
Stochastic Weight Averaging Revisited

Abstract
:1. Introduction
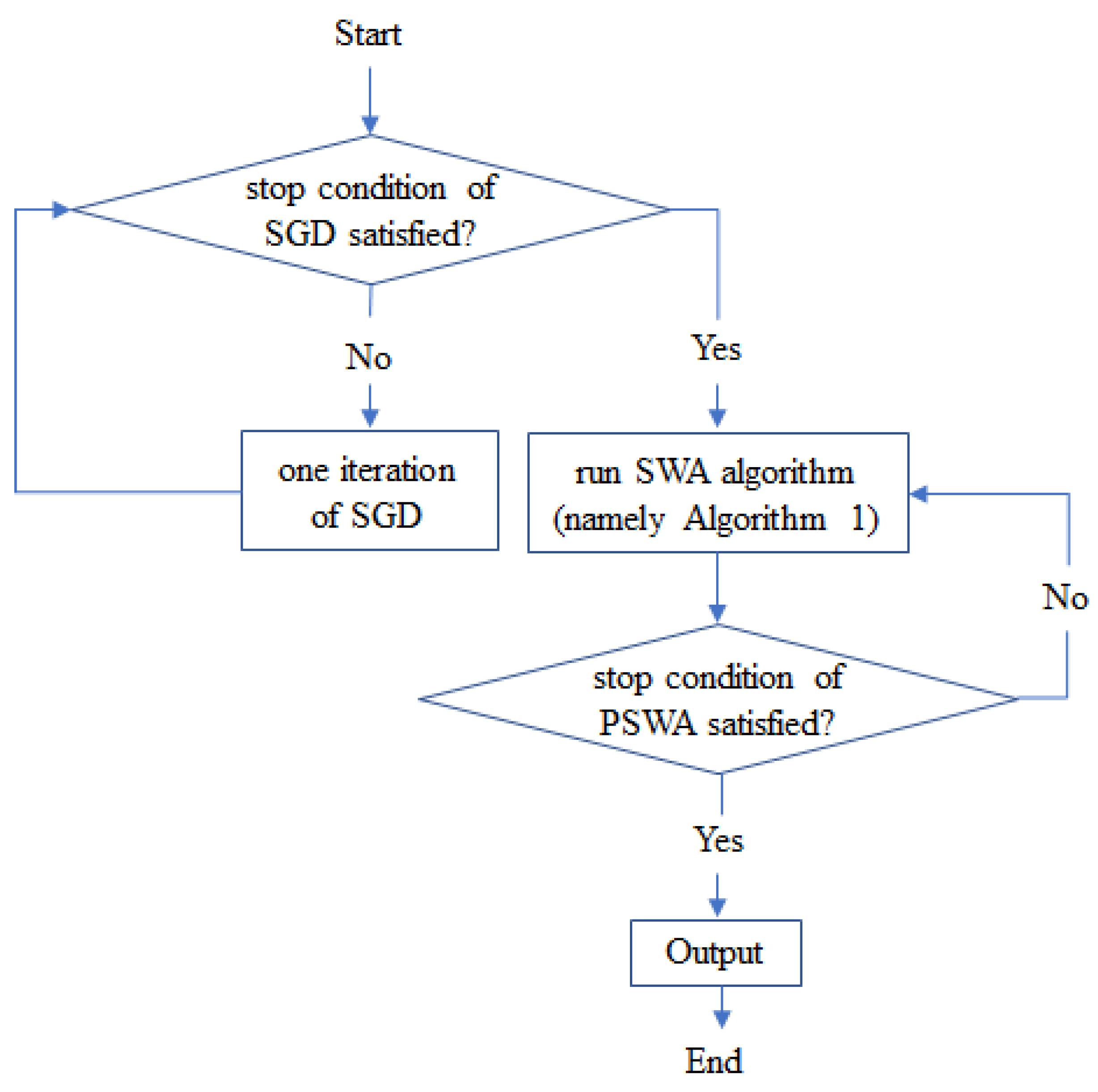
| Algorithm 1 Stochastic Weight Averaging (SWA) |
Input: weights , learning-rate schedule, cycle length c, number of iterations n Output:
|
1.1. Limitations
- If we did not use the momentum technique in its backbone SGD, how would SWA behave?
- If the SGD that processed before SWA could not converge or converged to a bad optimum, could SWA still work?
- What was the actual function of the weight-averaging operation in SWA, either variance reduction, the identification of a wider optimum, or both?
1.2. Contributions
- We disentangled the contributions of the weight-averaging operation, the CHC learning-rate schedule, the application of momentum and weight decaying, and the rate at which the preceding SGD converged, to the behavior of SWA.
