
Dynamic Computation Offloading with Deep Reinforcement Learning in Edge Network

Abstract
:1. Introduction
- We propose a novel dynamic computation offloading strategy, where the computation offloading and service migration are combined to select intermediate nodes with sufficient resources. This strategy can minimize the cost of task processing user requests.
- We model this kind of optimal intermediate node selection problem as an MDP and implement deep reinforcement learning algorithms to reduce the large MDP space and achieve fast decision-making.
- A large number of simulations are carried out to verify the effectiveness of this strategy in reducing both the delay and the energy consumption.
2. Related Work
2.1. Task Offloading in Edge Computing (EC)
2.2. Service Migration in Edge Computing (EC)
3. Modeling and Problem Formulation
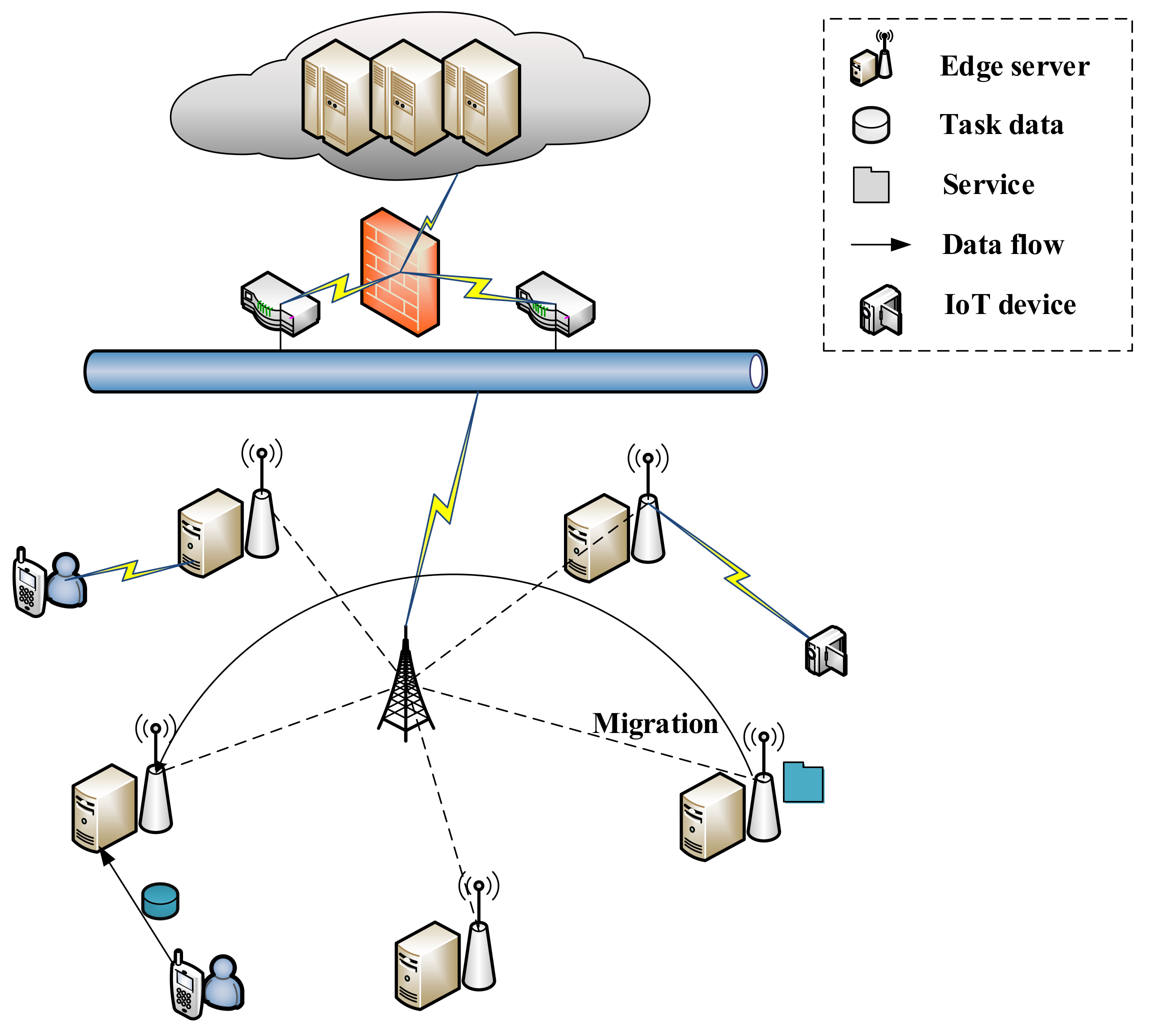
3.1. System Model
3.2. Delay Model
3.2.1. Task-Offloading Delay
3.2.2. Task Processing Delay
3.2.3. Task Queuing Delay
3.2.4. Service Migration Delay
3.3. Energy Consumption Model
3.3.1. Data Transmission Energy Consumption
3.3.2. Processing Energy Consumption
3.4. Problem Formulation
4. Algorithm
4.1. Dynamic Computation Offloading Strategy
- The workload on the local edge server is heavy, which significantly increases the task processing delay, leading to QoS reductions.
- The corresponding service for the task request is not configured on the local edge server.
