4.3.1. Shock Load Condition Where Is 1050 m/s
- (1)
Study on IP
(i) Constructing training sample set and test sample sets
In addressing the IP when the
is 1050 m/s, in order to guarantee the excellent generalization ability of the ANNs, 2000 sample points were generated for the BRVs with the CV of 0.02, and 500 sample points were generated for the BRVs with the CV of 0.005, so as to construct the training sample set with 2500 sample points. Then, a test sample set of 1000 sample points was constructed for the BRVs with each of the CVs of 0.005, 0.01, 0.015, and 0.02. The four test sample sets tested whether the ANNs could accurately calculate the RRs under these randomness conditions. The statistical results of the initiation and non-initiation frequencies of Composition B in these training sample set and test sample sets are shown in
Table 4.
(ii) Determining the structure and important parameters of ANNs
In this example, according to the numbers of the BRVs and RR in the IP, the neuron numbers of the input layer, first hidden layer, second hidden layer, and output layer of the GABPNN for the IP were, respectively, set as 19, 25, 15, and 1. So, the structure of this GABPNN was . In addition, the network maximum training time Tmax was set as 20,000, the network training rate Rt was set as 0.05, the network training allowable error Ea was set as 0.001, the population size Mp was set as 20, the maximum generation Gmax was set as 30, the chromosome crossover probability Pc was set as 0.75, the chromosome mutation probability Pm was set as 0.1, and the fitness coefficient C was set as 20.0.
In addition, the structure and corresponding parameters of the BPNN were the same as the corresponding ones of the GABPNN. The neuron numbers of the input layer and output layer of the RBFNN were the same as the corresponding ones of the GABPNN, and the neuron number of the hidden layer of the RBFNN was equal to the sample size q of the training sample set.
(iii) Performance comparison of ANNs
Firstly, the GABPNN, BPNN, and RBFNN were trained by the above training sample set. Then, these three trained ANNs were tested by each of the above four test sample sets, with the test results shown in
Table 5 and
Figure 6. In
Table 5, the
δT stands for the calculation results of these three ANNs (the actual output results of the
δ), and the
δE the expected output results of the
δ.
According to the test results shown in
Table 5 and
Figure 6, all the test accuracy results with which the GABPNN calculated the 0–1 recognition results of the
δ corresponding to these 4 test sample sets were above 90%, and these test results were also better than the test results of BPNN and RBFNN. It is proved that the GABPNN has stronger nonlinear mapping ability than the BPNN and RBFNN, and the GABPNN can accurately calculate the 0–1 recognition results of the
δ corresponding to the BRV sample points. Therefore, the GABPNN can be used as the surrogate model of the IP, and the GABP-MCS can also be used to estimate the
R’s of Composition B.
(iv) Estimation of R based on GABP-MCS
A prediction sample set with 100,000 sample points was constructed under each of the above 4 randomness conditions, and the 0–1 recognition results of the
δ corresponding to these 4 prediction sample sets were obtained by the GABP-MCS, so as to obtain accurate estimates of the actual
R’s of Composition B under these 4 randomness conditions. The results are shown in
Table 6 and
Figure 7.
According to the statistical data in
Table 6 and the correlation curve in
Figure 7, it can be concluded that when the
is 1050 m/s, the
R of Composition B is negatively correlated with the CV of the BRVs; that is, the smaller the CV of the BRVs, the higher the
R of Composition B. This is because the smaller the CV of the BRVs, the more concentrated the distribution of the BRV sample points in the corresponding prediction sample sets, the more BRV sample points there are that can lead Composition B to be initiated, the lower the randomness of the SIREM, and the more likely this SIREM is a deterministic problem; thus, the randomness calculation results of this SIREM will be closer to the deterministic results described in
Section 4.1. So, it can be further deduced that, if the CV of the BRVs dropped to 0, this SIREM would become a deterministic problem, so Composition B would definitely be initiated (the
R would increase to 1) under the shock load condition where
was 1050 m/s, which would be exactly the same as the deterministic results presented in
Section 4.1.
- (2)
Study on DPR
(i) Constructing the training sample set and test sample sets
The sample points that could lead Composition B to be initiated were selected again from the training sample set and test sample sets of the IP, so as to construct the training sample set and test sample sets of the DPR. Therefore, according to the statistical data in
Table 4, in addressing the DPR, the training sample set had 1554 sample points, and the 4 test sample sets, with the CVs of the BRVs being respectively 0.005, 0.01, 0.015, and 0.02, had 768, 685, 612, and 585 sample points respectively.
