
STrans-YOLOX: Fusing Swin Transformer and YOLOX for Automatic Pavement Crack Detection
Abstract
:1. Introduction
- We propose an automatic pavement crack detection network that fuses Swin Transformer and YOLOX. It complements the long-range dependencies between pixels compared with pure CNN-based networks. Compared with pure CNNs, it supplements the long-range dependencies between pixels. Moreover, compared with pure transformer-based networks, it preserves the advantage of the CNN in local modeling, not impairing the backbone to learn the local feature information.
- Swin Transformer is introduced to the model to make up for the insufficient modeling of the long-range dependencies of the convolution operations, thereby solving the problems of low contrast and background noise. Thus, it can better retain the edge detail features of the input images and increase the crack detection accuracy.
- A GAGM is designed to guide the low-level detail information with the high-level semantic information, which effectively overcomes the semantic and scale inconsistency when multi-class and multi-scale features are input into the FPN.
- α-IoU-NMS is utilized to suppress the redundant detection boxes more accurately, which can reduce the missing detection of occlusion and overlapping objects.
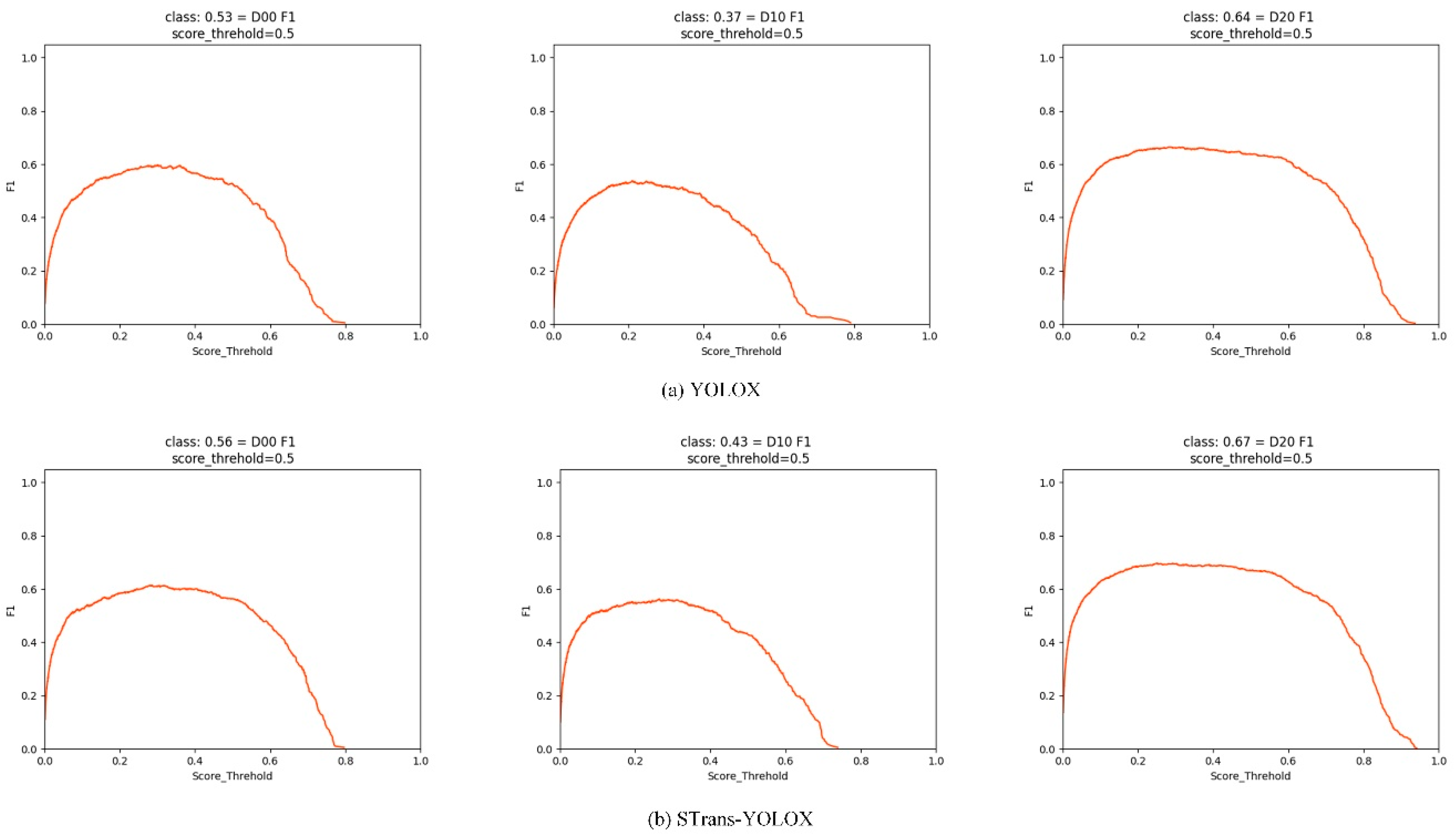
- STrans-YOLOX achieves mAP of 63.37% on the challenging pavement crack dataset, which surpasses the state-of-the-art models.