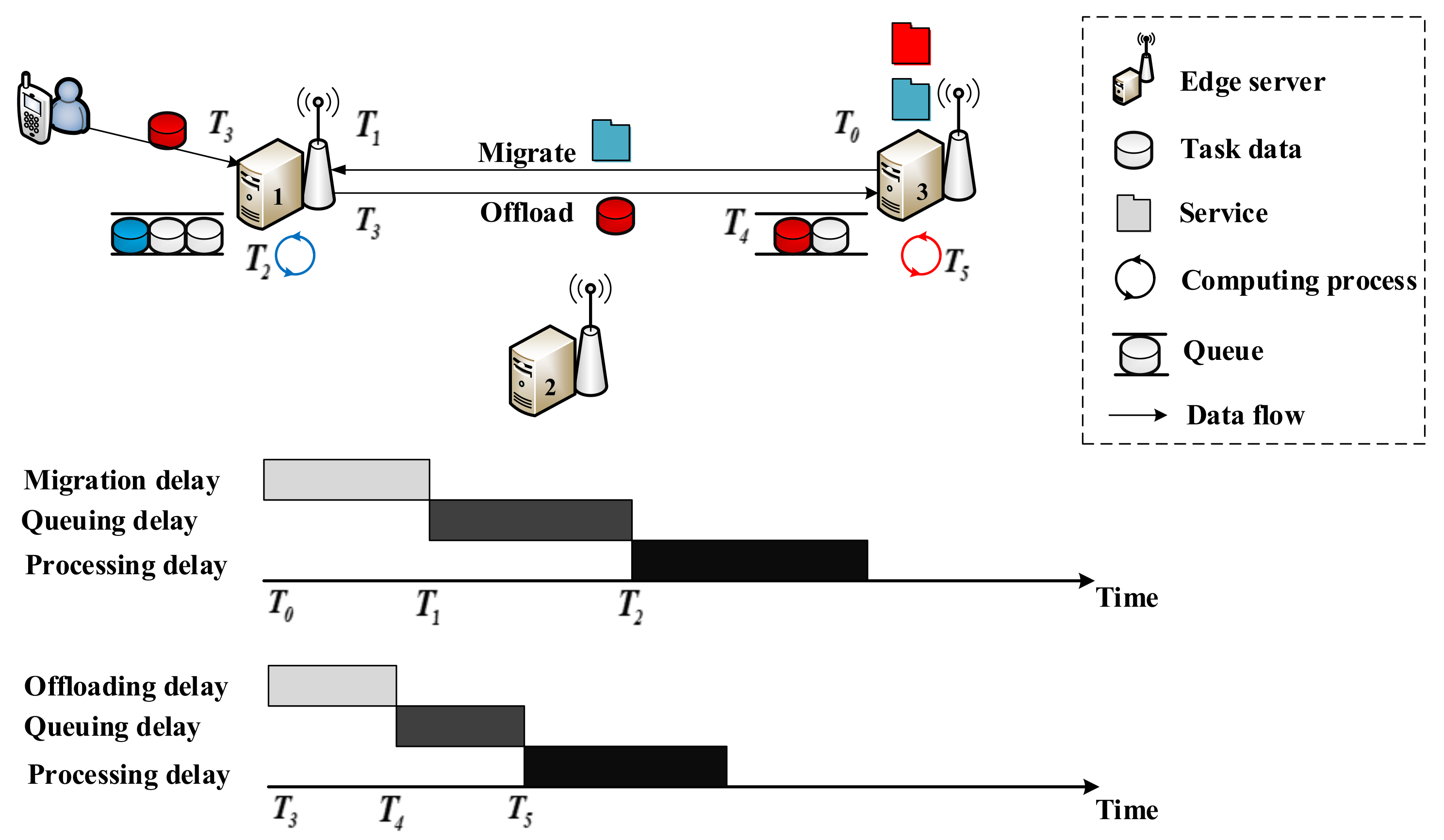
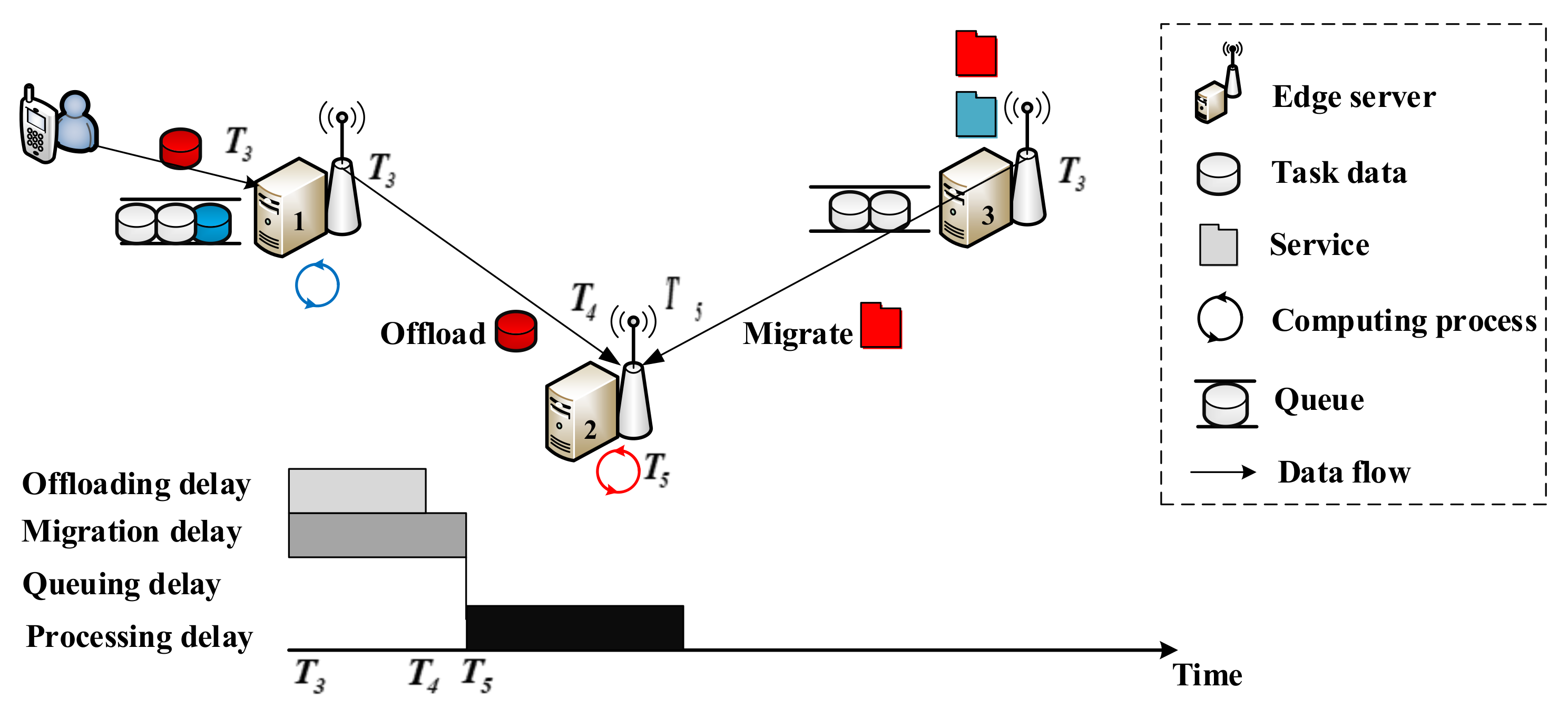
- Service migration process: the total transmission delay is the migration delay .
- Task offloading process: the total transmission delay is the offloading delay .
- Parallel service migration process and task offloading process: the total transmission delay is .
