
Fuzzy Windows with Gaussian Processed Labels for Ordinal Image Scoring Tasks

Abstract
:1. Introduction
- We directly face the internal challenge of the ordinal image classification task and clarify the theoretical reason why the ordinal image classification task is difficult.
- FW-GPL can indirectly reduce the influence of the overlapping features among the ordinal neighbor classes. This process can effectively improve the scoring performance of the ordinal images.
- When the ordinal sequence of the images is not consecutive, FW-GPL can achieve an equivalent performance to wholly sequential ordinal data by setting a proper length for the fuzzy window.
2. Related Work
2.1. Ordinal Classification
2.2. Windows for Ordinal Classification
2.3. Fuzzy Scoring for Ordinal Classification
2.4. Soft Labels and Gaussian Processes
3. Our Method
3.1. Normalized Gaussian Processed Labels
3.2. Fuzzy Windows with Normalized Gaussian Processed Labels
| Algorithm 1 Fuzzy Windows with Normalized Gaussian Processed Labels |
 |
4. Experiments
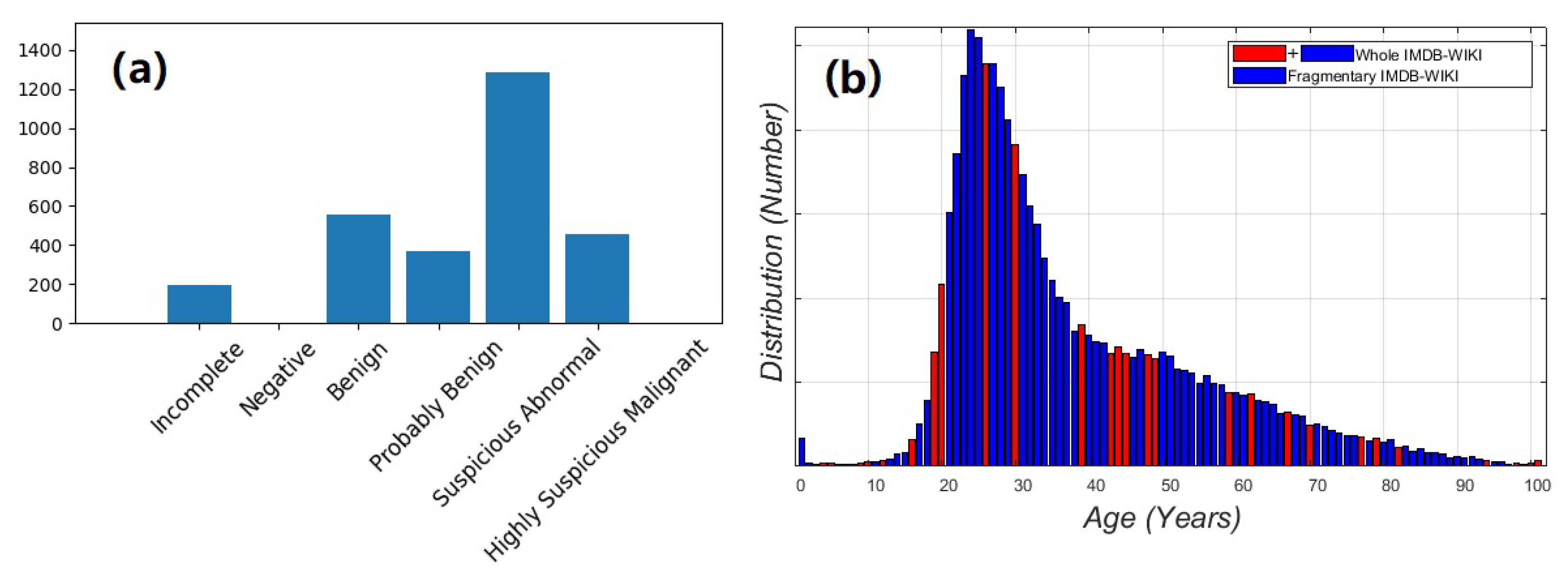
4.1. Datasets
4.1.1. Ordinal Medical Dataset
4.1.2. Facial-Age Estimation Datasets
4.2. Evaluation Metrics
4.3. Experiment Settings
| Algorithm 2 Training |
 |
4.4. Hardware and Software
5. Results and Analysis
5.1. Scoring Breast Cancer Images
5.2. Scoring Facial-Age Images
6. Ablation and Discussion
6.1. Ablation Study I (Influence of the Number of Neurons)
6.2. Ablation Study II (Influence of the Length of the Window )
6.3. Ablation Study III (Incomplete Ordinal Image Data)
6.4. Advantage and Limitation
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MDD | Major Depressive Disorder |
| FW-GPL | Fuzzy Window with the Gaussian Processed Labels |
| GP | Gaussian Processed |
| SCID-CV | DSM-IV Axis I Disorders, Clinician Version |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| BI-RADS | Breast Imaging-Reporting and Data System |
| IMDB | Internet Movie Database |
| WIKI | Wikipedia |
| FG-NET | Face and Gesture Recognition Research Network |
| MORPH-2 | Craniofacial Longitudinal Morphological Face Database II |
| CACD | Cross-Age Celebrity Dataset |
| FFCL | Fuzzy Fully Connected Layer |
| CBIS-DDSM | Curated Breast Imaging Subset of Digital Database of Screening Mammography |
| SOTA | State-Of-The-Art |
| RMSE | Root-Mean-Square Error |
| SLL-Loss | Single Label Learning with Specific Loss |
| OR-CNN | Ordinal Regression CNN |
| LDBL | Label Distribution Based Learning |
| DEX | Deep Expectation |
| DLDL | Deep Label Distribution Learning |
| DLDL-V2 | Deep Label Distribution Learning V2 |
| FGSM | Fast Gradient Sign Method |
| GDD | Gradients Decent Direction |
| FG-NET | Face and Gesture Recognition Research Network |
| MORPH | Craniofacial Longitudinal Morphological Face Database |
| CACD | Cross-Age Celebrity Dataset |
| MAE | Mean Absolute Error |
| ACC | Accuracy |
| MV | Mean Variance |
| SSR | Soft Stagewise Regression |
| C3AE | Compact yet efficient Cascade Context-based Age Estimation |
References
