
NFT Image Plagiarism Check Using EfficientNet-Based Deep Neural Network with Triplet Semi-Hard Loss



Abstract
:1. Introduction
- Preprocessing the NFT dataset and using it to generate augmented images.
- Detecting plagiarized NFT images based on EfficientNet-B0-based deep neural network (EfficientNet-B0-DNN) with triplet semi-hard loss.
- Developing a network suitable for actual NFT ecosystems and providing high accuracy and reliable performance.
- Comparing several modern deep learning methods and pointing out the EfficientNet-B0-DNN method outperforms other CNN methods such as ResNet50, DenseNet, and MobileNetV2 in terms of loss and accuracy.
2. System Overview
2.1. NFTs Concept
| Algorithm 1: ERC-721 Standard Interface |
interface ERC721 { function transferFrom(address _from, address _to, uint256 _tokenId) external payable; function ownerOf(uint256 _tokenId) external view returns (address); function balanceOf(address _owner) external view returns (uint256); ... } |
| Algorithm 2: ERC-1155 Standard Interface |
interface ERC1155 { event TransferSingle(address indexed _operator, address indexed _from, address indexed _to, uint256 _id, uint256 _value); event TransferBatch(address indexed _operator, address indexed _from, address indexed _to, uint256[] _ids, uint256[] _values); function balanceOfBatch(address[] calldata _owners, uint256[] calldata _ids) external view returns (uint256[] memory); ... } |
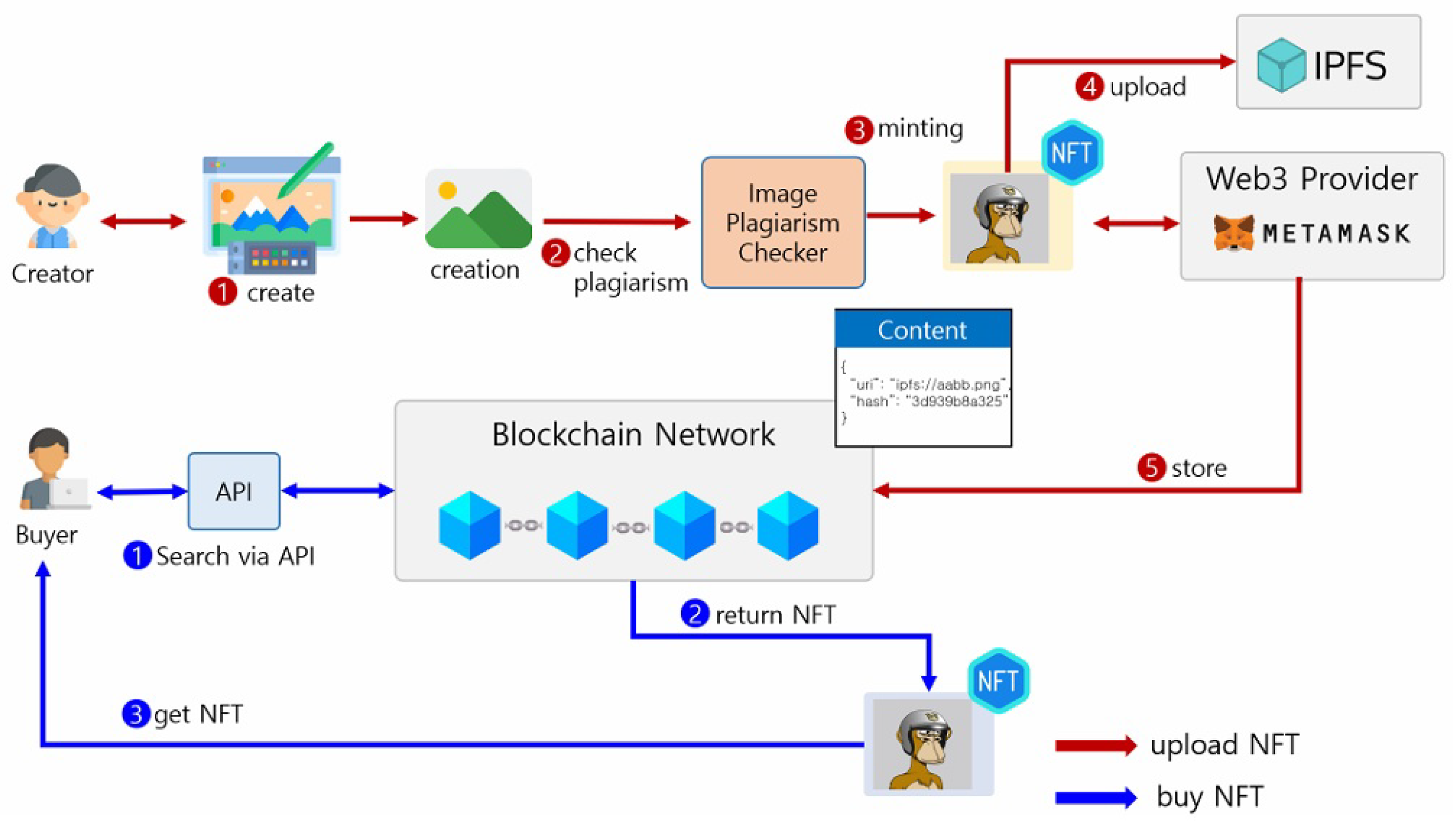
2.2. Proposed Solution Scheme
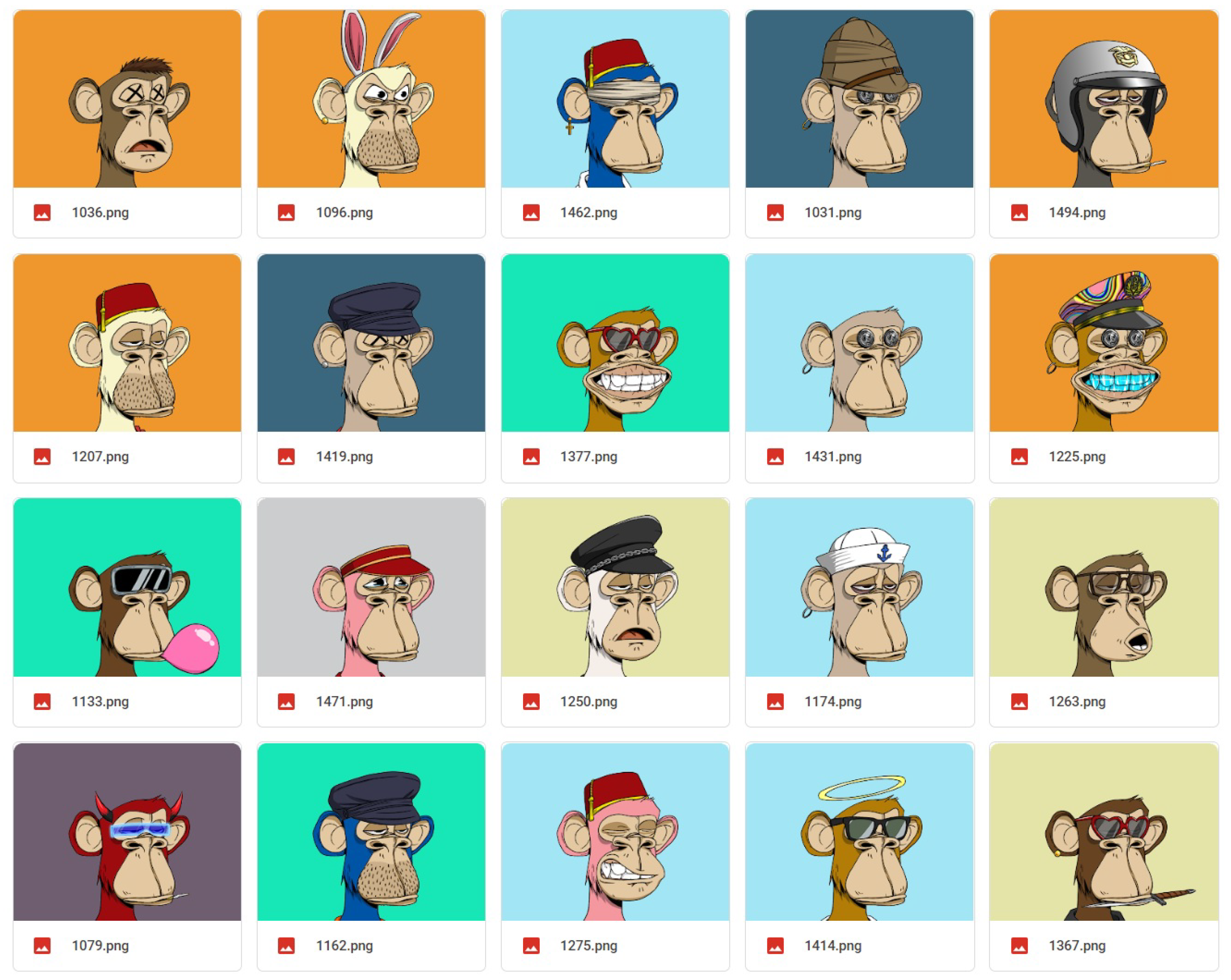
2.3. NFTs Image Dataset
2.4. Image Augmentation
3. Methodology
