
Research on Crack Width Measurement Based on Binocular Vision and Improved DeeplabV3+

Abstract
:1. Introduction
2. Crack Region Segmentation Algorithm
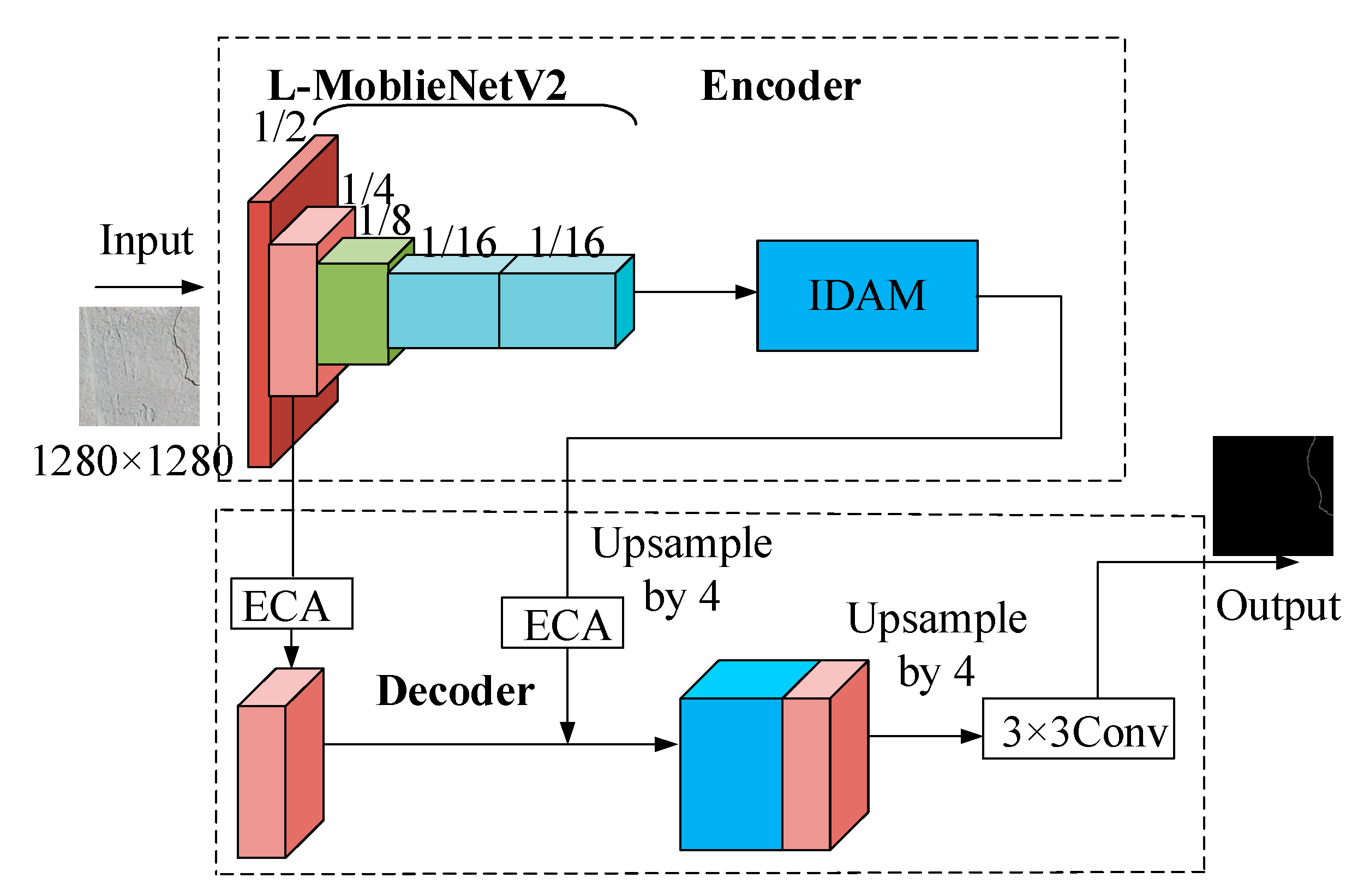
2.1. Improved DeeplabV3+ Algorithm
- (1)
- Modify the Xception feature extraction network to the L-MobileNetV2 network structure.