2. Related Work
2.1. Pavement Crack Detection Methods Based on CNNs
2.2. Transformer-Based Methods
3. Methodology
3.1. Overview of YOLOX
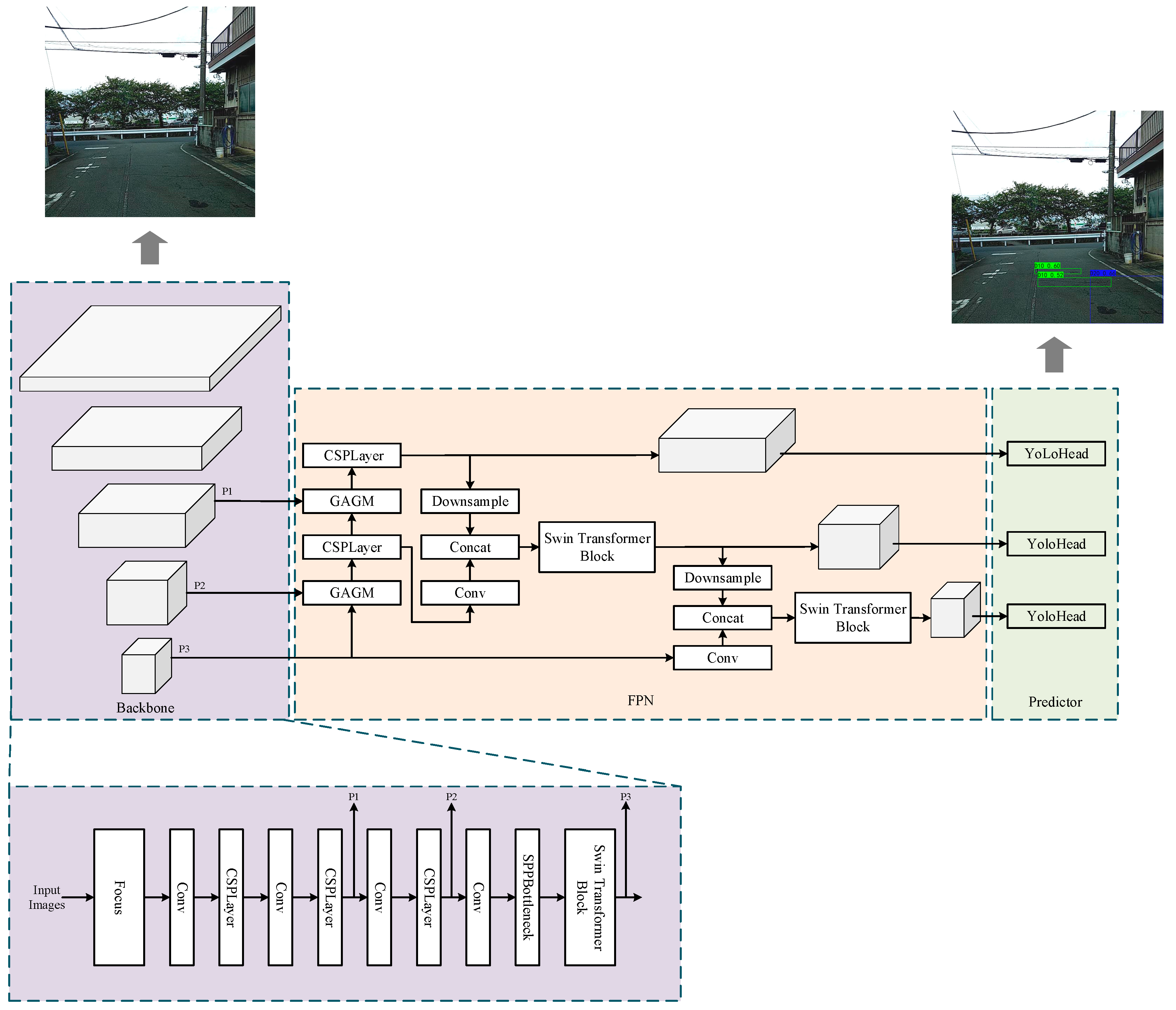
3.2. STrans-YOLOX
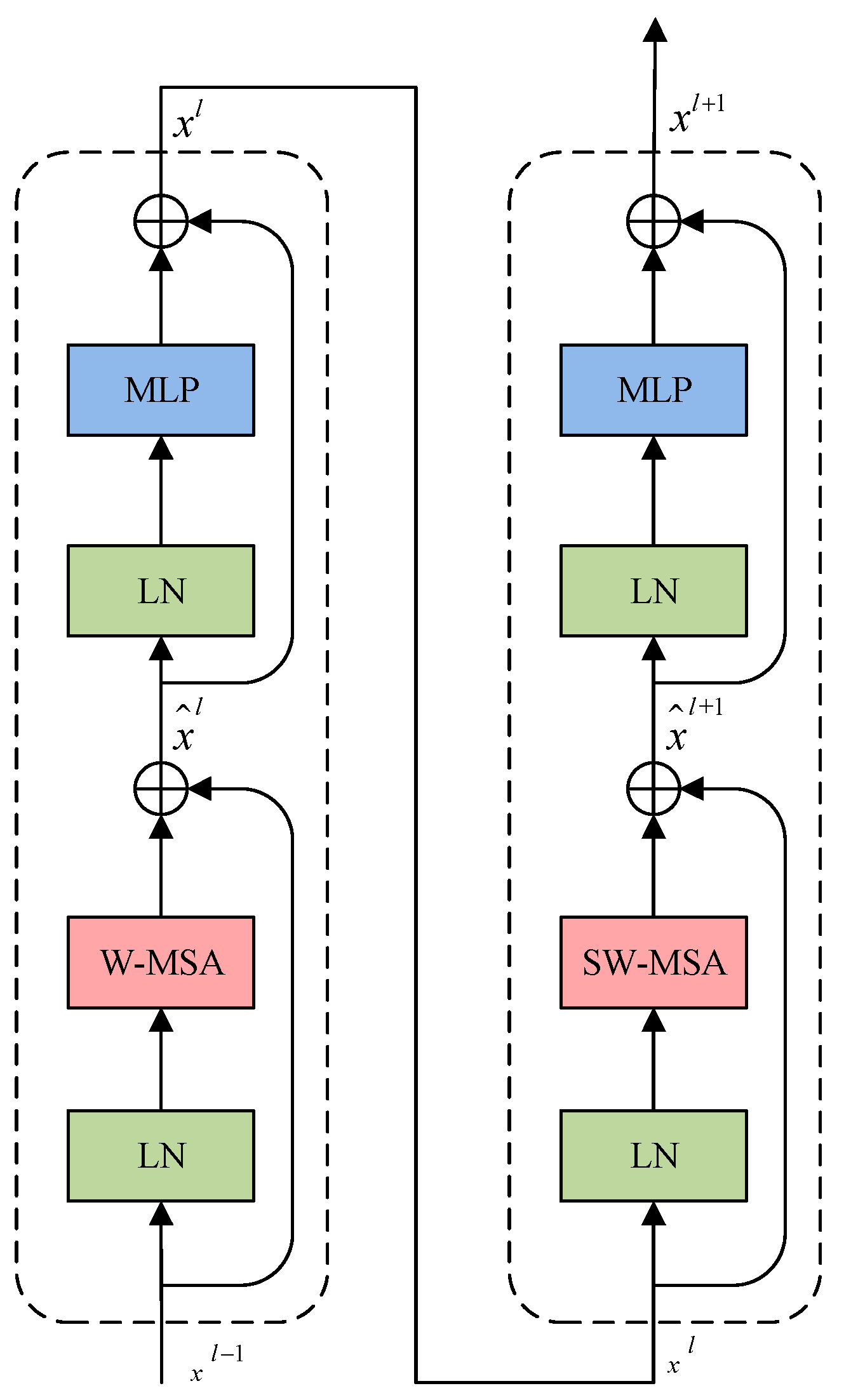
3.2.1. Swin Transformer Block

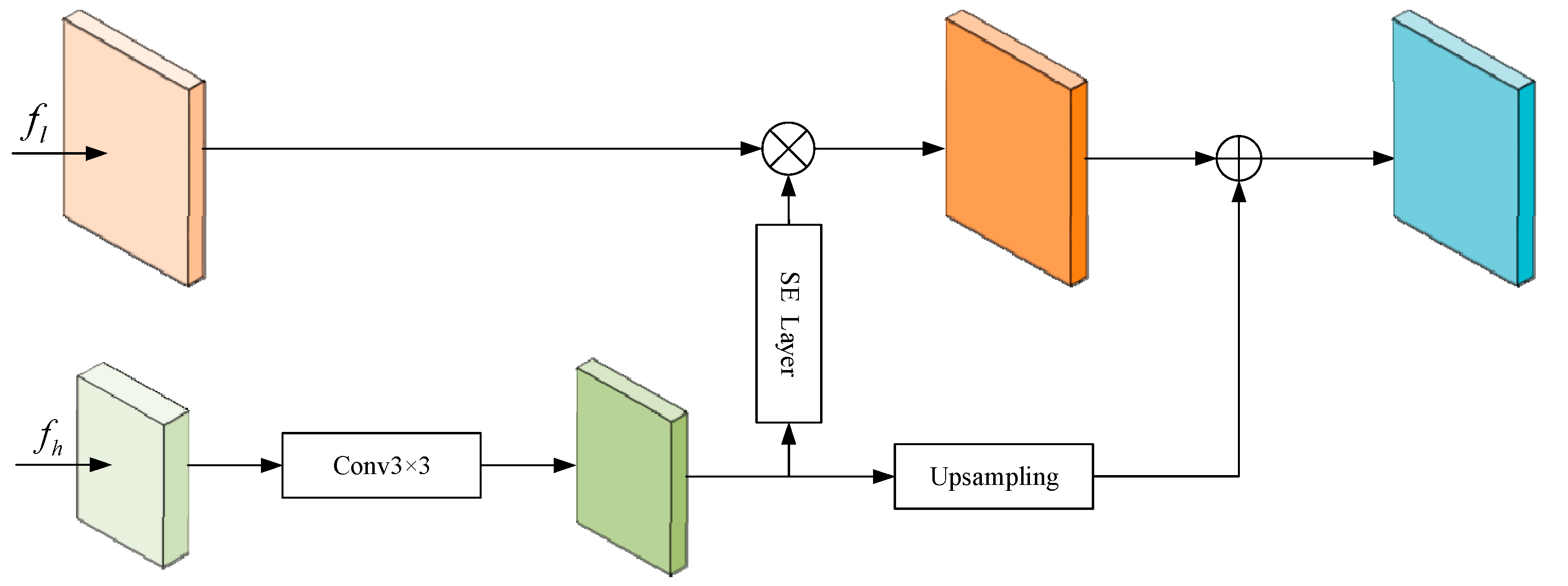
3.2.2. Global Attention Guidance Module (GAGM)
3.2.3. α-IoU-NMS
- (1)
- Traditional NMS
- (2)
- α-IoU-NMS
4. Experiments and Results
4.1. Dataset Acquisition
4.2. Evaluation Metrics
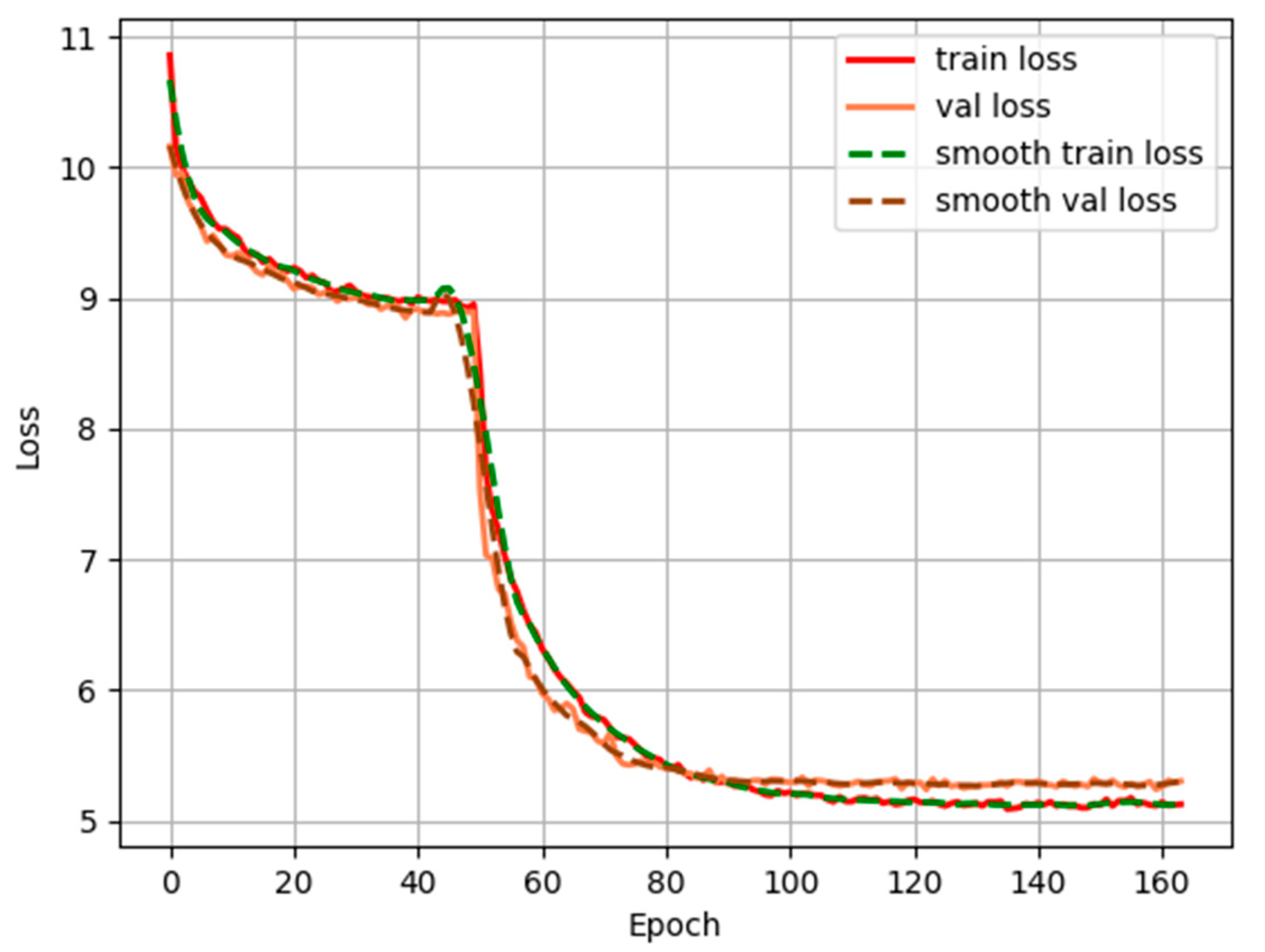
4.3. Implementation Details
4.4. Experimental Results and Analysis
- (1)
- Comparison of the Results with the State-of-the-Art Models
- (2)
- Ablation Study
- (a)
- Effect of Swin Transformer Blocks
- (b)
- Effect of GAGM
- (c)
- Effect of α-IoU-NMS
- (3)
- Visual Detection Results on the Pavement Crack Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Oliveira, H.; Correia, P.L. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of the 7th European Signal Processing Conference, Glasgow, Scotland, UK, 24–28 August 2009; pp. 622–626. [Google Scholar]
