
Improving Deep Echo State Network with Neuronal Similarity-Based Iterative Pruning Merging Algorithm

Abstract
:1. Introduction
- A new NS-IPMA that works effectively in improving the generalization performance of DeepESN is proposed.
- The proposed method contributes to simplifying the structure of DeepESN and reducing computational cost.
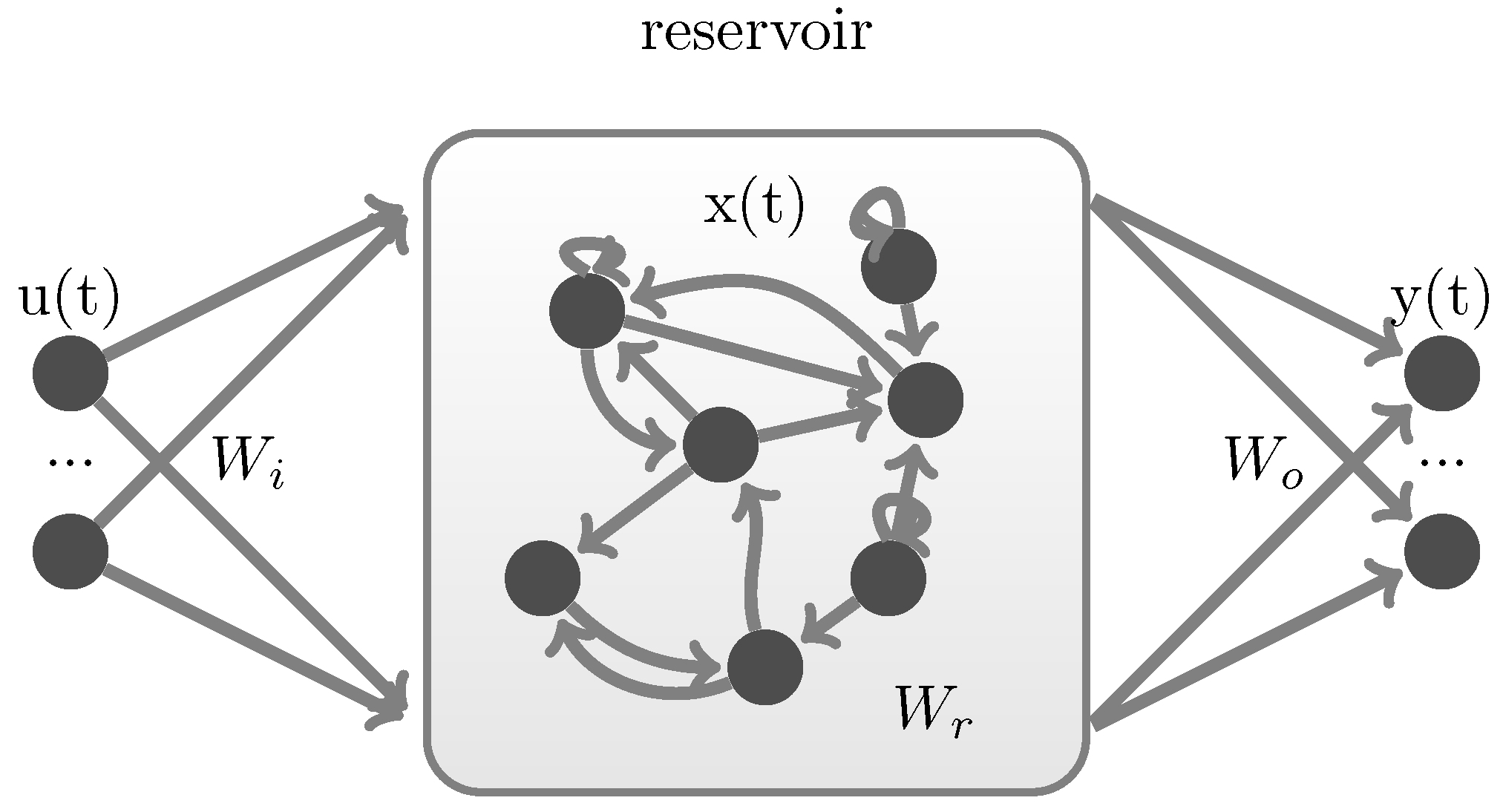
2. Deep Echo State Network
2.1. Leaky Integrator Echo State Network
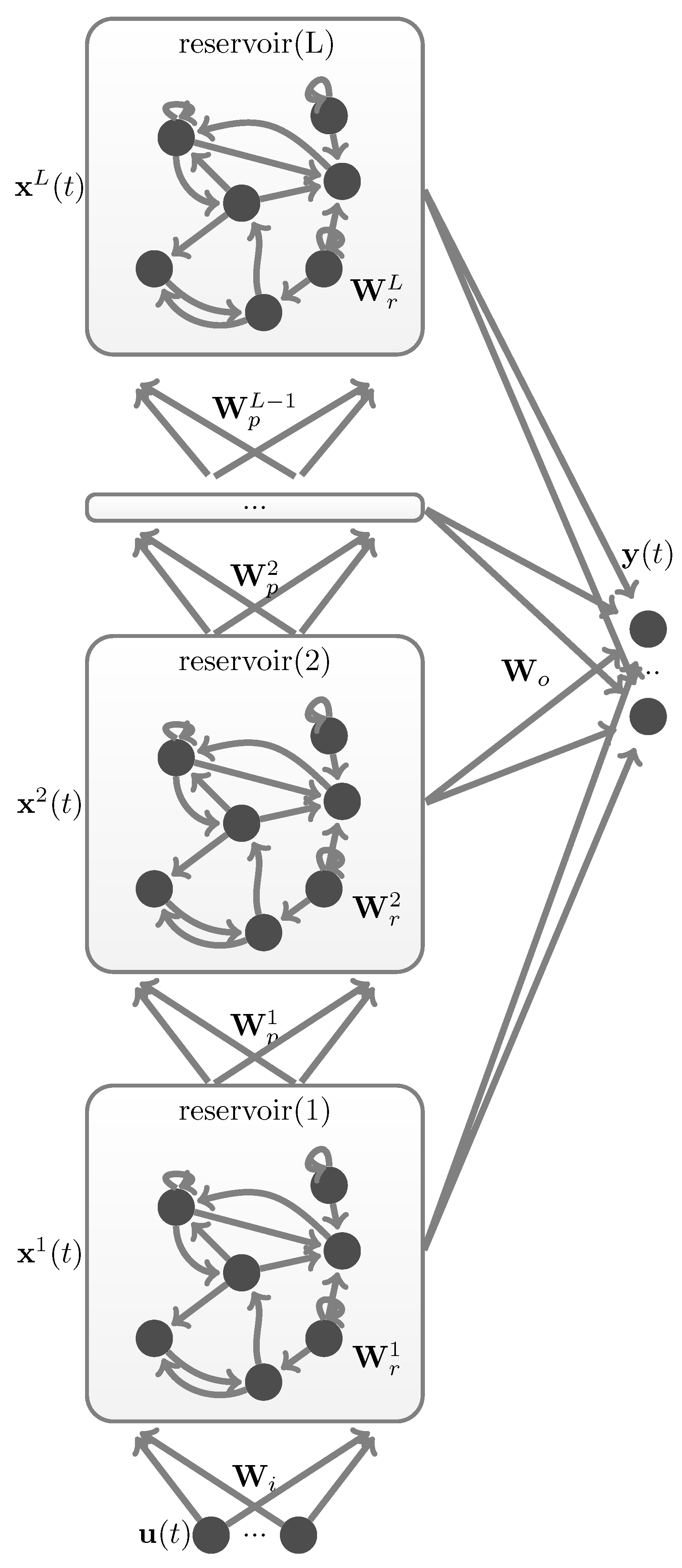
2.2. Deep Echo State Network
2.3. Architectural Richness of DeepESN
3. Pruning Deep Echo State Network with a Neuronal Similarity-Based Iterative Pruning Merging Algorithm
3.1. Sensitive Iterative Pruning Algorithm to Simple Cycle Reservoir Network
- Establish an SCRN with a large enough reservoir and satisfactory performance.
