

On the Use of Deep Learning for Video Classification


Abstract
:1. Introduction
Contribution
- A more recent review was done by A. Anusya [5]; this review covers very few methods for video classification, clustering, and tagging. However, the review provided is not comprehensive and lacks concise information, coverage of topic, datasets, analysis of state-of-art approaches, and research limitations;
- Rani et al. [6] also conducted a recent review on video classification methods, and their review covered some recent video classification approaches and summary-based description of some recent works. This review also had some limitations including the missing analysis of recent state-of-art approaches and a very limited description of topics covered;
- Y. Li et al. [7] recently conducted a systematic and good review on live sport video classification. This review covers most of the recent works in live sport video classification, including the tools, video interaction features, and feature extraction methods. This is a comprehensive review, but the findings are not summarized in tables for research gaps and advantages and disadvantages of existing methods for a quick review. Moreover, this review is more specific to live sport video classification;
- A recent review was also done by Md Islam et al. [8]; in this review, they included all the methods for video classification, including deep learning. However, as the focus of review is not on deep learning approaches, these methods are therefore not completely covered in this review;
- Ullah. H. et al. [9] also conducted a recent systematic review; however, the focus of their review remained on human activity recognition;
- Z. Wu. [10] presented a concise review on video classification specific to deep learning methods. This review provides a good description on deep learning models, feature extraction tools, benchmark dataset, and comparison of existing methods for video classification. However, this review was conducted in the year 2016, and it does not cover the recent state-of-art deep learning methods;
- Q. Ren [11] conducted a simple review on video classification methods; however, the techniques covered in this review are not well described, and the review also lacks in the description of research gaps, benchmark datasets, limitations of existing methods, and performance metrics.
- A summary of state-of-art, CNN-based deep learning models for image analysis;
- An in-depth review of deep learning approaches for video classification highlighting the notable findings;
- A summary of breakthroughs in the automatic video classification task;
- Analysis of research trends from past towards future;
- Description of benchmark datasets, evaluations metrics, and comparison of recent state-of-art deep learning approaches in terms of performance.
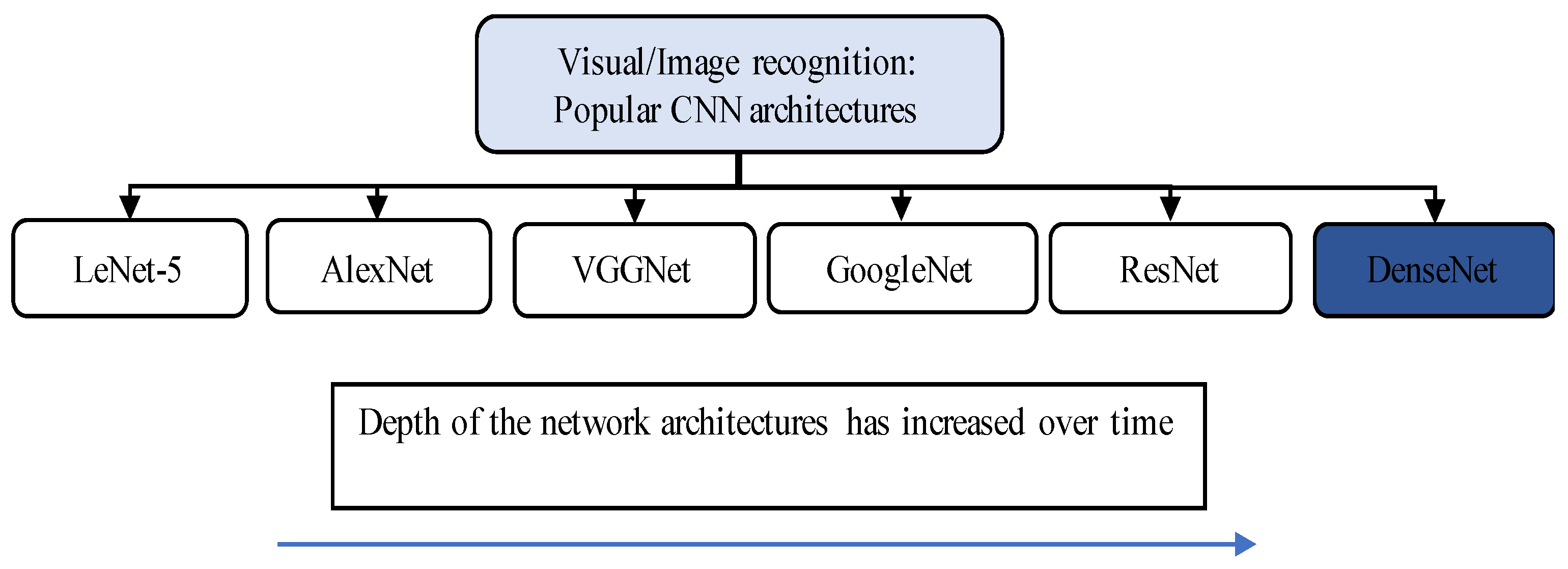
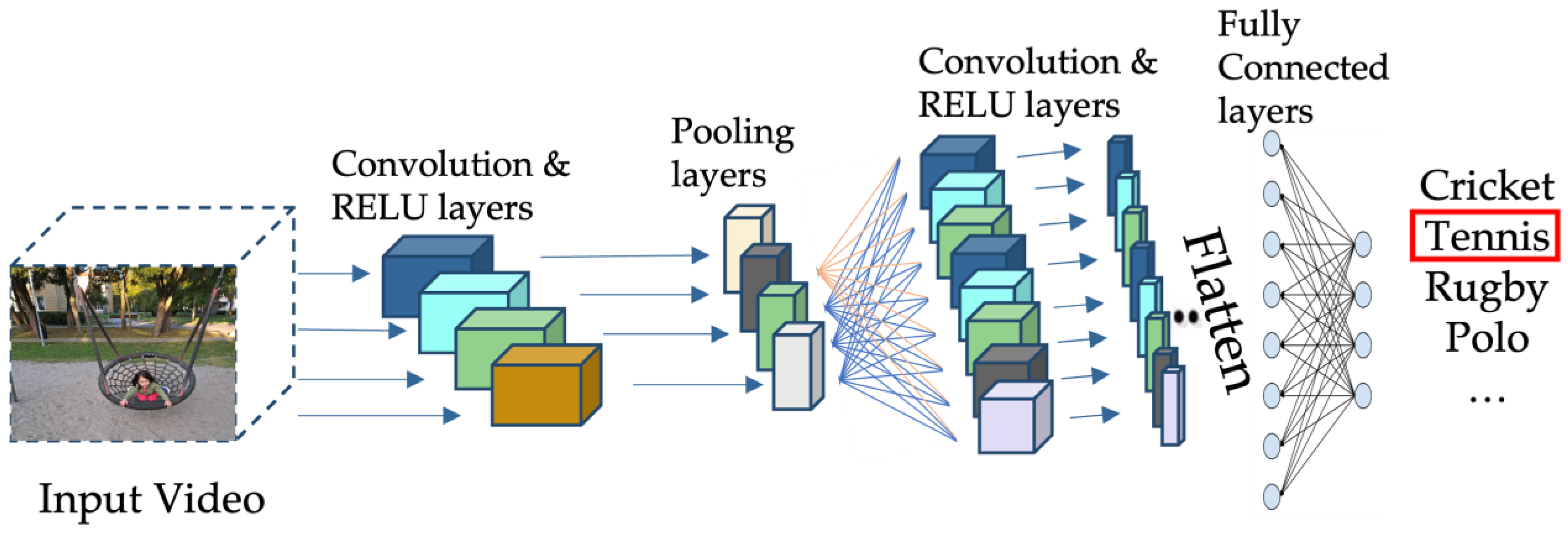
2. Convolutional Neural Networks (CNN) for Image Analysis
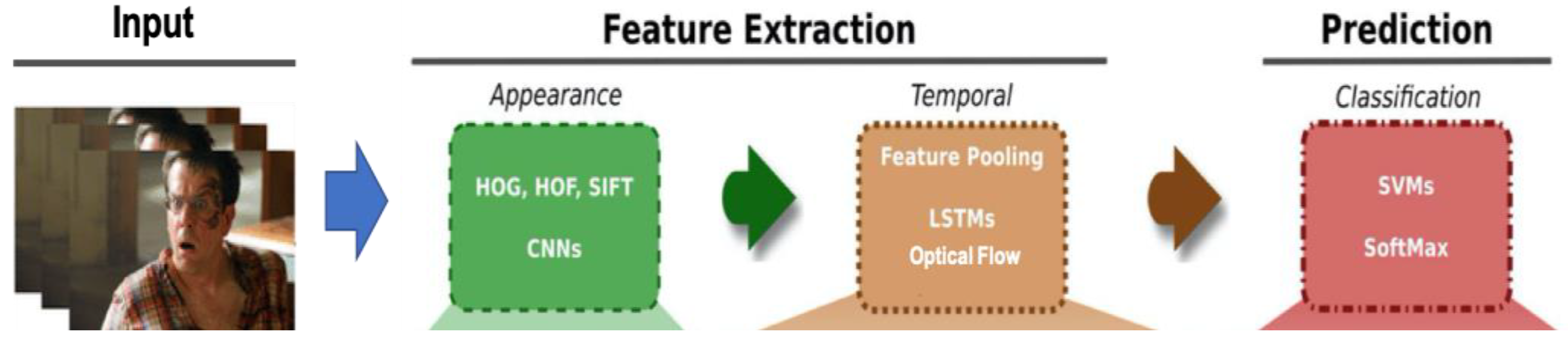
3. Video Classification
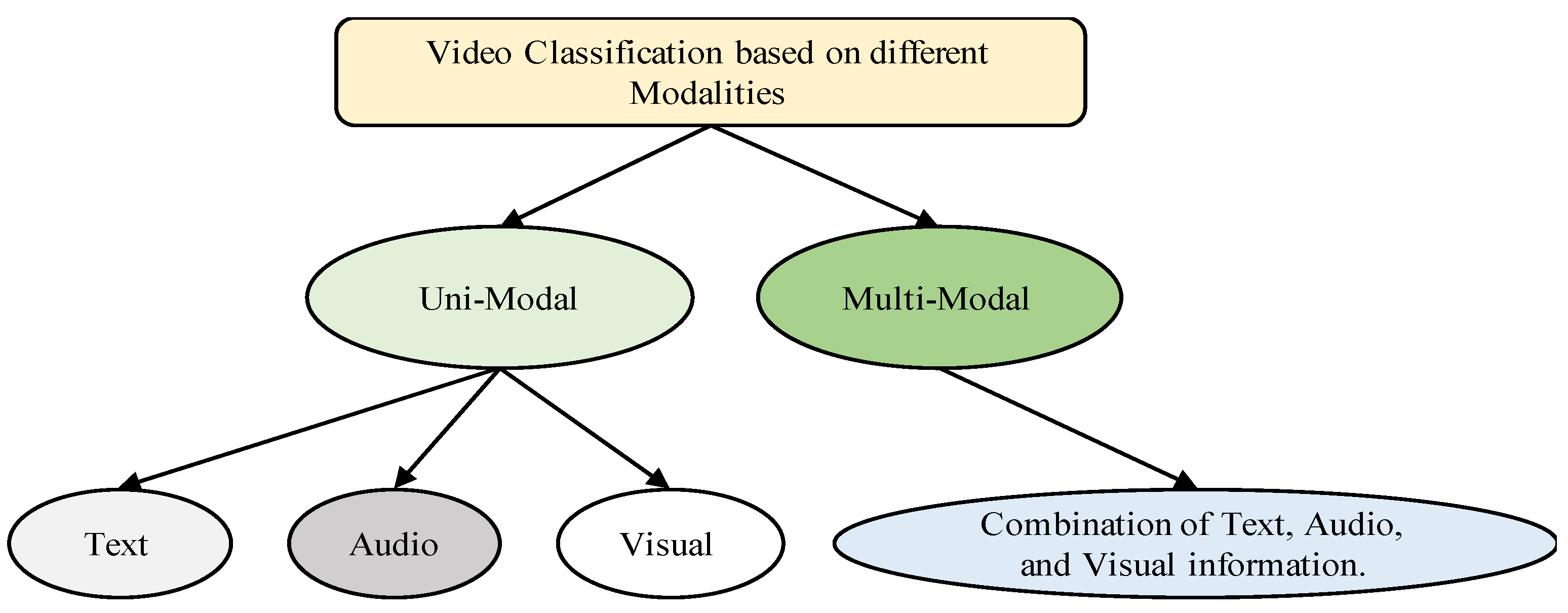
3.1. Video Data Modalities
3.2. Traditional Handcrafted Features
3.3. Deep Learning Frameworks
3.4. Breakthroughs
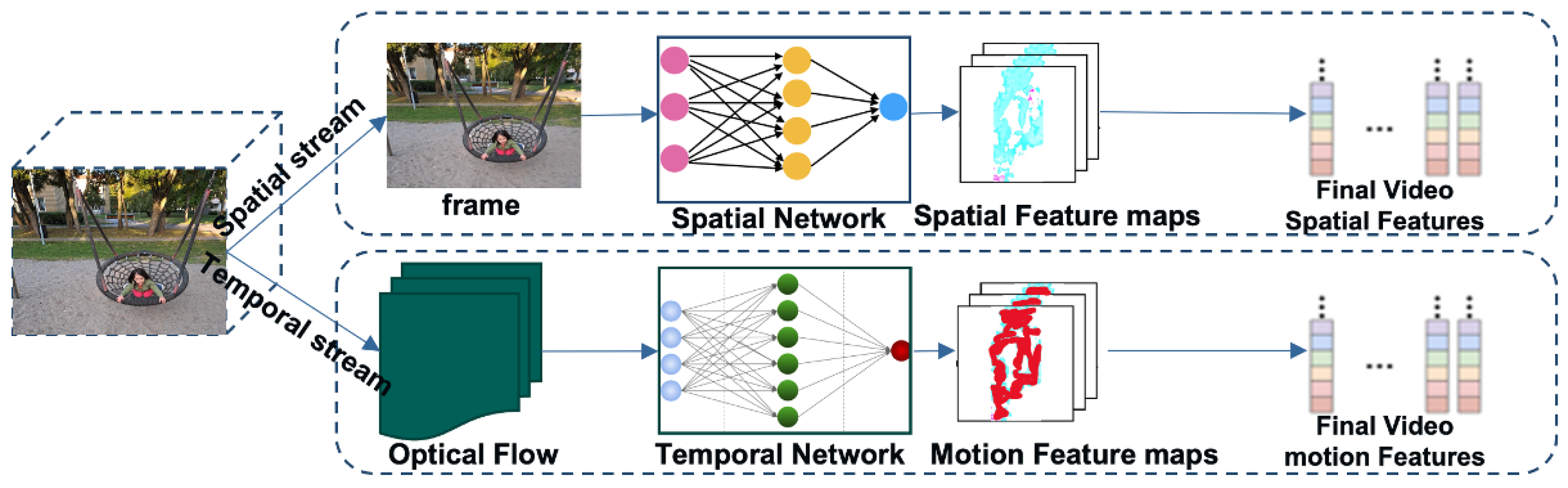
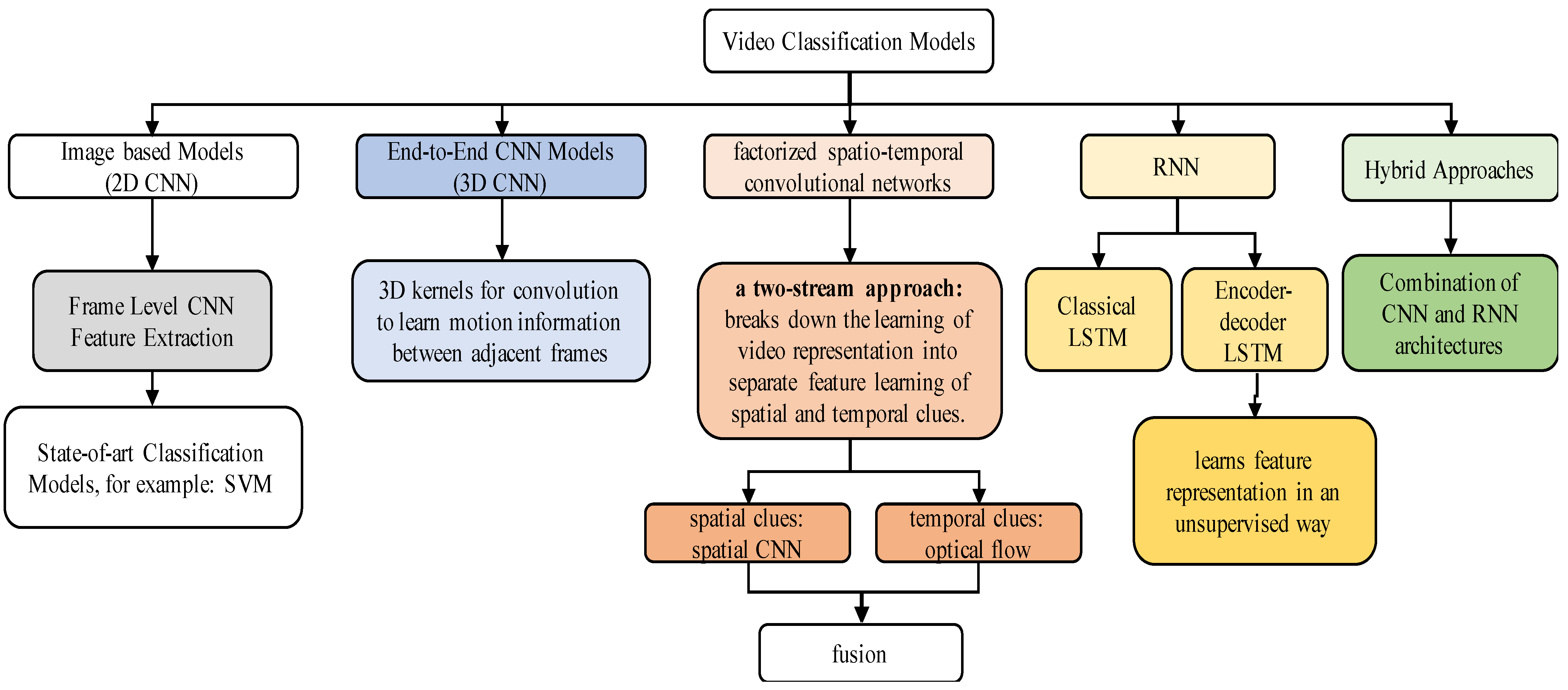
3.5. Basic Deep Learning Architectures for Video Classification
3.6. Developments in Video Classification over Time
3.7. Summary of Some Notable Deep Learning Frameworks Developments
3.8. Few-Shot Video Classification
3.9. Geometric Deep Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Features | Model | Evaluation | Dataset | Problem | Fusion | Findings |
|---|---|---|---|---|---|---|---|
| [57] | Automatic spatio-temporal features/self-learning. Temporal features captured both locally and globally. | Multiresolution CNN architecture. | By the fraction of test samples that contained at least one of the ground truth labels in the top k predictions. | Sports-1M, UCF-101. | Multi-class | Single frame, Early Fusion, Late Fusion, Slow Fusion. | When compared to a multilayer neural network with rectified linear units followed by a Softmax classifier built using histogram features, the Softmax classifier performed better (both local features such as texton, HOG, cuboids, etc., and global features such as color moments, and hue–saturation). |
| [108] | Visual (dense trajectory descriptors): A 30-d trajectory shape descriptor, a 96-d HOG descriptor, a 108-d HOF descriptor, and a 108-d MBH descriptor (local visual descriptors). Audio Features: MFCCs and Spectrogram SIFT. | Deep neural network (DNN). | Mean average precision (mAP). | Hollywood2, Columbia Consumer Videos (CCV), and CCV+. | Multi-class | Regularized fusion of multiple features. | Found better than dense trajectory features and classification utilizing the basic early fusion technique. |
| [109] | Tensor-Train Factorization (global representation for the whole sequence). | Recurrent neural network (RNN). | Classification accuracy. | UCF11, Hollywood2, YouTube Celebrities Face Data. | Multi-class | - | Tensor-Train layer-based RNN such as LSTM and GRU perform better than the plain RNN architectures for video classification. |