- Zhao, H.; Qin, G.; Wang, X. Improvement of canny algorithm based on pavement edge detection. In Proceedings of the 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; pp. 964–967. [Google Scholar]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. Convolutional neural networks-based crack detection for real concrete surface. In Proceedings of the SPIE Conference on Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems, Denver, CO, USA, 5–8 March 2018; pp. 105983V-1–105983V-7. [Google Scholar]
- Han, Z.; Chen, H.; Liu, Y.; Li, Y.; Du, Y.; Zhang, H. Vision-Based Crack Detection of Asphalt Pavement Using Deep Convolutional Neural Network. Iran. J. Sci. Technol. Trans. Civ. Eng. 2021, 45, 2047–2055. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2016; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:360200410934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Tang, J.; Mao, Y.; Wang, J.; Wang, L. Multi-task Enhanced Dam Crack Image Detection Based on Faster R-CNN. In Proceedings of the 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 336–340. [Google Scholar]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection and classification using deep neural networks with smartphone images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated Road Crack Detection Using Deep Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5212–5215. [Google Scholar]
- Du, Y.; Pan, N.; Xu, Z.; Deng, F.; Kang, H. Pavement distress detection and classification based on YOLO network. Int. J. Pavement Eng. 2021, 22, 1659–1672. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, Z.H. Automated Asphalt Highway Pavement Crack Detection Based on Deformable Single Shot Multi-Box Detector Under a Complex Environment. IEEE Access 2021, 9, 150925–150938. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Z.; Yu, L. YOLO Object Detection Algorithm with Hybrid Atrous Convolutional Pyramid. In Proceedings of the IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; pp. 940–945. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Dong, H.P.; Kislyuk, D. Toward Transformer-Based Object Detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature Pyramid Transformer. In Proceedings of the European Conference on Computer Vision, Glasgow, Scotland, UK, 23–28 August 2020; pp. 323–339. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual Event, Nashville, TN, USA, 20–25 June 2021; pp. 16514–16524. [Google Scholar]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the EEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Mohammadi, S.; Noori, M.; Bahri, A.; Majelan, S.G.; Havaei, M. CAGNet: