
Selection of Potential Regions for the Creation of Intelligent Transportation Systems Based on the Machine Learning Algorithm Random Forest




Abstract
:1. Introduction
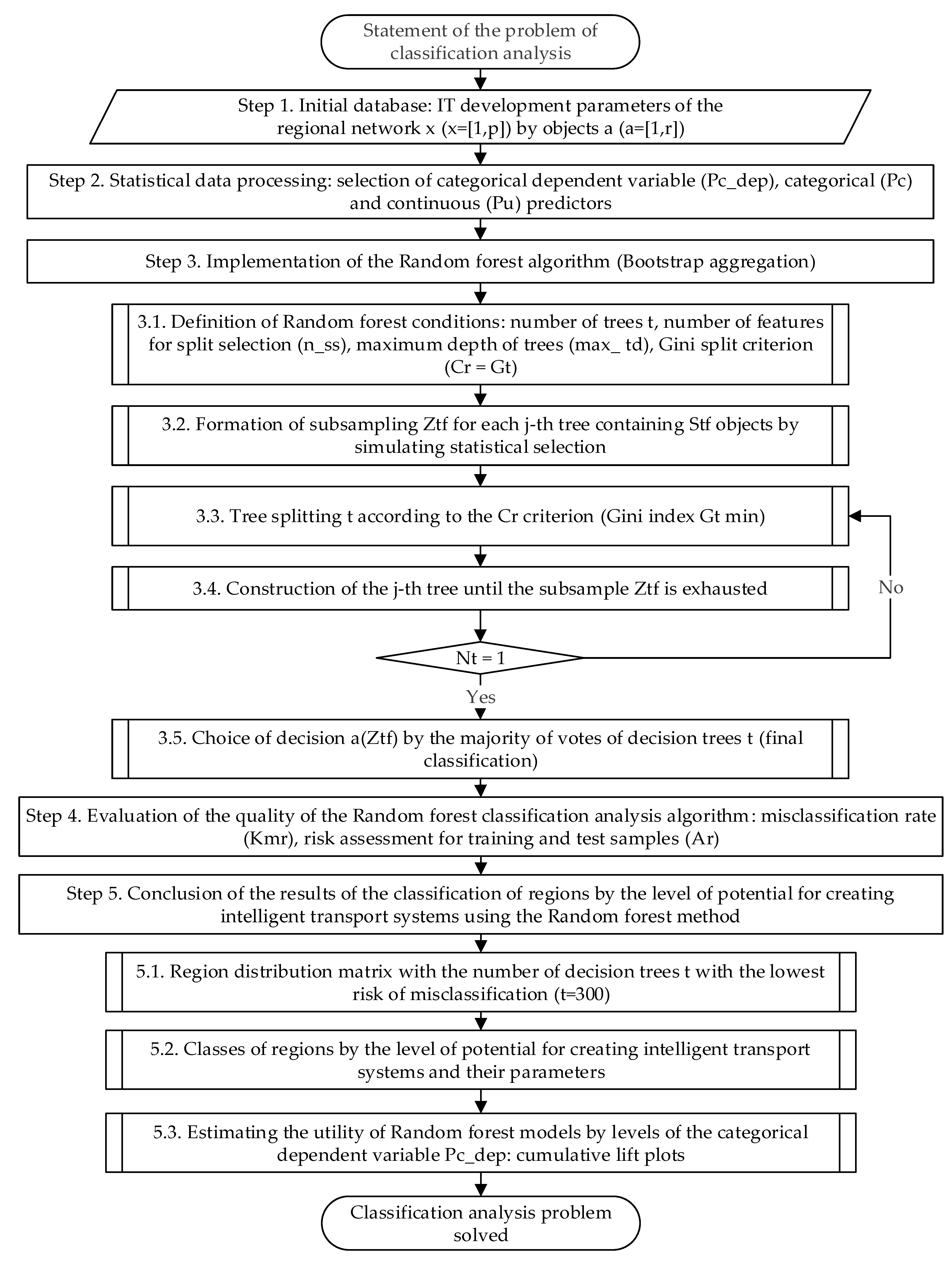
2. Methodology
- X1a—share of digitalization of telecommunication networks in region a:
- Tdiga—is the number of digital nodes in the telecommunication network in the region,
- Talla—is the total number of nodes in the telecommunication network in the region;
- X2a—is the gross product per capita in the region:
- Vpa—is the gross domestic product of the region.
