
Research on Multi-Scale Feature Extraction and Working Condition Classification Algorithm of Lead-Zinc Ore Flotation Foam
Abstract
:1. Introduction
2. Materials and Methods
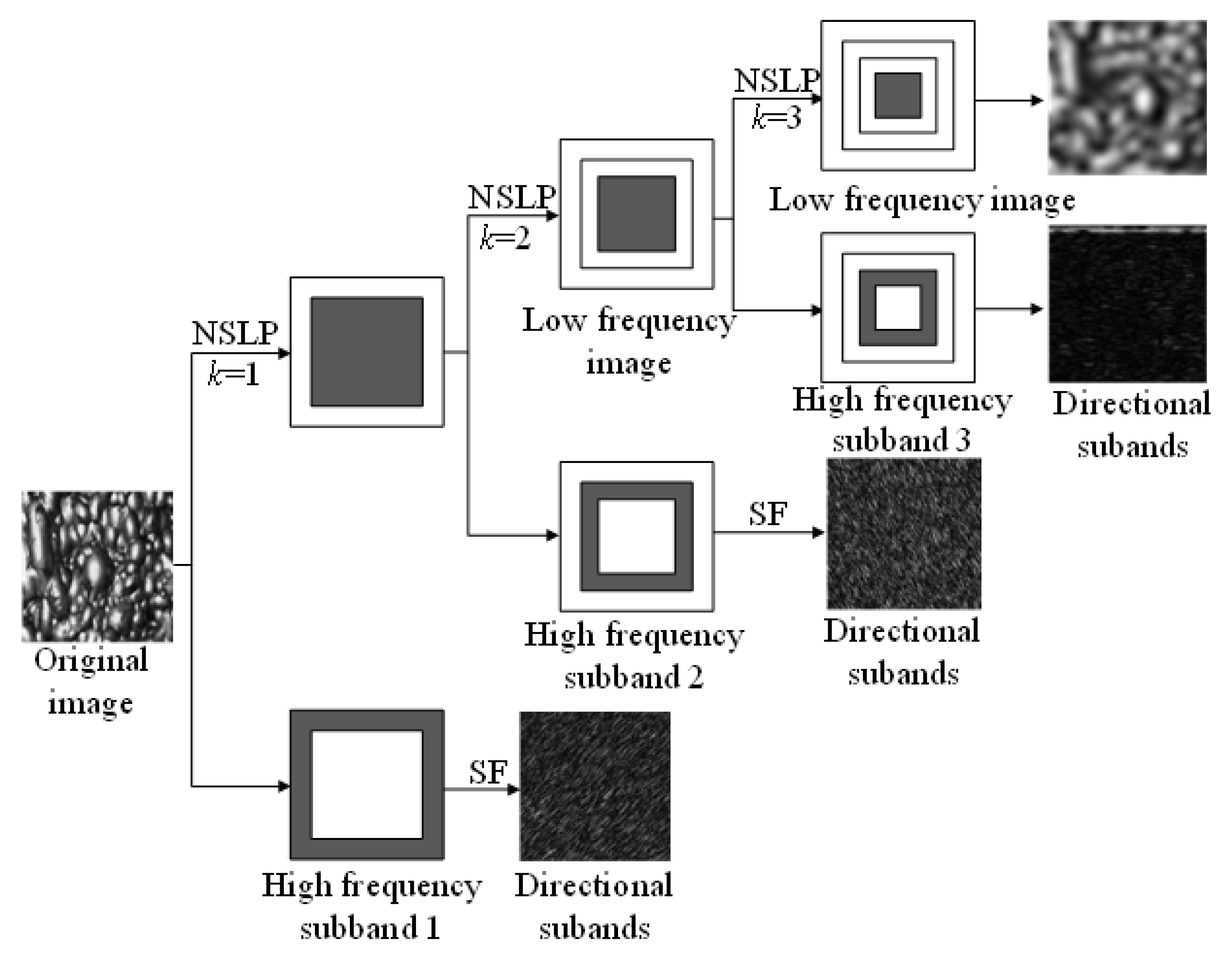
2.1. Multi-Scale NSST-CNN Feature Extraction
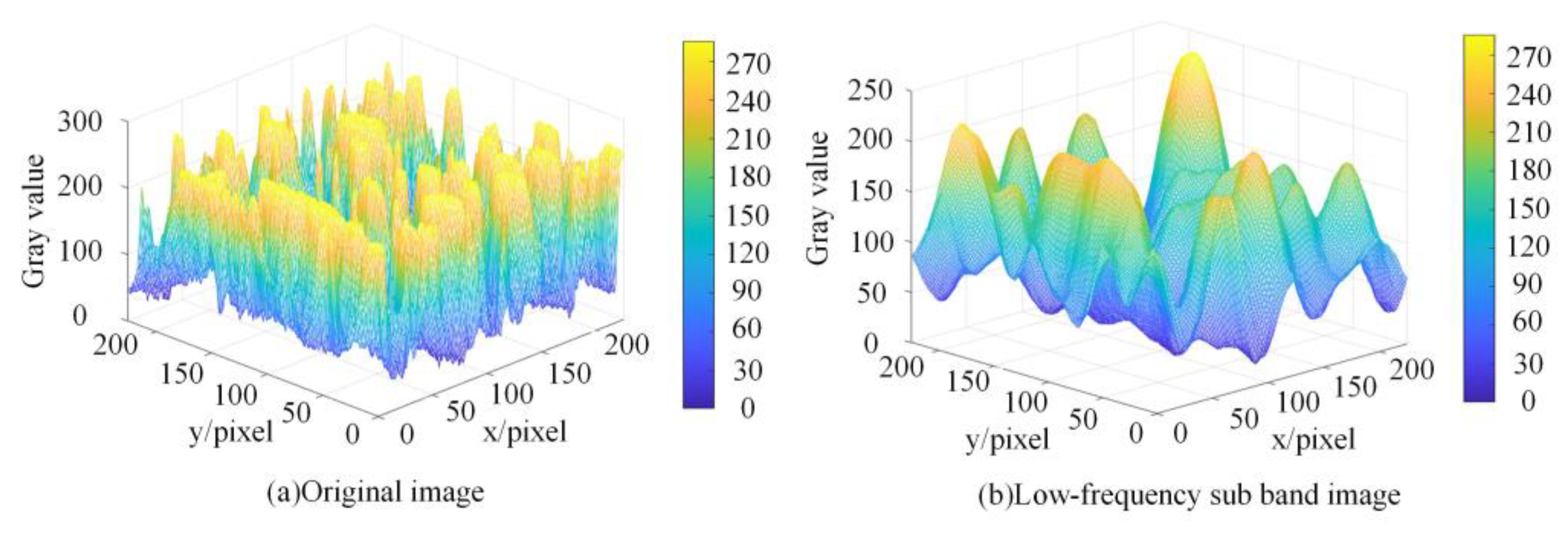
2.1.1. NSST Multi-Scale Dissection of Bubble Images
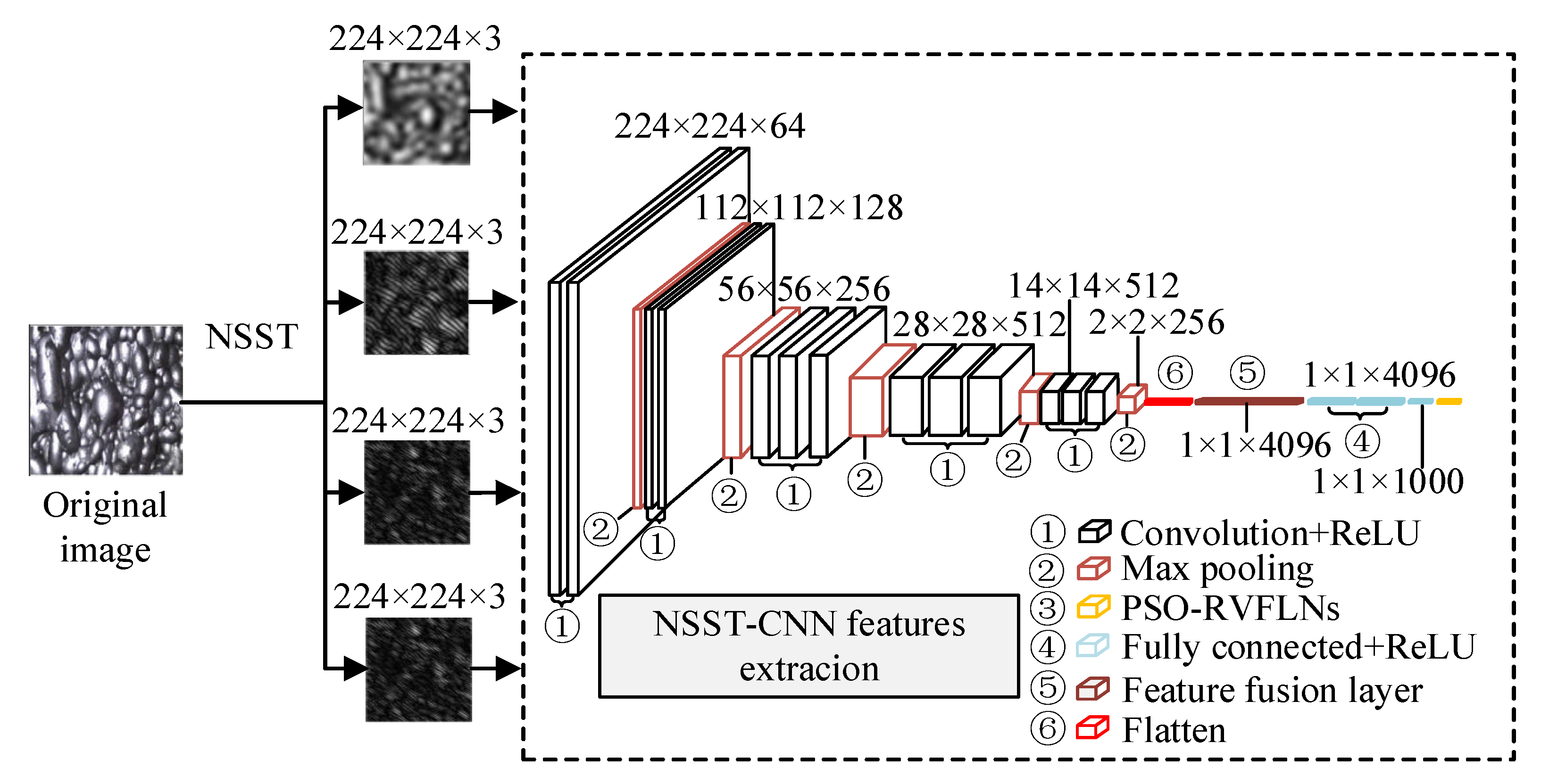
2.1.2. Construction of an NSST-CNN Feature Extraction Network
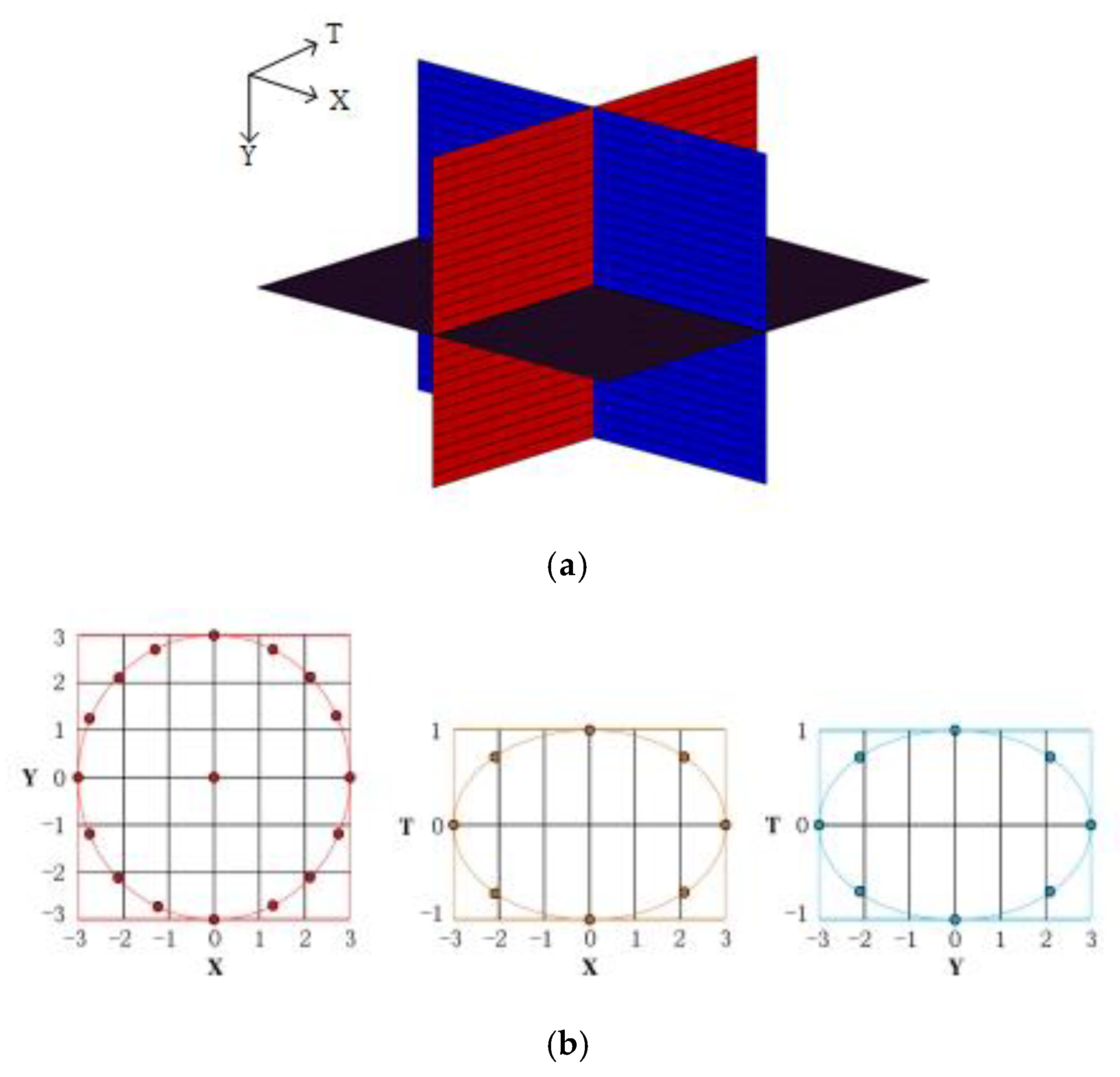
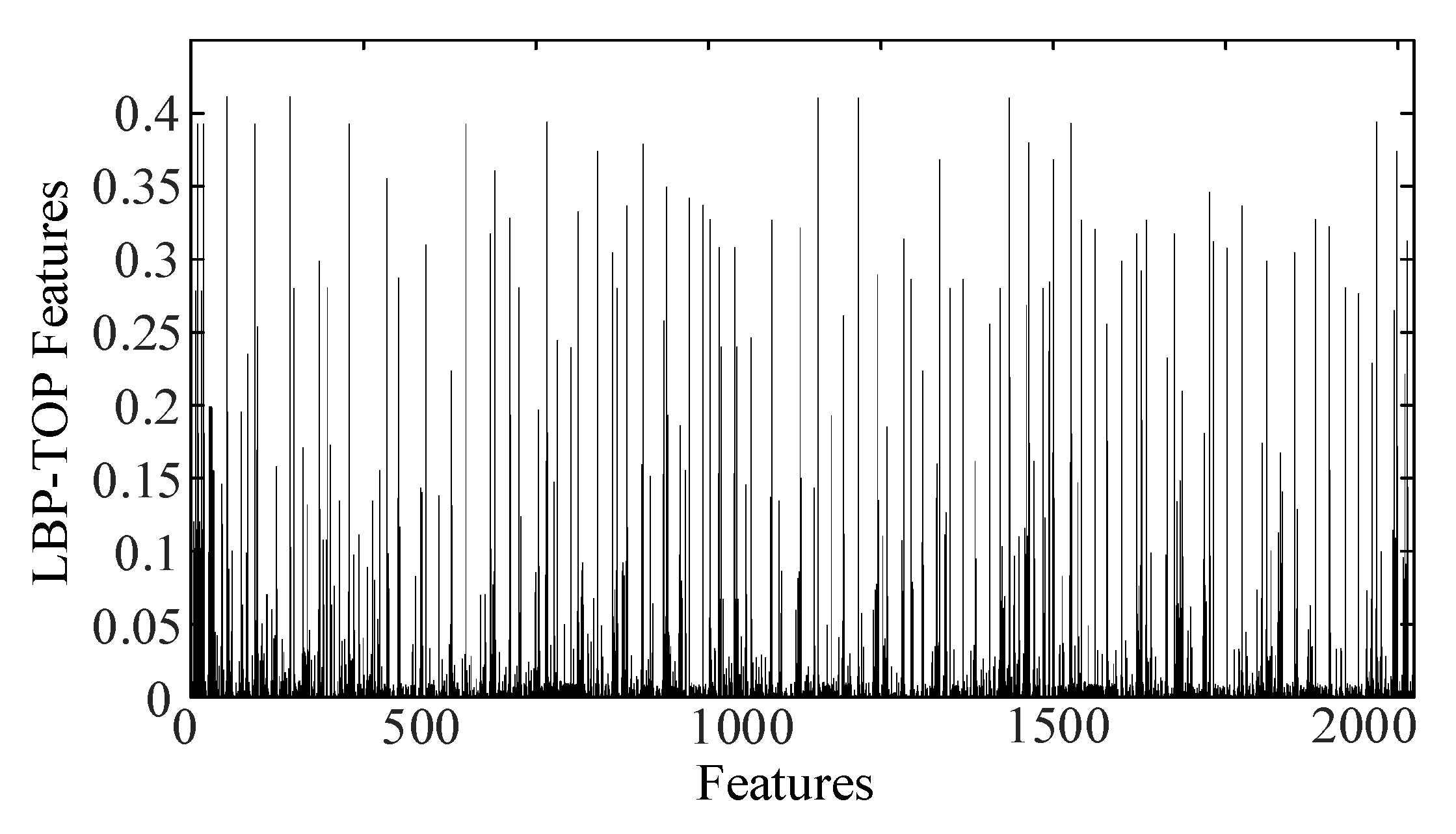
2.2. LBP-TOP Feature Extraction
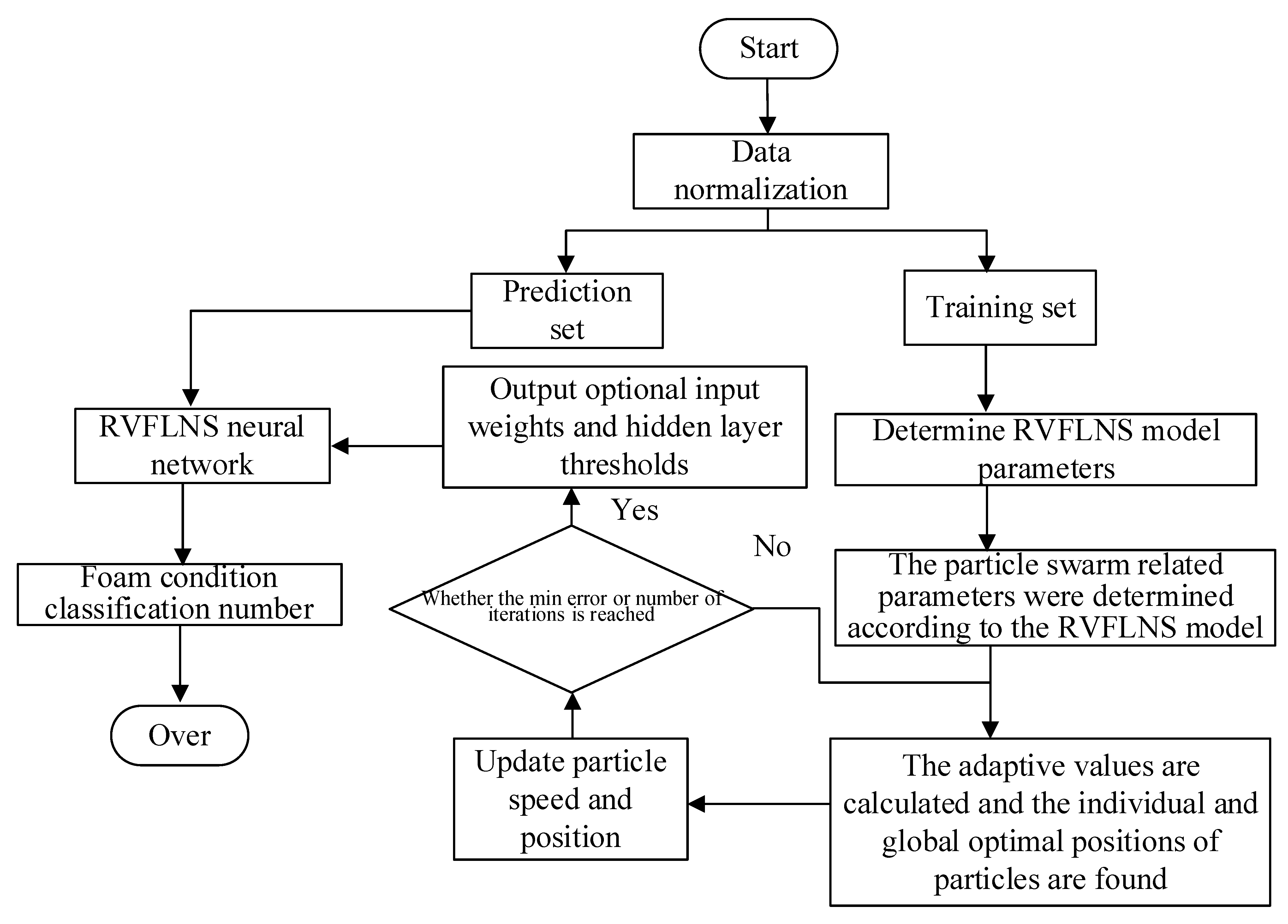
2.3. PSO-RVFLNS Condition Recognition Based on CNN and LBP Features
2.3.1. Random Weight Neural Network
2.3.2. PSO Algorithm
3. Results
3.1. LBP Experimental Analysis
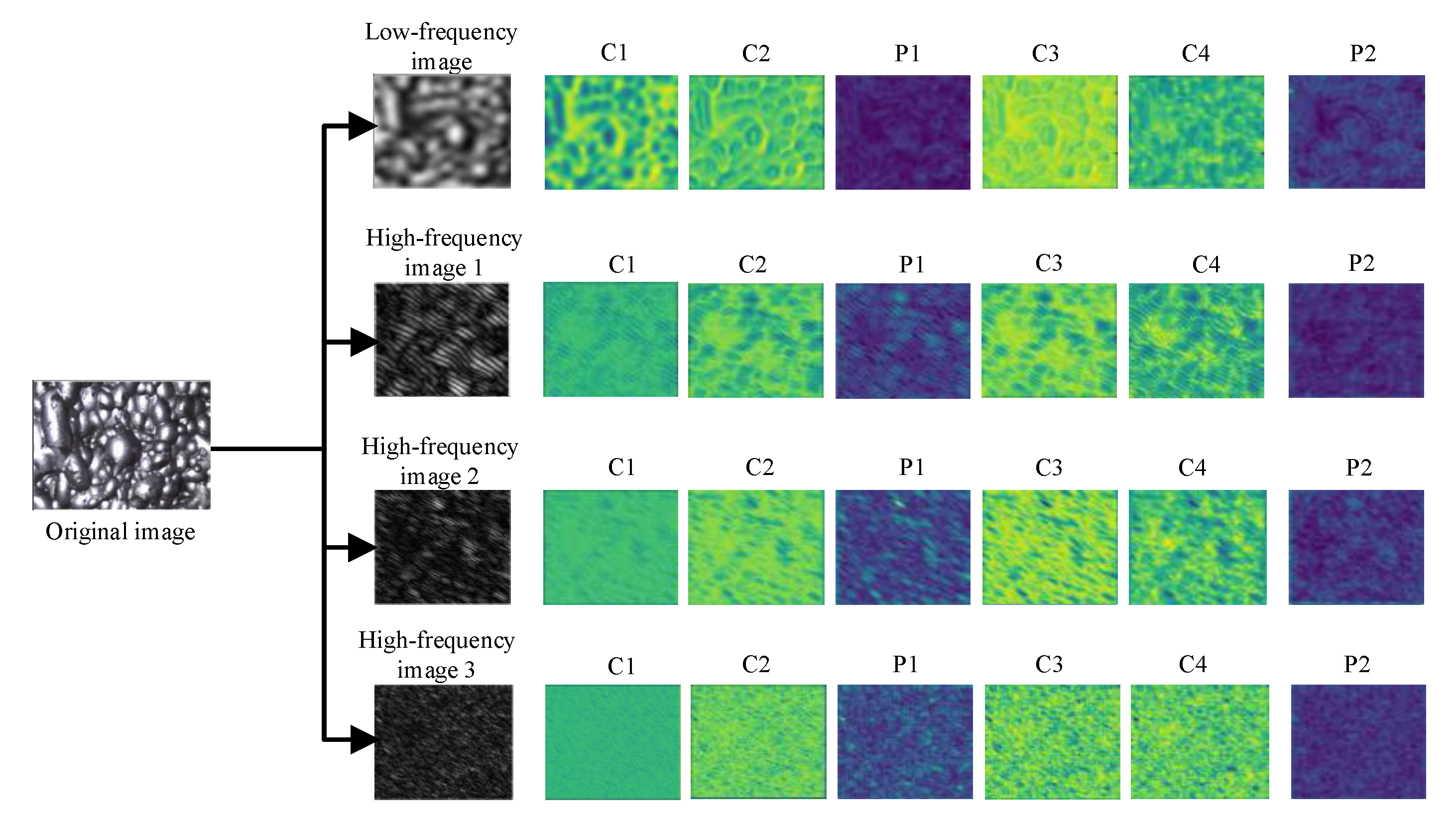
3.2. Visualization Analysis of CNN Feature Map
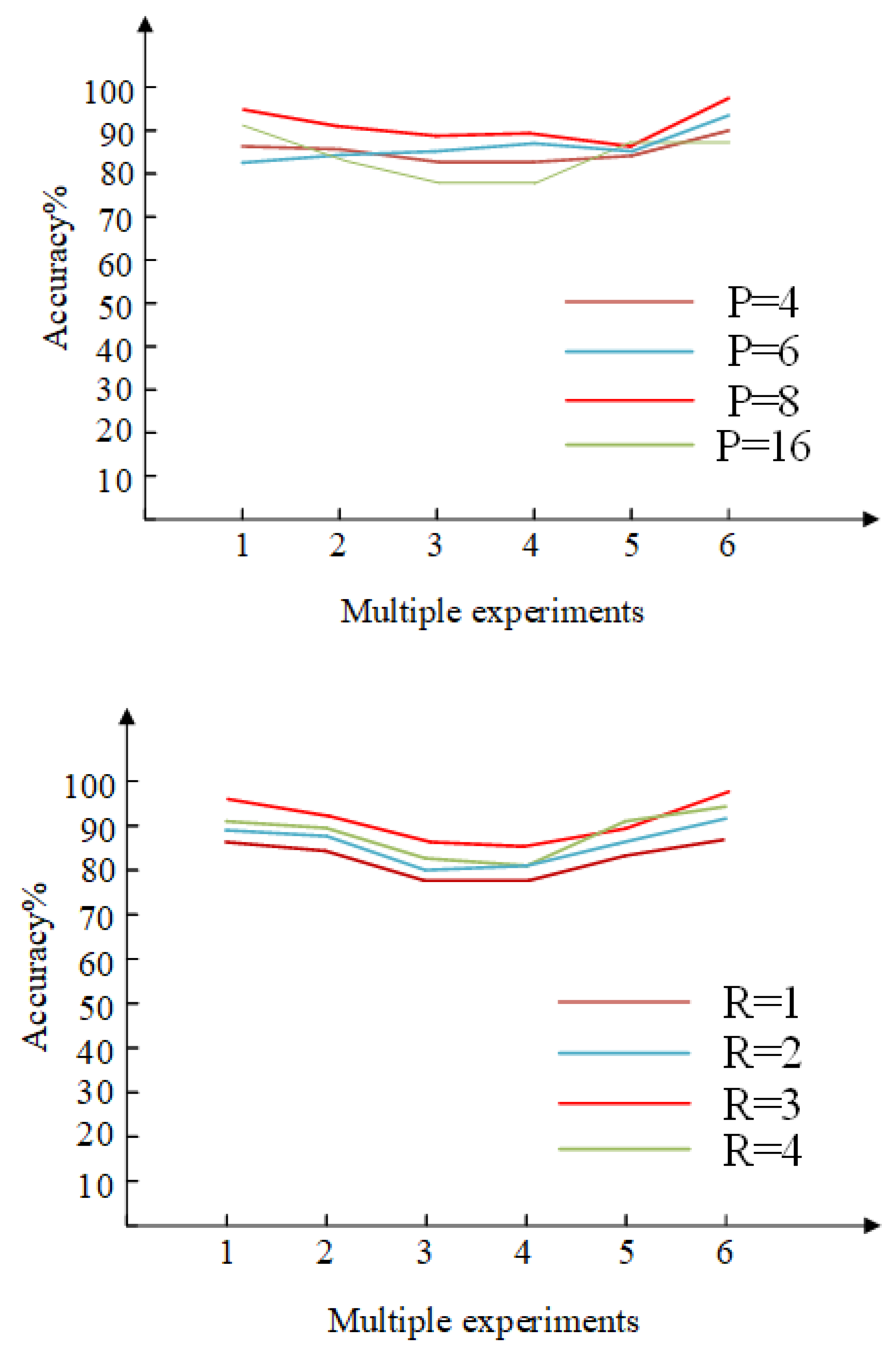
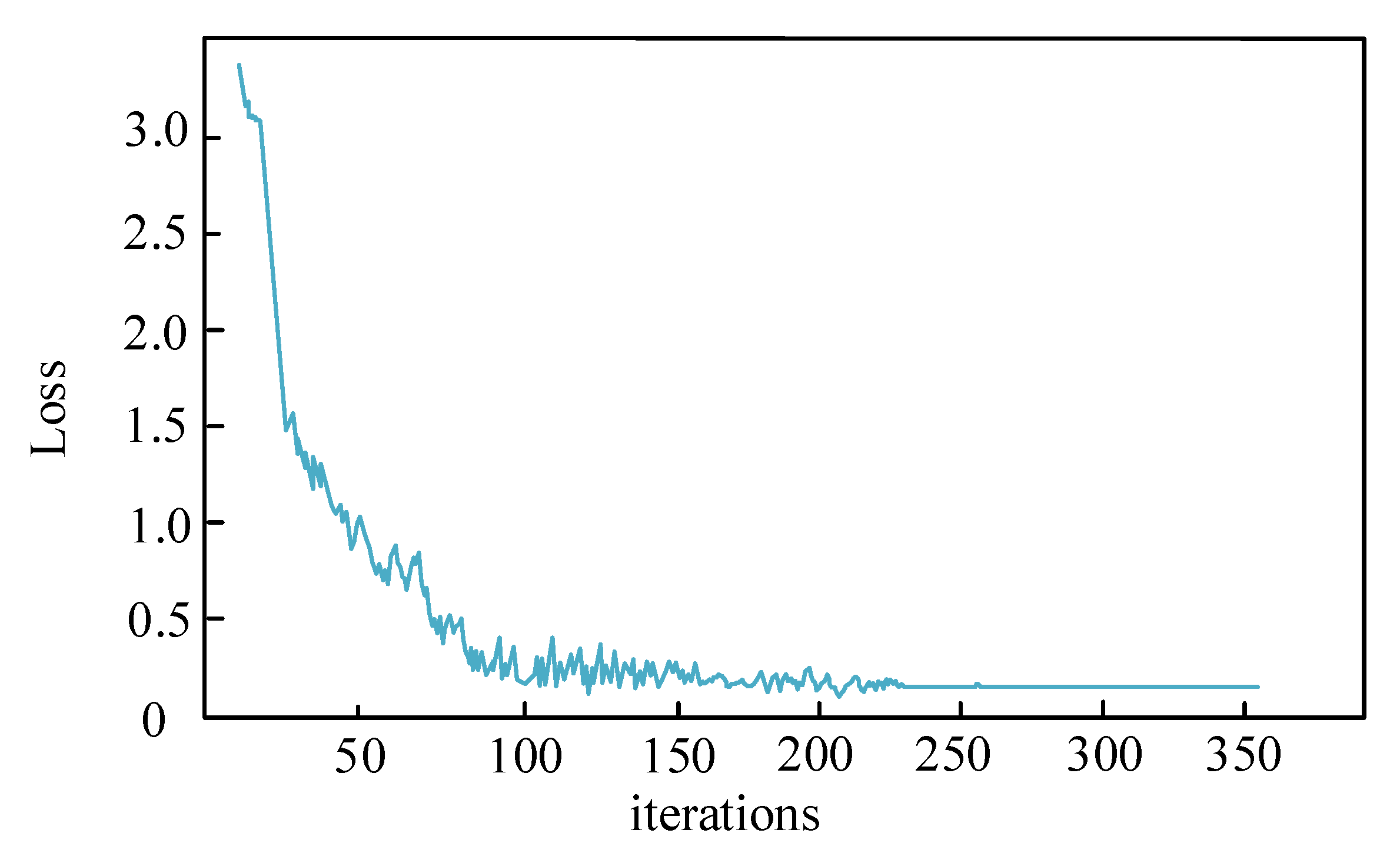
