
Machine Learning Based Representative Spatio-Temporal Event Documents Classification

Abstract
:1. Introduction
- We defined the RSTEDoc in terms of the most important event among multiple events included in a document. Detailed definitions are given in Section 3.1.
- We built 10,000 gold-standard training datasets for classifying RSTEDocs. Since there are no publicly open training data for classifying RSTEDocs yet, we hand-built training data based on large-volume news articles.
- We developed a BiLSTM-based classifier for RSTEDocs and compared to traditional machine learning, using deep learning-based models (CNN and LSTM) as a baseline.
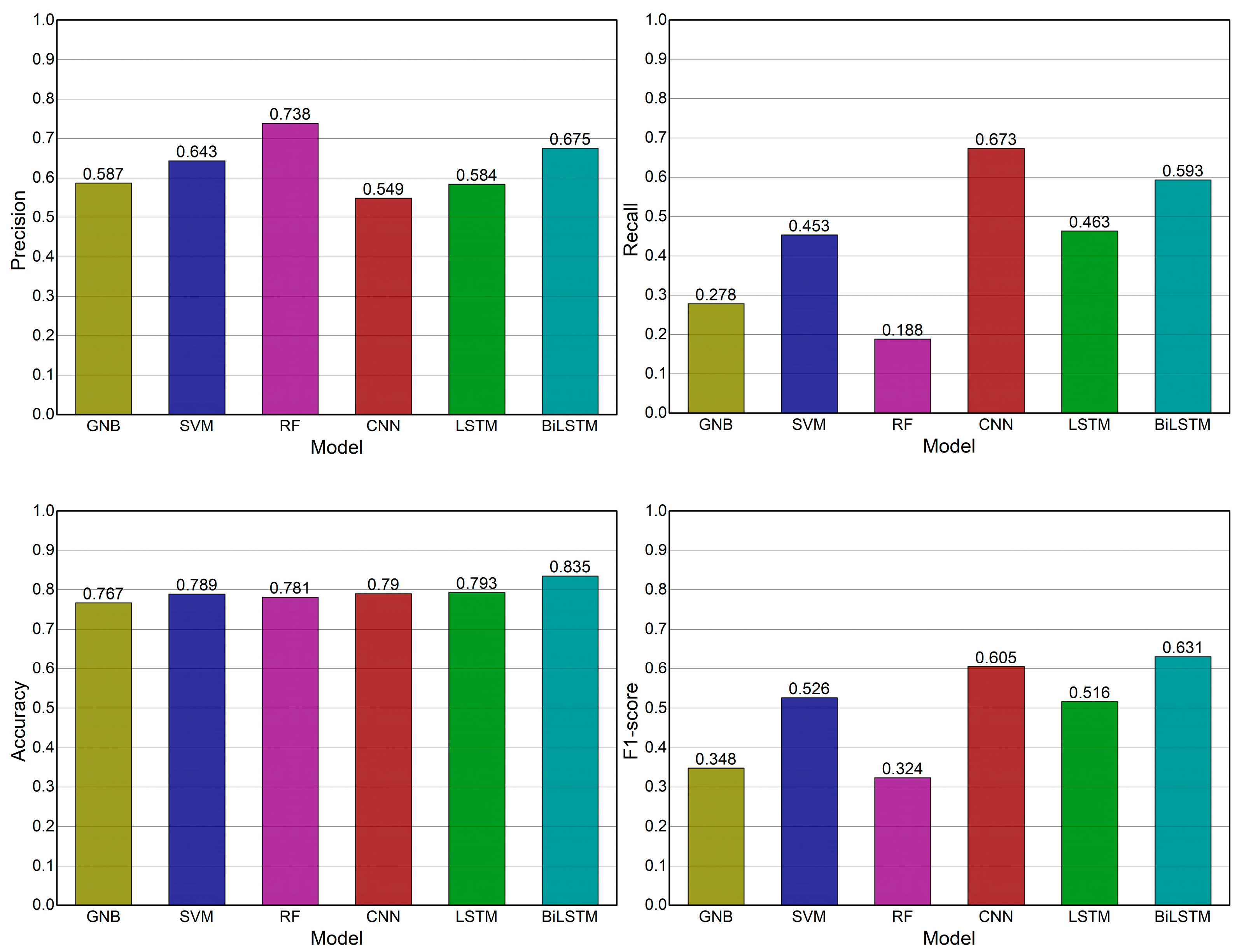
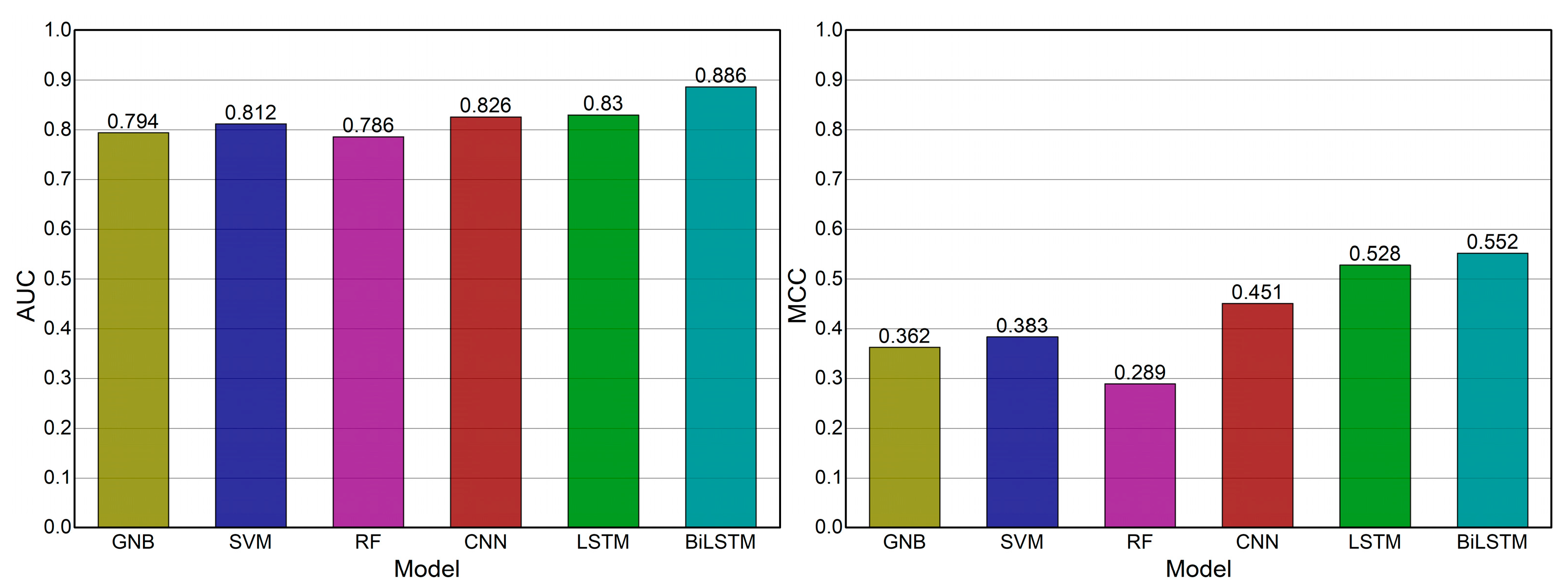
- The BiLSTM-based model had the highest performance among other machine learning models with an F1 score of 0.631 and an accuracy of 0.835.