Content-aware guidance for salient object detection. Pattern Recognit 2020, 103, 107303. [Google Scholar] [CrossRef]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. arXiv 2021, arXiv:2110.13675v2. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. An annotated image dataset for Automatic Road Damage Detection using Deep Learning. Data Brief 2021, 36, 107133. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multi-box Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Train Set | Validation Set | Test Set | Total |
|---|---|---|---|---|
| D00 | 3262 | 399 | 388 | 4049 |
| D10 | 3243 | 348 | 388 | 3979 |
| D20 | 5009 | 542 | 648 | 6199 |
| Total | 11,514 | 1289 | 1424 | 14,277 |
| Method | Accuracy (%) | FPS | |||
|---|---|---|---|---|---|
| AP (D00) | AP (D10) | AP (D20) | mAP | ||
| SSD | 50.37 | 30.14 | 68.57 | 49.70 | 27.65 |
| CenterNet | 55.56 | 44.92 | 65.34 | 55.28 | 37.32 |
| RetinaNet | 58.30 | 23.61 | 73.33 | 51.75 | 21.82 |
| YOLOv3 | 55.40 | 44.88 | 70.47 | 56.91 | 26.17 |
| YOLOv4 | 54.30 | 46.08 | 70.61 | 57.00 | 19.99 |
| YOLOv5-M | 57.17 | 38.51 | 65.33 | 53.67 | 39.43 |
| YOLOX-M | 59.92 | 50.98 | 70.18 | 60.36 | 39.01 |
| STrans-YOLOX | 62.11 | 55.78 | 73.30 | 63.73 | 26.59 |
