1. Introduction
In the ISO 20000, the IT incident outage is defined as “Any incident that is not part of the standard operation of the service interferes or reduces the quality of the service” [
1]. Reducing risk and uncertainty of all types and sizes (both internally and externally) is vital in determining the success of any large business. For example, major incidents associated with network outages have significantly impacted all aspects of the businesses, including employee productivity and customer satisfaction. The report (
https://blogs.gartner.com/andrew-lerner/2014/07/16/the-cost-of-downtime, accessed on 30 August 2022) indicated that in the US, the effects of major incidents have cost approximately
$36,326/h, and the mean downstream cost to businesses have cost an additional
$105,302/h. Unfortunately, approximately 12 billion incident reports are generated daily, specifically for IT infrastructure issues, and these have been disruptive to large businesses [
2]. Overall, these incidents can easily lead to high operational costs and, eventually, impact an organization’s reputation for handling major issues, which can have a knock-on effect on the overall success of the organization [
3]. These problems indicate the growing importance of early major incident detection [
4]. The early detection of potential major incidents may increase the meantime of identifying major incidents, which could reduce the resolution times and decrease the adverse impacts on IT business operations [
3].
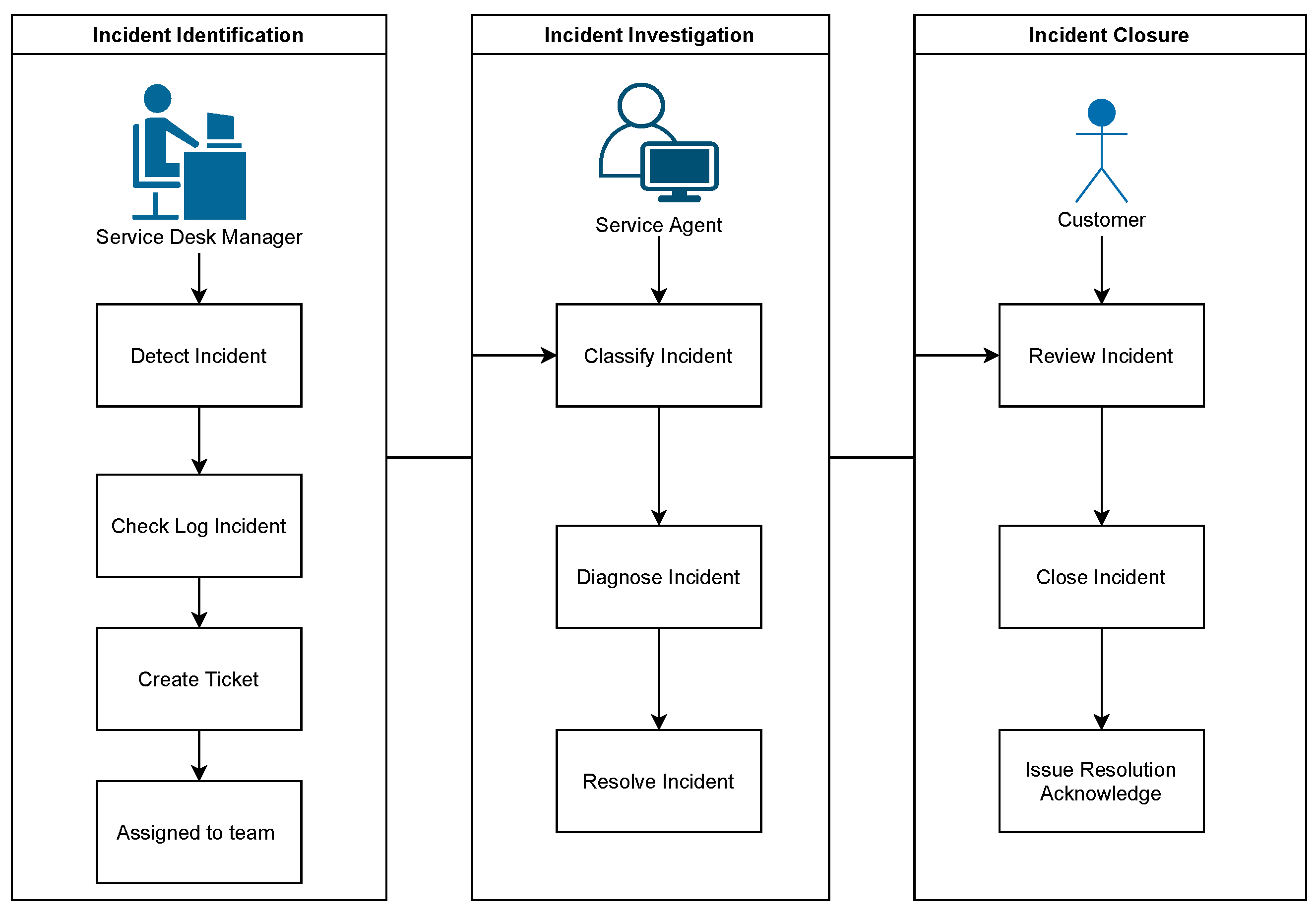
An example of a typical IT incident management system is presented in
Figure 1.
In a typical manual process, the IT service desk is entirely responsible for managing major incidents, from the identification until the resolution and closure [
5]. Due to its manual aspect, human errors directly impact the efficiency of the operation (e.g., wrongly assigned tickets resulting in more time to process and probable waste of resources) [
6]. In addition, if too many incidents arise and a priority queue is activated, the severity assignment becomes critical, as wrongly prioritized incidents further increase the complexity of the problem. Ref. [
7] identified that companies with a well-managed incident management system had managed to minimize their productivity losses and maintain their service quality. Therefore, incident prioritization was essential to determine the impact of such outages. Similarly, the ability to predict major incidents from the initial incident reports could provide a significant advantage in reducing disruptions and preventing actual outages from occurring. However, this is not a straightforward process, and there are some issues to address:
Multi-modal Unstructured Data: Incident reports often contain text and numerical information.
Mixing Data: Incident reports with similar content could be linked to a significant outage or only a minor problem.
Imbalanced Data: Many incident reports are often related to minor incidents, rather than major incidents.
1.1. Scope and Problem Definition
The incident management process begins as soon as incident ticket logs have been generated. Most of the time, these outages resolve at the organizational level (depending on the system’s availability) or via the system’s components (specific system segments issue an alert). Based on the severity of the issue, the tickets are then forwarded to the relevant subject matter experts. However, the IT service management (ITSM) process is still manual, which results in inaccuracies and financial losses (e.g., backlogs due to miss-assignment of severity, high disc-memory usage, time consumption for root-cause analysis). AIOPS addressed problems by classifying outages and responding appropriately to the situation. AI was employed to do this. AIOPS real-world difficulties and threats were reflected in the statistics from the IT outage incidents. This information was kept private. It operated optimally with a three-tier architecture that incorporated system, data, and management tools.
1.2. Contributions
In this paper, we have provided a framework for proactive incident risk prediction. This framework describes a learning value to the company, prevents and mitigates risk, and optimizes resources with improved customer service and satisfaction.
We proposed a novel framework for automating the prediction of major incidents to mitigate risks associated with the escalation of incidents. We aimed to transform reactive major incident management to proactive, within IT infrastructure.
We presented different possible solutions to handle the imbalances in the major incident report (MIR) and non-major incident report (NMIR) records in the dataset.
We then conducted a comparative analysis of state-of-art classification models designed to predict major IT incidents.
The organization’s primary aim should govern IT risk management [
8]. Risk mitigation should include immediate responses, appropriate improvements, and continual risk monitoring [
9]. Given the widespread usage of AI in numerous business sectors, our working hypothesis was that IT incident management should be automated. We provided an automated service management system based on cutting-edge AI models, such as machine learning (ML) and deep learning (DL). Large organizations can use this approach to enable early event detection and prioritization.