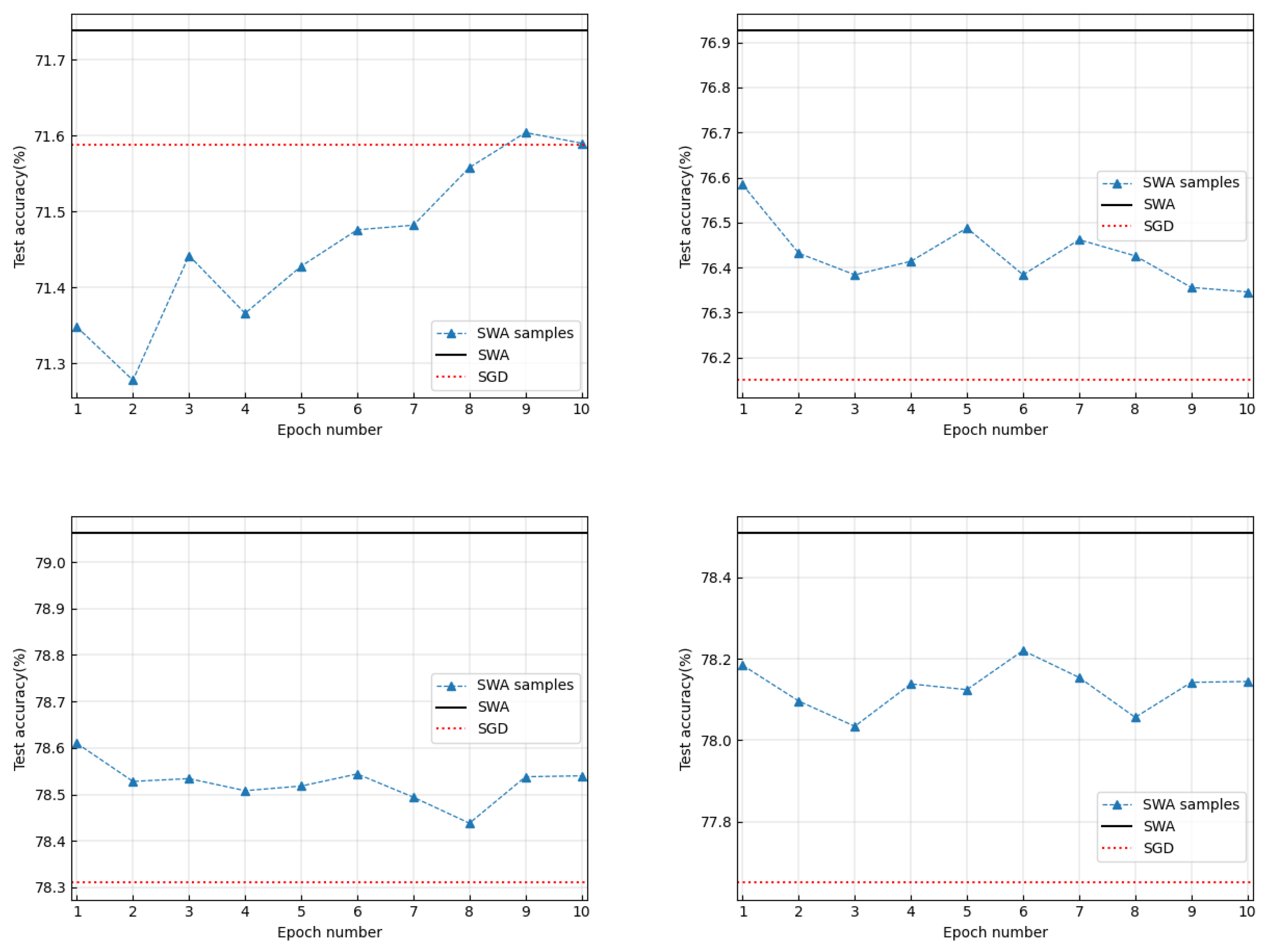
- We found that the actual function of the weight-averaging operation in SWA was variance reduction, similar to tail-averaging [1].
