
Identifying Weak Adhesion in Single-Lap Joints Using Lamb Wave Data and Artificial Intelligence Algorithms
 , , and
, , and 
Abstract
:1. Introduction
2. Preliminary Concepts
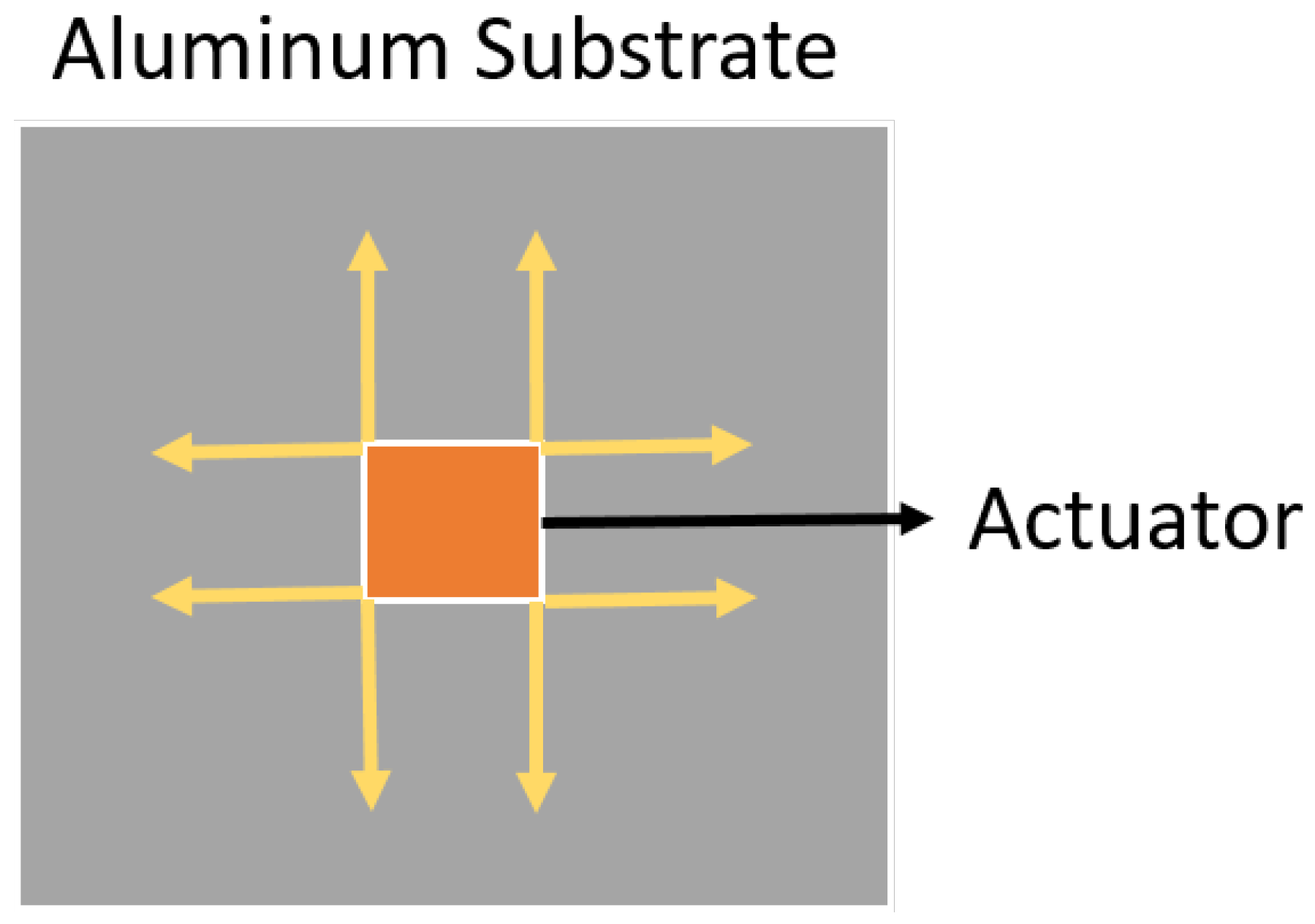
2.1. Lamb Waves
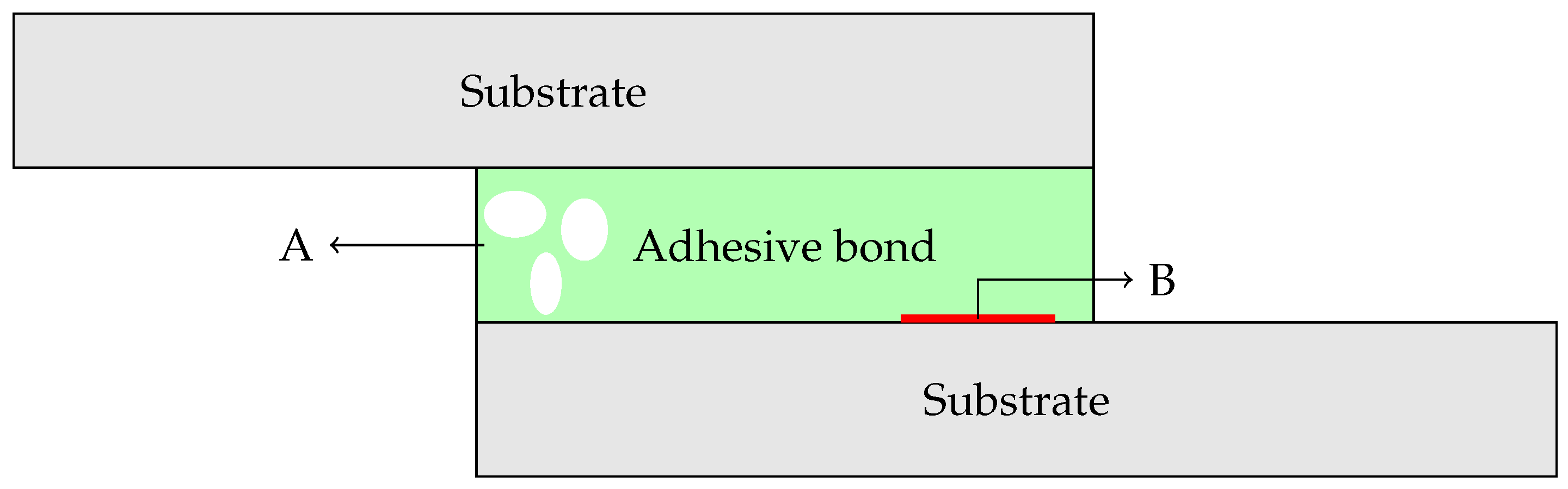
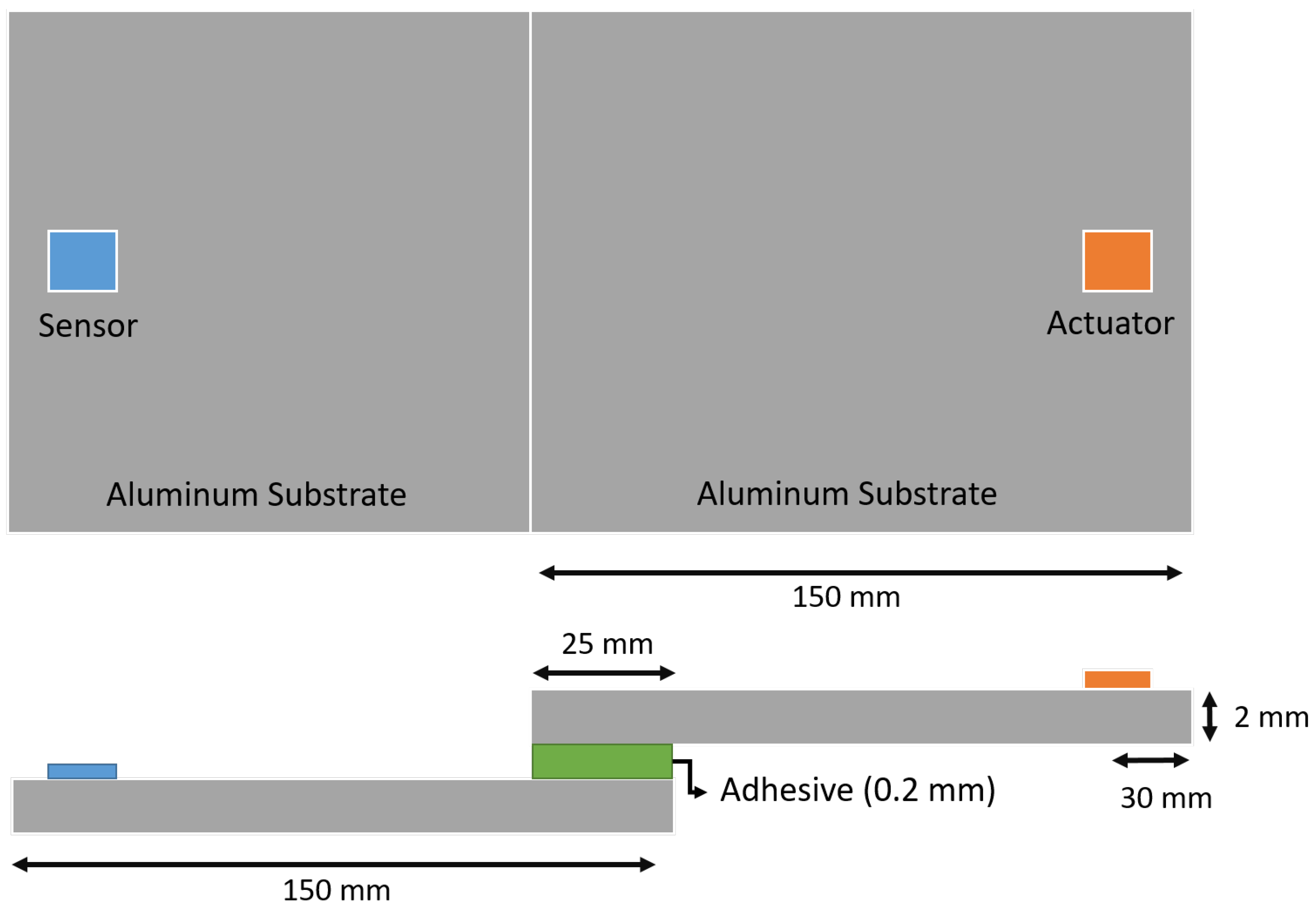
2.2. Adhesive Joints and Defects
3. Artificial Intelligence Algorithms
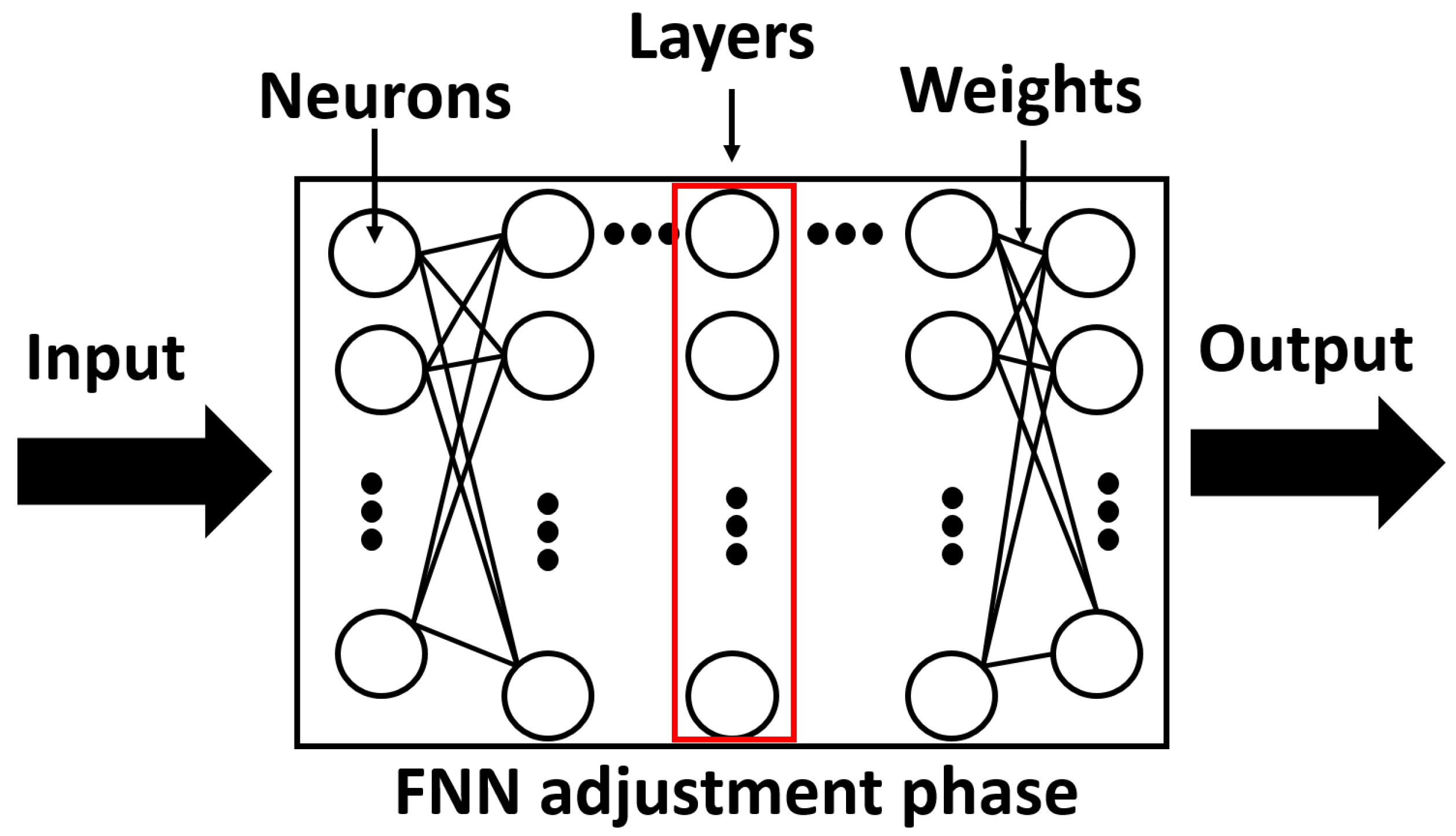
