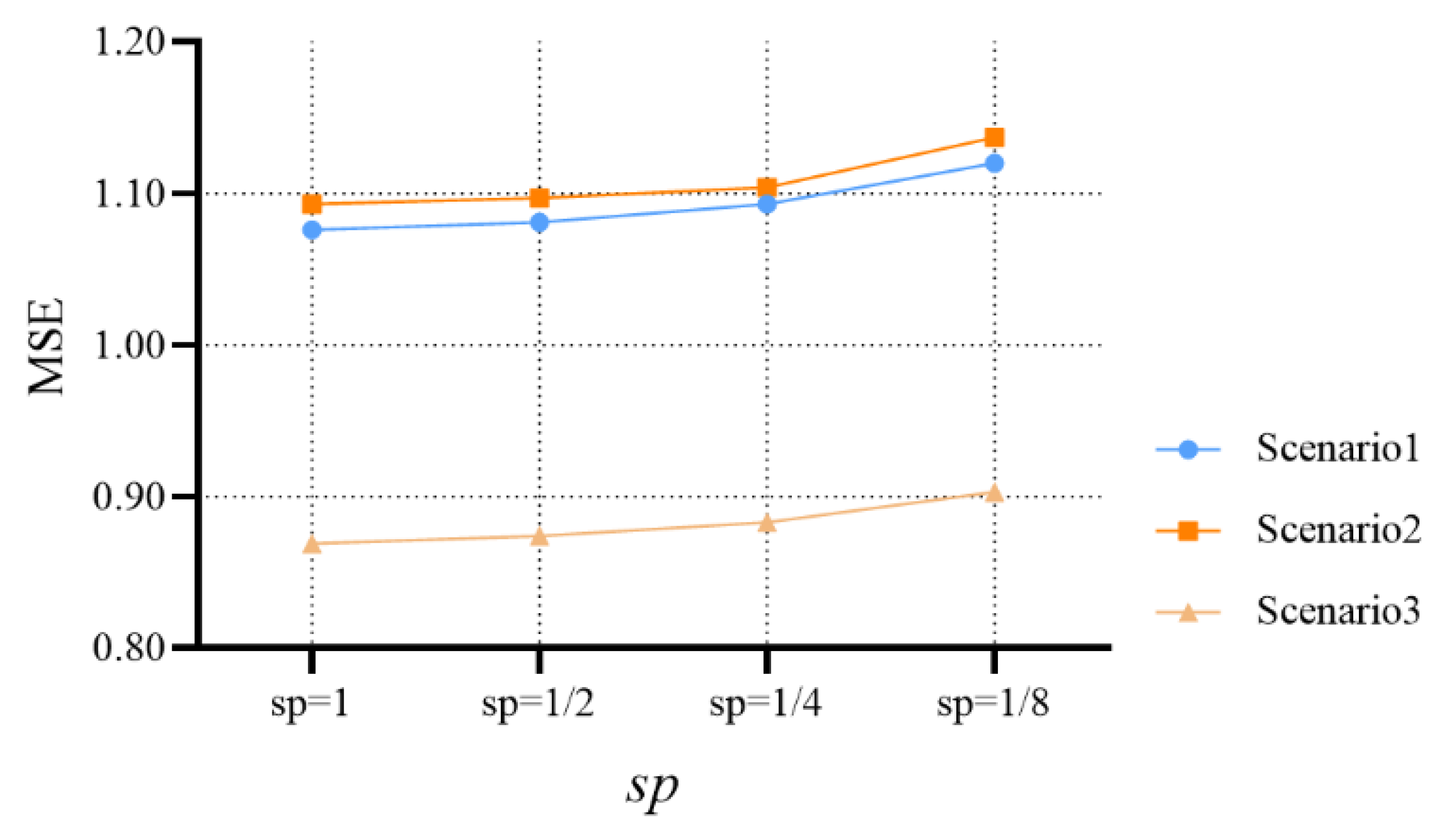
4.6. Effect of Source Domain Sparsity (RQ4)
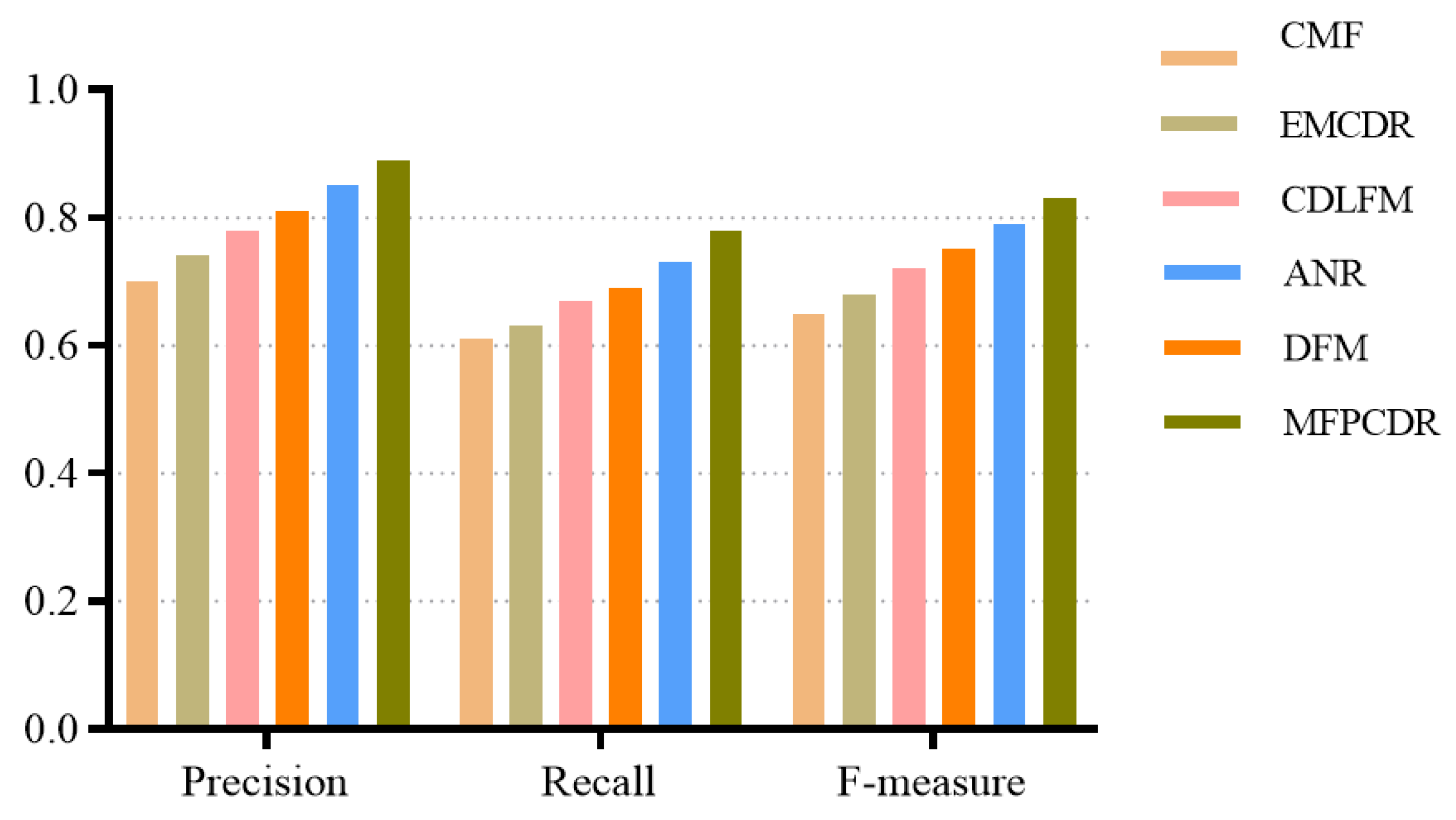
4.7. Classification Performance Evaluation of MFPCDR (RQ5)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soattoet, S. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10657–10665. [Google Scholar]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; De Freitas, N. Learning to learn by gradient descent by gradient descent. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; p. 29. [Google Scholar]
- Thrun, S.; Pratt, L. Learning to learn: Introduction and overview. In Learning to Learn; Springer: Boston, MA, USA, 1998; pp. 3–17. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; p. 29. [Google Scholar]
- Khodadadeh, S.; Boloni, L.; Shah, M. Unsupervised meta-learning for few-shot image classification. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; p. 32. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Meta-learning to detect rare objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9925–9934. [Google Scholar]
- Oreshkin, B.; Rodríguez López, P.; Lacoste, A. Tadam: Task dependent adaptive metric for improved few-shot learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; p. 31. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a Model for Few-Shot Learning; International Conference on Learning Representations; OpenReview: Amherst, MA, USA, 2016. [Google Scholar]
- Gordon, J.; Bronskill, J.; Bauer, M.; Nowozin, S.; Turner, R.E. Meta-learning probabilistic inference for prediction. arXiv 2018, arXiv:1805.09921. [Google Scholar]
- Zhang, Y.; Feng, F.; Wang, C.; He, X.; Wang, M.; Li, Y.; Zhang, Y. How to retrain recommender system? A sequential meta-learning method. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, China, 25–30 July 2020; pp. 1479–1488. [Google Scholar]
- Wei, T.; He, J. Comprehensive fair meta-learned recommender system. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 1989–1999. [Google Scholar]
- Zheng, Y.; Liu, S.; Li, Z.; Wu, S. Cold-start sequential recommendation via meta learner. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 35, pp. 4706–4713. [Google Scholar]
- Wang, S.; Yang, L.; Gong, J.; Zheng, S.; Du, S.; Liu, Z.; Philip, S.Y. MetaKRec: Collaborative Meta-Knowledge Enhanced Recommender System. arXiv 2022, arXiv:2211.07104. [Google Scholar]
