
All-Digital Computing-in-Memory Macro Supporting FP64-Based Fused Multiply-Add Operation
Abstract
:1. Introduction
2. Overview
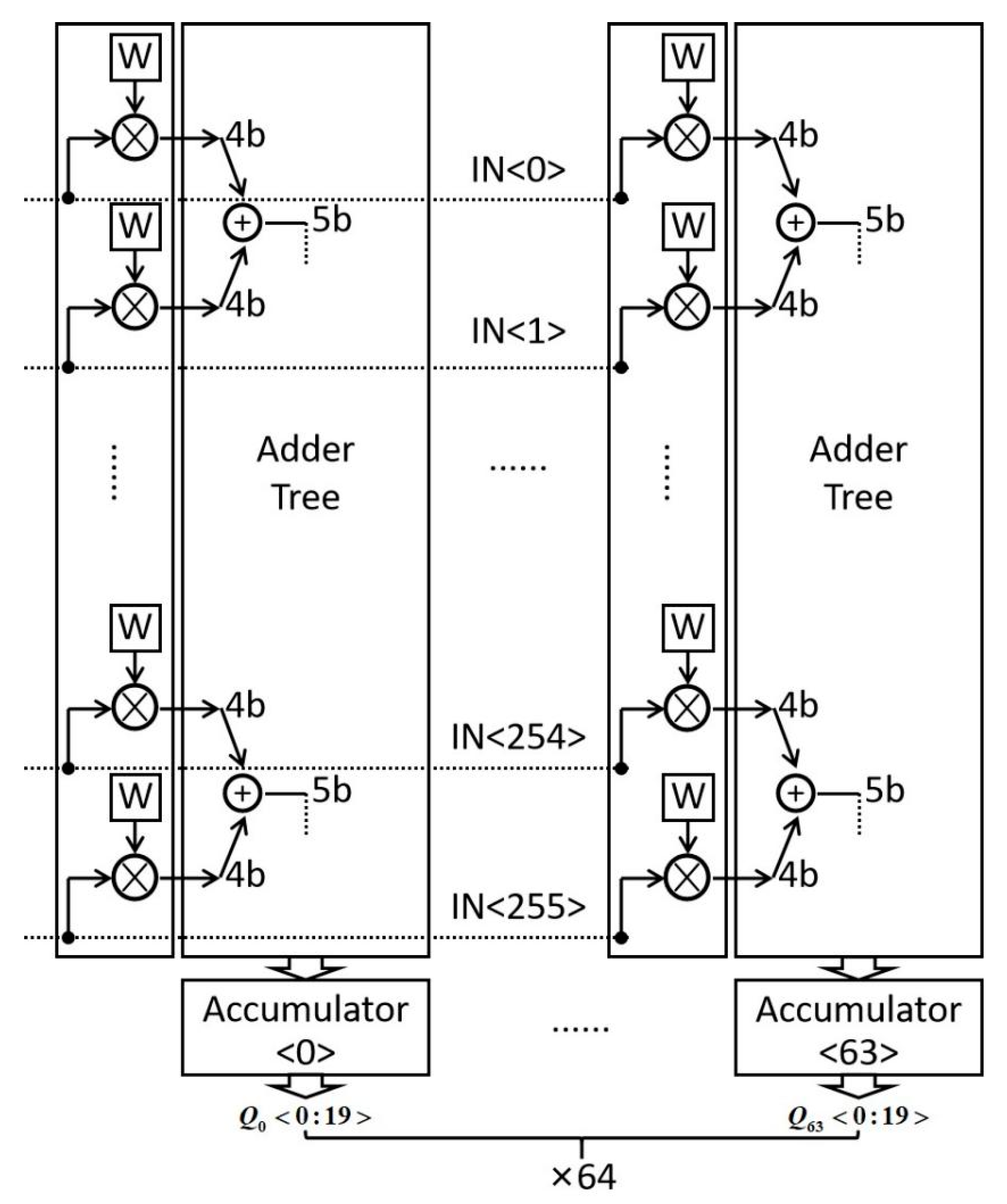
2.1. Digital CIM Macro
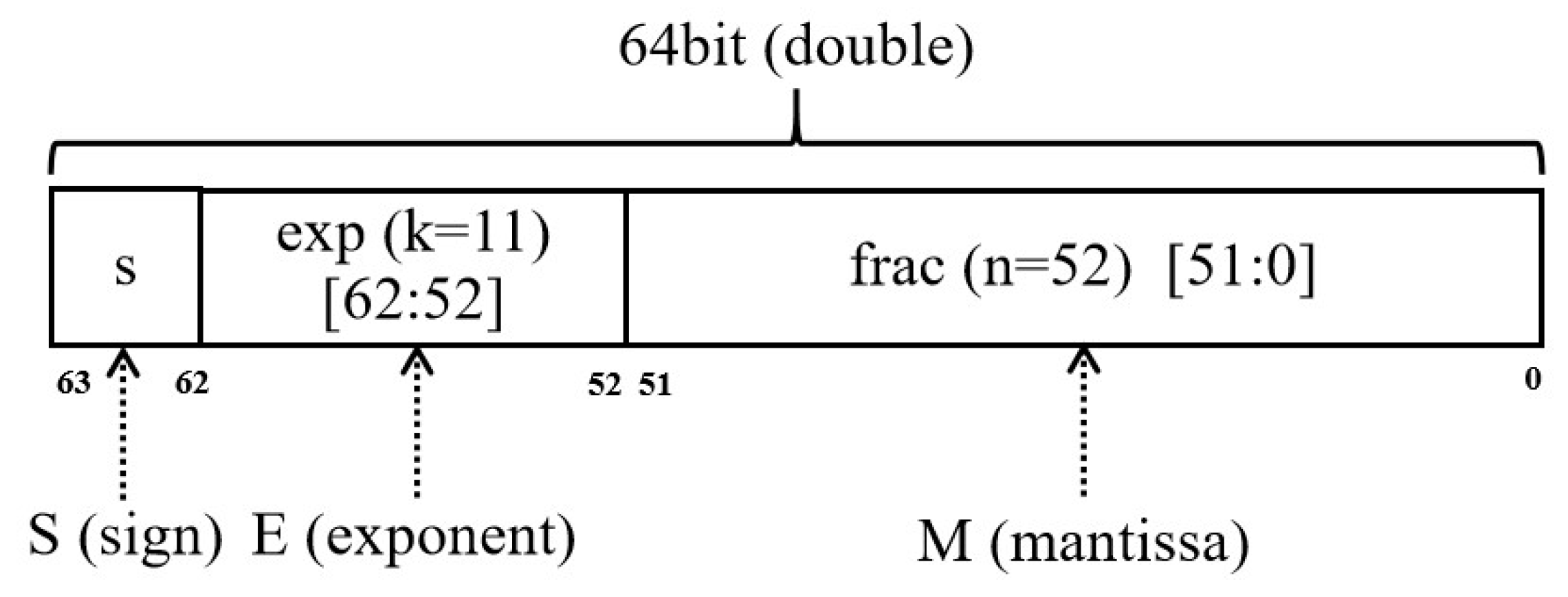
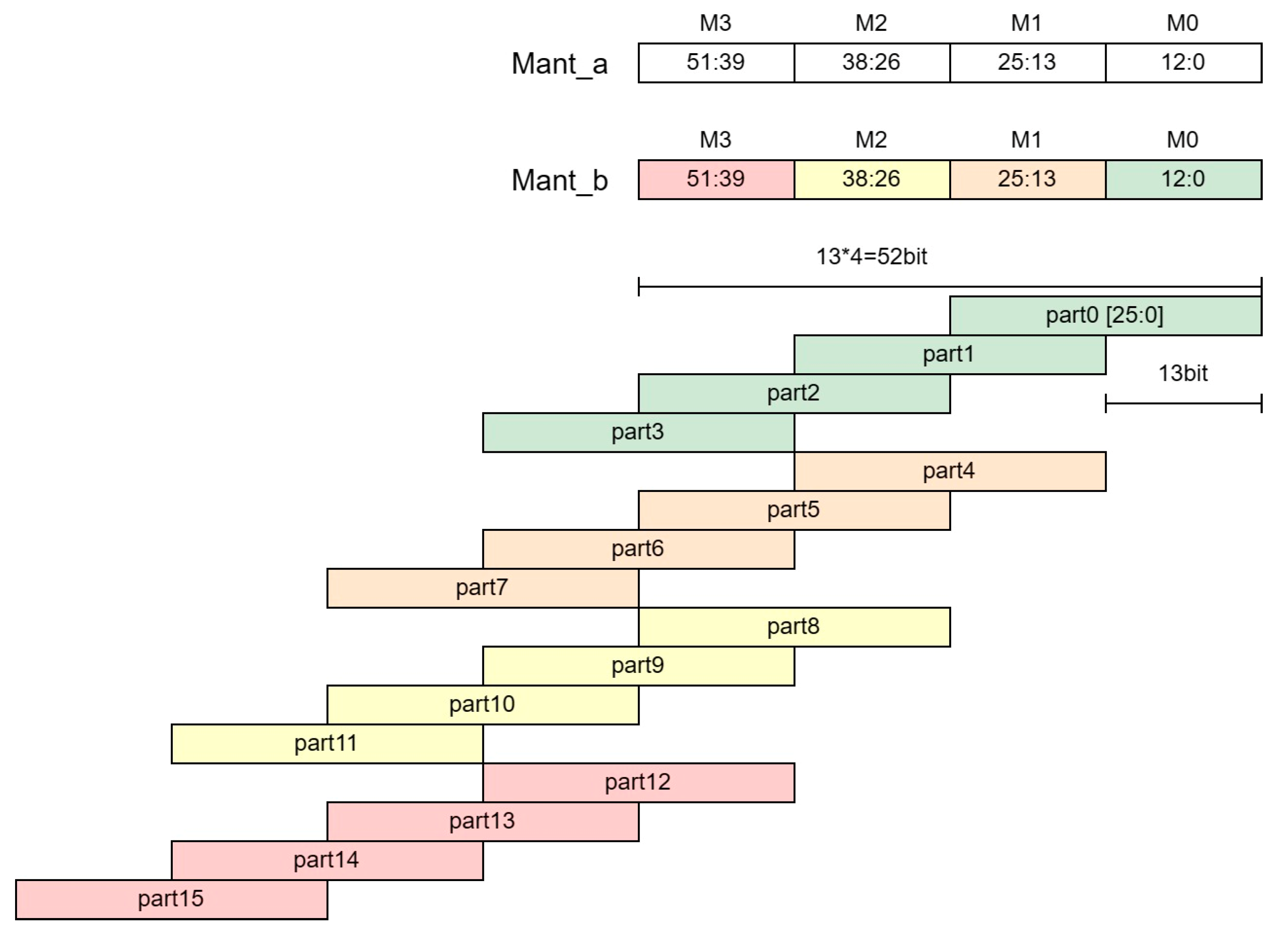
2.2. FP64 Data Format
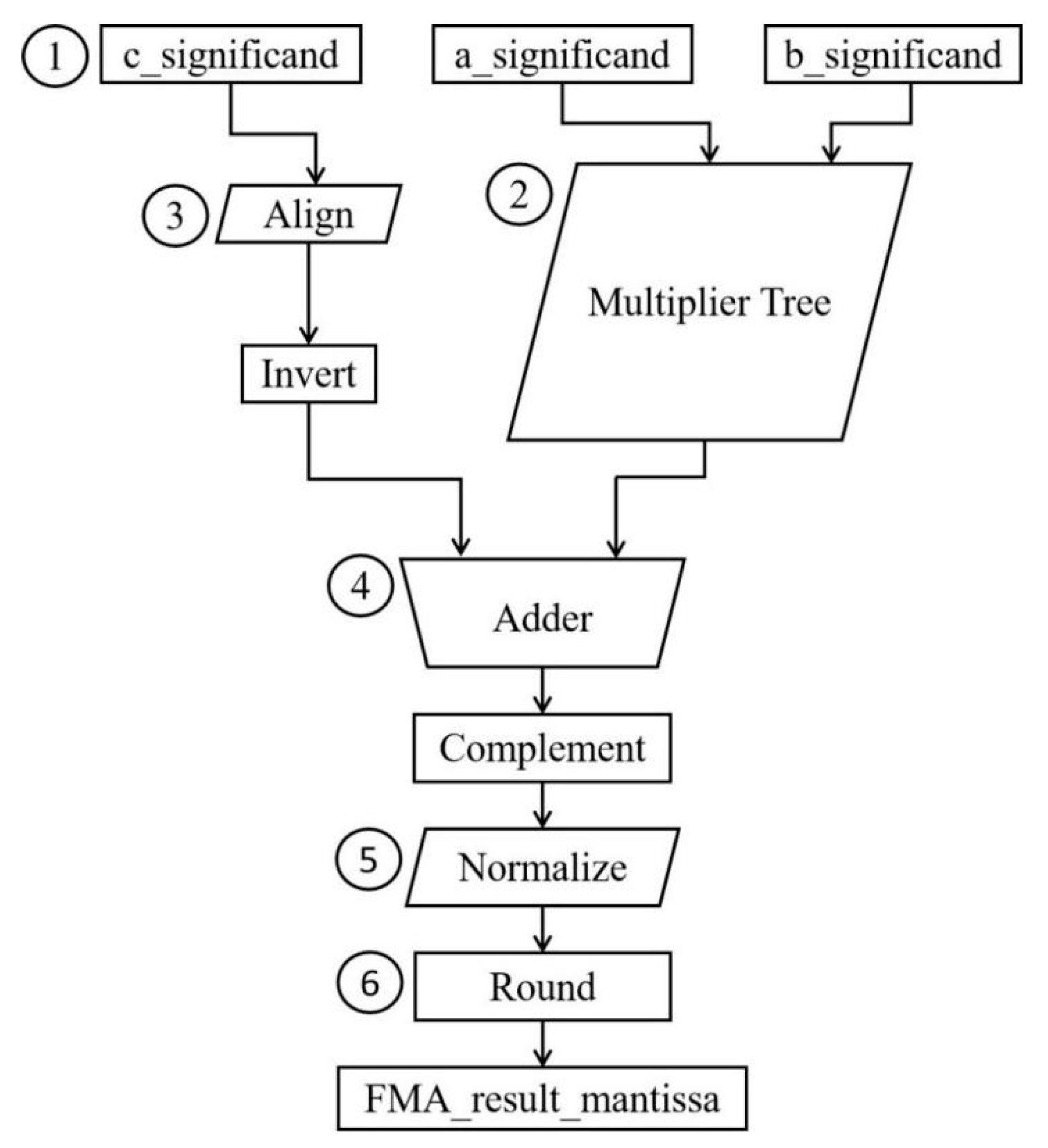
2.3. The Algorithm of FMA Operator
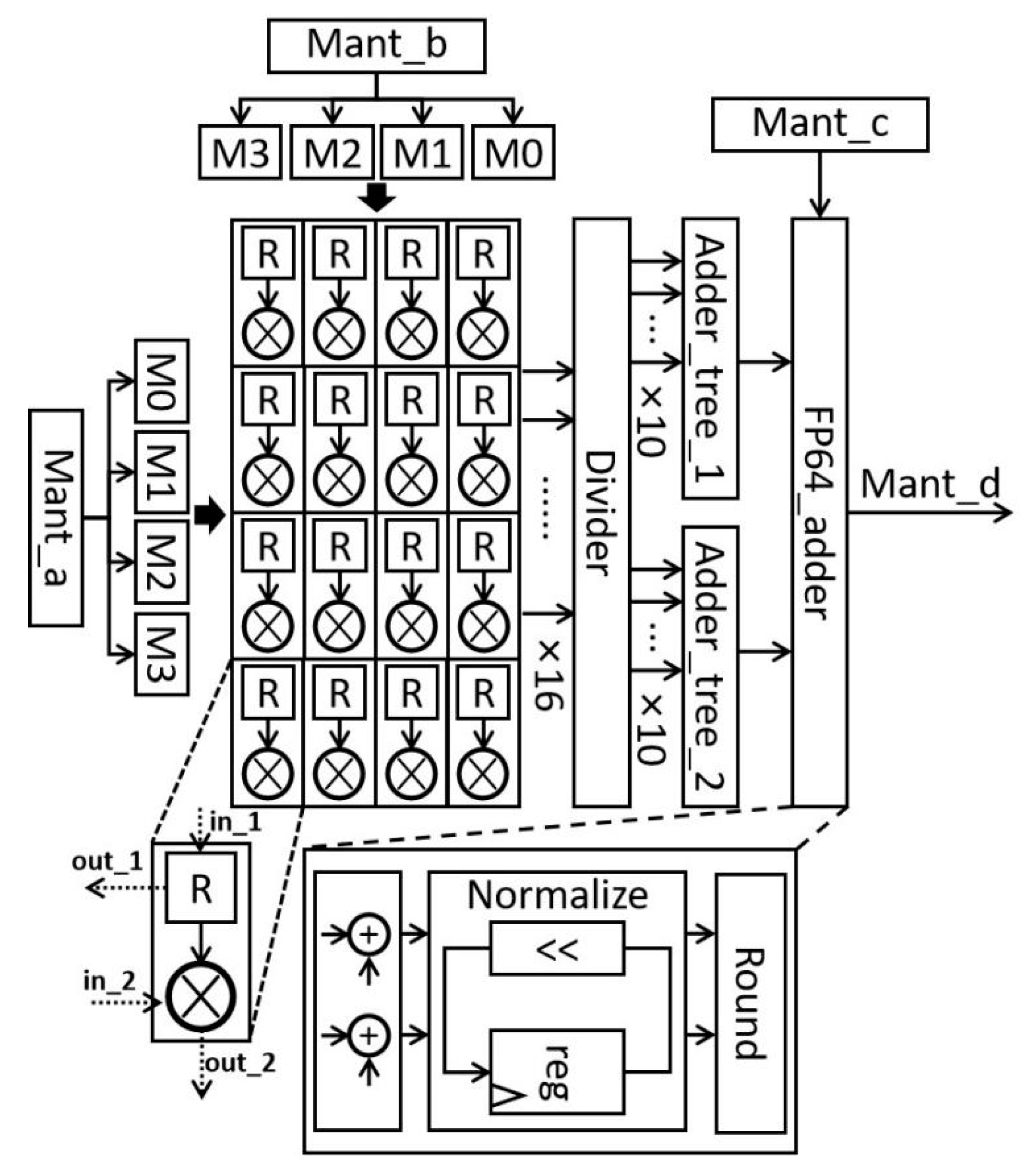
3. The Proposed Architecture of DCIM-FF
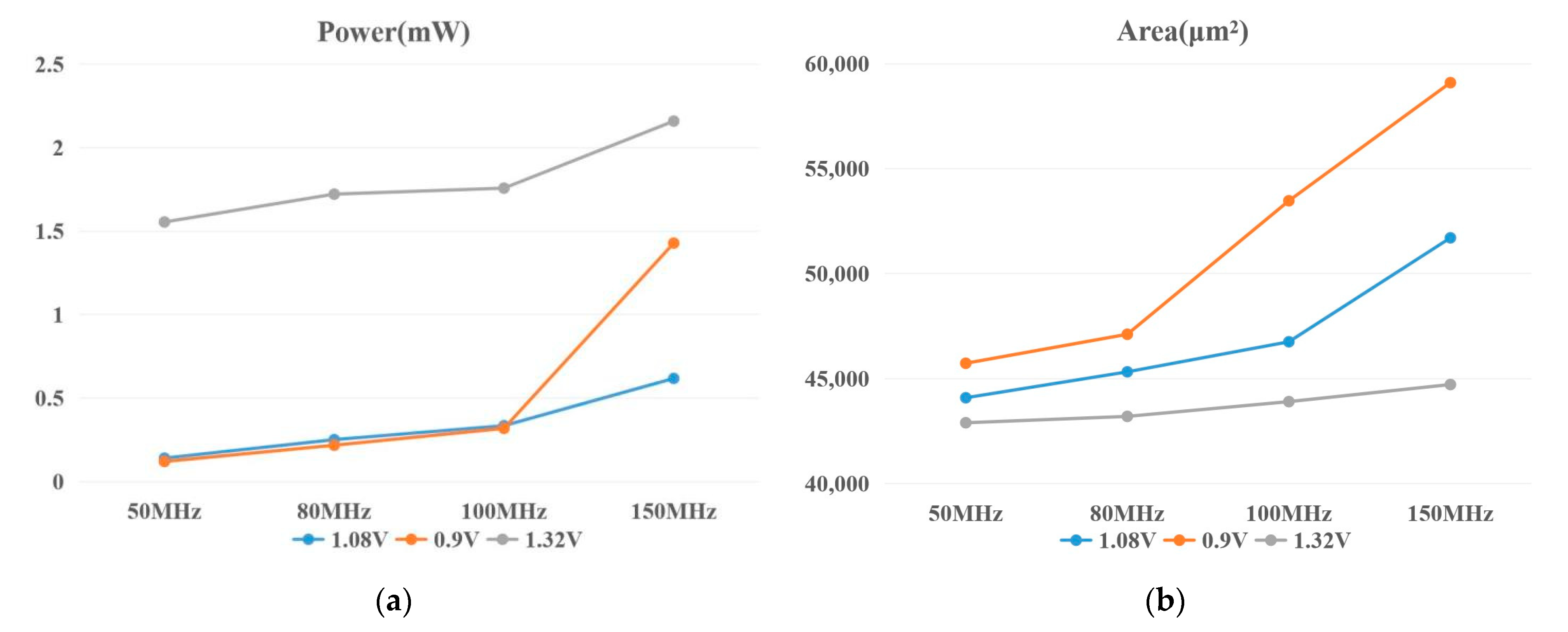
4. Simulation and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tan, L.; Kothapalli, S.; Chen, L.; Hussaini, O.; Bissiri, R.; Chen, Z. A survey of power and energy efficient techniques for high performance numerical linear algebra operations. Parallel Comput. 2014, 40, 559–573. [Google Scholar] [CrossRef]
- Chen, J.; Li, J.; Li, Y.; Miao, X. Multiply accumulate operations in memristor crossbar arrays for analog computing. J. Semicond. 2021, 42, 013104. [Google Scholar] [CrossRef]
- Feinberg, B.; Vengalam UK, R.; Whitehair, N.; Wang, S.; Ipek, E. Enabling scientific computing on memristive accelerators. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018. [Google Scholar]
- Kautz, W.H. Cellular logic-in-memory arrays. IEEE Trans. Comput. 1969, 100, 719–727. [Google Scholar] [CrossRef]
- Stone, H.S. A logic-in-memory computer. IEEE Trans. Comput. 1970, 100, 73–78. [Google Scholar] [CrossRef]
- Ahn, J.; Yoo, S.; Mutlu, O.; Choi, K. PIM-enabled instructions: A low-overhead, locality-aware processing-in-memory architecture. ACM SIGARCH Comput. Archit. News 2015, 43, 336–348. [Google Scholar] [CrossRef]