- Tutz, G. Ordinal regression: A review and a taxonomy of models. Wiley Interdiscip. Rev. Comput. Stat. 2022, 14, e1545. [Google Scholar] [CrossRef]
- Gao, B.B.; Liu, X.X.; Zhou, H.Y.; Wu, J.; Geng, X. Learning Expectation of Label Distribution for Facial Age and Attractiveness Estimation. arXiv 2020, arXiv:2007.01771. [Google Scholar]
- Pan, H.; Hu, H.; Shan, S.; Chen, X. Mean-Variance Loss for Deep Age Estimation from a Face. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhang, C.; Liu, S.; Xu, X.; Zhu, C. C3AE: Exploring the limits of compact model for age estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 12587–12596. [Google Scholar]
- Yang, T.Y.; Huang, Y.H.; Lin, Y.Y.; Hsiu, P.C.; Chuang, Y.Y. Ssr-net: A compact soft stagewise regression network for age estimation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; Volume 5, p. 7. [Google Scholar]
- Shen, W.; Guo, Y.; Wang, Y.; Zhao, K.; Wang, B.; Yuille, A.L. Deep Regression Forests for Age Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2304–2313. [Google Scholar]
- Liu, Y.; Wang, F.; Kong, A.W.K. Probabilistic deep ordinal regression based on Gaussian processes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5301–5309. [Google Scholar]
- Zhou, Y.; He, J.; Gu, H. Partial label learning via Gaussian processes. IEEE Trans. Cybern. 2016, 47, 4443–4450. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.Y.; Liu, S.; Li, B.; Guo, Z.; Samal, A.; Wan, J.; Li, S.Z. Label distribution-based facial attractiveness computation by deep residual learning. IEEE Trans. Multimed. 2017, 20, 2196–2208. [Google Scholar] [CrossRef] [Green Version]
- Wen, X.; Li, B.; Guo, H.; Liu, Z.; Hu, G.; Tang, M.; Wang, J. Adaptive Variance Based Label Distribution Learning for Facial Age Estimation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Berg, A.; Oskarsson, M.; O’Connor, M. Deep ordinal regression with label diversity. In Proceedings of the 2021 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2740–2747. [Google Scholar]
- Li, W.; Huang, X.; Lu, J.; Feng, J.; Zhou, J. Learning probabilistic ordinal embeddings for uncertainty-aware regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13896–13905. [Google Scholar]
- Chen, G.; Peng, J.; Wang, L.; Yuan, H.; Huang, Y. Feature constraint reinforcement based age estimation. Multimed. Tools Appl. 2022. [Google Scholar] [CrossRef]
- Ricanek, K.; Tesafaye, T. MORPH: A longitudinal image database of normal adult age-progression. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 341–345. [Google Scholar] [CrossRef]
- Panis, G.; Lanitis, A. An Overview of Research Activities in Facial Age Estimation Using the FG-NET Aging Database; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Chen, B.C.; Chen, C.S.; Hsu, W.H. Face Recognition and Retrieval Using Cross-Age Reference Coding With Cross-Age Celebrity Dataset. IEEE Trans. Multimed. 2015, 17, 804–815. [Google Scholar] [CrossRef]
- Kang, C.; Yu, X.; Wang, S.H.; Guttery, D.S.; Pandey, H.M.; Tian, Y.; Zhang, Y.D. A heuristic neural network structure relying on fuzzy logic for images scoring. IEEE Trans. Fuzzy Syst. 2020, 29, 34–45. [Google Scholar] [CrossRef] [Green Version]