- Singh, A.P.; Gordon, G.J. Relational learning via collective matrix factorization. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 650–658. [Google Scholar]
- Hu, G.; Zhang, Y.; Yang, Q. Conet: Collaborative cross networks for cross-domain recommendation. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 667–676. [Google Scholar]
- Darvishy, A.; Ibrahim, H.; Sidi, F.; Mustapha, A. HYPNER: A hybrid approach for personalized news recommendation. IEEE Access 2020, 8, 46877–46894. [Google Scholar] [CrossRef]
- Pan, W.; Xiang, E.; Liu, N.; Yang, Q. Transfer learning in collaborative filtering for sparsity reduction. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; Volume 24, pp. 230–235. [Google Scholar]
- Gulzar, Y.; Alwan, A.A.; Abdullah, R.M.; Abualkishik, A.Z.; Oumrani, M. OCA: Ordered Clustering-Based Algorithm for E-Commerce Recommendation System. Sustainability 2023, 15, 2947. [Google Scholar] [CrossRef]
- Man, T.; Shen, H.; Jin, X.; Cheng, X. Cross-domain recommendation: An embedding and mapping approach. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; Volume 17, pp. 2464–2470. [Google Scholar]
- Kang, S.; Hwang, J.; Lee, D.; Yu, H. Semi-supervised learning for cross-domain recommendation to cold-start users. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1563–1572. [Google Scholar]
- Zhao, C.; Li, C.; Xiao, R.; Deng, H.; Sun, A. CATN: Cross-domain recommendation for cold-start users via aspect transfer network. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, China, 25–30 July 2020; pp. 229–238. [Google Scholar]
- Drif, A.; Zerrad, H.E.; Cherifi, H. Ensvae: Ensemble variational autoencoders for recommendations. IEEE Access 2020, 8, 188335–188351. [Google Scholar] [CrossRef]
- Chen, C.; Wu, H.; Su, J.; Lyu, L.; Zheng, X.; Wang, L. Differential Private Knowledge Transfer for Privacy-Preserving Cross-Domain Recommendation. In Proceedings of the ACM Web Conference 2022, Virtual, France, 25–29 April 2022; pp. 1455–1465. [Google Scholar]
- Drif, A.; Zerrad, H.E.; Cherifi, H. Context-awareness in ensemble recommender system framework. In Proceedings of the 2021 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Kuala Lumpur, Malaysia, 12–13 June 2021; pp. 1–6. [Google Scholar]
- Zhu, Y.; Tang, Z.; Liu, Y.; Zhuang, F.; Xie, R.; Zhang, X.; Lin, L.; He, Q. Personalized transfer of user preferences for cross-domain recommendation. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1507–1515. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Ammad-Ud-Din, M.; Ivannikova, E.; Khan, S.A.; Oyomno, W.; Fu, Q.; Tan, K.E.; Flanagan, A. Federated collaborative filtering for privacy-preserving personalized recommendation system. arXiv 2019, arXiv:1901.09888. [Google Scholar]