- Elliott, D.G.; Stumm, M.; Snelgrove, W.M.; Cojocaru, C.; McKenzie, R. Computational RAM: Implementing processors in memory. IEEE Des. Test Comput. 1999, 16, 32–41. [Google Scholar] [CrossRef]
- Li, S.; Niu, D.; Malladi, K.T.; Zheng, H.; Brennan, B.; Xie, Y. Drisa: A dram-based reconfigurable in-situ accelerator. In Proceedings of the 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Cambridge, MA, USA, 14–18 October 2017. [Google Scholar]
- Wong HS, P.; Salahuddin, S. Memory leads the way to better computing. Nat. Nanotechnol. 2015, 10, 191–194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heo, J.; Kim, J.; Lim, S.; Han, W.; Kim, J.Y. T-PIM: An Energy-Efficient Processing-in-Memory Accelerator for End-to-End On-Device Training. IEEE J. Solid-State Circuits 2022, 58, 600–613. [Google Scholar] [CrossRef]
- Dong, Q.; Sinangil, M.E.; Erbagci, B.; Sun, D.; Khwa, W.S.; Liao, H.J.; Wang, Y.; Chang, J. 15.3 A 351TOPS/W and 372.4 GOPS compute-in-memory SRAM macro in 7nm FinFET CMOS for machine-learning applications. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Zhao, C.; Fang, J.; Jiang, J.; Xue, X.; Zeng, X. ARBiS: A Hardware-Efficient SRAM CIM CNN Accelerator With Cyclic-Shift Weight Duplication and Parasitic-Capacitance Charge Sharing for AI Edge Application. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 70, 364–377. [Google Scholar] [CrossRef]
- Seshadri, V.; Lee, D.; Mullins, T.; Hassan, H.; Boroumand, A.; Kim, J.; Mowry, T.C. Ambit: In-memory accelerator for bulk bitwise operations using commodity DRAM technology. In Proceedings of the 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Cambridge, MA, USA, 14–18 October 2017. [Google Scholar]