- (2)
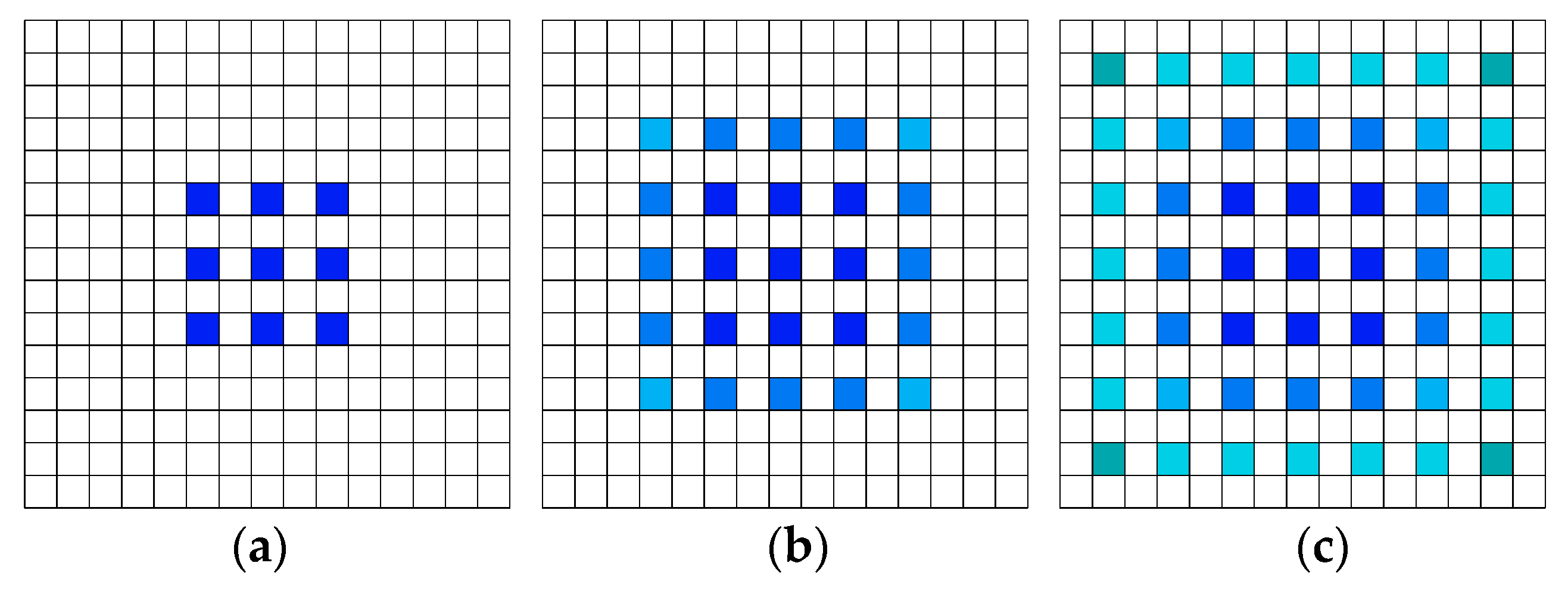
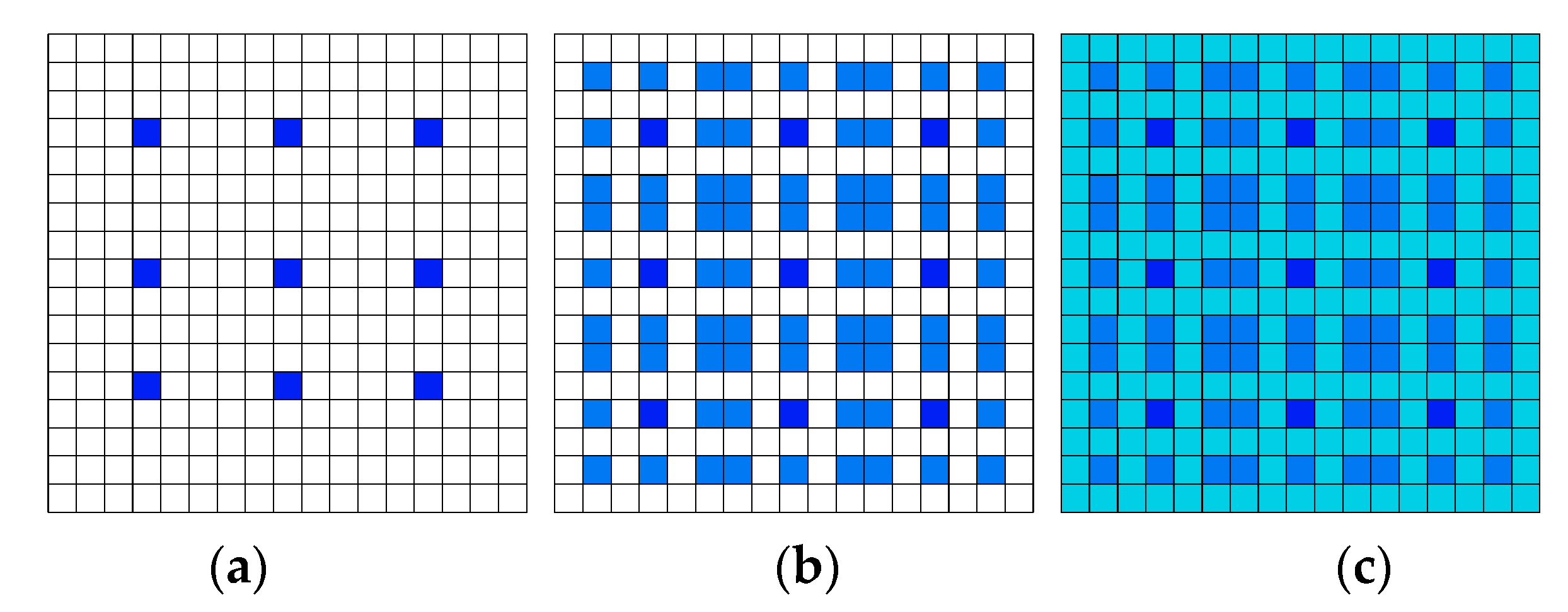
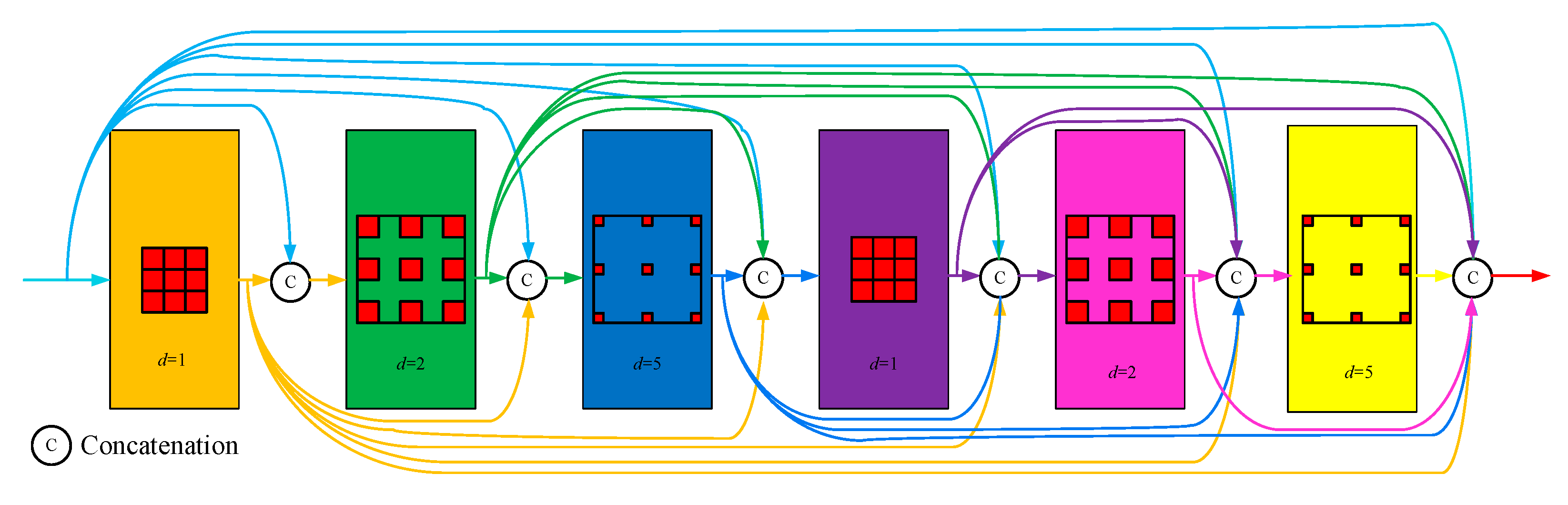
- According to the HDC (Hybrid Dilated Convolution) strategy, an improved DenseASPP module (IDAM) is designed to replace the ASPP (Atrous Spatial