
GhostNeXt: Rethinking Module Configurations for Efficient Model Design

Abstract
:1. Introduction
2. Related Work
3. The Proposed Method
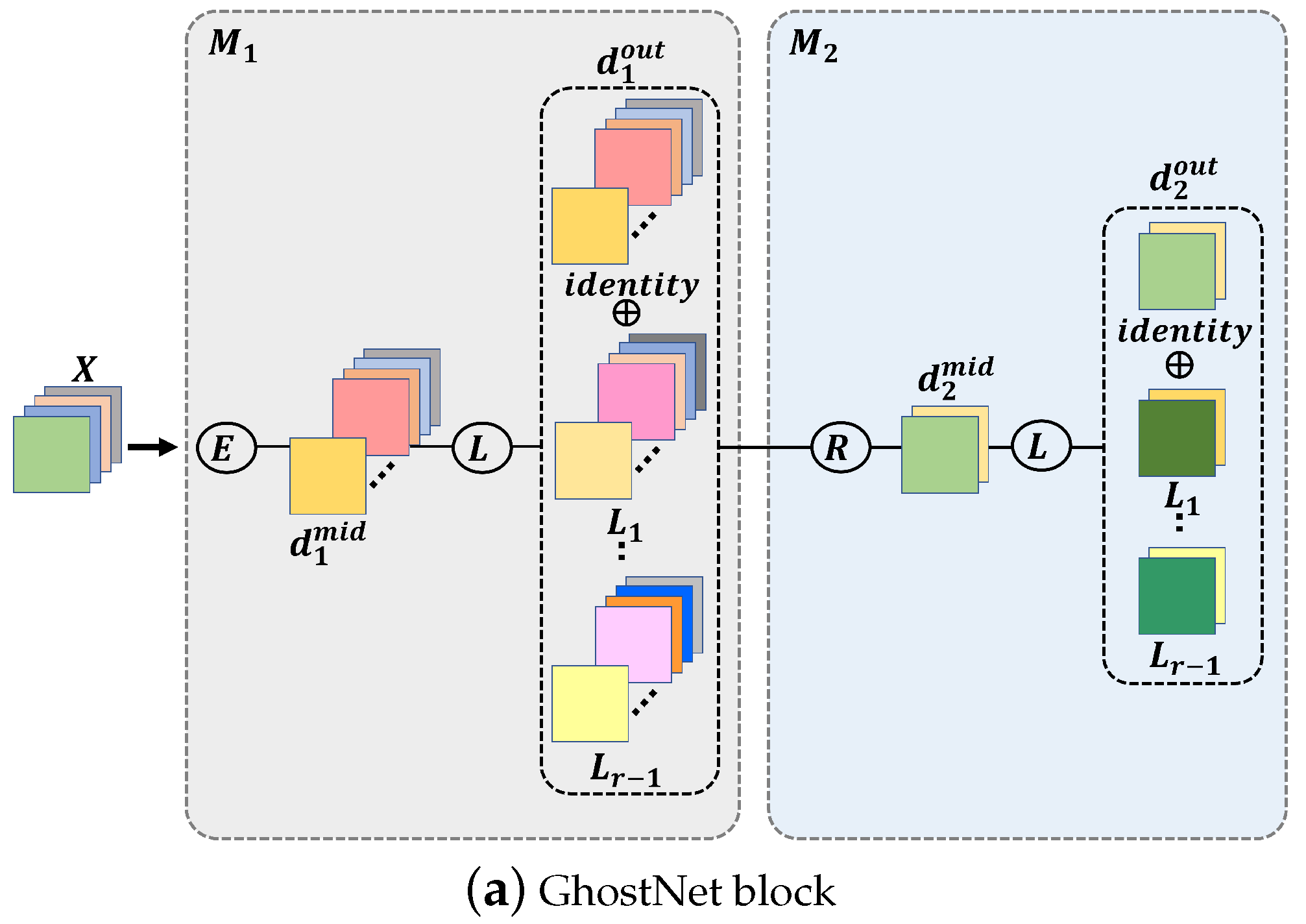
3.1. GhostNet
