
PC-Allocation: Performance Cliff-Aware Two-Level Cache Resource Allocation Scheme for Storage System

Abstract
:1. Introduction
- We model and analyze the potential of performance cliffs, and present the shortcomings of the two existing methods, and the unaware performance potential.
- Based on an analysis result, we propose a cliff-aware cache allocation algorithm that takes the MRC as an input and calculates a cache allocation which satisfies the capacity or performance constraints.
- We carefully compare the allocation results of the cliff-aware and the cliff-remove under various constraints, and validate the effectiveness of the proposed scheme.
2. Background and Motivation
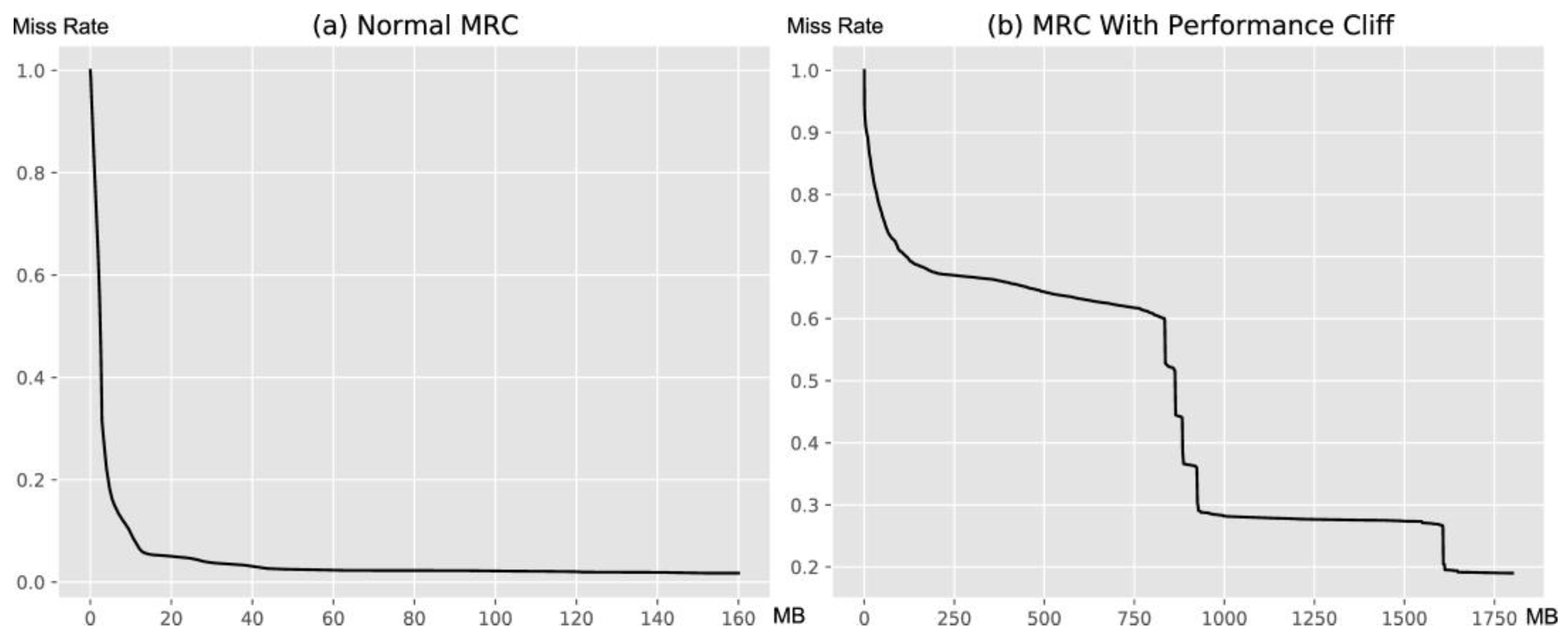
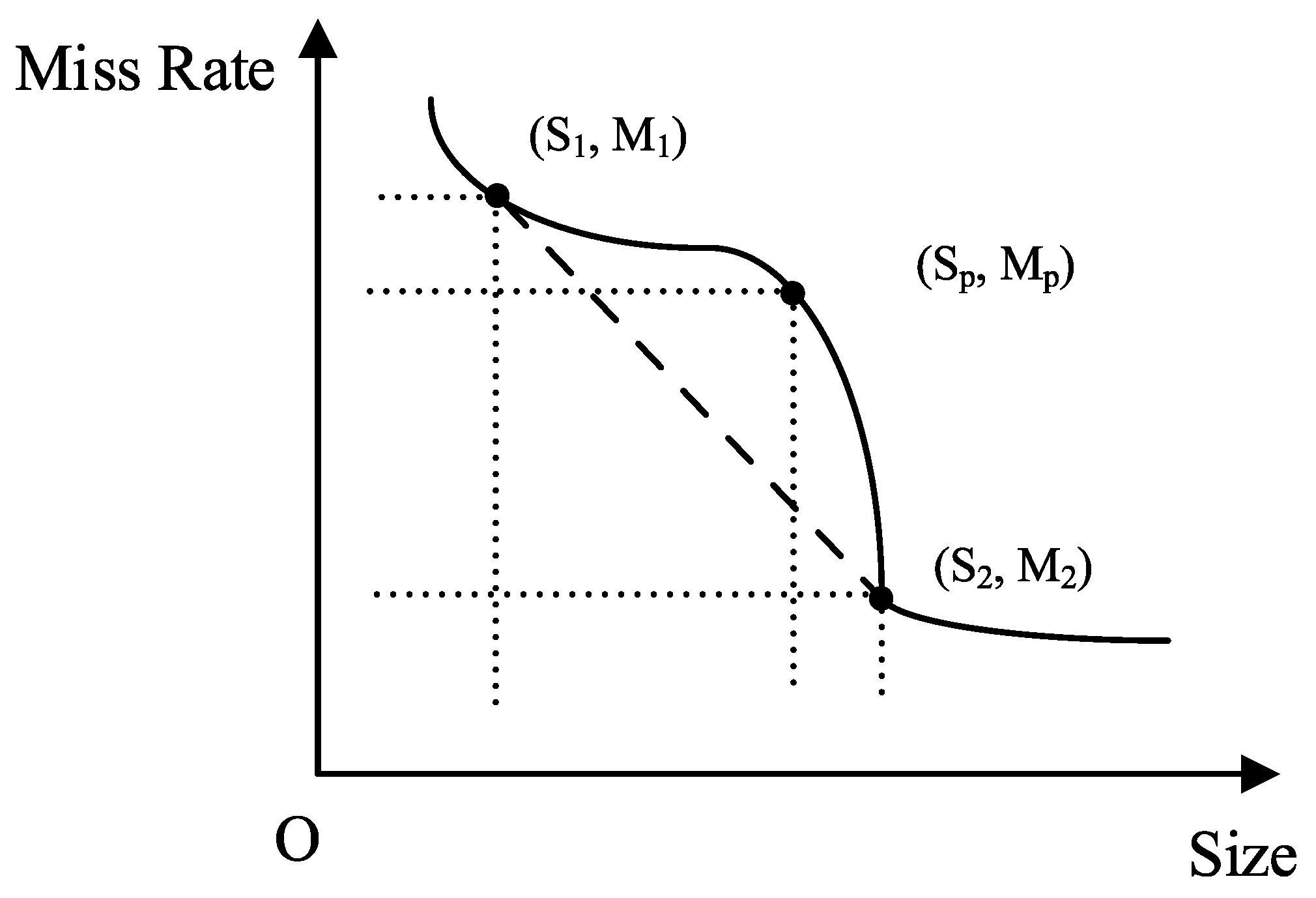
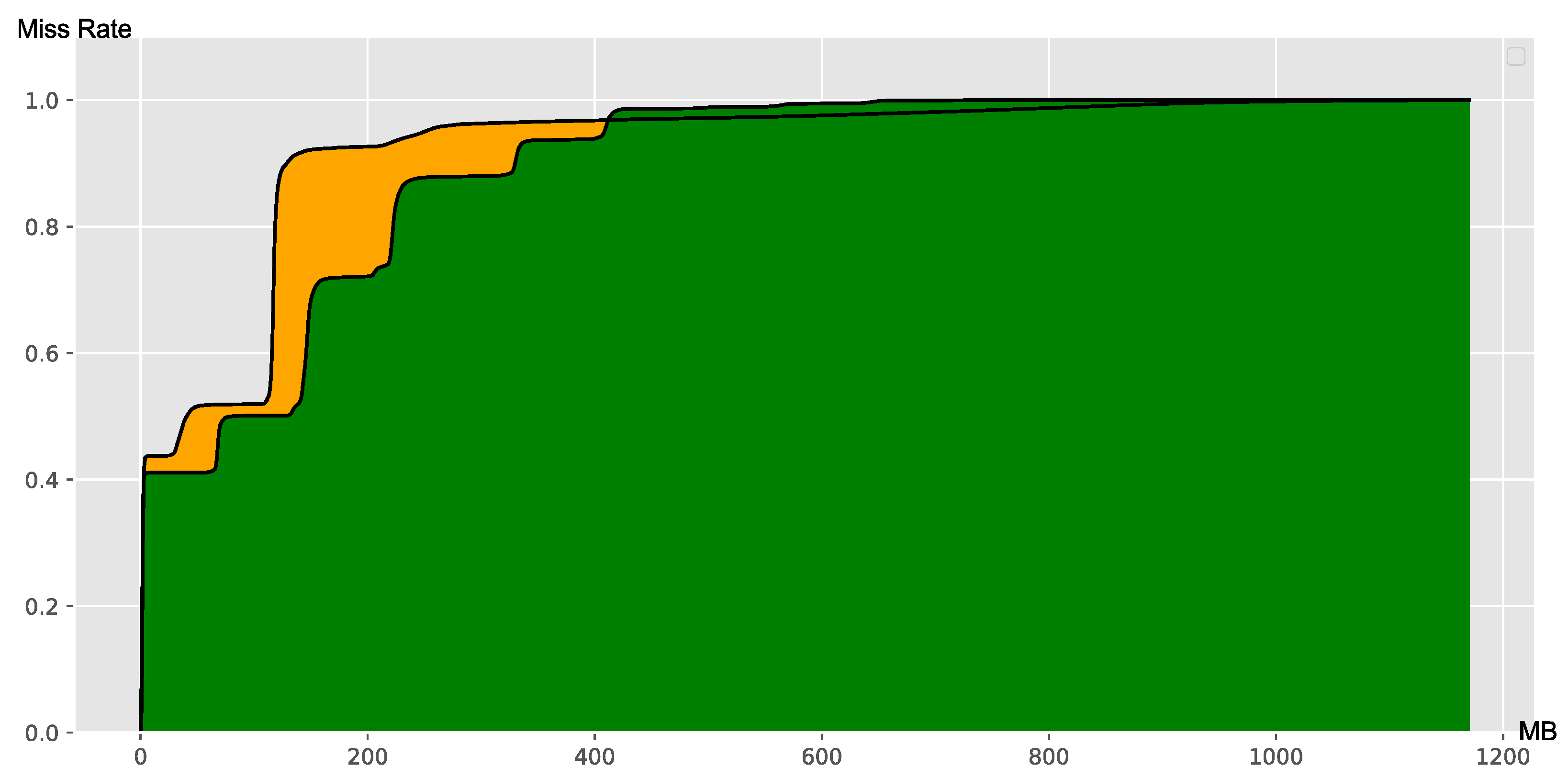
2.1. Cache Performance Cliff
2.2. Cliff Potential Performance Analysis
3. The Design of the Cliff-Aware Cache Allocation Algorithm
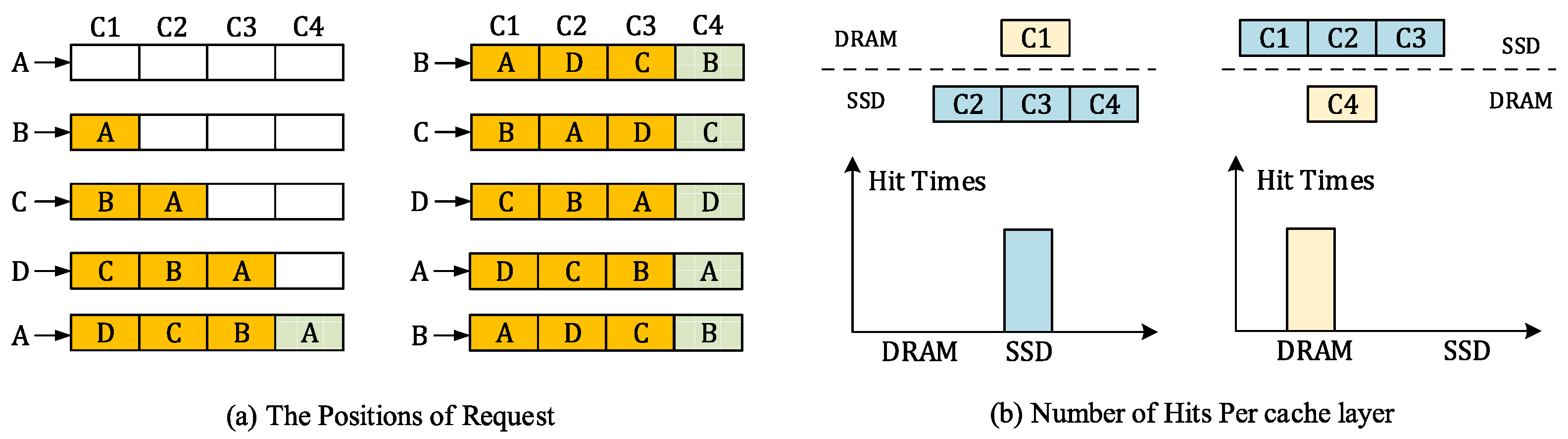
3.1. Cache Performance Cliff Positioning
3.2. Cliff-Aware Cache Allocation Algorithm
- Collect application access characteristics to generate an MRC curve using the fixed space or fixed rate sampling method.
- Generate a convex hull point set according to the MRC curve.
- The allocation algorithm takes the convex hull set as input, and locates the cache cliff area from the convex hull set.
- Locate the starting point, turning point, and ending point of the cliff in the cliff area. From the starting point to the turning point is a stable area, and from the turning point to the end point is a performance area. Traverse all feasible cache allocation schemes, and calculate the optimal allocation result of the performance function. The definition of the performance function is related to the cache capacity, cache cost, expected hit rate, etc.
