
Experience Replay Optimisation via ATSC and TSC for Performance Stability in Deep RL
Abstract
:1. Introduction
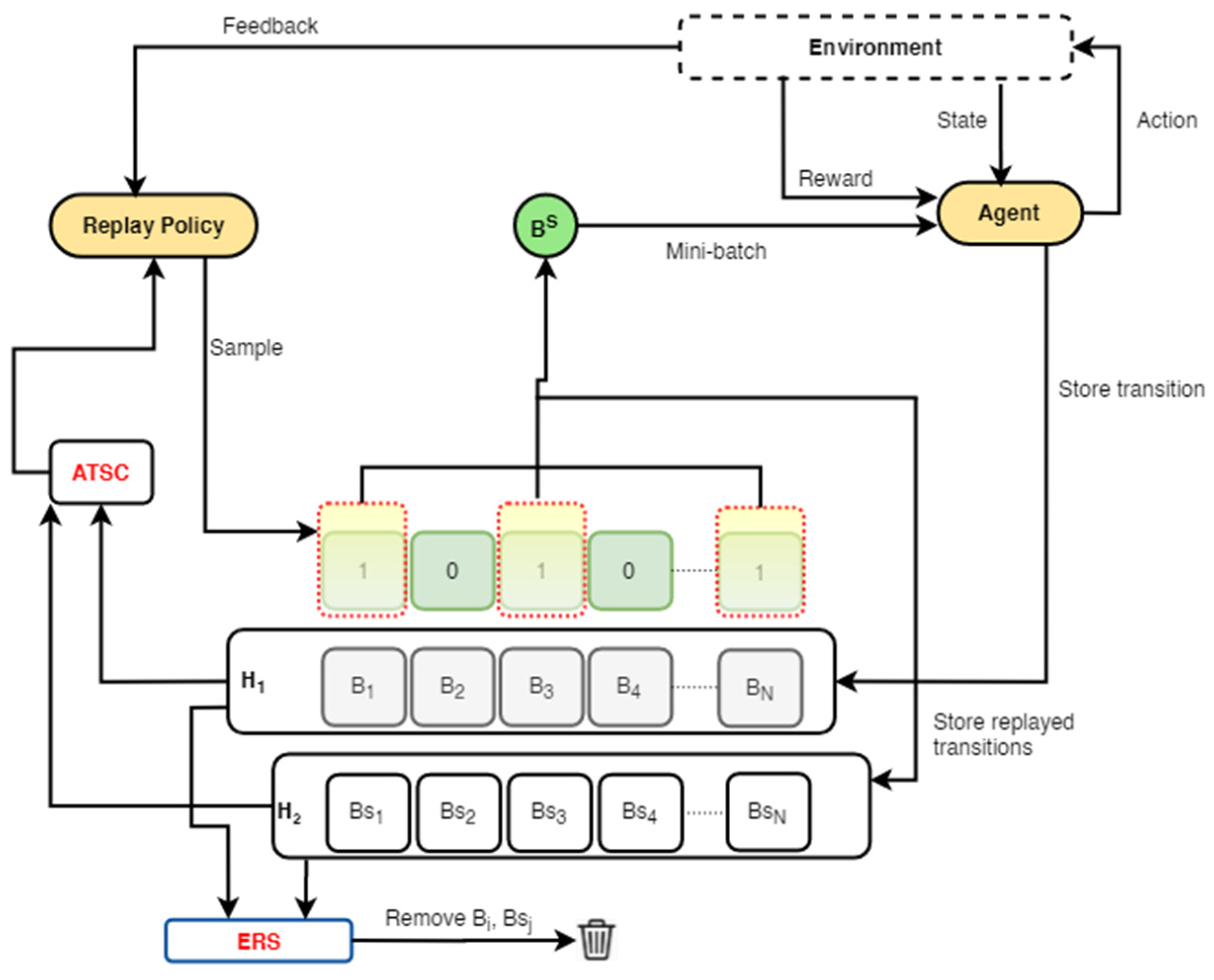
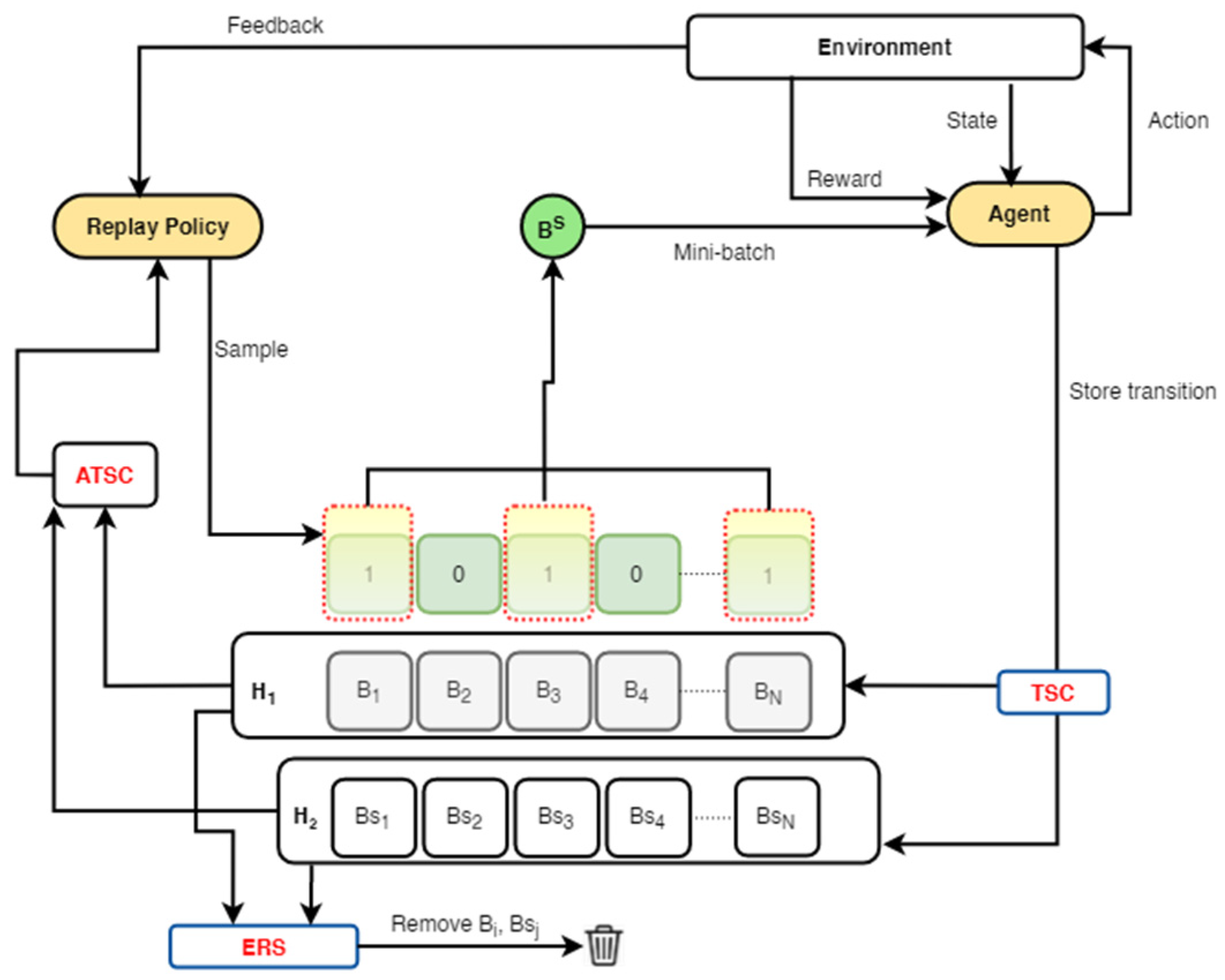
- To effectively improve the performance stability of ERO, an alternating transition selection control (ATSC) and a dual memory are introduced into the standard ERO to design a first framework. The ATSC uses a selection ratio to sample transitions from the dual memory into the replay policy network to promote complementary and stable learning.
- A transition storage control (TSC), which uses either a reward or a temporal difference error (TDE) threshold, is further integrated into the first framework to ensure that more rewarding and diverse transitions are frequently stored in the dual memory.
2. Related Works
2.1. Experience Retention Strategies and Algorithms
2.2. Experience Selection Strategies and Algorithms

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Algorithm | Sampling Strategy | Retention Strategy | |||
|---|---|---|---|---|---|---|
| Uniform | Priority | Sequential | Uniform | Priority | ||
| [8] | Deep Q-Network (DQN) | √ | √ | |||
| [9] | Prioritised Experience Replay (PER) | √ | √ | |||
| [11] | Deep Deterministic Policy Gradient (DDPG) | √ | √ | |||