| [110] | Improved Fisher vector (iFV) and explicit feature maps to represent features of conv and fc layers. Long-term temporal information. | A multilayer and multimodal fusion framework of deep neural networks based on fully connected (FC)-RNN. | Classification accuracy. | UCF101, HMDB51. | Multi-class | Multilayer and multimodal fusion framework. | When compared to enhanced dense trajectories, which require a number of handcrafted procedures such as dense point tracking, camera motion estimation, person detection, and so on, the proposed FC-RNN obtained competitive results. |
| [50] | Convolutional temporal feature pooling architectures (conv pooling, late pooling, slow pooling, local pooling). Global video-level descriptors. | Two CNN architectures (AlexNet and GoogleNet) and LSTM. | By the fraction of test samples that contained at least one of the ground truth labels in the top k predictions. | UCF101, Sports 1 million. | Multi-class | Late fusion | (i) UCF-101 necessitates the utilization of optical flow. (ii) Optical flow is not always beneficial, especially when the videos are captured in the wild, such as Sports-1M. (iii) To make use of optical flow, a more advanced sequence processing architecture such as LSTM is required. (iv) The maximum documented performance is achieved by using LSTMs on both image frames and optical flow for the Sports-1M benchmark. |
| [111] | Spatiotemporal feature learning: a SMART block and ARTNet for short-term spatiotemporal feature learning with a possibility to explore long-term learning. | ARTNet by integrating the SMART block into the C3D-ResNet18 architecture, where SMART block architecture is composed of appearance branch and relationship branch. | Top-1 and Top-5 accuracy. | Kinetics, UCF101, and HMDB51. | Multi-class | Concatenation and reduction operation. | (i) In terms of spatiotemporal feature learning, SMART blocks outperform 3D convolutions (3D-CNN). (ii) In the case of ARTNet, supplementing RGB input with optical flow improves performance. (iii) The optical flow modality can give additional information. (iv) Optical flow’s high computing cost prevents it from being used in real-world systems. |
| [112] | Spatial, short-term motion and audio clues using CNN. Long-term temporal dynamics. (Multimodal features). | CNNs-LSTM model with multi-stream multi-class fusion process to adaptively determine the optimal fusion weights for generating the final scores of each class. | Classification accuracy. | UCF-101, Columbia Consumer Videos. | Multi-class | Multi-Stream Multi-Class Fusion. | Average fusion, kernel average fusion, weighted fusion, logistic regression fusion, and MKL fusion are all proven to be inferior to the proposed multi-stream multi-class fusion technique. |
| [113] | Two distinct layers: 1 × 1 × 1 conventional convolutions for channel interaction (but no local interaction) and k × k × k depth-wise convolutions for local spatiotemporal interactions (but not channel interaction). Global spatiotemporal average pooling layer. | Channel-separated convolutional network (CSN). Two models: interaction-preserved channel-separated network (ip-CSN) and interaction-reduced channel-separated network (ir-CSN). | Classification accuracy. | Sports1M and Kinetics. | Multi-class | - | (i) In 3D group convolutional networks, the number of channel interactions has a significant impact on accuracy. (ii) Separating channel interactions from spatiotemporal interactions in 3D convolutions improves accuracy and reduces computing cost. (iii) Three-dimensional channel-separated convolutions offer regularization and avoid overfitting. |
| [114] | The 3D network is optimized with three loss functions: (i) cross-entropy (CE) loss, (ii) pseudo-CE loss, and (iii) soft CE loss. 2D Image and 3D video model capture short and long visual descriptors. | Semi-supervised learning (VideoSSL) with 3D ResNet-18. | Top-1 | UCF101, HMDB51, and Kinetics. | Multi-class | - | (i) For 3D video classification, a direct application of current semi-supervised algorithms (which were initially designed for 2D imagery) cannot yield adequate results. (ii) The accuracy of 3D-CNN models is much improved by a calibrated use of object appearance indicators for semi-supervised learning. |
| [115] | Modal- and channel-wise attentions. | Expansion-squeeze excitation fusion network | Accuracy, confusion matrix | ETRI-ACTIVITY3D, NUT RGB+D | Multi-class | Multi-modal | (i) Modal-fusion nets (M-Nets) and channel-fusion nets (C-Nets) are capable of capturing the modal and channel-wise dependencies between features in order to improve the discriminative power of features via modal and channel-wise ESEs. (ii) By adding the penalty of the difference between the minimum prediction losses on the single modalities and the prediction loss on the fused modality, multi-modal loss (ML) can further enforce the consistency between the single-modal features and the fused multi-modal features. |
4. Benchmark Datasets, Evaluation Metrics, and Comparison of Existing State-of-the-Art for Video Classification