4.2. DQN-Based Computation Offloading Algorithm
4.2.1. Reinforcement Learning Settings
| Algorithm 1 Deep Q-Learning |
| Input: Output: 1: for episode = 1, N do 2: Observe 3: for i = 1, t do 4: /*Action Selection*/ 5: Select according pre-defined policy 6: Observe 7: Calculate by Equation (16) 8: /*Q-network Update*/ 9: Output 10: end for 11: end for |
4.2.2. Q-Network Update
| Algorithm 2 Q-Network Update |
| Input:
Output: 1: Store in 2: Sample 3: for in do 4: Calculate 5: Calculate target network’s Q-value 6: Compute the error between and 7: end for 8: 9: Occasionally reset 10: Return |
4.2.3. DCOS
| Algorithm 3 DCOS |
| Input:
Output: 1: for episode = 1, N do 2: Observe 3: 4: Initialize 5: for i = 1, t do 6: /*Action Selection*/ 7: Select according pre-defined policy 8: Observe 9: Calculate by Equation (16) 10: /*Call Algorithm 2*/ 11: 12: Output 13: end for 14: end for |
5. Experiments
5.1. Experimental Settings
- The time delay for task-offloading, service migration, and task-processing.
- The energy consumption for task-offloading, service migration and task-processing.
- Deep Deterministic Policy Gradient (DDPG) [33]: Task scheduling is only based on the task-offloading strategy, and the optimal offloading target node is output by the DQN network.
- Extensive Service Migration Model (ESM) [39]: The task is processed on the local node. If the node has not configured the related service, the system model performs the service migration according to the optimal policy related to the migration costs.
5.2. Performance Evaluation
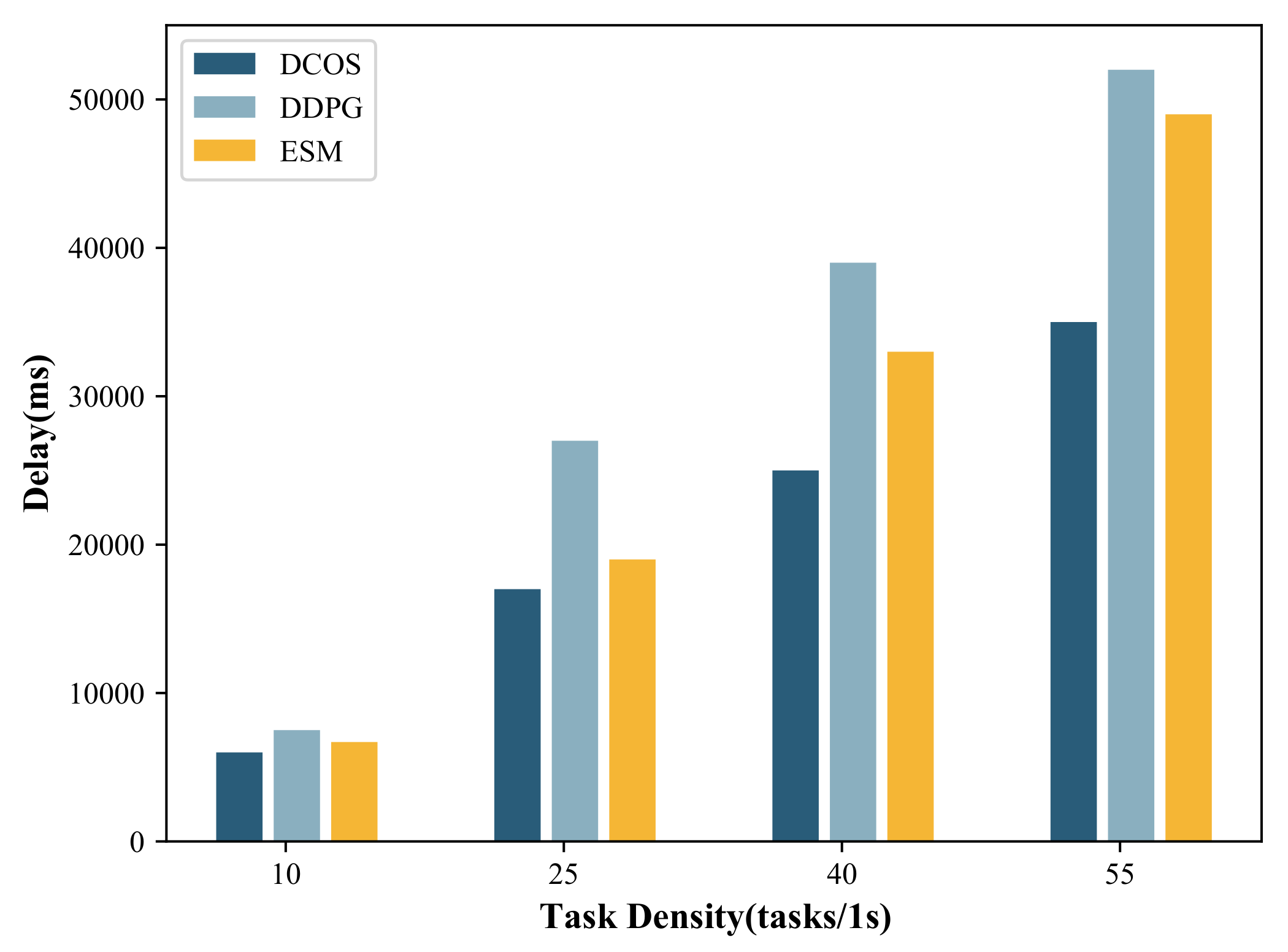
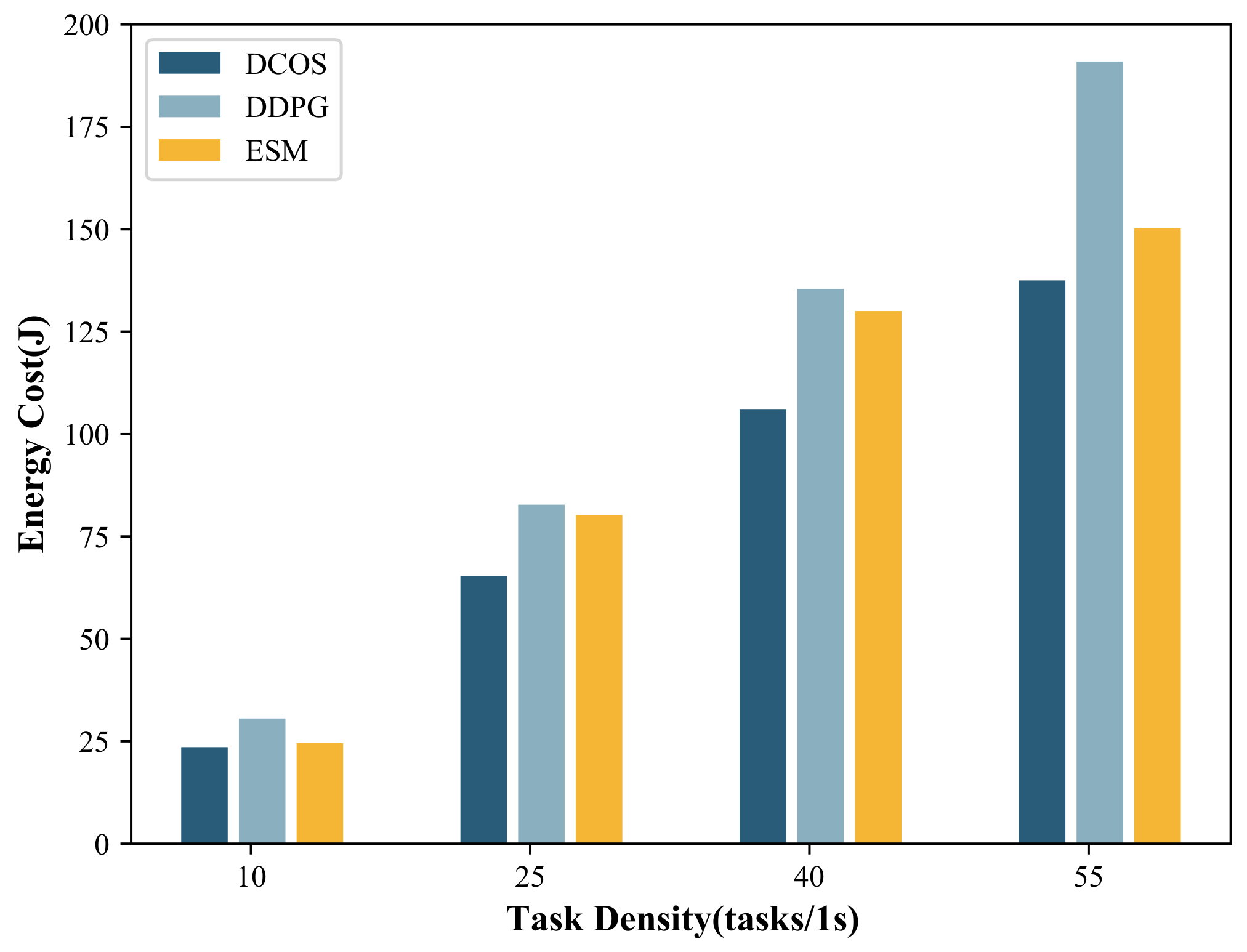
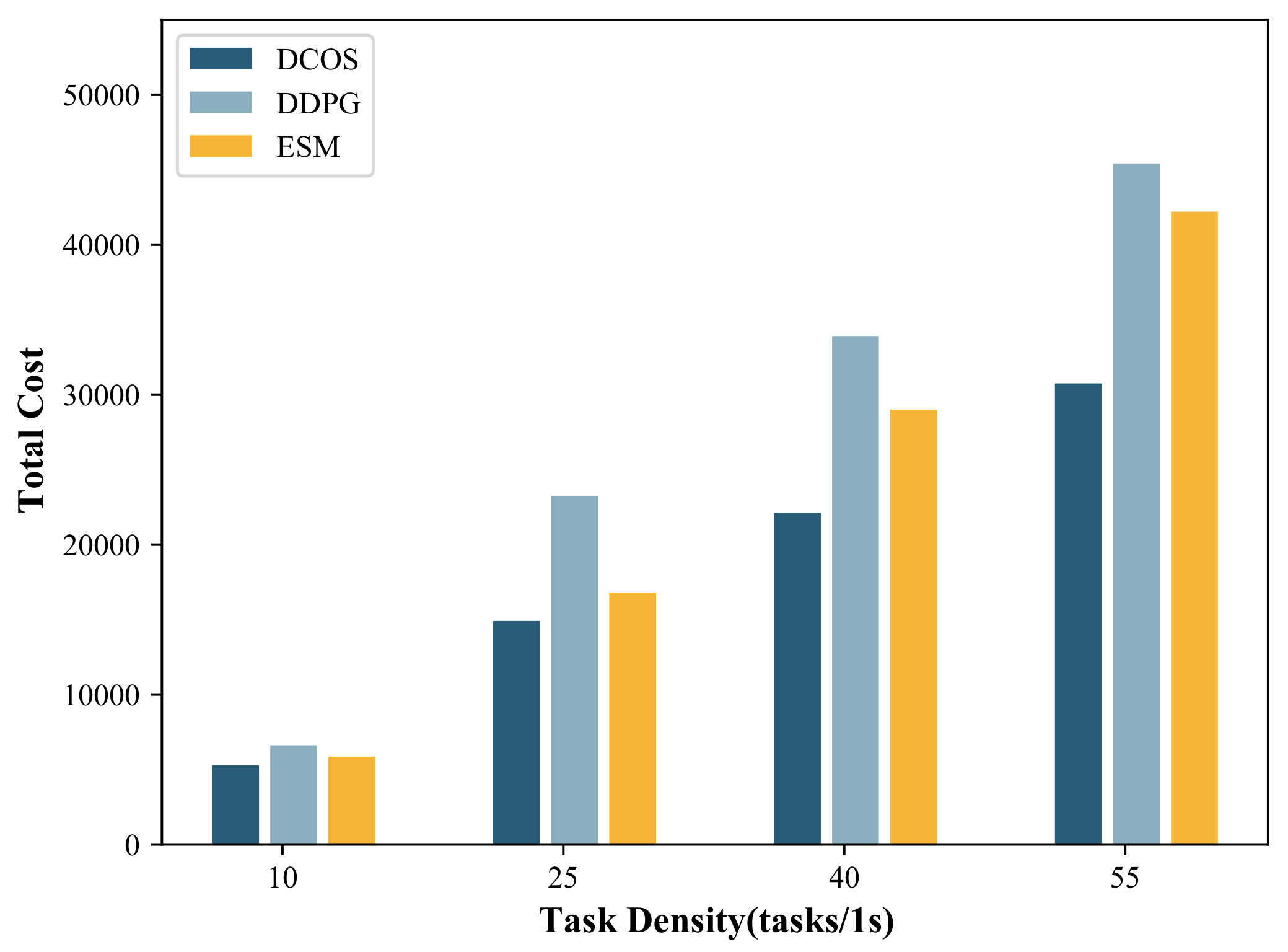
5.2.1. Influence of Task Density
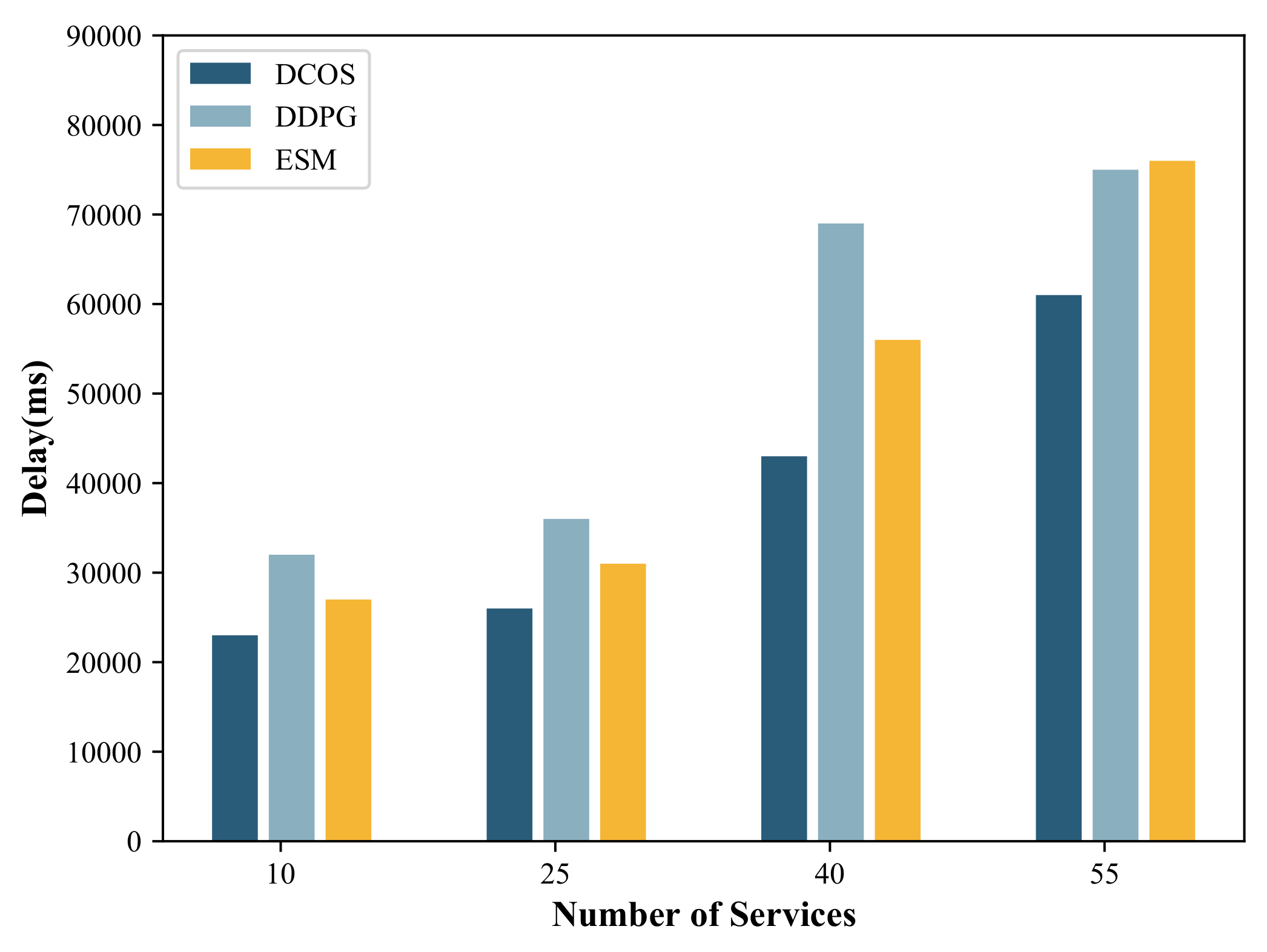
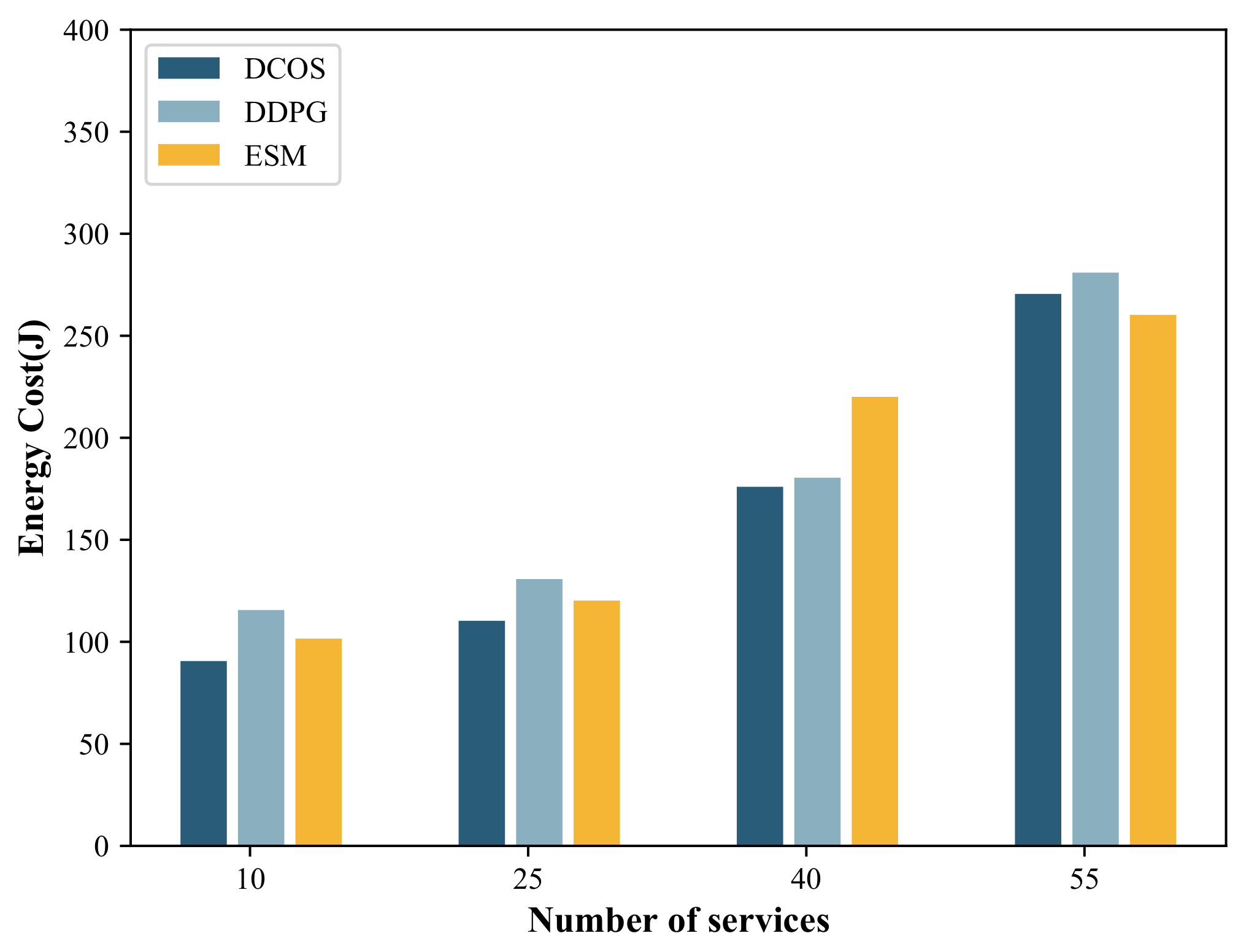
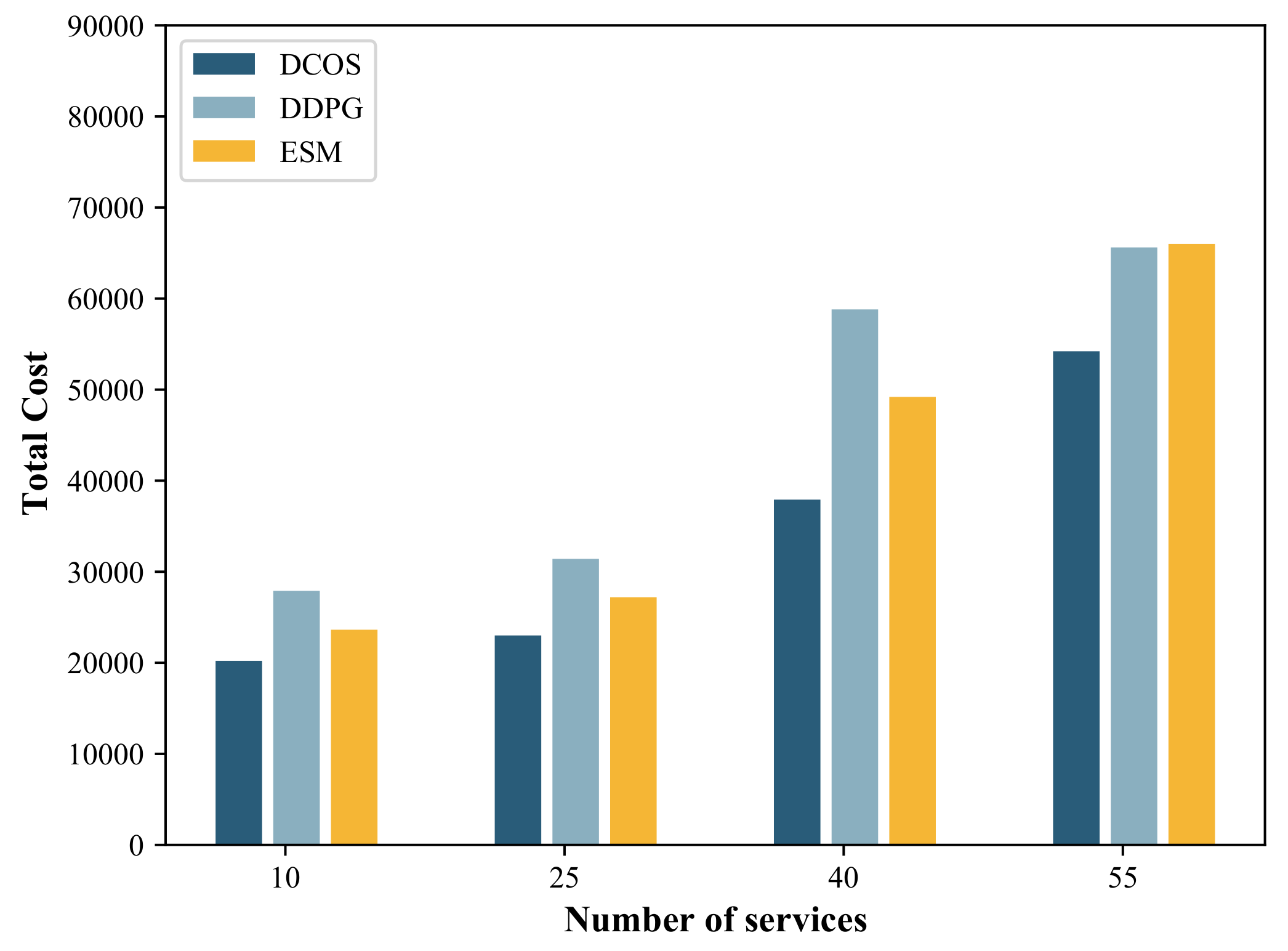
5.2.2. Influence of Number of Services
6. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Symbol | Description |
| F | Edge server set |
| n | Number of edge servers |
| The unique identifier of edge server i | |
| The location of edge server i | |
| The processing capability of edge server i | |
| The task list processed on edge server | |
| H | Service set |
| m | Number of service classes |
| The unique identifier of service i | |
| The capacity of service i | |
| T | Time period |
| The i-th time slot in T | |
| C | Task request set |
| k | Number of task requests |
| The unique identifier of task i | |