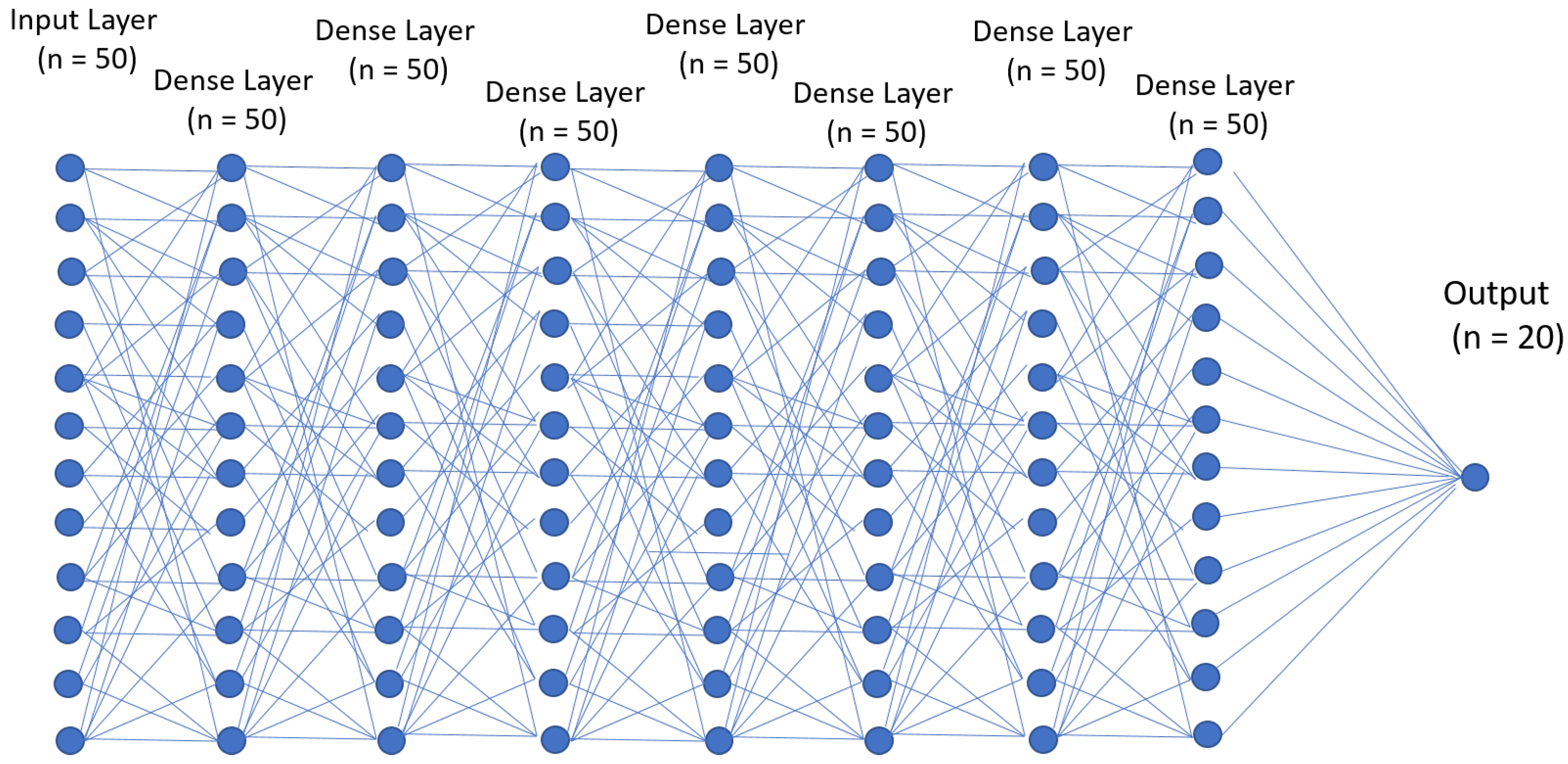
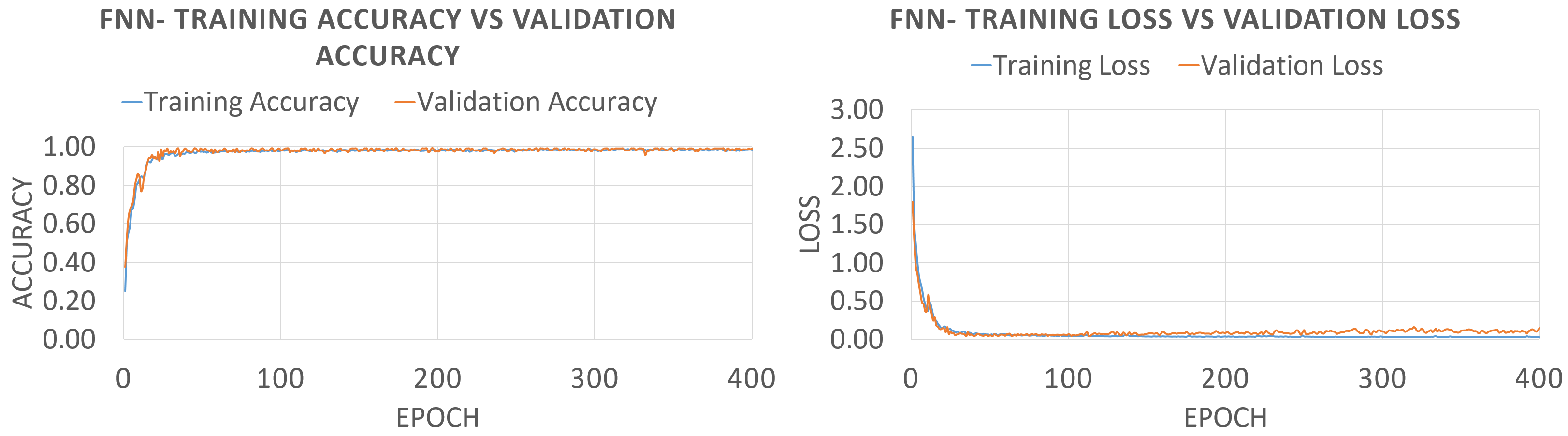
3.1. Feedforward Neural Networks
3.2. Recurrent Neural Network
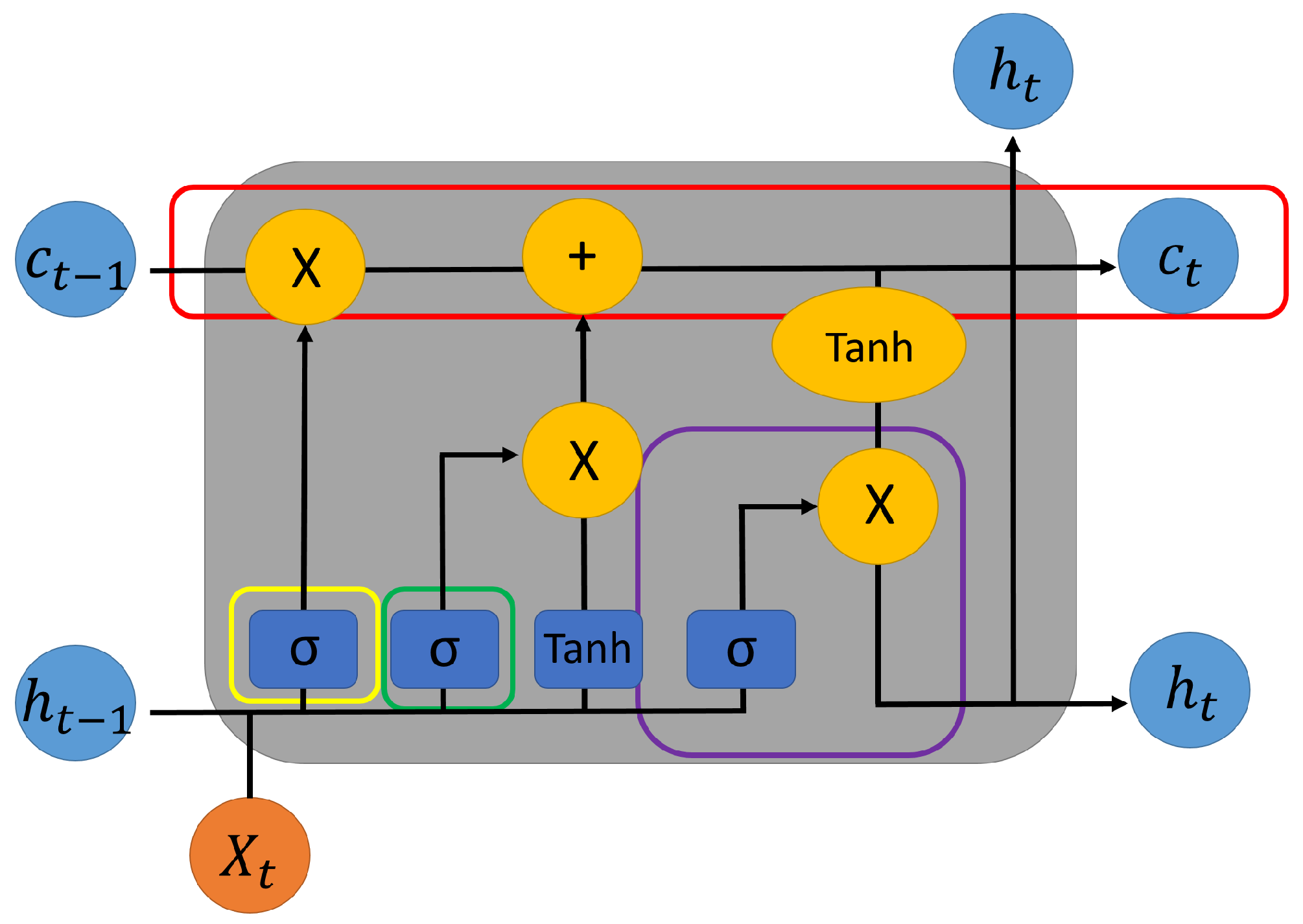
3.2.1. Long Short-Term Memory
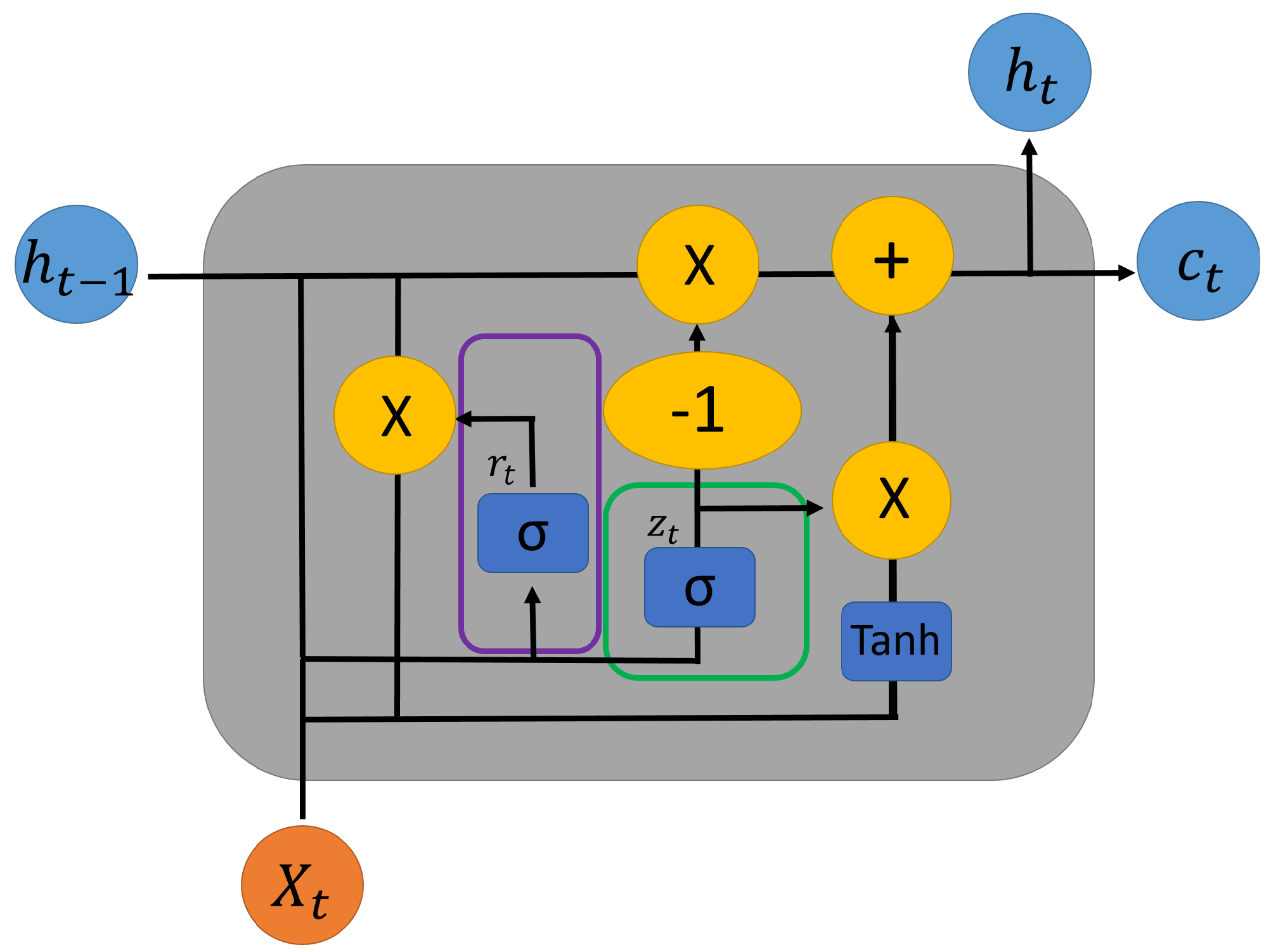
3.2.2. Gated Recurrent Unit
- The first step is an update gate, as shown in Figure 4 (circled in green color), which is used to determine how much information will be updated in the unit. This gate is denoted as and calculated by:
- The next step is a reset gate, seen in Figure 4, circled in purple, denoted as and calculated by:This gate is used to determine how much information needs to be forgotten. When the value of this gate is close to zero, it determines that the j-th information should be forgotten in the current memory. Any value close to one means that the data will be preserved.