The rest of the paper is organized as follows:
Section 2 provides the literature review,
Section 3 describes the data, followed by
Section 4, which proposes a novel framework for incident risk prediction with the state-of-the-art classification method description.
Section 5 describes the experimental setup, and
Section 6 provides the results and analysis. Finally,
Section 7 discusses the research. A conclusion is provided in
Section 8.
2. Background
There has been limited implementation of ML techniques that are specific to IT incident classification. A summary of recent studies is listed in
Table 1. From our observation, among the prominent works adopting conventional ML classifiers for IT incidents, support vector machine (SVM) has been the most popular (22 studies), followed by naive Bayes (NB) with 13 studies, decision tree (DT) with 10 studies,
k-nearest neighbor (KNN) with 5 studies, logistic regression (LR) with 4 studies, and lastly, only 2 studies implementing random forest (RF). Large-scale organizations opted for the simplicity of these conventional ML models due to their limited resources in terms of organizational structures and computing facilities. For example, SVM was preferred simply because the algorithm is less computationally demanding and, thus, significantly reduces the cost of the solution.
In addition, there has been a lackluster interest in adopting DL network models for IT incident classification, which is a stark contrast to the popularity of these models in most other industries. One potential problem has been the implementation complexity, particularly the interpretive ability of the algorithms and the computational resources demanded when training DL models. There have been very few implementations of DL available in the literature, and only [
10,
11] using long short-term memory networks (LSTM) [
12] and convolutional neural networks (CNN) [
13] were noted. As expected, the implementation of a more advanced method (e.g., deep transfer learning transformers such as bidirectional encoder representations from transformers (BERT) [
14], robustly optimized BERT (RoBERTa) [
15], and enhanced representation through knowledge integration (ERNIE 2.0) [
16]) was even rarer. We found a single study by [
17] that adopted BERT in their IT incidents risk prediction model. Independent of the underlying algorithms, most DL models require a precise set of parameters that have been tailored to the problem. These parameters are frequently static and often hard-coded into the models. As such, updating and maintaining these solutions is complicated and requires a dedicated team [
18]. More advanced DL models have been synonymous with black boxes, which are relatively complex to interpret. Due to this high level of abstraction, many firms may be reluctant to trust the output generated from DL models, which could result in the failure of automation initiatives.
Understanding the semantics of IT incidents is essential for building the overall context of the corpus. The incidents in their raw form contain quality and usability constraints that must be removed using natural language processing (NLP) and preprocessing approaches [
19]. Critically, when considering the imbalanced distribution often associated with real-time datasets, researchers have overlooked critical features when developing their corpus. We examined the existing NLP preprocessing pipelines and observed some interesting challenges, including the implementation of lemmatization and stemming strategies during the preprocessing phase. Previous analyses have revealed that language modeling techniques have produced better results for lemmatization than for stemming for document retrieval when precision was the performance metric. Another study by [
17] addressed the issue of identifying the right textual features for a large corpus using a tailored preprocessing pipeline. However, the pipeline was not generic and required substantial changes, based on the specific attributes of the datasets, to function. Despite the complexity of context understanding, NLP techniques have been developed for feature extraction (as listed in
Table 1) to capture the maximum attributes of a given corpus.
In terms of the specific feature-engineering techniques, the term frequency-inverse document frequency (TF-IDF) [
20] has been the most preferred (12 implementations for incident severity prediction studies were found). TFIDF has been preferred because TF-IDF vectorization determines the TF-IDF score for each word in the corpus and assigns that information to a vector. As a result, each document in the corpus had its own vector, and the vector had a TF-IDF score assigned to every word that appeared anywhere in the collection of documents at any time. The vector detected whether or not two texts were comparable by comparing their TF-IDF vectors using a cosine similarity metric. TF-IDF provides a simple way to calculate the association between features and their importance within a text. It is memory and operationally efficient, which contributes to its popularity. Another popular approach has been the count vectorizer, a traditional feature extraction method based on the bag-of-words approach [
21]. As compared to TF-IDF, count vectorizer was more computationally intensive and often unable to identify important keywords [
22]. Despite the popularity of both methods, there have been clear limitations, especially when handling large-scale, unstructured, and imbalanced datasets commonly found in IT incident reporting.
Conventional ML vectorizers have a limited vocabulary, which is insufficient for large datasets. As indicated in [
21], conventional vectorizers were ineffective in handling real-world ITSM data because they could not be upgraded. The vocabulary of traditional ML approaches was fixed and unable to adapt to upcoming real-time tickets. Most conventional vectorizers are also costly due to the cardinality review that must be performed exhaustively for each word. These weaknesses have been addressed by adopting a more advanced feature extraction method offered by state-of-the-art models, such as BERT, RoBERTa, and ERNIE 2.0. These Transformer models can avoid repetition, providing positional embeddings and learning relationships between words. For example, ref. [
17] presented results showing transformer-based feature extractors outperformed conventional vectorizers.
The survey presented here revealed that in terms of performance when using accuracy as a metric, conventional ML models performed much better than the more advanced DL models. For example, [
10], in their analysis using an open IT support ticket dataset, showed that NB outperformed the more advanced LSTM model (74% to 69% accuracy, respectively). Moreover, ref. [
12] demonstrated a gradient boosting (GB) model that slightly outperformed a CNN model by 3% with an accuracy score of 95%–92% for automating the Information Technology Infrastructure Library (ITIL) dataset. On the contrary, we found this was not reflective of the true potential of these advanced DL models. There have been noteworthy issues in their implementations, such as insufficient training due to limited infrastructure (most advanced DL methods require extensive training to facilitate learning [
23]), lack of understanding of the DL architecture (difficult to identify the bias of the model), lack of hyperparameter optimization (which is time-consuming and requires extensive memory utilization), and lack of validation for performance evaluation.
In this literature survey, we recognized that an updated comparative analysis of ML algorithms and state-of-the-art DL approaches, including transformer architectures for incident prediction, was required, as the vocabulary handled by ML classifiers is limited, making ML insufficient when learning from larger datasets that are complex (mixed and unstructured) and imbalanced. Therefore, we present a comprehensive analysis in this paper, focused on first-time transformer models. We hypothesized that the transformer model could significantly improve performance metrics due to its attention mechanism and its ability to handle larger vocabulary sizes.
Table 1.
Existing implementations of automated IT incident prediction utilizing AI models.
Table 1.
Existing implementations of automated IT incident prediction utilizing AI models.