- Establish a new link between two neighbors of pruned neurons, the link weight is determined to eliminate the perturbation caused by pruning, denoting the input to before pruning , the input to after pruning , the perturbation is eliminated, and the original reservoir behavior is maintained as long as is set as close as possible to , by solving the following optimization problem:
- Adjust the output weights by retraining the network, and then calculate the training error.
- Repeat steps 2–4 until the training error or the reservoir size reaches an acceptable range.
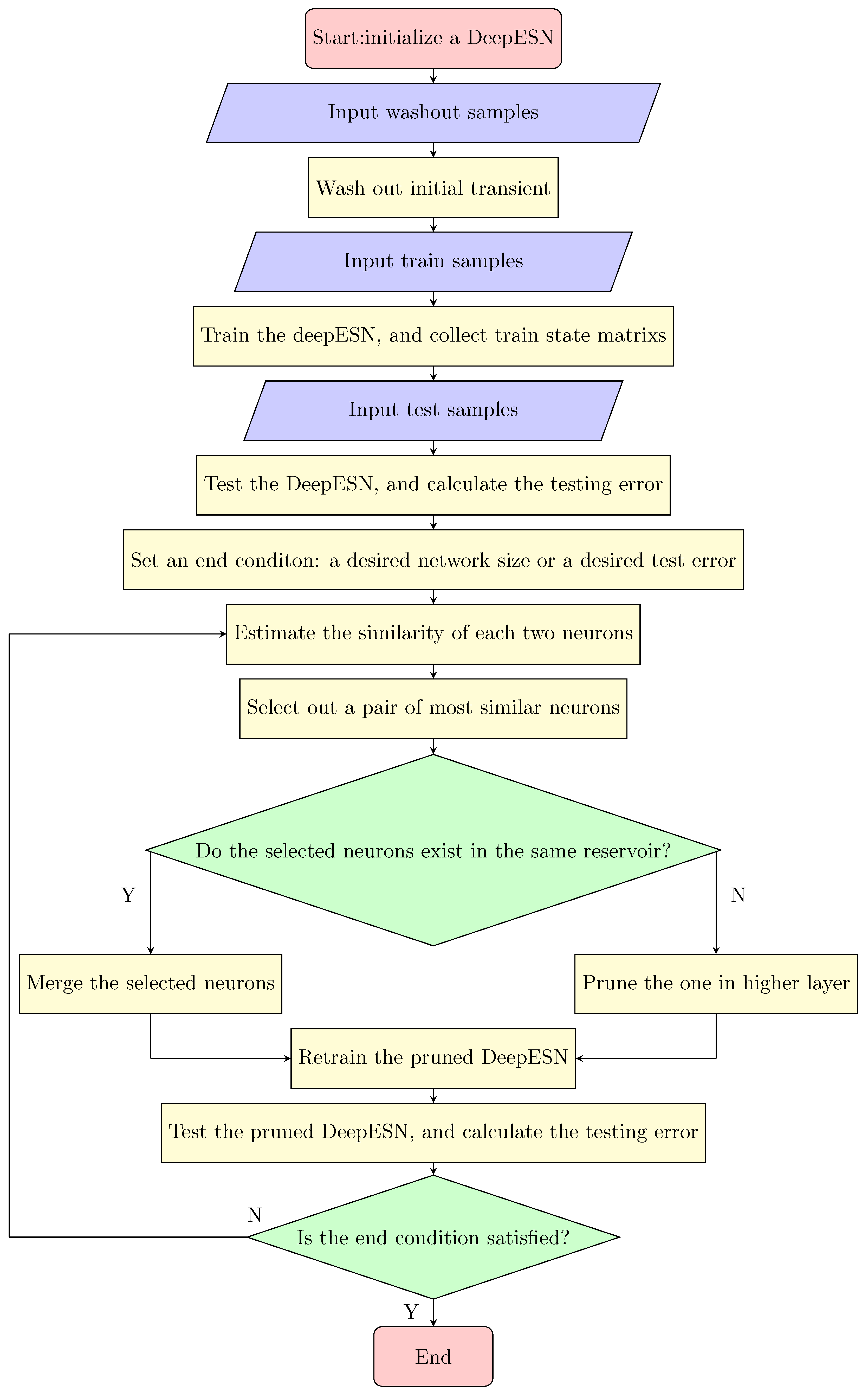
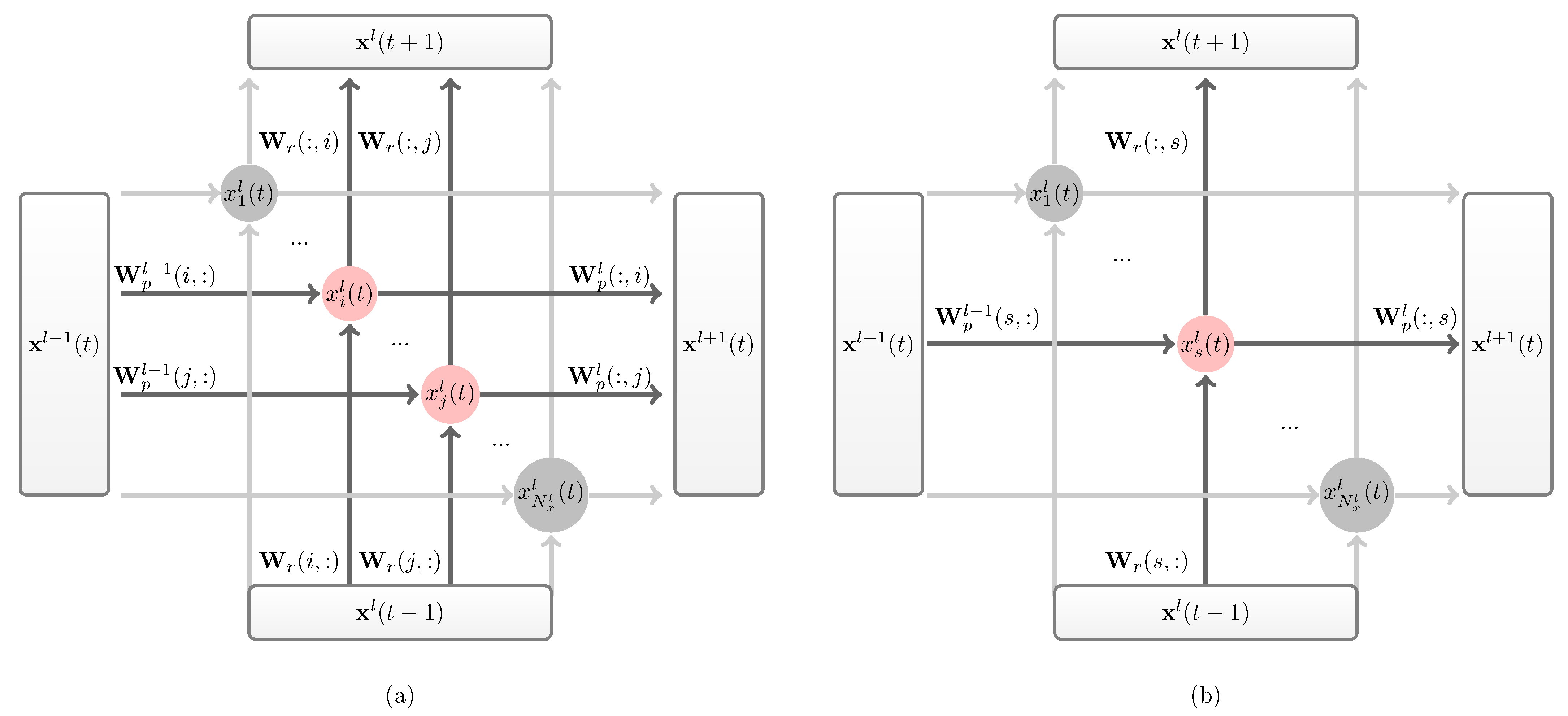
3.2. Neuronal Similarity-Based Iterative Pruning Merging Algorithm to Deep Echo State Network
- Initially generate a performable DeepESN with large enough reservoirs by tuning hyperparameters to minimize the average of training and validate error using the particle swarm optimization (PSO) algorithm; please refer to Appendix A for more details on hyperparameter tuning. This DeepESN is a primitive network to implement.