- The third step is to determine the current memory. This gate is denoted as in the following expression and, in Figure 4, seen as .This gate also uses the Hadamard product to decide how much of the hidden state of the content should be forgotten.
- Finally, the last step is to determine the information to be stored in the hidden layer at the current iteration that will be passed onto the next cell. This step is denoted as in the following equation and, in Figure 4, is denoted as :These steps can all be easily visualized in Figure 4.
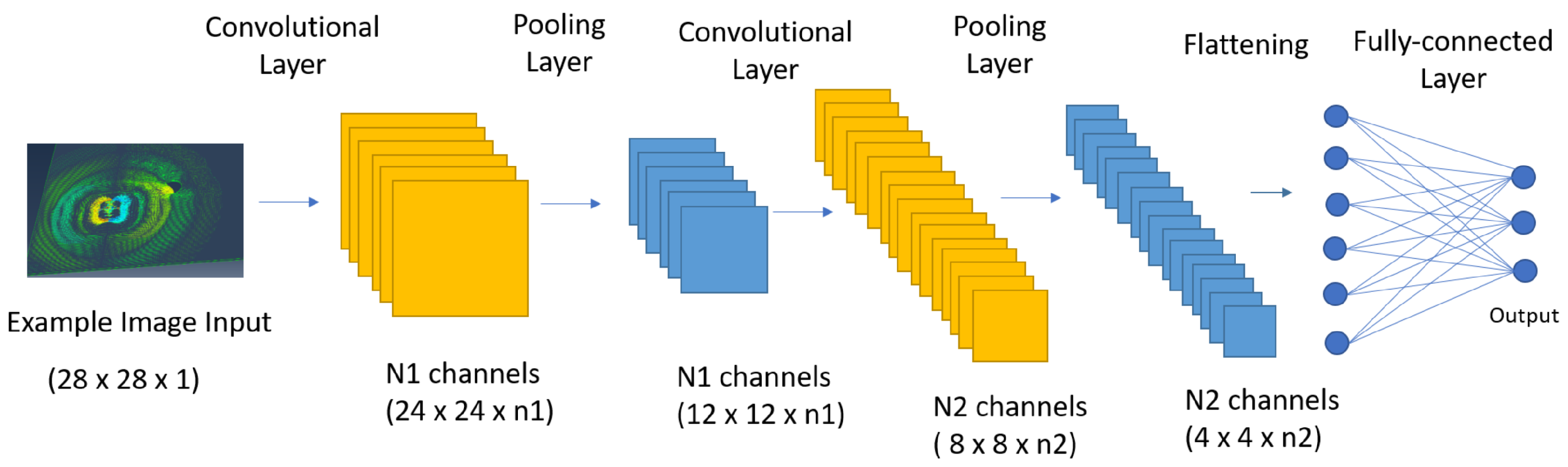
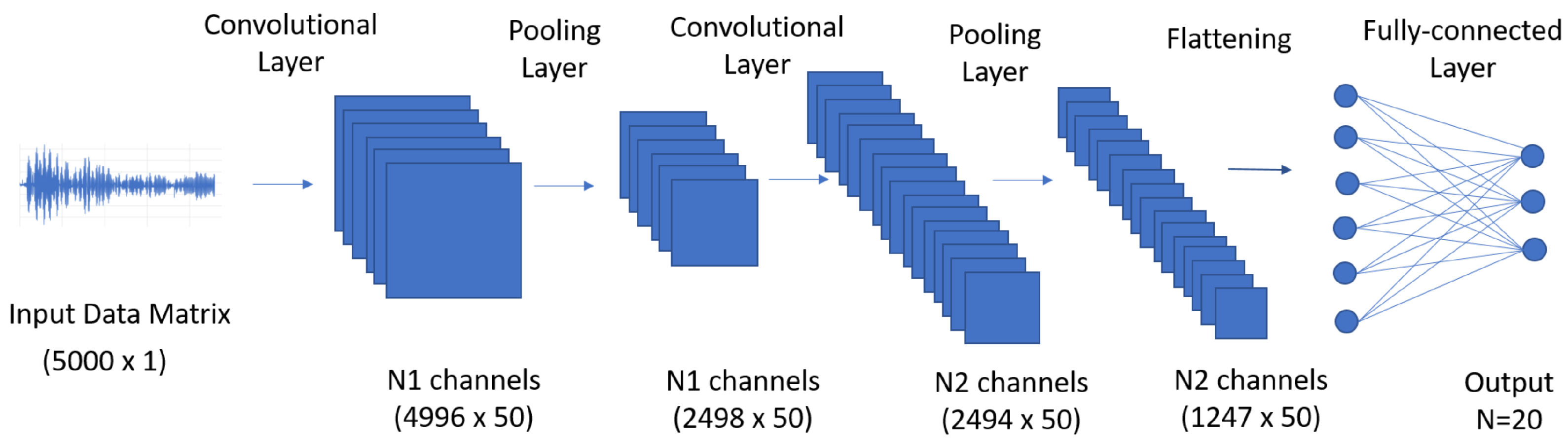
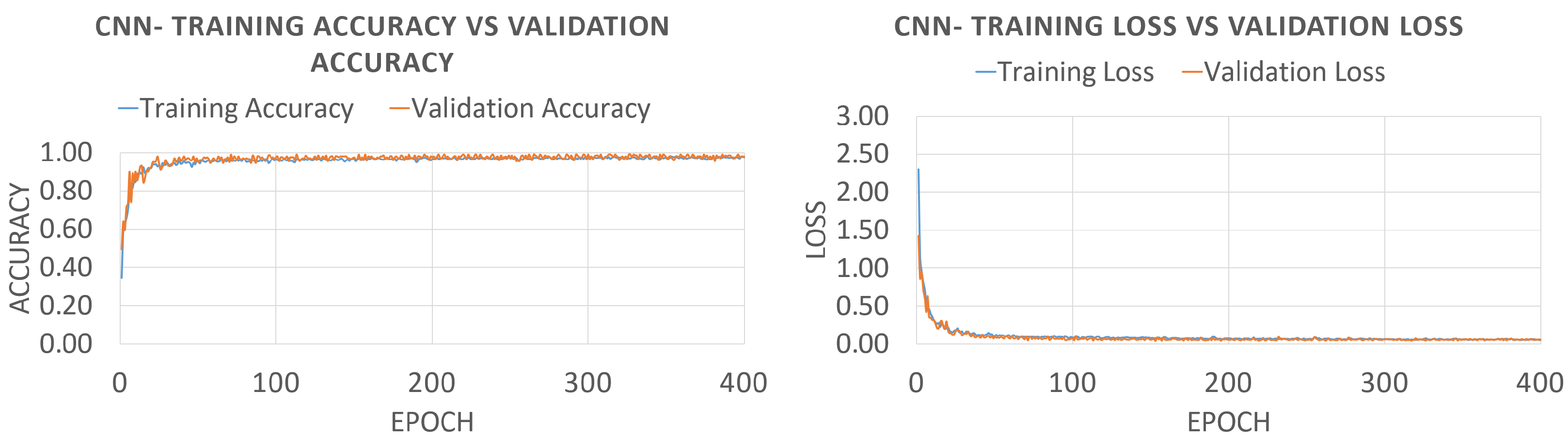
3.3. Convolutional Neural Network
4. Numerical Simulated Data