| Data | Pre-Processing | Feature Engineering | Techniques | Ref |
|---|
| Open-source data of Endava helpdesk operators | anonymization, lowercasing, lemmatizing, stemming, noise removal | No | CNN, RF, GB, average and stack ensemble | [24] |
| ITIL CHM department | removing stop words, punctuation, turning to lowercase, stemming | linguistic Features | TF-IDF and KNN, decision tree, NB, LR, SVM, QUICKSUCCESS | [25] |
| Fast-food restaurant chain | DateTime column named closed ticket transform from string to DateTime format. | feature extraction was performed based on daily data. Irrelevant features were removed. The feature was selected based on probability theory. | NB, LR, and gradient boosting decision tree model | [26] |
| IT department from a big multinational company | tokenization, stop word and digits removal, word stemming, and part-of-speech filtering by selecting only open grammatical classes | word count per solution category against text data. | TF-IDF and multinomial naive Bayes SVM, KNN, decision tree, and logistic regression | [27] |
| IBM Tivoli monitoring system | No | No | HMDB and ICTR model | [28] |
| German Jordanian University. | remove HTML tags and special characters | TF-IDF feature vectorization | SVM, NB, rule-based, and decision tree | [29] |
| IT infrastructural incident data | remove stop words, special characters, date and time, phone number, and email address | Chi-squared was used to select important features using TFIDF vectorizer. Top 1000 important feature selected. | NB, SVM, and Ada SVM | [30] |
| IBM CMDB dataset | keywords and their annotations as classification features | Selecting top Configuration Item records from CMDB to prevent complexity. TF-IDF was used to give importance | SVM | [31] |
| Incident issue tracking system of Istanbul Technical University data | purifying of tickets from HTML and numerical expression tags was carried out | Bag of words using TF-IDF | decision trees, SVM, KNN, and NB | [32] |
| Confidential data of IT Company | tokenization, stop words removal, and stemming | part of speech tagging was performed to filter out vocabulary | SVM | [19] |
| Real-world incident ticket data | tokenization, stop words removal and stemming | TFIDF | SVM | [33] |
| Real-world IT infrastructure service desk ticket data | remove stop words, special character, date and time, phone number, and email address | TF-IDF | LR, K-NN, MNB and SVM | [34] |
| Organization ticket data | lemmatization, POS tagging | TFIDF with Jaccard coefficient filtration | k-means clustering, Jaccard distance, and cosine distance | [35] |
| UCI ML repository | No | embedding | relational graph convolutional networks | [36] |
| Case study data | No | TFIDF | SVM using RBF kernel and XGBoost | [37] |
| IBM real-time dataset | HTML tag removal, Unicode inconsistencies, header/footer/entities replacement | semantic role sampling | BERT | [17] |
| Telco trouble ticket dataset | remove punctuation and stop words | TFIDF | random forest, DL, gradient boosting, XGBoost, and extremely randomized trees classifiers | [38] |
| Service Now dataset in IT help desk and ticketing | remove punctuation and stop words | Doc2vec using ServiceNow ticketing system | logistic regression | [18] |
| Tickets dataset of service level agreement | remove punctuation and stop words, URL. | Count Vectorizer | decision trees, SVM, KNN and NB | [39] |
3. Dataset Description
For this study, we used a dataset from a large multinational company comprising 500,000 total records. The dataset comprised real-time IT incidents collected from January 2020 to March 2021. These incidents were recorded by the organization’s three main stakeholders (agencies, employees, and customers). The reported incidents were classified either as major incident reports (MIR) or non-major incident reports (NMIR). Examples of the incident reports are provided below:
An MIR was an incident report that had been escalated to major status or had a direct link to major incidents identified by the IT team. Conversely, NMIR was a regular incident with less impact on the operation. The class of each incident was labeled retrospectively after processing. The dataset is structured as:
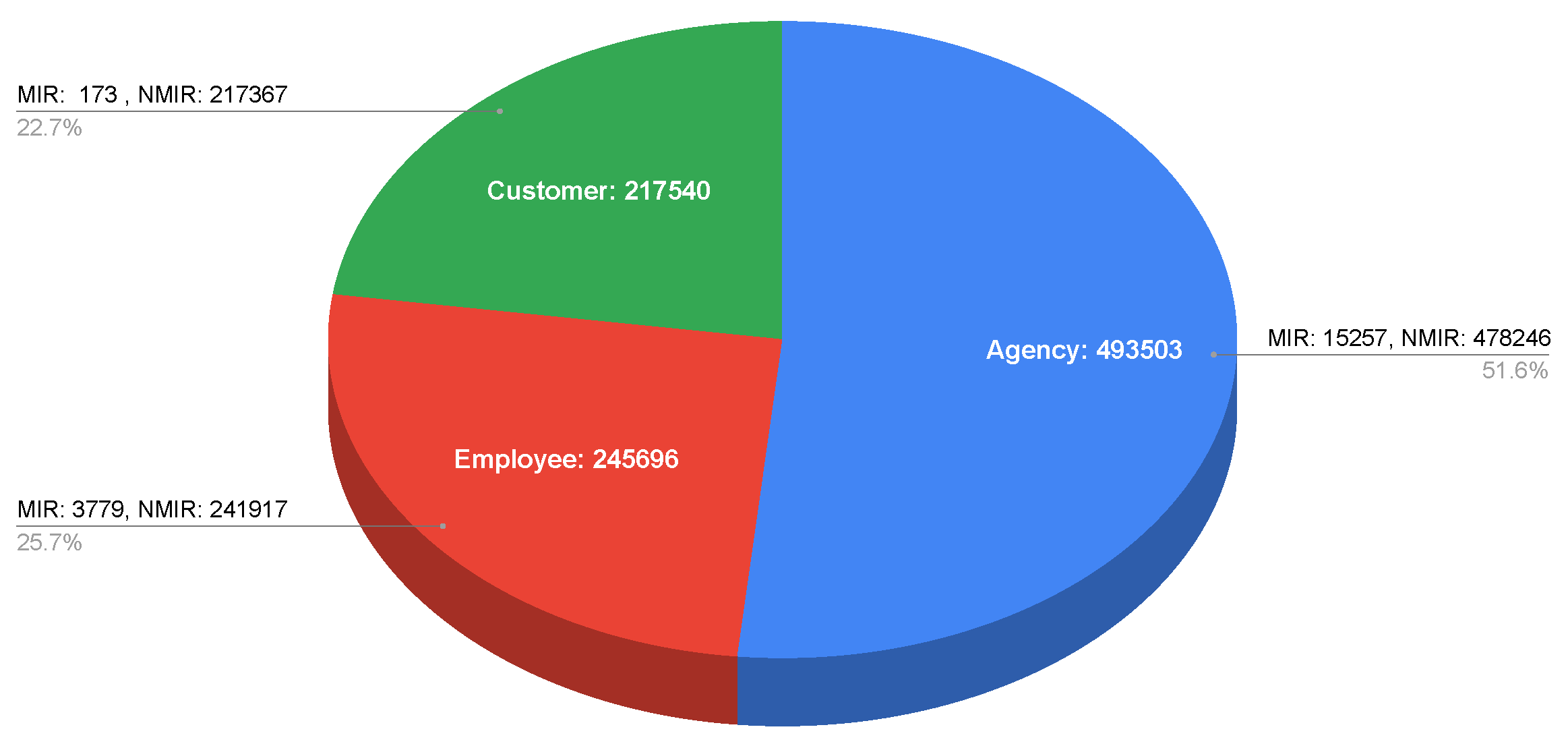
The distribution of the datasets is depicted in
Figure 2. The
Agency_records contained 493,503 incidents, out of which 15,257 were MIR and 478,246 were NMIR records. The
Employee_records contained 245,696 incidents with 3779 MIR and 241,917 NMIR values. The
Customer_records had 217,540 incidents with 173 as MIR and 217,367 as NMIR. As observed, the datasets were significantly imbalanced and skewed heavily in favor of NMIR incidents.
Specific to this study, we only used the
Description,
Short description (incident details), and the
Status (labels MIR or NMIR) within the available datasets columns. In addition, we utilized the
MIR opened at (MOA) and
Incident opened at (IOA) columns for estimating the prediction horizon (i.e., time advantage that could be realized by investigating the cause of an incident potentially related to a major outage). A sample of the dataset is described in
Table 2. To address the imbalanced class issue in our dataset, we curated new datasets using a custom data-augmentation approach [
40]. We added the actual MIR records from the other stakeholders’ datasets to each stakeholder dataset. This enriched each dataset while preventing additional extraneous information in the vocabulary. Data augmentation was intended to increase the occurrences of the MIR classified incidents that were severely lacking in the original dataset. The dataset composition was, as follows:
We also concatenated all the records to increase the number of MIR records, as follows:
We also performed up-sampling using the synthetic minority oversampling technique (SMOTE) [
41]. We used SMOTE for oversampling because it generated synthetic data points that were different from the actual points instead of duplicating records with no extra information and increasing vector size. Using SMOTE, we generated three sampled subsets:
Our literature survey indicated that most of the reported studies did not use resampling, which may have resulted in sub-optimal learning [
19,
29,
37]. We hypothesized that by increasing the minority class (i.e., in the highly imbalanced situations observed in our dataset), we could improve the feature extraction of the minority class (in this case, MIR classified reports), which would lead to a higher accuracy. By performing SMOTE, we managed to increase occurrences of the minority class (MIR) records. For Agency_smote, we generated 462,989 MIR records, which were added to the existing 478,246 NMIR records. For Employee_smote, we generated 238,138 MIR records, which were added to the existing 241,917 NMIR records. For Customer_smote, we generated 217,194 MIR records, which were added to the existing 217,367 NMIR records.
