
Crop Disease Diagnosis with Deep Learning-Based Image Captioning and Object Detection





Abstract
:1. Introduction
2. Related Work
2.1. History of Deep Learning-Based Image Captioning and Object Detection
2.2. Model Application Case
3. Materials and Methods
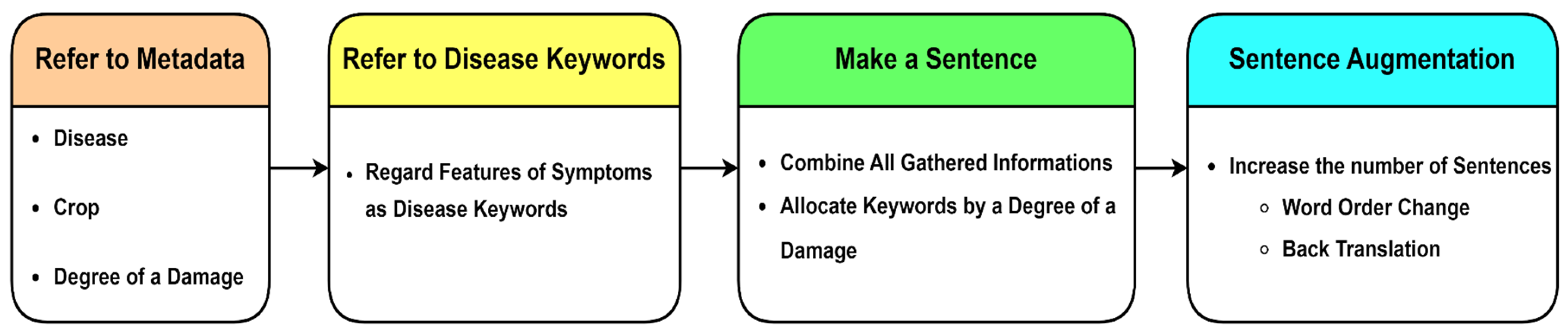
3.1. Data Collection
3.2. Data Preprocessing
3.2.1. Data Preprocessing for Image Captioning
- Early Stage: “round spots”
- Middle Stage: “round spots” + “dark or yellowish-brown spores”
- Late Stage: “round spots” + “dark or yellowish brown spores” + ”dry twisting”
- Early Stage: A round spot appears on the pepper, which is suspected to be a red pepper anthracnose.
- Middle Stage: The pepper has yellowish brown spores and round spots, so it is suspected to be a pepper anthracnose.
- Late Stage: It is suspected that it is a pepper anthracnose, as it appears to have circular spots, yellow-brown spores, and dry twist on the pepper.
3.2.2. Preprocessing for Object Detection Model
3.3. Structure of the Crop Disease Diagnosis Solution
3.3.1. Image Captioning Model
- (a)
- InceptionV3
- (b)
- Transformer
- (c)
- InceptionV3-Transformer
3.3.2. Object Detection Model
- (a)
- YOLOv5
3.3.3. Flow of Crop Disease Diagnosis Solution
4. Result
4.1. Quantitative Result
4.1.1. Quantitative Result of Image Captioning Model