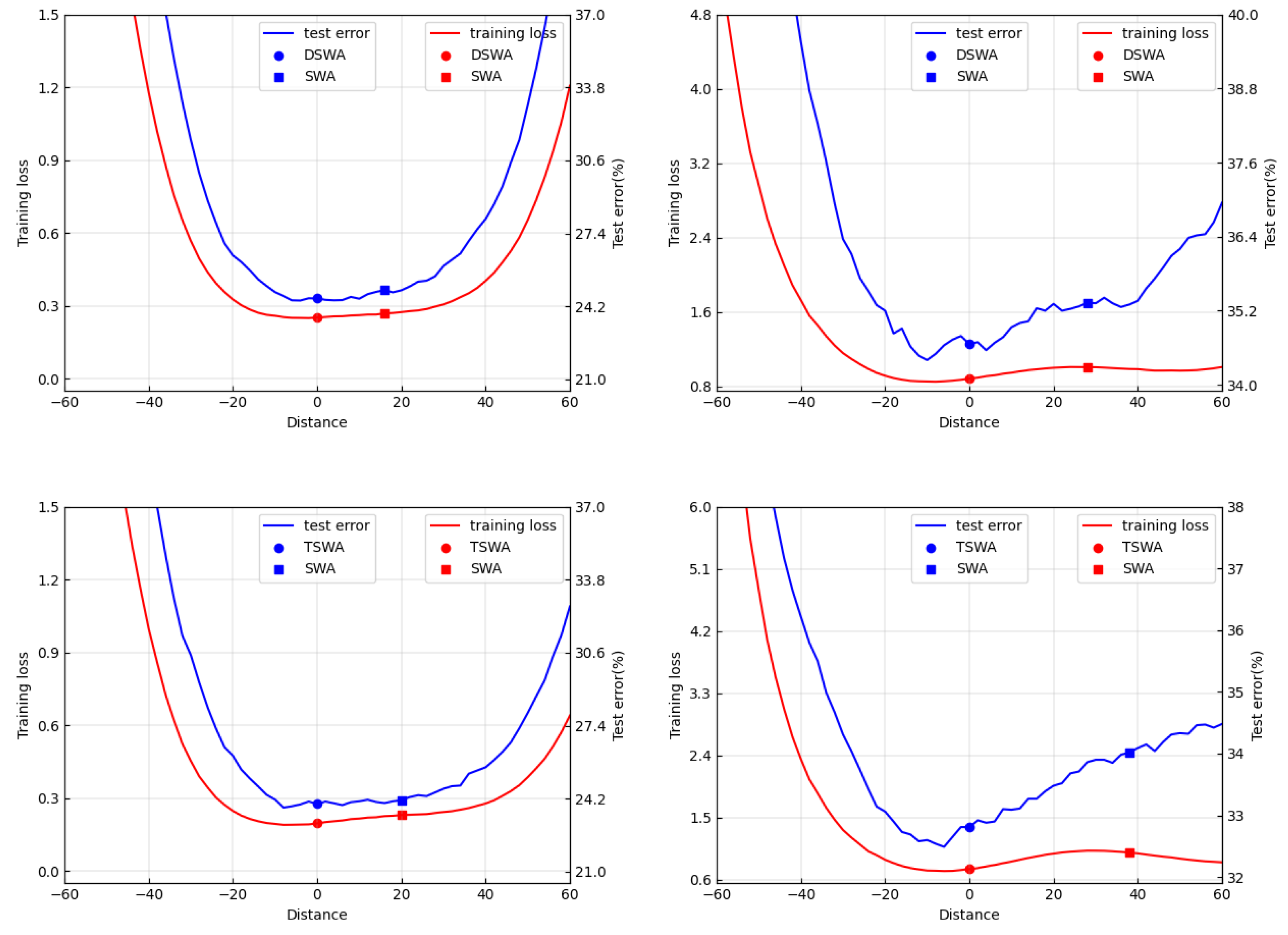
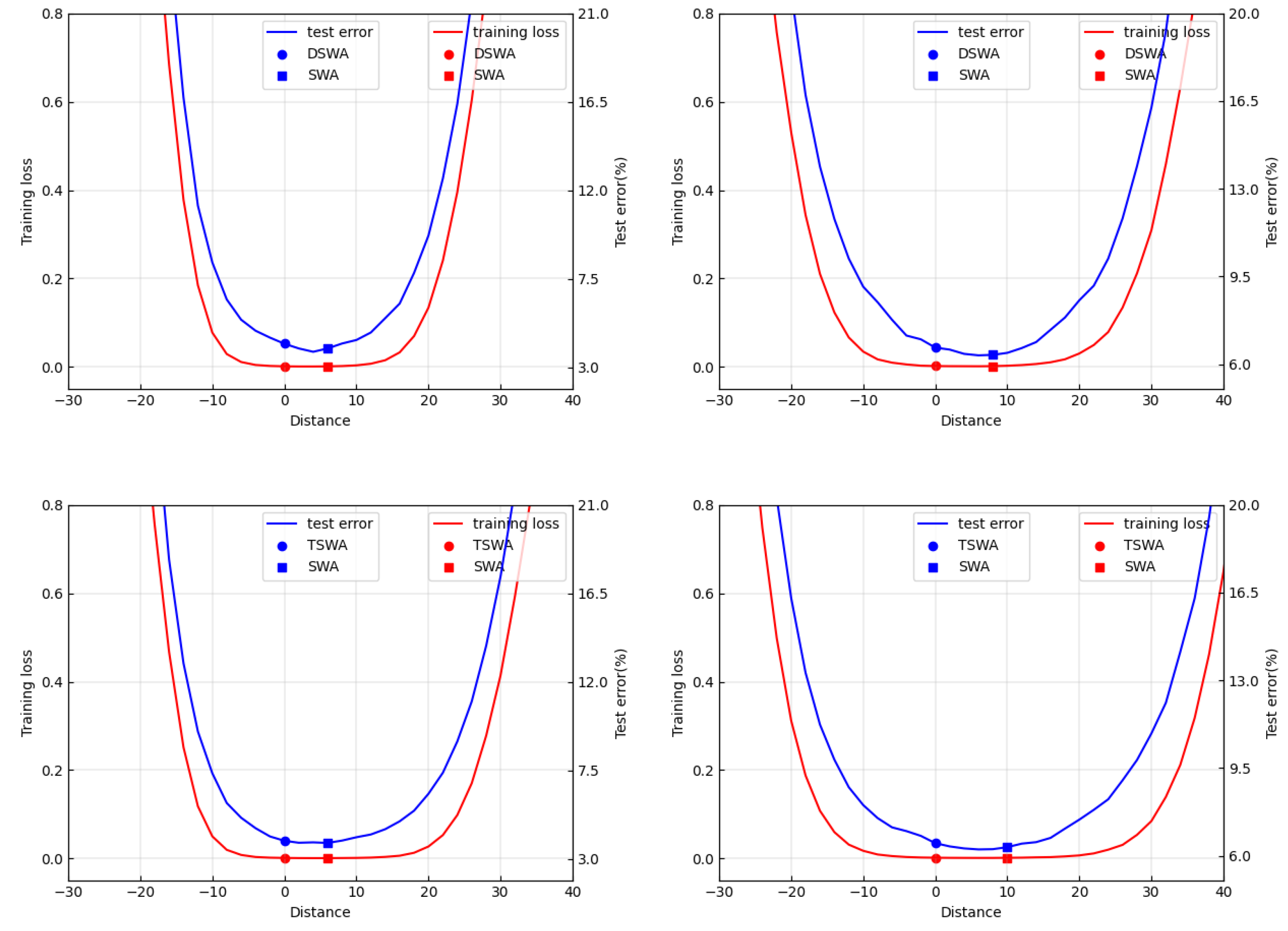
- We found cases in which SWA failed to discover better optima than its backbone SGD.