- Pa—population in the region;
- X3a—proportion of digitalization of the regional telephone network:
- Cdiga—is the number of digital nodes in the telephone network in the region,
- Calla—is the total number of nodes in the telecommunication network in the region;
- X4a—is the share of investment in the reconstruction and modernization of infrastructure in the total investment in fixed capital:
- Iinfa—is the amount of investment for the reconstruction and modernization of infrastructure in the region,
- Iinfa—is the total amount of investment in the region,
- X5a—is the proportion of public roads that meet regulatory requirements:
- Rnorma—is the length of the public roads that meet regulatory requirements,
- Ralla—is the total length of public roads in the region,
- X6a—is the proportion of nondepreciated fixed assets in transport, communications, and information:
- Fana—is the value of nondepreciated fixed assets in transport, communications, and information in the region
- Falla—total value of fixed assets in transport, communications, and information in the region.
- Xav is the sample average of the indicator;
- Xi is the i-th element of the sampling frame for the indicator;
- n is the size of the sampling frame for the indicator.
- N—is the number of objects in the current tree node t (the «parent» node);
- N1 and N2—are the numbers of objects in vertices t1 and t2, corresponding to the left and right vertices (node «daughter») in the case of a binary tree.
- a(Ztf)—is the solution of the final classifier of the j-th tree t (j = 1, t);
- b(Ztf)—is the solution of the base classifier of the j-th tree (j = 1, t);
- sign—is a function that returns the sign of its argument.
- Ar—is an estimate of the risk of the object classification error;
- Prs—is the number of cases correctly classified by the tree;
- Ps—is the total number of times the objects are classified (sample size).
3. Results
3.1. Statistical Processing of Raw Data
3.2. Quality Assessment of the Random Forest Machine Learning Algorithm
3.3. Classes of Regions According to the Level of Capacity for Building Intelligent Transportation Systems Using the Random Forest Method
4. Conclusions
- The author’s methodology for sequential classification analysis for identifying objects with the potential to create intelligent transportation systems is proposed. The methodology is based on the random forest method of classifying trees using a bagging machine and a composite learning meta-algorithm. The choice of the method is justified by its best behavior, with a large number of predictor variables required for an objective aggregate assessment of digital development and the quality of territories. For the convenience of potential users, the method is presented as an algorithm of five key procedures: (1) setting the analysis task and forming the initial database; (2) statistical data processing based on descriptive analytics; (3) step-by-step implementation of the random forest algorithm by the ensemble bootstrap aggregation method; (4) quality assessment of the classification analysis algorithm based on the misclassification error rate and risk assessment for training and test samples; and (5) the output of the random forest method classification of regions by the level of intelligent transportation system creation potential.
- The proposed classification analysis algorithm is demonstrated using the example of selecting Russian regions for the creation of intelligent transportation systems. The procedure for statistical data processing based on descriptive analytics is shown. Continuous and classification predictors for random forest machine learning are defined from the set of basic indicators, taking into account the conditions of sample variance established in the methodology: Pc1—living standard of the population in the region; Pu2—share of digitalization of the regional telephone network; Pu3—share of investments aimed at reconstruction and modernization of the infrastructure in total investment in fixed capital; Pu4—share of public roads that meet regulatory requirements; and Pu5—the share of depreciated fixed assets in transport, communications, and information.
- The quality of the classification analysis algorithm is evaluated by the random forest method based on the misclassification coefficients. Analysis of the coefficients for all variants of the studied sets of solving trees (tmax = 50, 100, 150, 200, 250, 300, and 400) showed a low generalization ability of the learning algorithm due to its retraining. The reason for overtraining is the high complexity of the model due to the large amount of information, as well as the stochastic relationship between the predictors and the dependent categorical variable. The admissibility of retrained algorithms and the formation of the «fine-grained» random forest model for solving the classification problems under the condition of no prediction is proven. The optimal value of trees, tmax = 300, is established in view of the smallest estimate of the risk of misclassification.