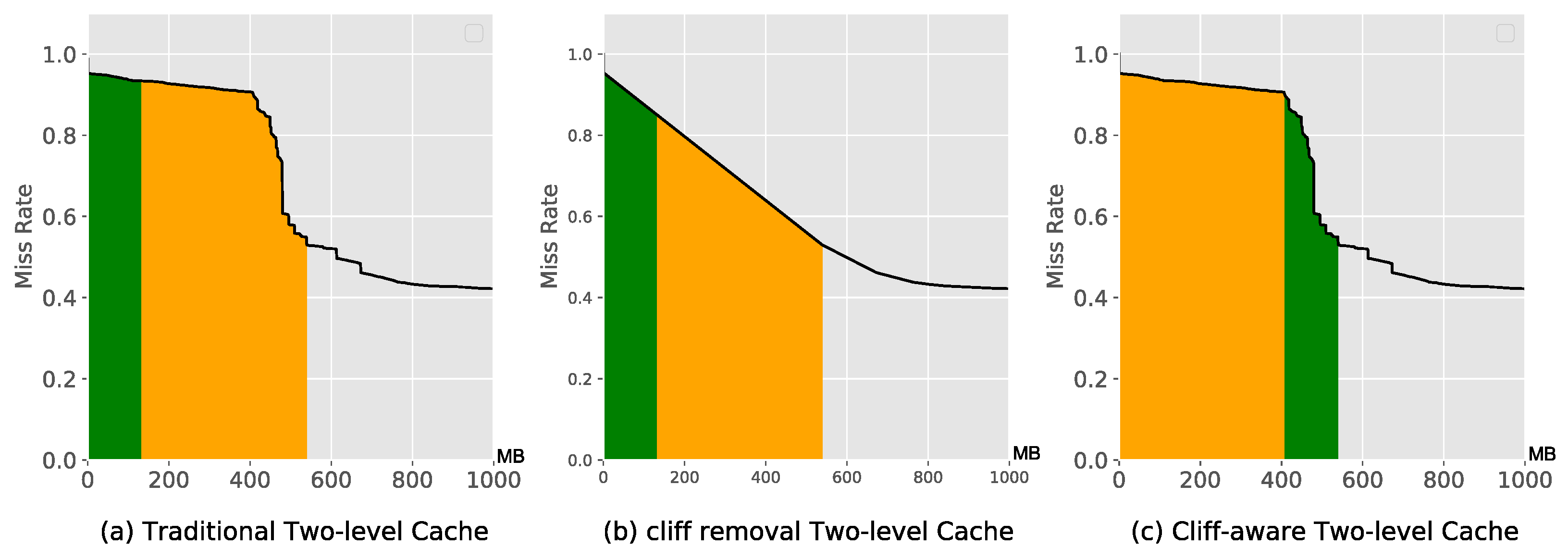
- The plan of not doing any treatment. Directly according to the original MRC allocation, the allocation finds the first-level cache standard point and the second-level cache standard point, and the cost value at this time is the minimum cost.
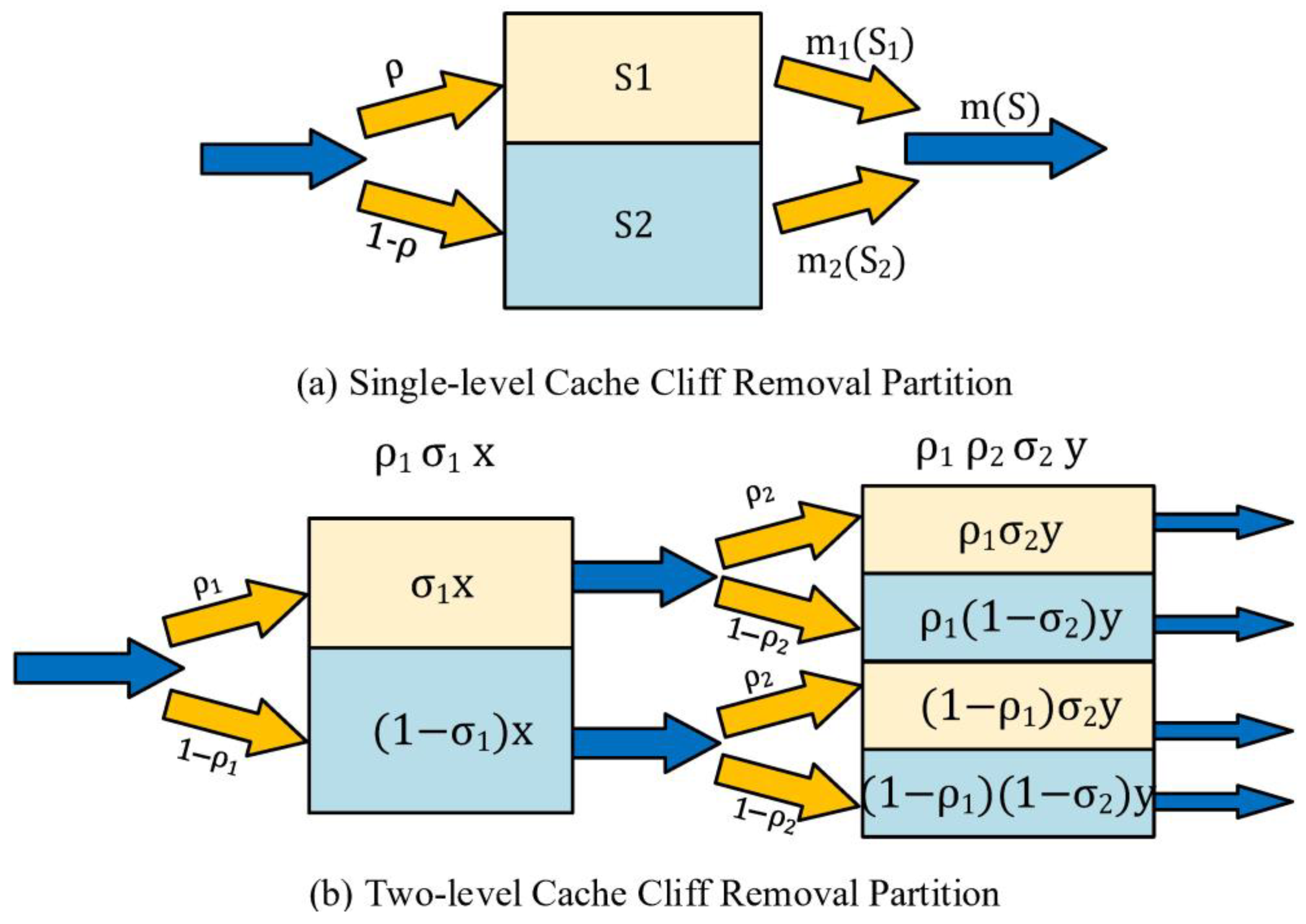
- Cliff removal plan. Similar to (1), but first remove the performance cliff in the form of partitions, and then perform cache allocation and calculation accommodation.