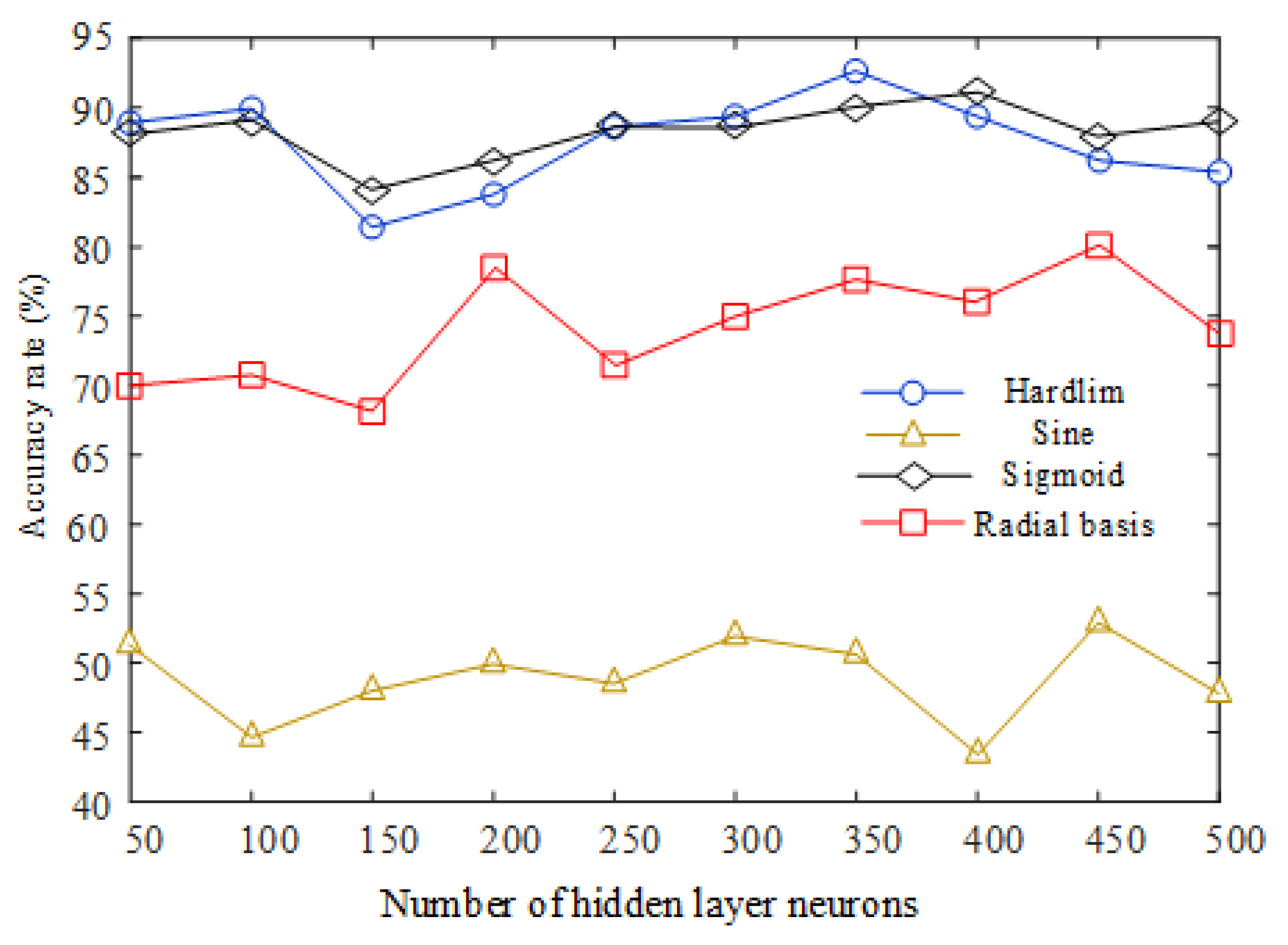
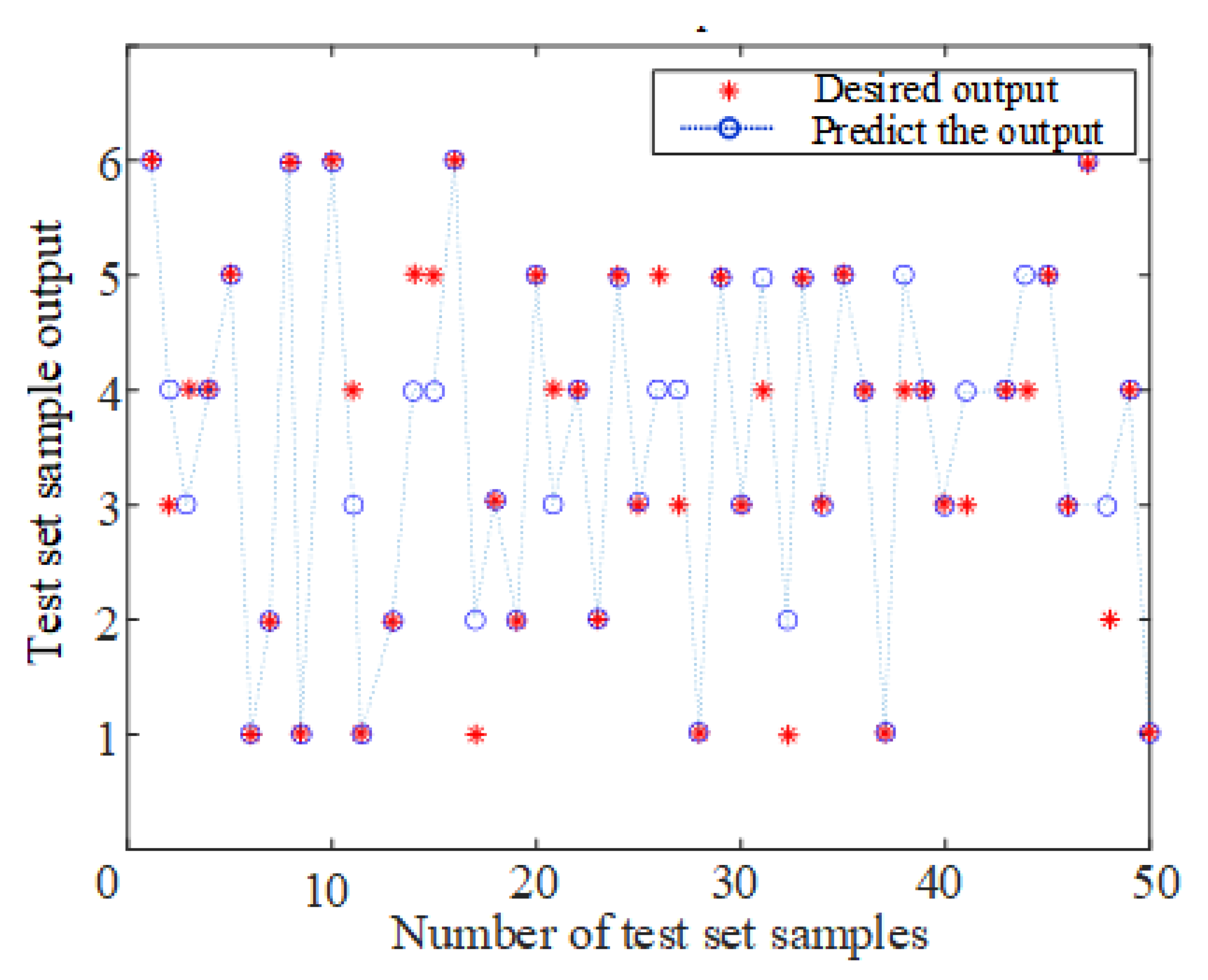
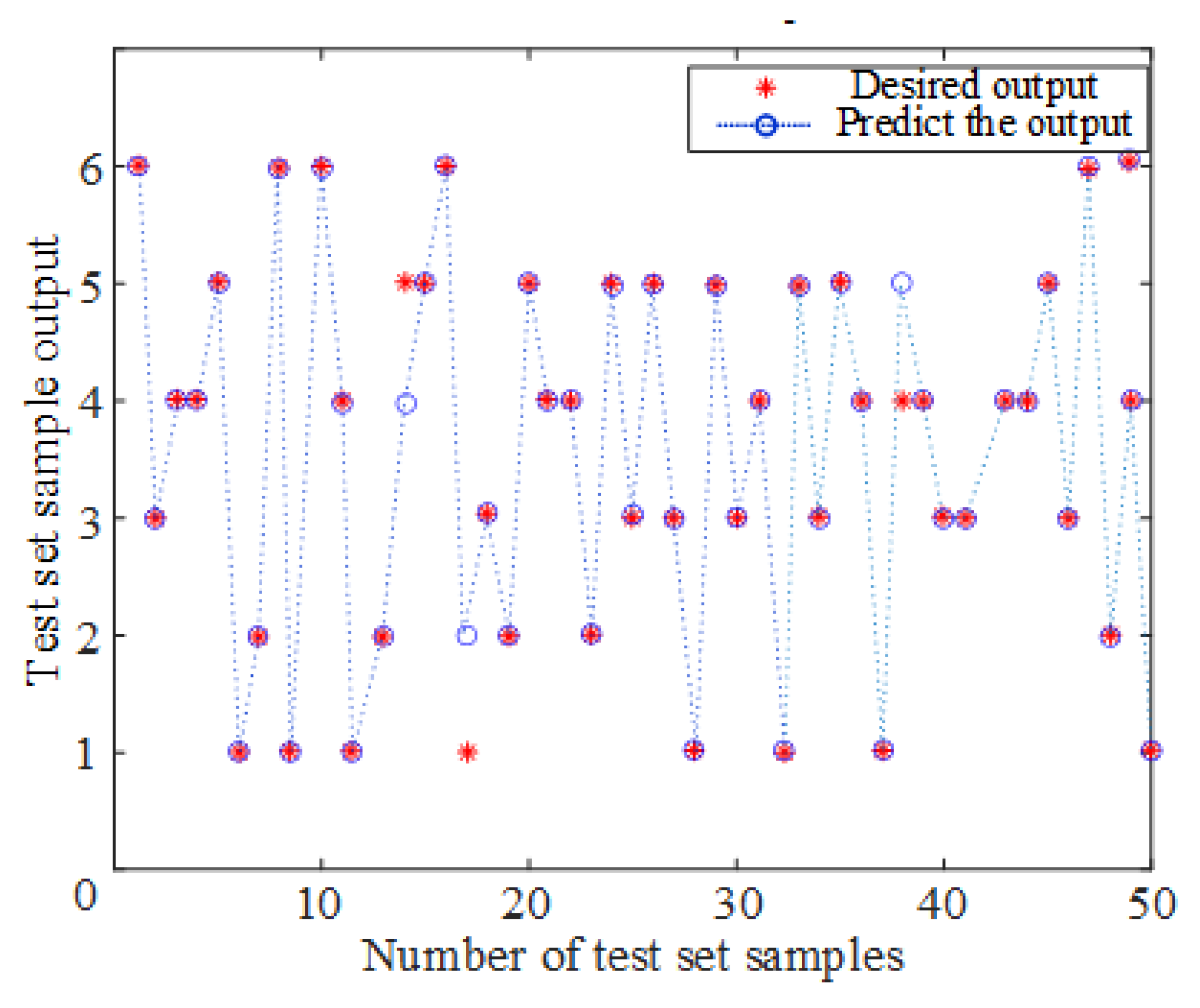
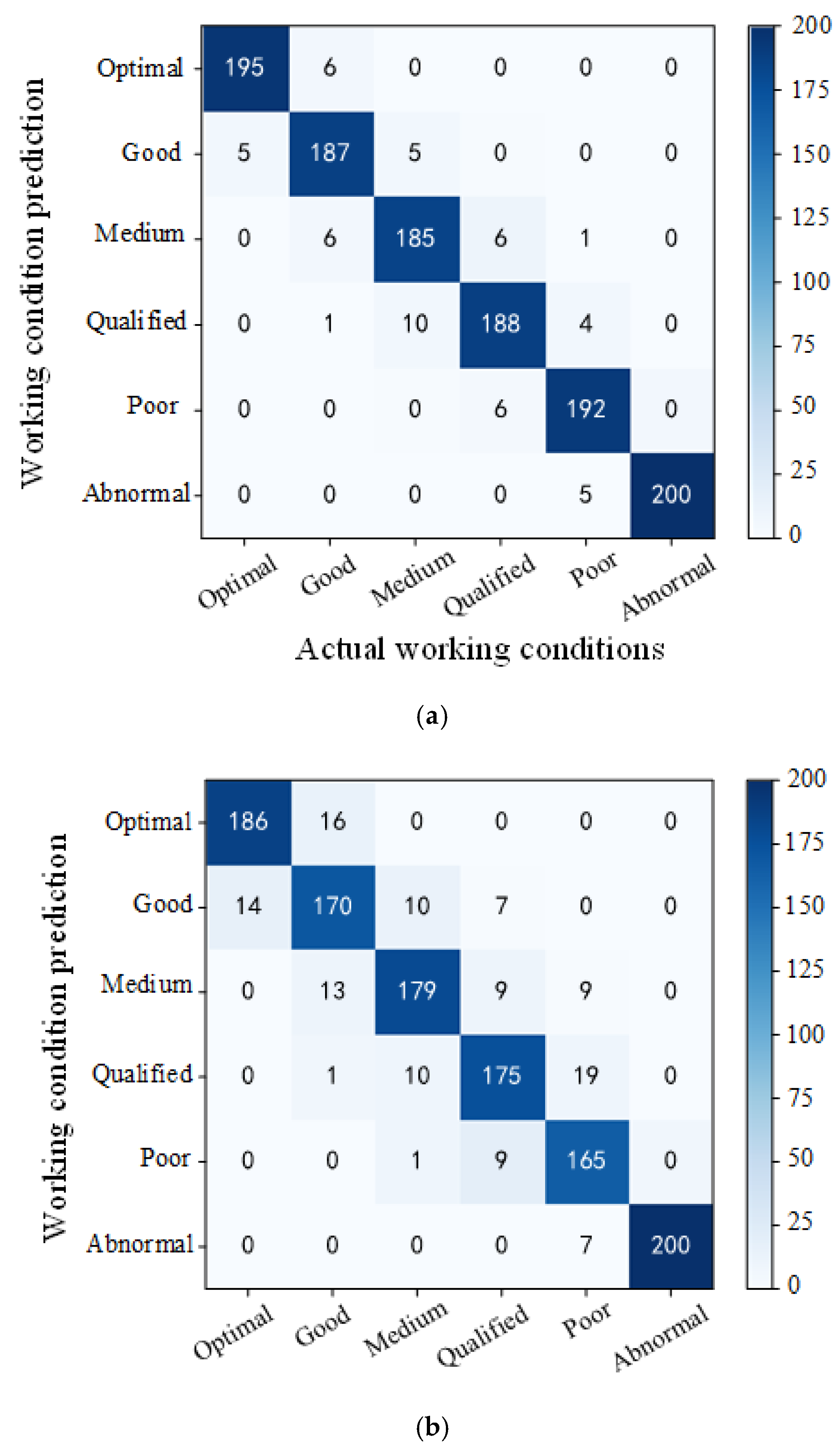
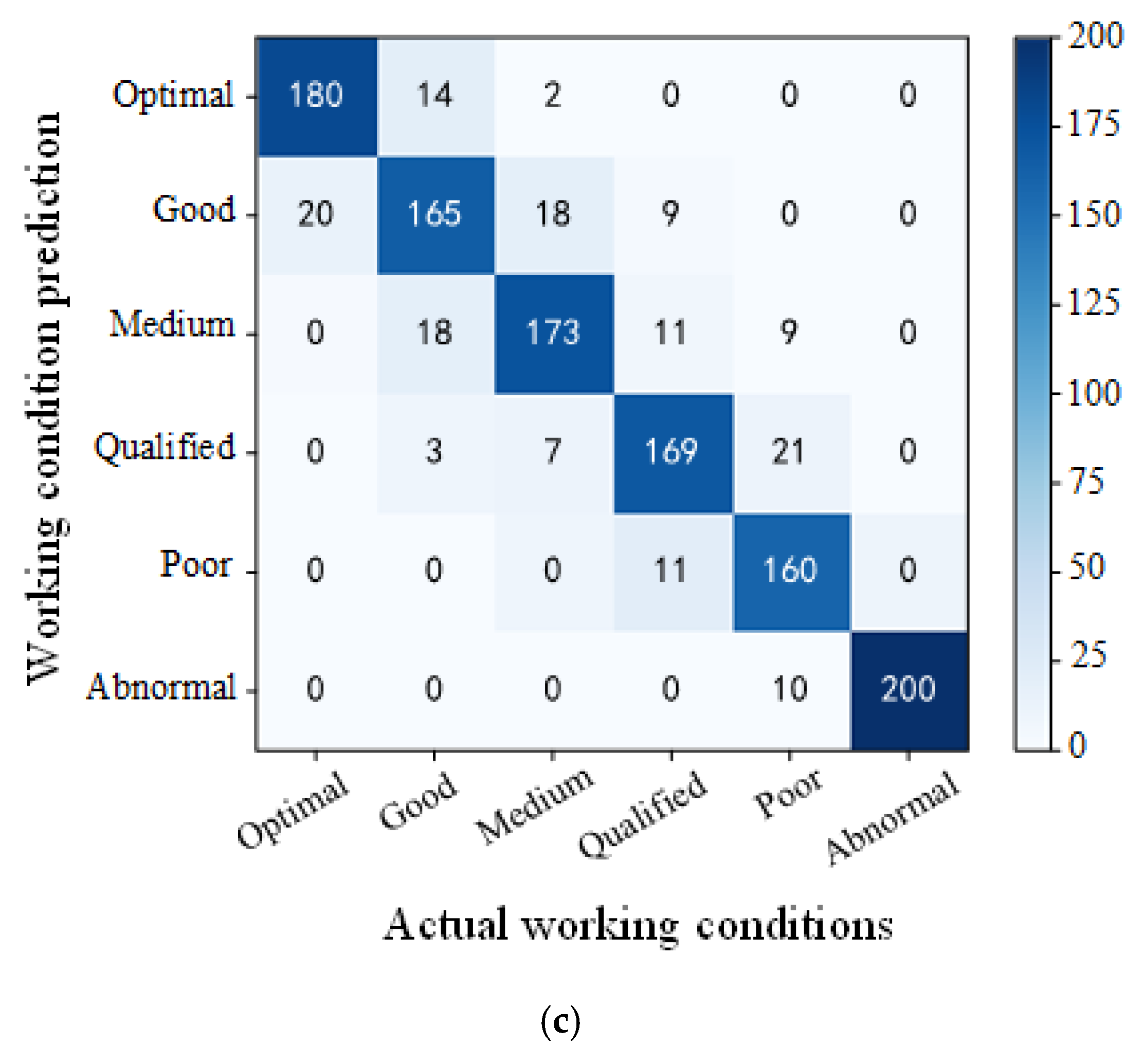
3.3. PSO-RVFLNS Parameter Setting and Classification Effect
4. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Tang, Z.; Ai, M.; Gui, W. Nonlinear modeling of the relationship between reagent dosage and flotation froth surface image by Hammerstein-Wiener mode. Miner. Eng. 2018, 120, 19–28. [Google Scholar] [CrossRef]
- Huang, L.; Liao, Y. Extraction and identification of multi-scale equivalent morphology characteristics of flotation bubbles in NSCT domain. Opt. Precis. Eng. 2020, 28, 704–716. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, S.; Lang, J.; Shao, H. The application and research of the liquid level control technology used in mineral flotation process which based on the modbus communication