- Shin, N.H.; Lee, S.H.; Kim, C.S. Moving window regression: A novel approach to ordinal regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18760–18769. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Evaluation measures for ordinal regression. In Proceedings of the 2009 Ninth International Conference on Intelligent Systems Design and Applications, Pisa, Italy, 30 November–2 December 2009; pp. 283–287. [Google Scholar]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Rothe, R.; Timofte, R.; Van Gool, L. Dex: Deep expectation of apparent age from a single image. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 10–15. [Google Scholar]
- Niu, Z.; Zhou, M.; Wang, L.; Gao, X.; Hua, G. Ordinal regression with multiple output cnn for age estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4920–4928. [Google Scholar]
- Cao, W.; Mirjalili, V.; Raschka, S. Rank consistent ordinal regression for neural networks with application to age estimation. Pattern Recognit. Lett. 2020, 140, 325–331. [Google Scholar] [CrossRef]
- Rothe, R.; Timofte, R.; Van Gool, L. Deep expectation of real and apparent age from a single image without facial landmarks. Int. J. Comput. Vis. 2018, 126, 144–157. [Google Scholar] [CrossRef] [Green Version]
- Gámez, J.C.; Garcia, D.; González, A.; Perez, R. An approximation to solve regression problems with a genetic fuzzy rule ordinal algorithm. Appl. Soft Comput. 2019, 78, 13–28. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; Alcalá, R.; González, S.; Nojima, Y.; García, S. Evolutionary fuzzy rule-based methods for monotonic classification. IEEE Trans. Fuzzy Syst. 2017, 25, 1376–1390. [Google Scholar] [CrossRef]
- Vega, R.; Gorji, P.; Zhang, Z.; Qin, X.; Rakkunedeth, A.; Kapur, J.; Jaremko, J.; Greiner, R. Sample efficient learning of image-based diagnostic classifiers via probabilistic labels. In Proceedings of the International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 13–15 April 2021; pp. 739–747. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Gao, B.B.; Xing, C.; Xie, C.W.; Wu, J.; Geng, X. Deep label distribution learning with label ambiguity. IEEE Trans. Image Process. 2017, 26, 2825–2838. [Google Scholar] [CrossRef] [Green Version]
- Geng, X. Label distribution learning. IEEE Trans. Knowl. Data Eng. 2016, 28, 1734–1748. [Google Scholar] [CrossRef] [Green Version]
- Imani, E.; White, M. Improving regression performance with distributional losses. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2157–2166. [Google Scholar]
- Chu, W.; Ghahramani, Z.; Williams, C.K. Gaussian processes for ordinal regression. J. Mach. Learn. Res. 2005, 6, 1019–1041. [Google Scholar]
- Liu, H.; Lu, J.; Feng, J.; Zhou, J. Ordinal deep feature learning for facial age estimation. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 157–164. [Google Scholar]
- Zhang, Z.; Lai, C.; Liu, H.; Li, Y.F. Infrared facial expression recognition via Gaussian-based label distribution learning in the dark illumination environment for human emotion detection. Neurocomputing 2020, 409, 341–350. [Google Scholar] [CrossRef]