Pyramid Pooling) structure in the original model.
- (3)
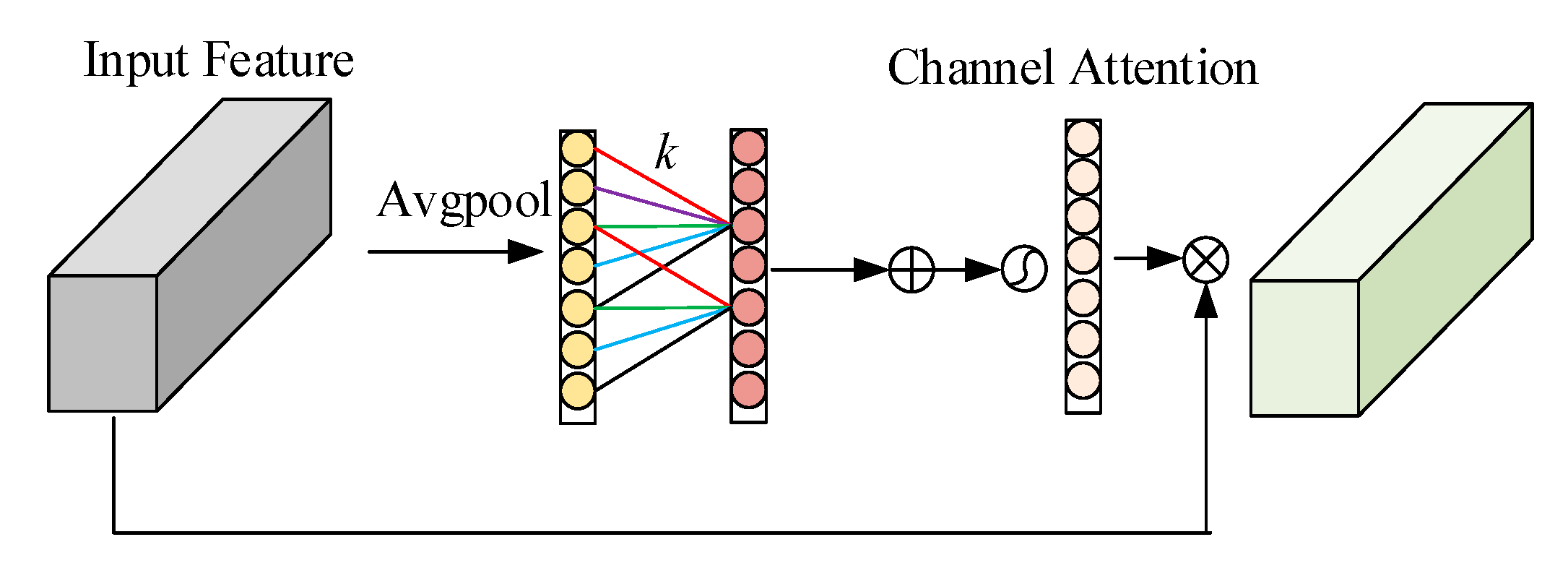
- ECA (Efficient Channel Attention) mechanism is introduced to modulate the weight of channel information before splicing 1/4 shallow feature layers and 1/16 deep semantic information.