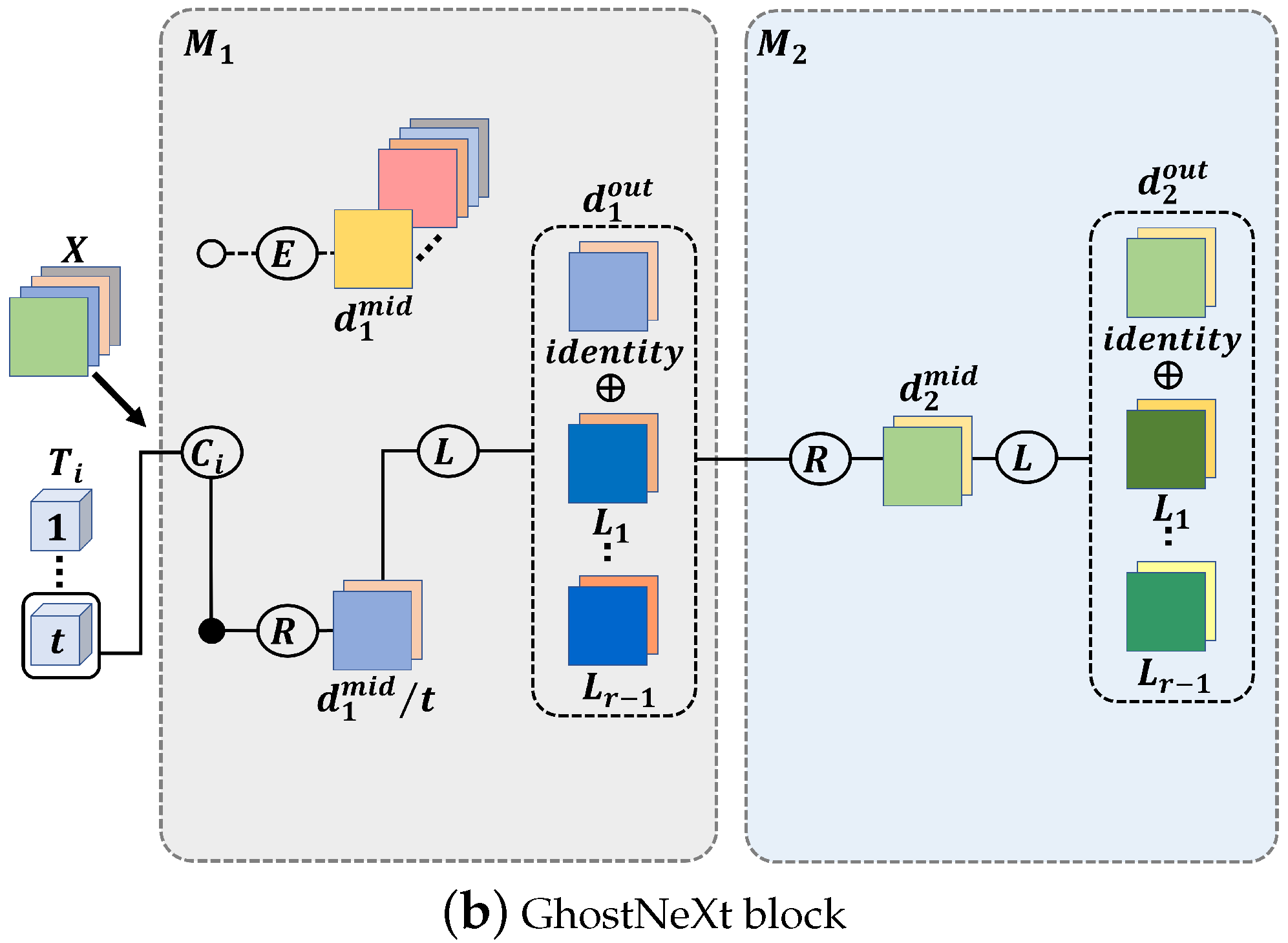
3.2. The Proposed Method: GhostNeXt
4. Experiments
4.1. Setup
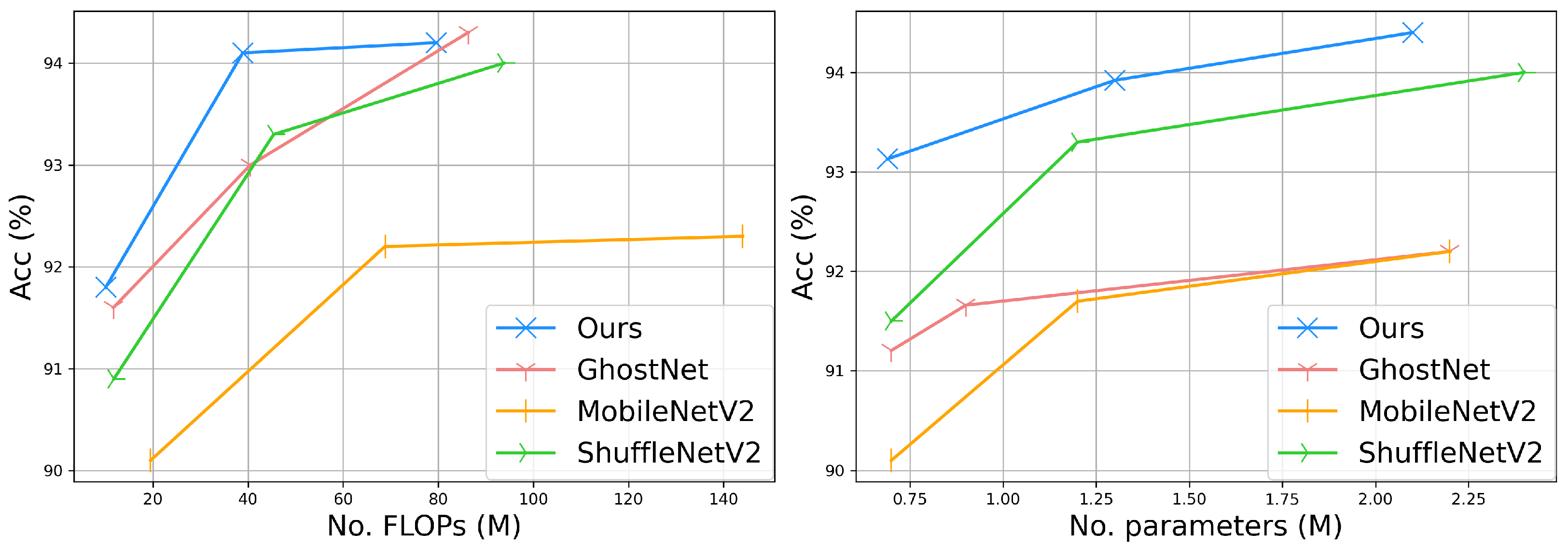
4.2. Small-Scale Datasets
4.3. Large-Scale Datasets