- Cliff perception assignment. Based on the cliff split point, expand the capacity forward or backward, and calculate the performance function. Complete the traversal of all feasible capacities.
| Algorithm 1 Cliff-aware Cache Allocation Algorithm |
| Input: |
| SLO: The SLO target of the ith Application |
| cliff_begin: the starting position of performance cliff |
| cliff_end: the ending position of performance cliff |
| Output: |
| x: the desired DRAM capacity at least cost |
| y: the desired SSD capacity at least cost |
| B = [] |
| M = 0 |
| if performace(cliff_end−cliff_begin.,cliff_begin)) ≥ SLO then |
| B.append(cliff_end−cliff_begin.,cliff_begin) |
| for m = cliff_end; m ≥ 0; left_shrink(m) do |
| for n = cliff_begin; n ≤ m; right_shrink(n) do |
| if performance(m − n, m) < SLO then |
| left_expand(n) |
| B.append(m − n, m) |
| break |
| end if |
| end for |
| end for |
| else: |
| While (performace(cliff_end−cliff_begin.,cliff_begin)) ≤ SLO) |
| right_expand (cliff_end); |
| for m = cliff_end; m ≤ max_cache_size; right_expand (m) do |
| for n = cliff_begin; n ≥ 0; left_expand(n) do |
| if performance(m − n, m) ≥ SLO then |
| B.append(m − n, m) |
| break |
| end if |
| end for |
| end for |
| end if |
| x = B [0][0] |
| y = B [0][1] |
| min_cost = cost(x,y) |
| for i←1; i≤ B.size(); i++ do |
| if cost(B[i][0], B[i][1]) < min_cost then: |
| min_cost = cost(B[i][0], B[i][1] |
| x = B[i][0] |
| y = B[i][1] |
| end if |
| end for |
| return x, y |
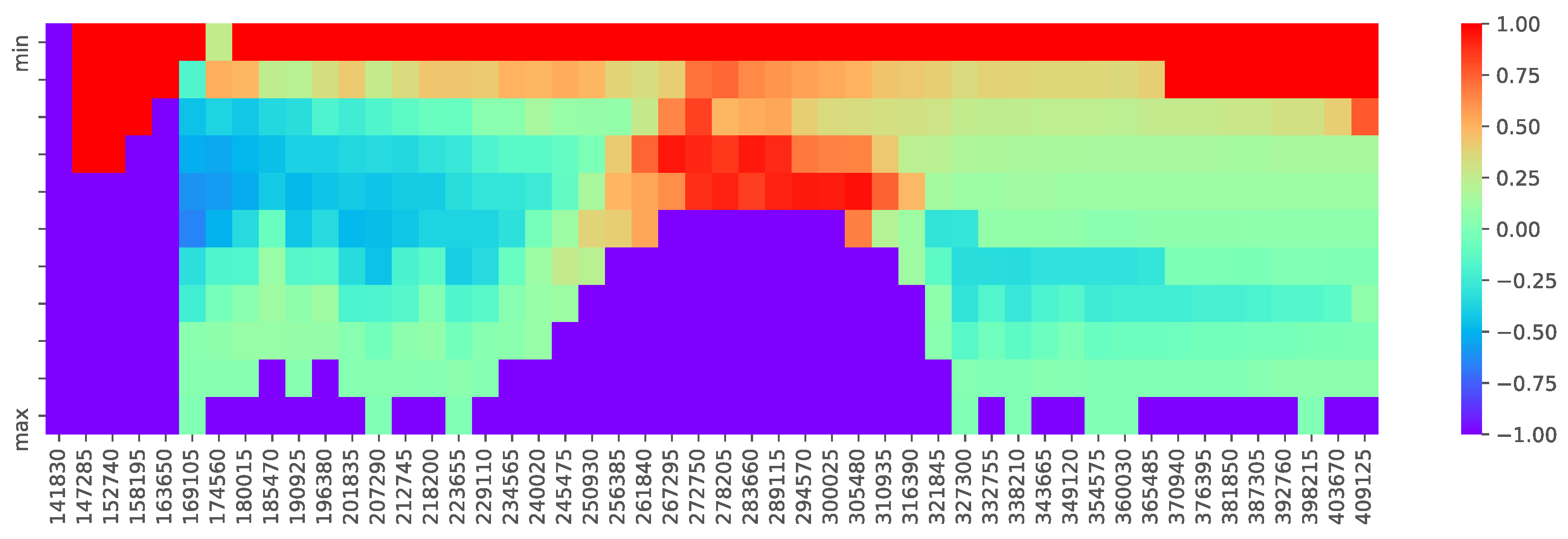
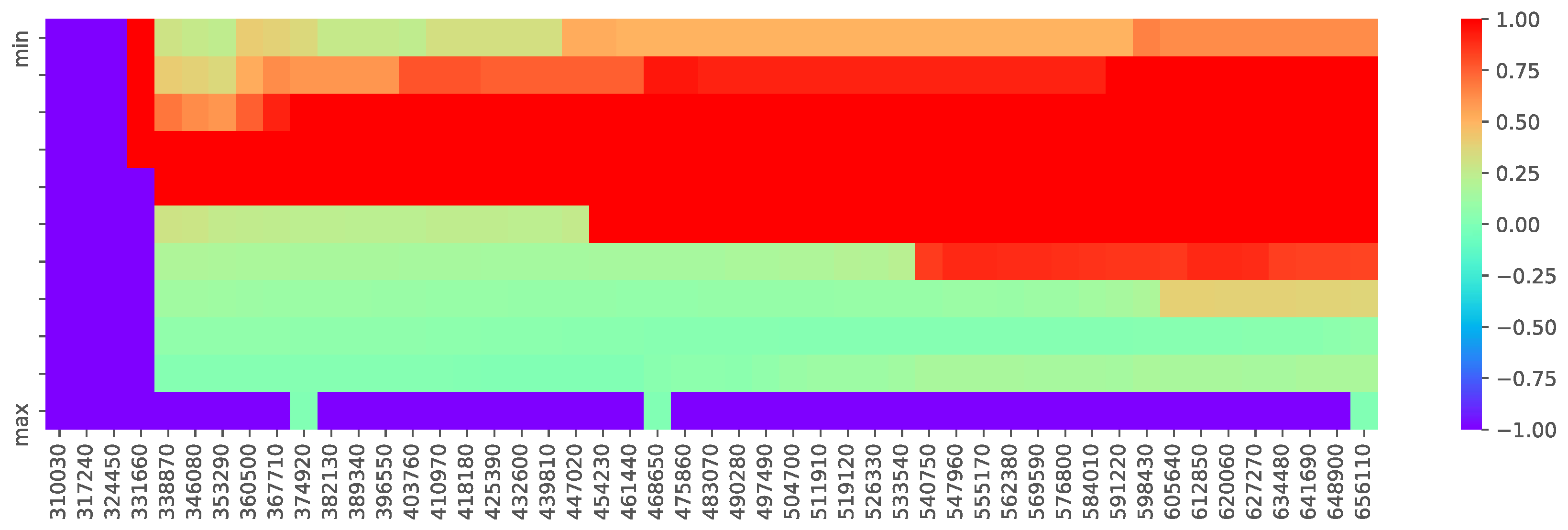
3.3. Constraints
4. Experimental Methodology
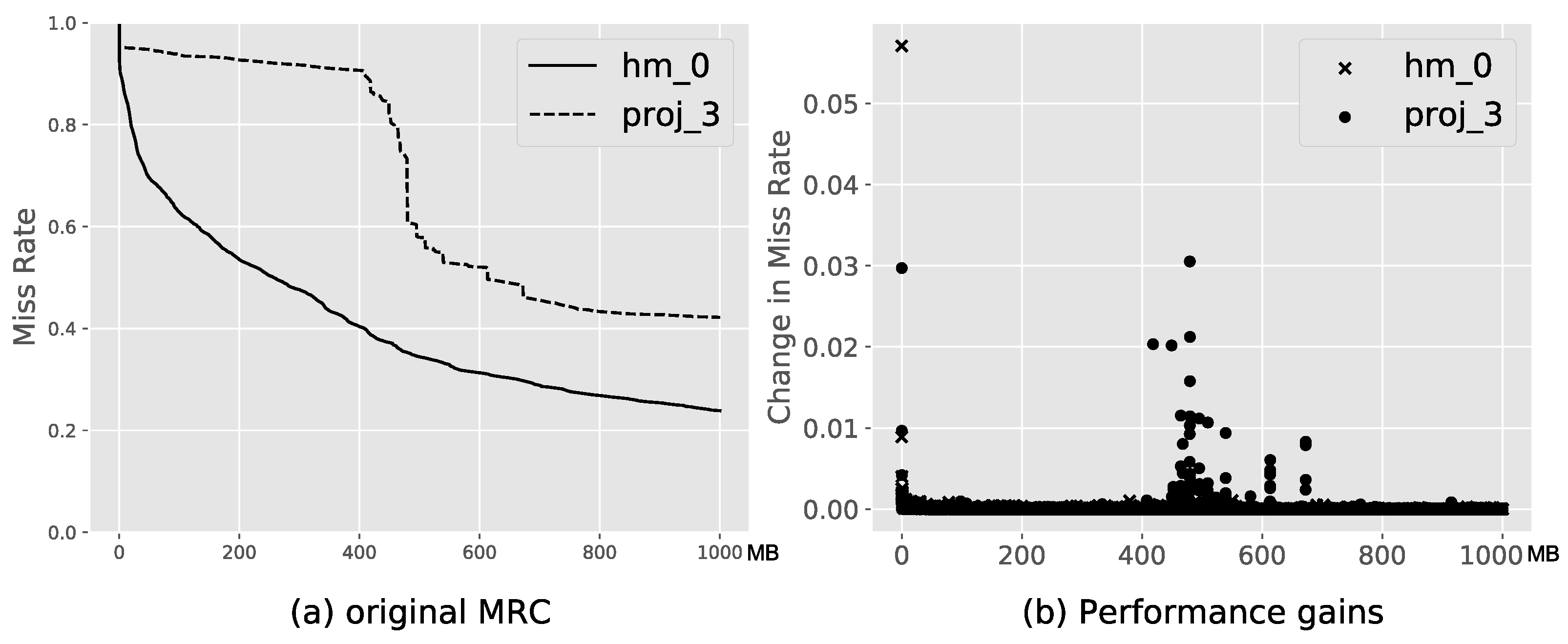
4.1. Minimum Cost Cache Allocation
4.2. Running on Real Devices
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reinsel, D.; Gantz, J.; Rydning, J. Data Age 2025: The Evolution of Data to Life-Critical Don’t Focus on Big Data; IDC Analyze the Future: Framingham, MA, USA, 2017. [Google Scholar]
- Mastour, N.; Jemaï, M.; Ridene, S. Calculation of ground state and Hartree energies of MoS2/WSe2 assembled type II quantum well. Micro Nanostruct. 2022, 171, 207417. [Google Scholar] [CrossRef]
- Mastour, N.; Ramachandran, K.; Ridene, S.; Daoudi, K.; Gaidi, M. Tailoring the optical band gap of In–Sn–Zn–O (ITZO) nanostructures with co-doping process on ZnO crystal system: An experimental and theoretical validation. Eur. Phys. J. Plus 2022, 137, 1137. [Google Scholar] [CrossRef]