- Washout the reservoirs, and activate the reservoirs using training samples to obtain the training state matrix.
- (a)
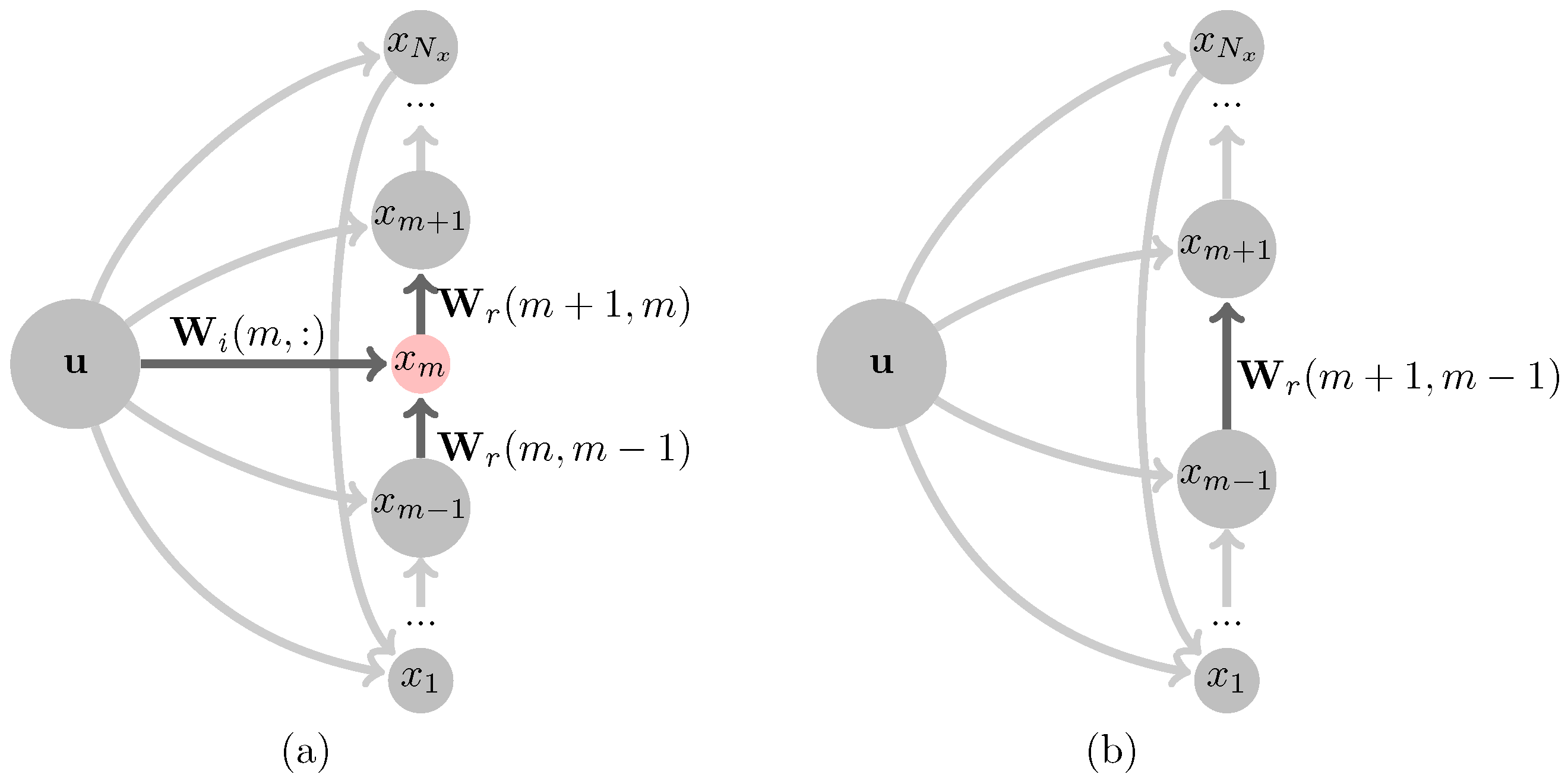
- If selected neurons are in the same reservoir (note as and ), merge them. As diagramed in Figure 5, is the son neurons merged as the substitute of its parents and . l is the reservoir layer where and exist. The related weight matrix , and is refreshed as follows:if , perform as ; if , does not exist.
- (b)
- If selected neurons are in different reservoirs (note as and ), prune one in a high layer (assume ). The related weight matrix , and is refreshed as follows:if , perform as ; if , does not exist.
- Adjust the output weights by retraining the network, and then estimate the performance of the current network.
- Repeat steps 2–5 until the training error or the network size reaches an acceptable range.