- As a result of performing all the sequential procedures for constructing a random forest with the number of decision trees t = 300, the given sample of regions is classified into four classes according to the most informative continuous predictors (Pu3, Pu4, and Pu5). The classes formed by certain standards for the values of intelligent transportation system capacity are characterized. The numerical distribution of the population of regions in the form of a matrix is presented. The cumulative lift diagrams to assess the probability of assigning an object to a class, utility, and performance of random forest class models are constructed. Based on logistic regression analysis of the relationship between predictors and the categorical dependent variable, the Pc_dep «reached» and Pc_dep «finalized» models obtained are the most productive with the highest probability of correct classification.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Alex, C.; Pierre-Olivier, V.; Romain, N. Enhancement of Vehicle Eco-Driving Applicability through Road Infrastructure Design and Exploitation. Vehicles 2023, 5, 367–386. [Google Scholar] [CrossRef]
- Cao, B.; Shahraki, A.A. Planning of Transportation Infrastructure Networks for Sustainable Development with Case Studies in Chabahar. Sustainability 2023, 15, 5154. [Google Scholar] [CrossRef]
- Kim, D.; Kwon, D.; Han, J.; Lee, S.M.; Elkosantini, S.; Suh, W. Data-Driven Model for Identifying Factors Influencing Electric Vehicle Charging Demand: A Comparative Analysis of Early- and Maturity-Phases of Electric Vehicle Programs in Korea. Appl. Sci. 2023, 13, 3760. [Google Scholar] [CrossRef]
- Wang, J.; Yang, X.; Kumari, S. Investigating the Spatial Spillover Effect of Transportation Infrastructure on Green Total Factor Productivity. Energies 2023, 16, 2733. [Google Scholar] [CrossRef]
- De Fabiis, F.; Mancuso, A.C.; Silvestri, F.; Coppola, P. Spatial Economic Impacts of the TEN-T Network Extension in the Adriatic and Ionian Region. Sustainability 2023, 15, 5126. [Google Scholar] [CrossRef]
- Efron, B. Resampling Plans and the Estimation of Prediction Error. Stats 2021, 4, 1091–1115. [Google Scholar] [CrossRef]
- Mohammed, G.P.; Alasmari, N.; Alsolai, H.; Alotaibi, S.S.; Alotaibi, N.; Mohsen, H. Autonomous Short-Term Traffic Flow Prediction Using Pelican Optimization with Hybrid Deep Belief Network in Smart Cities. Appl. Sci. 2022, 12, 10828. [Google Scholar] [CrossRef]
- Malysheva, T.; Shinkevich, A.; Ostanin, L.; Zhandarova, L.; Muzhzhavleva, T.; Kandrashina, E. Organization challenges of competitive petrochemical products production. Espacios 2018, 39, 28. [Google Scholar]
- Quessada, M.; Pereira, R.; Revejes, W. ITSMEI: An intelligent transport system for monitoring traffic and event information. Int. J. Distrib. Sens. Netw. 2020, 16, 1550147720963751. [Google Scholar] [CrossRef]
- Andrade, J.L.; Valencia, J.L. A Fuzzy Random Survival Forest for Predicting Lapses in Insurance Portfolios Containing Imprecise Data. Mathematics 2022, 11, 198. [Google Scholar] [CrossRef]
- Makond, B.; Pornsawad, P.; Thawnashom, K. Decision Tree Modeling for Osteoporosis Screening in Postmenopausal Thai Women. Informatics 2022, 9, 83. [Google Scholar] [CrossRef]