| [12] | Episodic Memory Deep Q-Network (EMDQN) | √ | √ | |||
| [13] | Selective Experience Replay (SER) | √ | √ | √ | ||
| [14] | Prioritised Sequence Experience Replay (PSER) | √ | √ | |||
| [15] | Experience Replay Optimisation (ERO) | √ | √ | √ | ||
| [16] | Attentive Experience Replay (AER) | √ | √ | √ | ||
| [17] | Double Experience Replay (DER) | √ | √ | √ | ||
| [26] | Prioritised Stochastic Memory Management (PSMM) | √ | √ | |||
| [30] | Twin Delayed Deep Deterministic Policy Gradient (TD3) | √ | √ | |||
| [31] | Proximal Policy Optimisation (PPO) | √ | √ | |||
| [33] | Dual Memory Structure (DMS) | √ | √ | √ | √ | |
3. General Framework for ERO-ATSC
3.1. ERO and Alternating ERO
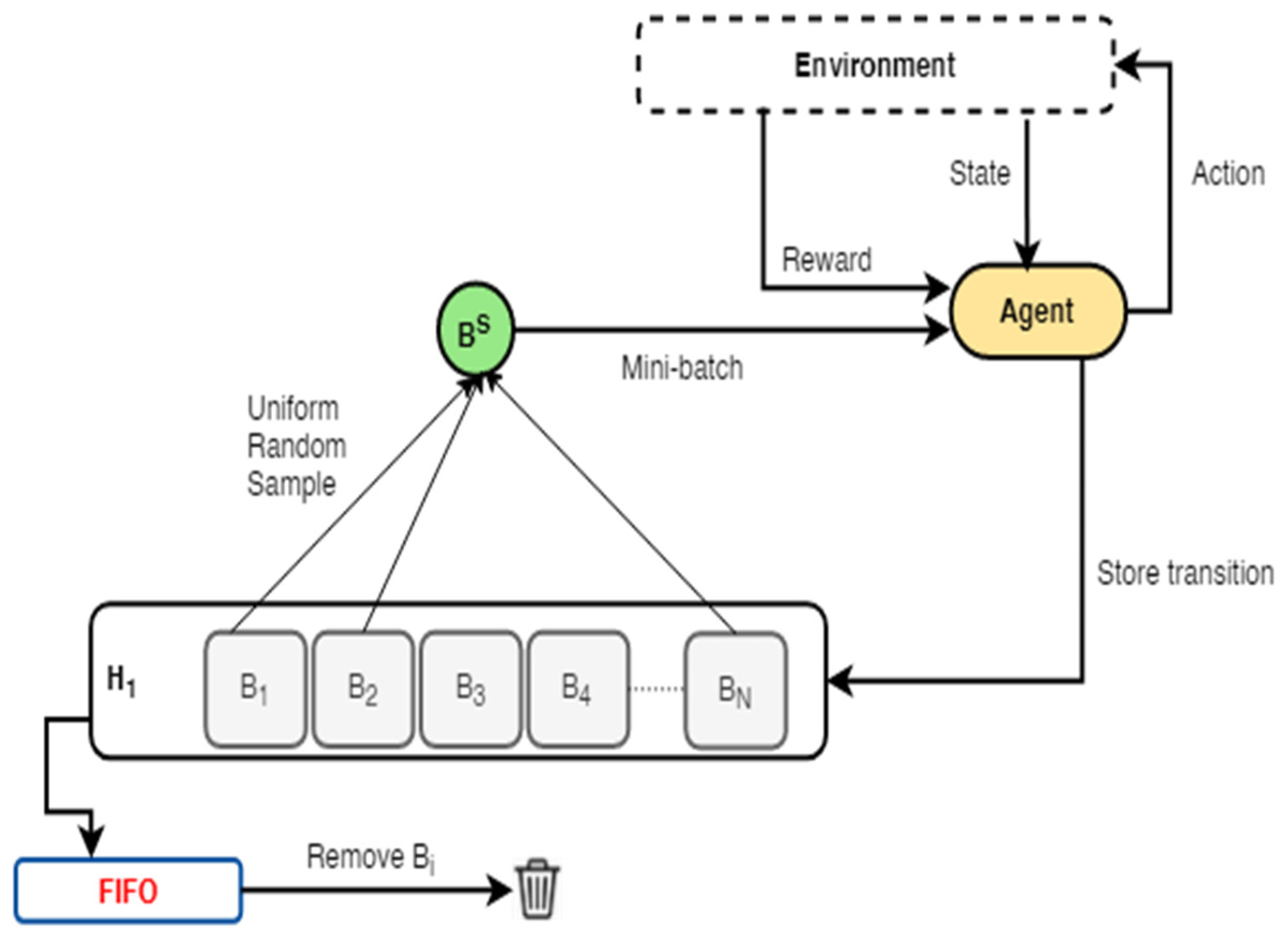
3.1.1. ERO Framework
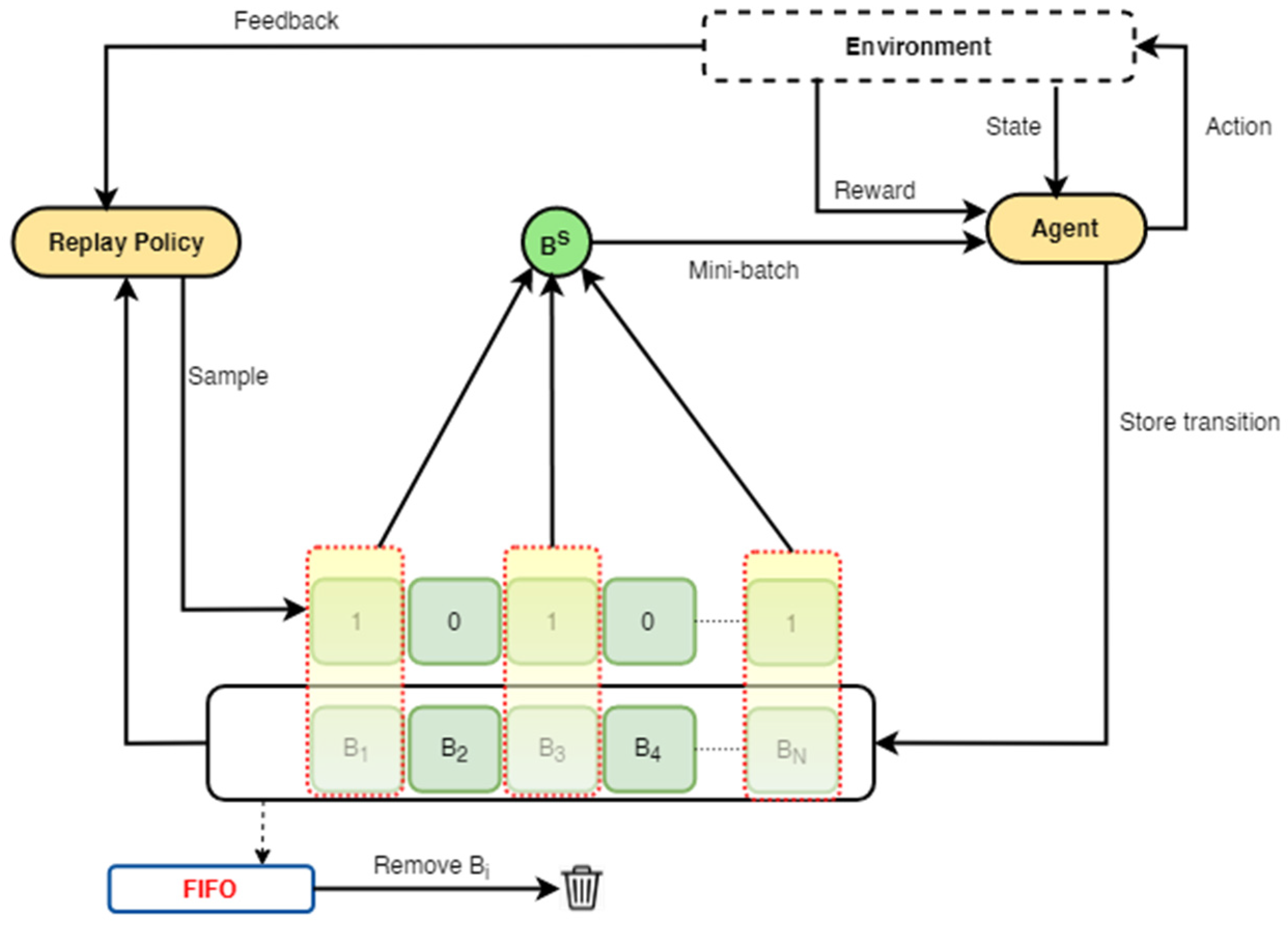
3.1.2. Alternating Transition Selection Framework
| Algorithm 1: ERO-ATSC with TSC |
| Given: An off-policy RL algorithm DDPG Sampling strategies (S1, S2) from replay where: S1 and S2 samples with ERO Return strategies (F1, F2) where F1 and F2 are FIFO and Enhanced-FIFO Reward threshold (Rt), sampling ratio (), mini-batch size (Mb) |
| 1: Initialise DDPG and replay buffer H1, H2 |
| 2: observe state (S0) and choose action (a0) using DDPG |