4.1. Benchmark Datasets for Video Classification
4.2. Performance Evaluation Metrics for Video Classification
4.3. Comparison of Some Existing Approaches on UCF-101 Dataset
4.4. Comparison of Different Deep Learning Architectures
5. Key Findings
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Samek, W.; Montavon, G.; Lapuschkin, S.; Anders, C.J.; Muller, K.-R. Explaining Deep Neural Networks and Beyond: A Review of Methods and Applications. Proc. IEEE 2021, 109, 247–278. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Minallah, N.; Tariq, M.; Aziz, N.; Khan, W.; Rehman, A.; Belhaouari, S.B. On the performance of fusion based planet-scope and Sentinel-2 data for crop classification using inception inspired deep convolutional neural network. PLoS ONE 2020, 15, e0239746. [Google Scholar] [CrossRef]
- Rehman, A.; Bermak, A. Averaging Neural Network Ensembles Model for Quantification of Volatile Organic Compound. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 848–852. [Google Scholar] [CrossRef]
- Anushya, A. Video Tagging Using Deep Learning: A Survey. Int. J. Comput. Sci. Mob. Comput. 2020, 9, 49–55. [Google Scholar]
- Rani, P.; Kaur, J.; Kaswan, S. Automatic Video Classification: A Review. EAI Endorsed Trans. Creat. Technol. 2020, 7, 163996. [Google Scholar] [CrossRef]
- Li, Y.; Wang, C.; Liu, J. A Systematic Review of Literature on User Behavior in Video Game Live Streaming. Int. J. Environ. Res. Public Health 2020, 17, 3328. [Google Scholar] [CrossRef]
- Islam, M.S.; Sultana, M.S.; Roy, U.K.; al Mahmud, J. A review on Video Classification with Methods, Findings, Performance, Challenges, Limitations and Future Work. J. Ilm. Tek. Elektro Komput. Dan Inform. 2021, 6, 47. [Google Scholar] [CrossRef]
- Ullah, H.A.; Letchmunan, S.; Zia, M.S.; Butt, U.M.; Hassan, F.H. Analysis of Deep Neural Networks for Human Activity Recognition in Videos—A Systematic Literature Review. IEEE Access 2021, 9, 126366–126387. [Google Scholar] [CrossRef]
- Wu, Z.; Yao, T.; Fu, Y.; Jiang, Y.-G. Deep learning for video classification and captioning. In Frontiers of Multimedia Research; ACM: New York, NY, USA, 2017; pp. 3–29. [Google Scholar] [CrossRef]
- Ren, Q.; Bai, L.; Wang, H.; Deng, Z.; Zhu, X.; Li, H.; Luo, C. A Survey on Video Classification Methods Based on Deep Learning. DEStech Trans. Comput. Sci. Eng. 2019. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based Learning Applied to Document Recognition. Intell. Signal Process. 2001, 306–351. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 2, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Ian, G.; Yoshua, B.; Aaron, C. Deep Learning (Adaptive Computation and Machine Learning Series); The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Shah, A.M.; Yan, X.; Shah, S.A.A.; Mamirkulova, G. Mining patient opinion to evaluate the service quality in healthcare: A deep-learning approach. J. Ambient Intell. Humaniz Comput. 2020, 11, 2925–2942. [Google Scholar] [CrossRef]
- De Jong, R.J.; de Wit, J.J.M.; Uysal, F. Classification of human activity using radar and video multimodal learning. IET Radar Sonar Navig. 2021, 15, 902–914. [Google Scholar] [CrossRef]
- Truong, B.T.; Venkatesh, S.; Dorai, C. Automatic genre identification for content-based video categorization. In Proceedings of the International Conference on Pattern Recognition 2000, Barcelona, Spain, 3–7 September 2000; Volume 15, pp. 230–233. [Google Scholar] [CrossRef]
- Huang, C.; Fu, T.; Chen, H. Text-based video content classification for online video-sharing sites. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 891–906. [Google Scholar] [CrossRef]
- Lee, K.; Ellis, D.P.W. Audio-based semantic concept classification for consumer video. IEEE Trans. Audio Speech Lang Process. 2010, 18, 1406–1416. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, J.; Wang, Y. Classification TV programs based on audio information using hidden Markov model. In Proceedings of the 1998 IEEE 2nd Workshop on Multimedia Signal Processing, Redondo Beach, CA, USA, 7–9 December 1998; pp. 27–32. [Google Scholar] [CrossRef]
- Laptev, I.; Lindeberg, T. Space-time interest points. In Proceedings of the IEEE International Conference on Computer Vision, 2003, Nice, France, 13–16 October 2003; Volume 1, pp. 432–439. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar] [CrossRef]
- Scovanner, P.; Ali, S.; Shah, M. A 3-dimensional sift descriptor and its application to action recognition. In Proceedings of the ACM International Multimedia Conference and Exhibition, Augsburg, Germany, 25–29 September 2007; pp. 357–360. [Google Scholar] [CrossRef]
- Kläser, A.; Marszałek, M.; Schmid, C. A spatio-temporal descriptor based on 3D-gradients. In Proceedings of the BMVC 2008—British Machine Vision Conference 2008, Leeds, UK, September 2008. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3952, pp. 428–441. [Google Scholar] [CrossRef]
- Sadanand, S.; Corso, J.J. Action bank: A high-level representation of activity in video. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1234–1241. [Google Scholar] [CrossRef]