- Rajawat, A.S.; Goyal, S.B.; Bedi, P.; Verma, C.; Ionete, E.I.; Raboaca, M.S. 5G-Enabled Cyber-Physical Systems for Smart Transportation Using Blockchain Technology. Mathematics 2023, 11, 679. [Google Scholar] [CrossRef]
- Ahmed Hamza, M.; Alqahtani, H.; Elkamchouchi, D.H.; Alshahrani, H.; Alzahrani, J.S.; Maray, M.; Ahmed Elfaki, M.; Aziz, A.S.A. Hyperparameter Tuned Deep Autoencoder Model for Road Classification Model in Intelligent Transportation Systems. Appl. Sci. 2022, 12, 10605. [Google Scholar] [CrossRef]
- Alanazi, F. A Systematic Literature Review of Autonomous and Connected Vehicles in Traffic Management. Appl. Sci. 2023, 13, 1789. [Google Scholar] [CrossRef]
- Zadobrischi, E.; Dimian, M. Vehicular Communications Utility in Road Safety Applications: A Step toward Self-Aware Intelligent Traffic Systems. Symmetry 2021, 13, 438. [Google Scholar] [CrossRef]
- Kaja, H.; Beard, C. A Multi-Layered Reliability Approach in Vehicular Ad-Hoc Networks. Int. J. Interdiscip. Telecommun. Netw. 2020, 12, 132–140. [Google Scholar] [CrossRef]
- Mohapatra, S.; Mohanachandran, D.; Dwivedi, G.; Kesharvani, S.; Harish, V.S.K.V.; Verma, S.; Verma, P. A Comprehensive Study on the Sustainable Transportation System in India and Lessons to Be Learned from Other Developing Nations. Energies 2023, 16, 1986. [Google Scholar] [CrossRef]
- Zhang, X.; Han, D.; Zhang, X.; Fang, L. Design and Application of Intelligent Transportation Multi-Source Data Collabora-tion Framework Based on Digital Twins. Appl. Sci. 2023, 13, 1923. [Google Scholar] [CrossRef]
- Almalaq, A.; Albadran, S.; Mohamed, M.A. Deep Machine Learning Model-Based Cyber-Attacks Detection in Smart Power Systems. Mathematics 2022, 10, 2574. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Fu, E.; Tang, S. Multiscale Backcast Convolution Neural Network for Traffic Flow Prediction in The Frequency Domain. Appl. Sci. 2022, 12, 11912. [Google Scholar] [CrossRef]
- Subramani, N.; Easwaramoorthy, S.; Mohan, P.; Subramanian, M.; Sambath, V. A Gradient Boosted Decision Tree-Based In-fluencer Prediction in Social Network Analysis. Mathematics 2023, 7, 6. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2009; p. 533. [Google Scholar]
- Al-Turjman, F.; Lemayian, J. Intelligence, security, and vehicular sensor networks in internet of things (IoT)-enabled smart-cities: An overview. Comput. Electr. Eng. 2020, 87, 106776. [Google Scholar] [CrossRef]
- Lin, T.-H.; Jiang, J.-R. Credit Card Fraud Detection with Autoencoder and Probabilistic Random Forest. Mathematics 2021, 9, 2683. [Google Scholar] [CrossRef]
- Khoei, T.T.; Ismail, S.; Al Shamaileh, K.; Devabhaktuni, V.K.; Kaabouch, N. Impact of Dataset and Model Parameters on Machine Learning Performance for the Detection of GPS Spoofing Attacks on Unmanned Aerial Vehicles. Appl. Sci. 2022, 13, 383. [Google Scholar] [CrossRef]
- Azeez, N.; Odufuwa, O.; Misra, S.; Oluranti, J.; Damaševičius, R. Windows PE Malware Detection Using Ensemble Learning. Informatics 2021, 8, 10. [Google Scholar] [CrossRef]
- Mazhar, T.; Asif, R.N.; Malik, M.A.; Nadeem, M.A.; Haq, I.; Iqbal, M.; Kamran, M.; Ashraf, S. Electric Vehicle Charging System in the Smart Grid Using Different Machine Learning Methods. Sustainability 2023, 15, 2603. [Google Scholar] [CrossRef]
- Behrooz, H.; Hayeri, Y.M. Machine Learning Applications in Surface Transportation Systems: A Literature Review. Appl. Sci. 2022, 12, 9156. [Google Scholar] [CrossRef]