(ii) Determining the structure and important parameters of ANNs
According to the numbers of the BRVs and RRs in the DPR, the neuron numbers of the input layer, hidden layer, and output layer of the GABPNN for the DPR were, respectively, set as 19, 25, and 3. So, the structure of this GABPNN was . In addition, the Tmax was set as 20,000, the Rt was set as 0.05, the Ea was set as 0.001, the Mp was set as 20, the Gmax was set as 30, the Pc was set as 0.75, the Pm was set as 0.1, and the C was set as 0.5.
In addition, the structure and corresponding parameters of the BPNN were the same as the corresponding ones of the GABPNN. The neuron numbers of the input layer and output layer of the RBFNN were the same as the corresponding ones of the GABPNN, and the neuron number of the hidden layer of the RBFNN was equal to the sample size q of the training sample set.
(iii) Performance comparison of ANNs
Firstly, the GABPNN, BPNN, and RBFNN were trained by the above training sample set. Then, these three trained ANNs were tested by each of the above four test sample sets, and the test results are shown in
Table 7 and
Figure 8.
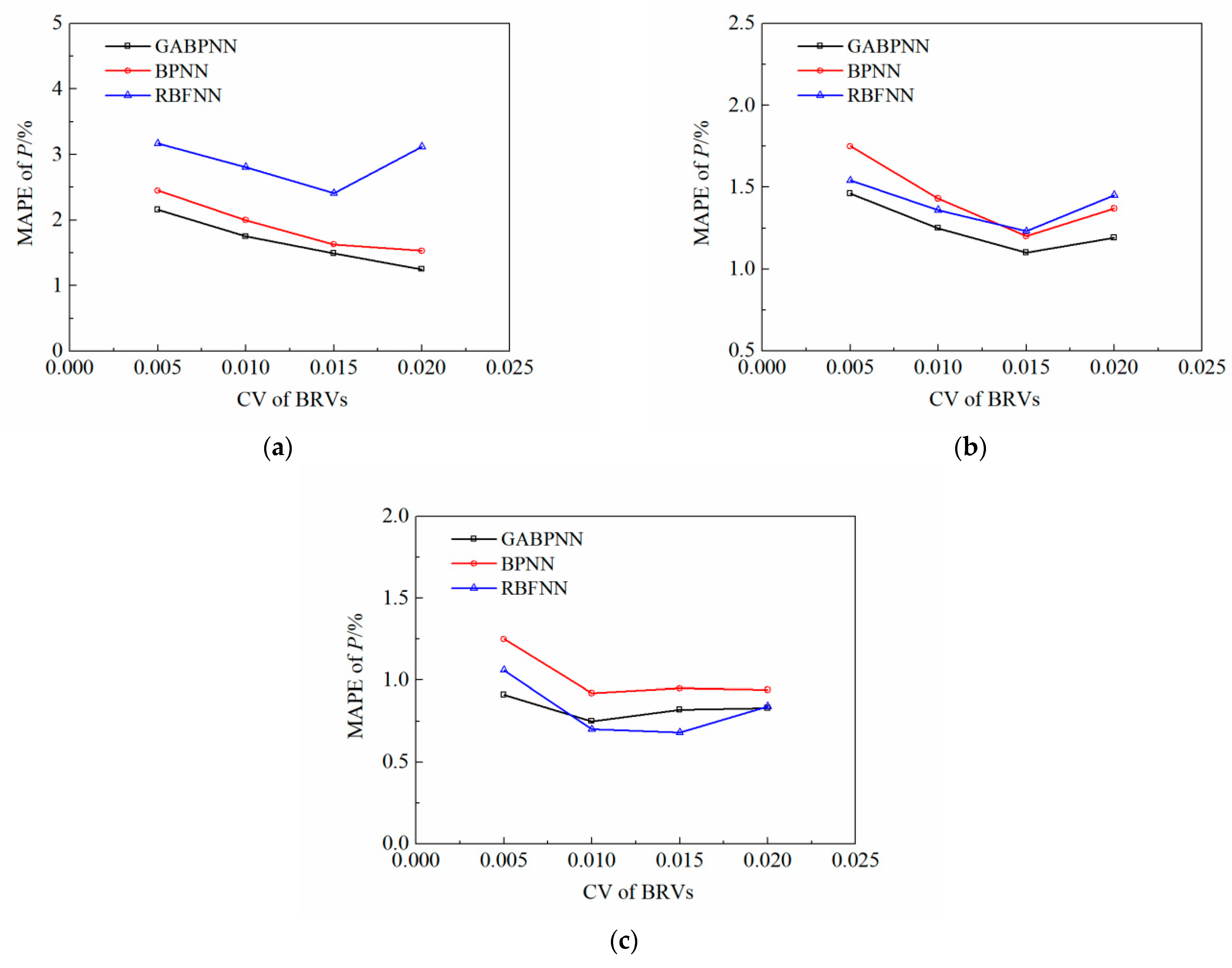
The test results in
Table 7 and
Figure 8 show that the GABPNN consistently had a Mean Absolute Percentage Errors (MAPE) lower than 2.2% in calculating the
P of each gauge in the numerical model corresponding to these 4 test sample sets, and the MAPEs of the GABPNN were slightly higher than the corresponding ones of the RBFNN only when calculating the
P of the gauge 3 corresponding to the test sample sets where the CVs of BRVs were respectively 0.01 and 0.015, and the MAPEs of the GABPNN were lower than the corresponding ones of the RBFNN and BPNN when calculating the
P of each gauge under other conditions. It is proved that the GABPNN has stronger nonlinear mapping ability than the BPNN and RBFNN, and the GABPNN can accurately calculate the
P of each gauge corresponding to the BRV sample points. Therefore, the GABPNN can be used as the surrogate model of the DPR, and the GABP-MCS can also be used to estimate the statistical characteristics of the
P of each gauge of Composition B.