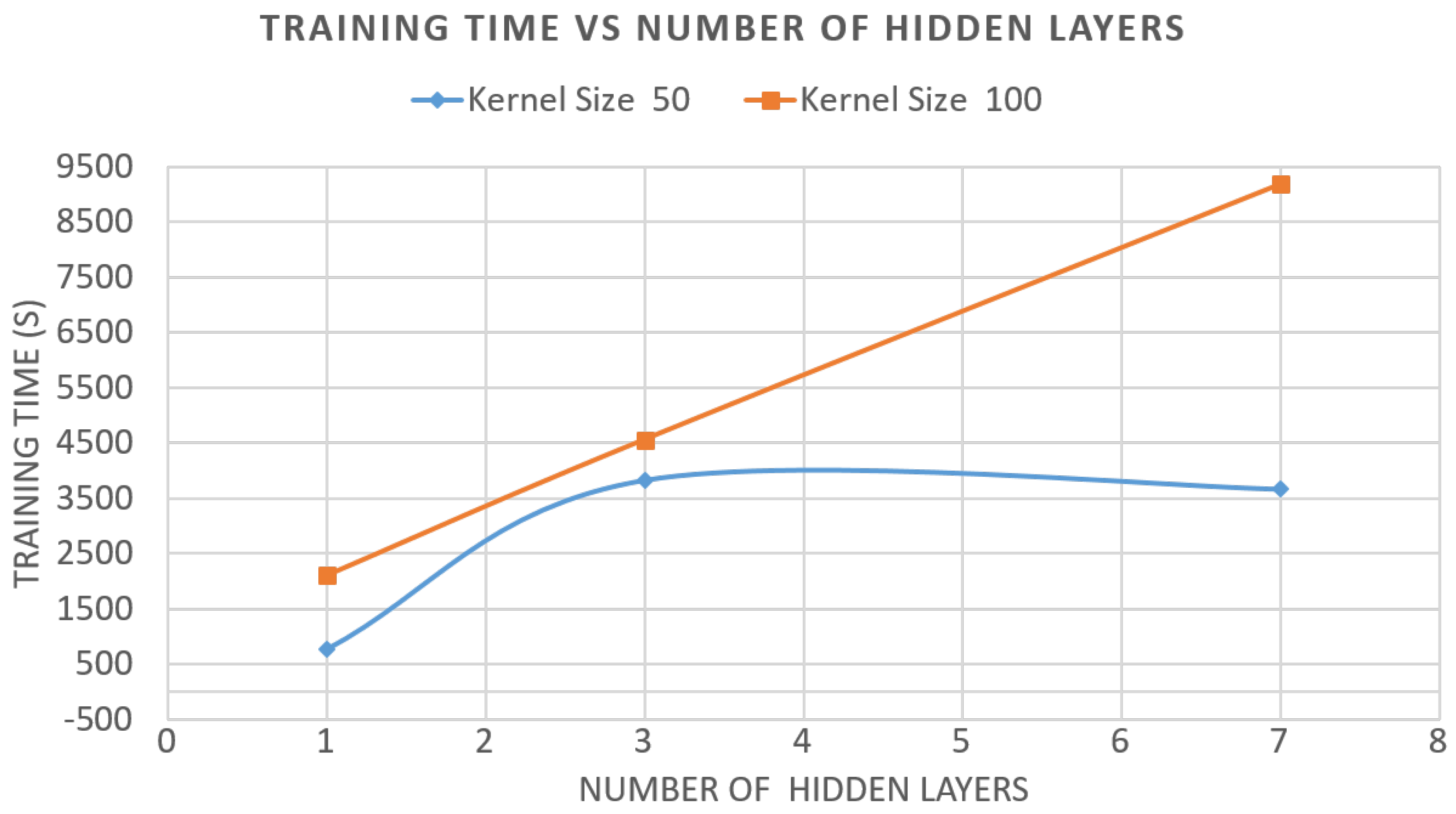
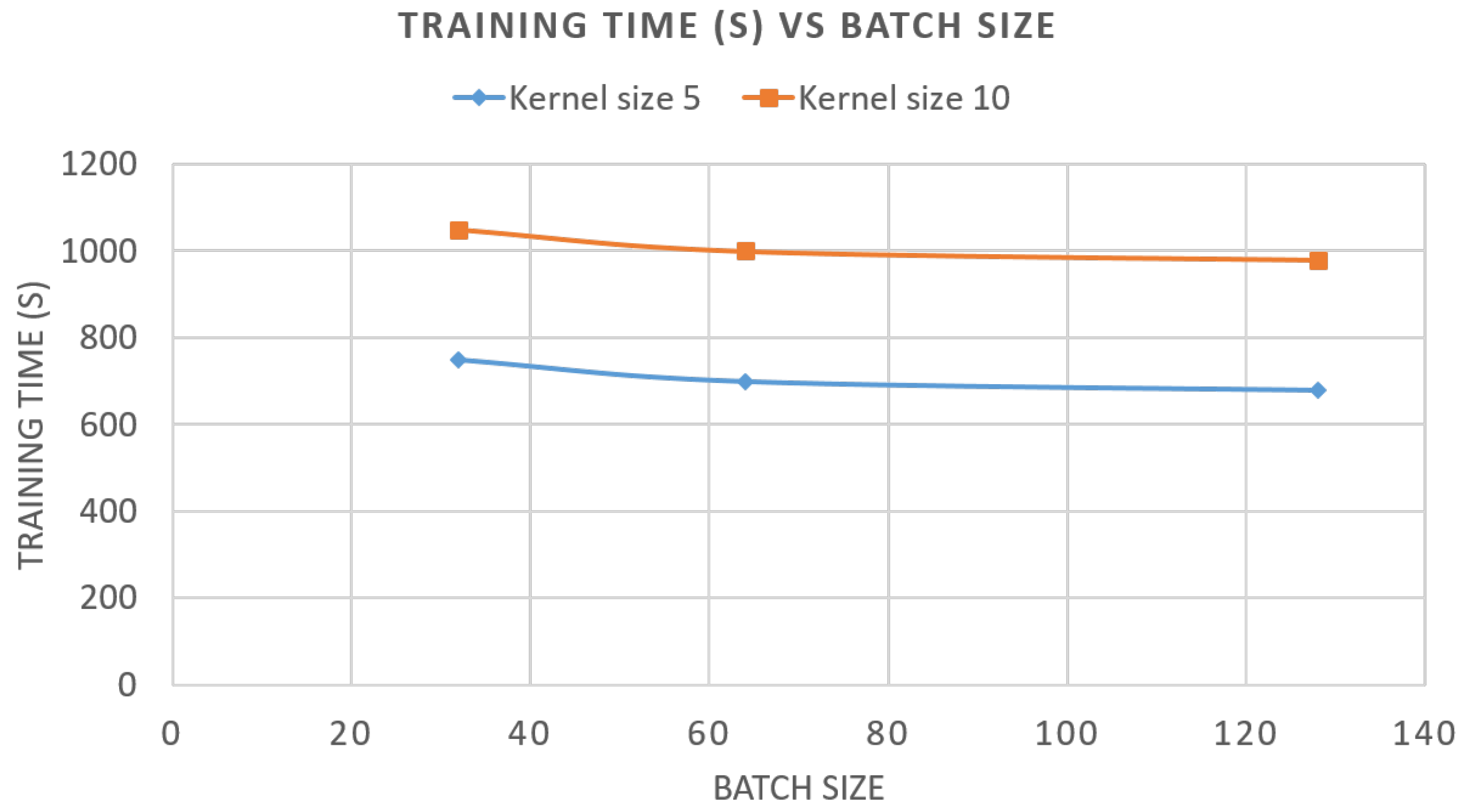
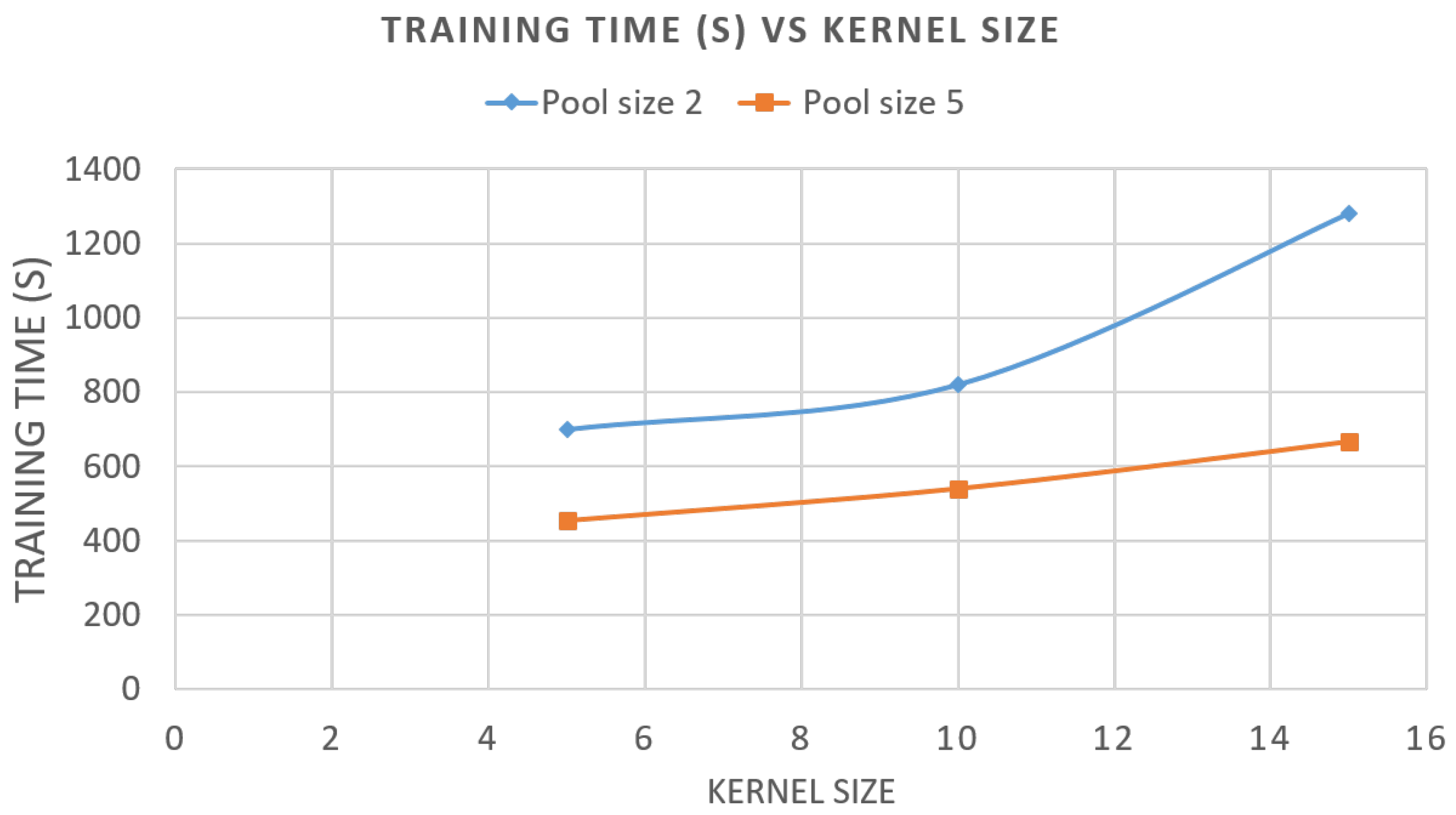
5. Algorithm Application and Results
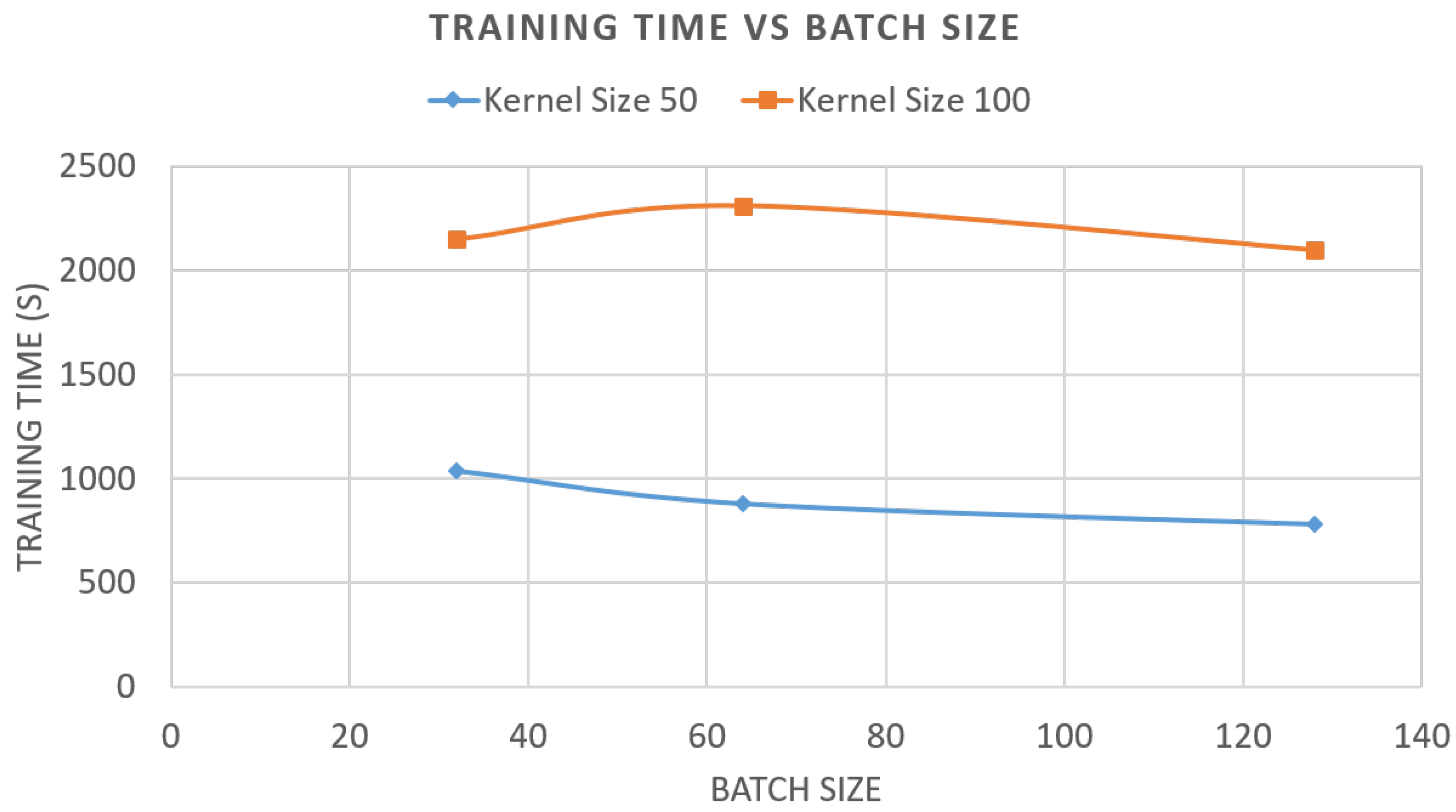
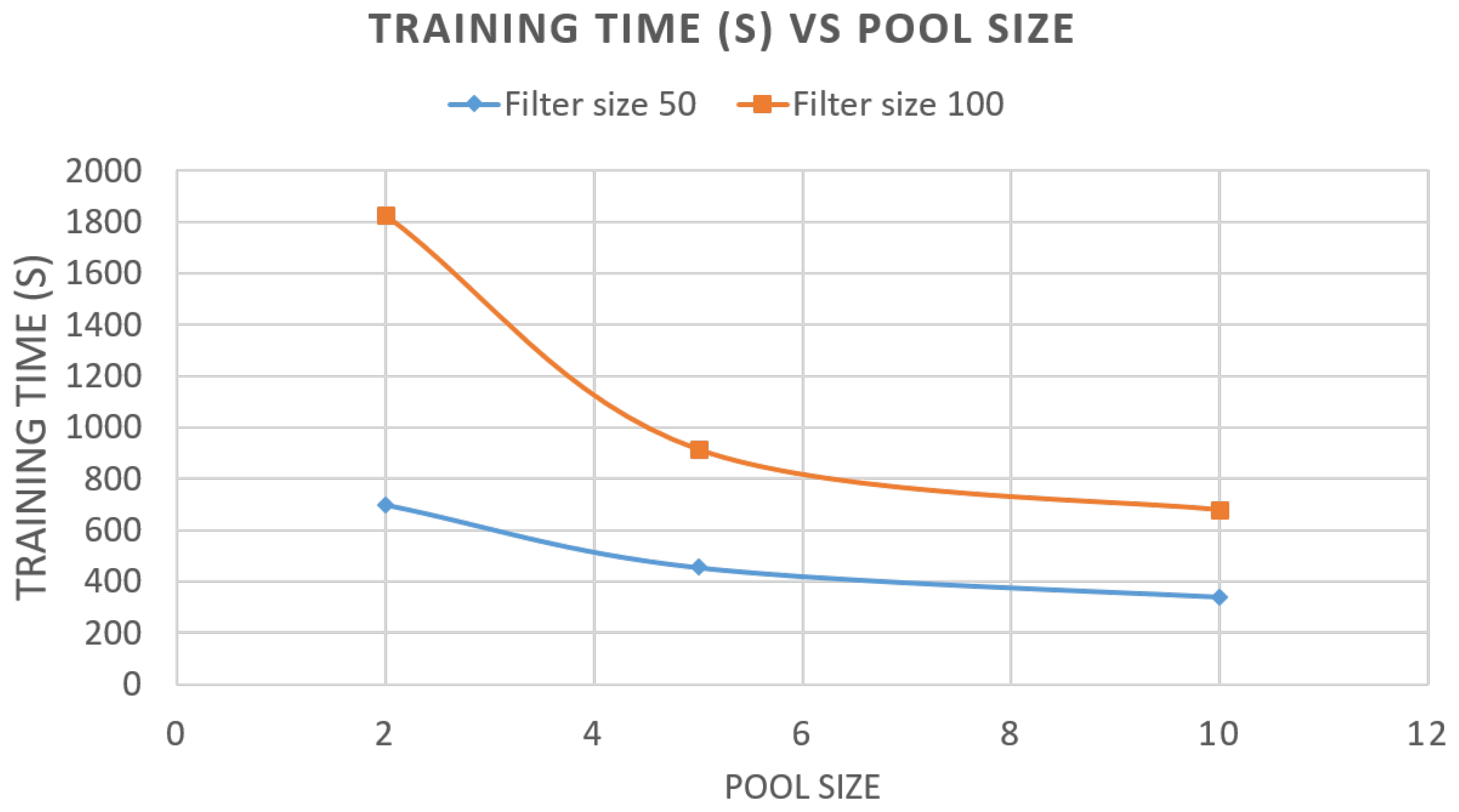
5.1. Evaluation of Components and Indicators
- Batch size: 128;
- Number of hidden layers: seven;
- Kernel size: 50.