- Brennand, C.A.R.L.; Filho, G.P.R.; Maia, G.; Cunha, F.; Guidoni, D.L.; Villas, L.A. Towards a Fog-Enabled Intelligent Transportation System to Reduce Traffic Jam. Sensors 2019, 19, 3916. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Zheng, D.; Liu, Y.; Wu, X.; Jiang, H.; Qiu, J. Multiaxial Strength Criterion Model of Concrete Based on Random Forest. Mathematics 2023, 11, 244. [Google Scholar] [CrossRef]
- De Morais, G.R.; Calil, Y.C.D.; de Oliveira, G.F.; Saldanha, R.R.; Andrey Maia, C. A Sustainable Location Model of Transshipment Terminals Applied to the Expansion Strategies of the Soybean Intermodal Transport Network in the State of Mato Grosso, Brazil. Sustainability 2023, 15, 1063. [Google Scholar] [CrossRef]
- Cornelius, E.; Akman, O.; Hrozencik, D. COVID-19 Mortality Prediction Using Machine Learning-Integrated Random Forest Algorithm under Varying Patient Frailty. Mathematics 2021, 9, 2043. [Google Scholar] [CrossRef]
- Zou, H.; Cao, K.; Jiang, C. Spatio-Temporal Visual Analysis for Urban Traffic Characters Based on Video Surveillance Camera Data. ISPRS Int. J. Geo-Inf. 2021, 10, 177. [Google Scholar] [CrossRef]
- Dushkin, R. Intelligent Transport Systems; DMK Press: Moscow, Russia, 2020; p. 282. [Google Scholar]
- Elagin, V.; Spirkina, A.; Buinevich, M.; Vladyko, A. Technological Aspects of Blockchain Application for Vehicle-to-Network. Information 2020, 11, 465. [Google Scholar] [CrossRef]
- Farag, M.M.G.; Rakha, H.A. Development and Evaluation of a Cellular Vehicle-to-Everything Enabled Energy-Efficient Dynamic Routing Application. Sensors 2023, 23, 2314. [Google Scholar] [CrossRef] [PubMed]
- Faroqi, H.; Mesbah, M.; Kim, J. Behavioural advertising in the public transit network. Res. Transp. Bus. Manag. 2019, 32, 100421. [Google Scholar] [CrossRef]
- Federal State Statistics Service. Available online: http://www.gks.ru (accessed on 25 December 2022).
- Gkikas, D.C.; Theodoridis, P.K.; Beligiannis, G.N. Enhanced Marketing Decision Making for Consumer Behaviour Classification Using Binary Decision Trees and a Genetic Algorithm Wrapper. Informatics 2022, 9, 45. [Google Scholar] [CrossRef]
- Paz, H.; Maia, M.; Moraes, F.; Lustosa, R.; Costa, L.; Macêdo, S.; Barreto, M.E.; Ara, A. Local Processing of Massive Databases with R: A National Analysis of a Brazilian Social Programme. Stats 2020, 3, 444–464. [Google Scholar] [CrossRef]
- Kovalnogov, V.; Fedorov, R.; Klyachkin, V.; Generalov, D.; Kuvayskova, Y.; Busygin, S. Applying the Random Forest Method to Improve Burner Efficiency. Mathematics 2022, 10, 2143. [Google Scholar] [CrossRef]
- Li, X.; Qin, B.; Luo, Y.; Zheng, D. A Differential Privacy Budget Allocation Algorithm Based on Out-of-Bag Estimation in Random Forest. Mathematics 2022, 10, 4338. [Google Scholar] [CrossRef]
- Mallidis, I.; Yakavenka, V.; Konstantinidis, A.; Sariannidis, N. A Goal Programming-Based Methodology for Machine Learning Model Selection Decisions: A Predictive Maintenance Application. Mathematics 2021, 9, 2405. [Google Scholar] [CrossRef]
- Malysheva, T.; Kudryavceva, S. Use of Data Mining technologies in solving the problems of developing resource-saving environmentally-oriented production systems. MMTT 2020, 3, 143–148. [Google Scholar]