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior recognition via sparse spatio-temporal features. In Proceedings of the 2nd Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; Volume 2005, pp. 65–72. [Google Scholar] [CrossRef]
- Willems, G.; Tuytelaars, T.; Van Gool, L. An efficient dense and scale-invariant spatio-temporal interest point detector. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5303, pp. 650–663. [Google Scholar] [CrossRef]
- Wang, L.; Qiao, Y.; Tang, X. Video action detection with relational dynamic-poselets. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8693, pp. 565–580. [Google Scholar] [CrossRef]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar] [CrossRef]
- Kar, A.; Rai, N.; Sikka, K.; Sharma, G. AdaScan: Adaptive scan pooling in deep convolutional neural networks for human action recognition in videos. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5699–5708. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal multiplier networks for video action recognition. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 7445–7454. [Google Scholar] [CrossRef]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3D residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9912, pp. 20–36. [Google Scholar] [CrossRef]
- Wang, Y.; Long, M.; Wang, J.; Yu, P.S. Spatiotemporal pyramid network for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Lan, Z.; Zhu, Y.; Hauptmann, A.G.; Newsam, S. Deep Local Video Feature for Action Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops; 2017; pp. 1219–1225. [Google Scholar] [CrossRef]
- Duta, I.C.; Ionescu, B.; Aizawa, K.; Sebe, N. Spatio-temporal vector of locally max pooled features for action recognition in videos. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3205–3214. [Google Scholar] [CrossRef]
- Shen, J.; Huang, Y.; Wen, M.; Zhang, C. Toward an Efficient Deep Pipelined Template-Based Architecture for Accelerating the Entire 2-D and 3-D CNNs on FPGA. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 1442–1455. [Google Scholar] [CrossRef]
- Duta, I.C.; Nguyen, T.A.; Aizawa, K.; Ionescu, B.; Sebe, N. Boosting VLAD with double assignment using deep features for action recognition in videos. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 2210–2215. [Google Scholar] [CrossRef]
- Xu, Z.; Yang, Y.; Hauptmann, A.G. A discriminative CNN video representation for event detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1798–1807. [Google Scholar] [CrossRef] [Green Version]
- Girdhar, R.; Ramanan, D.; Gupta, A.; Sivic, J.; Russell, B. ActionVLAD: Learning spatio-temporal aggregation for action classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 971–980. [Google Scholar]
- Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving deeper into convolutional networks for learning video representations. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar] [CrossRef]
- Srivastava, N.; Mansimov, E.; Salakhutdinov, R. Unsupervised learning of video representations using LSTMs. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 1, pp. 843–852. [Google Scholar]
- Ng, J.Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar] [CrossRef]
- Taylor, G.W.; Fergus, R.; LeCun, Y.; Bregler, C. Convolutional learning of spatio-temporal features. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6316, pp. 140–153. [Google Scholar] [CrossRef]
- Le, Q.V.; Zou, W.Y.; Yeung, S.Y.; Ng, A.Y. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3361–3368. [Google Scholar] [CrossRef]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for human action recognition. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7065, pp. 29–39. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Zha, S.; Luisier, F.; Andrews, W.; Srivastava, N.; Salakhutdinov, R. Exploiting Image-trained CNN Architectures for Unconstrained Video Classification. In Proceedings of the BMVC, Swansen, UK, 7–10 September 2015; pp. 60.1–60.13. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.F. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 4489–4497. [Google Scholar] [CrossRef] [Green Version]
- Shu, X.; Tang, J.; Qi, G.-J.; Liu, W.; Yang, J. Hierarchical Long Short-Term Concurrent Memory for Human Interaction Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1110–1118. [Google Scholar] [CrossRef]
- Shu, X.; Zhang, L.; Qi, G.-J.; Liu, W.; Tang, J. Spatiotemporal Co-Attention Recurrent Neural Networks for Human-Skeleton Motion Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3300–3315. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 1, 568–576. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; 2016; pp. 1933–1941. [Google Scholar] [CrossRef]
- Wu, Z.; Jiang, Y.-G.; Wang, X.; Ye, H.; Xue, X.; Wang, J. Fusing Multi-Stream Deep Networks for Video Classification. arXiv 2015, arXiv:1509.06086. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Shan, K.; Wang, Y.; Tang, Z.; Chen, Y.; Li, Y. MixTConv: Mixed Temporal Convolutional Kernels for Efficient Action Recognition. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1751–1756. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, X.; Jiang, Y.G.; Ye, H.; Xue, X. Modeling spatial-Temporal clues in a hybrid deep learning framework for video classification. In Proceedings of the MM 2015—2015 ACM Multimedia Conference, Brisbane, Australia, 26–30 October 2015; pp. 461–470. [Google Scholar] [CrossRef]