- Jlidi, Z.; Baachaoui, S.; Raouafi, N.; Ridene, S. Temperature effect on structural, morphological and optical properties of 2D-MoS2 layers: An experimental and theoretical study. Optik 2021, 228, 166166. [Google Scholar] [CrossRef]
- Górski, T.; WOźniak, A.P. Optimization of Business Process Execution in Services Architecture: A Systematic Literature Review. IEEE Access 2021, 9, 111833–111852. [Google Scholar] [CrossRef]
- Saboor, A.; Hassan, M.F.; Akbar, R.; Shah, S.N.M.; Hassan, F.; Magsi, S.A.; Siddiqui, M.A. Containerized Microservices Orchestration and Provisioning in Cloud Computing: A Conceptual Framework and Future Perspectives. Appl. Sci. 2022, 12, 5793. [Google Scholar] [CrossRef]
- Liu, Z.; Lee, H.W.; Xiang, Y.; Grunwald, D.; Ha, S. eMRC: Efficient Miss Ratio Approximation for Multi-Tier Caching. In Proceedings of the FAST, Virtual, 23–25 February 2021; pp. 293–306. Available online: https://www.usenix.org/conference/fast21/presentation/liu (accessed on 1 January 2023).
- Shasha, D.; Johnson, T. 2q: A low overhead high performance buffer management replacement algorithm. In Proceedings of the 20th International Conference on Very Large Data Bases, New York, NY, USA, 12 September 1994; pp. 439–450. [Google Scholar]
- Megiddo, N.; Modha, D.S. ARC: A Self-Tuning, Low Overhead Replacement Cache. In Proceedings of the FAST ’03 Conference, San Francisco, CA, USA, 31 March–2 April 2003; Volume 3, pp. 115–130. [Google Scholar] [CrossRef]
- Jiang, S.; Zhang, X. LIRS: An efficient low inter-reference recency set replacement policy to improve buffer cache performance. ACM Sigmetr. Perform. Eval. Rev. 2002, 30, 31–42. [Google Scholar] [CrossRef]
- Zhou, K.; Sun, S.; Wang, H.; Huang, P.; He, X.; Lan, R.; Li, W.; Liu, W.; Yang, T. Demystifying cache policies for photo stores at scale: A tencent case study. In Proceedings of the 2018 International Conference on Supercomputing, Beijing, China, 12–15 June 2018; pp. 284–294. [Google Scholar] [CrossRef]
- Mattson, R.L.; Gecsei, J.; Slutz, D.R.; Traiger, I.L. Evaluation techniques for storage hierarchies. IBM Syst. J. 1970, 9, 78–117. [Google Scholar] [CrossRef]
- Niu, Q.; Dinan, J.; Lu, Q.; Sadayappan, P. PARDA: A fast parallel reuse distance analysis algorithm. In Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium, Shanghai, China, 21–25 May 2012; pp. 1284–1294. [Google Scholar] [CrossRef]