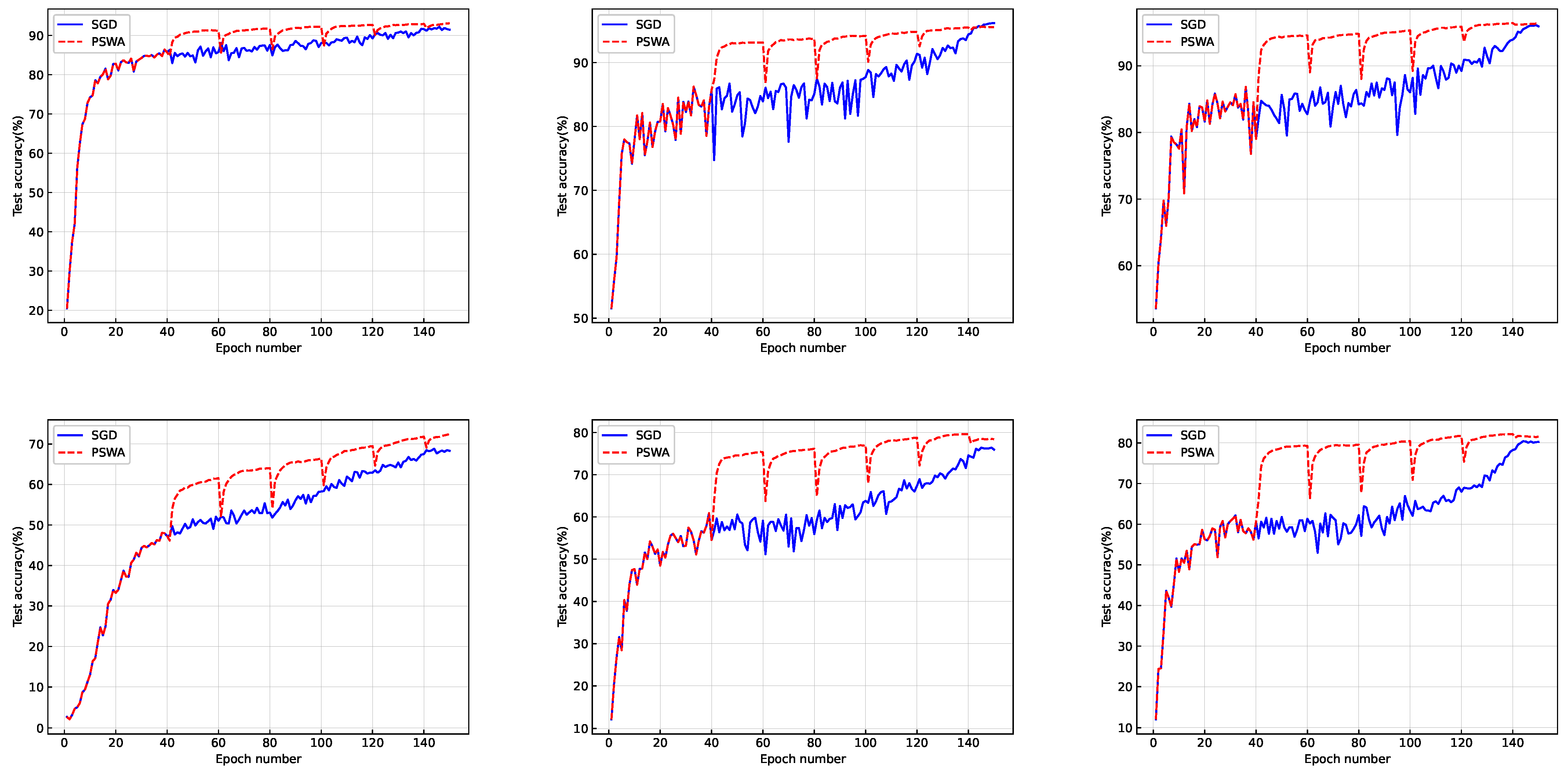
- We found that SWA explored the parameter space more widely than its backbone SGD algorithm, which could be under-fitted due to a lack in the training budget. Inspired by this finding, we proposed a novel algorithm design, termed periodic SWA (PSWA), and demonstrated that it was preferable to SGD when the training budget was limited to the point it could not support the convergence of SGD.
2. Related Work
2.1. Iterate Averaging
2.2. Cyclical Learning Rates
2.3. Convergence Theory
2.4. Loss Landscape Study & Sharpness-Aware Minimization
2.5. Application Scenarios
3. Main Results
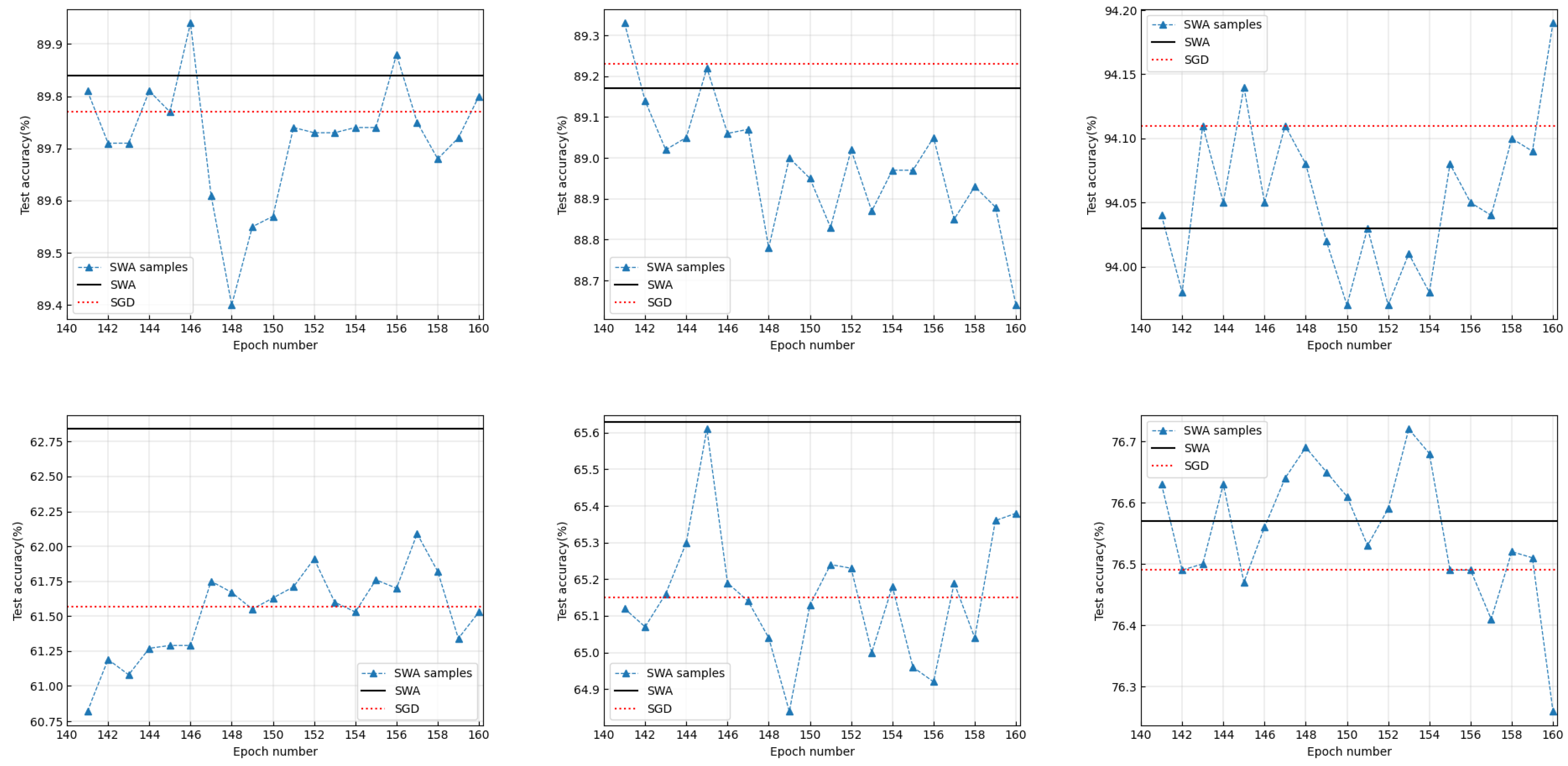
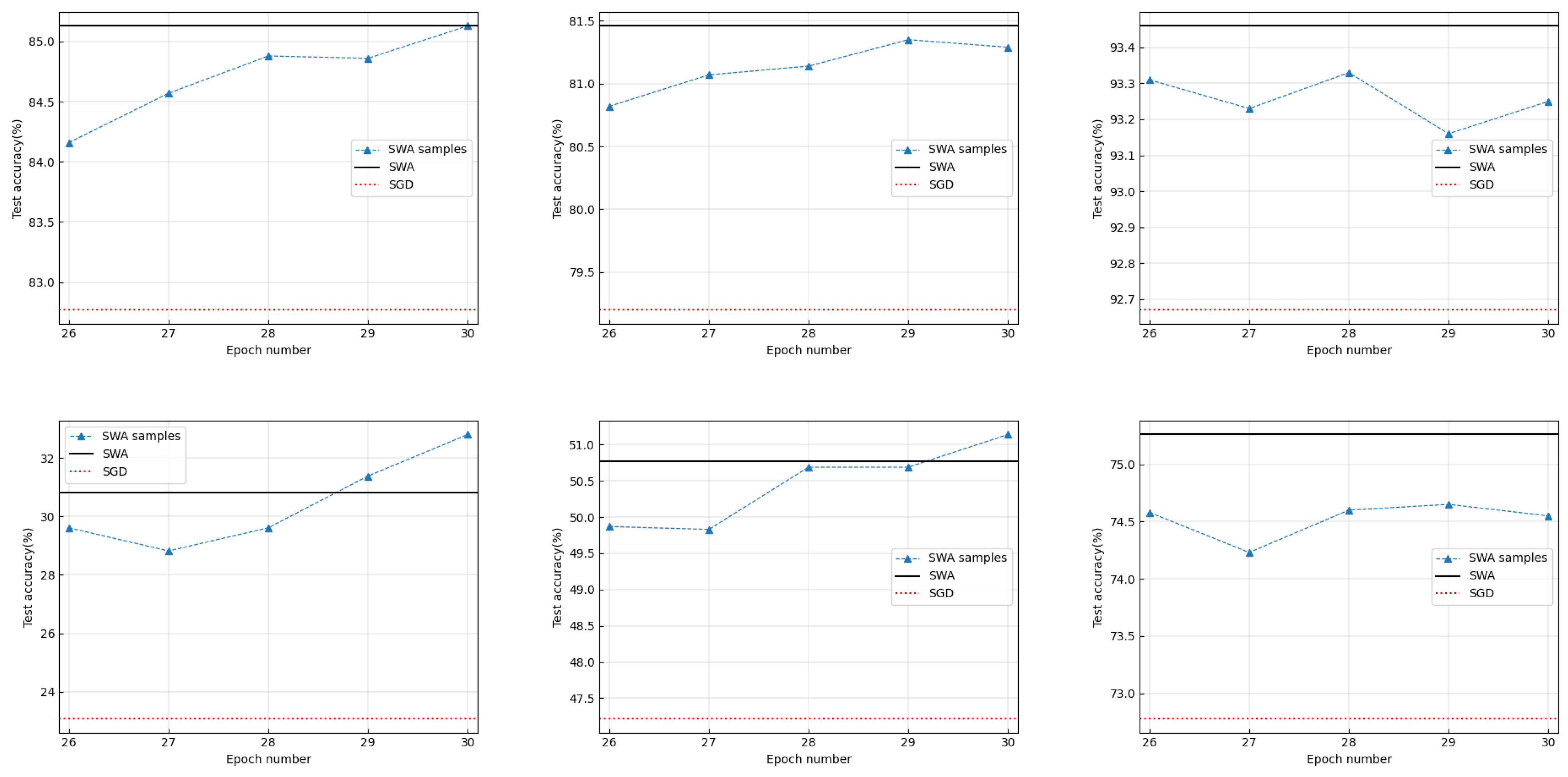
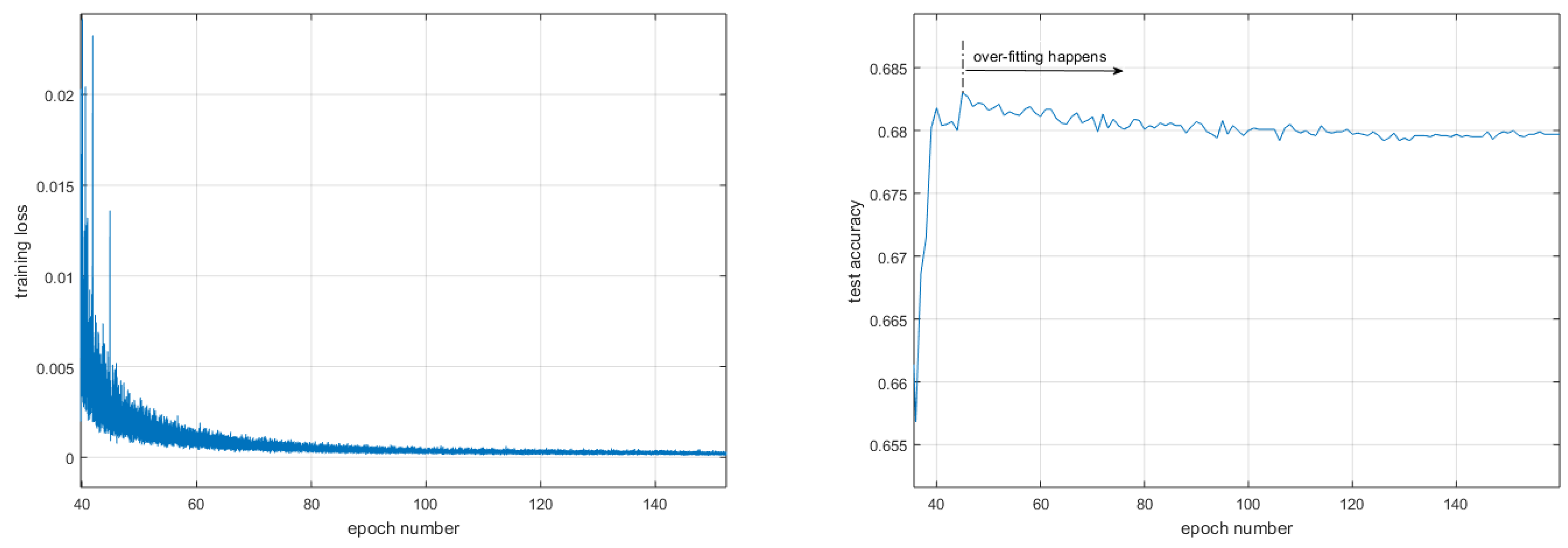
3.1. Does SWA Always Identify Wider Optima Than SGD?
3.2. What Is the Real Function of the Weight-Averaging Operations in SWA?
4. Periodic SWA
4.1. On the Global Geometric Structure of the DNN Loss Landscape
| Algorithm 2 Double Stochastic Weight Averaging (DSWA) |
Input: weights , learning-rate schedule, cycle length c, number of iterations n (assumed to be multiples of 2) Output:
|
| Algorithm 3 Triple Stochastic Weight Averaging (TSWA) |
Input: weights , learning-rate schedule, cycle length c, number of iterations n (assumed to be multiples of 3) Output:
|
4.2. On the Performance of PSWA
4.3. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Experimental Settings and More Experimental Results
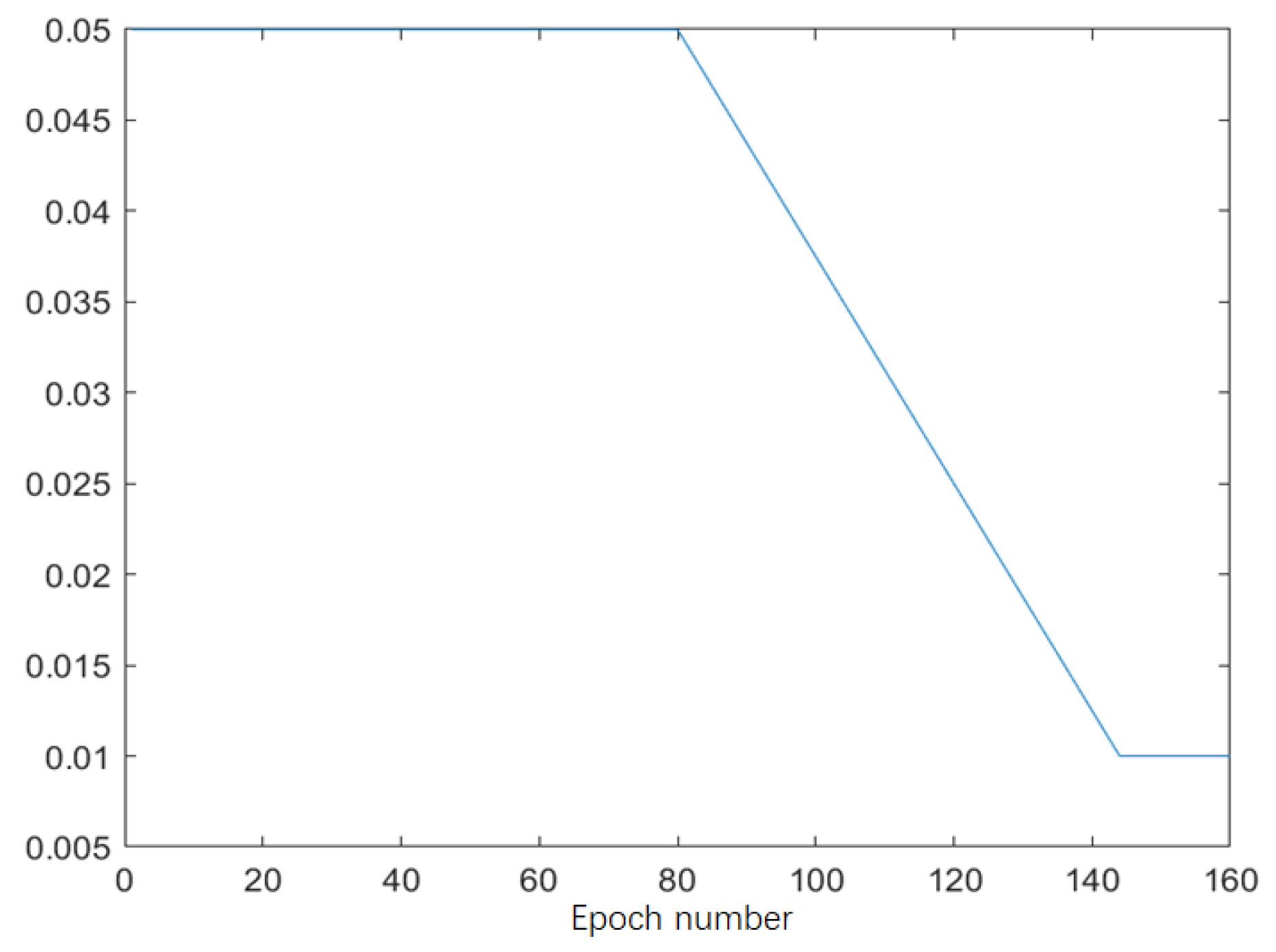
Appendix A.1. Experimental Setting
Appendix A.1.1. Experimental Settings for Results Reported in Section 3.1
Appendix A.1.2. Experimental Settings for Results Reported in Section 3.2