- Rajasekhar, G.P.; Granger, E.; Cardinal, P. Deep domain adaptation with ordinal regression for pain assessment using weakly-labeled videos. Image Vis. Comput. 2021, 110, 104167. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, C.; Dong, M.; Le, J.; Rao, M. Using ranking-cnn for age estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5183–5192. [Google Scholar]
- Chen, S.; Zhang, C.; Dong, M. Deep age estimation: From classification to ranking. IEEE Trans. Multimed. 2017, 20, 2209–2222. [Google Scholar] [CrossRef]
- Li, K.; Xing, J.; Hu, W.; Maybank, S.J. D2C: Deep cumulatively and comparatively learning for human age estimation. Pattern Recognit. 2017, 66, 95–105. [Google Scholar] [CrossRef] [Green Version]
- Tan, Z.; Zhou, S.; Wan, J.; Lei, Z.; Li, S.Z. Age estimation based on a single network with soft softmax of aging modeling. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2016; pp. 203–216. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. arXiv 2017, arXiv:1607.02533. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9185–9193. [Google Scholar]
- Hodson, T.O. Root-mean-square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the mean root square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Geras, K.J.; Wolfson, S.; Shen, Y.; Wu, N.; Kim, S.; Kim, E.; Heacock, L.; Parikh, U.; Moy, L.; Cho, K. High-resolution breast cancer screening with multi-view deep convolutional neural networks. arXiv 2017, arXiv:1703.07047. [Google Scholar]
- Akselrod-Ballin, A.; Karlinsky, L.; Alpert, S.; Hasoul, S.; Ben-Ari, R.; Barkan, E. A region based convolutional network for tumor detection and classification in breast mammography. In Deep Learning and Data Labeling for Medical Applications; Springer: Berlin/Heidelberg, Germany, 2016; pp. 197–205. [Google Scholar]
- Lin, Y.; Shen, J.; Wang, Y.; Pantic, M. FP-Age: Leveraging Face Parsing Attention for Facial Age Estimation in the Wild. arXiv 2021, arXiv:2106.11145. [Google Scholar] [CrossRef]
- Deng, Z.; Liu, H.; Wang, Y.; Wang, C.; Yu, Z.; Sun, X. PML: Progressive Margin Loss for Long-tailed Age Classification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 10498–10507. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | |||||||
|---|---|---|---|---|---|---|---|
| Probability Outputs | 0.19 | 0.1 | 0.01 | 0.4 | 0.18 | 0.09 | 0.03 |
| Original Labels | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| Errors | 0.19 | 0.1 | 0.01 | −0.6 | 0.18 | 0.09 | 0.03 |
| Gaussian Window | 0 | 0.05 | 0.1 | 0.7 | 0.1 | 0.05 | 0 |
| Gaussian Labels | 0 | 0.07 | 0.14 | 1 | 0.14 | 0.07 | 0 |
| 0.19 | 0.03 | −0.13 | −0.6 | 0.04 | 0.02 | 0.03 |
| Scores (BI-RADS) | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| Training Set (Mass + Calcification) | 192 (129 + 63) | 1 | 559 (77 + 482) | 368 (279 + 89) | 1286 (533 + 753) | 458 (299 + 159) |
| Testing Set (Mass + Calcification) | 46 (33 + 13) | 2 | 85 (14 + 71) | 109 (85 + 24) | 347 (169 + 178) | 115 (75 + 40) |
| Datasets Name | Train | Test | Val | Total | Label Range |
|---|---|---|---|---|---|
| IMDB-WIKI | 260,282 | ⊗ | ⊗ | 523,051 | 0–100 |