- Petrov, T.; Pocta, P.; Kovacikova, T. Benchmarking 4G and 5G-Based Cellular-V2X for Vehicle-to-Infrastructure Communication and Urban Scenarios in Cooperative Intelligent Transportation Systems. Appl. Sci. 2022, 12, 9677. [Google Scholar] [CrossRef]
- Mateichyk, V.; Kostian, N.; Smieszek, M.; Mosciszewski, J.; Tarandushka, L. Evaluating Vehicle Energy Efficiency in Urban Transport Systems Based on Fuzzy Logic Models. Energies 2023, 16, 734. [Google Scholar] [CrossRef]
- Ntafloukas, K.; McCrum, D.P.; Pasquale, L. A Cyber-Physical Risk Assessment Approach for Internet of Things Enabled Transportation Infrastructure. Appl. Sci. 2022, 12, 9241. [Google Scholar] [CrossRef]
- Shen, P.; Yin, P.; Niu, B. Assessing the Combined Effects of Transportation Infrastructure on Regional Tourism Development in China Using a Spatial Econometric Model (GWPR). Land 2023, 12, 216. [Google Scholar] [CrossRef]
- Shinkevich, A.; Malysheva, T.; Ryabinina, E.; Morozova, V.; Sokolova, N.; Vasileva, A.; Ishmuradova, I. Formation of network model of value added chain based on integration of competitive enterprises in innovation-oriented cross-sectorial clusters. Int. J. Environ. Sci. Educ. 2016, 11, 10347–10364. [Google Scholar]
- Shinkevich, A.I.; Malysheva, T.V.; Vertakova, Y.V.; Plotnikov, V.A. Optimization of Energy Consumption in Chemical Production Based on Descriptive Analytics and Neural Network Modeling. Mathematics 2021, 9, 322. [Google Scholar] [CrossRef]
- Taisheva, G.; Ismagilova, E. System-logistic approach in the field of recycling of municipal solid waste in the Chuvash republic. In Proceedings of the International Scientific and Practical Conference on Sustainable Development of Regional Infrastructure (ISSDRI 2021), Yekaterinburg, Russia, 14–15 March 2021; pp. 305–311. [Google Scholar]
- Tékouabou, S.C.K.; Gherghina, C.; Toulni, H.; Mata, P.N.; Martins, J.M. Towards Explainable Machine Learning for Bank Churn Prediction Using Data Balancing and Ensemble-Based Methods. Mathematics 2022, 10, 2379. [Google Scholar] [CrossRef]
- Wu, S.; Xiang, W.; Li, W.; Chen, L.; Wu, C. Dynamic Scheduling and Optimization of AGV in Factory Logistics Systems Based on Digital Twin. Appl. Sci. 2023, 13, 1762. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, W.; Liu, L.; Ren, J.; Wang, L. Three-Branch Random Forest Intrusion Detection Model. Mathematics 2022, 10, 4460. [Google Scholar] [CrossRef]
- Zhao, L.; Zhu, Y.; Zhao, T. Deep Learning-Based Remaining Useful Life Prediction Method with Transformer Module and Random Forest. Mathematics 2022, 10, 2921. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| X1 | X2 | X3 | X4 | X5 | X6 | |
|---|---|---|---|---|---|---|
| Sampling variance (Sv) | 1.12 | 5439.97 × 108 | 60.10 | 68.87 | 285.09 | 60.13 |
| Standard error (Es) | 0.12 | 80,474.63 | 0.85 | 0.91 | 1.84 | 0.85 |
| Standard deviation (Ds) | 1.06 | 737,562.14 | 7.75 | 8.30 | 16.88 | 7.75 |
| Average (Av) | 2.24 | 635,182.02 | 94.86 | 19.07 | 44.79 | 40.71 |
| Excess (Ex) | −1.00 | 27.81 | 9.60 | −0.03 | 0.45 | −0.34 |
| Asymmetry (As) | 0.44 | 4.71 | −2.60 | 0.41 | 0.25 | 0.23 |
| Interval (Int) | 3.00 | 5,564,744.30 | 47.00 | 40.40 | 91.32 | 35.60 |
| Minimum (Min) | 1.00 | 145,723.10 | 53.00 | 2.90 | 5.70 | 25.30 |
| Maximum (Max) | 4.00 | 5,710,467.40 | 100.00 | 43.30 | 97.03 | 60.90 |
| Number of objects (Ra) | 84 | 84 | 84 | 84 | 84 | 84 |