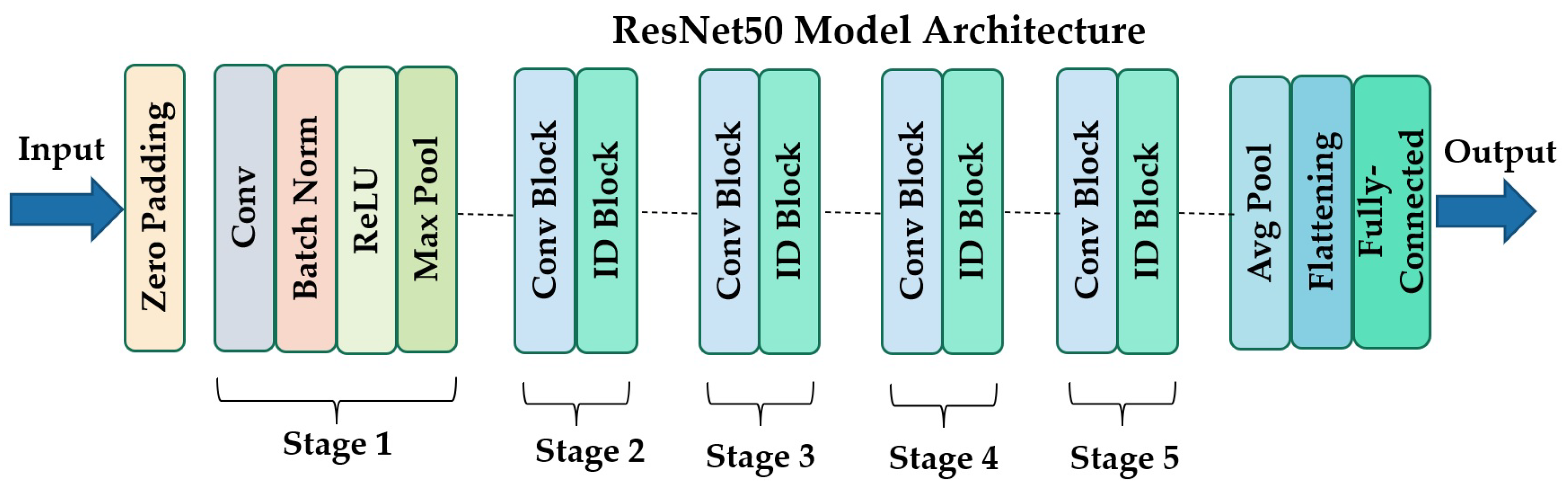
3.1. ResNet50
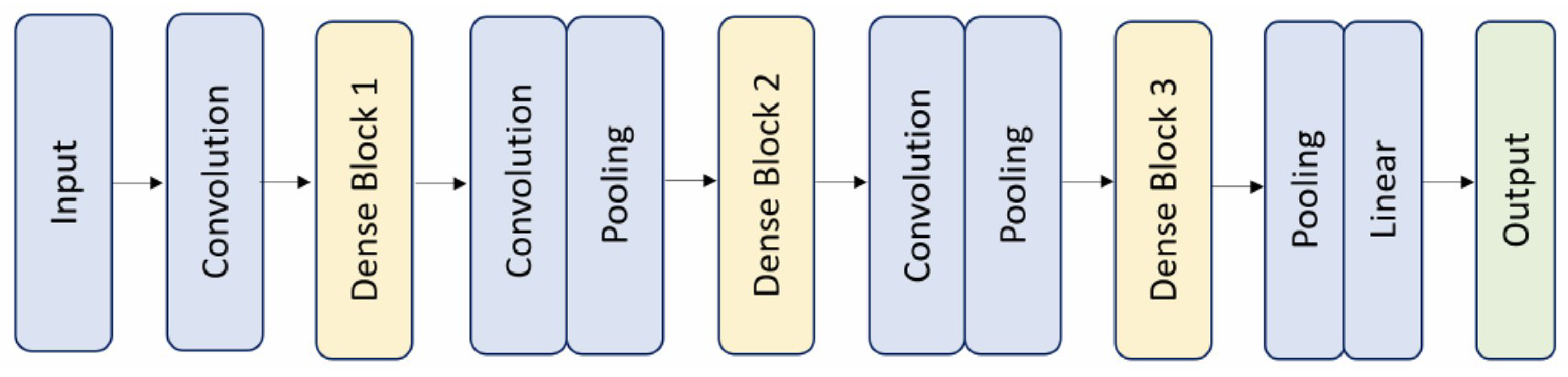
3.2. DenseNet
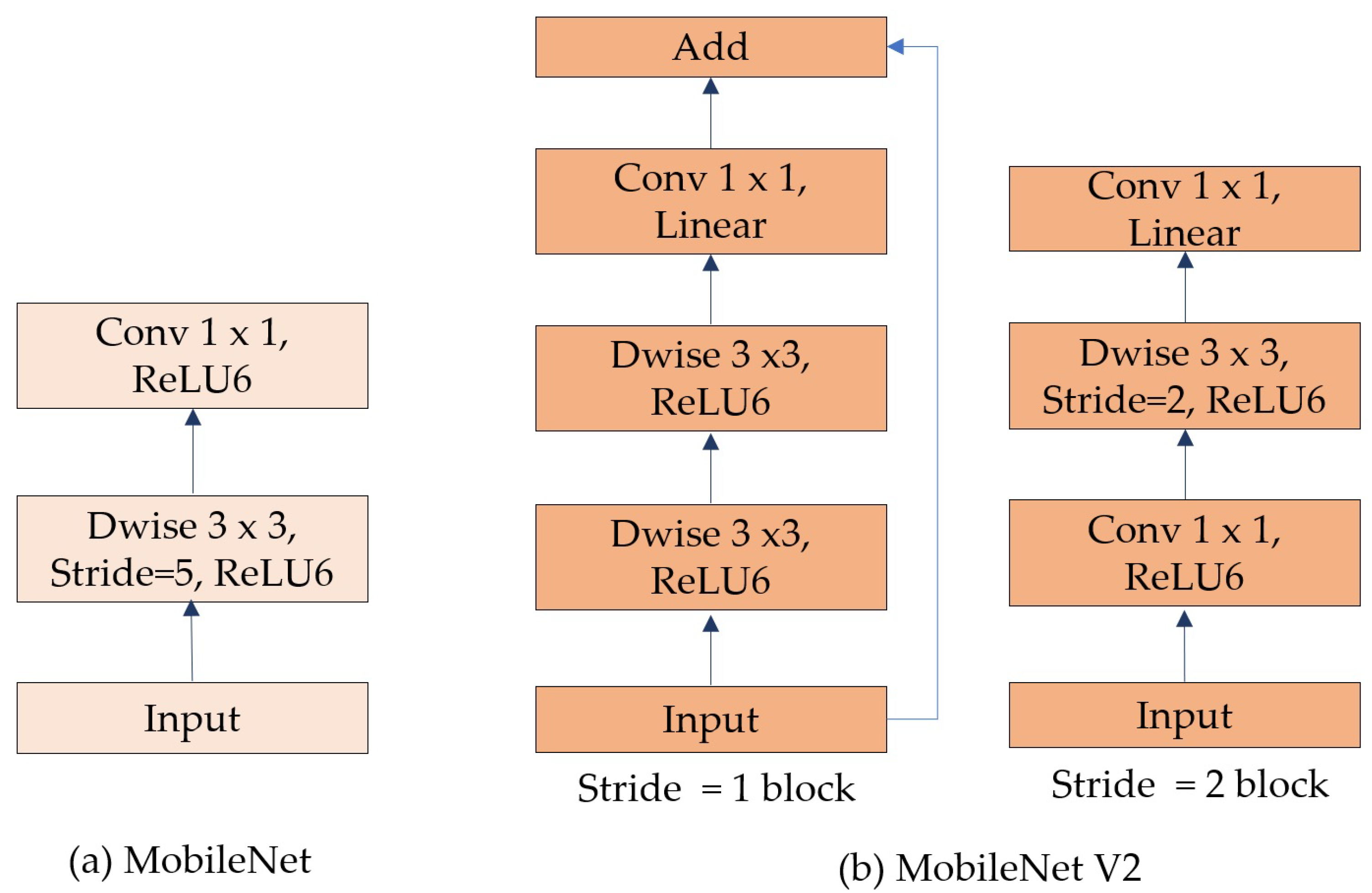
3.3. MobileNetV2
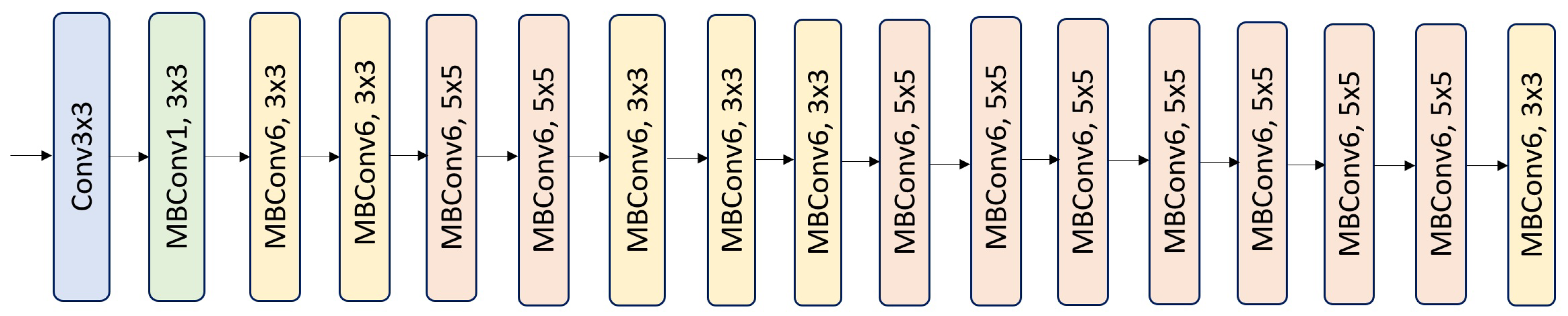
3.4. EfficientNet
4. Experiment and Results
4.1. Hyperparameters Setting
4.2. Performance Criteria
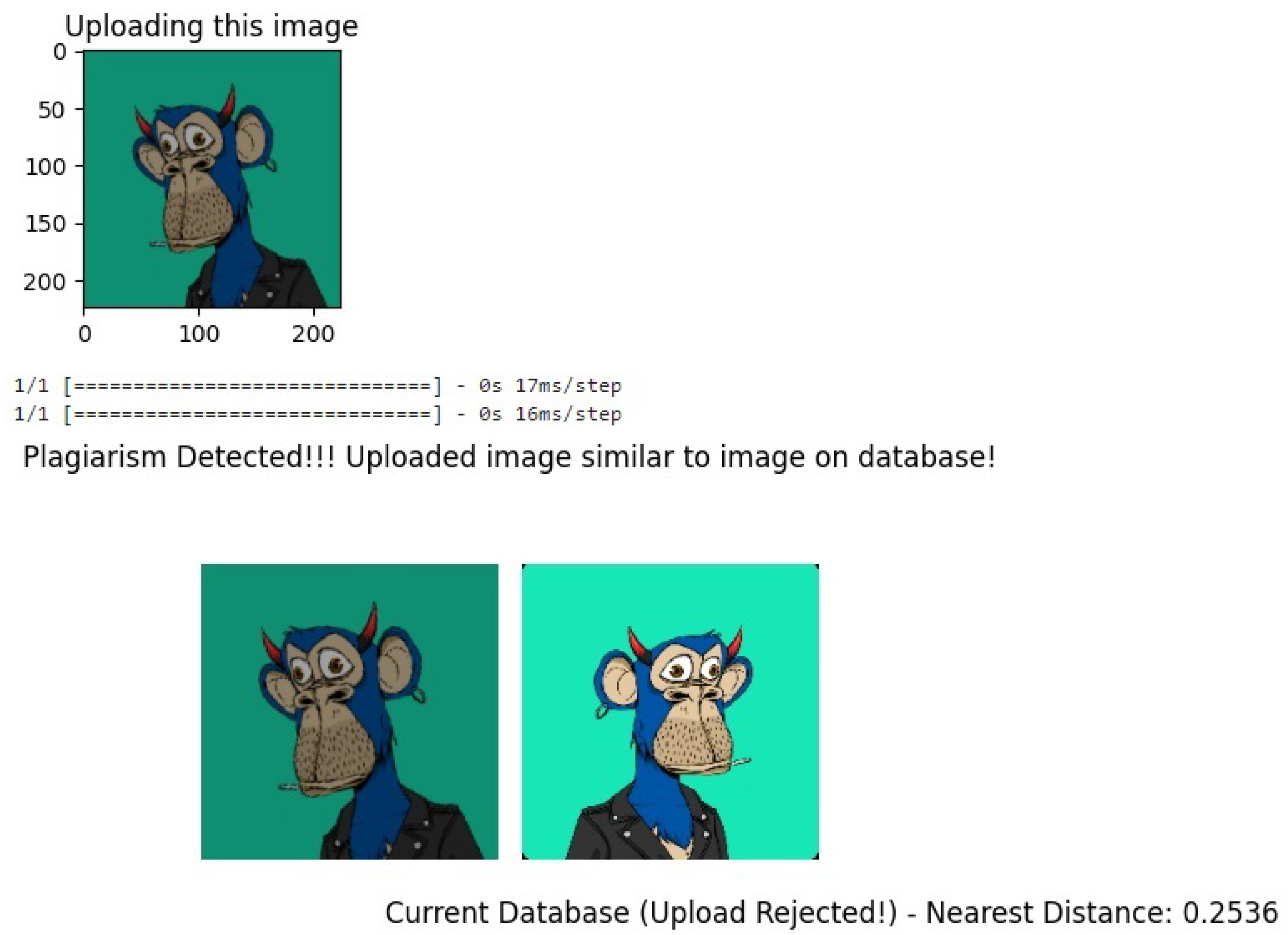
4.2.1. Euclidean Distance
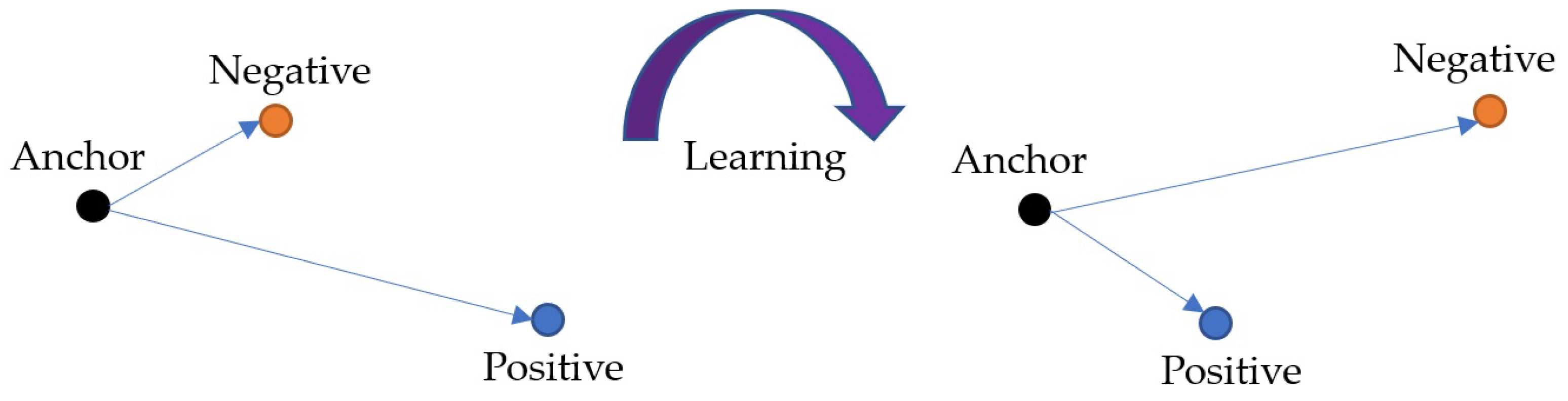
4.2.2. Triplet Semi-Hard Loss
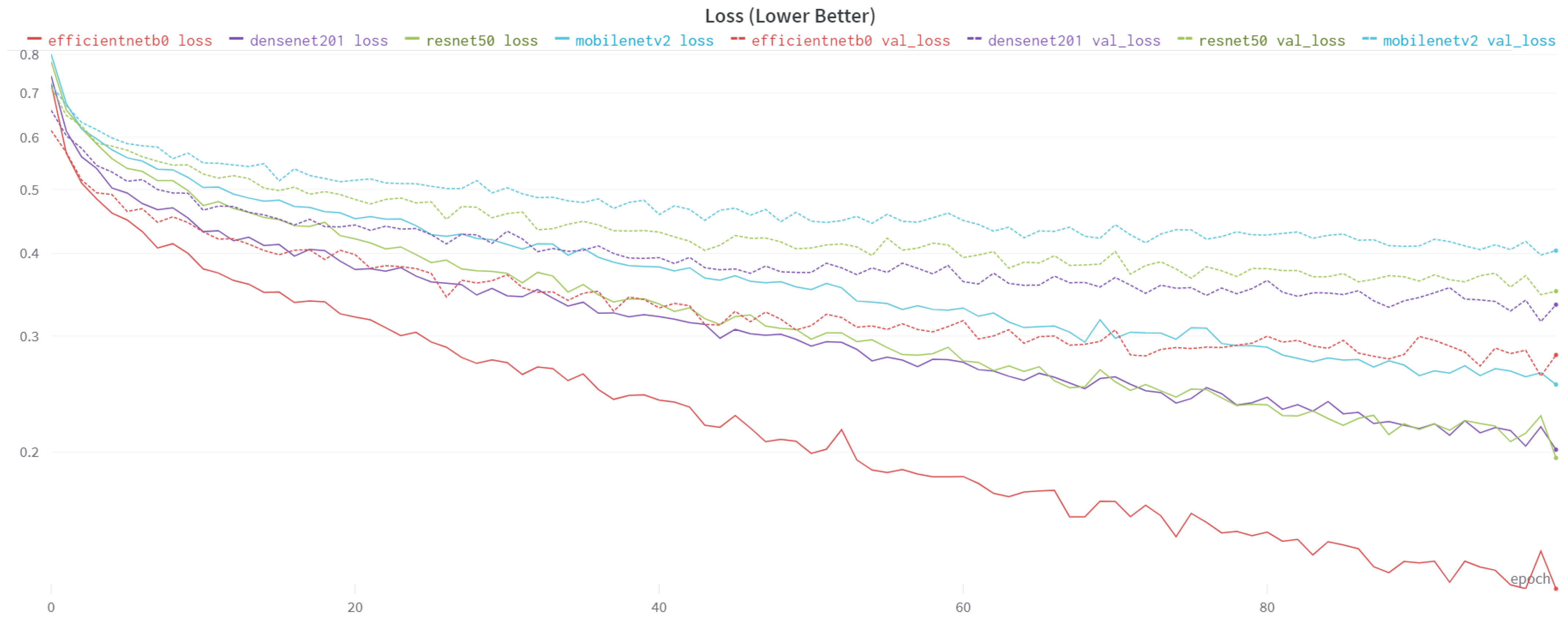
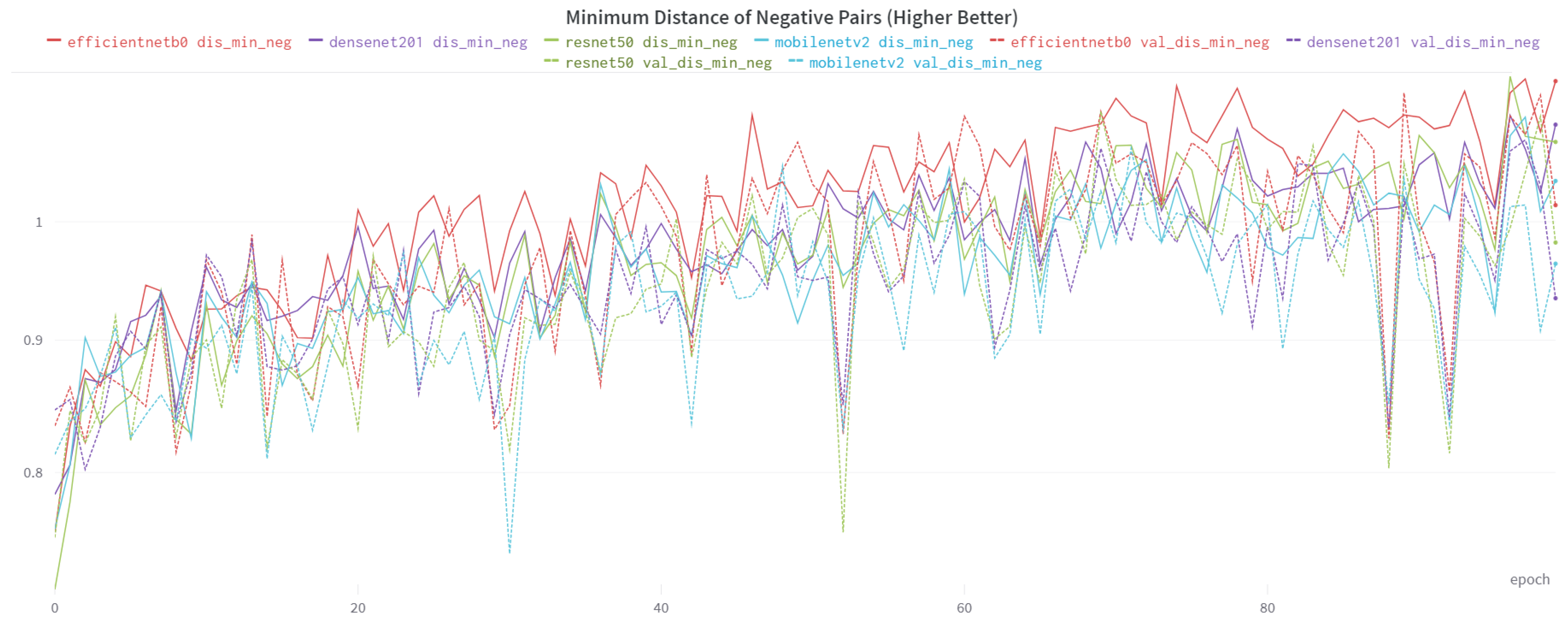