(iv) Estimation of the statistical characteristics of P based on GABP-MCS
The sample points that could lead Composition B to be initiated were selected from the prediction sample sets of the IP, so as to construct the prediction sample sets of the DPR. According to
Table 6, in addressing the DPR, the 4 prediction sample sets, with the CVs of the BRVs being, respectively, 0.005, 0.01, 0.015, and 0.02, had 78,654, 66,291, 61,281, and 58,711 sample points, respectively. The calculation results of the
P’s of the three gauges in the numerical model corresponding to these four prediction sample sets were obtained by the GABP-MCS, so as to obtain the accurate estimates of the actual statistical characteristics of the
P’s of these three gauges under the above four randomness conditions, as shown in
Table 8 and
Figure 9.
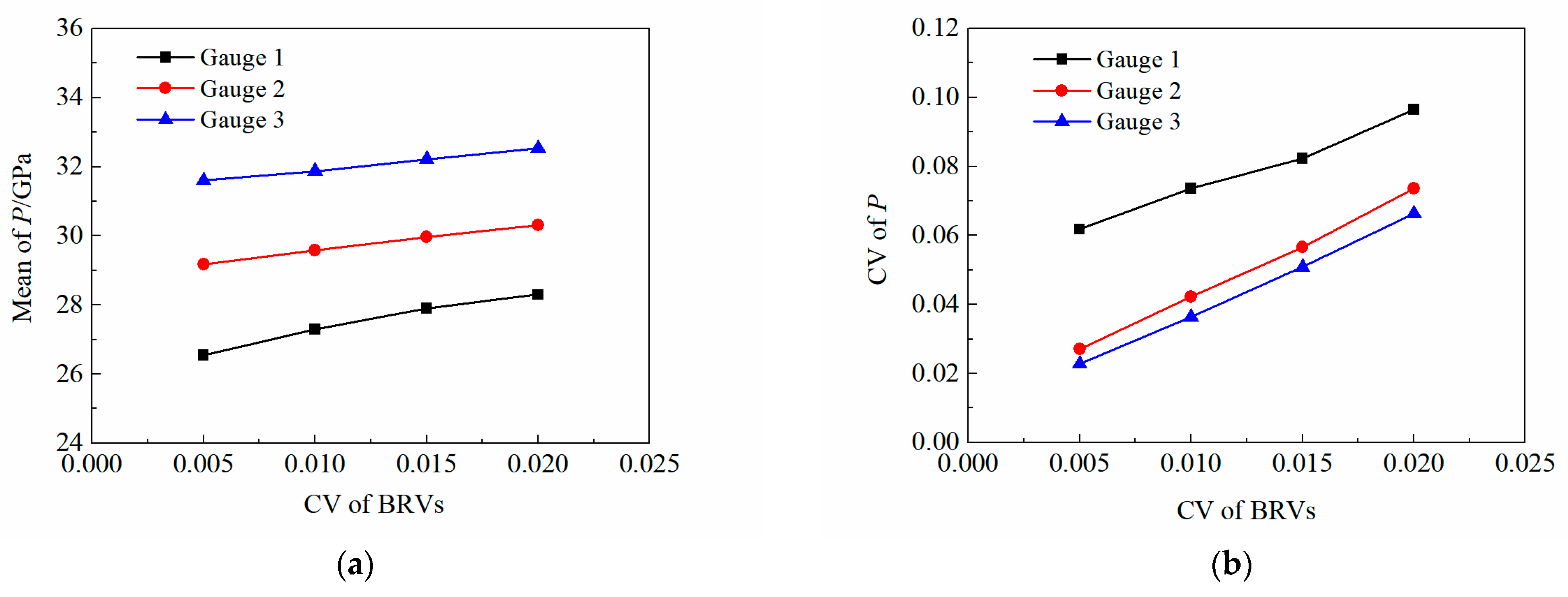
The following are the three observations from
Table 8 and
Figure 9 and their interpretation. First, for each gauge, the mean of its
P is positively correlated with the CV of the BRVs; that is, the mean of its
P can increase gradually with the CV of the BRVs. This is because the more likely the BRV sample points result in the initiation of Composition B, the greater
P Composition B tends to generate in subsequent detonations. Furthermore, the larger the CV of the BRVs, the more scattered the distribution of the BRV sample points in the corresponding prediction sample sets, and the more BRV sample points that can result in lower values of the
P will be eliminated in addressing the DPR for the initiation failure of Composition B. In this case, a higher proportion of the BRV sample points, which result in the higher values of the
P in the prediction sample sets, suggests the higher estimated means of the
P. What is also observed is that, under these four randomness conditions, the CVs of the
P’s of the three gauges in the numerical model are all significantly larger than the CVs of the BRVs, which indicates that the randomness of the BRVs can magnify the randomness of the
P. The third observation is that, for each gauge, the CV of its
P is also positively correlated with the CV of the BRVs; that is, the CV of its
P can decrease with the CV of the BRVs. This is because the smaller the CV of the BRVs, the lower the randomness of the SIREM and the lower the randomness of the
P, which suggests the smaller the CV of the
P. So, it can be further deduced that, if the CV of the BRVs dropped to 0, the SIREM would become a deterministic problem, the CVs of the
P would also drop to 0, and the
P would also become a deterministic variable accordingly.
4.3.2. Shock Load Condition Where Is 1000 m/s
- (1)
Study on IP