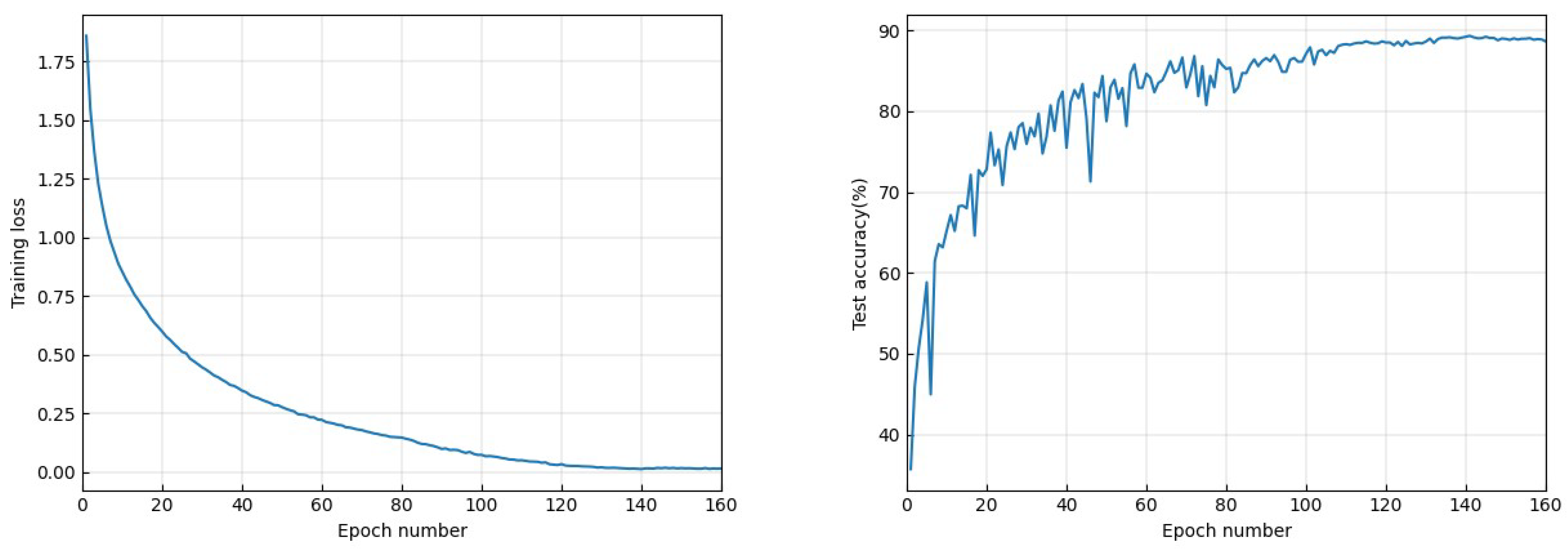
Appendix A.2. Experiment on ImageNet

Appendix A.3. Experiments with a Toy CNN Model


Appendix A.4. Experiments with Graph Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | GCN | GraphSAGE | GAT |
|---|---|---|---|
| L | 200 | 20 | 300 |
| 0.01 | 0.003 | 0.005 | |
| 180 | 15 | 270 | |
| 0.02 | 0.01 | 0.01 |
| Parameter | MinCutPool | SAGPool |
|---|---|---|
| L | 1000 | 300 |
| 0.001 | 0.003 | |
| 900 | 270 | |
| 0.01 | 0.01 |
| Parameter | MinCutPool | SAGPool |
|---|---|---|
| L | 50 | 150 |
| 0.001 | 0.003 | |
| 35 | 120 | |
| 0.01 | 0.005 |
| Parameter | MinCutPool | SAGPool |
|---|---|---|
| L | 500 | 300 |
| 0.0001 | 0.003 | |
| 450 | 270 | |
| 0.001 | 0.01 |
References
- Jain, P.; Kakade, S.; Kidambi, R.; Netrapalli, P.; Sidford, A. Parallelizing stochastic gradient descent for least squares regression: Mini-batching, averaging, and model misspecification. J. Mach. Learn. Res. 2018, 18, 1–42. [Google Scholar]
- Ruppert, D. Efficient Estimations from a Slowly Convergent Robbins-Monro Process; Technical Report; Cornell University Operations Research and Industrial Engineering: New York, NY, USA, 1988. [Google Scholar]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef] [Green Version]
- Neu, G.; Rosasco, L. Iterate averaging as regularization for stochastic gradient descent. In Proceedings of the Conference on Learning Theory, Stockholm, Sweden, 6–9 July 2018; pp. 3222–3242. [Google Scholar]
- Izmailov, P.; Podoprikhin, D.; Garipov, T.; Vetrov, D.; Wilson, A.G. Averaging weights leads to wider optima and better generalization. In Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI), Monterey, CA, USA, 6–10 August 2018; pp. 1–10. [Google Scholar]