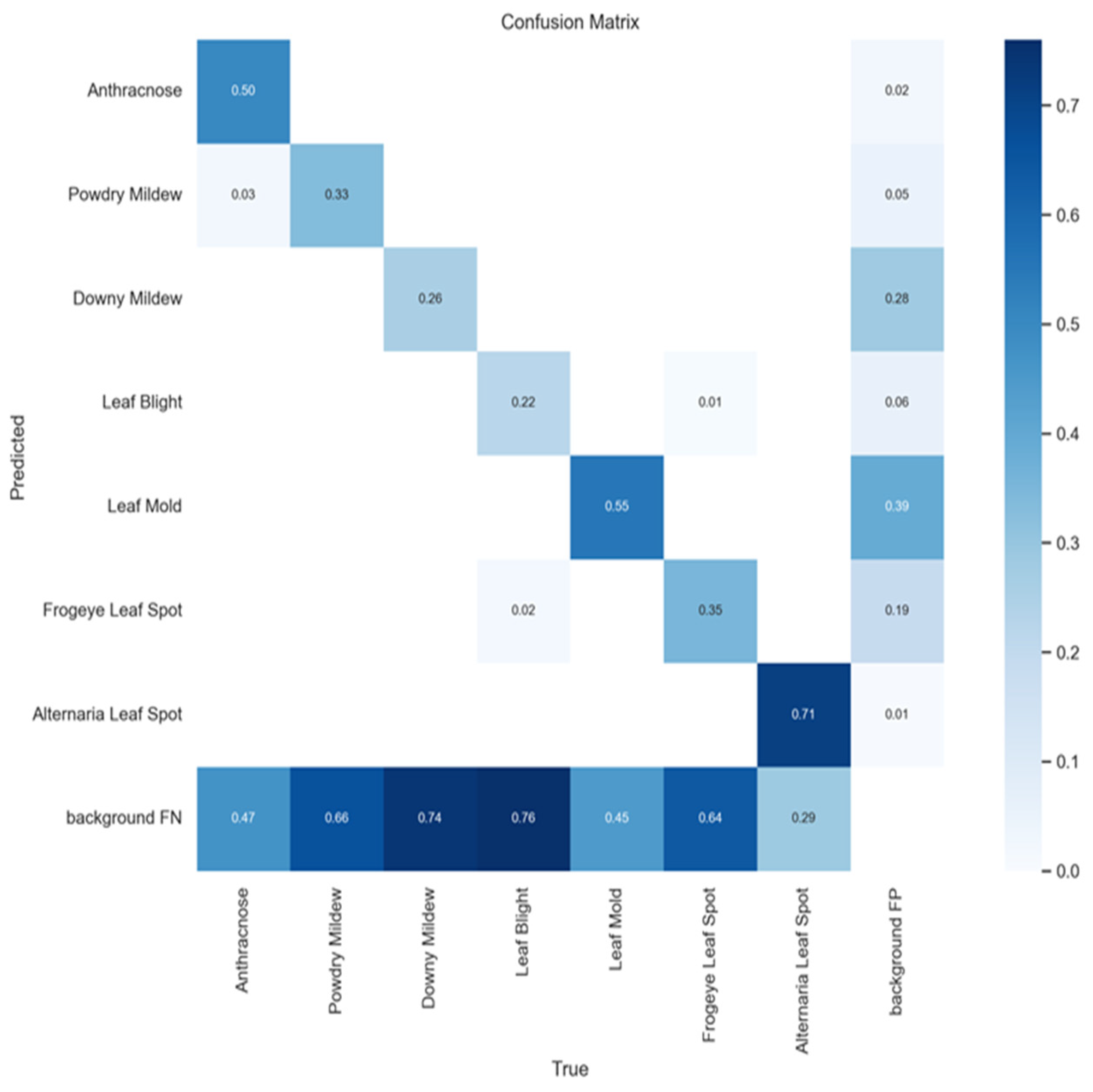
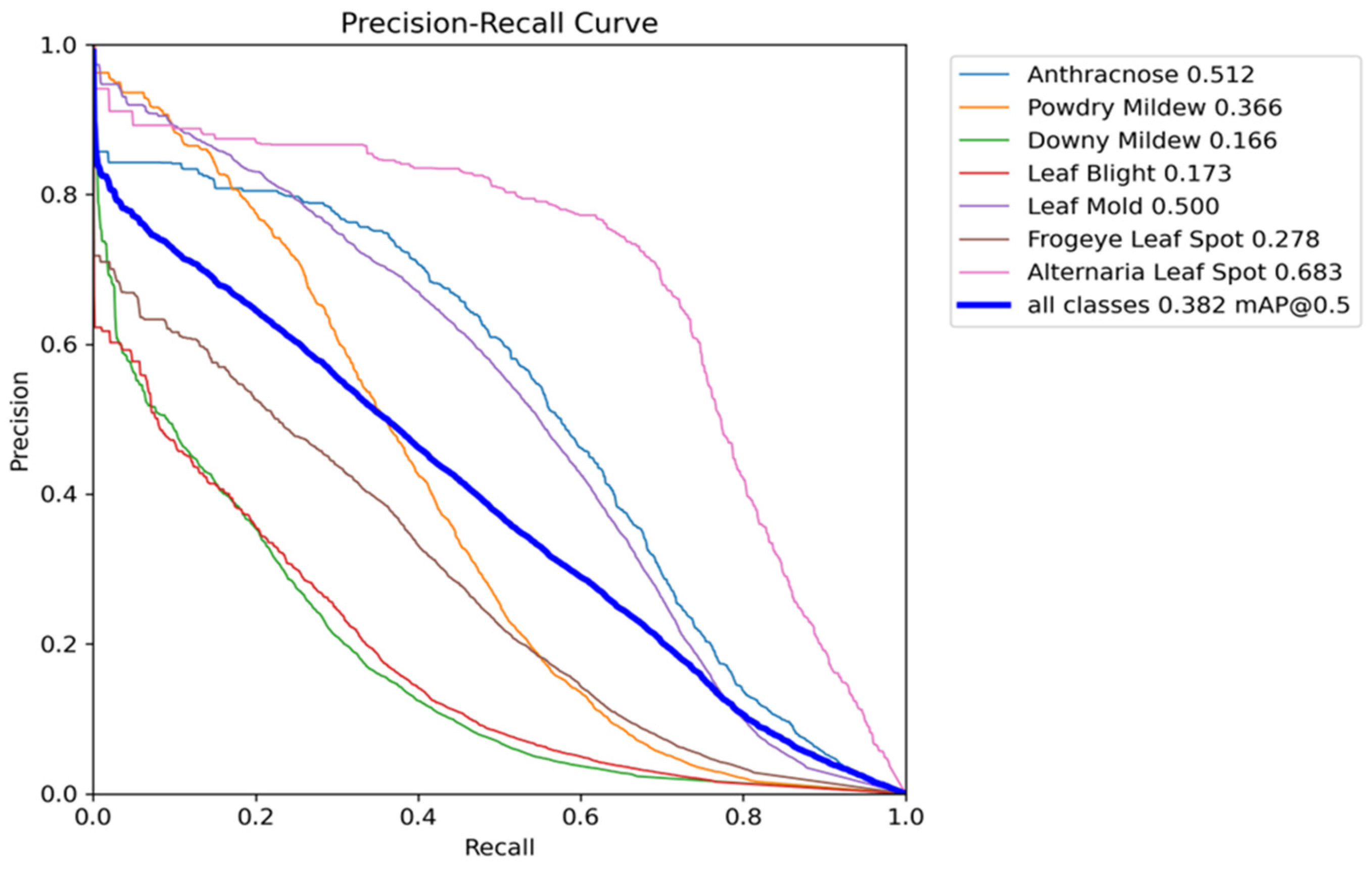
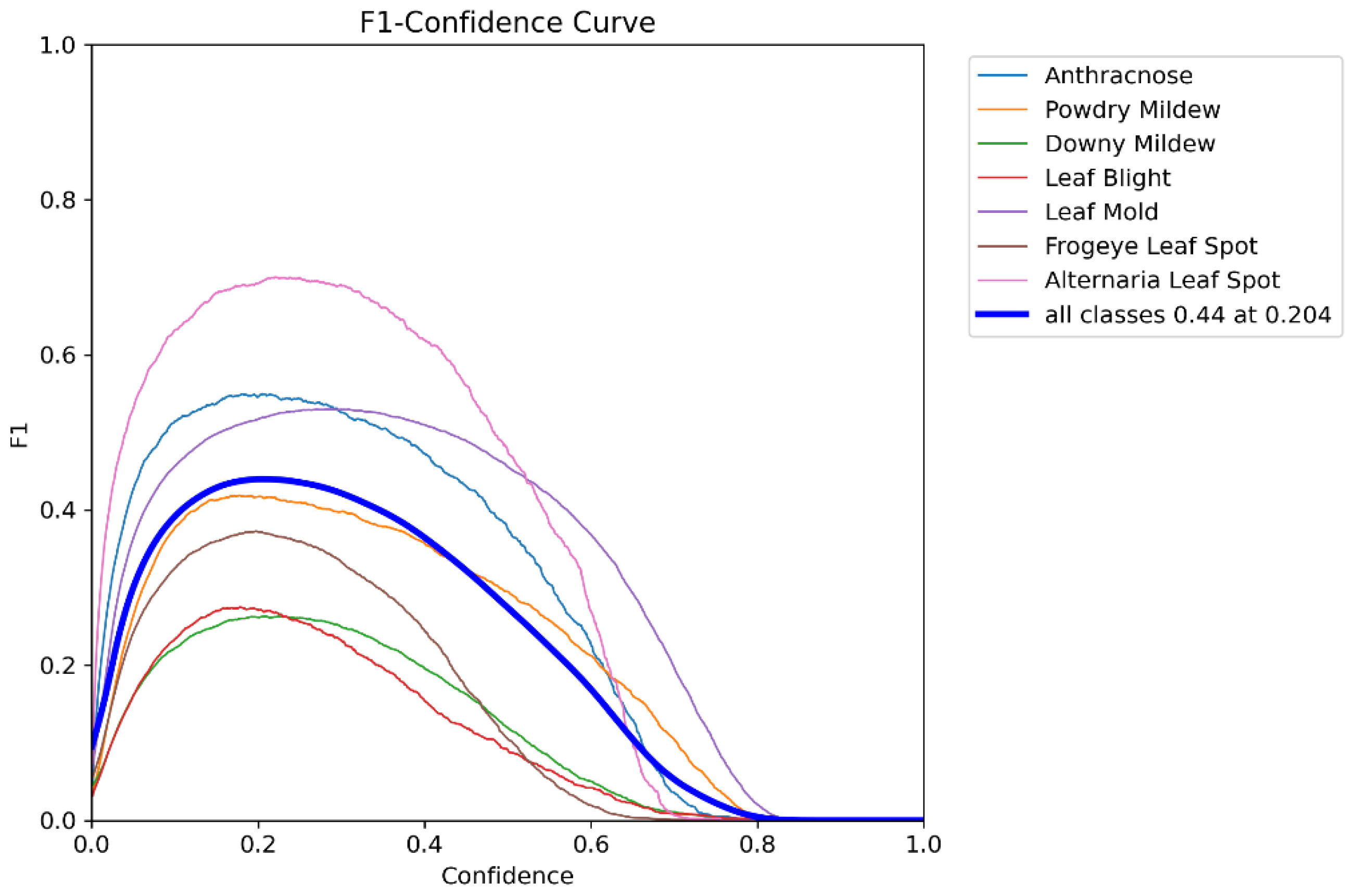
4.1.2. Quantitative Result of Object Detection
4.2. Qualitative Result
4.2.1. Qualitative Result of Image Captioning Model
4.2.2. The Qualitative Result of Object Detection Model
4.3. Result Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khamparia, A.; Saini, G.; Gupta, D.; Khanna, A.; Tiwari, S.; Albuquerque, V.H.C. Seasonal crops disease prediction and classification using deep convolutional encoder network. Circuits Syst. Signal Process. 2020, 39, 818–836. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhaudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2048–2057. [Google Scholar]
- Li, G.; Zhu, L.; Liu, P.; Yang, Y. Entangled Transformer for Image Captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8928–8937. [Google Scholar]
- Zhang, X.; Bai, L.; Zhang, Z.; Li, Y. Multi-Scale Keypoints Feature Fusion Network for 3D Object Detection from Point Clouds. Hum.-Cent. Comput. Inf. Sci. 2022, 12, 12–29. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Park, D.; Cha, J.W. Image Caption Generation using Object Attention Mechanism; Korean Institute of Information Scientists and Engineers: Seoul, Republic of Korea, 2019; pp. 82–87. [Google Scholar]