| The location of task i | |
| The capacity of task i | |
| The service type required by the task i | |
| The number of CPU circles required by the task i. | |
| B | Channel bandwidth |
| The background noise | |
| The energy consumption constant of the transmission and receiver electronics | |
| The energy consumption constant of the transmit amplifier | |
| Total delay | |
| Total energy consumption | |
| Total cost | |
| Weight of delay in | |
| Weight of energy consumption in | |
| System state during | |
| The best action to output after observing state | |
| Reward during | |
| State space | |
| Action space | |
| The Q-value of state-action pair | |
| Experience replay memory space | |
| Learning rate | |
| Discount parameter | |
| Loss function of the DNN | |
| Weights of the DNN |
References
- Wang, K.; Yang, Z.; Liang, B.; Ji, W. An intelligence optimization method based on crowd intelligence for IoT devices. Int. J. Crowd Sci. 2021, 5, 218–227. [Google Scholar] [CrossRef]
- Tang, J.; Wu, S.; Wei, L.; Liu, W.; Qin, T.; Zhou, Z.; Gu, J. Energy-Efficient Sensory Data Collection Based on Spatiotemporal Correlation in IoT Networks. Int. J. Crowd Sci. 2022, 6, 34–43. [Google Scholar] [CrossRef]
- Ma, X.; Li, Q.; Zou, L.; Peng, J.; Zhou, J.; Chai, J.; Jiang, Y.; Muntean, G.M. QAVA: QoE-Aware Adaptive Video Bitrate Aggregation for HTTP Live Streaming Based on Smart Edge Computing. Trans. Broadcast. 2022, 68, 661–676. [Google Scholar] [CrossRef]
- Lee, S.H. Real-time edge computing on multi-processes and multi-threading architectures for deep learning applications. Microprocess. Microsyst. 2022, 92, 104554. [Google Scholar] [CrossRef]
- Bonomi, F. Connected vehicles, the internet of things, and fog computing. In Proceedings of the The Eighth ACM International Workshop on Vehicular Inter-Networking (VANET), Las Vegas, NV, USA, 19–23 September 2011; pp. 13–15. [Google Scholar]
- Shakarami, A.; Shahidinejad, A.; Ghobaei-Arani, M. An autonomous computation offloading strategy in Mobile Edge Computing: A deep learning-based hybrid approach. J. Netw. Comput. Appl. 2021, 178, 102974. [Google Scholar] [CrossRef]
- Osei-Mensah, E.; Thabet, S.K.S.; Luo, C.; Asiedu-Ayeh, E.; Bamisile, O.; Nyantakyi, I.O.; Adun, H. A Novel Distributed Media Caching Technique for Seamless Video Streaming in Multi-Access Edge Computing Networks. Appl. Sci. 2022, 12, 4205. [Google Scholar] [CrossRef]