- Sebastian, A.; Le Gallo, M.; Khaddam-Aljameh, R.; Eleftheriou, E. Memory devices and applications for in-memory computing. Nat. Nanotechnol. 2020, 15, 529–544. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Xu, C.; Zou, Q.; Zhao, J.; Lu, Y.; Xie, Y. Pinatubo: A processing-in-memory architecture for bulk bitwise operations in emerging non-volatile memories. In Proceedings of the 53rd Annual Design Automation Conference, Austin, TX, USA, 5–9 June 2016. [Google Scholar]
- Si, X.; Tu, Y.N.; Huang, W.H.; Su, J.W.; Lu, P.J.; Wang, J.H.; Liu, T.W.; Wu, S.Y.; Liu, R.; Chou, Y.C.; et al. 15.5 A 28nm 64Kb 6T SRAM computing-in-memory macro with 8b MAC operation for AI edge chips. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Su, J.W.; Si, X.; Chou, Y.C.; Chang, T.W.; Huang, W.H.; Tu, Y.N.; Liu, R.; Lu, P.J.; Liu, T.W.; Wang, J.H.; et al. 15.2 a 28nm 64Kb inference-training two-way transpose multibit 6T SRAM Compute-in-Memory macro for AI edge chips. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Su, J.W.; Chou, Y.C.; Liu, R.; Liu, T.W.; Lu, P.J.; Wu, P.C.; Chung, Y.L.; Hung, L.Y.; Ren, J.S.; Pan, T.; et al. 16.3 a 28nm 384kb 6t-sram computation-in-memory macro with 8b precision for ai edge chips. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; Volume 64. [Google Scholar]