protocol. In Proceedings of the 2013 25th Chinese Control and Decision Conference (CCDC), Guiyang, China, 25–27 May 2013; IEEE: New York, NY, USA, 2013. [Google Scholar]
- Zhang, D.; Gao, X. A digital twin dosing system for iron reverse flotation. J. Manuf. Syst. 2022, 63, 238–249. [Google Scholar] [CrossRef]
- Bhondayi, C. Flotation froth phase bubble size measurement. Miner. Process. Extr. Metall. Rev. 2022, 43, 251–273. [Google Scholar] [CrossRef]
- Yao, Q.L.; Hu, X.; Lei, H. Object detection in remotese1234nsing images using multiscale convolutional neural networks. Acta Opt. Sin. 2019, 39, 1128002. [Google Scholar]
- Fu, Y.; Aldrich, C. Froth image analysis by use of transfer learning and convolutional neural networks. Miner. Eng. 2018, 115, 68–78. [Google Scholar] [CrossRef]
- Fu, Y.; Aldrich, C. Flotation froth image recognition with convolutional neural networks. Miner. Eng. 2019, 132, 183–190. [Google Scholar] [CrossRef]
- Morar, S.H.; Bradshaw, D.J.; Harris, M.C. The use of the froth surface lamellae burst rate as a flotation froth stability measurement. Miner. Eng. 2012, 36–38, 152–159. [Google Scholar] [CrossRef]
- Wang, X.; Song, C.; Yang, C.; Xie, Y. Process working condition recognition based on the fusion of morphological and pixel set features of froth for froth flotation. Miner. Eng. 2019, 128, 17–26. [Google Scholar] [CrossRef]
- Liao, Y.; Yang, J.; Wang, Z.; Wang, W. Identification of flotation conditions based on dual-mode convolutional neural network adaptive transfer learning. Acta Photonica Sin. 2020, 49, 173–184. [Google Scholar]
- Li, Z.-M.; Gui, W.-H.; Zhu, J.-Y. Fault detection in flotation processes based on deep learning and support vector machine. J. Central South Univ. 2019, 26, 2504–2515. [Google Scholar] [CrossRef]
- Chen, Y.; Cai, Y.; Li, S. Antimony Flotation Condition Recognition Based on Lightweight Convolutional Visual Transformer. Adv. Laser Electron. 2023, 60, 0615002. [Google Scholar]