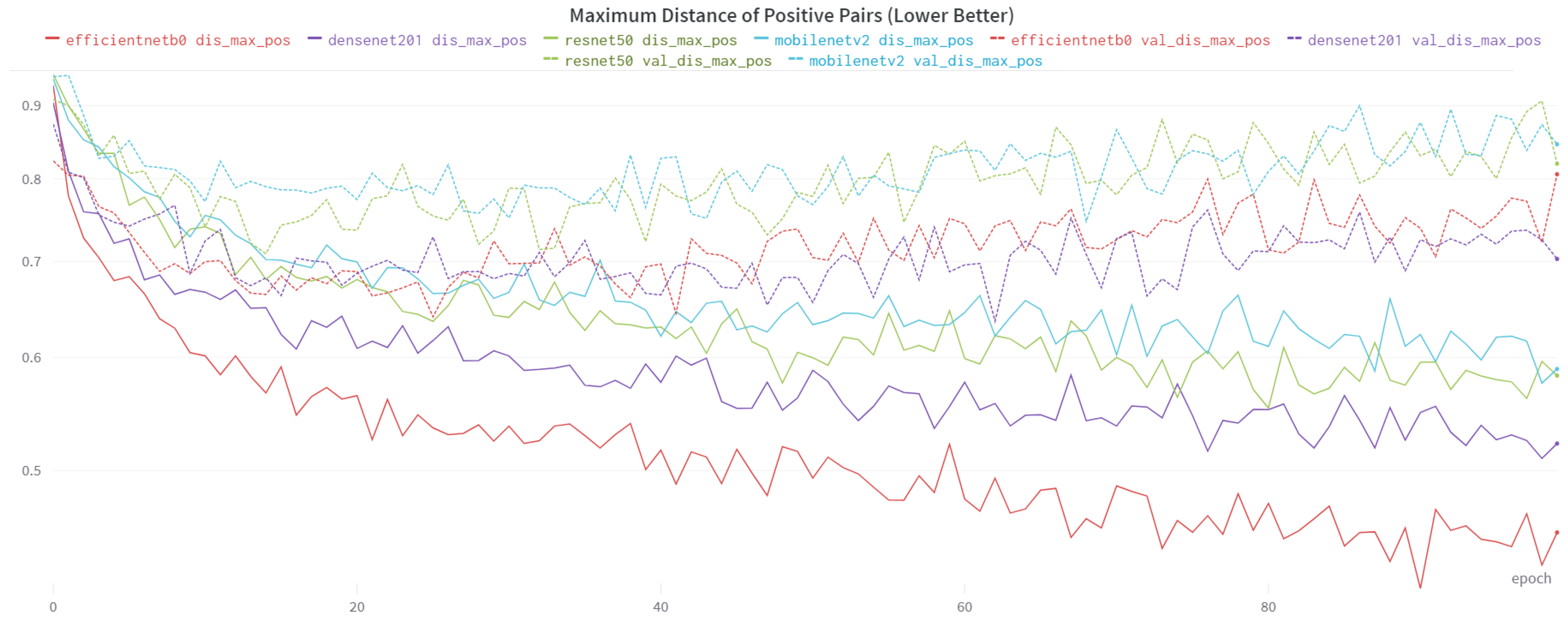
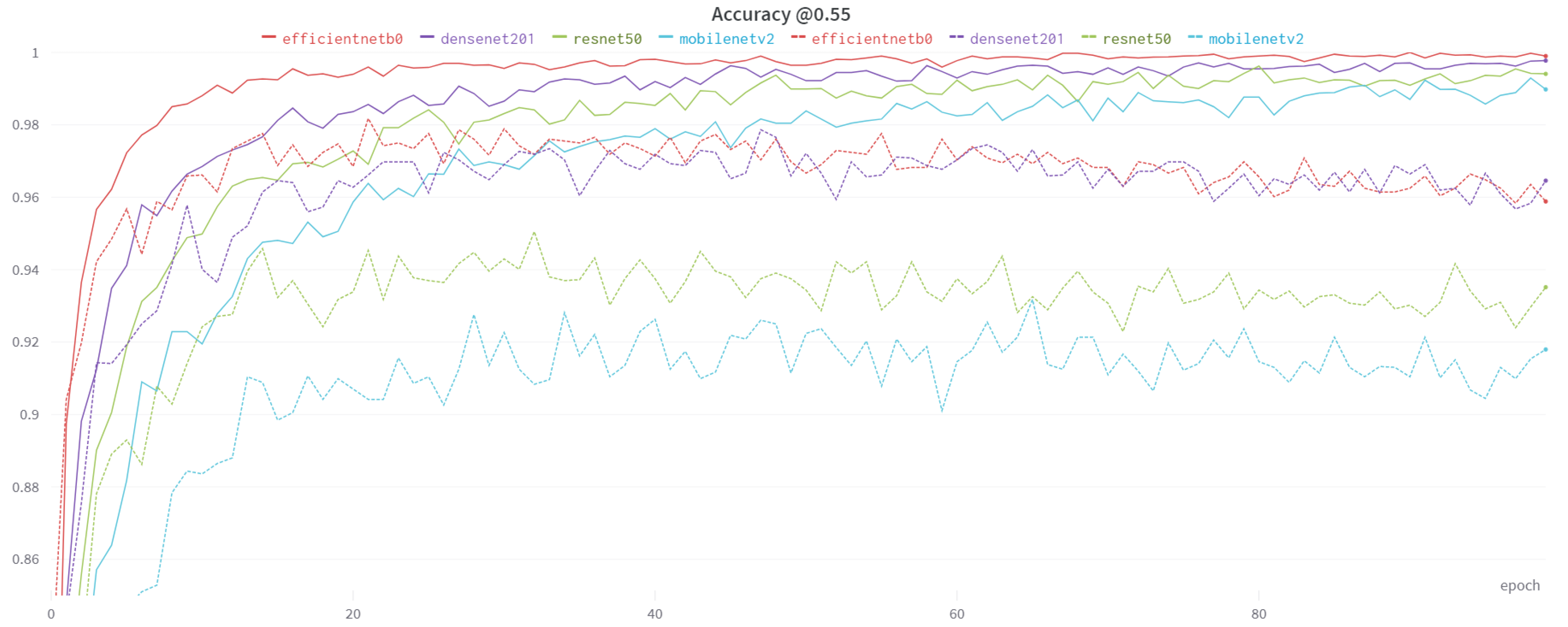
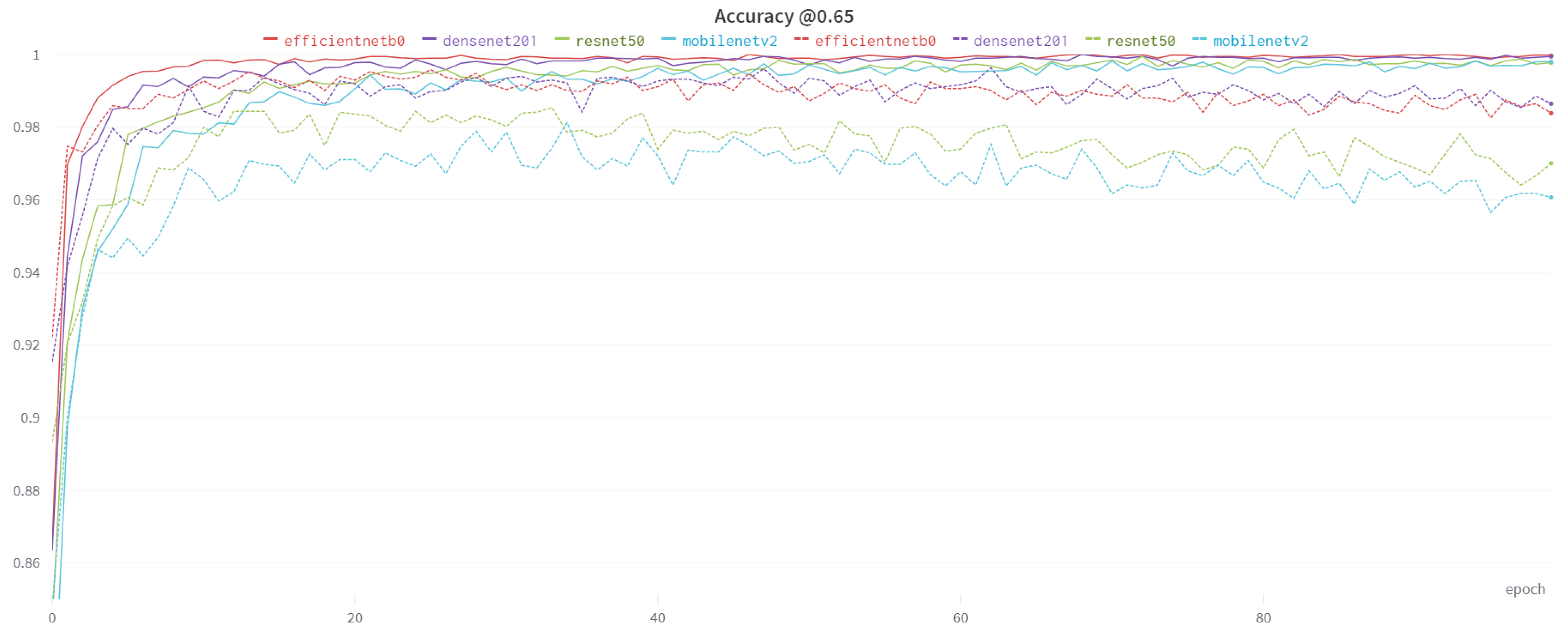
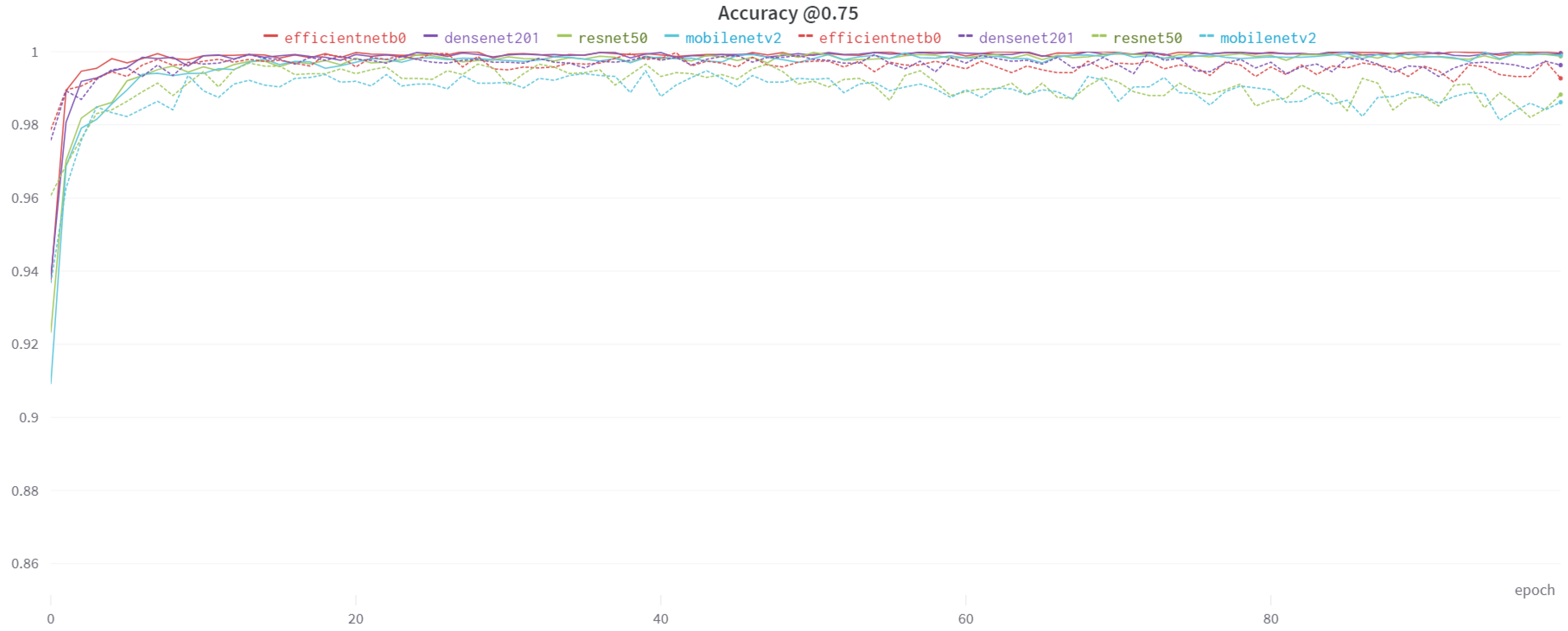
4.3. Results and Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Adam | Adaptive Momentum Estimation |
| ANN | Artificial Neural Networks |
| API | Application Programming Interface |
| ASCII | American Standard Code for Information Interchange |
| CID | Content Identification |
| CNN | Convolutional Neural Network |
| CV | Computer Vision |
| DNN | Deep Neural Network |
| EIP | Ethereum Improvement Proposals |
| ERC | Ethereum Request for Comment |
| GAN | Generative Adversarial Network |
| HSV | Hue Saturation Value |
| HTTP | Hypertext Transfer Protocol |
| IPFS | InterPlanetary File System |
| NDFA | Non-deterministic Finite Automaton |
| NFT | Non-Fungible Token |
| ReLU | Rectified Linear Unit |
| RGB | Red Green Blue |
| SGD | Stochastic Gradient Descent |
References
- Ozon Networks, I. What is an NFT? Available online: https://opensea.io/learn/what-are-nfts (accessed on 16 December 2022).