- Lin, G.; Liang, F.; Pan, W.; Ming, Z. Fedrec: Federated recommendation with explicit feedback. IEEE Intell. Syst. 2020, 36, 21–30. [Google Scholar] [CrossRef]
- Liang, F.; Pan, W.; Ming, Z. Fedrec++: Lossless federated recommendation with explicit feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 4224–4231. [Google Scholar]
- Muhammad, K.; Wang, Q.; O’Reilly-Morgan, D.; Tragos, E.; Smyth, B.; Hurley, N.; Geraci, J.; Lawlor, A. Fedfast: Going beyond average for faster training of federated recommender systems. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, CA, USA, 6–10 July 2020; pp. 1234–1242. [Google Scholar]
- Lin, Y.; Ren, P.; Chen, Z.; Ren, Z.; Yu, D.; Ma, J.; Rijke, M.D.; Cheng, X. Meta matrix factorization for federated rating predictions. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, China, 25–30 July 2020; pp. 981–990. [Google Scholar]
- Yan, D.; Zhao, Y.; Yang, Z.; Jin, Y.; Zhang, Y. FedCDR: Privacy-preserving federated cross-domain recommendation. Digit. Commun. Netw. 2022, 8, 552–560. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- McMahan, E.B.; Moore, D.; Ramage, S.; Hampson, B.A.; Arcas, Y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Proceedings of Machine Learning Research, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.S. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv 2017, arXiv:1708.04617. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Fu, W.; Peng, Z.; Wang, S.; Xu, Y.; Li, J. Deeply Fusing Reviews and Contents for Cold Start Users in Cross-Domain Recommen-dation Systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 1–27 February 2019; Volume 33, pp. 94–101. [Google Scholar]
- Wang, X.; Peng, Z.; Wang, S.; Yu, P.S.; Fu, W.; Hong, X. Cross-domain recommendation for cold-start users via neighborhood based feature mapping. In International Conference on Database Systems for Advanced Applications; Springer: Cham, Switzerland, 2018; pp. 158–165. [Google Scholar]
- Chin, J.Y.; Zhao, K.; Joty, S.; Cong, G. ANR: Aspect-based neural recommender. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 147–156. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Domain | Dataset | Overlap Users | |||||
|---|---|---|---|---|---|---|---|---|