4. Experiments
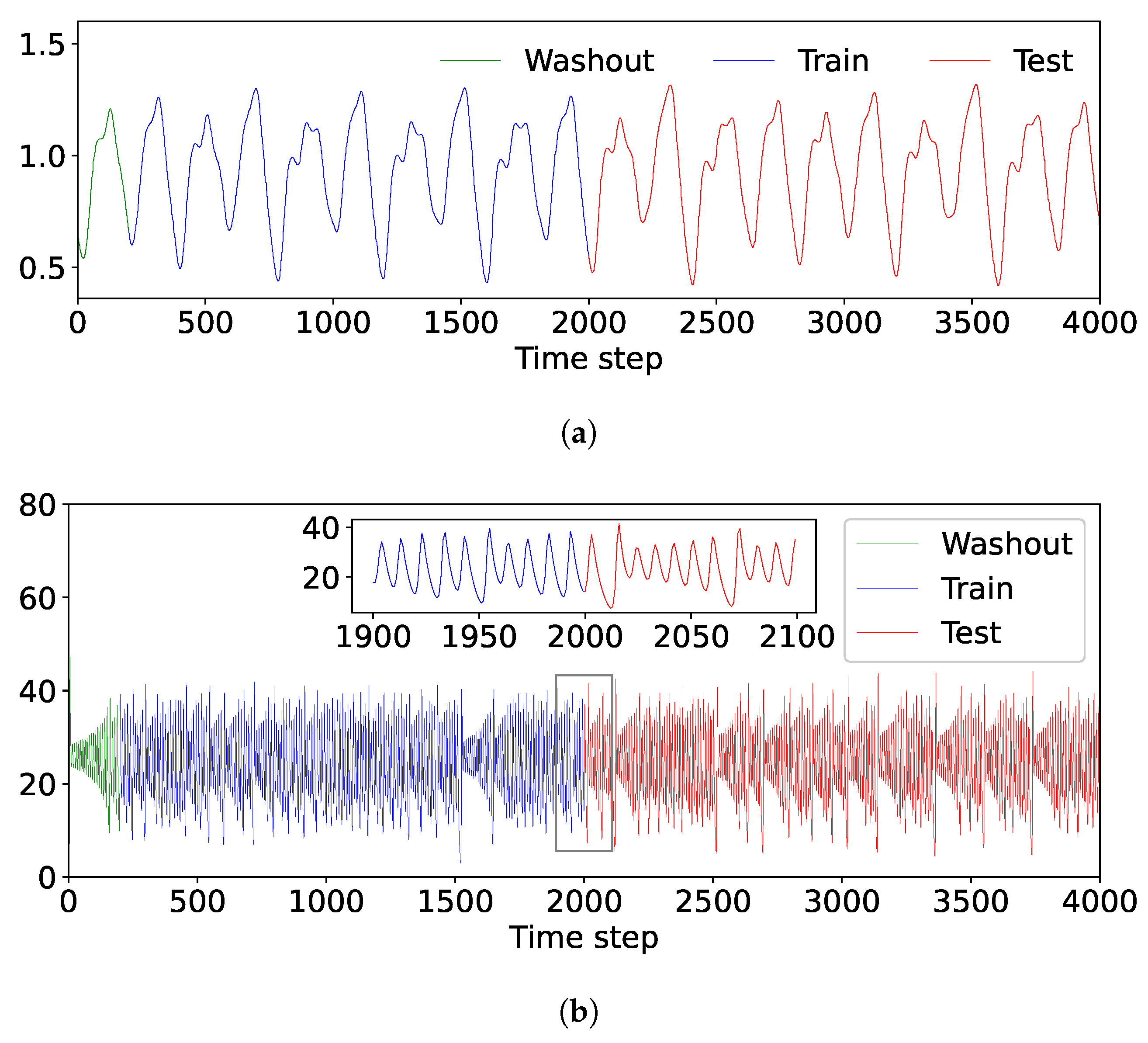
4.1. Datasets
4.1.1. Mackey–Glass Chaotic Time Series
4.1.2. Lorenz Chaotic Time Series
4.2. Next Spot Prediction Task
4.3. Ablation Experiment and Control Experiment
5. Results and Discussion
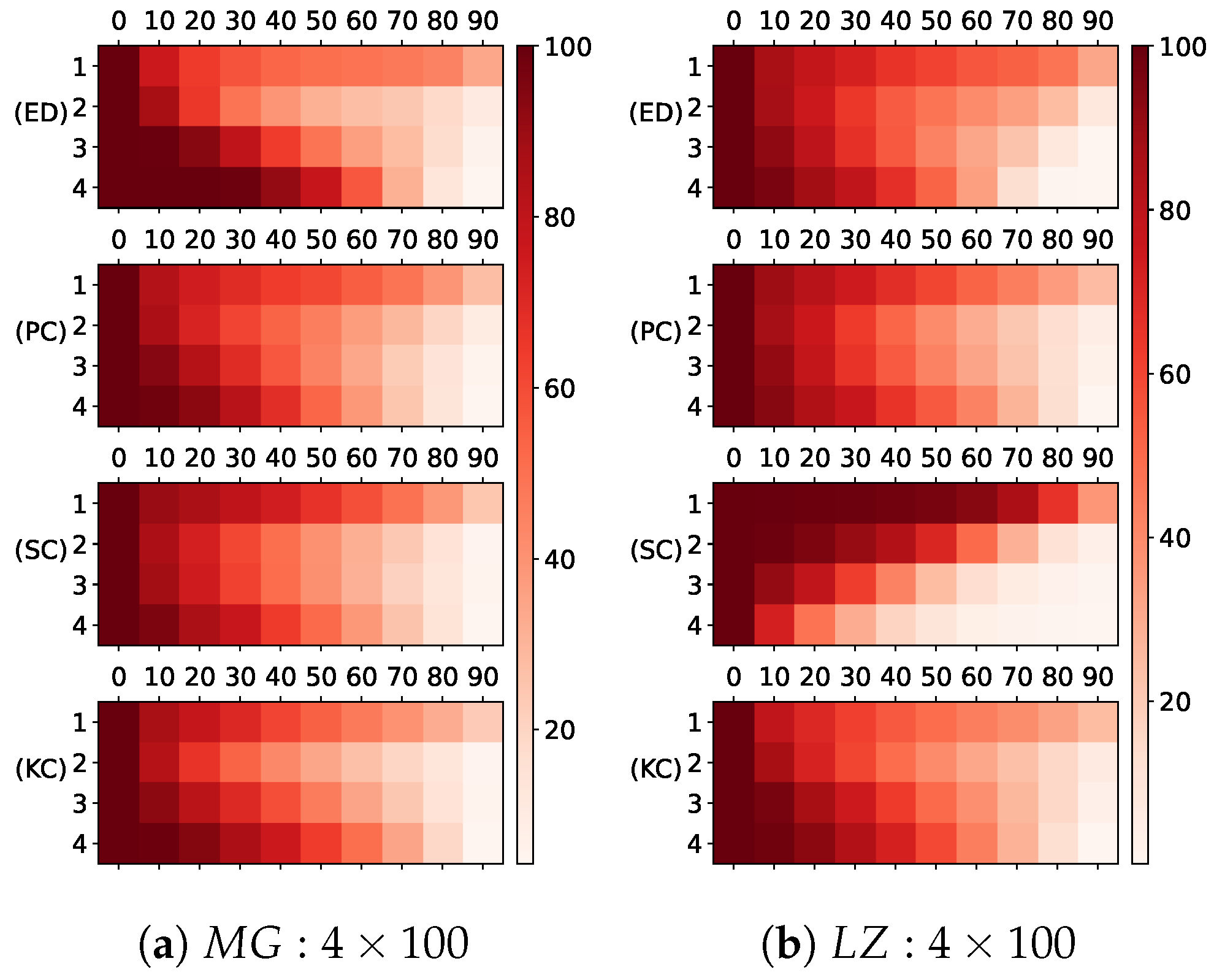
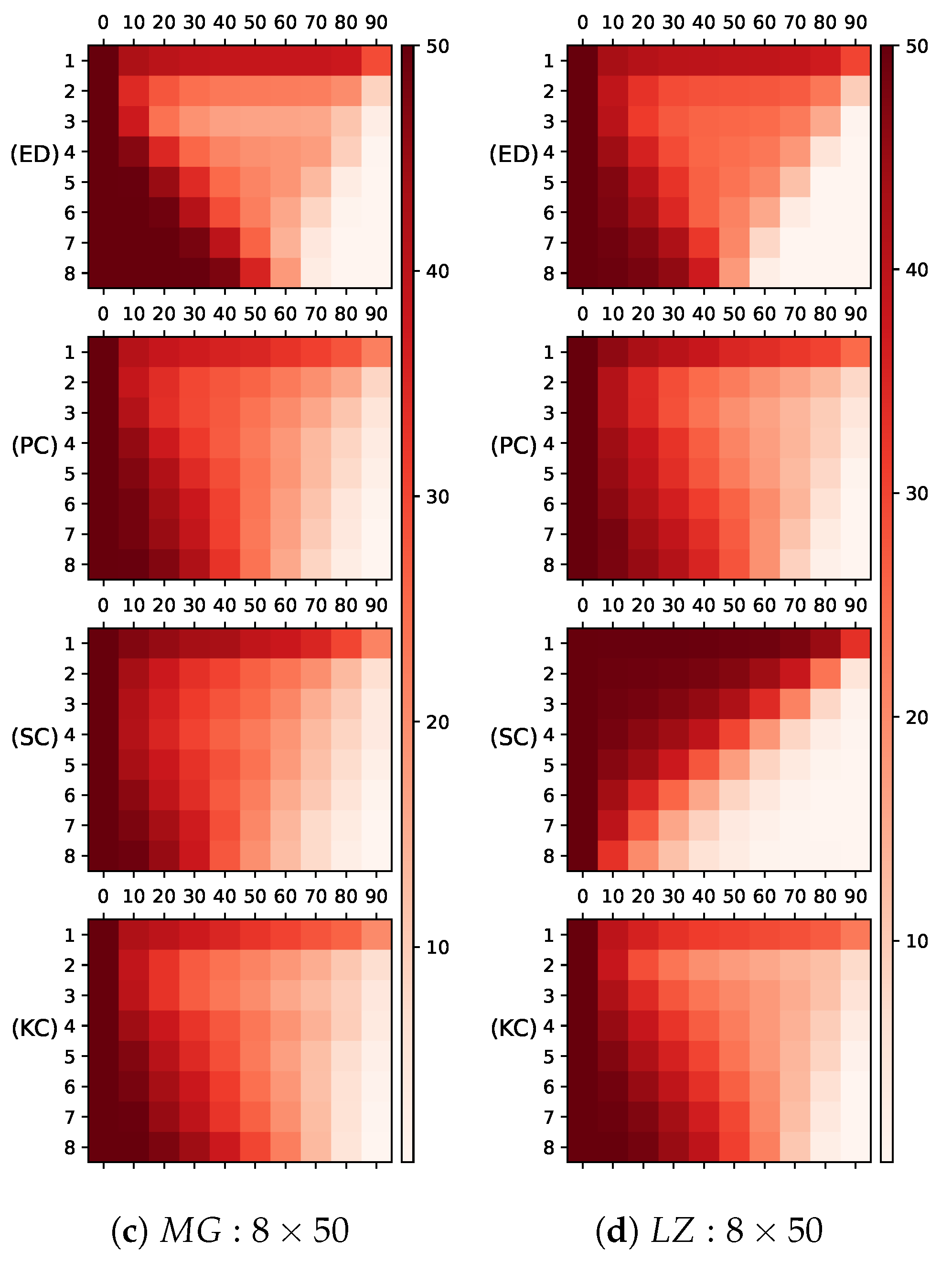
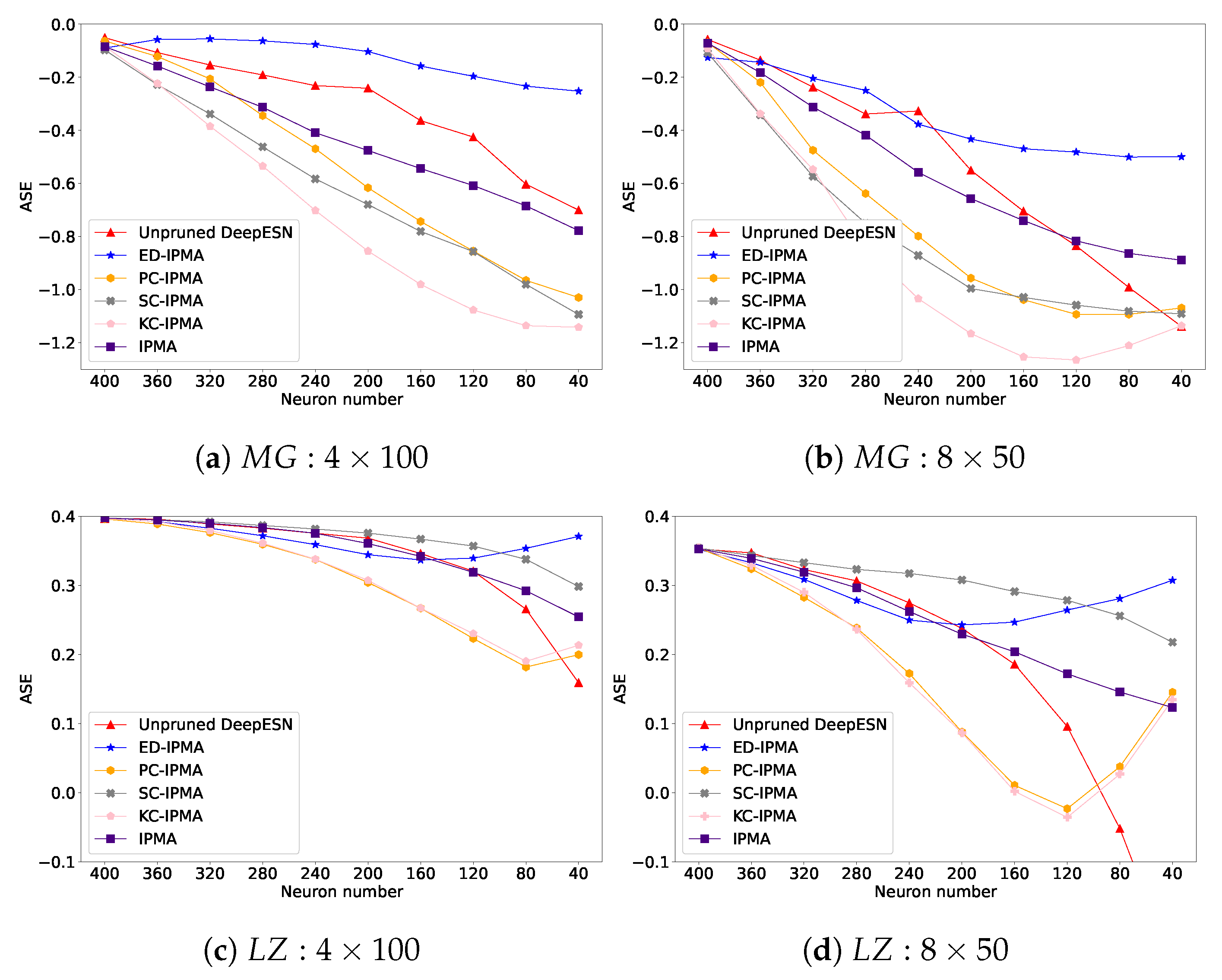
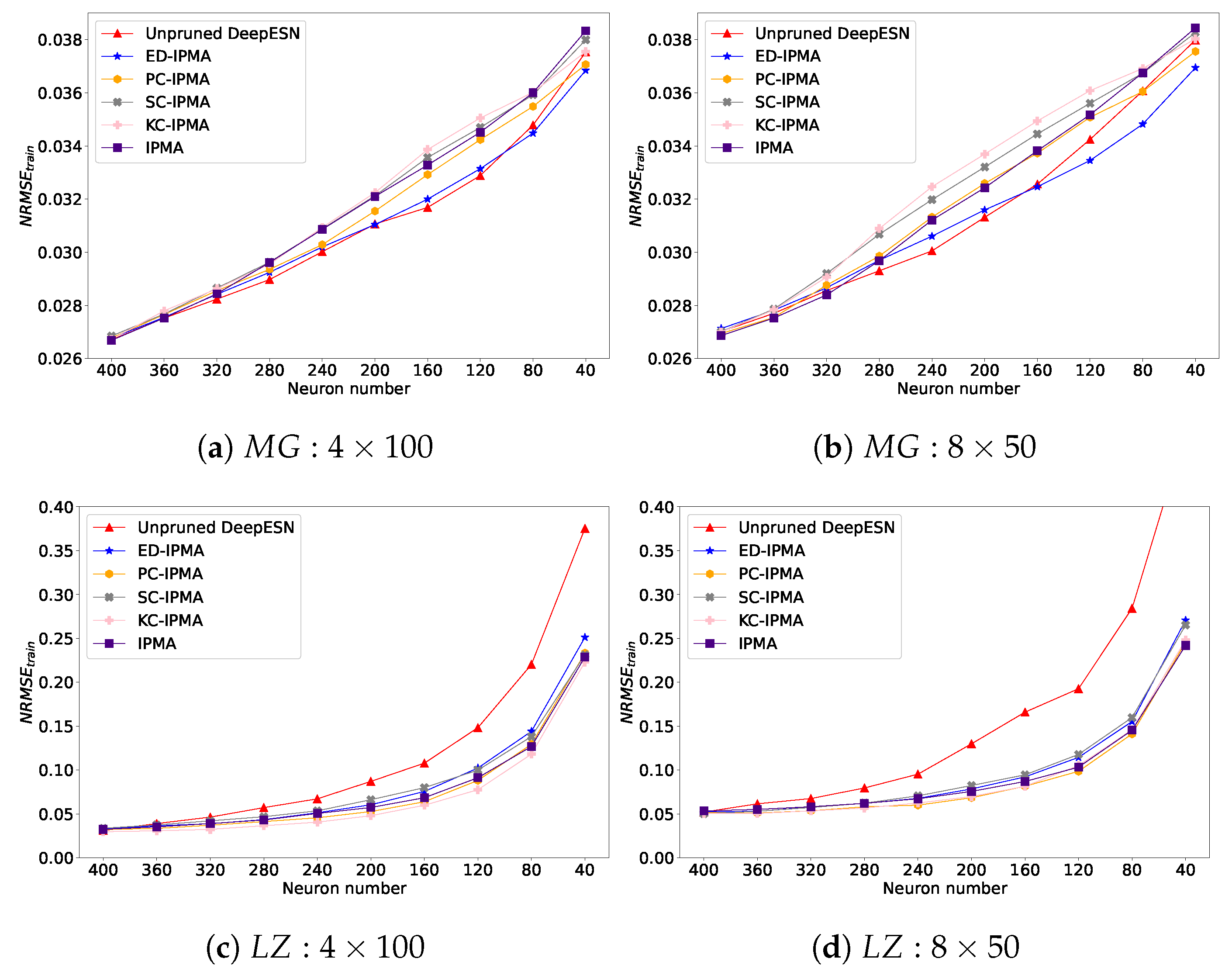
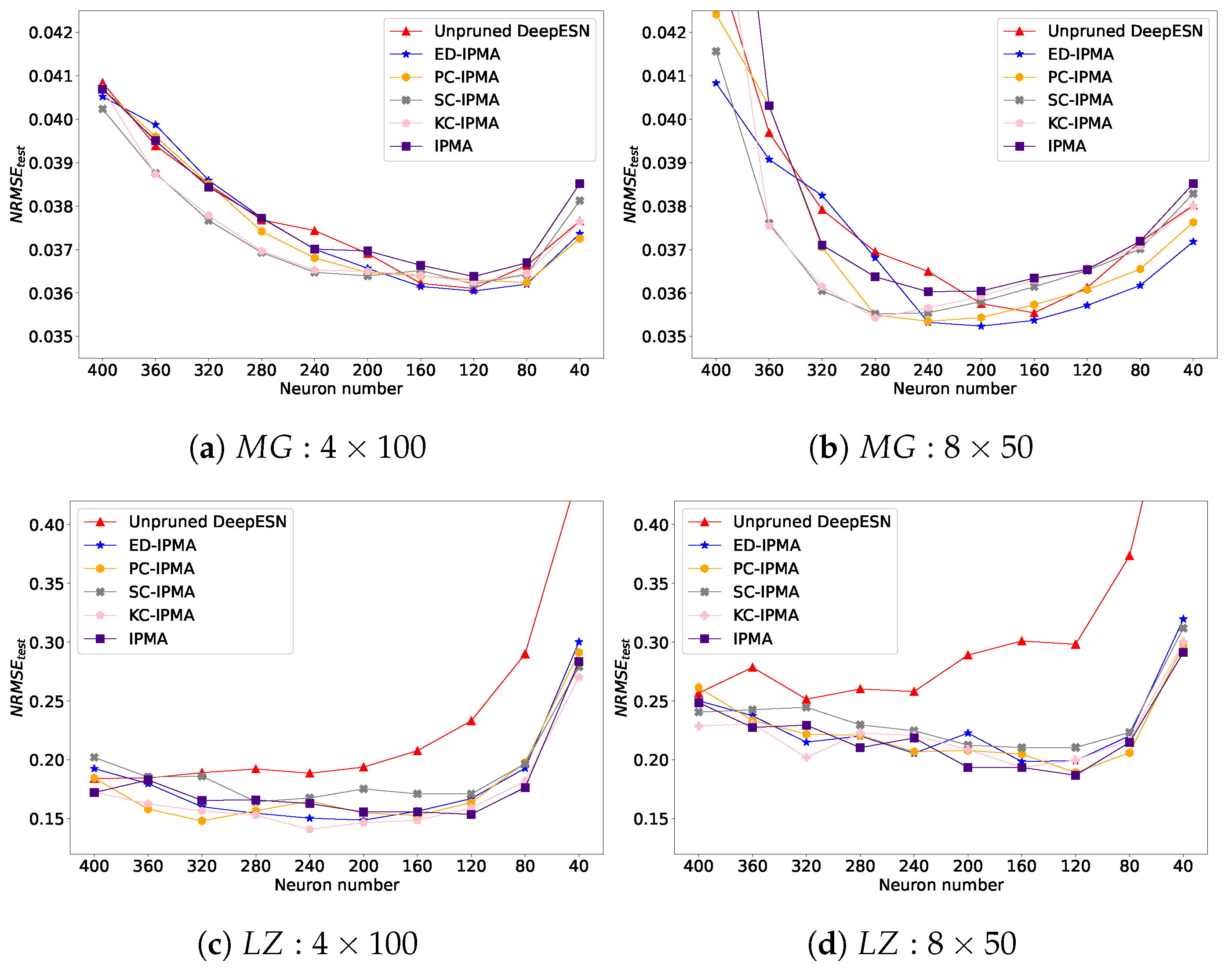
5.1. Hierarchical Structure
5.2. Reservoir Diversity and Error Performance
6. Conclusions and Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RNN | Recurrent neural network |
| ESN | Echo state network |
| LSTM | Long short-term memory |
| GRU | Gated recurrent unit |
| DNN | Deep neural network |
| DeepESN | Deep echo state network |
| SIPA | Sensitive iterative pruning algorithm |
| SCRN | Simple cycle reservoir network |
| NS-IPMA | Neuronal similarity-based iterative pruning merging algorithm |
| LI-ESN | Leaky integrator echo state network |
| ESP | Echo state property |
| RC | Reservoir computing |
| ASE | Average state entropy |
| ED | Euclidean distance |
| PC | Pearson’s correlation |
| SC | Spearman’s correlation |
| KC | Kendall’s correlation |
| ED-IPMA | NS-IPMA based on the inverse of Euclidean distance criterion |
| PC-IPMA | NS-IPMA based on the inverse of Pearson’s correlation criterion |
| SC-IPMA | NS-IPMA based on the inverse of Spearman’s correlation criterion |
| KC-IPMA | NS-IPMA based on the inverse of Kendall’s correlation criterion |
| IPMA | Iterative pruning merging algorithm |
| PSO | Particle swarm optimization |
| Mackey–Glass | |
| Lorenz z-axis | |
| DC | Direct component |
| NRMSE | Normalized root mean square error |
| RT | Real-time |
Appendix A. Hyperparameter Tuning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ||||
|---|---|---|---|---|
| Initial Size | ||||
| 0.92 | 0.92 | 0.92 | 0.92 | |
| 0.8 | 0.8 | 0.8 | 0.8 | |
| 0.373 84 | 0.253 14 | 0.096 31 | 0.064 94 | |
| 0.211 36 | 0.241 62 | 0.335 51 | 0.347 11 | |
References