| 3: for episode =1, M do |
| 4: observer (st; rt; st+1) |
| 5: store transition (st, at, rt, st+1) in H1 to follow ERO |
| 6: if rt > Rt then |
| 7: store transition (st, at, rt, st+1) in H2 to follow ERO |
| 8: end if |
| 9: for t = 1; T do |
| 10: if size (H2) > Mb then |
| 11: with S1, S2, and sampling ratio λ, sample transition from H1 and H2 |
| 12: else |
| 13: with S1, sample transition from H1 |
| 14: end if |
| 15: update weight according to DDPG |
| 16: end for |
| 17: if H1 is full then |
| 18: use F2 |
| 19: end if |
| 20: if H2 is full then |
| 21: use F1 |
| 22: end if |
| 23: end for |
4. Method
4.1. Environmental Setup
4.2. Parameter Settings
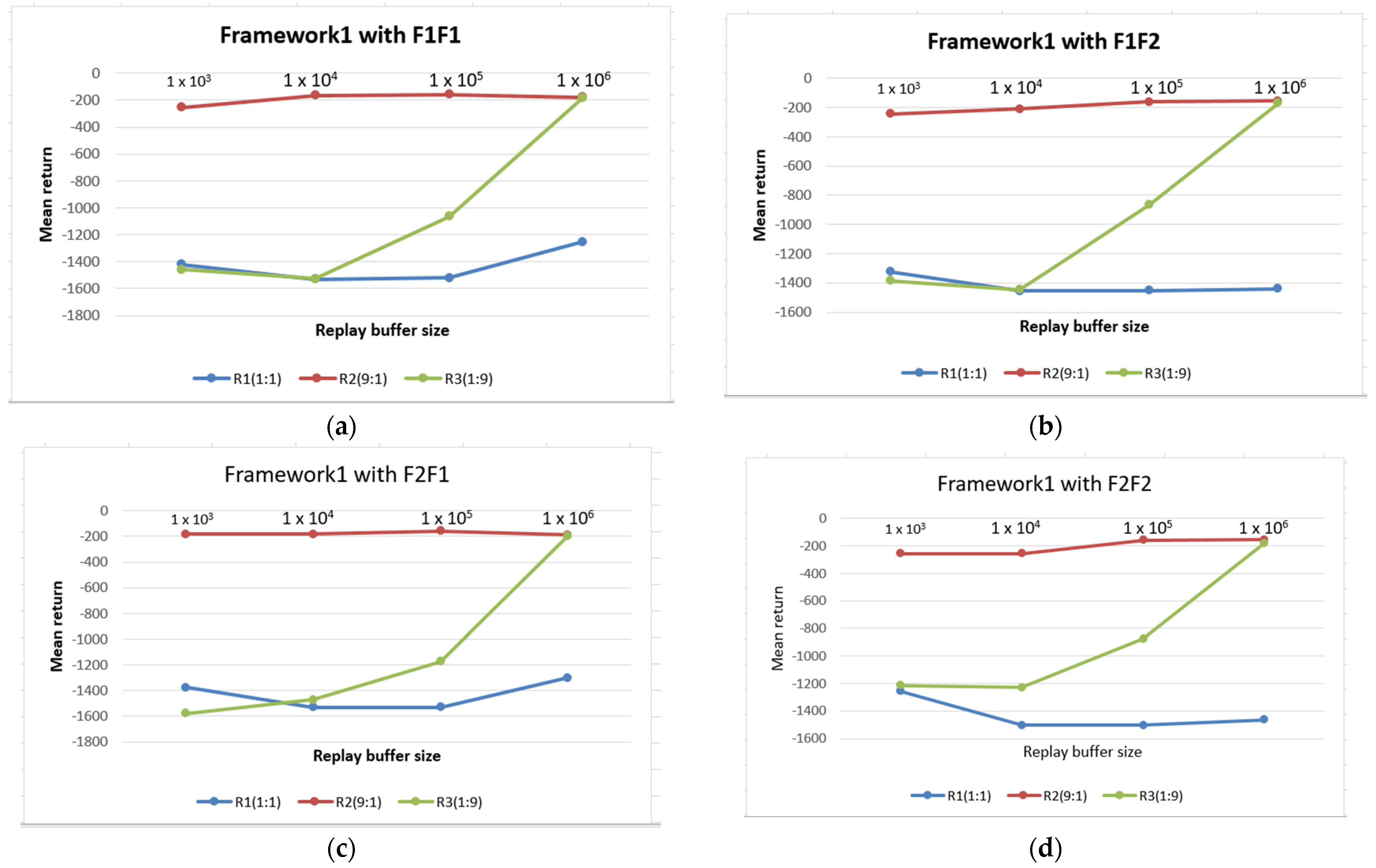
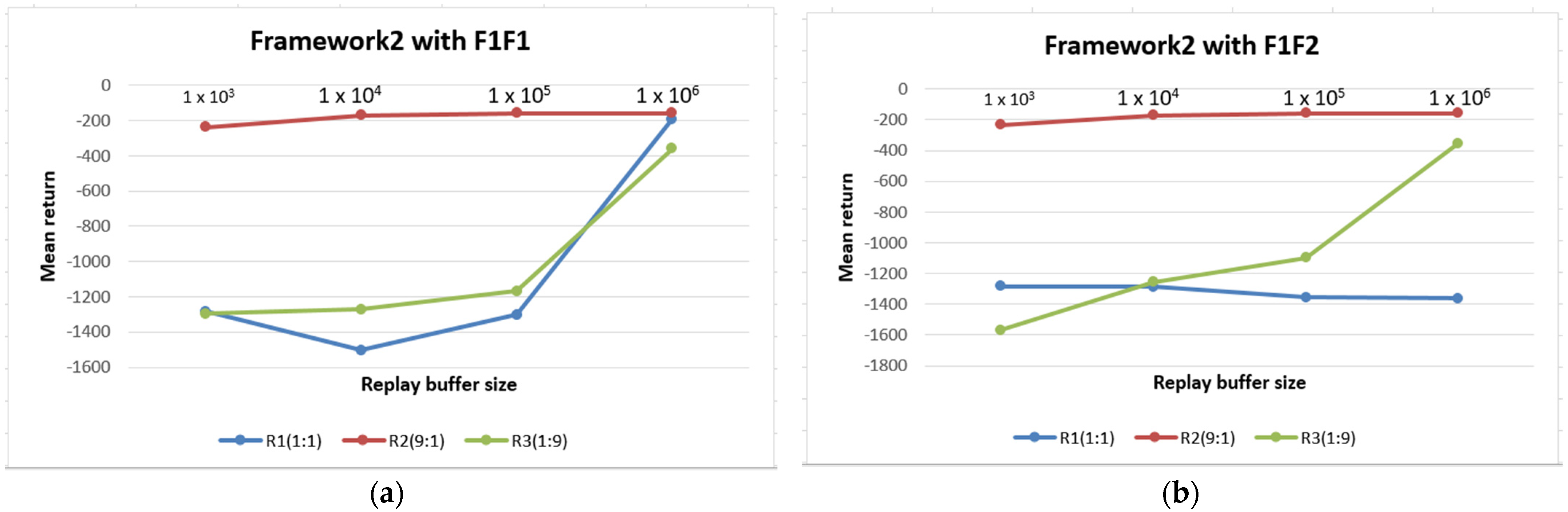
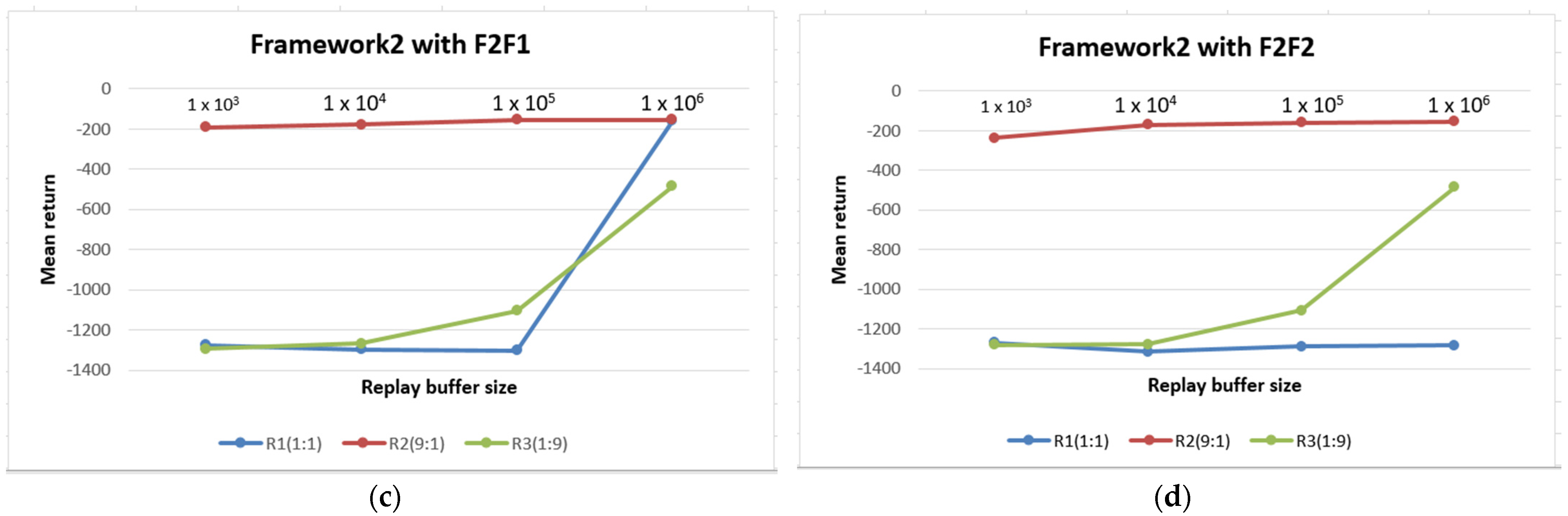
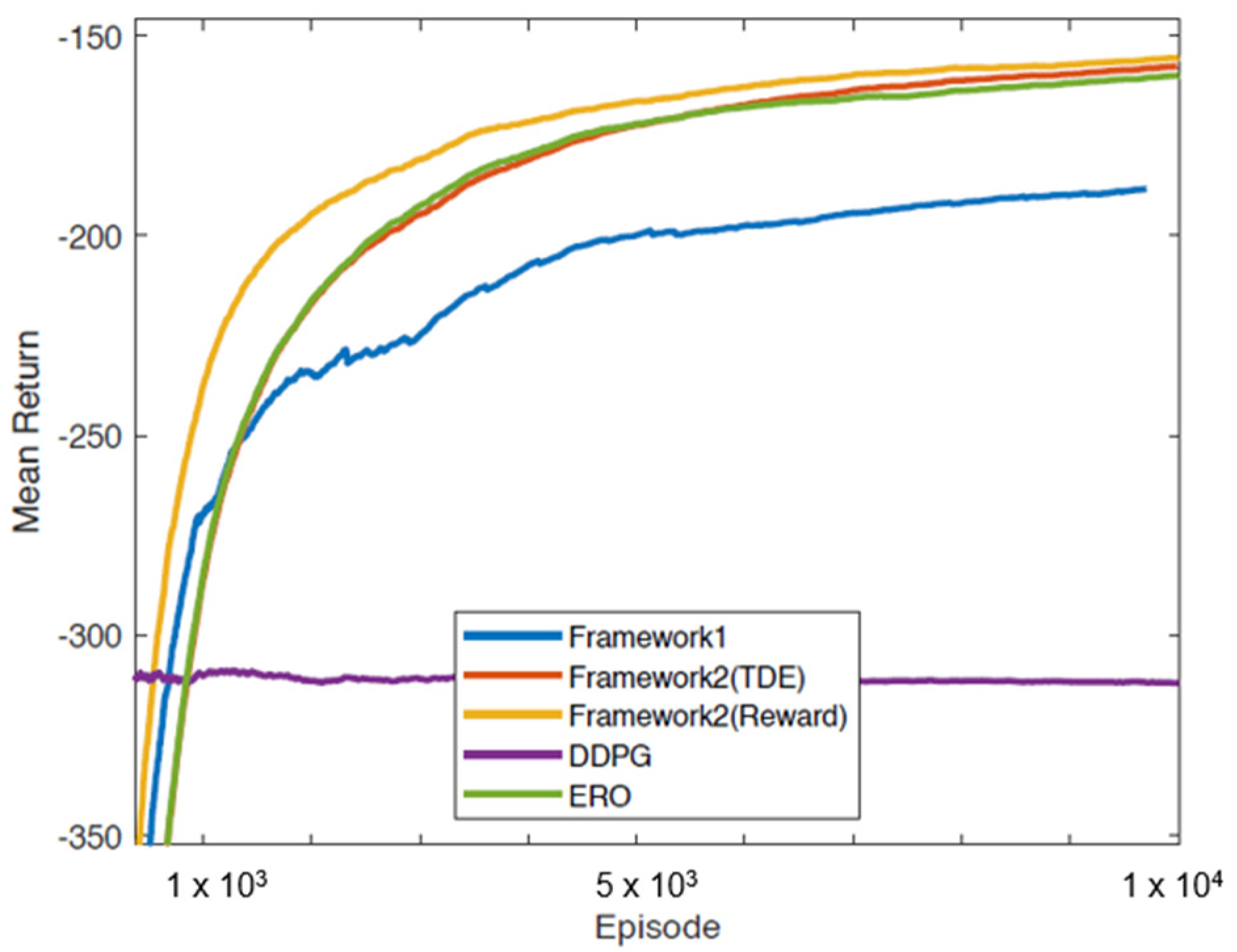
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Barto, A.; Thomas, P.; Sutton, R. Some Recent Applications of Reinforcement Learning. In Proceedings of the Eighteenth Yale Workshop on Adaptive and Learning Systems, New Haven, CT, USA, 21–23 June 2017. [Google Scholar]
- Wu, J.; He, H.; Peng, J.; Li, Y.; Li, Z. Continuous reinforcement learning of energy management with deep q network for a power-split hybrid electric bus. Appl. Energy 2018, 222, 799–811. [Google Scholar] [CrossRef]