| FG-NET | 990 | 12 | ⊗ | 1002 | 0–69 |
| MORPH 2 | 4380 | 1095 | ⊗ | 5475 | 16–70 |
| CACD | 145,275 | 10571 | 7600 | 163,446 | ⊗ |
| Method | CNN + FCL | CNN + FFCL | CNN + W-GPL |
|---|---|---|---|
| Geras [47] (BI-RADS: 0/1/2) | 68.8% | 70.1% | 70.3% |
| Akselrod-Ballin [48] (BI-RADS: 2/(3-4-5)) | 60.0% | 62.3% | 62.4% |
| Kang [17] (BI-RADS: 0/(2-3)/(4-5)) | 72.0% | 74.1% | 74.2% |
| Kang [17] (BI-RADS: 0/1/2/3/4/5) | 56.34% ±1.4% | 57.40% ±1.7% | 58.29% ±1.9% |
| Type | Method | MORPH 2 | FG-NET | CACD | Paras |
|---|---|---|---|---|---|
| Bulky | DEX [21] | 3.25 | 4.63 | - | 138 M |
| DEX * [21] | 2.68 | 3.09 | 6.52 | 138 M | |
| MV [3] | 2.41 | 4.10 | - | 138 M | |
| MV * [3] | 2.16 | 2.68 | - | 138 M | |
| DLDL-v2 [2] | 1.969 | - | - | 138 M | |
| FP-Age [49] | 2.04 | 5.60 | 5.60 | 138 M | |
| FP-Age * [49] | 1.90 | 4.68 | 4.33 | 138 M | |
| DRF [6] | 2.80 | 3.47 | 5.63 | - | |
| PML [50] | 2.31 | 2.16 | - | - | |
| JREAE [13] | 2.71 | 3.390 | 4.596 | - | |
| MWR [18] | 2.13 | - | 5.68 | - | |
| FW-GPL [Ours] | 2.71 | 4.27 | - | 138 M | |
| FW-GPL * [Ours] | 2.24 | 2.73 | 6.10 | 138 M | |
| Compact | ORCNN [3] | 3.27 | 6.44 | - | 479.7 K |
| MRCNN [3] | 3.42 | - | - | 479.7 K | |
| SSR [5] | 3.16 | - | - | 40.9 K | |
| C3AE [4] | 2.78 | 4.09 | - | 39.7 K | |
| C3AE * [4] | 2.75 | 2.95 | - | 39.7 K | |
| AVDL * [10] | 2.37 | 2.32 | - | 11 M | |
| MWR [18] | 2.00 | 2.23 | - | - | |
| FW-GPL[Ours] | 2.72 | 3.71 | - | 40.9 K |
| Method | DEX | DEX with FW-GPL | |||
|---|---|---|---|---|---|
| 100 | 50 | 20 | 10 | 5 | |
| RMSE | 12.46 | 13.36 | 12.65 | 12.60 | 12.80 |
| MAE | 8.94 | 8.67 | 8.79 | 8.62 | 8.59 |
| Method | DEX | DEX without FW-GPL | |||
|---|---|---|---|---|---|
| 100 | 50 | 20 | 10 | 5 | |
| RMSE | 13.57 | 13.38 | 12.86 | 12.67 | 12.71 |
| MAE | 8.96 | 8.83 | 8.77 | 8.64 | 8.74 |
| Method | DEX with FW-GPL | ||||
|---|---|---|---|---|---|
| 5 | 10 | 20 | 50 | 100 | |
| RMSE | 15.17 | 15.10 | 14.58 | 13.65 | 13.68 |
| MAE | 10.18 | 10.11 | 9.78 | 9.69 | 9.71 |
| Method | DEX with FW-GPL | ||
|---|---|---|---|
| 5 | 10 | 20 | |
| RMSE | 12.91 | 12.60 | 12.60 |
| MAE | 8.78 | 8.62 | 8.62 |
| Method | DEX | FW-GPL | |||
|---|---|---|---|---|---|
| 0 | 5 | 10 | 20 | 50 | |
| RMSE | 12.46 | 14.73 | 14.30 | 13.64 | 12.72 |
| MAE | 8.94 | 9.43 | 9.13 | 8.78 | 8.81 |
| Method | DEX | FW-GPL | |||
|---|---|---|---|---|---|
| 101 | 50 | 20 | 10 | 5 | |
| RMSE | 12.46 | 13.36 | 12.65 | 12.60 | 12.80 |
| MAE | 8.94 | 8.67 | 8.79 | 9.08 | 8.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, C.; Yao, X.; Novak, D. Fuzzy Windows with Gaussian Processed Labels for Ordinal Image Scoring Tasks. Appl. Sci. 2023, 13, 4019. https://doi.org/10.3390/app13064019
Kang C, Yao X, Novak D. Fuzzy Windows with Gaussian Processed Labels for Ordinal Image Scoring Tasks. Applied Sciences. 2023; 13(6):4019. https://doi.org/10.3390/app13064019
Chicago/Turabian StyleKang, Cheng, Xujing Yao, and Daniel Novak. 2023. "Fuzzy Windows with Gaussian Processed Labels for Ordinal Image Scoring Tasks" Applied Sciences 13, no. 6: 4019. https://doi.org/10.3390/app13064019