4. Proposed Framework
Currently, there is a gap in the literature concerning the performance evaluation of AI algorithms in this domain. In this study, we proposed a comprehensive framework that compared various ML and DL approaches, specifically for IT incident prediction, using our proprietary industry-level data. We developed a computational pipeline that began with preprocessing, followed by feature extraction, training, and evaluation (a detailed description of the pipeline is presented in
Section 5.1) and shown in
Figure 3.
Our comparative pipeline is shown in
Figure 4. The first phase of the pipeline was data preparation. As discussed earlier in
Section 3, we had performed data augmentation and synthetic resampling on our original dataset. These datasets were split (70% for training and 30% for testing). Using the training data, we had performed supervised training using all 11 classifiers. Specific to the DL-based classifiers, we allocated 20% of our training dataset for training validation using the default Keras model’s
fit function. The training phase was performed for 10 epochs with
binary_crossentropy as the loss function and AUC as the performance metric. We selected AUC as a metric to prevent over-fitting due to the imbalanced characteristics of our dataset. Finally, the models were tested with the test data (30% of the dataset). Similarly, the AUC score was determined to evaluate the performance of all 11 classifiers.
An essential element of the prediction framework was the utilization of various state-of-the-art classifiers. In this work, we categorized these classifiers as (1) conventional ML methods, including NB, SVM, gradient boosting (GB), extreme gradient boosting (XGBoost), and categorical boosting (CatBoost); (2) DL-based approaches, including gated recurrent unit (GRU), CNN, and Bi-LSTM; and lastly, (3) transformers, including BERT, robustly optimized BERT (RoBERTa), and enhanced representation through knowledge integration (ERNIE 2.0). A brief description of each classifier is provided below.
NB [
42]: Naive Bayes classifier is based on Bayes theorem and is one of the popular ML algorithms for classification. NB is a simple probabilistic model that assumes that each feature or variable of the same class makes an independent and equal contribution to the outcome. Our dataset was divided into a feature matrix and a target vector. The feature matrix (
X) contained all the vectors (rows) of the dataset, in which each vector consisted of the value of dependent features. We assumed that the number of features were
d,
while the target vector (
y) contained the value of the class variable for each row, according to its feature matrix. The feature matrix (
X) was the incident description reported in the database system. The target (
y) value would either be MIR or NMIR. In this instance,
was the probability of the class
y (for MIR or NMIR), according to the incident description (
X). The maximum probability function provided the classification label, either MIR or NMIR.
GB [
43]: Gradient boosting classifier is an approach developed to train a weak hypothesis iteratively to arrive at a better hypothesis. Gradient boosting combines the previous model with the next generated model to minimize the prediction error. It minimizes the loss function iteratively, starting with a negative gradient, i.e., a weak hypothesis. In this work, we performed a binary classification (MIR or NMIR) using the description column of the incident. The algorithm began with one leaf node that predicted the initial value for each description of the incident. Next, the algorithm used the
of the target value, yielding an average survival value assigned to our initial leaf node. If the probability of surviving exceeded
, we first classified every sample in the training dataset as MIR. (Note: where
was a common threshold value associated with binary classification decision based on probability).
XGBoost [
44]: Extreme gradient boosting is an optimized GB technique that provides efficient, flexible, and portable tree model results. It offers parallel tree boosting that provides solutions quickly and accurately. XGBoost is efficient for open-source implementation and significantly distributed environments, such as Hadoop, Sun Grid Engine (SGE), and Message Passing Interface (MPI). It predicts the residual or error of prior models to obtain its final predictions. The gradient descent algorithm minimizes loss when adding new models. We trained the model with 500 trees and a depth (
max_depth) of 1 (for the root node). As compared to other available boosting techniques, e.g., GB, XGBoost was fast, memory efficient, and highly accurate [
45].
Catboost [
46]: Category and boosting adopts minimal variance sampling, a type of stochastic gradient boosting with weighted sampling. In this instance, the weighted sampling occurred at the tree level and not the split level. It grows as a balanced tree; the split score minimizes the loss and maximizes the accuracy score. Changing policy parameters (with a penalty function at level nodes) is also possible. In contrast to a traditional approach, this study addressed the MIR and NMIR classification problems. We trained the model with 400 trees and a depth (
max_depth) of 1 (root node only). As compared to the XGBoost, Catboost was twice as fast with better accuracy [
47].
SVM [
48]: Support vector machines utilize associated learning to analyze data for classification. Based on the descriptions of known incidents, SVM built a model that assigned MIR or NMIR labels to new incidents. The algorithm considered all incident descriptions and mapped them to a space that maximized the distance between the two classes. In the context of this study, we had a training dataset of incident descriptions labeled “0” for MIR and “1” for NMIR,
where
is either 0 or 1, each denoting to a point
, where each
is a
p-dimensional real vector. We were interested in the maximum-margin hyperplane that divided the group of points
, for which
from the group of points for which
, which was defined so that the distance between the hyperplane and the nearest point
from either group was maximized. Any hyperplane could be written as the set of points
x, satisfying
, where
w was the (not necessarily normalized) normal vector to the hyperplane. This was similar to Hesse’s normal form, except that
w was not necessarily a unit vector. The parameter
determined the offset of the hyperplane from the origin along the normal vector
W.
Bi-LSTM [
49]: Bi-directional long short-term memory is an improved version of the LSTM model (a variant of the recursive DL architecture) that can process data in both forward and backward directions. Bi-LSTM helps map models that allow for sequential dependencies in words and phrases. For our framework, Bi-LSTM assisted in training MIR and NMIR sequences by preserving this information using two independent RNN cells that stored the iterative states for a longer time. Bi-LSTM contained the IT incident input
concatenated with hidden state
, which was further forwarded to three gates (Forget, Input, and Output). The Input gate has an embedded gate known as an Update. The Update gate memorized the past and present sentence sequence. The value from the update gate multiplied the cell state
, resulting in the hidden state or unit
. Our Bi-LSTM architecture comprised five layers: one embedding layer with a size of 300, one bi-directional layer with 280 LSTM neurons, two dropout layers, and one classification layer (dense layer). The total number of trainable parameters for the model was 23,346,401.
CNN [
50]: Convolutional neural network is synonymous with image classification, but recently, it has significantly contributed to NLP. CNN is used to extract high-level feature functions from n-gram. For example, ref. [
51] developed a word-embedding matrix layer that memorized the weights during the network training phase. We used our framework’s input labels (MIR or NMIR) as tokens to map to the word-embedding matrix. In this mapping, every convolutional filter mapped to each window of the embedding layer. In CNN, matrix reduction reduced the dimension of the matrix to a constant length. We executed the matrix reduction on every possible window. Each reduced matrix was the input for the fully connected layer. In the next layer, we used the activation function to create a single dimension input of features per tensor output; The global max pooling layer with 256 batch sizes and 23,027,144 trainable parameters were used. In the final layer, we applied the Softmax activation function to translate the real-probability values into MIR or NMIR labels.