- Gallicchio, C.; Micheli, A. Architectural richness in deep reservoir computing. Neural Comput. Appl. 2022, 8. [Google Scholar] [CrossRef]
- Jaeger, H.; Haas, H. Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; He, K.; Cabrera, D.; Li, C.; Bai, Y.; Long, J. Transmission Condition Monitoring of 3D Printers Based on the Echo State Network. Appl. Sci. 2019, 9, 3058. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Che, Z.P.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent Neural Networks for Multivariate Time Series with Missing Values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, X.; Ren, W. Prediction of Air Pollution Concentration Based on mRMR and Echo State Network. Appl. Sci. 2019, 9, 1811. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Wang, B.; Zhou, Y.; Sun, H. WOA-Based Echo State Network for Chaotic Time Series Prediction. J. Korean Phys. Soc. 2020, 76, 384–391. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, B.; Zhou, Y.; Gu, J.; Wu, Y. Prediction of Chaotic Time Series Based on SALR Model with Its Application on Heating Load Prediction. Arab. J. Sci. Eng. 2021, 46, 8171–8187. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, H.; Xiao, F.; Yan, X.; Sun, L. Network traffic prediction method based on echo state network with adaptive reservoir. Softw. Pract. Exp. 2021, 51, 2238–2251. [Google Scholar] [CrossRef]
- Baek, J.; Choi, Y. Deep Neural Network for Predicting Ore Production by Truck-Haulage Systems in Open-Pit Mines. Appl. Sci. 2020, 10, 1657. [Google Scholar] [CrossRef] [Green Version]
- Gallicchio, C.; Micheli, A.; Pedrelli, L. Deep reservoir computing: A critical experimental analysis. Neurocomputing 2017, 268, 87–99. [Google Scholar] [CrossRef]
- Gallicchio, C.; Micheli, A.; Silvestri, L. Local Lyapunov exponents of deep echo state networks. Neurocomputing 2018, 298, 34–45. [Google Scholar] [CrossRef]
- Gallicchio, C.; Micheli, A. Echo State Property of Deep Reservoir Computing Networks. Cogn. Comput. 2017, 9, 337–350. [Google Scholar] [CrossRef]
- Gallicchio, C.; Micheli, A. Deep Echo State Network (DeepESN): A Brief Survey. arXiv 2017, arXiv:abs/1712.04323. [Google Scholar]