- Yue, J.; Yuan, Z.; Feng, X.; He, Y.; Zhang, Z.; Si, X.; Liu, R.; Chang, M.F.; Li, X.; Yang, H.; et al. 14.3 a 65nm computing-in-memory-based cnn processor with 2.9-to-35.8 tops/w system energy efficiency using dynamic-sparsity performance-scaling architecture and energy-efficient inter/intra-macro data reuse. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Eckert, C.; Wang, X.; Wang, J.; Subramaniyan, A.; Iyer, R.; Sylvester, D.; Blaaauw, D.; Das, R. Neural cache: Bit-serial in-cache acceleration of deep neural networks. In Proceedings of the 2018 ACM/IEEE 45Th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018. [Google Scholar]
- Yue, J.; Feng, X.; He, Y.; Huang, Y.; Wang, Y.; Yuan, Z.; Zhan, M.; Liu, J.; Su, J.W.; Chung, Y.L.; et al. 15.2 A 2.75-to-75.9 TOPS/W computing-in-memory NN processor supporting set-associate block-wise zero skipping and ping-pong CIM with simultaneous computation and weight updating. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; Volume 64. [Google Scholar]
- Fujiwara, H.; Mori, H.; Zhao, W.C.; Chuang, M.C.; Naous, R.; Chuang, C.K.; Hashizume, T.; Sun, D.; Lee, C.F.; Akarvardar, K.; et al. A 5-nm 254-TOPS/W 221-TOPS/mm 2 Fully-Digital Computing-in-Memory Macro Supporting Wide-Range Dynamic-Voltage-Frequency Scaling and Simultaneous MAC and Write Operations. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–26 February 2022; Volume 65. [Google Scholar]
- Tu, F.; Wang, Y.; Wu, Z.; Liang, L.; Ding, Y.; Kim, B.; Liu, L.; Wei, S.; Xie, Y.; Yin, S. A 28nm 29.2 TFLOPS/W BF16 and 36.5 TOPS/W INT8 Reconfigurable Digital CIM Processor with Unified FP/INT Pipeline and Bitwise In-Memory Booth Multiplication for Cloud Deep Learning Acceleration. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–26 February 2022; Volume 65. [Google Scholar]