2. Related Work
2.1. Spatio-Temporal Event Detection
2.2. Deep-Learning-Based Document Classification
3. Materials and Methods
3.1. Definition
3.2. Machine Learning Models
3.2.1. Convolutional Neural Network
3.2.2. Bidirectional Long Short-Term Memory
4. Experiment
4.1. Datasets
4.2. Data Preprocessing
5. Result and Discussion
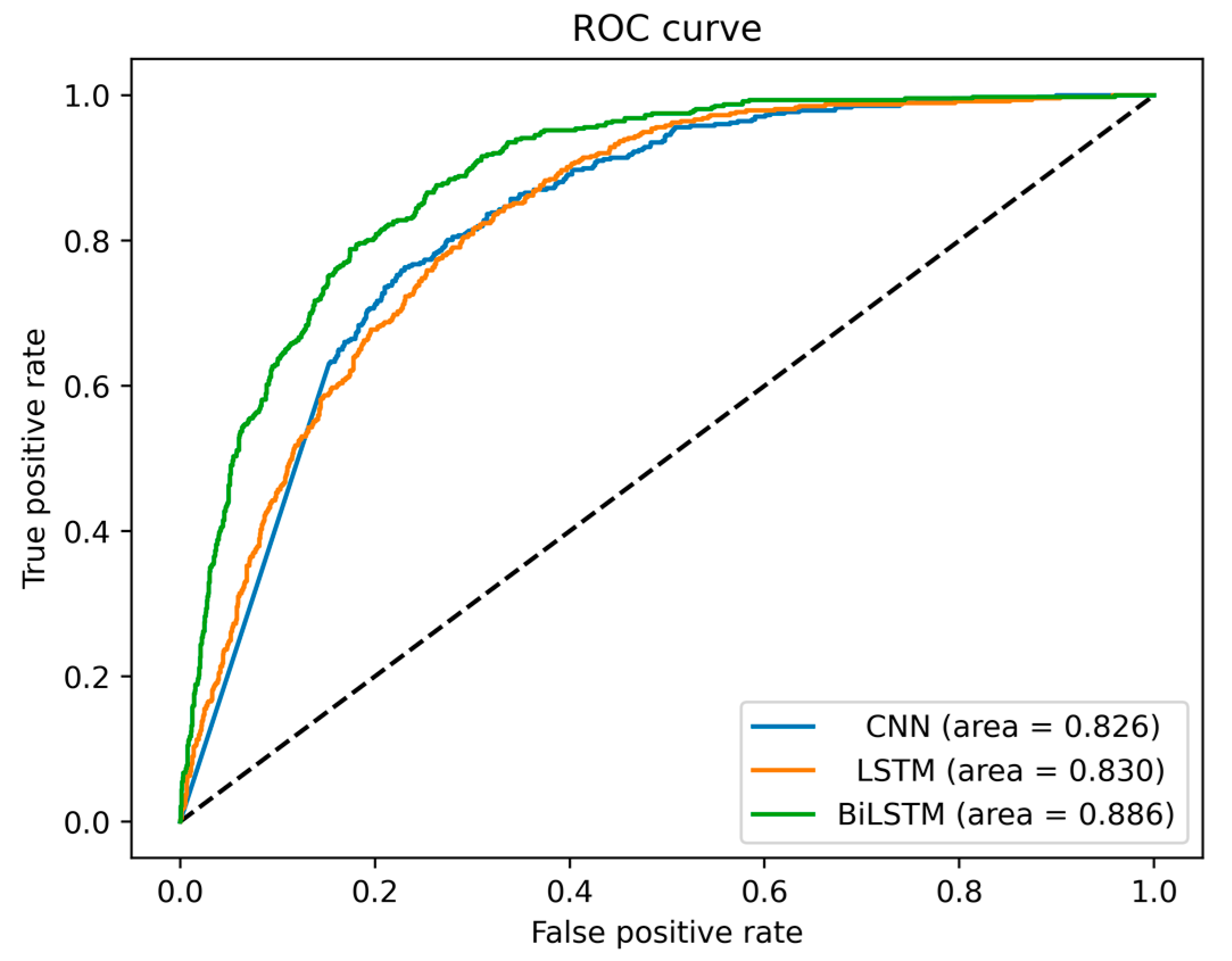
5.1. Performance Evaluation
5.2. Experimental Results
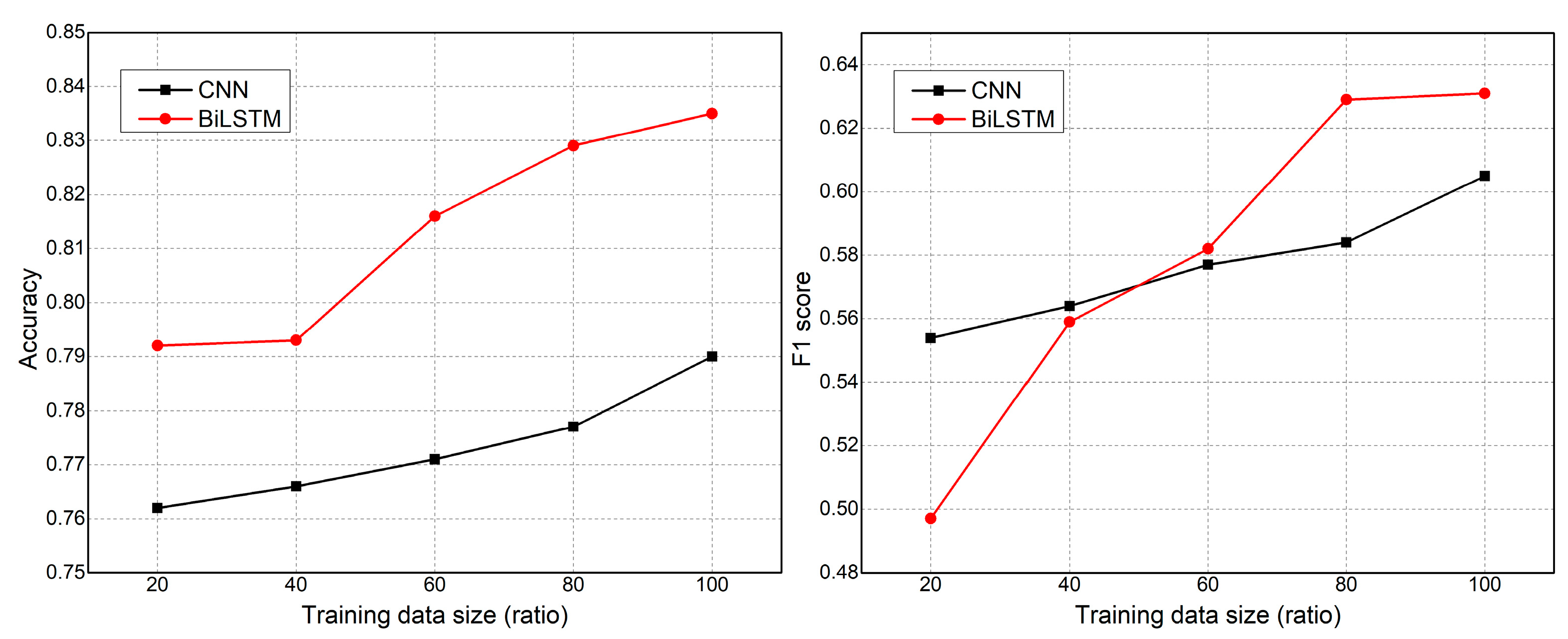
5.3. Learning Curve Analysis
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Ding, L.; Salem, M.B. A Novel Architecture for Automatic Document Classification for Effective Security in Edge Computing Environments. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018. [Google Scholar]
- Yang, Y.; Pierce, T.; Carbonell, J. A study of retrospective and on-line event detection. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; ACM: New York, NY, USA, 1998; pp. 28–36. [Google Scholar]
- Li, Z.; Wang, B.; Li, M.; Ma, W.-Y. A probabilistic model for retrospective news event detection. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, Brazil, 15–19 August 2005; ACM: New York, NY, USA, 2005; pp. 106–113. [Google Scholar]
- Yang, Y.; Carbonell, J.G.; Brown, R.D.; Pierce, T.; Archibald, B.T.; Liu, X. Learning approaches for detecting and tracking news events. IEEE Intell. Syst. Appl. 1999, 14, 32–43. [Google Scholar] [CrossRef] [Green Version]
- Kim, B.; Yang, Y.; Park, J.S.; Jang, H.-J. A Convolution Neural Network-Based Representative Spatio-Temporal Documents Classification for Big Text Data. Appl. Sci. 2022, 12, 3843. [Google Scholar] [CrossRef]
- Yu, M.; Bambacus, M.; Cervone, G.; Clarke, K.; Duffy, D.; Huang, Q.; Li, J.; Li, W.; Li, Z.; Liu, Q.; et al. Spatiotemporal event detection: A review. Int. J. Digit. Earth 2020, 13, 1339–1365. [Google Scholar] [CrossRef] [Green Version]
- George, Y.; Karunasekera, S.; Harwood, A. Real-time spatio-temporal event detection on geotagged social media. J. Big Data 2021, 8, 91. [Google Scholar] [CrossRef]