- Jo, M.; Han, S.; Jeong, C. TOD: Trash Object Detection Dataset. J. Inf. Process. Syst. 2022, 18, 524–534. [Google Scholar]
- Kristiani, E.; Tsan, Y.T.; Liu, P.Y.; Yen, N.Y.; Yang, C.T. Binary and Multi-Class Assessment of Face Mask Classification on Edge AI Using CNN and Transfer Learning. Hum.-Cent. Comput. Inf. Sci. 2022, 12, 53. [Google Scholar]
- Mohanty, S.P.; Hughes, D.P.; Salathe, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fuentes, A.; Yoon, S.; Kim, S.C.; Park, D.S. A Robust Deep-Learning-Based Detector for Real-Time Tomato Plant Diseases and Pests Recognition. Sensors 2017, 17, 2022. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Zhou, C.; Xing, J. Improved Deep Residual Network for Apple Leaf Disease Identification. J. Inf. Process. Syst. 2021, 17, 1115–1126. [Google Scholar]
- Nanehkaran, Y.A.; Zhang, D.; Chen, J.; Tian, Y.; Al-Nabhan, N. Recognition of plant leaf diseases based on computer vision. J. Ambient. Intell. Humaniz. Comput. 2020, 1–18. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, D.; Nanehkaran, Y.A.; Li, D. Detection of rice plant diseases based on deep transfer learning. J. Sci. Food Agric. 2020, 100, 3246–3256. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Chen, J.; Zhang, D.; Sun, Y.; Nanehkaran, Y.A. Using deep transfer learning for image-based plant disease identification. Comput. Electron. Agric. 2020, 173, 105393. [Google Scholar] [CrossRef]