- Cha, J.; Chun, S.; Lee, K.; Cho, H.C.; Park, S.; Lee, Y.; Park, S. SWAD: Domain generalization by seeking flat minima. In Proceedings of the Thirty-fifth Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Hwang, J.W.; Lee, Y.; Oh, S.; Bae, Y. Adversarial Training with Stochastic Weight Average. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 814–818. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On large-batch training for deep learning: Generalization gap and sharp minima. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Garipov, T.; Izmailov, P.; Podoprikhin, D.; Vetrov, D.; Wilson, A.G. Loss surfaces, mode connectivity, and fast ensembling of dnns. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 8803–8812. [Google Scholar]
- Huang, G.; Li, Y.; Pleiss, G.; Liu, Z.; Hopcroft, J.E.; Weinberger, K.Q. Snapshot ensembles: Train 1, get M for free. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Smith, L.N.; Topin, N. Super-convergence: Very fast training of neural networks using large learning rates. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, Baltimore, MD, USA, 14–18 April 2019; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2019; Volume 11006, p. 1100612. [Google Scholar]
- Smith, L.N.; Topin, N. Exploring loss function topology with cyclical learning rates. arXiv 2017, arXiv:1702.04283. [Google Scholar]
- Ghorbani, B.; Krishnan, S.; Xiao, Y. An investigation into neural net optimization via hessian eigenvalue density. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2232–2241. [Google Scholar]