GRU [
52]: Gated recurrent unit is an RNN DL variant that retains information for a longer time and improves the computing speed. GRU consists of two neural gates (Update and Reset gates) for updating the previous cell state and discarding the irrelevant state. For this purpose, we provided MIR or NMIR values as input
, which concatenated with hidden states
and moved to the Update gate. In the final phase, we used the Sigmoid activation function to maintain an output within the range of (0,1), resulting in an MIR or NMIR value. The architecture comprised 5 layers, containing one embedding layer with a size of 300 vectors, one GRU layer with 140 neurons, and one dense layer with a sigmoid activation function. The model had a total of 23,037,981 trainable parameters.
BERT [
14]: Bidirectional encoder representations from transformers consists of several encoder transformers within a pool of pre-trained models. BERT follows the bidirectional orientation of learning information from a sequence of words from left to right and right to left. Each encoder encapsulates two sub-layers: a self-attention layer and a feed-forward layer. We have employed a trained BERT architecture contain 12 layers of the encoder, 12 attention heads, 768 hidden sizes, and 110M trainable parameters. It was pre-trained on 800M unlabeled data extracted from BooksCorpus and 2500 M words from Wikipedia, and then, it was transferred to the incident prediction problem. We performed an additional preprocessing step for our dataset using the BERTtokenizer. It tokenized and reformatted the sequence of tokens by adding CLS (a classification token indicating the start of a sequence) and SEP tokens (appended to the end of the sequence). The length of our incident description token was less than 512 tokens; therefore, we utilized padding (
PAD) to fill the unused token slots (further details below). Our BERT model output an embedding vector of 768 in each of the tokens and had 340M trainable parameters.
ERNIE 2.0 [
16]: Enhanced Representation through knowledge Integration (ERNIE) is a pre-trained framework that performs the training of new sequences with historically trained tasks. For text classification, ERNIE 2.0 has outperformed BERT with highly accurate results [