| Number of Trees in Random Forest (tmax) | Name of Sample | Risk Assessment (Ar) | Standard Error (Es) |
|---|---|---|---|
| 50 | Train data | 0.074835 | 0.003651 |
| Test data | 0.579786 | 0.009371 | |
| 100 | Train data | 0.037389 | 0.002632 |
| Test data | 0.507696 | 0.009492 | |
| 150 | Train data | 0.056641 | 0.003207 |
| Test data | 0.507696 | 0.009492 | |
| 200 | Train data | 0.054273 | 0.003144 |
| Test data | 0.507696 | 0.009492 | |
| 250 | Train data | 0.054273 | 0.003144 |
| Test data | 0.471651 | 0.009478 | |
| 300 | Train data | 0.073526 | 0.003621 |
| Test data | 0.471651 | 0.009478 | |
| 400 | Train data | 0.054273 | 0.003144 |
| Test data | 0.506362 | 0.009492 |
| Name of Decisive Variables | Class 1 «High Capacity to Create ITS» | Class 2 «Average Capacity to Create ITS» | Class 3 «Low Capacity to Create ITS» | Class 4 «Creating an ITS Is not Feasible» | |
|---|---|---|---|---|---|
| Share of digitalization of telecommunication networks in the region, % | Pc_dep | 100.0 | 95.0 < Pc_dep < 100.0 | 90.0 < Pc_dep < 95.0 | Pc_dep < 90.0 |
| share of investments in reconstruction and modernization of infrastructure in the total volume of investments in fixed assets, % (group average) | Pu3 | 18.90 | 19.20 | 19.90 | 18.30 |
| proportion of public roads that meet regulatory requirements, % (group average), | Pu4 | 44.80 | 42.70 | 47.50 | 46.60 |
| share of nondepreciated fixed assets in transportation, communications, and information, % (group average) | Pu5 | 42.16 | 41.03 | 37.49 | 40.72 |
| Pc_dep Variable Level | Class 1 «High Capacity to Create ITS » | Class 2 «Average Capacity to Create ITS» | Class 3 «Low Capacity to Create ITS» | Class 4 «Creating an ITS Is Not Feasible» | Distribution of Regions by Pc_dep Level, % |
|---|---|---|---|---|---|
| Reached | |||||
| Share in Class 1–4, % | 85.84 | 20.82 | 17.98 | 51.41 | 36.00 |
| Share in reached, % | 50.00 | 30.00 | 10.00 | 10.00 | |
| Final | |||||
| Share in Class 1–4, % | 0.00 | 54.24 | 17.84 | 0.00 | 31.00 |
| Share in final, % | 0.00 | 88.74 | 11.26 | 0.00 | |
| Prefinal | |||||
| Share in Class 1–4, % | 0.00 | 19.17 | 33.10 | 48.59 | 20.00 |
| Share in prefinal, % | 0.00 | 49.78 | 33.18 | 17.03 | |
| Project | |||||
| Share in Class 1–4, % | 14.16 | 5.77 | 31.09 | 0.00 | 13.00 |
| Share in project, % | 24.37 | 24.57 | 51.06 | 0.00 | |
| Distribution of regions by ITS capacity (Grades 1–4), % | 21.00 | 52.00 | 20.00 | 7.00 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shinkevich, A.I.; Malysheva, T.V.; Ershova, I.G. Selection of Potential Regions for the Creation of Intelligent Transportation Systems Based on the Machine Learning Algorithm Random Forest. Appl. Sci. 2023, 13, 4024. https://doi.org/10.3390/app13064024
Shinkevich AI, Malysheva TV, Ershova IG. Selection of Potential Regions for the Creation of Intelligent Transportation Systems Based on the Machine Learning Algorithm Random Forest. Applied Sciences. 2023; 13(6):4024. https://doi.org/10.3390/app13064024
Chicago/Turabian StyleShinkevich, Aleksey I., Tatyana V. Malysheva, and Irina G. Ershova. 2023. "Selection of Potential Regions for the Creation of Intelligent Transportation Systems Based on the Machine Learning Algorithm Random Forest" Applied Sciences 13, no. 6: 4024. https://doi.org/10.3390/app13064024