- Chen, S.; Zheng, Y.; Lu, W.; Varadarajan, V.; Wang, K. Energy-optimal dynamic computation offloading for industrial iot in fog computing. Trans. Green Commun. Netw. 2019, 4, 566–576. [Google Scholar] [CrossRef]
- Adhikari, M.; Mukherjee, M.; Srirama, S.N. DPTO: A deadline and priority-aware task offloading in fog computing framework leveraging multilevel feedback queueing. Internet Things J. 2019, 7, 5773–5782. [Google Scholar] [CrossRef]
- Liu, L.; Chang, Z.; Guo, X. Socially aware dynamic computation offloading scheme for fog computing system with energy harvesting devices. Internet Things J. 2018, 5, 1869–1879. [Google Scholar] [CrossRef]
- Zhang, G.; Shen, F.; Yang, Y.; Qian, H.; Yao, W. Fair task offloading among fog nodes in fog computing networks. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Qin, M.; Cheng, N.; Jing, Z.; Yang, T.; Xu, W.; Yang, Q.; Rao, R.R. Service-oriented energy-latency tradeoff for iot task partial offloading in mec-enhanced multi-rat networks. Internet Things J. 2020, 8, 1896–1907. [Google Scholar] [CrossRef]
- Bozorgchenani, A.; Tarchi, D.; Corazza, G.E. Centralized and distributed architectures for energy and delay efficient fog network-based edge computing services. Trans. Green Commun. Netw. 2018, 3, 250–263. [Google Scholar] [CrossRef]
- Yuan, X.; Xie, Z.; Tan, X. Computation Offloading in UAV-Enabled Edge Computing: A Stackelberg Game Approach. Sensors 2022, 22, 3854. [Google Scholar] [CrossRef] [PubMed]
- Shamsadini, A.; Entezari-Maleki, R. Time-aware MDP-based Service Migration in 5G Mobile Edge Computing. In Proceedings of the 2022 27th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 23–24 February 2022; pp. 1–5. [Google Scholar]
- Chen, X.; Bi, Y.; Chen, X.; Zhao, H.; Cheng, N.; Li, F.; Cheng, W. Dynamic Service Migration and Request Routing for Microservice in Multi-cell Mobile Edge Computing. Internet Things J. 2022, 9, 13126–13143. [Google Scholar] [CrossRef]
- Xu, M.; Zhou, Q.; Wu, H.; Lin, W.; Ye, K.; Xu, C. PDMA: Probabilistic service migration approach for delay-aware and mobility-aware mobile edge computing. Softw. Pract. Exp. 2022, 52, 394–414. [Google Scholar] [CrossRef]
- Xu, J.; Ma, X.; Zhou, A.; Duan, Q.; Wang, S. Path selection for seamless service migration in vehicular edge computing. Internet Things J. 2020, 7, 9040–9049. [Google Scholar] [CrossRef]
- Labriji, I.; Meneghello, F.; Cecchinato, D.; Sesia, S.; Perraud, E.; Strinati, E.C.; Rossi, M. Mobility aware and dynamic migration of mec services for the internet of vehicles. Trans. Netw. Serv. Manag. 2021, 18, 570–584. [Google Scholar] [CrossRef]