- Landrigan, P.; Fuller, R.; Acosta, N.R.; Adeyi, O.; Arnold, R.M.; Basu, N.; Baldé, A.B.; Bertollini, R.; Bose-O’Reilly, S.; Boufford, J.; et al. The Lancet Commission on Pollution and Health. Lancet 2018, 391, 462–512. [Google Scholar] [CrossRef] [Green Version]
- Hu, L.; Zhang, B.; Hou, L.; Li, J. Adaptive online event detection in news streams. Knowl. Based Syst. 2017, 138, 105–112. [Google Scholar] [CrossRef]
- Chen, G.; Kong, Q.; Mao, W. Online event detection and tracking in social media based on neural similarity metric learning. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017. [Google Scholar]
- Nguyen, D.T.; Jung, J.E. Real-time event detection for online behavioral analysis of big social data. Future Gener. Comput. Syst. 2017, 66, 137–145. [Google Scholar] [CrossRef]
- Ahuja, A.; Wei, W.; Lu, W.; Carley, K.M.; Reddy, C.K. A probabilistic geographical aspect-opinion model for geo-tagged microblogs. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; IEEE: New York, NY, USA; pp. 721–726. [Google Scholar]
- Shah, Z.; Dunn, A.G. Event detection on twitter by mapping unexpected changes in streaming data into a spatiotemporal lattice. In Proceedings of the IEEE Transactions on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 1–16. [Google Scholar]
- Afyouni, I.; Khan, A.; Al Aghbar, Z. Deep-Eware: Spatio-temporal social event detection using a hybrid learning model. J. Big Data 2022, 9, 86. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Tian, S.; Qu, Y. Feature selection for text classification with Naïve Bayes. Expert Syst. Appl. 2009, 36, 5432–5435. [Google Scholar] [CrossRef]
- Pavel, H. How to Build and Apply Naive Bayes Classification for Spam Filtering. Medium, Towards Data Science. 31 January 2020.
- Mitra, V.; Wang, C.-J.; Banerjee, S. Text classification: A least square support vector machine approach. Appl. Soft Comput. 2007, 7, 908–914. [Google Scholar] [CrossRef]