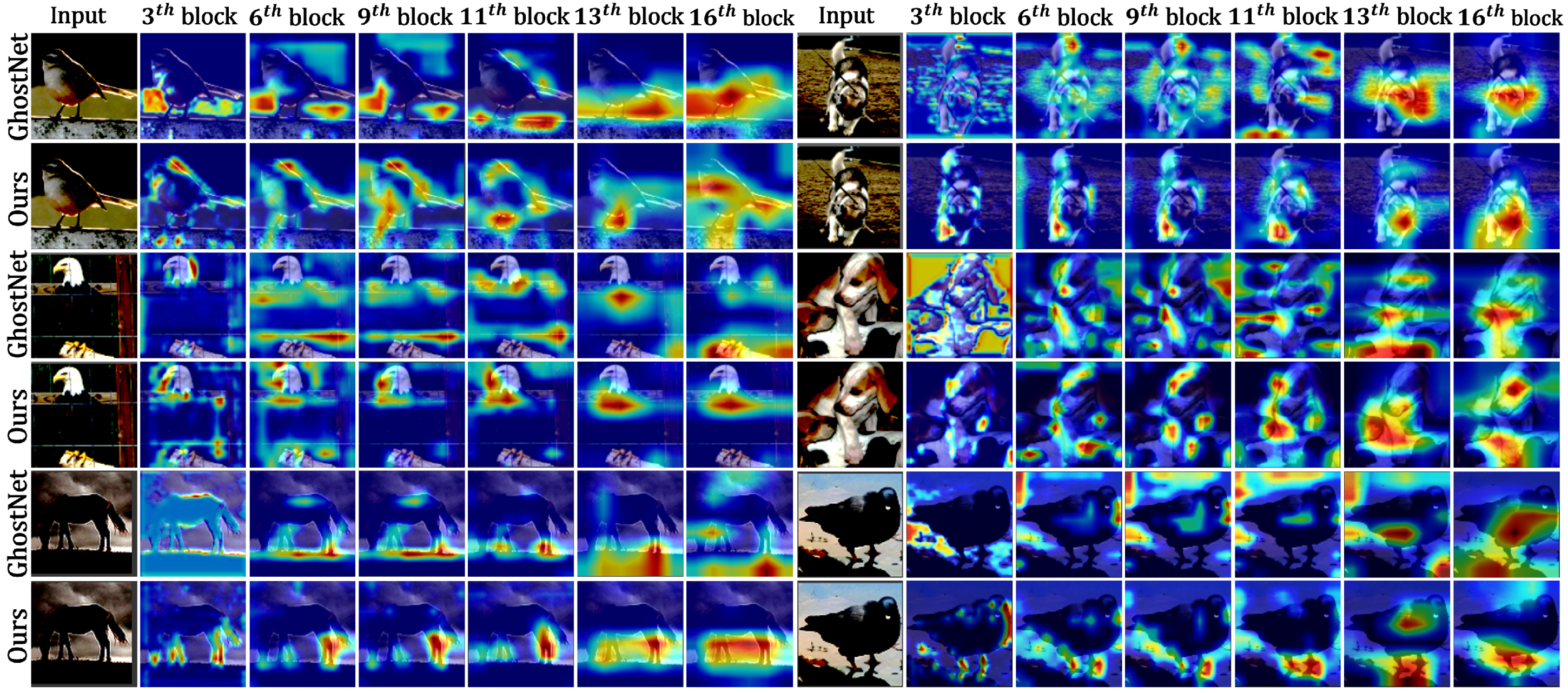
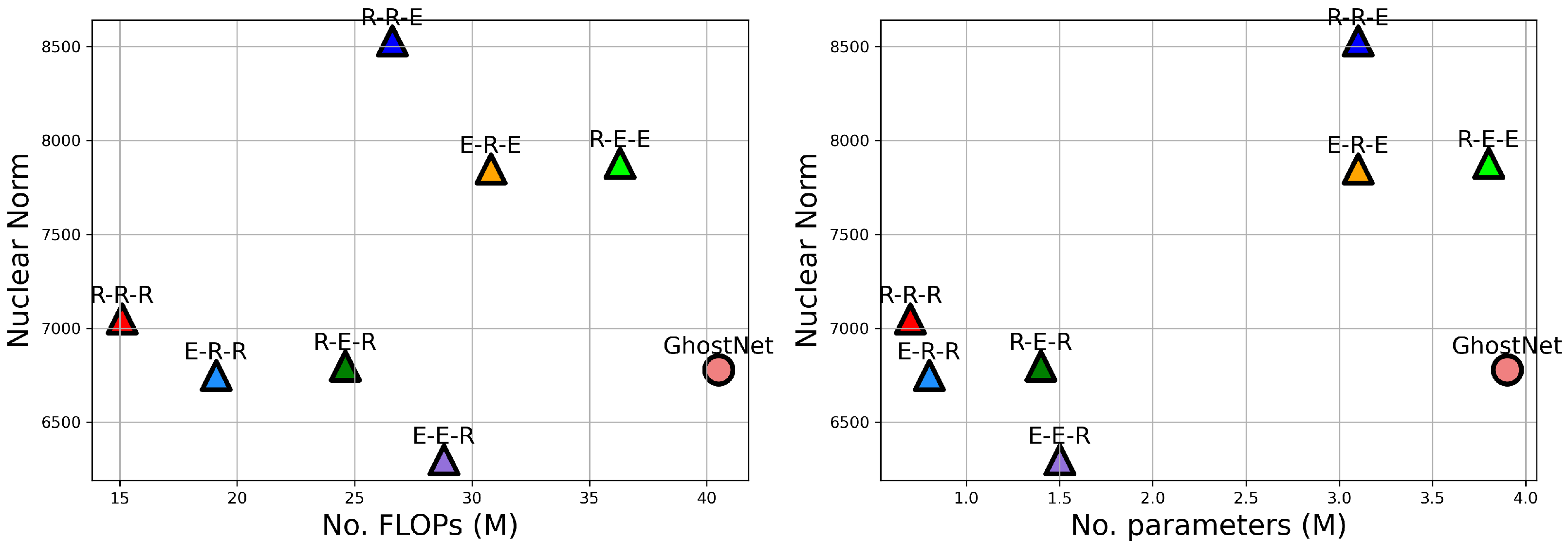
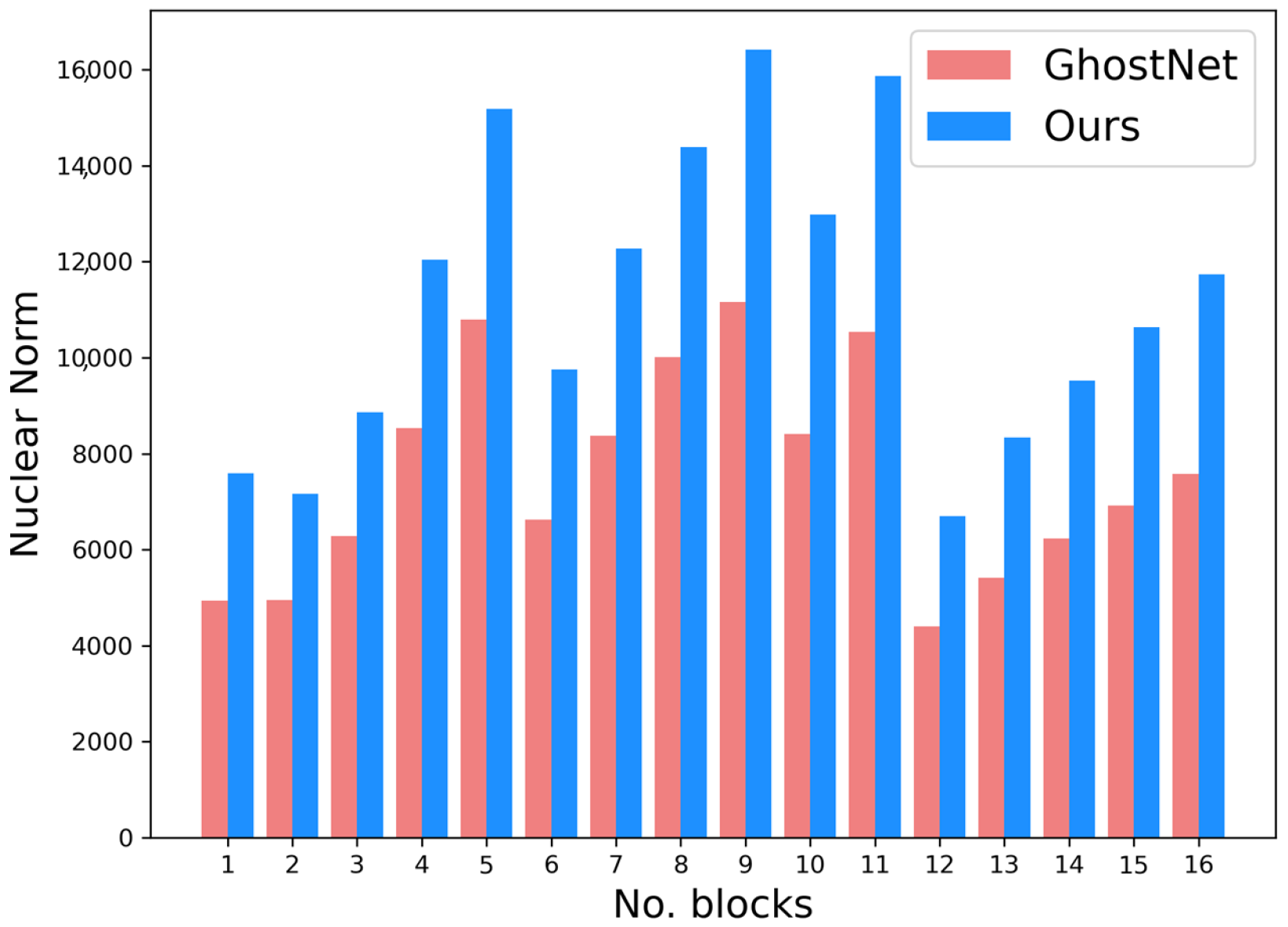
4.4. Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10428–10436. [Google Scholar]
- Han, D.; Yun, S.; Heo, B.; Yoo, Y. Rethinking Channel Dimensions for Efficient Model Design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 732–741. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-Ucsd Birds-200-2011 Dataset. 2011. Available online: https://www.kaggle.com/datasets/wenewone/cub2002011 (accessed on 20 January 2023).