- Mochram, R.; Makawowor, C.; Tanujaya, K.; Moniaga, J.; Jabar, B. Systematic Literature Review: Blockchain Security in NFT Ownership. In Proceedings of the 2022 International Conference on Electrical and Information Technology (IEIT), Malang, Indonesia, 14–15 September 2022; pp. 302–306. [Google Scholar]
- Abaci, I.; Ulku, E. NFT-based Asset Management System. In Proceedings of the 2022 International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkeym, 20–22 October 2022; pp. 697–701. [Google Scholar]
- Prior, G. Since the Explosion of NFTs, Plagiarism and Fakes Have Increase Problems. Available online: http://www.koreaittimes.com/news/articleView.html?idxno=111519 (accessed on 16 December 2022).
- Bonifacic, I. Over 80 Percent of NFTs Minted for Free on OpenSea Are Fake, Plagiarized or Spam. Available online: https://www.engadget.com/opensea-free-minting-tool-220008042.html (accessed on 19 December 2022).
- Pungila, C.; Galis, D.; Negru, V. A New High-Performance Approach to Approximate Pattern-Matching for Plagiarism Detection in Blockchain-Based Non-Fungible Tokens (NFTs). arXiv 2022, arXiv:2205.14492. [Google Scholar]
- Ibrahin, A.; Khalifa, O.; Ahmed, D. Plagiarism Detection of Images. In Proceedings of the 2020 IEEE Student Conference on Research and Development (SCOReD), Batu Pahat, Malaysia, 27–29 September 2020; pp. 183–188. [Google Scholar]
- Gayadhankar, K.; Patel, R.; Lodha, H.; Shinde, S. Image plagiarism detection using GAN-(Generative Adversarial Network). In Proceedings of the ITM Web of Conferences, Navi Mumbai, India, 14–15 July 2021; Volume 40, p. 03013. [Google Scholar]
- Meuschke, N.; Gondek, C.; Seebacher, D.; Breitinger, C.; Keim, D.; Gipp, B. An adaptive image-based plagiarism detection approach. In Proceedings of the 18th ACM/IEEE on Joint Conference on Digital Libraries, Fort Worth, TX, USA, 3–7 June 2018; pp. 131–140. [Google Scholar]
- Shahriar, S.; Hayawi, K. NFTGAN: Non-Fungible Token Art Generation Using Generative Adversarial Networks. In Proceedings of the 2022 7th International Conference on Machine Learning Technologies (ICMLT), Rome, Italy, 11–13 March 2022; pp. 255–259. [Google Scholar]
- Bao, H.; Roubaud, D. Non-Fungible Token: A Systematic Review and Research Agenda. J. Risk Financ. Manag. 2022, 15, 215. [Google Scholar] [CrossRef]
- Shilina, S. Blockchain and Non-Fungible Tokens (NFTs): A New Mediator Standard for Creative Industries Communication. 2021, pp. 217–225. Available online: https://bit.ly/3FLFDQV (accessed on 20 December 2022).
- Entriken, W.; Shirley, D.; Evans, J.; Sachs, N. EIP-721: Non-Fungible Token Standard, Ethereum Improvement Proposals, no. 721, January 2018. [Online Serial]. Available online: https://eips.ethereum.org/EIPS/eip-721 (accessed on 20 December 2022).
- Radomski, W.; Cooke, A.; Castonguay, P.; Therien, J.; Binet, E.; Sandford, R. EIP-1155: Multi Token Standard, Ethereum Improvement Proposals, no. 1155. June 2018. Available online: https://eips.ethereum.org/EIPS/eip-1155 (accessed on 20 December 2022).
- Wang, Q.; Li, R.; Wang, Q.; Chen, S. Non-fungible token (NFT): Overview, evaluation, opportunities and challenges. arXiv 2021, arXiv:2105.07447. [Google Scholar]
- Howell, J. ERC 1155 Vs. ERC 721—Key Differences. Available online: https://101blockchains.com/erc-1155-vs-erc-721/ (accessed on 16 February 2023).
- Ravencraft, E. NFTs Don’t Work the Way You Might Think They Do. Available online: https://www.wired.com/story/nfts-dont-work-the-way-you-think-they-do/ (accessed on 22 January 2023).
- Smith, C. Scaling. Available online: https://ethereum.org/en/developers/docs/scaling/ (accessed on 14 February 2023).
- Ivanovs, A. How to Create an NFT Collection With a Smart Contract. Available online: https://geekflare.com/create-nft-collection-with-a-smart-contract/ (accessed on 14 February 2023).
- Westerkamp, M. Blockchain Interoperability and Its Relevance. Available online: https://www.gsma.com/aboutus/workinggroups/blockchain-interoperability-and-its-relevance (accessed on 14 February 2023).
- Bellagarda, J.; Abu-Mahfouz, A. Connect2NFT: A Web-Based, Blockchain Enabled NFT Application with the Aim of Reducing Fraud and Ensuring Authenticated Social, Non-Human Verified Digital Identity. Mathematics 2022, 10, 3934. [Google Scholar] [CrossRef]
- Battah, A.; Madine, M.; Alzaabi, H.; Yaqoob, I.; Salah, K.; Jayaraman, R. Blockchain-based multi-party authorization for accessing IPFS encrypted data. IEEE Access 2020, 8, 196813–196825. [Google Scholar] [CrossRef]
- Choi, D. Decentralizing NFT.Storage. Available online: https://blog.nft.storage/posts/2022-01-20-decentralizing-nft-storage (accessed on 15 February 2023).
- Technology, M. IPFS NFT—How to Use IPFS for NFT Metadata. Available online: https://moralis.io/ipfs-nft-how-to-use-ipfs-for-nft-metadata/ (accessed on 11 January 2022).
- Mak, S. Nft-Classifier. Available online: https://www.kaggle.com/datasets/shaunmak/nft-classifier (accessed on 19 November 2022).