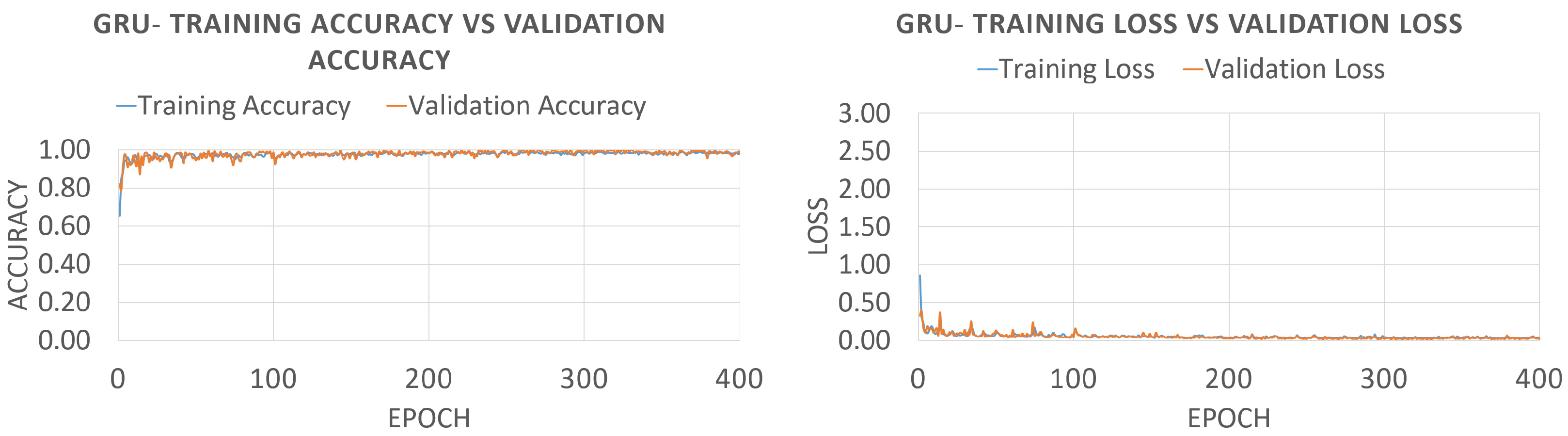
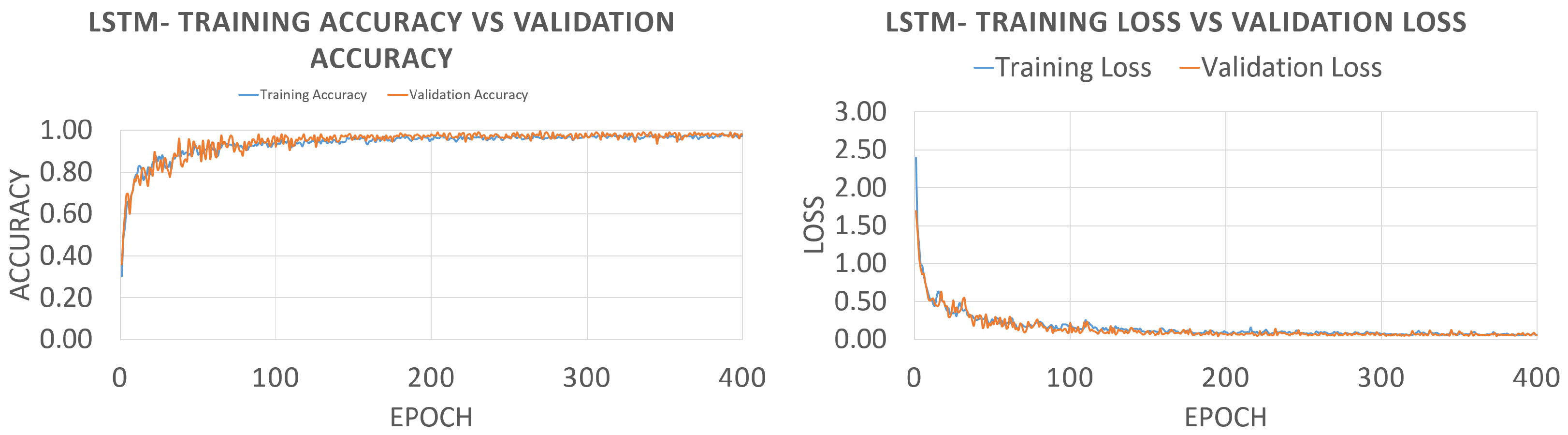
5.2. Results and Discussion
- −
- The accuracy score (acc) is used to evaluate the ratio of correct predictions to the total number of instances. This can be calculated aswhere denotes true positives, stands for true negatives, represents false positives, and finally, corresponds to false negatives.
- −
- The precision score (p) is the ratio of correctly predicted positive observations to the total number of positive ones. From a more intuitive perspective, it is the capacity of the algorithm to not label a positive sample as a negative one. It is given by:
- −
- The recall score (r) is the ratio of correctly predicted positive observations in a class, thus from an intuitive perspective, it is the capacity of the algorithm to determine all positive samples. Its value is calculated as:
- −
- The F1-score (F1) is the weighted average of the recall and precision and is commonly more important when there are large imbalances of the data in the class distributions. It is given by:
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Z.; Adams, R.; Da Silva, L.F. Prediction of crack initiation and propagation of adhesive lap joints using an energy failure criterion. Eng. Fract. Mech. 2011, 78, 990–1007. [Google Scholar] [CrossRef]
- da Silva, L.F.M.; Öchsner, A.; Adams, R.D. Handbook of Adhesion Technology, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Adin, M.S.; Kilickap, E. Strength of double-reinforced adhesive joints. Mater. Test. 2021, 63, 176–181. [Google Scholar] [CrossRef]
- Ramalho, G.M.; Lopes, A.M.; da Silva, L.F. Structural health monitoring of adhesive joints using Lamb waves: A review. Struct. Control. Health Monit. 2021, 29, e2849. [Google Scholar] [CrossRef]
- U.S. National Archives and Records Administration. Federal Aviation Regulations—Sec. 23.573; U.S. National Archives and Records Administration: Washington, DC, USA, 2014.