- Tanberk, S.; Kilimci, Z.H.; Tukel, D.B.; Uysal, M.; Akyokus, S. A Hybrid Deep Model Using Deep Learning and Dense Optical Flow Approaches for Human Activity Recognition. IEEE Access 2020, 8, 19799–19809. [Google Scholar] [CrossRef]
- Alhersh, T.; Stuckenschmidt, H.; Rehman, A.U.; Belhaouari, S.B. Learning Human Activity From Visual Data Using Deep Learning. IEEE Access 2021, 9, 106245–106253. [Google Scholar] [CrossRef]
- Kopuklu, O.; Kose, N.; Gunduz, A.; Rigoll, G. Resource efficient 3D convolutional neural networks. In Proceedings of the 2019 International Conference on Computer Vision Workshop, ICCVW 2019, Seoul, Korea, 27–28 October 2019; pp. 1910–1919. [Google Scholar] [CrossRef]
- Liu, H.; Bhanu, B. Pose-guided R-CNN for jersey number recognition in sports. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 2457–2466. [Google Scholar] [CrossRef]
- Huang, G.; Bors, A.G. Region-based non-local operation for video classification. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2020; pp. 10010–10017. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Biswas, A.; Jana, A.P.; Mohana; Tejas, S.S. Classification of objects in video records using neural network framework. In Proceedings of the International Conference on Smart Systems and Inventive Technology, ICSSIT 2018, Tirunelveli, India, 13–14 December 2018; pp. 564–569. [Google Scholar] [CrossRef]
- Jana, A.P.; Biswas, A.; Mohana. YOLO based detection and classification of objects in video records. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information and Communication Technology, RTEICT 2018, Bangalore, India, 18–19 May 2018; pp. 2448–2452. [Google Scholar] [CrossRef]
- Zhou, R.; Xia, D.; Wan, J.; Zhang, S. An intelligent video tag recommendation method for improving video popularity in mobile computing environment. IEEE Access 2020, 8, 6954–6967. [Google Scholar] [CrossRef]
- Khan, U.A.; Martinez-Del-Amor, M.A.; Altowaijri, S.M.; Ahmed, A.; Rahman, A.U.; Sama, N.U.; Haseeb, K.; Islam, N. Movie Tags Prediction and Segmentation Using Deep Learning. IEEE Access 2020, 8, 6071–6086. [Google Scholar] [CrossRef]
- Apostolidis, E.; Adamantidou, E.; Mezaris, V.; Patras, I. Combining adversarial and reinforcement learning for video thumbnail selection. In Proceedings of the ICMR 2021—2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Carta, S.; Giuliani, A.; Piano, L.; Podda, A.S.; Recupero, D.R. VSTAR: Visual Semantic Thumbnails and tAgs Revitalization. Expert Syst. Appl. 2022, 193, 116375. [Google Scholar] [CrossRef]
- Yang, Z.; Lin, Z. Interpretable video tag recommendation with multimedia deep learning framework. Internet Res. 2022, 32, 518–535. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, J.; Ye, X.; Jing, Q.; Wang, J.; Geng, Y. Few-Shot Transfer Learning With Attention Mechanism for High-Voltage Circuit Breaker Fault Diagnosis. IEEE Trans. Ind. Appl. 2022, 58, 3353–3360. [Google Scholar] [CrossRef]
- Zhong, C.; Wang, J.; Feng, C.; Zhang, Y.; Sun, J.; Yokota, Y. PICA: Point-wise Instance and Centroid Alignment Based Few-shot Domain Adaptive Object Detection with Loose Annotations. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 398–407. [Google Scholar] [CrossRef]
- Zhang, A.; Liu, F.; Liu, J.; Tang, X.; Gao, F.; Li, D.; Xiao, L. Domain-Adaptive Few-Shot Learning for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022. [Google Scholar] [CrossRef]
- Zhao, A.; Ding, M.; Lu, Z.; Xiang, T.; Niu, Y.; Guan, J.; Wen, J.R. Domain-Adaptive Few-Shot Learning. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021; pp. 1389–1398. [Google Scholar] [CrossRef]
- Gao, J.; Xu, C. CI-GNN: Building a Category-Instance Graph for Zero-Shot Video Classification. IEEE Trans. Multimedia 2020, 22, 3088–3100. [Google Scholar] [CrossRef]
- Zhu, L.; Yang, Y. Compound Memory Networks for Few-Shot Video Classification. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11211, pp. 782–797. [Google Scholar] [CrossRef]
- Hu, Y.; Gao, J.; Xu, C. Learning Dual-Pooling Graph Neural Networks for Few-Shot Video Classification. IEEE Trans. Multimedia 2021, 23, 4285–4296. [Google Scholar] [CrossRef]
- Cao, K.; Ji, J.; Cao, Z.; Chang, C.-Y.; Niebles, J.C. Few-Shot Video Classification via Temporal Alignment. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10615–10624. [Google Scholar] [CrossRef]
- Fu, Y.; Zhang, L.; Wang, J.; Fu, Y.; Jiang, Y.-G. Depth Guided Adaptive Meta-Fusion Network for Few-shot Video Recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1142–1151. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, L.; Qi, X.; Li, H.; Torr, P.H.S.; Koniusz, P. Few-Shot Action Recognition with Permutation-Invariant Attention. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12350, pp. 525–542. [Google Scholar] [CrossRef]
- Qi, M.; Qin, J.; Zhen, X.; Huang, D.; Yang, Y.; Luo, J. Few-Shot Ensemble Learning for Video Classification with SlowFast Memory Networks. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 3007–3015. [Google Scholar] [CrossRef]