- Chih, Y.D.; Lee, P.H.; Fujiwara, H.; Shih, Y.C.; Lee, C.F.; Naous, R.; Chen, Y.L.; Lo, C.P.; Lu, C.H.; Mori, H.; et al. 16.4 an 89tops/w and 16.3 tops/mm 2 all-digital sram-based full-precision compute-in memory macro in 22nm for machine-learning edge applications. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; Volume 64. [Google Scholar]
- Whitehead, N.; Fit-Florea, A. Precision & performance: Floating point and IEEE 754 compliance for NVIDIA GPUs. rn (A+ B) 2011, 21, 18749–19424. [Google Scholar]
- Szydzik, T.; Moloney, D. Precision refinement for media-processor SoCs: fp32-> fp64 on myriad. In Proceedings of the 2014 IEEE Hot Chips 26 Symposium (HCS), Las Palmas, Gran Canaria, Spain, 10–12 August 2014. [Google Scholar]
- Zhang, H.; Chen, D.; Ko, S.B. Efficient multiple-precision floating-point fused multiply-add with mixed-precision support. IEEE Trans. Comput. 2019, 68, 1035–1048. [Google Scholar] [CrossRef]
- Park, J.; Lee, S.; Jeon, D. A neural network training processor with 8-bit shared exponent bias floating point and multiple-way fused multiply-add trees. IEEE J. Solid-State Circuits 2021, 57, 965–977. [Google Scholar] [CrossRef]
- Stepchenkov, Y.; Stepchenkov, D.; Rogdestvenski, Y.; Shikunov, Y.; Diachenko, Y. Energy efficient speed-independent 64-bit fused multiply-add unit. In Proceedings of the 2019 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Saint Petersburg and Moscow, Russia, 28–31 January 2019. [Google Scholar]