- Gallicchio, C.; Micheli, A. Why Layering in Recurrent Neural Networks? In A DeepESN Survey. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Thomas, P.; Suhner, M.C. A New Multilayer Perceptron Pruning Algorithm for Classification and Regression Applications. Neural Process. Lett. 2015, 42, 437–458. [Google Scholar] [CrossRef]
- Wang, H.; Yan, X. Improved simple deterministically constructed Cycle Reservoir Network with Sensitive Iterative Pruning Algorithm. Neurocomputing 2014, 145, 353–362. [Google Scholar] [CrossRef]
- Jaeger, H.; Lukoševičius, M.; Popovici, D.; Siewert, U. Optimization and applications of echo state networks with leaky- integrator neurons. Neural Netw. 2007, 20, 335–352. [Google Scholar] [CrossRef]
- Yildiz, I.B.; Jaeger, H.; Kiebel, S.J. Re-visiting the echo state property. Neural Netw. 2012, 35, 1–9. [Google Scholar] [CrossRef]
- Gallicchio, C.; Micheli, A. Architectural and Markovian factors of echo state networks. Neural Netw. 2011, 24, 440–456. [Google Scholar] [CrossRef]
- Rodan, A.; Tino, P. Minimum complexity echo state network. IEEE Trans. Neural Netw. 2011, 22, 131–144. [Google Scholar] [CrossRef]
- Castellano, G.; Fanelli, A.; Pelillo, M. An iterative pruning algorithm for feedforward neural networks. IEEE Trans. Neural Netw. 1997, 8, 519–531. [Google Scholar] [CrossRef]
- Islam, M.M.; Sattar, M.A.; Amin, M.F.; Yao, X.; Murase, K. A New Adaptive Merging and Growing Algorithm for Designing Artificial Neural Networks. IEEE Trans. Syst. Man Cybern. Part (Cybern.) 2009, 39, 705–722. [Google Scholar] [CrossRef]
- Shahi, S.; Fenton, F.H.; Cherry, E.M. Prediction of chaotic time series using recurrent neural networks and reservoir computing techniques: A comparative study. Mach. Learn. Appl. 2022, 8, 100300. [Google Scholar] [CrossRef] [PubMed]
- Bianchi, F.M.; Maiorino, E.; Kampffmeyer, M.C.; Rizzi, A.; Jenssen, R. Other Recurrent Neural Networks Models. In Recurrent Neural Networks for Short-Term Load Forecasting: An Overview and Comparative Analysis; Springer International Publishing: Cham, Switzerland, 2017; pp. 31–39. [Google Scholar] [CrossRef]