- Wu, X.; Chen, H.; Wang, J.; Troiano, L.; Loia, V.; Fujita, H. Adaptive stock trading strategies with deep reinforcement learning methods. Inf. Sci. 2020, 538, 142–158. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S.; Yin, G. Reinforcement learning in healthcare: A survey. ACM Comput. Surv. 2021, 55, 1–36. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Perez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Lin, L.-J. Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- De Bruin, T.; Kober, J.; Tuyls, K.; Babuska, R. Experience selection in deep reinforcement learning for control. J. Mach. Learn. Res. 2018, 19, 1–56. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Casas, N. Deep deterministic policy gradient for urban traffic light control. arXiv 2017, arXiv:1703.09035. [Google Scholar]
- Zhang, S.; Sutton, R.S. A deeper look at experience replay. arXiv 2017, arXiv:1712.01275. [Google Scholar]
- Lin, Z.; Zhao, T.; Yang, G.; Zhang, L. Episodic memory deep q-networks. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 2433–2439. [Google Scholar]
- Isele, D.; Cosgun, A. Selective experience replay for lifelong learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Brittain, M.; Bertram, J.; Yang, X.; Wei, P. Prioritized sequence experience replay. arXiv 2019, arXiv:1905.12726. [Google Scholar]
- Zha, D.; Lai, K.-H.; Zhou, K.; Hu, X. Experience replay optimization. arXiv 2019, arXiv:1906.08387. [Google Scholar]
- Sun, P.; Zhou, W.; Li, H. Attentive experience replay. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5900–5907. [Google Scholar]
- Han, J.; Jo, K.; Lim, W.; Lee, Y.; Ko, K.; Sim, E.; Cho, J.; Kim, S. Reinforcement learning guided by double replay memory. J. Sens. 2021, 2021, 6652042. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- French, R. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Rolnick, D.; Ahuja, A.; Schwarz, J.; Lillicrap, T.; Wayne, G. Experience replay for continual learning. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, CA, USA, 8–14 December 2019. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef] [Green Version]
- Han, Y.; Huang, G.; Song, S.; Yang, L.; Wang, H.; Wang, Y. Dynamic neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7436–7456. [Google Scholar] [CrossRef]
- De Bruin, T.; Kober, J.; Tuyls, K.; Babuška, R. The importance of experience replay database composition in deep reinforcement learning. In Proceedings of the Deep Reinforcement Learning Workshop, Montréal, ON, Canada, 11 December 2015. [Google Scholar]