- Chen, J.; Zeb, A.; Nanehkaran, Y.A.; Zhang, D. Stacking ensemble model of deep learning for plant disease recognition. J. Ambient. Intell. Humaniz. Comput. 2022, 1–14. [Google Scholar] [CrossRef]
- Kim, Y.M.; An, H.U.; Jeon, H.G.; Kim, J.P.; Jang, G.J.; Hwang, H.C. A Study of Tram-Pedestrian Collision Prediction Method Using YOLOv5 and Motion Vector. KIPS Trans. Softw. Data Eng. 2021, 10, 561–568. [Google Scholar]
- AI-Hub Home Page. Available online: https://www.aihub.or.kr/ (accessed on 19 January 2023).
- AI-Hub; Facility Crop Disease Diagnostic Image Dataset Home Page. Available online: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=147 (accessed on 19 January 2023).
- AI-Hub; Outdoor Crop Disease Diagnostic Image Dataset Home Page. Available online: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=153 (accessed on 19 January 2023).
- National Crop Pest Management System Home Page. Available online: https://ncpms.rda.go.kr/npms/Main.np (accessed on 19 January 2023).
- Cho, S.W. The acquisition of word order in Korean. Calg. Work. Pap. Linguist. 1982, 7, 53–116. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 86–96. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Google Cloud Home Page. Available online: https://cloud.google.com/translate/automl/docs/evaluate (accessed on 19 January 2023).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Type | Code | Example of Code |