- (4)
- Introducing Focal loss and Dice loss functions to optimize the loss function.
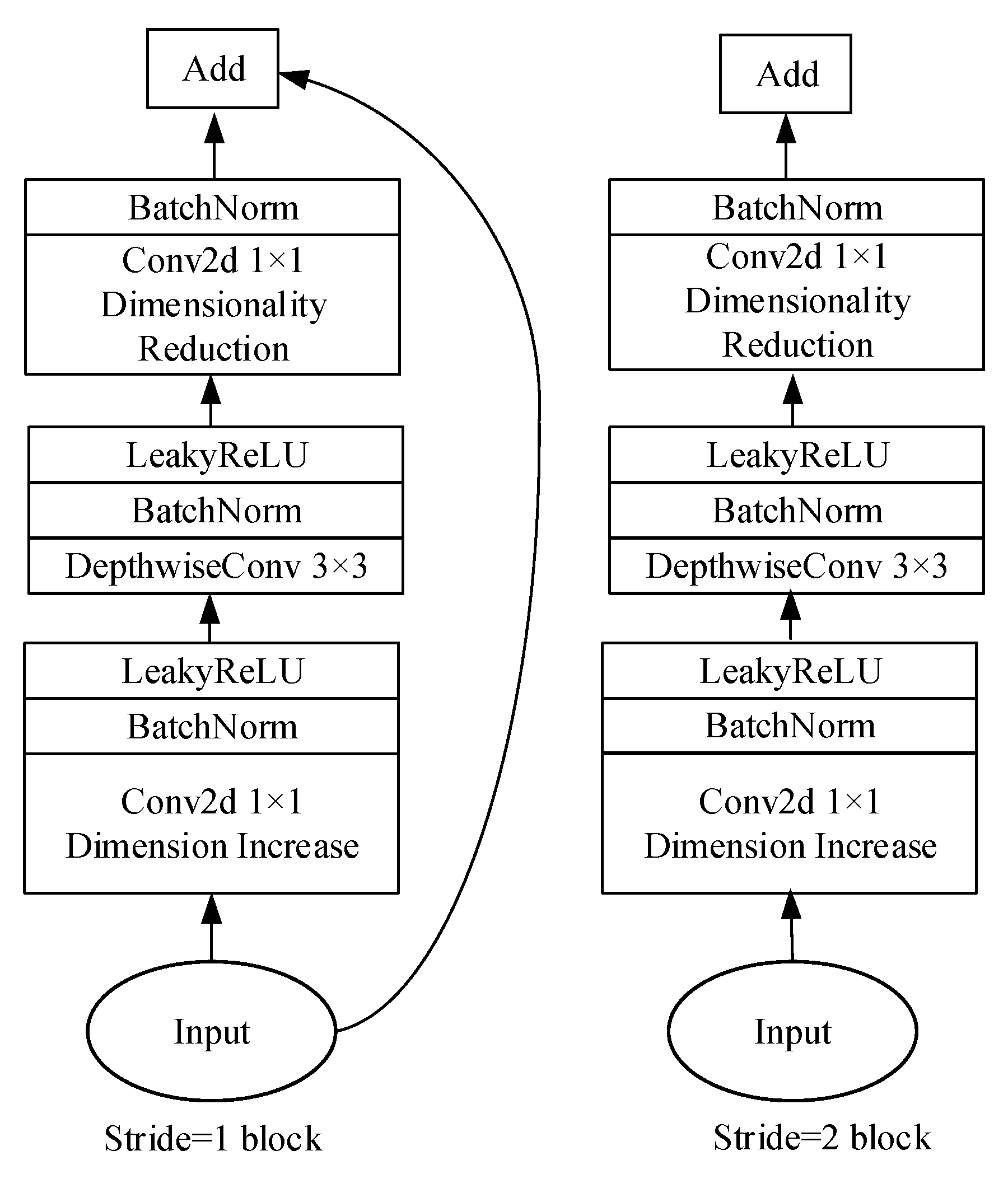
2.2. L-MobileNetV2
2.3. IDAM
2.4. ECA Attention Mechanism
2.5. Loss Function Modification
3. Visual Method for Measuring Crack Width in Concrete
3.1. Binocular Vision Spatial Coordinate Acquisition Algorithm