- Kwon, T.; Chang, D.E. Prioritized stochastic memory management for enhanced reinforcement learning. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Jeju, Republic of Korea, 24–26 June 2018; pp. 206–212. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Moore, A.W.; Atkeson, C.G. Prioritized sweeping: Reinforcement learning with less data and less time. Mach. Learn. 1993, 13, 103–130. [Google Scholar] [CrossRef]
- Quan, J.; Budden, D.; Barth-Maron, G.; Hessel, M.; Van Hasselt, H.; Silver, D. Distributed prioritized experience replay. arXiv 2018, arXiv:1803.00933. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Olin-Ammentorp, W.; Sokolov, Y.; Bazhenov, M. A dual-memory architecture for reinforcement learning on neuromorphic platforms. Neuromorphic Comput. Eng. 2021, 1, 024003. [Google Scholar] [CrossRef]
- Ko, W.; Chang, D.E. A dual memory structure for efficient use of replay memory in deep reinforcement learning. In Proceedings of the 2019 19th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 15–18 October 2019; pp. 1483–1486. [Google Scholar]
- Raffin, A.; Hill, A.; Ernestus, M.; Gleave, A.; Kanervisto, A.; Dormann, N. Stable baselines3. J. Mach. Learn. Res. 2021, 22, 120138. [Google Scholar]