| Scenario 1 | S | Books | 6053 | 149 | 302 | 604 | 1517 | 1815 |
| T | Movies and TV | |||||||
| Scenario 2 | S | Movies and TV | 2839 | 67 | 135 | 276 | 673 | 803 |
| T | CDs and Vinyl | |||||||
| Scenario 3 | S | Books | 1692 | 38 | 81 | 160 | 412 | 487 |
| T | CDs and Vinyl |
| Scenario | Scenario 1 | Scenario 2 | Scenario 3 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Books Movies and TV | Movies and TV CDs and Vinyl | Books CDs and Vinyl | ||||||||||||||
| 5% | 10% | 20% | 50% | 60% | 5% | 10% | 20% | 50% | 60% | 5% | 10% | 20% | 50% | 60% | ||
| Methods | ||||||||||||||||
| CMF | 1.183 | 1.175 | 1.172 | 1.168 | 1.165 | 1.170 | 1.166 | 1.159 | 1.143 | 1.142 | 0.969 | 0.964 | 0.961 | 0.945 | 0.937 | |
| EMCDR | 1.150 | 1.145 | 1.141 | 1.139 | 1.136 | 1.179 | 1.175 | 1.153 | 1.139 | 1.135 | 0.940 | 0.938 | 0.935 | 0.929 | 0.926 | |
| CDLFM | 1.147 | 1.140 | 1.137 | 1.132 | 1.128 | 1.174 | 1.172 | 1.146 | 1.137 | 1.131 | 0.953 | 0.934 | 0.929 | 0.925 | 0.922 | |
| DFM | 1.158 | 1.154 | 1.146 | 1.142 | 1.140 | 1.177 | 1.169 | 1.164 | 1.158 | 1.153 | 0.955 | 0.943 | 0.935 | 0.928 | 0.924 | |
| ANR | 1.139 | 1.137 | 1.132 | 1.128 | 1.125 | 1.163 | 1.158 | 1.145 | 1.136 | 1.133 | 0.942 | 0.921 | 0.914 | 0.905 | 0.901 | |
| MFPCDR | 1.099 | 1.095 | 1.081 | 1.079 | 1.076 | 1.147 | 1.134 | 1.128 | 1.106 | 1.093 | 0.907 | 0.899 | 0.895 | 0.878 | 0.869 | |
| Improve% | 3.51 | 3.69 | 4.50 | 4.34 | 4.35 | 1.37 | 2.07 | 1.48 | 2.64 | 3.53 | 3.71 | 2.38 | 2.07 | 2.98 | 3.55 | |
| Scenario | Books CDs and Vinyl | |||
|---|---|---|---|---|
| Index | Precision | Recall | F-Measure | |
| Methods | ||||
| CMF | 0.70 | 0.61 | 0.65 | |
| EMCDR | 0.74 | 0.63 | 0.68 | |
| CDLFM | 0.78 | 0.67 | 0.72 | |
| DFM | 0.81 | 0.69 | 0.75 | |
| ANR | 0.85 | 0.73 | 0.79 | |
| MFPCDR | 0.89 | 0.78 | 0.83 | |
| Improve% | 4.7% | 5.4% | 5.0% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di, Y.; Liu, Y. MFPCDR: A Meta-Learning-Based Model for Federated Personalized Cross-Domain Recommendation. Appl. Sci. 2023, 13, 4407. https://doi.org/10.3390/app13074407
Di Y, Liu Y. MFPCDR: A Meta-Learning-Based Model for Federated Personalized Cross-Domain Recommendation. Applied Sciences. 2023; 13(7):4407. https://doi.org/10.3390/app13074407
Chicago/Turabian StyleDi, Yicheng, and Yuan Liu. 2023. "MFPCDR: A Meta-Learning-Based Model for Federated Personalized Cross-Domain Recommendation" Applied Sciences 13, no. 7: 4407. https://doi.org/10.3390/app13074407