- Sagun, L.; Evci, U.; Guney, V.U.; Dauphin, Y.; Bottou, L. Empirical analysis of the hessian of over-parametrized neural networks. arXiv 2017, arXiv:1706.04454. [Google Scholar]
- Yao, Z.; Gholami, A.; Keutzer, K.; Mahoney, M.W. Pyhessian: Neural networks through the lens of the hessian. In Proceedings of the IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 581–590. [Google Scholar]
- Yang, Y.; Hodgkinson, L.; Theisen, R.; Zou, J.; Gonzalez, J.E.; Ramchandran, K.; Mahoney, M.W. Taxonomizing local versus global structure in neural network loss landscapes. In Proceedings of the Thirty-fifth Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34. [Google Scholar]
- Kleiner, A.; Neyshabur, B.; Mobahi, H.; Foret, P. Sharpness-aware Minimization for Efficiently Improving Generalization. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Allen-Zhu, Z.; Li, Y.; Song, Z. A convergence theory for deep learning via over-parameterization. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 242–252. [Google Scholar]
- Cheridito, P.; Jentzen, A.; Rossmannek, F. Non-convergence of stochastic gradient descent in the training of deep neural networks. J. Complex. 2021, 64, 101540. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 7370–7377. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 2017 Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Bianchi, F.M.; Grattarola, D.; Alippi, C. Spectral clustering with graph neural networks for graph pooling. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 874–883. [Google Scholar]
- Lee, J.; Lee, I.; Kang, J. Self-attention graph pooling. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 3734–3743. [Google Scholar]