16]. ERNIE 2.0 captures the contextual information with a series of shared text encoding layers, customized with recurrent neural networks or deep transformers with a stacked self-attention layer. Its multi-task learning encodes lexical, syntactic, and semantic information across tasks. When a new task arrives, this framework can incrementally train the distributed representations without forgetting the previously trained parameters. In our framework, we used 12 layers, 12 self-attention heads, and 768 dimensions in the hidden layer, resulting in 94M trainable parameters.
RoBERTa [
15]: Robustly optimized BERT emphasizes data being used for pre-training and the number of passes for training. The RoBERTa architecture was proposed to overcome the drawback of the original BERT model by increasing
batch size from 256 to 8k, providing better speed for performance metrics [
15]. We used a pre-trained transformer with built-in (vocab) 160GB in size for RoBERTa to conserve our computational resources. It reduced the perplexity of the masked language model by providing the provision to train with larger batches and longer sequences. It also provided the dynamic masking pattern over the training data during data preprocessing. In our framework, we implemented a large RoBERTa model with 12 encoder layers, 12 attention heads, and 768 dimensions in the hidden layer, resulting in 110M trainable parameters.
Finally, if an incident was classified as NMIR, it was assigned to the normal priority queue. If an incident was classified as MIR, it was directed to the high-priority queue and assigned immediately to the incident processing acceleration teams in order to resolve the issue as soon as possible.
7. Discussion
This study comprehensively evaluated AI classifiers using a real-world proprietary dataset. As observed, we faced a highly skewed distribution with almost a million records for NMIR and only 19,000 records for the MIR (which was only 2% of the overall dataset). The datasets were highly unstructured, which further complicated the data-preprocessing task. Our datasets consisted of raw incident reports/tickets. Therefore, most records contained typographical errors, misspellings, grammatical mistakes, and slang words. We also noticed that 6% of the incident log contained duplicate records, which did not provide any extra information and consumed additional memory resources during processing. We suggested removing these records because it introduced sparseness problems and increased the vector size. In a real-world setting, IT incident datasets require extensive cleaning using