- Li, C.; Zhu, L.; Li, W.; Luo, Y. Joint edge caching and dynamic service migration in SDN based mobile edge computing. J. Netw. Comput. Appl. 2021, 177, 102966. [Google Scholar] [CrossRef]
- Yuan, Q.; Li, J.; Zhou, H.; Lin, T.; Luo, G.; Shen, X. A joint service migration and mobility optimization approach for vehicular edge computing. Trans. Veh. Technol. 2020, 69, 9041–9052. [Google Scholar] [CrossRef]
- Li, J.; Chen, L.; Chen, J. Enabling technologies for low-latency service migration in 5G transport networks. J. Opt. Commun. Netw. 2021, 13, A200–A210. [Google Scholar] [CrossRef]
- Liu, Z.; Xu, X. Latency-aware service migration with decision theory for Internet of Vehicles in mobile edge computing. Wirel. Netw. 2022. [Google Scholar] [CrossRef]
- Chen, S.; Tang, B.; Wang, K. Twin delayed deep deterministic policy gradient-based intelligent computation offloading for IoT. Digit. Commun. Netw. 2022, in press. [CrossRef]
- Wang, S.; Urgaonkar, R.; Zafer, M.; He, T.; Chan, K.; Leung, K.K. Dynamic service migration in mobile edge computing based on markov decision process. IEEE/ACM Trans. Netw. 2019, 27, 1272–1288. [Google Scholar] [CrossRef]
- Liu, J.; Ji, W. Evolution of Agents in the Case of a Balanced Diet. Int. J. Crowd Sci. 2022, 6, 1–6. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Hassabis, D. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Wang, H.; Xu, H.; Huang, H.; Chen, M.; Chen, S. Robust task offloading in dynamic edge computing. Trans. Mob. Comput. 2021, 22, 500–514. [Google Scholar] [CrossRef]
- Zhou, J.; Tian, D.; Sheng, Z.; Duan, X.; Shen, X. Distributed task offloading optimization with queueing dynamics in multi-agent mobile-edge computing networks. Internet Things J. 2021, 8, 12311–12328. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Min, G.; Zomaya, A.Y.; Georgalas, N. Fast adaptive task offloading in edge computing based on meta reinforcement learning. Trans. Parallel Distrib. Syst. 2020, 32, 242–253. [Google Scholar] [CrossRef]
- Tran-Dang, H.; Kim, D.S. Frato: Fog resource based adaptive task offloading for delay-minimizing iot service provisioning. Trans. Parallel Distrib. Syst. 2021, 32, 2491–2508. [Google Scholar] [CrossRef]
- Qinghua, Z.; Ying, C.; Jingya, Z.; Yong, L. Computation offloading Optimization in Edge Computing based on Deep Reinforcement Learning. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020; pp. 1552–1558. [Google Scholar]