- Kaddour, J.; Liu, L.; Silva, R.; Kusner, M.J. When Do Flat Minima Optimizers Work? arXiv 2022, arXiv:2202.00661. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]






| Statistical Insight | Geometric Insight | Algorithm | |
|---|---|---|---|
| IA | √ | × | √ |
| CLR [9,10] | × | × | √ |
| Ensemble [11,12,13,14] | × | √ | √ |
| LL [6,8,15,16,17,18,19] | × | √ | √ |
| this work | √ | √ | √ |
| Cora | Citeseer | Pubmed | ||||
|---|---|---|---|---|---|---|
| Adam | SWA | Adam | SWA | Adam | SWA | |
| GCN | 81.2 | 81.3 | 70.5 | 70.8 | 79.5 | 79.6 |
| GraphSAGE | 80.2 | 79.3 | 69.8 | 69.7 | 77.8 | 77.7 |
| GAT | 81.6 | 81.7 | 70.6 | 70.4 | 76.1 | 76.2 |
| NCI1 | D&D | PROTEINS | ||||
|---|---|---|---|---|---|---|
| Adam | SWA | Adam | SWA | Adam | SWA | |
| MinCutPool | 74.78 | 75.25 | 79.67 | 80.86 | 76.44 | 77.34 |
| SAGPool | 71.63 | 72.57 | 71.89 | 70.87 | 77.73 | 78.37 |
| SGD | SWA | DSWA |
|---|---|---|
| 57.10 | 67.27 | 69.49 |
| VGG16 | PreResNet-164 | WideResNet-28-10 | |
|---|---|---|---|
| SGD | 55.28 | 70.55 | 76.30 |
| SWA | 65.89 | 76.45 | 80.95 |
| DSWA | 68.44 | 77.26 | 81.18 |
| TSWA | 68.68 | 77.33 | 81.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Jin, J.; Liu, B. Stochastic Weight Averaging Revisited. Appl. Sci. 2023, 13, 2935. https://doi.org/10.3390/app13052935
Guo H, Jin J, Liu B. Stochastic Weight Averaging Revisited. Applied Sciences. 2023; 13(5):2935. https://doi.org/10.3390/app13052935
Chicago/Turabian StyleGuo, Hao, Jiyong Jin, and Bin Liu. 2023. "Stochastic Weight Averaging Revisited" Applied Sciences 13, no. 5: 2935. https://doi.org/10.3390/app13052935