(i) Constructing training sample set and test sample sets
In addressing the IP when the
is 1000 m/s, in order to guarantee the excellent generalization ability of the ANNs and sufficient training sample points for the DPR, 3000 sample points were generated for the BRVs with the CV of 0.02, and 1000 sample points were generated for the BRVs with the CV of 0.005, so as to construct the training sample set with 4000 sample points. Then, a test sample set with 1000 sample points was constructed for the BRVs with each of the CVs of 0.005, 0.01, 0.015, and 0.02.
Table 9 shows the statistical results of the initiation and non-initiation frequencies of Composition B in these training sample set and test sample sets.
(ii) Determining the structure and important parameters of ANNs
In this stage, under the shock load condition that the
is 1000 m/s, the setting of the structure and important parameters of the GABPNN, BPNN, and RBFNN is the same as the corresponding operation under the shock load condition where the
is 1050 m/s; see
Section 4.3.1.
(iii) Performance comparison of ANNs
Firstly, the GABPNN, BPNN, and RBFNN were trained by the above training sample set. Then, these three trained ANNs were tested by each of the above four test sample sets, and the test results shown in
Table 10 and
Figure 10 were obtained.
According to the test results shown in
Table 10 and
Figure 10, the test accuracy when the GABPNN calculated the 0–1 recognition results of the
δ corresponding to these 4 test sample sets was consistently higher than 87%, and the testing accuracy of the GABPNN was slightly lower than the corresponding one of the RBFNN only when calculating the 0–1 recognition results of the
δ corresponding to the test sample set with the CV of BRVs as 0.02, and the testing accuracies of the GABPNN were higher than the corresponding ones of the RBFNN and BPNN when calculating the 0–1 recognition results of the
δ under other conditions. It is proved that the GABPNN has stronger nonlinear mapping ability than the BPNN and RBFNN, and the GABPNN can accurately calculate the 0–1 recognition results of the
δ corresponding to the BRV sample points. Therefore, the GABPNN can be used as the surrogate model of the IP, and the GABP-MCS can also be used to estimate the
R’s of Composition B.
(iv) Estimation of R based on GABP-MCS
A prediction sample set with 100,000 sample points was constructed under each of the above 4 randomness conditions, and the 0–1 recognition results of the
δ corresponding to these 4 prediction sample sets were obtained by the GABP-MCS, so as to obtain the accurate estimates of the actual
R’s of Composition B under these 4 randomness conditions.