- Fu, Y.; Wang, C.; Fu, Y.; Wang, Y.X.; Bai, C.; Xue, X.; Jiang, Y.G. Embodied One-Shot Video Recognition. In Proceedings of the 27th ACM International Conference on Multimedia, Nice France, 21–25 October 2019; pp. 411–419. [Google Scholar] [CrossRef]
- Bishay, M.; Zoumpourlis, G.; Patras, I. Tarn: Temporal attentive relation network for few-shot and zero-shot action recognition. arXiv 2019, arXiv:1907.09021. [Google Scholar]
- Feng, Y.; Gao, J.; Xu, C. Learning Dual-Routing Capsule Graph Neural Network for Few-shot Video Classification. IEEE Trans. Multimedia 2022, 1. [Google Scholar] [CrossRef]
- Shu, X.; Xu, B.; Zhang, L.; Tang, J. Multi-Granularity Anchor-Contrastive Representation Learning for Semi-Supervised Skeleton-Based Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1–18. [Google Scholar] [CrossRef]
- Xu, B.; Shu, X.; Song, Y. X-Invariant Contrastive Augmentation and Representation Learning for Semi-Supervised Skeleton-Based Action Recognition. IEEE Trans. Image Process. 2022, 31, 3852–3867. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar] [CrossRef]
- Cao, W.; Yan, Z.; He, Z.; He, Z. A Comprehensive Survey on Geometric Deep Learning. IEEE Access 2020, 8, 35929–35949. [Google Scholar] [CrossRef]
- Masci, J.; Boscaini, D.; Bronstein, M.M.; Vandergheynst, P. Geodesic Convolutional Neural Networks on Riemannian Manifolds. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 832–840. [Google Scholar] [CrossRef]
- Boscaini, D.; Masci, J.; Rodolà, E.; Bronstein, M. Learning shape correspondence with anisotropic convolutional neural networks. Adv. Neural Inf. Process. Syst 2016, 29, 3197–3205. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodolà, E.; Svoboda, J.; Bronstein, M.M. Geometric deep learning on graphs and manifolds using mixture model CNNs. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5425–5434. [Google Scholar] [CrossRef]
- Litany, O.; Remez, T.; Rodola, E.; Bronstein, A.; Bronstein, M. Deep Functional Maps: Structured Prediction for Dense Shape Correspondence. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5660–5668. [Google Scholar] [CrossRef]
- Boscaini, D.; Masci, J.; Melzi, S.; Bronstein, M.M.; Castellani, U.; Vandergheynst, P. Learning class-specific descriptors for deformable shapes using localized spectral convolutional networks. Eurographics Symp. Geom. Process. 2015, 34, 13–23. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5100–5109. [Google Scholar]
- Li, Y.; Cao, W. An Extended Multilayer Perceptron Model Using Reduced Geometric Algebra. IEEE Access 2019, 7, 129815–129823. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric Deep Learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Wu, Z.; Jiang, Y.G.; Wang, J.; Pu, J.; Xue, X. Exploring inter-feature and inter-class relationships with deep neural networks for video classification. In Proceedings of the MM 2014—2014 ACM Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 167–176. [Google Scholar] [CrossRef]
- Yang, Y.; Krompass, D.; Tresp, V. Tensor-train recurrent neural networks for video classification. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Volume 8, pp. 5929–5938. [Google Scholar]
- Yang, X.; Molchanov, P.; Kautz, J. Multilayer and multimodal fusion of deep neural networks for video classification. In Proceedings of the MM 2016—2016 ACM Multimedia Conference, Amsterdam, The Netherlands, 15–29 October 2016; pp. 978–987. [Google Scholar] [CrossRef]
- Wang, L.; Li, W.; Li, W.; Van Gool, L. Appearance-and-relation networks for video classification. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1430–1439. [Google Scholar]
- Wu, Z.; Jiang, Y.G.; Wang, X.; Ye, H.; Xue, X. Multi-stream multi-class fusion of deep networks for video classification. In Proceedings of the MM 2016—Proceedings of the 2016 ACM Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016; pp. 791–800. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Feiszli, M. Video classification with channel-separated convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 Octobet–2 November 2019; pp. 5552–5561. [Google Scholar]
- Jing, L.; Parag, T.; Wu, Z.; Tian, Y.; Wang, H. VideoSSL: Semi-Supervised Learning for Video Classification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1110–1119. [Google Scholar]
- Shu, X.; Yang, J.; Yan, R.; Song, Y. Expansion-Squeeze-Excitation Fusion Network for Elderly Activity Recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5281–5292. [Google Scholar] [CrossRef]
- Li, Z.; Li, R.; Jin, G. Sentiment analysis of danmaku videos based on naïve bayes and sentiment dictionary. IEEE Access 2020, 8, 75073–75084. [Google Scholar] [CrossRef]
- Zhen, M.; Li, S.; Zhou, L.; Shang, J.; Feng, H.; Fang, T.; Quan, L. Learning Discriminative Feature with CRF for Unsupervised Video Object Segmentation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12372, pp. 445–462. [Google Scholar] [CrossRef]
- Ruz, G.A.; Henríquez, P.A.; Mascareño, A. Sentiment analysis of Twitter data during critical events through Bayesian networks classifiers. Future Gener. Comput. Syst. 2020, 106, 92–104. [Google Scholar] [CrossRef]