a closely monitored preprocessing pipeline to extract important linguistic features, which we included as part of the proposed prediction framework. Additionally, we demonstrated that data augmentation provided relatively better results than the synthetic data. We developed a custom approach of data augmentation, in which actual data from various channels (representing the minority label) were added to enrich the dataset belonging to the industry stakeholder. This enrichment was more beneficial than generating synthetic records to avoid duplication that added no additional information to the vocabulary.
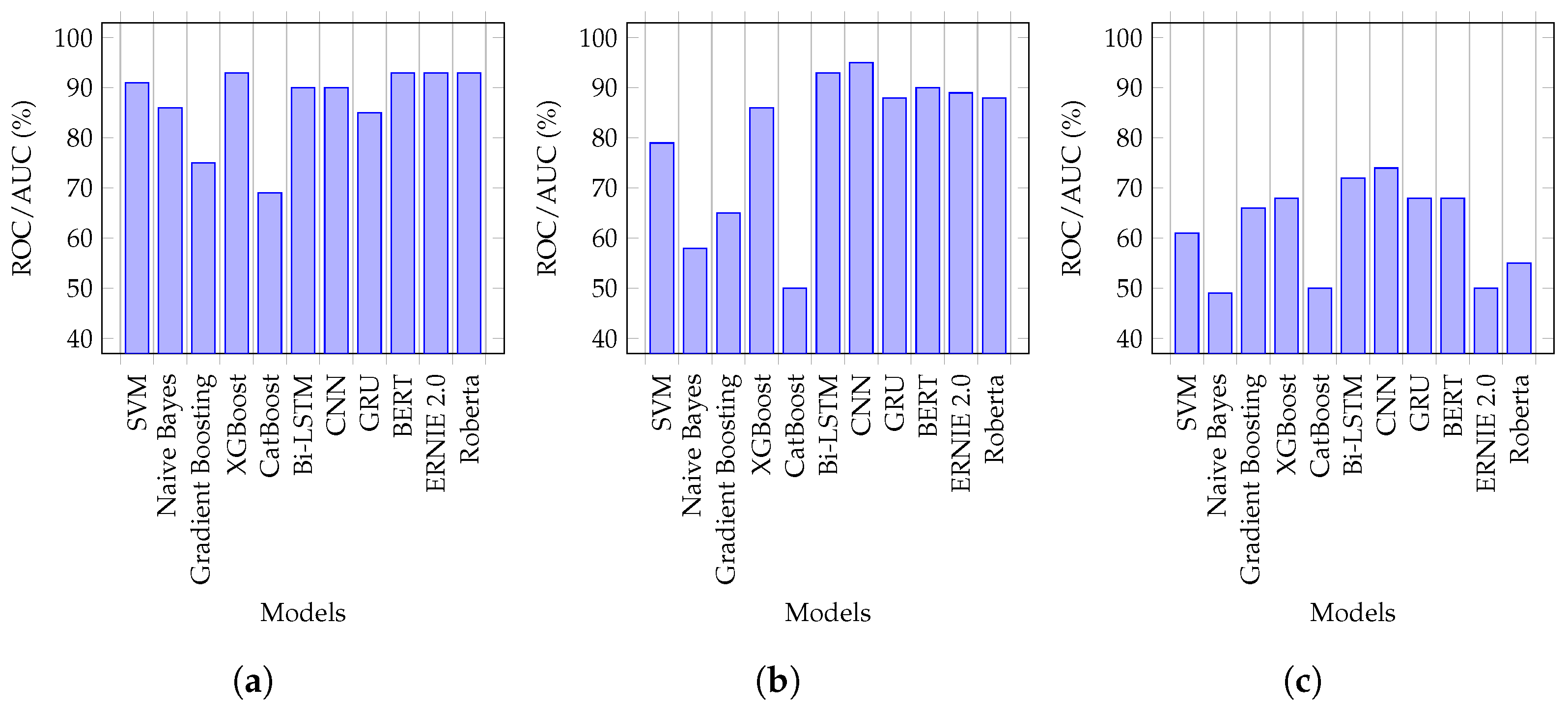
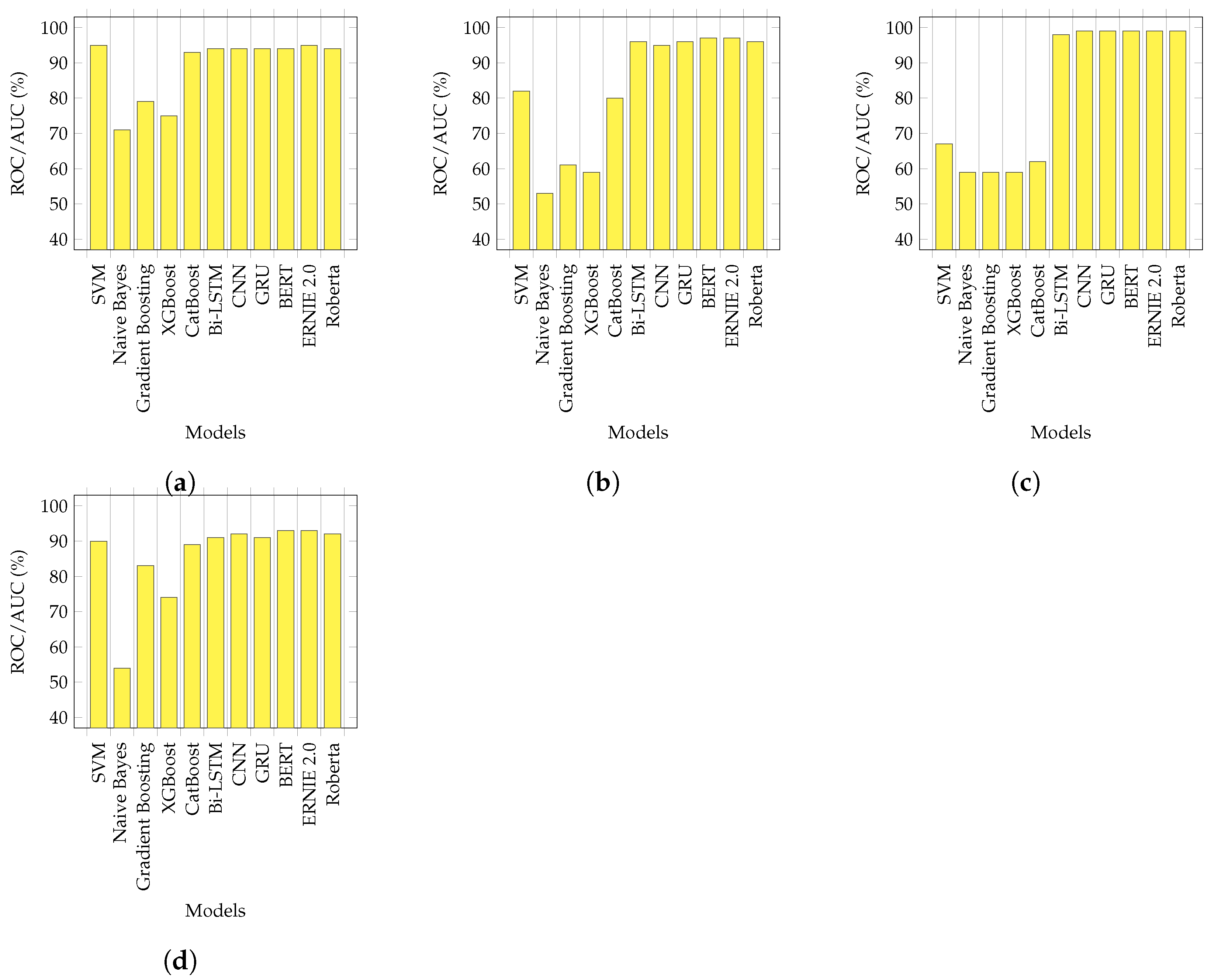
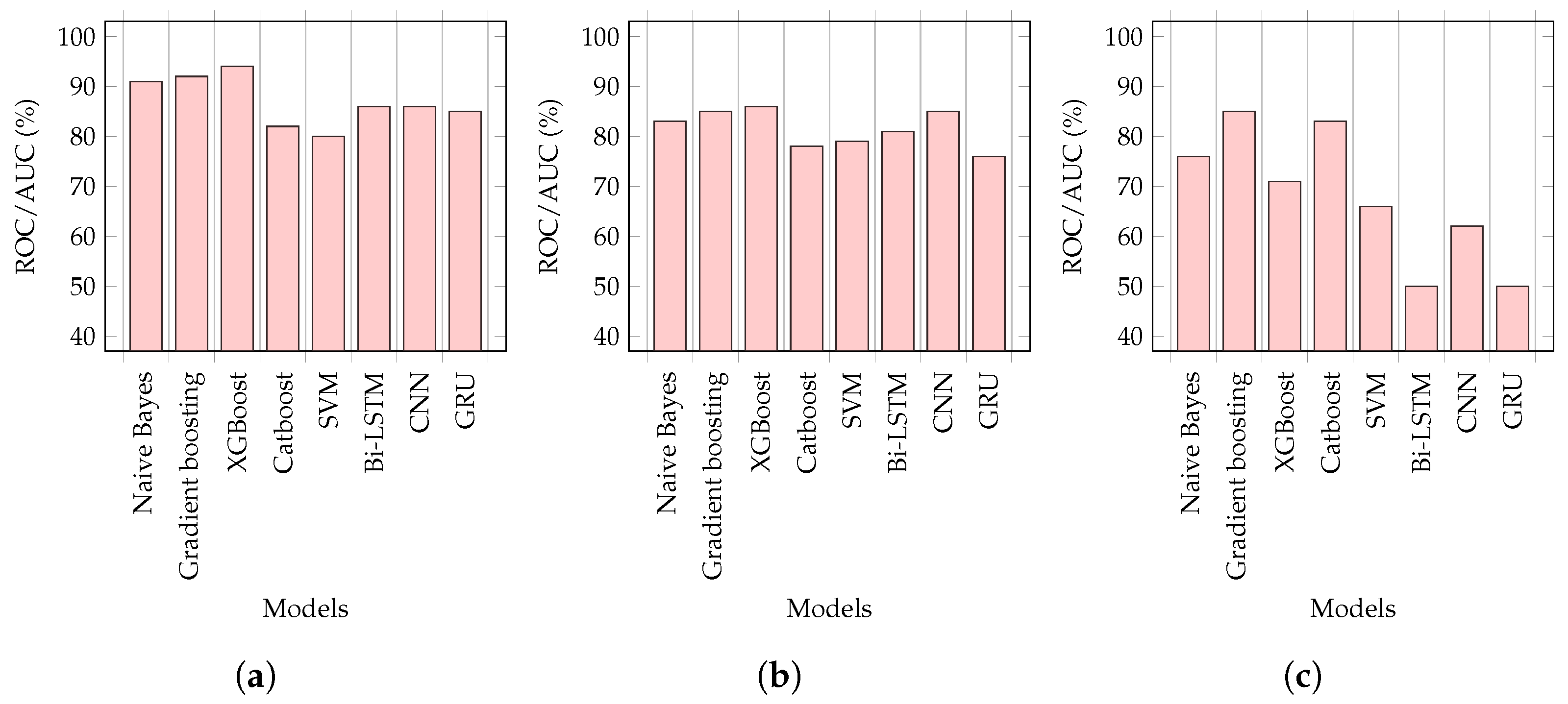
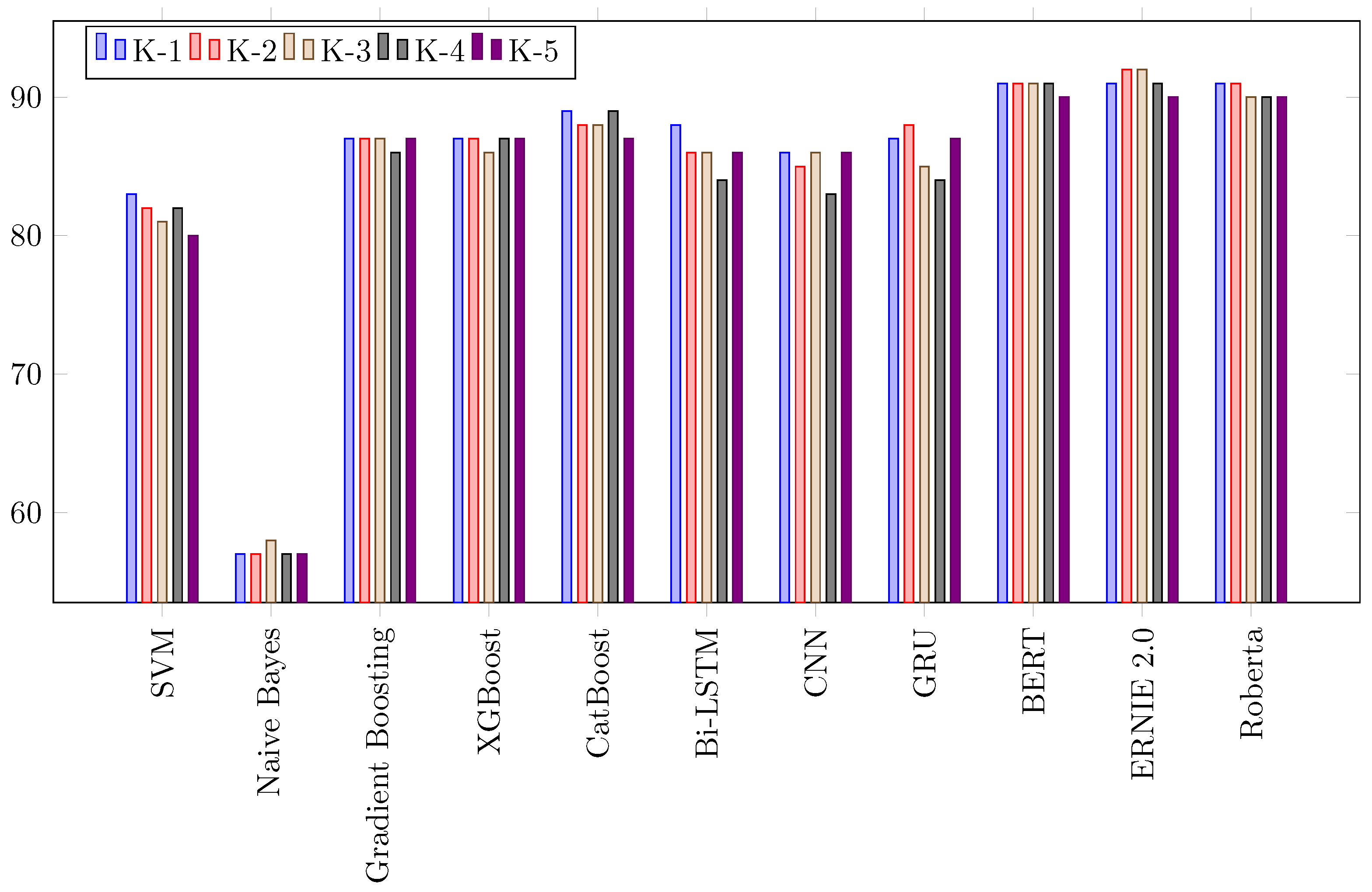
Our analysis showed that the transformers performed marginally better than the DL-based models and significantly better than the conventional ML models. For example, given the Combine_All dataset, ERNIE 2.0 outperformed all conventional ML models, performing better than NB, GB, SVM, XGBoost, and CatBoost, by 39%, 10%, 3%, 19%, and 4%, respectively. As compared to the DL-based models, ERNIE 2.0 produced slightly better results, with a 1% improvement over the CNN and a 2% improvement over the Bi-LSTM. Generally, the DL-based models performed better due to their recall memory units that extracted high-level abstract features; however, they performed slightly worse, as compared to transformers because of their limited vocabulary [
10]. Our findings were in agreement with this observation.
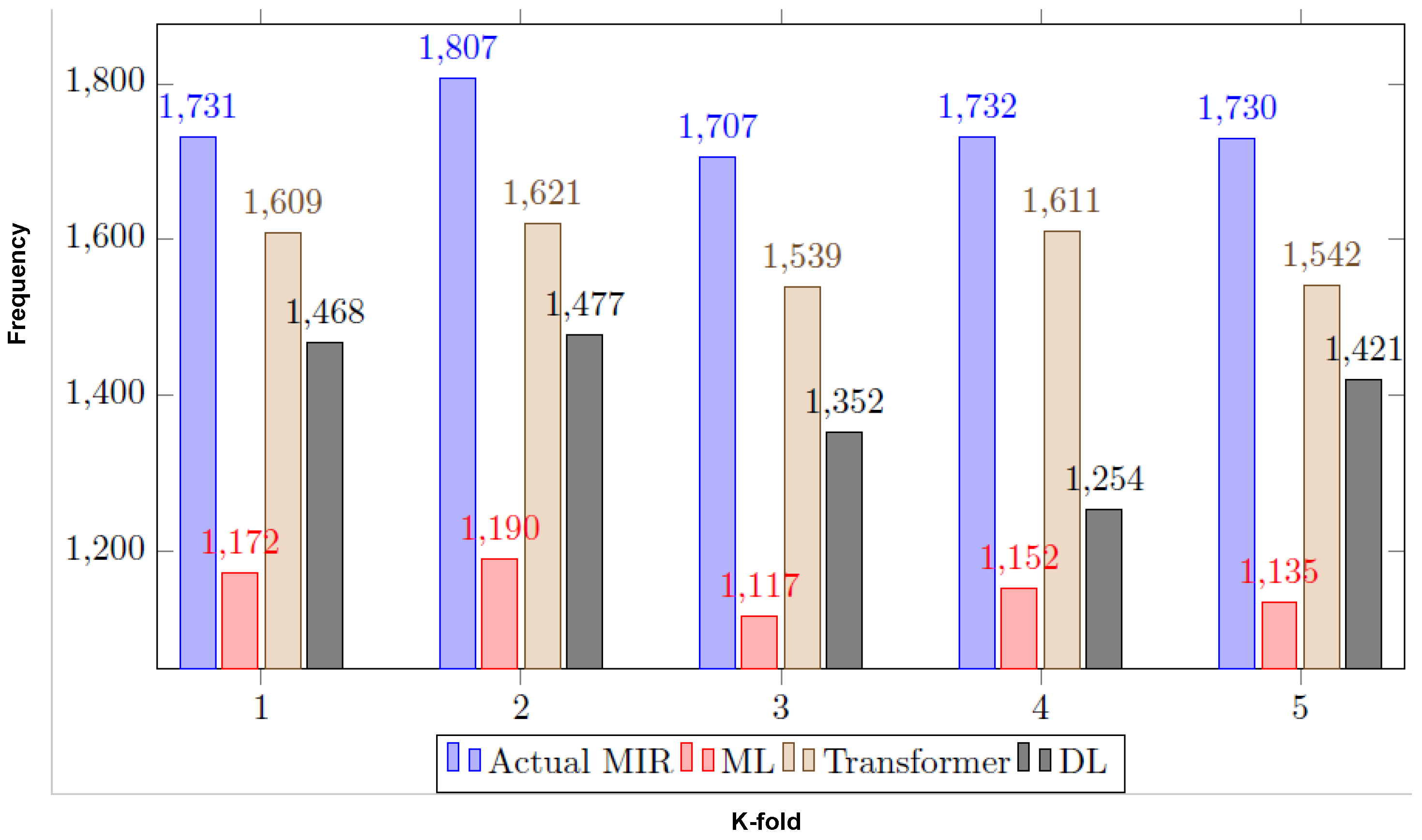
We found that accuracy was not the right performance metric because our initial results for imbalanced data were more skewed towards the majority class. We used a confusion matrix and area under the ROC curve to better quantify the correct and incorrect predictions. Based on our findings, the ROC metric showed the classifier’s exactness and completeness much better than accuracy. For example, Customer_records had the lowest minority class (MIR) records at 0.05%, which was highly imbalanced. Its ROC scores varied from 50% to 74%, whereas its accuracy score was 99%, which was misleading and highly skewed by the majority (NMIR) class. We calculated the confusion matrix by k-fold validation and the mean for each fold. Our results showed that RoBERTa possessed the highest mean score with 1462 TPs and 64,539 TNs values.