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 554–561. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar]
- Saleh, B.; Elgammal, A. Large-scale classification of fine-art paintings: Learning the right metric on the right feature. arXiv 2015, arXiv:1505.00855. [Google Scholar]
- Eitz, M.; Hays, J.; Alexa, M. How do humans sketch objects? ACM Trans. Graph. (TOG) 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.kaggle.com/competitions/cifar-10/data (accessed on 20 January 2023).
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Yang, Z.; Wang, Y.; Chen, X.; Shi, B.; Xu, C.; Xu, C.; Tian, Q.; Xu, C. Cars: Continuous evolution for efficient neural architecture search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1829–1838. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10734–10742. [Google Scholar]
- Wan, A.; Dai, X.; Zhang, P.; He, Z.; Tian, Y.; Xie, S.; Wu, B.; Yu, M.; Xu, T.; Chen, K.; et al. Fbnetv2: Differentiable neural architecture search for spatial and channel dimensions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12965–12974. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Pan, J.; Bulat, A.; Tan, F.; Zhu, X.; Dudziak, L.; Li, H.; Tzimiropoulos, G.; Martinez, B. Edgevits: Competing light-weight cnns on mobile devices with vision transformers. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XI. Springer: Switzerland, 2022; pp. 294–311. [Google Scholar]
- Radosavovic, I.; Johnson, J.; Xie, S.; Lo, W.Y.; Dollár, P. On network design spaces for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1882–1890. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. The Annals of Mathematical Statistics. 1951, pp. 400–407. Available online: https://projecteuclid.org/journals/annals-of-mathematical-statistics/volume-22/issue-3/A-Stochastic-Approximation-Method/10.1214/aoms/1177729586.full (accessed on 10 December 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Parameters (M) | FLOPs (M) |
|---|---|---|
| Dataset | CIFAR-10 [17] | CIFAR-100 [17] | STL-10 [18] | CUBS [12] | Stanford Cars [13] | Flowers [14] | WikiArt [15] | Sketch [16] |
|---|---|---|---|---|---|---|---|---|
| # Train | 50,000 | 50,000 | 5000 | 5994 | 8144 | 2040 | 42,129 | 16,000 |
| # Test | 10,000 | 10,000 | 8000 | 5794 | 8041 | 6149 | 10,628 | 40,000 |
| # Class | 10 | 100 | 10 | 200 | 196 | 102 | 195 | 250 |
| Image Size | 32 × 32 | 32 × 32 | 96 × 96 | 224 × 224 | 224 × 224 | 224 × 224 | 224 × 224 | 224 × 224 |
| Model | CIFAR-100 | STL-10 | CIFAR-10 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ACC (%) | Params (M) | FLOPs (M) | ACC (%) | Params (M) | FLOPs (M) | ACC (%) | Params (M) | FLOPs (M) | |
| VGG-16 | 74.4 | 14.8 | 314.0 | 75.4 | 14.7 | - | 93.6 | 14.7 | 313.0 |
| ResNet-56 | 72.5 | 0.8 | 127.3 | 77.7 | 0.8 | 290.0 | 93.0 | 0.8 | 125.0 |
| ResNeXt-29 (2 × 64d) | 79.8 | 7.6 | 263.6 | 80.6 | 7.5 | 606.6 | 96.0 | 7.5 | 263.5 |