- Fantinel, R.; Cenedese, A.; Fadel, G. Hybrid Learning Driven by Dynamic Descriptors for Video Classification of Reflective Surfaces. IEEE Trans. Industr. Inform. 2021, 17, 8102–8111. [Google Scholar] [CrossRef]
- Costa, F.F.; Saito, P.T.M.; Bugatti, P.H. Video action classification through graph convolutional networks. In Proceedings of the VISIGRAPP 2021—16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Vienna, Austria, 8–10 February 2021; Volume 4, pp. 490–497. [Google Scholar] [CrossRef]
- Xu, Q.; Zhu, L.; Dai, T.; Yan, C. Aspect-based sentiment classification with multi-attention network. Neurocomputing 2020, 388, 135–143. [Google Scholar] [CrossRef]
- Bibi, M.; Aziz, W.; Almaraashi, M.; Khan, I.H.; Nadeem, M.S.A.; Habib, N. A Cooperative Binary-Clustering Framework Based on Majority Voting for Twitter Sentiment Analysis. IEEE Access 2020, 8, 68580–68592. [Google Scholar] [CrossRef]
- Sailunaz, K.; Alhajj, R. Emotion and sentiment analysis from Twitter text. J. Comput. Sci. 2019, 36, 101003. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in the Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Cai, Z.; Wang, L.; Peng, X.; Qiao, Y. Multi-view super vector for action recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 596–603. [Google Scholar] [CrossRef]
- Sun, L.; Jia, K.; Yeung, D.Y.; Shi, B.E. Human action recognition using factorized spatio-temporal convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4597–4605. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. C3D: Generic Features for Video Analysis. 2015. Available online: https://vlg.cs.dartmouth.edu/c3d/ (accessed on 20 January 2023).
- Peng, X.; Wang, L.; Wang, X.; Qiao, Y. Bag of visual words and fusion methods for action recognition: Comprehensive study and good practice. Comput. Vis. Image Underst. 2016, 150, 109–125. [Google Scholar] [CrossRef]
- Lev, G.; Sadeh, G.; Klein, B.; Wolf, L. RNN fisher vectors for action recognition and image annotation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9910, pp. 833–850. [Google Scholar] [CrossRef]
- Park, E.; Han, X.; Berg, T.L.; Berg, A.C. Combining multiple sources of knowledge in deep CNNs for action recognition. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016, Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar] [CrossRef]
- Wang, X.; Farhadi, A.; Gupta, A. Actions ~ Transformations. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2658–2667. [Google Scholar] [CrossRef]
- Zhu, W.; Hu, J.; Sun, G.; Cao, X.; Qiao, Y. A Key Volume Mining Deep Framework for Action Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1991–1999. [Google Scholar] [CrossRef]









| Reference | Year | Coverage | Highlights | Drawbacks |
|---|---|---|---|---|
| A. Anusya [5] | 2020 | 2014–2019 | Video classification, tagging, and clustering. | Not comprehensive and lacks concise information. |
| Rani et al. [6] | 2020 | 2001–2016 | Text, audio, and visual modalities for video classification. | Missing analysis of recent state-of-art approaches. |
| Y. Li et al. [7] | 2020 | 2012–2019 | Live sport video classification. | More specific to live sport video classification. |
| Md Islam et al. [8] | 2021 | 2004–2020 | Machine learning approaches for video classification. | Focus of review is not on deep learning approaches. |
| Ullah. H. et al. [9] | 2021 | 2015–2020 | Human activity recognition using deep learning. | Focus only on the human activity recognition. |
| This study | 2022 | 2000–2022 | Comprehensive deep learning review for video classification. | - |
| Categories | Working Principle | References |
|---|---|---|
| Hand-crafted approaches | These representations are handcrafted and employ various feature encoding techniques, such as histograms and pyramids. | Spatiotemporal Interest Points (STIPs) [26], iDT [27], SIFT-3D [28], HOG3D [29], Motion Boundary Histogram [30], Cuboids [32], Action-Bank [31], 3D SURF [33], Dynamic-Poselets [34]. |
| 2D- CNNs | These are image based models where frame level feature extraction is performed using CNN architecture and classification is performed using state-of-art classification models, for example SVM. | [55] |
| 3D-CNNs | 2D image classification extension to 3D for video (For example the Inception 3D (I3D) architecture). | [56] |
| Spatiotemporal Convolutional Networks | To aggregate the temporal and the spatial information, these methods primarily depend on convolution and pooling. | [54,57,58] |
| Recurrent Spatial Networks | To represent temporal information in videos, recurrent neural networks such as LSTM or GRU are used. | [47,53,59,60] |
| Two/multi Stream Networks | In addition to the context frame visuals, these methods use layered optical flow to identify movements. | [50,61,62,63] |
| Mixed convolutional models | Models built with the ResNet architecture in mind. They are particularly interested in models that utilize 3D convolution in the bottom or top layers but 2D in the remainder; these are referred to as “mixed convolutional” models. Or the methods based on mixed temporal convolution with different kernel sizes. | [64,65] |