- Frederik Hvilshoj Balanced and Imbalanced Datasets in Machine Learning [Introduction]. Available online: https://encord.com/blog/an-introduction-to-balanced-and-imbalanced-datasets-in-machine-learning/ (accessed on 17 February 2022).
- Nelson, J. What Is Image Preprocessing and Augmentation? Available online: https://blog.roboflow.com/why-preprocess-augment/ (accessed on 22 December 2022).
- Donges, N. What Is Transfer Learning? Exploring the Popular Deep Learning Approach. Available online: https://builtin.com/data-science/transfer-learning (accessed on 23 December 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Prihatno, A.; Utama, I.; Kim, J.; Jang, Y. Metal Defect Classification Using Deep Learning. In Proceedings of the 2021 Twelfth International Conference on Ubiquitous and Future Networks (ICUFN), Jeju Island, Republic of Korea, 17–20 August 2021; pp. 389–393. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Wey, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Vaibhav Kumar MobileNet vs ResNet50—Two CNN Transfer Learning Light Frameworks. Available online: https://analyticsindiamag.com/mobilenet-vs-resnet50-two-cnn-transfer-learning-light-frameworks (accessed on 19 February 2023).
- Lee, C.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Artificial Intelligence And Statistics; U.S. Department of Energy: Washington, DC, USA, 2015; pp. 562–570. [Google Scholar]
- Tsang, S. Review: MobileNetV2—Light Weight Model (Image Classification). Available online: https://towardsdatascience.com/review-mobilenetv2-light-weight-model-image-classification-8febb490e61c (accessed on 6 January 2023).
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Biswas, P. Intuitions behind Different Activation Functions in Deep Learning. Available online: https://towardsdatascience.com/intuitions-behind-different-activation-functions-in-deep-learning-a2b1c8d044a (accessed on 25 January 2023).
- Pramoditha, R. How to Choose the Optimal Learning Rate for Neural Networks. Available online: https://towardsdatascience.com/how-to-choose-the-optimal-learning-rate-for-neural-networks-362111c5c783 (accessed on 25 January 2023).
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Ng, A. How to Choose the Optimal Learning Rate for Neural Networks. Available online: https://cs230.stanford.edu/files/C2M2.pdf (accessed on 25 January 2023).
- Prihatno, A.; Nurcahyanto, H.; Ahmed, M.; Rahman, M.; Alam, M.; Jang, Y. Forecasting PM2.5 Concentration Using a Single-Dense Layer BiLSTM Method. Electronics 2021, 10, 1808. [Google Scholar] [CrossRef]
- Chugh, H.; Gupta, S.; Garg, M.; Gupta, D.; Juneja, S.; Turabieh, H.; Na, Y.; Kiros Bitsue, Z. Image retrieval using different distance methods and color difference histogram descriptor for human healthcare. J. Healthc. Eng. 2022, 2022, 9523009. [Google Scholar] [CrossRef] [PubMed]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 19 December 2022).
- Kim, S.; Kim, D.; Cho, M.; Kwak, S. Proxy anchor loss for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3238–3247. [Google Scholar]
- Chollet, F. Keras Applications. Available online: https://keras.io/api/applications/ (accessed on 12 January 2023).
- Wongpanich, A.; Pham, H.; Demmel, J.; Tan, M.; Le, Q.; You, Y.; Kumar, S. Training EfficientNets at supercomputer scale: 83% ImageNet top-1 accuracy in one hour. In Proceedings of the 2021 IEEE International Parallel And Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021; pp. 947–950. [Google Scholar]
- Pedraza, A.; Deniz, O.; Bueno, G. On the relationship between generalization and robustness to adversarial examples. Symmetry 2021, 13, 817. [Google Scholar] [CrossRef]
- Rafi, A.; Kamal, U.; Hoque, R.; Abrar, A.; Das, S.; Laganiere, R.; Hasan, M. Application of DenseNet in Camera Model Identification and Post-processing Detection. CVPR Work. 2019, 19–28. [Google Scholar]
- Deepchecks Ltd. Densenet. Available online: https://deepchecks.com/glossary/densenet/ (accessed on 3 February 2023).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Models Compared (ResNet50, DenseNet, MobileNetV2, EfficientNet-B0) |
|---|---|
| ine Activation | ReLU |
| Batch Size | 64 |
| Learning rate | 0.001 |
| Training data | 70% |
| Validation data | 30% |
| Loss Function | Triplet semi-hard loss |
| Optimizer | Adam |
| Embedded dimension | 128 |
| Epoch | 100 |
| Model | Loss | Validation Loss | Training Times |
|---|---|---|---|
| ResNet50 | 0.1961 | 0.3507 | 228.677 |
| DenseNet | 0.2018 | 0.3346 | 223.992 |
| MobileNetV2 | 0.2533 | 0.4040 | 222.148 |
| EfficientNet-B0 | 0.1242 | 0.2808 | 230.379 |
| Parameter | Model | Train | Validation |
|---|---|---|---|
| ResNet50 | 0.5827 | 0.8199 | |
| DenseNet | 0.5223 | 0.7032 | |
| Maximum Distance of Positive Pairs | MobileNetV2 | 0.5889 | 0.8457 |
| EfficientNet-B0 | 0.4526 | 0.8059 | |
| ResNet50 | 1.074 | 0.9817 | |
| DenseNet | 1.090 | 0.9342 | |
| Minimum Distance of Negative Pairs | MobileNetV2 | 1.037 | 0.9634 |
| EfficientNet-B0 | 1.133 | 1.0150 |
| Threshold Score | Model | Accuracy | Validation Accuracy |
|---|---|---|---|
| ResNet50 | 0.9941 | 0.9352 | |
| DenseNet | 0.9977 | 0.9646 | |
| 0.55 | MobileNetV2 | 0.9898 | 0.9180 |
| EfficientNet-B0 | 0.9990 | 0.9588 | |
| ResNet50 | 0.9977 | 0.9700 | |
| DenseNet | 0.9995 | 0.9864 | |
| 0.65 | MobileNetV2 | 0.9980 | 0.9607 |
| EfficientNet-B0 | 0.9997 | 0.9838 | |
| ResNet50 | 0.9987 | 0.9883 | |
| DenseNet | 0.9995 | 0.9963 | |
| 0.75 | MobileNetV2 | 0.9990 | 0.9862 |
| EfficientNet-B0 | 0.9996 | 0.9927 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prihatno, A.T.; Suryanto, N.; Oh, S.; Le, T.-T.-H.; Kim, H. NFT Image Plagiarism Check Using EfficientNet-Based Deep Neural Network with Triplet Semi-Hard Loss. Appl. Sci. 2023, 13, 3072. https://doi.org/10.3390/app13053072
Prihatno AT, Suryanto N, Oh S, Le T-T-H, Kim H. NFT Image Plagiarism Check Using EfficientNet-Based Deep Neural Network with Triplet Semi-Hard Loss. Applied Sciences. 2023; 13(5):3072. https://doi.org/10.3390/app13053072
Chicago/Turabian StylePrihatno, Aji Teguh, Naufal Suryanto, Sangbong Oh, Thi-Thu-Huong Le, and Howon Kim. 2023. "NFT Image Plagiarism Check Using EfficientNet-Based Deep Neural Network with Triplet Semi-Hard Loss" Applied Sciences 13, no. 5: 3072. https://doi.org/10.3390/app13053072