- Huang, L.; Shen, L.; Dai, K.; Wang, Z. A new architecture for multiple-precision floating-point multiply-add fused unit design. In Proceedings of the 18th IEEE Symposium on Computer Arithmetic (ARITH’07), Montpellier, France, 25–27 June 2007. [Google Scholar]
- Manolopoulos, K.; Reisis, D.; Chouliaras, V.A. An efficient dual-mode floating-point multiply-add fused unit. In Proceedings of the 2010 17th IEEE International Conference on Electronics, Circuits and Systems, Athens, Greece, 12–15 December 2010. [Google Scholar]
- Gök, M.; Özbilen, M.M. Multi-functional floating-point MAF designs with dot product support. Microelectron. J. 2008, 39, 30–43. [Google Scholar]
- Arunachalam, V.; Raj, A.N.J.; Hampannavar, N.; Bidul, C.B. Efficient dual-precision floating-point fused-multiply-add architecture. Microprocess. Microsyst. 2018, 57, 23–31. [Google Scholar]
- Quinnell, E.; Swartzlander, E.E.; Lemonds, C. Floating-point fused multiply-add architectures. In Proceedings of the 2007 Conference Record of the Forty-First Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 4–7 November 2007. [Google Scholar]
- Hokenek, E.; Montoye, R.K.; Cook, P.W. Second-generation RISC floating point with multiply-add fused. IEEE J. Solid-State Circuits 1990, 25, 1207–1213. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input/Output | Data form | ||
| Normalized | Denormalized | ||
| Input | a | 0x405676f4ede9dbd4 | 0xac7e15859290f |
| b | 0x40340aa015402a80 | 0x3fdf9fbf3f7e7efd | |
| c | 0x407726f04de09bc1 | 0xd375c9a74d3d | |
| Output | d | 0x40a0f6acacac57ff | 0x6272fbb808f07 |
| Input/Output | Rounding mode | ||
| Round-to-Nearest-even | Round-to-Zero | ||
| Input | a | 0x404a084410882110 | 0x404a084410882110 |