- Guyott, C.C.H.; Cawley, P.; Adams, R. The non-destructive testing of adhesively bonded structure: A review. J. Adhes. 1986, 20, 129–159. [Google Scholar] [CrossRef]
- Adin, H.; Adin, M.S. Effect of particles on tensile and bending properties of jute epoxy composites. Mater. Test. 2022, 64, 401–411. [Google Scholar] [CrossRef]
- Jeenjitkaew, C.; Guild, F.J. The analysis of kissing bonds in adhesive joints. Int. J. Adhes. Adhes. 2017, 75, 101–107. [Google Scholar] [CrossRef]
- Mańka, M.; Rosiek, M.; Martowicz, A.; Stepinski, T.; Uhl, T. PZT based tunable Interdigital Transducer for Lamb waves based NDT and SHM. Mech. Syst. Signal Process. 2016, 78, 71–83. [Google Scholar] [CrossRef]
- Adin, H.; Saglam, Z.; Adin, M.S. Numerical Investigation of Fatigue Behavior of Non-patched and Patched Aluminum/Composite Plates. Eur. Mech. Sci. 2021, 5, 168–176. [Google Scholar] [CrossRef]
- Alleyne, D.N. The Nondestructive Testing of Plates Using Ultrasound Lamb Waves. Ph.D. Thesis, Imperial College London (University of London), London, UK, 1991. [Google Scholar]
- Giurgiutiu, V.; Cuc, A. Embedded Non-Destructive Evaluation for Structural Health Monitoring, Damage Detection, and Failure Prevention. Shock Vib. Dig. 2005, 37, 83–105. [Google Scholar] [CrossRef]
- Dodson, J.; Inman, D. Thermal sensitivity of Lamb waves for structural health monitoring applications. Ultrasonics 2013, 53, 677–685. [Google Scholar] [CrossRef]
- Su, Z.; Ye, L.; Lu, Y. Guided Lamb waves for identification of damage in composite structures: A review. J. Sound Vib. 2006, 295, 753–780. [Google Scholar] [CrossRef]
- Kessler, S.; Spearing, S.; Soutis, C. Structural Health Monitoring in Composite Materials Using Lamb Wave Methods. Smart Mater. Struct. 2002, 11, 269–278. [Google Scholar] [CrossRef] [Green Version]
- Giurgiutiu, V. Tuned Lamb Wave Excitation and Detection with Piezoelectric Wafer Active Sensors for Structural Health Monitoring. J. Intell. Mater. Syst. Struct. 2005, 16, 291–305. [Google Scholar] [CrossRef]
- De Luca, A.; Perfetto, D.; Petrone, G.; De Fenza, A.; Caputo, F. Guided-waves in a low velocity impacted composite winglet. In Key Engineering Materials; Trans Tech Publications Ltd.: Sevilla, Spain, 2018; Volume 774, pp. 343–348. [Google Scholar]
- Petrone, G. Dispersion curves for a natural fibre composite panel: Experimental and numerical investigation. Aerosp. Sci. Technol. 2018, 82, 304–311. [Google Scholar] [CrossRef]
- Kumar, S.; Sunny, M.R. A novel nonlinear Lamb wave based approach for detection of multiple disbonds in adhesive joints. Int. J. Adhes. Adhes. 2021, 107, 102842. [Google Scholar] [CrossRef]
- Adams, R.D.; Adams, R.D.; Comyn, J.; Wake, W.C.; Wake, W. Structural Adhesive Joints in Engineering; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Wojtczak, E.; Rucka, M. Monitoring the curing process of epoxy adhesive using ultrasound and Lamb wave dispersion curves. Mech. Syst. Signal Process. 2021, 151, 107397. [Google Scholar] [CrossRef]
- Zupan, J.; Novič, M.; Li, X.; Gasteiger, J. Classification of multicomponent analytical data of olive oils using different neural networks. Anal. Chim. Acta 1994, 292, 219–234. [Google Scholar] [CrossRef]
- Albawi, S.; Abbas, Y.A.; Almadany, Y. Robust skin diseases detection and classification using deep neural networks. Int. J. Eng. Technol. 2018, 7, 6473–6480. [Google Scholar]
- Dongare, A.; Kharde, R.; Kachare, A.D. Introduction to artificial neural network. Int. J. Eng. Innov. Technol. (IJEIT) 2012, 2, 189–194. [Google Scholar]
- Plumb, A.P.; Rowe, R.C.; York, P.; Brown, M. Optimisation of the predictive ability of artificial neural network (ANN) models: A comparison of three ANN programs and four classes of training algorithm. Eur. J. Pharm. Sci. 2005, 25, 395–405. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Dhruv, P.; Naskar, S. Image classification using convolutional neural network (CNN) and recurrent neural network (RNN): A review. In Machine Learning and Information Processing; Springer: Singapore, 2020; pp. 367–381. [Google Scholar]
- Yang, S.; Yu, X.; Zhou, Y. LSTM and BRU neural network performance comparison study: Taking yelp review dataset as an example. In Proceedings of the 2020 International workshop on Electronic Communication and Artificial Intelligence (IWECAI), Shanghai, China, 12–14 June 2020; pp. 98–101. [Google Scholar]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM–a tutorial into long short-term memory recurrent neural networks. arXiv 2019, arXiv:1909.09586. [Google Scholar]
- Huang, Z.; Yang, F.; Xu, F.; Song, X.; Tsui, K.L. Convolutional Gated Recurrent Unit–Recurrent Neural Network for State-of-Charge Estimation of Lithium-Ion Batteries. IEEE Access 2019, 7, 93139–93149. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Lee, B.; Staszewski, W. Modelling of Lamb waves for damage detection in metallic structures: Part I. Wave propagation. Smart Mater. Struct. 2003, 12, 804. [Google Scholar] [CrossRef]
- Packo, P.; Bielak, T.; Spencer, A.; Staszewski, W.; Uhl, T.; Worden, K. Lamb wave propagation modelling and simulation using parallel processing architecture and graphical cards. Smart Mater. Struct. 2012, 21, 075001. [Google Scholar] [CrossRef]
- Ahmad, Z.; Gabbert, U. Simulation of Lamb wave reflections at plate edges using the semi-analytical finite element method. Ultrasonics 2012, 52, 815–820. [Google Scholar] [CrossRef]
- Adin, H.; Yıldız, B.; Adin, M.S. Numerical investigation of fatigue behaviours of non-patched and patched aluminium pipes. Eur. J. Tech. (EJT) 2021, 11, 60–65. [Google Scholar] [CrossRef]
- Loreiro, V.; Ramalho, G.; Tenreiro, A.; Lopes, A.M.; da Silva, L. Feature extraction and visualization for damage detection on adhesive joints, utilizing Lamb waves and supervised machine learning algorithms. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2022, 236, 8842–8855. [Google Scholar] [CrossRef]
- Ramalho, G.M.; Barbosa, M.R.; Lopes, A.M.; da Silva, L.F. Damage Classification Methodology Utilizing Lamb Waves and Artificial Neural Networks. J. Test. Eval. 2022, 50, 19. [Google Scholar] [CrossRef]
- Poudel, A.; Chu, T.P. Assessment of Composite Aluminum Adhesive Joints Using Digital Image Correlation. Mater. Eval. 2022, 80. [Google Scholar] [CrossRef]
- Cantrell, D.R. Onset of Kissing Bond Formation for Varying Levels of Bondline Contamination in CFRP. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2022. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Variables to Be Tested | ||
|---|---|---|
| Batch Size | Kernel Size | Number of Hidden Layers |
| 32 | 50 | 1 |
| 64 | 100 | 3 |
| 128 | 400 | 7 |
| Evaluation Criteria | ||||
|---|---|---|---|---|
| Algorithm | Accuracy | Precision | Recall | F1-Score |
| FNN | 0.99 | 0.99 | 0.99 | 0.99 |
| CNN | 0.975 | 0.97 | 0.98 | 0.97 |
| GRU | 0.99 | 0.99 | 0.99 | 0.99 |
| LSTM | 0.98 | 0.98 | 0.98 | 0.98 |
| Epochs and Total Time | |||
|---|---|---|---|
| Algorithm | Epochs to Converge | Time to Converge (min) | Total Time (min) |
| FNN | 100 | 7 | 28.0 |
| CNN | 150 | 4.5 | 12.3 |
| GRU | 35 | 15 | 177.5 |
| LSTM | 150 | 89 | 238.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramalho, G.M.F.; M. Lopes, A.; Carbas, R.J.C.; Da Silva, L.F.M. Identifying Weak Adhesion in Single-Lap Joints Using Lamb Wave Data and Artificial Intelligence Algorithms. Appl. Sci. 2023, 13, 2642. https://doi.org/10.3390/app13042642
Ramalho GMF, M. Lopes A, Carbas RJC, Da Silva LFM. Identifying Weak Adhesion in Single-Lap Joints Using Lamb Wave Data and Artificial Intelligence Algorithms. Applied Sciences. 2023; 13(4):2642. https://doi.org/10.3390/app13042642
Chicago/Turabian StyleRamalho, Gabriel M. F., António M. Lopes, Ricardo J. C. Carbas, and Lucas F. M. Da Silva. 2023. "Identifying Weak Adhesion in Single-Lap Joints Using Lamb Wave Data and Artificial Intelligence Algorithms" Applied Sciences 13, no. 4: 2642. https://doi.org/10.3390/app13042642