- Liang, J.-Z. SVM multi-classifier and Web document classification. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No.04EX826), Shanghai, China, 26–29 August 2004. [Google Scholar]
- Sharma, S.K.; Sharma, N.K.; Potter, P.P. Fusion Approach for Document Classification using Random Forest and SVM. In Proceedings of the 2020 9th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 4–5 December 2020. [Google Scholar]
- Afzal, M.Z.; Capobianco, S.; Malik, M.I.; Marinai, S.; Breuel, T.M.; Dengel, A.; Liwicki, M. Deepdocclassifier: Document classification with deep Convolutional Neural Network. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Sarasu, R.; Thyagharajan, K.K.; Shanker, N.R. SF-CNN: Deep Text Classification and Retrieval for Text Documents. Intell. Autom. Soft Comput. 2023, 35, 1799–1813. [Google Scholar] [CrossRef]
- Chang, W.-C.; Yang, Y. DocBERT: BERT for Document Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), Online, 5–10 July 2020; pp. 1422–1432. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–18 November 2020; pp. 4905–4915. [Google Scholar]
- Kristiani, E.; Tsan, Y.-T.; Liu, P.-Y.; Yen, N.Y.; Yang, C.-T. Binary and Multi-Class Assessment of Face Mask Classification on Edge AI Using CNN and Transfer Learning. Hum. Cent. Comput. Inf. Sci. 2022, 12, 53. [Google Scholar]
- Song, W.; Zhang, L.; Tian, Y.; Fong, S.; Liu, J. CNN-based 3D object classification using Hough space of LiDAR point clouds. Hum. Cent. Comput. Inf. Sci. 2020, 10, 19. [Google Scholar] [CrossRef]
- Bamasaq, O.; Alghazzawi, D.; Alshehri, S.; Jamjoom, A.; Asghar, M.Z. Efficient Classification of Hyperspectral Data Using Deep Neural Network Model. Hum. Cent. Comput. Inf. Sci. 2022, 12, 35. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Sak, H.; Senior, A.W.; Beaufays, F. Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling,” 2014. Available online: https://research.google/pubs/pub43905/ (accessed on 18 February 2023).