| ResNeXt-29 (4 × 64d) | 81.0 | 14.7 | 511.4 | 81.5 | 14.6 | 1160.0 | 96.2 | 14.6 | 511.3 |
| MobileNetV2 (0.5×) | 68.1 | 0.8 | 19.6 | 71.3 | 0.7 | 49.6 | 90.1 | 0.7 | 19.5 |
| ShuffleNetV2 (0.5×) | 69.2 | 0.4 | 11.9 | 71.4 | 0.3 | 26.6 | 90.9 | 0.3 | 11.8 |
| GhostNet (0.5×) | 71.6 | 1.4 | 11.8 | 70.1 | 1.3 | 25.2 | 91.6 | 1.3 | 11.7 |
| Ours (0.7×) | 71.5 | 0.5 | 10.3 | 71.2 | 0.4 | 22.5 | 91.8 | 0.4 | 10.1 |
| MobileNetV2 (1.0×) | 72.9 | 2.3 | 68.9 | 73.2 | 2.2 | 161.0 | 92.2 | 2.2 | 68.8 |
| ShuffleNetV2 (1.0×) | 73.7 | 1.3 | 45.5 | 74.7 | 1.2 | 102.3 | 93.3 | 1.2 | 45.4 |
| GhostNet (1.0×) | 75.3 | 4.0 | 40.6 | 71.6 | 3.9 | 87.7 | 93.0 | 3.9 | 40.5 |
| Ours(1.5×) | 75.4 | 1.4 | 39.1 | 75.7 | 1.3 | 87.0 | 94.1 | 1.3 | 38.9 |
| MobileNetV2 (1.5×) | 72.8 | 5.1 | 144.7 | 74.4 | 4.9 | 355.0 | 92.3 | 4.9 | 144.0 |
| ShuffleNetV2 (1.5×) | 75.7 | 2.5 | 93.9 | 75.5 | 2.4 | 211.0 | 94.0 | 2.4 | 93.8 |
| GhostNet (1.5×) | 77.2 | 7.9 | 86.4 | 74.4 | 7.7 | 187.7 | 94.3 | 7.7 | 86.3 |
| Ours (2.2×) | 76.2 | 2.6 | 79.8 | 77.1 | 2.5 | 178.1 | 94.2 | 2.5 | 79.6 |
| Model | ACC (%) | Params (M) | FLOPs (M) |
|---|---|---|---|
| ResNet-56 [4] | 93.0 | 0.8 | 125.0 |
| Ghost-ResNet-56 | 92.6 | 0.5 | 53.5 |
| Ours-ResNet-56 | 92.5 | 0.2 | 38.0 |
| Dataset | MobileNetV2 (0.6×) | ShuffleNetV2 (1.0×) | GhostNet (1.0×) | Ours (1.3×) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC (%) | Params (M) | FLOPs (M) | ACC (%) | Params (M) | FLOPs (M) | ACC (%) | Params (M) | FLOPs (M) | ACC (%) | Params (M) | FLOPs (M) | |
| CUBS [12] | 53.6 | 1.2 | 164.0 | 53.1 | 1.5 | 149.0 | 55.9 | 4.1 | 150.0 | 58.2 | 1.2 | 136.0 |
| Stanford Cars [13] | 76.0 | 1.2 | 164.0 | 75.7 | 1.5 | 149.0 | 79.0 | 4.1 | 150.0 | 80.3 | 1.2 | 136.0 |
| Flowers [14] | 58.2 | 1.1 | 164.0 | 60.5 | 1.4 | 149.0 | 64.8 | 4.0 | 150.0 | 66.3 | 1.1 | 136.0 |
| WikiArt [15] | 64.2 | 1.2 | 164.0 | 59.4 | 1.5 | 149.0 | 62.0 | 4.1 | 150.0 | 65.0 | 1.2 | 136.0 |
| Sketch [16] | 72.8 | 1.3 | 164.0 | 71.7 | 1.5 | 149.0 | 71.6 | 4.2 | 150.0 | 72.3 | 1.3 | 136.0 |
| Model | ACC (%) | Params (M) | FLOPs (M) |
|---|---|---|---|
| 93.0 | 3.9 | 40.5 | |
| (GhostNet) | |||
| 93.4 | 1.5 | 28.8 | |
| 93.1 | 0.8 | 19.1 | |
| 93.2 | 3.1 | 30.8 | |
| 92.5 | 0.7 | 15.1 | |
| 93.0 | 3.1 | 26.6 | |
| 92.9 | 1.4 | 24.6 | |
| 93.3 | 3.8 | 36.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, K.; Kim, G.-h.; Kim, E. GhostNeXt: Rethinking Module Configurations for Efficient Model Design. Appl. Sci. 2023, 13, 3301. https://doi.org/10.3390/app13053301
Hong K, Kim G-h, Kim E. GhostNeXt: Rethinking Module Configurations for Efficient Model Design. Applied Sciences. 2023; 13(5):3301. https://doi.org/10.3390/app13053301
Chicago/Turabian StyleHong, Kiseong, Gyeong-hyeon Kim, and Eunwoo Kim. 2023. "GhostNeXt: Rethinking Module Configurations for Efficient Model Design" Applied Sciences 13, no. 5: 3301. https://doi.org/10.3390/app13053301