| Notation | Explanation |
|---|---|
| Function approximator | |
| Replay buffer | |
| A transition in the replay buffer B | |
| Parameters of the function approximator | |
| Feature vector | |
| Priority score | |
| Cumulative reward | |
| Cumulative reward of current policy | |
| Cumulative reward of previous policy | |
| A specified batch size of sampled transitions |
| Hyperparameter | Value |
|---|---|
| Batch size | 64 |
| Actor learning rate | 1 × 10−4 |
| Critic learning rate | 1 × 10−3 |
| Gamma | 0.99 |
| Eval steps | 100 |
| Eval episodes | 10 |
| Environment complexity (seed) | 1 × 106 |
| Notation | Explanation |
|---|---|
| H1 | The first replay buffer |
| H2 | The second replay buffer |
| F1 | First-In-First-Out (FIFO) |
| F2 | Enhanced FIFO |
| F1F1 | Both H1 and H2 use F1 |
| F1F2 | H1 uses F1 and H2 uses F2 |
| F2F2 | Both H1 and H2 use F2 |
| F2F1 | H1 uses F2 and H2 uses F1 |
| R1 | Experiences are selected from H1 and H2 with a ratio of 1:1 |
| R2 | Experiences are selected from H1 and H2 with a ratio of 9:1 |
| R3 | Experiences are selected from H1 and H2 with a ratio of 1:9 |
| Frameworks | F1F1 | F1F2 | F2F1 | F2F2 |
|---|---|---|---|---|
| Framework 1 | −188.42 | −191.34 | −177.50 | −206.28 |