- Waldspurger, C.A.; Park, N.; Garthwaite, A.T.; Ahmad, I. Efficient MRC Construction with SHARDS. In Proceedings of the FAST, Santa Clara, CA, USA, 16–19 February 2015; Volume 15, pp. 95–110. [Google Scholar] [CrossRef]
- Carra, D.; Neglia, G. Efficient miss ratio curve computation for heterogeneous content popularity. In Proceedings of the 2020 USENIX Conference on Usenix Annual Technical Conference, Rome, Italy, 15–17 July 2020; pp. 741–751. [Google Scholar] [CrossRef]
- Waldspurger, C.A.; Saemundsson, T.; Ahmad, I.; Park, N. Cache Modeling and Optimization using Miniature Simulations. In Proceedings of the USENIX Annual Technical Conference, Santa Clara, CA, USA, 12–14 July 2017; pp. 487–498. [Google Scholar] [CrossRef]
- Hu, X.; Wang, X.; Zhou, L.; Luo, Y.; Wang, Z.; Ding, C.; Ye, C. Fast miss ratio curve modeling for storage cache. ACM Trans. Storage (TOS) 2018, 14, 1–34. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, P.; Zhou, K.; Wang, H.; Hu, J.; Ji, Y.; Cheng, B. OSCA: An online-model based cache allocation scheme in cloud block storage systems. In Proceedings of the 2020 USENIX Conference on Usenix Annual Technical Conference, Online, 15–17 July 2020; pp. 785–798. [Google Scholar] [CrossRef]
- Beckmann, N.; Sanchez, D. Talus: A simple way to remove cliffs in cache performance. In Proceedings of the 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), Huazhong, China, 15–17 July 2020; pp. 64–75. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Wang, Y.; Wang, Z. Efficient modeling of random sampling-based lru. In Proceedings of the 50th International Conference on Parallel Processing, Lemont, IL, USA, 9–12 August 2021; pp. 1–11. [Google Scholar] [CrossRef]
- Arteaga, D.; Ahmad, I.; Cabrera, J.; Jun, S.; Xu, J.; Xu, S.; Sundararaman, S.; Zhao, M.; Zhen, S.; Tarasov, V.; et al. Cloudcache: On-demand flash cache management for cloud computing. In Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST 16), Santa Clara, CA, USA, 22–25 February 2016; pp. 355–369. [Google Scholar] [CrossRef]
- Prabhakar, R.; Srikantaiah, S.; Patrick, C.; Kandemir, M. Dynamic storage cache allocation in multi-server architectures. In Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, Portland, OR, USA, 14–20 November 2009; pp. 1–12. [Google Scholar] [CrossRef]