- Labate, D.; Lim, W.Q.; Kutyniok, G.; Weiss, G. Sparse multidimensional representation using shearlets. In Wavelets XI; SPIE: Philadelphia, PA, USA, 2005. [Google Scholar]
- Easley, G.; Labate, D.; Lim, W.Q. Sparse directional image representations using the discrete shearlet transform. Appl. Comput. Harmon. Anal. 2008, 25, 25–46. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Mei, W.; Du, H. A novel image fusion algorithm based non-subsampled shearlet transform and morphological component analysis. Signal Image Video Process. 2016, 10, 959–966. [Google Scholar] [CrossRef]
- Shahdoosti, H.R.; Khayat, O. Image denosing using spars representation classification and non-subsampled shearlet transform. Signal Image Video Process. 2016, 10, 1081–1087. [Google Scholar] [CrossRef]
- Wu, J.; Guo, R.; Liu, R.; Ke, Z. Convolutional neural target recognition for missileborne linear array LIDAR. Acta Phoronica Sin. 2019, 48, 0701002. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance -IoU Loss: Faster and better learning for bounding box regression. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Yu, Y. Research on Neonatal Pain Expression Recognition Based on LBP-TOP Feature. Master’s Thesis, Nanjing University of Posts and Telecommunications, Nanjing, China, 2016. [Google Scholar]
- Zhao, G.; Pietikainen, M. Dynamic Texture Recognition Using Local Binary Patterns with an Application to Facial Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, T. Research on Key Technologies of Face Micro-Expression Recognition Based on Video. Master’s Thesis, Southeast University, Nanjing, China, 2018. [Google Scholar]
- Li, Q. Research on Micro-Expression Detection and Recognition Technology Based on Video. Master’s Thesis, Southeast University, Nanjing, China, 2017. [Google Scholar]