Table 11 and
Figure 11 show the results.
According to the statistical data in
Table 11 and the correlation curve in
Figure 11, it can be concluded that, when the
is 1000 m/s, the
R of Composition B is positively correlated with the CV of the BRVs; that is, the smaller the CV of the BRVs, the lower the
R of Composition B. This is because the smaller the CV of the BRVs, the more concentrated the distribution of the BRV sample points in the corresponding prediction sample sets, the less BRV sample points there are that can lead Composition B to be initiated, and the lower the randomness of the SIREM. If the CV of the BRVs dropped to 0, this SIREM would become a deterministic problem, so Composition B would not be initiated (the
R would drop to 0) under the shock load condition where
was 1000 m/s, which would be exactly the same as the deterministic results described in
Section 4.1.
- (2)
Study on DPR
(i) Constructing training sample set and test sample sets
The same method discussed in
Section 4.3.1 was adopted to construct the training sample set and test sample sets of the DPR.
Table 9 shows that in addressing the DPR, the training sample set had 1580 sample points and the 4 test sample sets with 258, 367, 398, and 454 sample points, which correspond, respectively, to the CVs of the BRVs at 0.005, 0.01, 0.015, and 0.02.
(ii) Determining the structure and important parameters of ANNs
When the
is 1000 m/s, the setting of the structure and important parameters of the GABPNN, BPNN, and RBFNN is the same as the corresponding operation when the
is 1050 m/s; see
Section 4.3.1 for the setting process.
(iii) Performance comparison of ANNs
Firstly, the GABPNN, BPNN, and RBFNN were trained by the above training sample set. Then, these three trained ANNs were tested by each of the above four test sample sets, and the test results shown in
Table 12 and
Figure 12 were obtained.
According to the test results shown in
Table 12 and
Figure 12, the GABPNN consistently had MAPEs lower than 2.6% in calculating the
P of each gauge in the numerical model corresponding to these 4 test sample sets, and these test results were also better than the test results of BPNN and RBFNN. It is proved that the GABPNN has stronger nonlinear mapping ability than the BPNN and RBFNN, and the GABPNN can accurately calculate the
P of each gauge corresponding to the BRV sample points. Therefore, the GABPNN can be used as the surrogate model of the DPR, and the GABP-MCS can also be used to estimate the statistical characteristics of the
P of each gauge of Composition B.
(iv) Estimation of the statistical characteristics of P based on GABP-MCS
The sample points that could lead Composition B to be initiated were selected from the prediction sample sets of the IP, so as to construct the prediction sample sets of the DPR. According to
Table 11, in addressing the DPR, the 4 prediction sample sets, with the CVs of the BRVs being, respectively, 0.005, 0.01, 0.015, and 0.02, had 26,151, 36,677, 40,812, and 43,155 sample points, respectively. The calculation results of the
P’s of the three gauges in the numerical model corresponding to these four prediction sample sets were obtained by the GABP-MCS, so as to obtain the accurate estimates of the actual statistical characteristics of the
P’s of these three gauges under the above four randomness conditions, as shown in
Table 13 and
Figure 13.
The following are the three observations from
Table 13 and
Figure 13 and their interpretation. First, for each gauge, the mean of its
P is positively correlated with the CV of the BRVs; that is, the mean of its
P can increase with the CV of the BRVs. This is because the more likely the BRV sample points result in the initiation of Composition B, the greater
P Composition B tends to generate in subsequent detonations. Furthermore, the larger the CV of the BRVs, the more scattered the distribution of the BRV sample points in the corresponding prediction sample sets, and the more BRV sample points that can result in higher values of the
P will be reserved in addressing the DPR, for they can lead to the initiation of Composition B. This suggests the higher estimates of the means of the
P. What is also observed is that, under these four randomness conditions, the CVs of the
P’s of the three gauges in the numerical model are all significantly larger than the CVs of the BRVs, which indicates that the randomness of the BRVs can magnify the randomness of the
P. The third observation is that, for any gauge, the CV of its
P is also positively correlated with the CV of the BRVs; that is, the CV of its
P can increase with the CV of the BRVs. This is because the larger the CV of the BRVs, the higher the randomness of the SIREM, and the higher the randomness of the
P, which suggests the larger the CV of the
P.
The above are the details of this applied example. The study results show that the shock response of Composition B has obvious randomness under the action of the main BRVs, and that the GABP-MCS can be adopted to solve the SIREM to obtain satisfactory randomness study results. Moreover, since Composition B is representative among various kinds of energetic materials, this example can also prove the universality of GABP-MCS in the study on SIREM.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}