- Mackey, M.C.; Glass, L. Oscillation and chaos in physiological control systems. Science 1977, 197, 287–289. [Google Scholar] [CrossRef]
- Maat, J.R.; Malali, A.; Protopapas, P. TimeSynth: A Multipurpose Library for Synthetic Time Series in Python. 2017. Available online: https://github.com/TimeSynth/TimeSynth (accessed on 22 February 2023).
- Chao, K.H.; Chang, L.Y.; Xu, F.Q. Smart Fault-Tolerant Control System Based on Chaos Theory and Extension Theory for Locating Faults in a Three-Level T-Type Inverter. Appl. Sci. 2019, 9, 3071. [Google Scholar] [CrossRef] [Green Version]
- Yan, S.R.; Guo, W.; Mohammadzadeh, A.; Rathinasamy, S. Optimal deep learning control for modernized microgrids. Appl. Intell. 2022. [Google Scholar] [CrossRef]
- Saini, S.S.; Soni, D.; Malhi, S.S.; Tiwari, V.; Goyal, A. Automatic irrigation control system using Internet of Things(IoT). J. Discret. Math. Sci. Cryptogr. 2022, 25, 879–889. [Google Scholar] [CrossRef]
- Ozkan, M.B.; Karagoz, P. Data Mining-Based Upscaling Approach for Regional Wind Power Forecasting: Regional Statistical Hybrid Wind Power Forecast Technique (RegionalSHWIP). IEEE Access 2019, 7, 171790–171800. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, H.; Chen, P.; Xia, Q.; Gan, Z.; Shan, W. An efficient isomorphic CNN-based prediction and decision framework for financial time series. Intell. Data Anal. 2022, 26, 893–909. [Google Scholar] [CrossRef]
- Zhang, B.; Sun, X.; Liu, S.; Deng, X. Tracking control of multiple unmanned aerial vehicles incorporating disturbance observer and model predictive approach. Trans. Inst. Meas. Control 2020, 42, 951–964. [Google Scholar] [CrossRef]
- Xing, X.; Lin, J.; Wan, C.; Song, Y. Model Predictive Control of LPC-Looped Active Distribution Network With High Penetration of Distributed Generation. IEEE Trans. Sustain. Energy 2017, 8, 1051–1063. [Google Scholar] [CrossRef]