3.2. Crack Parameter Acquisition Algorithm
3.3. Measurement Process of Crack Parameters
4. Experiment and Analysis
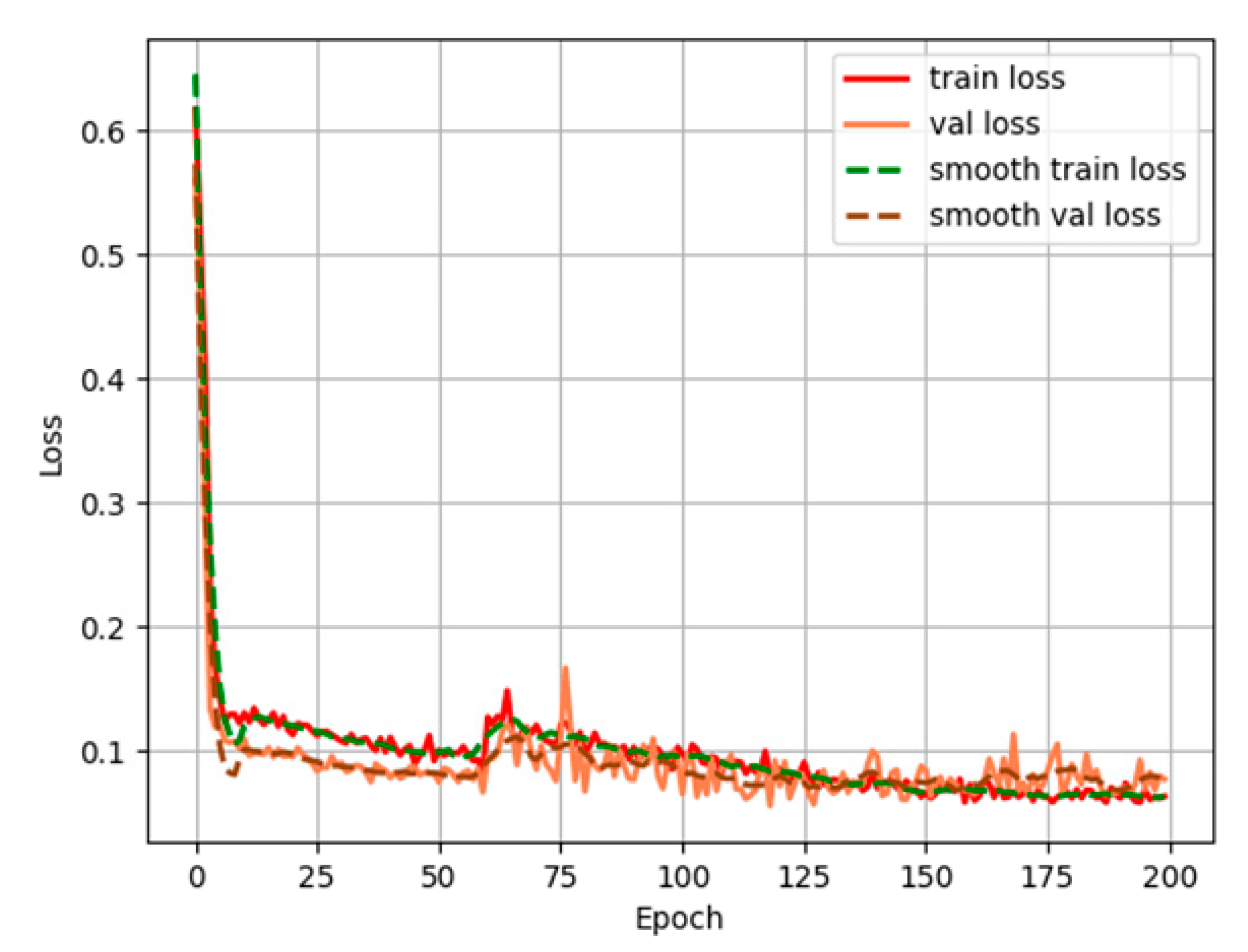
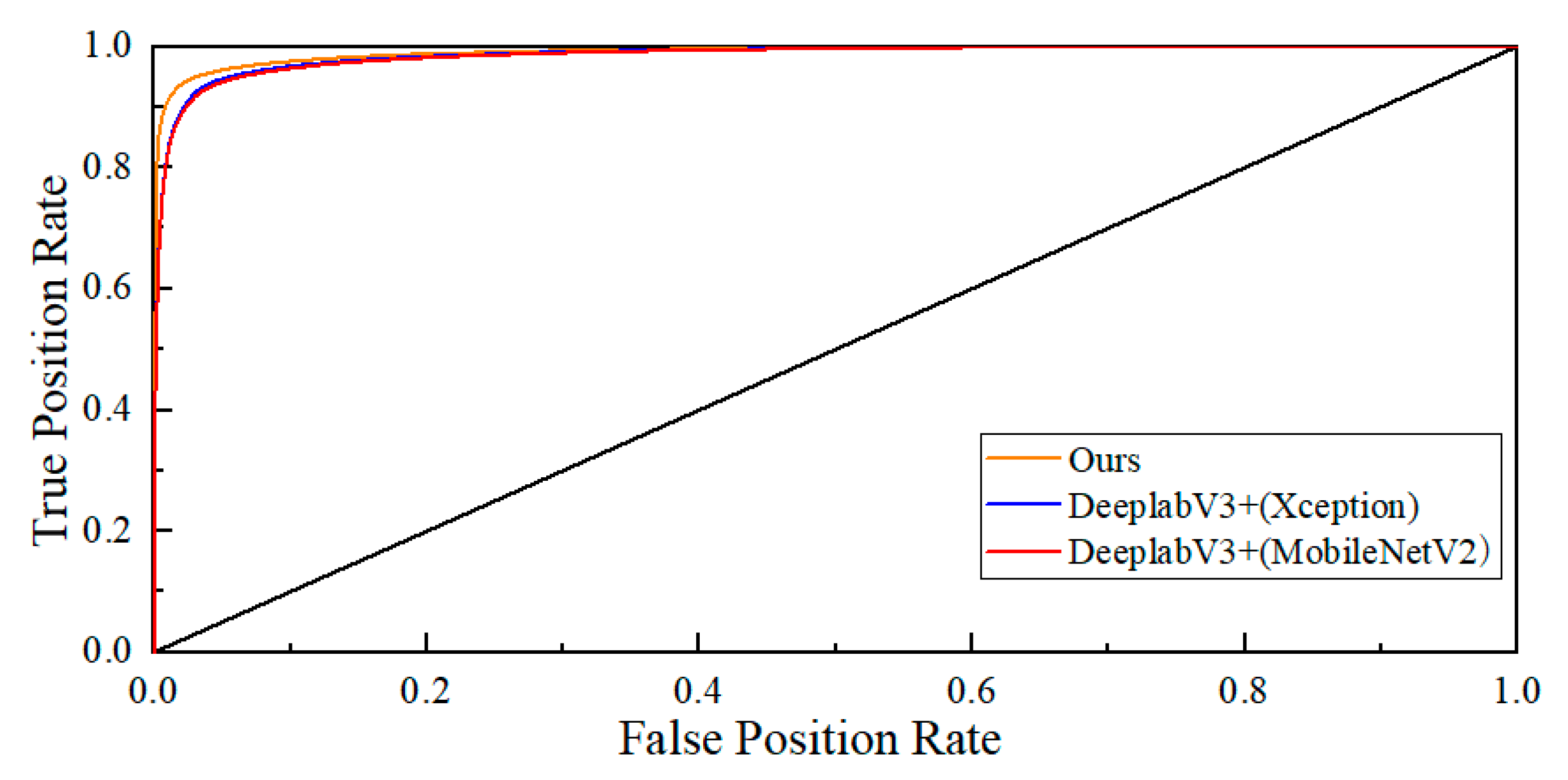
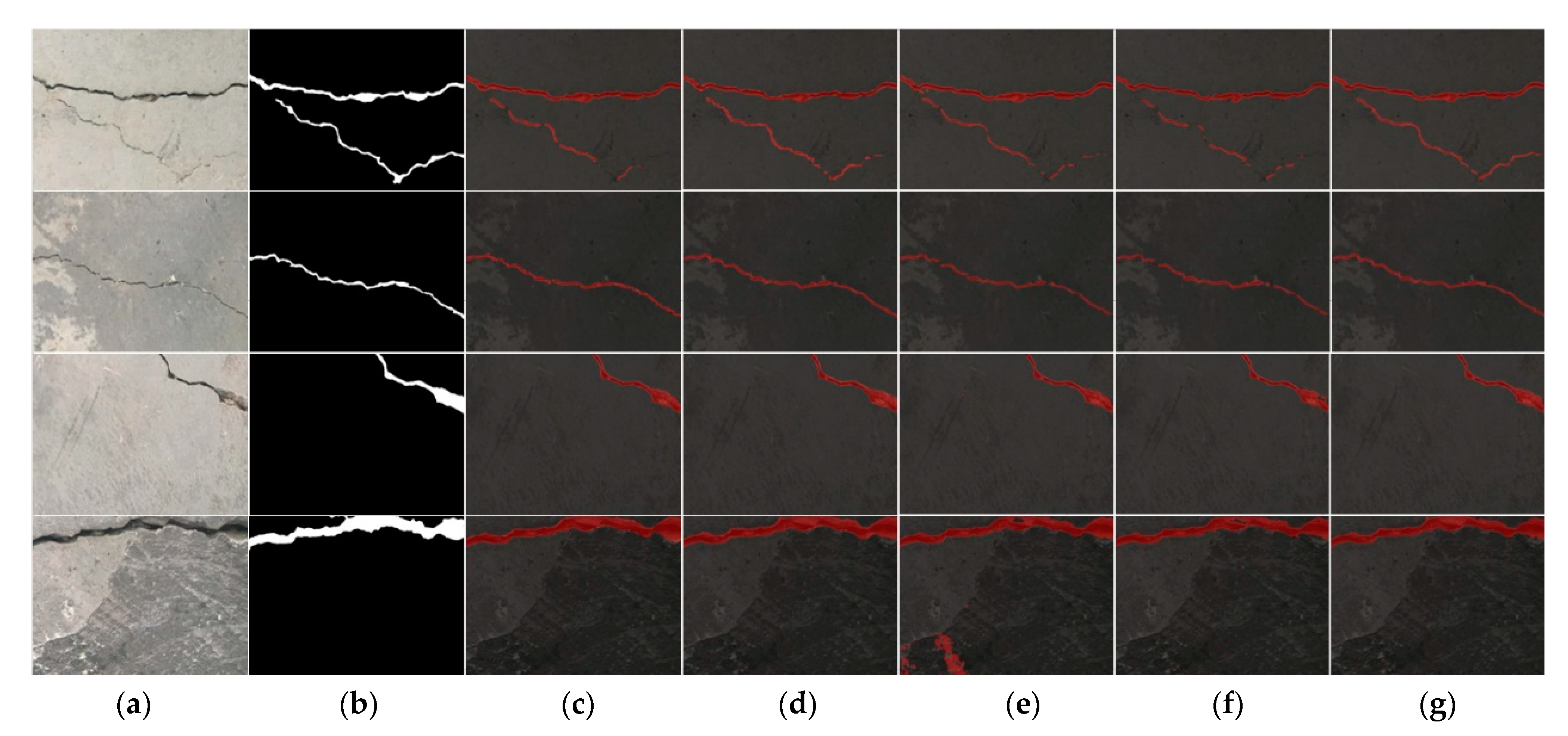
4.1. Improved DeeplabV3+ Algorithm Verification Experiment
4.2. Crack Measurement Experiment
5. Conclusions
- (1)
- The improved DeeplabV3+ model using the L-MobileNetV2 backbone network, IDAM module, ECA attention mechanism, and modified loss function can segment the crack area in the image more accurately than the current mainstream segmentation models. The MIoU, MPA, and PA of the model are 92.26%, 95.54%, and 99.45%, respectively.