|---|---|---|---|
| Disease | Integer | 0, 1, …, 20 | 14 |
| Crop | Integer | 0, 1, …, 10 | 9 |
| Area | Integer | 0, 1, …, 7 | 3 |
| Grow | Integer | 11, 12, 13 | 12 |
| Risk | Integer | 0, 1, 2, 3 | 2 |
| Bounding Box Points | Dictionary | {xtl, ytl, xbr, ybr} | {“xtl”: 100, “ytl”: 200, “xbr”: 1100, “ybr”: 1200} |
| BLEU_1 | BLEU_ 2 | BLEU_3 | BLEU_4 | BLEU_AVG |
|---|---|---|---|---|
| 78.64 | 69.77 | 61.08 | 50.58 | 64.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.I.; Lee, J.H.; Jang, S.H.; Oh, S.J.; Doo, I.C. Crop Disease Diagnosis with Deep Learning-Based Image Captioning and Object Detection. Appl. Sci. 2023, 13, 3148. https://doi.org/10.3390/app13053148
Lee DI, Lee JH, Jang SH, Oh SJ, Doo IC. Crop Disease Diagnosis with Deep Learning-Based Image Captioning and Object Detection. Applied Sciences. 2023; 13(5):3148. https://doi.org/10.3390/app13053148
Chicago/Turabian StyleLee, Dong In, Ji Hwan Lee, Seung Ho Jang, Se Jong Oh, and Ill Chul Doo. 2023. "Crop Disease Diagnosis with Deep Learning-Based Image Captioning and Object Detection" Applied Sciences 13, no. 5: 3148. https://doi.org/10.3390/app13053148