| b | 0xc0510df41be837d0 | 0xc0510df41be837d0 | |
| c | 0xc08603ab87570eae | 0xc08603ab87570eae | |
| Output | d | 0xc0b0a0338b14cb85 | 0xc0b0a0338b14cb84 |
| Input | Output | ||
|---|---|---|---|
| a | b | c | d |
| 0x40485194a3294653 (48.64) | 0x4043b7cf6f9edf3e (39.44) | 0x408c3336e66dccdc (902.40) | 0x40a608ee290e4081 (2820.47) |
| 0x405676f4ede9dbd4 (89.86) | 0x40340aa015402a80 (20.04) | 0x407726f04de09bc1 (370.43) | 0x40a0f6acacac57ff (2171.34) |
| 0x403d5982b305660b (29.35) | 0x4052a5f94bf297e5 (74.59) | 0x4084a6c84d909b21 (660.85) | 0x40a64445c82b8f97 (2850.14) |
| 0x4053b5a96b52d6a6 (78.84) | 0x403633c46788cf12 (22.20) | 0x408507b58f6b1ed6 (672.96) | 0x40a2eeb45c197595 (2423.35) |
| 0x40580ec81d903b20 (96.23) | 0x40585af4b5e96bd3 (97.42) | 0x4077c61f8c3f187e (380.38) | 0x40c30da89eda44c6 (9755.32) |
| 0x40224af495e92bd2 (9.15) | 0x4056940f281e503d (90.31) | 0x408d1d98bb317663 (931.70) | 0x409b76f7d9f00be1 (1757.74) |
| 0x40182bb05760aec1 (6.04) | 0x4051e68fcd1f9a3f (71.60) | 0x405128b6516ca2d9 (68.64) | 0x407f54e634717e2c (501.31) |
| 0x4035cbdb97b72f6e (21.80) | 0x402e5dacbb5976b3 (15.18) | 0x4085b413e827d050 (694.51) | 0x409005c4f3053501 (1025.44) |
| 0x4019d4b3a96752cf (6.46) | 0x404265e8cbd197a3 (36.80) | 0x407edc24b8497093 (493.76) | 0x4086db06849fa665 (731.38) |
| 0x4050f2ffe5ffcc00 (67.80) | 0x40574e329c6538ca (93.22) | 0x40882edcddb9bb73 (773.86) | 0x40bbb601b2e4538b (7094.01) |
| 0x4055877f0efe1dfc (86.12) | 0x4058a97952f2a5e5 (98.65) | 0x407146fc8df91bf2 (276.44) | 0x40c121dc66dc7400 (8771.72) |