- (2)
- Experimental results show that the method proposed in this paper has good measurement accuracy on the surface of the concrete structure. The error value of crack width measurement is less than 0.2 mm, and the error rate is less than 4%. Changing the angle between the camera optical axis and the concrete plane to measure the crack under 90 degrees to 10 degrees, it is found that the measured crack width RMSE increases with the decrease of the angle, but is not higher than 0.2 mm.
- (3)
- The proposed method is easy to deploy and improves crack detection efficiency. In the future, it can be integrated into a mobile automation platform to replace manual work and realize the regular detection of cracks on concrete pavements, bridges, and other surfaces. At the same time, without changing the resolution, the theoretical error of binocular vision measurement will increase rapidly with the increase in distance, and the current system cannot guarantee the accuracy of long-distance measurement.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Van Steen, C.; Nasser, H.; Verstrynge, E.; Wevers, M. Acoustic emission source characterisation of chloride-induced corrosion damage in reinforced concrete. Struct. Health Monit. 2022, 21, 1266–1286. [Google Scholar] [CrossRef]
- Ye, Y.; Hu, S.; Fan, X.; Lu, J. Effect of adhesive failure on measurement of concrete cracks using fiber Bragg grating sensors. Opt. Fiber Technol. 2022, 71, 102934. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, Y.; Li, Q.; Zhou, Y.; Yu, D. ROV-based binocular vision system for underwater structure crack detection and width measurement. Multimed. Tools Appl. 2022, 1–25. [Google Scholar] [CrossRef]
- Tang, Y.; Huang, Z.; Chen, Z.; Chen, M.; Zhou, H.; Zhang, H.; Sun, J. Novel visual crack width measurement based on backbone double-scale features for improved detection automation. Eng. Struct. 2023, 274, 115158. [Google Scholar] [CrossRef]
- Tong, Z.; Gao, J.; Han, Z.; Wang, Z. Recognition of asphalt pavement crack length using deep convolutional neural networks. Road Mater. Pavement Des. 2018, 19, 1334–1349. [Google Scholar] [CrossRef]
- Kang, D.; Benipal, S.S.; Gopal, D.L.; Cha, Y.J. Hybrid pixel-level concrete crack segmentation and quantification across complex backgrounds using deep learning. Autom. Constr. 2020, 118, 103291. [Google Scholar] [CrossRef]
- Shahrokhinasab, E.; Hosseinzadeh, N.; Monirabbasi, A.; Torkaman, S. Performance of image-based crack detection systems in concrete structures. J. Soft Comput. Civ. Eng. 2020, 4, 127–139. [Google Scholar]
- Lin, C.S.; Chen, S.H.; Chang, C.M.; Shen, T.W. Crack detection on a retaining wall with an innovative, ensemble learning method in a dynamic imaging system. Sensors 2019, 19, 4784. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.C.; Jahanshahi, M.R. NB-FCN: Real-time accurate crack detection in inspection videos using deep fully convolutional network and parametric data fusion. IEEE Trans. Instrum. Meas. 2019, 69, 5325–5334. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Wang, J.; Wang, L.; Yue, X.G. Concrete cracks detection based on FCN with dilated convolution. Appl. Sci. 2019, 9, 2686. [Google Scholar] [CrossRef] [Green Version]
- Dung, C.V. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Lau, S.L.; Chong, E.K.; Yang, X.; Wang, X. Automated pavement crack segmentation using u-net-based convolutional neural network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Hsieh, Y.A.; Tsai, Y.J. Machine learning for crack detection: Review and model performance comparison. J. Comput. Civ. Eng. 2020, 34, 04020038. [Google Scholar] [CrossRef]
- Su, H.; Wang, X.; Han, T.; Wang, Z.; Zhao, Z.; Zhang, P. Research on a U-Net Bridge Crack Identification and Feature-Calculation Methods Based on a CBAM Attention Mechanism. Buildings 2020, 12, 1561. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Li, G.; Ma, B.; He, S.; Ren, X.; Liu, Q. Automatic tunnel crack detection based on u-net and a convolutional neural network with alternately updated clique. Sensors 2020, 20, 717. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.J.; Liu, Y.F.; Nie, X.; Mo, Y.L. Deep convolutional neural networks for semantic segmentation of cracks. Struct. Control Health Monit. 2022, 29, e2850. [Google Scholar] [CrossRef]