- Kim, T.; Sathyanarayana, S.D.; Chen, S.; Im, Y.; Zhang, X.; Ha, S.; Joe-Wong, C. Modems: Optimizing edge computing migrations for user mobility. J. Sel. Areas Commun. 2022. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, Y.; Lok, T.M.; Huang, K. Multi-cell mobile edge computing: Joint service migration and resource allocation. Trans. Wirel. Commun. 2021, 20, 5898–5912. [Google Scholar] [CrossRef]
- Li, C.; Zhang, Y.; Gao, X.; Luo, Y. Energy-latency tradeoffs for edge caching and dynamic service migration based on DQN in mobile edge computing. J. Parallel Distrib. Comput. 2022, 166, 15–31. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, Z.; Gu, B.; Yamori, K.; Tanaka, Y. A deep reinforcement learning based approach for cost-and energy-aware multi-flow mobile data offloading. IEICE Trans. Commun. 2018, 101, 1625–1634. [Google Scholar] [CrossRef]
- Tang, Z.; Zhou, X.; Zhang, F.; Jia, W.; Zhao, W. Migration modeling and learning algorithms for containers in fog computing. Trans. Serv. Comput. 2018, 12, 712–725. [Google Scholar] [CrossRef]
- Park, S.W.; Boukerche, A.; Guan, S. A novel deep reinforcement learning based service migration model for mobile edge computing. In Proceedings of the 2020 IEEE/ACM 24th International Symposium on Distributed Simulation and Real Time Applications (DS-RT), Prague, Czech Republic, 14–16 September 2020; pp. 1–8. [Google Scholar]
- Jiao, Y.; Wang, C. A Blockchain-Based Trusted Upload Scheme for the Internet of Things Nodes. Int. J. Crowd Sci. 2022, 6, 92–97. [Google Scholar] [CrossRef]
- Dinh, H.T.; Lee, C.; Niyato, D.; Wang, P. A survey of mobile cloud computing: Architecture, applications, and approaches. Wireless communications and mobile computing. Wirel. Commun. Mob. Comput. 2013, 13, 1587–1611. [Google Scholar] [CrossRef]
- Willis, D.; Dasgupta, A.; Banerjee, S. Paradrop: A multi-tenant platform to dynamically install third party services on wireless gateways. In Proceedings of the 9th ACM Workshop on Mobility in the Evolving Internet Architecture, Maui, HI, USA, 11 September 2014; pp. 43–48. [Google Scholar]
- Bittencourt, L.F.; Lopes, M.M.; Petri, I.; Rana, O.F. Towards virtual machine migration in fog computing. In Proceedings of the 2015 10th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), Krakow, Poland, 4–6 November 2015; pp. 1–8. [Google Scholar]