| 0x40454d4a9a95352a (42.60) | 0x40425f44be897d13 (36.74) | 0x408073cc6798cf32 (526.47) | 0x40a057d8496a0647 (2091.92) |
| 0x402b9cf739ee73dd (13.81) | 0x4045124e249c4939 (42.14) | 0x4081a05840b08161 (564.04) | 0x4091e7931bfbd1a3 (1145.89) |
| 0x404ed729ae535ca7 (61.68) | 0x402c429885310a62 (14.13) | 0x40842ee7ddcfbb9f (645.86) | 0x4097b5ad8d59deb1 (1517.42) |
| 0x3ffdeebbdd77baef (1.87) | 0x4042f095e12bc258 (37.88) | 0x408d9f3d3e7a7cf5 (947.90) | 0x408fd627ca73d130 (1018.77) |
| FMA Designs | Cycles | Delay (ns) | Area (μm2) | Power (mW) | Throughput (MOPS) | Power Efficiency (TOPS/W) |
|---|---|---|---|---|---|---|
| [30] | 3 | 3.40 | 708,590 | - | 294 | - |
| [31] | 3 | 3.34 | 286,766 | 35.2 | 291 | 8.27 |
| [32] | 4 | 3.61 | 1,803,624 | - | 277 | - |
| [33] | 8 | 3.24 | 149,000 | 17.8 | 308 | 17.3 |
| [34] | 1 | 1.08 | 259,005 | 425 | 926 | 2.18 |
| This work | 9 | 60 | 51,703 | 0.62 | 16.7 | 26.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Mo, K.; Liu, L.; Pan, B.; Li, W.; Kang, W.; Li, L. All-Digital Computing-in-Memory Macro Supporting FP64-Based Fused Multiply-Add Operation. Appl. Sci. 2023, 13, 4085. https://doi.org/10.3390/app13074085
Li D, Mo K, Liu L, Pan B, Li W, Kang W, Li L. All-Digital Computing-in-Memory Macro Supporting FP64-Based Fused Multiply-Add Operation. Applied Sciences. 2023; 13(7):4085. https://doi.org/10.3390/app13074085
Chicago/Turabian StyleLi, Dejian, Kefan Mo, Liang Liu, Biao Pan, Weili Li, Wang Kang, and Lei Li. 2023. "All-Digital Computing-in-Memory Macro Supporting FP64-Based Fused Multiply-Add Operation" Applied Sciences 13, no. 7: 4085. https://doi.org/10.3390/app13074085