| Hybrid Approaches | These are models based on integration of CNN and RNN architectures. | [66,67,68] |
| Dataset | # of Videos | # of Classes | Year | Background |
|---|---|---|---|---|
| KTH | 600 | 6 | 2004 | Static |
| Weizmann | 81 | 9 | 2005 | Static |
| Kodak | 1358 | 25 | 2007 | Dynamic |
| Hollywood | 430 | 8 | 2008 | Dynamic |
| Hollywood2 | 1787 | 12 | 2009 | Dynamic |
| MCG-WEBV | 234,414 | 15 | 2009 | Dynamic |
| Olympic Sports | 800 | 16 | 2010 | Dynamic |
| HMDB51 | 6766 | 51 | 2011 | Dynamic |
| CCV | 9317 | 20 | 2011 | Dynamic |
| UCF-101 | 13,320 | 101 | 2012 | Dynamic |
| THUMOS-2014 | 18,394 | 101 | 2014 | Dynamic |
| MED-2014 (Dev. set) | 31,000 | 20 | 2014 | Dynamic |
| Sports-1M | 1,133,158 | 487 | 2014 | Dynamic |
| ActivityNet | 27,901 | 203 | 2015 | Dynamic |
| EventNet | 95,321 | 500 | 2015 | Dynamic |
| MPII Human Pose | 20,943 | 410 | 2014 | Dynamic |
| FCVID | 91,223 | 239 | 2015 | Dynamic |
| UCF11 | 1600 | 11 | 2009 | Dynamic |
| YouTube Celebrities Face | 1910 | 47 | 2008 | Dynamic |
| Kinetics | 300,000 | 400 | 2017 | Dynamic |
| YouTube-8M | 6.1 M | 3862 | 2018 | Dynamic |
| JHMDB | 928 | 21 | 2011 | Dynamic |
| Something-something | 110,000 | 174 | 2017 | Dynamic |
| Evaluation Metric | Year of Publication | Reference |
|---|---|---|
| Accuracy | 2020–2021 | [116,117,118,119,120] |
| Precision | 2020–2021 | [116,118,119] |
| Recall | 2020–2021 | [116,118,119] |
| F1 Score | 2020–2021 | [116,118,119] |
| Micro F1 | 2020 | [121,122] |
| K-Fold | 2019 | [123] |
| Top-k | 2018,2021 | [111,114] |
| Method | Accuracy |
|---|---|
| LRCN [48] | 82.9 |
| DT + MVSV [125] | 83.5 |
| LSTM–Composite [49] | 84.3 |
| FSTCN [126] | 88.1 |
| C3D [127] | 85.2 |
| iDT + HSV [128] | 87.9 |
| Two-Stream [61] | 88.0 |
| RNN-FV [129] | 88.0 |
| LSTM [50] | 88.6 |
| MultiSource CNN [130] | 89.1 |
| Image-Based [55] | 89.6 |
| TDD [35] | 90.3 |
| Multilayer and Multimodal Fusion [110] | 91.6 |
| Transformation CNN [131] | 92.4 |
| Multi-Stream [112] | 92.6 |
| Key Volume Mining [132] | 92.7 |
| Convolutional Two-Stream [62] | 93.5 |
| Temporal Segment Networks [39] | 94.2 |
| Architecture Name | Parameters | Error Rate | Depth | Category | Year |
|---|---|---|---|---|---|
| LeNet | 0.060 M | [dist]MNIST: 0.8 MNIST: 0.95 | 5 | Spatial exploitation | 1998 |
| AlexNet | 60 M | ImageNet: 16.4 | 8 | Spatial exploitation | 2012 |
| ZfNet | 60 M | ImageNet: 11.7 | 8 | Spatial exploitation | 2014 |
| VGG | 138 M | ImageNet: 7.3 | 19 | Spatial exploitation | 2014 |
| GoogLeNet | 4 M | ImageNet: 6.7 | 22 | Spatial exploitation | 2015 |
| Inception-V3 | 23.6 M | ImageNet: 3.5 multi-crop: 3.58 Single-Crop: 5.6 | 159 | Depth + width | 2015 |
| Highway networks | 2.3 M | CIFAR-10: 7.76 | 19 | Depth + multi-path | 2015 |
| Inception-V4 | 35 M | ImageNet: 4.01 | 70 | Depth + width | 2016 |
| Inception-ResNet | 55.8 M | ImageNet: 3.52 | 572 | Depth + width + multi-path | 2016 |
| ResNet | 25.6 M 1.7 M | ImageNet: 3.6 CIFAR-10: 6.43 | 152 110 | Depth + multi-path | 2016 |
| DelugeNet | 20.2 M | CIFAR-10: 3.76 CIFAR-100: 19.02 | 146 | Multi-path | 2016 |
| FractalNet | 38.6 M | CIFAR-10: 7.27 CIFAR-10 +: 4.60 CIFAR-10 ++: 4.59 CIFAR-100: 28.20 CIFAR-100 +: 22.49 CIFAR100 ++: 21.49 | 20 40 | Multi-path | 2016 |
| WideResNet | 36.5 M | CIFAR-10: 3.89 CIFAR-100: 18.85 | 28 – | Width | 2016 |
| Xception | 22.8 M | ImageNet: 0.055 | 126 | Width | 2017 |
| Residual attention neural network | 8.6 M | CIFAR-10: 3.90 CIFAR-100: 20.4 ImageNet: 4.8 | 452 | Attention | 2017 |
| ResNeXt | 68.1 M | CIFAR-10: 3.58 CIFAR-100: 17.31 ImageNet: 4.4 | 29 - 101 | Width | 2017 |
| Squeeze and excitation networks | 27.5 M | ImageNet: 2.3 | 152 | Feature-map exploitation | 2017 |
| DenseNet | 25.6 M 25.6 M 15.3 M 15.3 M | CIFAR-10 +: 3.46 CIFAR100 +: 17.18 CIFAR-10: 5.19 CIFAR-100: 19.64 | 190 190 250 250 | Multi-path | 2017 |
| PolyNet | 92 M | ImageNet: Single: 4.25 Multi: 3.45 | – – | Width | 2017 |
| PyramidalNet | 116.4 M 27.0 M 27.0 M | ImageNet: 4.7 CIFAR-10: 3.48 CIFAR-100: 17.01 | 200 164 164 | Width | 2017 |
| Convolutional block attention Module (ResNeXt101 (32 × 4d) + CBAM) | 48.96 M | ImageNet: 5.59 | 101 | Attention | 2018 |
| Concurrent spatial and channel excitation mechanism | – | MALC: 0.12 Visceral: 0.09 | – | Attention | 2018 |
| Channel boosted CNN | – | – | – | Channel boosting | 2018 |
| Competitive squeeze and excitation network CMPE-SE-WRN-28 | 36.92 M 36.90 M | CIFAR-10: 3.58 CIFAR-100: 18.47 | 152 152 | Feature-map exploitation | 2018 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
ur Rehman, A.; Belhaouari, S.B.; Kabir, M.A.; Khan, A. On the Use of Deep Learning for Video Classification. Appl. Sci. 2023, 13, 2007. https://doi.org/10.3390/app13032007
ur Rehman A, Belhaouari SB, Kabir MA, Khan A. On the Use of Deep Learning for Video Classification. Applied Sciences. 2023; 13(3):2007. https://doi.org/10.3390/app13032007
Chicago/Turabian Styleur Rehman, Atiq, Samir Brahim Belhaouari, Md Alamgir Kabir, and Adnan Khan. 2023. "On the Use of Deep Learning for Video Classification" Applied Sciences 13, no. 3: 2007. https://doi.org/10.3390/app13032007