- Sun, X.; Xie, Y.; Jiang, L.; Cao, Y.; Liu, B. DMA-Net: DeepLab With Multi-Scale Attention for Pavement Crack Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18392–18403. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, H.; Huang, M. A deep learning-based fine crack segmentation network on full-scale steel bridge images with complicated backgrounds. IEEE Access 2021, 9, 114989–114997. [Google Scholar] [CrossRef]
- Ni, F.; Zhang, J.; Chen, Z. Zernike-moment measurement of thin-crack width in images enabled by dual-scale deep learning. Comput. -Aided Civ. Infrastruct. Eng. 2019, 34, 367–384. [Google Scholar] [CrossRef]
- Ji, X.; Miao, Z.; Kromanis, R. Vision-based measurements of deformations and cracks for RC structure tests. Eng. Struct. 2020, 212, 110508. [Google Scholar] [CrossRef]
- Zhao, S.; Kang, F.; Li, J. Non-Contact Crack Visual Measurement System Combining Improved U-Net Algorithm and Canny Edge Detection Method with Laser Rangefinder and Camera. Appl. Sci. 2022, 12, 10651. [Google Scholar] [CrossRef]
- Shan, B.; Zheng, S.; Ou, J. A stereovision-based crack width detection approach for concrete surface assessment. KSCE J. Civ. Eng. 2016, 20, 803–812. [Google Scholar] [CrossRef]
- Chen, J.K.; Long, H.H.; Zhao, J.K. Research of the algorithm calculating the length of bridge crack based on stereo vision. In Proceedings of the 2017 4th International Conference on Systems and Informatics (ICSAI), Hangzhou, China, 11–13 November 2017. [Google Scholar]
- Liu, B. Long-Distance Recognition of Crack Width in Building Wall Based on Binocular Vision. In Proceedings of the 2021 3rd International Conference on Artificial Intelligence and Advanced Manufacture, New York, NY, USA, 23–25 October 2021. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE winter conference on applications of computer vision (WACV), Lake Tahoe, CA, USA, 12–15 March 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–19 June 2020. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Model | MIoU | MPA | PA | Parameter Size |
|---|---|---|---|---|
| PSPNet | 85.90% | 90.74% | 99.08% | 2.376M |
| HRNet | 84.96% | 89.91% | 98.92% | 9.637M |
| U-Net | 87.02% | 90.26% | 99.12% | 24.891M |
| DeeplabV3+(Xception) | 88.70% | 93.67% | 99.18% | 54.709M |
| DeeplabV3+(MobileNetV2) | 88.79% | 92.28% | 99.23% | 5.813M |
| Ours | 92.26% | 95.54% | 99.45% | 16.833M |
| ID | True Value/mm | Results of Method 1/mm | Error Value/mm | Rate of Error/% | Results of Method 2/mm | Error Value/mm | Rate of Error/% | Results of Method 3/mm | Error Value/mm | Rate of Error/% |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5.412 | 6.025 | +0.613 | 11.33 | 5.876 | +0.464 | 8.57 | 5.586 | +0.174 | 3.22 |
| 2 | 4.210 | 4.412 | +0.202 | 4.80 | 4.366 | +0.156 | 3.71 | 4.085 | −0.125 | 2.97 |
| 3 | 3.567 | 3.775 | +0.208 | 5.83 | 3.238 | −0.329 | 9.22 | 3.696 | +0.129 | 3.62 |
| 4 | 6.189 | 5.023 | −1.166 | 18.84 | 5.848 | −0.341 | 5.51 | 6.321 | +0.132 | 2.13 |
| ID | Measurement Error Value/mm | ||||
|---|---|---|---|---|---|
| 10° | 30° | 50° | 70° | 90° | |
| 1 | 0.205 | 0.190 | −0.188 | −0.164 | 0.174 |
| 2 | 0.198 | −0.176 | 0.171 | 0.152 | −0.125 |
| 3 | −0.210 | 0.184 | 0.165 | −0.144 | 0.129 |
| 4 | 0.182 | −0.187 | 0.126 | 0.152 | 0.132 |
| RMSE | 0.199 | 0.184 | 0.164 | 0.153 | 0.141 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Shen, P. Research on Crack Width Measurement Based on Binocular Vision and Improved DeeplabV3+. Appl. Sci. 2023, 13, 2752. https://doi.org/10.3390/app13052752
Chen C, Shen P. Research on Crack Width Measurement Based on Binocular Vision and Improved DeeplabV3+. Applied Sciences. 2023; 13(5):2752. https://doi.org/10.3390/app13052752
Chicago/Turabian StyleChen, Chaoxin, and Peng Shen. 2023. "Research on Crack Width Measurement Based on Binocular Vision and Improved DeeplabV3+" Applied Sciences 13, no. 5: 2752. https://doi.org/10.3390/app13052752