- Wang, S.; Urgaonkar, R.; Zafer, M.; He, T.; Chan, K.; Leung, K.K. Dynamic service migration in mobile edge-clouds. In Proceedings of the 2015 IFIP Networking Conference (IFIP Networking), Toulouse, France, 20–22 May 2015; pp. 1–9. [Google Scholar]
- Heinzelman, W.R.; Chandrakasan, A.; Balakrishnan, H. Energy-efficient communication protocol for wireless microsensor networks. Wireless communications and mobile computing. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2000; p. 10. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. Commun. Surv. Tutorials 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Rouzbahani, H.M.; Karimipour, H.; Lei, L. Optimizing scheduling policy in smart grids using probabilistic Delayed Double Deep Q-Learning (P3DQL) algorithm. Sustain. Energy Technol. Assessments 2022, 53, 102712. [Google Scholar] [CrossRef]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of adam and beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Simulation Value | Description |
|---|---|---|
| 2 GHz | The processing capability of edge server | |
| random in [20, 30] ms | The i-th time slot | |
| n | 50 | The number of edge servers |
| k | 30 | The max number of task requests at each time slot |
| m | 50 | The number of service classes |
| random in [0.2, 5] MB | The capacity of service | |
| uniform in [2, 12] cycles/bit | The number of CPU circles required by the task | |
| random in [0.5, 5] MB | The task capacity | |
| B | 500 MHz | The channel bandwidth |
| −100 dBm | The background noise | |
| 0.8 | Weight of delay in total cost | |
| 0.2 | Weight of energy consumption in total cost | |
| 0.1 nJ/(bit × m2) | The energy consumption constant of the transmit amplifier | |
| 50 nj/bit | The energy consumption constant of the transmission and receiver electronics |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Y.; Li, X.; Wu, X.; Zhou, Z. Dynamic Computation Offloading with Deep Reinforcement Learning in Edge Network. Appl. Sci. 2023, 13, 2010. https://doi.org/10.3390/app13032010
Bai Y, Li X, Wu X, Zhou Z. Dynamic Computation Offloading with Deep Reinforcement Learning in Edge Network. Applied Sciences. 2023; 13(3):2010. https://doi.org/10.3390/app13032010
Chicago/Turabian StyleBai, Yang, Xiaocui Li, Xinfan Wu, and Zhangbing Zhou. 2023. "Dynamic Computation Offloading with Deep Reinforcement Learning in Edge Network" Applied Sciences 13, no. 3: 2010. https://doi.org/10.3390/app13032010