- Benrabah, M.; Kara, K.; AitSahed, O.; Hadjili, M.L. Constrained Nonlinear Predictive Control Using Neural Networks and Teaching-Learning-Based Optimization. J. Control. Autom. Electr. Syst. 2021, 32, 1228–1243. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, H.; Che, Z.; Wang, Y.; Zeng, C. Extended State Observer-Based Predictive Speed Control for Permanent Magnet Linear Synchronous Motor. Processes 2019, 7, 618. [Google Scholar] [CrossRef] [Green Version]











| Group | Unpruned DeepESN | Pruned DeepESN | |||||
|---|---|---|---|---|---|---|---|
| Method | - | ED-IPMA | PC-IPMA | SC-IPMA | KC-IPMA | IPMA | |
| (Mean) | 0.036 105 | 0.036 046 | 0.036 240 | 0.036 206 | 0.036 243 | 0.036 380 | |
| (Std.) | 0.000 483 | 0.000 388 | 0.000 221 | 0.000 281 | 0.000 144 | 0.000 291 | |
| Neuron number | 120 | 120 | 80 | 120 | 120 | 120 | |
| (Mean) | 0.035 544 | 0.035 238 | 0.035 350 | 0.035 516 | 0.035 427 | 0.036 030 | |
| (Std.) | 0.000 699 | 0.000 346 | 0.000 516 | 0.000 533 | 0.000737 | 0.000 338 | |
| Neuron number | 160 | 200 | 240 | 280 | 280 | 240 | |
| (Mean) | 0.184 285 | 0.148 812 | 0.152 775 | 0.164 455 | 0.140 930 | 0.155 667 | |
| (Std.) | 0.043 201 | 0.026 072 | 0.024 417 | 0.022 953 | 0.031 862 | 0.027 816 | |
| Neuron number | 400 | 200 | 160 | 280 | 240 | 200 | |
| (Mean) | 0.251 535 | 0.198 581 | 0.189 230 | 0.210 376 | 0.193 678 | 0.186 933 | |
| (Std.) | 0.044 484 | 0.027 631 | 0.024 995 | 0.033 404 | 0.029 164 | 0.024 092 | |
| Neuron number | 320 | 160 | 120 | 160 | 160 | 120 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Q.; Zhang, H.; Mao, Y. Improving Deep Echo State Network with Neuronal Similarity-Based Iterative Pruning Merging Algorithm. Appl. Sci. 2023, 13, 2918. https://doi.org/10.3390/app13052918
Shen Q, Zhang H, Mao Y. Improving Deep Echo State Network with Neuronal Similarity-Based Iterative Pruning Merging Algorithm. Applied Sciences. 2023; 13(5):2918. https://doi.org/10.3390/app13052918
Chicago/Turabian StyleShen, Qingyu, Hanwen Zhang, and Yao Mao. 2023. "Improving Deep Echo State Network with Neuronal Similarity-Based Iterative Pruning Merging Algorithm" Applied Sciences 13, no. 5: 2918. https://doi.org/10.3390/app13052918