| Framework 2 (Reward) | −180.103 | −179.95 | −170.71 | −180.31 |
| Framework2 (TDE) | −192.87 | −192.56 | −170.18 | −172.47 |
| Frameworks | 1 × 106 | 1 × 105 | 1 × 104 | 1 × 103 |
|---|---|---|---|---|
| Framework 1 | −188.28 | −156.43 | −182.50 | −182.76 |
| Framework 2 (Reward) | −155.43 | −155.46 | −-179.53 | −192.42 |
| Framework2 (TDE) | −157.58 | −160.97 | −173.80 | −188.39 |
| Environments | Framework 2 (Reward) | Framework 2 (TDE) |
|---|---|---|
| Pendulum-v0 | −155.43 | −157.58 |
| MountainCarContinuous-v0 | −1.86 | −1.87 |
| LunarLanderContinuous-v2 | −20.77 | −32.02 |
| BipedalWalker-v3 | −6.60 | −131.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Osei, R.S.; Lopez, D. Experience Replay Optimisation via ATSC and TSC for Performance Stability in Deep RL. Appl. Sci. 2023, 13, 2034. https://doi.org/10.3390/app13042034
Osei RS, Lopez D. Experience Replay Optimisation via ATSC and TSC for Performance Stability in Deep RL. Applied Sciences. 2023; 13(4):2034. https://doi.org/10.3390/app13042034
Chicago/Turabian StyleOsei, Richard Sakyi, and Daphne Lopez. 2023. "Experience Replay Optimisation via ATSC and TSC for Performance Stability in Deep RL" Applied Sciences 13, no. 4: 2034. https://doi.org/10.3390/app13042034