- Hussain, S.N.; Aziz, A.A.; Hossen, M.J.; Aziz, N.A.A.; Murthy, G.R.; Mustakim, F.B. A Novel Framework Based on CNN-LSTM Neural Network for Prediction of Missing Values in Electricity Consumption Time-Series Datasets. J. Inf. Process. Syst. 2022, 18, 115–129. [Google Scholar]
- Zeng, Y.; Zhang, R.; Yang, L.; Song, S. Cross-Domain Text Sentiment Classification Method Based on the CNN-BiLSTM-TE Model. J. Inf. Process. Syst. 2021, 17, 818–833. [Google Scholar]
- Park, S.; Jung, S.; Moon, J.; Hwang, E. Explainable Photovoltaic Power Forecasting Scheme Using BiLSTM. KIPS Trans. Softw. Data Eng. 2022, 11, 339–346. [Google Scholar]
- Fast Text. Available online: https://fasttext.cc (accessed on 18 February 2023).
- National Institute of the Korean Language. Available online: https://www.korean.go.kr (accessed on 18 February 2023).
- Chicco, D. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3730–3744. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Huang, X.; Chen, K.; Cai, D. Graph Convolutional Networks with Entity Aware Attention for Document Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 4498–4505. [Google Scholar]
- Manzo, M.; Pellino, S. FastGCN+ ARSRGemb: A novel framework for object recognition. J. Electron. Imaging 2021, 30, 033011. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Topic | No. | When | No. | Who | Article |
|---|---|---|---|---|---|---|
| No. | Where | No. | What | |||
| 0 | life | nan | nan | nan | nan | ‘Subway pilgrims’ on their way to work… |
| nan | nan | nan | nan | |||
| 0 | society | nan | nan | nan | nan | Was Congressman Jin Seong-ho… |
| nan | nan | nan | nan | |||
| 1 | society | 1 | 31 December last year | 1 | citizens | Politicians, please stop fighting… |
| 1 | Daegu Sports Park | 1 | New Year’s Eve Bell | |||
| 1 | society | 2 | Last 31 December | 1 | Daejeon citizens | Citizens of Daejeon celebrate the New Year… |
| 2 | Daejeon Jung-gu | 2 | candlelight vigil |
| Split Data | Count | RSTEDoc | Non-RSTEDoc | Ratio |
|---|---|---|---|---|
| Training | 6000 | 1433 | 4567 | 31.38% |
| Validation | 2000 | 477 | 1523 | 31.32% |
| Test | 2000 | 477 | 1523 | 31.32% |
| Total | 10000 | 2387 | 7613 | 31.35% |
| Machine Learning | Precision | Recall | F1 Score | Accuracy | AUC | MCC |
|---|---|---|---|---|---|---|
| Gaussian Naïve Bayes | 0.587 | 0.278 | 0.348 | 0.767 | 0.794 | 0.362 |
| Linear SVM | 0.643 | 0.453 | 0.526 | 0.789 | 0.812 | 0.383 |
| Random Forest | 0.738 | 0.188 | 0.324 | 0.781 | 0.786 | 0289 |
| CNN | 0.549 | 0.673 | 0.605 | 0.790 | 0.826 | 0.451 |
| LSTM | 0.584 | 0.463 | 0.516 | 0.793 | 0.830 | 0.528 |
| BiLSTM | 0.675 | 0.593 | 0.631 | 0.835 | 0.886 | 0.552 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Yang, Y.; Park, J.S.; Jang, H.-J. Machine Learning Based Representative Spatio-Temporal Event Documents Classification. Appl. Sci. 2023, 13, 4230. https://doi.org/10.3390/app13074230
Kim B, Yang Y, Park JS, Jang H-J. Machine Learning Based Representative Spatio-Temporal Event Documents Classification. Applied Sciences. 2023; 13(7):4230. https://doi.org/10.3390/app13074230
Chicago/Turabian StyleKim, Byoungwook, Yeongwook Yang, Ji Su Park, and Hong-Jun Jang. 2023. "Machine Learning Based Representative Spatio-Temporal Event Documents Classification" Applied Sciences 13, no. 7: 4230. https://doi.org/10.3390/app13074230