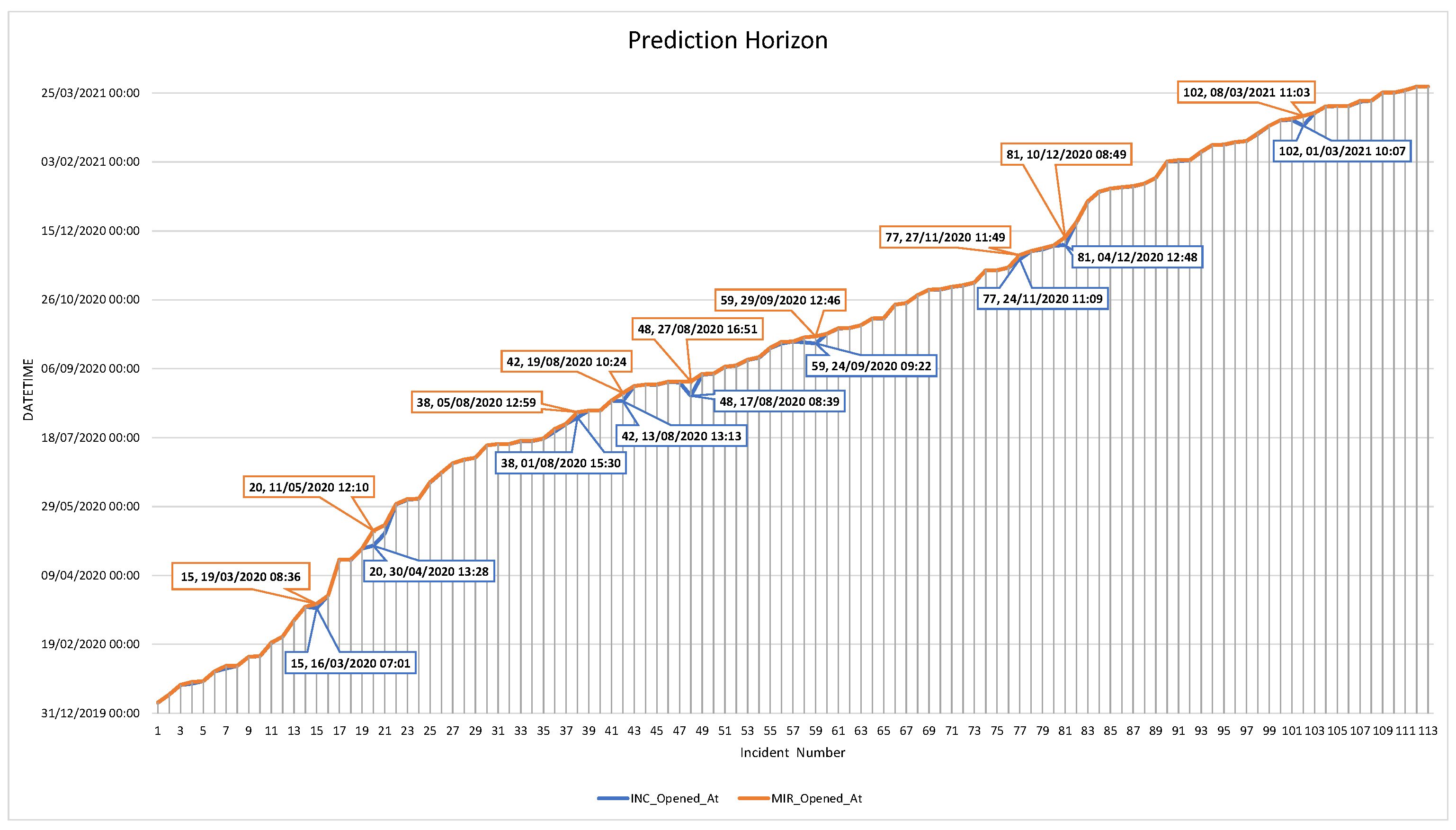
We calculated the prediction horizon to identify the average time for the ITSM system restoration from escalated deadlock. We targeted incident opened at(IOA) and MIR opened at(MOA) to calculate the prediction horizon. We evaluated the average incident escalation time, which was 2 h 30 min of saved time due to applying our proposed IT incident framework. It not only saved resources but also helped to prevent a deadlock situation. Considering the complexity of the prediction, the possibility of implementing RL to enhance these transformers is a significant possibility. At the time, we could identify any studies that were associated with RL implementation for IT incidents prediction. The convergence rate of RL models for classification was estimated to be 40% more, as compared to the other state-of-the-art model [
56], which could hinder the adoption for large-scale industrial datasets. Furthermore, future work could involve evaluating NLPGym [
57], a toolkit that bridges NLP and RL. The NLPGym provides a policy for reward and penalty against action, and deep-Q networks (DQN) could be used to train the model. We are optimistic that we can improve the accuracy score significantly through RL.
8. Conclusions
This paper leveraged state-of-art machine-learning (NB, SVM, GB, XGBoost, CatBoost), deep-learning (GRU, CNN, Bi-LSTM), and transformer architectures (BERT, Roberta, and ERNIE) to classify the provided incidents as major (MIR) and non-major (NMIR) to address the challenge of IT incident prediction. This paper was the first attempt to employ deep learning and transformers for solving IT service management problems, to the best of our knowledge. We experimented with three different sources of incidents: agency, customer, and employee. The transformer architectures (BERT, RoBERTa, and ERNIE) and XGBoost outperformed all other methods, with a 93% ROC for agency records, and with CNN, a 95% and 74% for employee and customers, respectively. To address the problem of data imbalance in our work, we resampled and curated synthetic data (SMOTE). With resampling, we achieved 95% with ERNIE for agency, 95% with BERT and ERNIE for employee, 99% with transformer and deep-learning models for customers, and 93% with BERT and ERNIE for all combined (employee, agency, and customer). For synthetic data, XGBoost had 94% for agency, 86% for employees, and with GB, 85% for customers. With the resampling and synthetic data curation, we noticed significant relative improvements, at 2.10% for agency and employees and 33% for the customer. We also identified the limitations of deep learning models for SMOTE, which we plan to address in the future. Additionally, our proposed framework computed the average prediction horizon, which was 2 h 30 min and leveraged this to minimize the meantime to resolve incidents. In the future, we will implement our framework for managing and reducing change failure rates associated with the incident mean time to resolution (MTTR). For future work, we are planning to perform a complete analysis of ITSM with state-of-the-art cross-validation techniques because the literature lacks this domain.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