- Cidon, A.; Eisenman, A.; Alizadeh, M.; Katti, S. Cliffhanger: Scaling performance cliffs in web memory caches. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), Santa Clara, CA, USA, 17–18 March 2016; pp. 379–392. [Google Scholar] [CrossRef]
- Rajasekaran, S.; Duan, S.; Zhang, W.; Wood, T. Multi-cache: Dynamic, efficient partitioning for multi-tier caches in consolidated VM environments. In Proceedings of the 2016 IEEE International Conference on Cloud Engineering (IC2E), Berlin, Germany, 4–8 April 2016; pp. 182–191. [Google Scholar] [CrossRef]
- Meng, F.; Zhou, L.; Ma, X.; Uttamchandani, S.; Liu, D. vCacheShare: Automated Server Flash Cache Space Management in a Virtualization Environment. In Proceedings of the USENIX Annual Technical Conference, Philadelphia, PA, USA, 19–20 June 2014; pp. 133–144. [Google Scholar] [CrossRef]
- Narayanan, D.; Donnelly, A.; Rowstron, A. Write off-loading: Practical power management for enterprise storage. ACM Trans. Storage (TOS) 2008, 4, 1–23. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Capacity | ρ1 | σ1 | ρ2 | σ2 | DRAM Hit |
|---|---|---|---|---|---|
| (0, 8) | 0 | ||||
| (1, 7) | 0.875 | 0 | 0.375 | 0 | 9 |
| (2, 6) | 0.75 | 0 | 0.5 | 0 | 9 |
| (3, 5) | 0.625 | 0 | 0.375 | 0 | 18 |
| (4, 4) | 0.5 | 0 | 0.5 | 0 | 36 |
| (5, 3) | 0.375 | 0 | 0.625 | 0 | 36 |
| (6, 2) | 0.25 | 0 | 0.75 | 0 | 9 |
| (7, 1) | 0.125 | 0 | 0.875 | 0 | 63 |
| (8, 0) | 0 |
| Parameter | Value |
|---|---|
| cliff_size_threshold | 0.2 |
| cliff_hit_rate_threshold | 0.4 |
| capacity_proportion | 0.6 |
| hit_rate_proportion | 0.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Zhang, C.; Nie, S.; Duan, K.; Wu, W. PC-Allocation: Performance Cliff-Aware Two-Level Cache Resource Allocation Scheme for Storage System. Appl. Sci. 2023, 13, 3556. https://doi.org/10.3390/app13063556
Liu S, Zhang C, Nie S, Duan K, Wu W. PC-Allocation: Performance Cliff-Aware Two-Level Cache Resource Allocation Scheme for Storage System. Applied Sciences. 2023; 13(6):3556. https://doi.org/10.3390/app13063556
Chicago/Turabian StyleLiu, Song, Chen Zhang, Shiqiang Nie, Keqiang Duan, and Weiguo Wu. 2023. "PC-Allocation: Performance Cliff-Aware Two-Level Cache Resource Allocation Scheme for Storage System" Applied Sciences 13, no. 6: 3556. https://doi.org/10.3390/app13063556