- Guo, C. Research on Spontaneous Facial Micro-Expression Recognition Method. Master’s Thesis, National University of Defense Technology, Changsha, China, 2019. [Google Scholar]
- Huang, G.B. An insight into extreme learning machines: Random neurons, random features and kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Ankur, S.; Tharo, S.; Kalyanmoy, D. Using Karush-Kuhn-Tucker proximity measure for solving bilevel optimization problems. Swarm Evol. Comput. 2019, 44, 496–510. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the Icnn95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: New York, NY, USA, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Parsopoulos, K.E.; Vrahatis, M.N. Particle Swarm Optimization and Intelligence: Advances and Applications; IGI Global: Hershey, PA, USA, 2010; pp. 25–40. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activation Function | Number of Neurons | Accuracy (%) |
|---|---|---|
| Hardlim | 350 | 90.5 |
| Sine | 300 | 53.6 |
| Sigmoid | 400 | 91.1 |
| Radial basis | 450 | 81.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, X.; Zhao, H.; Liu, J.; Ma, S.; Hu, M. Research on Multi-Scale Feature Extraction and Working Condition Classification Algorithm of Lead-Zinc Ore Flotation Foam. Appl. Sci. 2023, 13, 4028. https://doi.org/10.3390/app13064028
Jiang X, Zhao H, Liu J, Ma S, Hu M. Research on Multi-Scale Feature Extraction and Working Condition Classification Algorithm of Lead-Zinc Ore Flotation Foam. Applied Sciences. 2023; 13(6):4028. https://doi.org/10.3390/app13064028
Chicago/Turabian StyleJiang, Xiaoping, Huilin Zhao, Junwei Liu, Suliang Ma, and Mingzhen Hu. 2023. "Research on Multi-Scale Feature Extraction and Working Condition Classification Algorithm of Lead-Zinc Ore Flotation Foam" Applied Sciences 13, no. 6: 4028. https://doi.org/10.3390/app13064028