| Method | AP (D00)/% | AP (D10)/% | AP (D20)/% | Map/% |
|---|---|---|---|---|
| YOLOX | 59.92 | 50.98 | 70.18 | 60.36 |
| YOLOX + Swin Transformer | 60.01 (↑0.09) | 53.48 (↑2.5) | 72.59 (↑2.41) | 62.03 (↑1.67) |
| YOLOX + Swin Transformer + GAGM | 61.44 (↑1.43) | 55.63 (↑2.15) | 72.63 (↑0.04) | 63.23 (↑1.2) |
| YOLOX + Swin Transformer + GAGM + α-IoU-NMS | 62.11 (↑0.67) | 55.78 (↑0.15) | 73.30 (↑0.67) | 63.73 (↑0.5) |
| α | 0.5 | 0.6 | 0.7 | 0.75 | 0.8 | 0.9 | 1 | 2 | 3 |
|---|---|---|---|---|---|---|---|---|---|
| mAP/% | 63.19 | 63.63 | 63.62 | 63.73 | 63.71 | 63.62 | 63.23 | 58.93 | 52.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, H.; Li, J.; Cai, L.; Wu, M. STrans-YOLOX: Fusing Swin Transformer and YOLOX for Automatic Pavement Crack Detection. Appl. Sci. 2023, 13, 1999. https://doi.org/10.3390/app13031999
Luo H, Li J, Cai L, Wu M. STrans-YOLOX: Fusing Swin Transformer and YOLOX for Automatic Pavement Crack Detection. Applied Sciences. 2023; 13(3):1999. https://doi.org/10.3390/app13031999
Chicago/Turabian StyleLuo, Hui, Jiamin Li, Lianming Cai, and Mingquan Wu. 2023. "STrans-YOLOX: Fusing Swin Transformer and YOLOX for Automatic Pavement Crack Detection" Applied Sciences 13, no. 3: 1999. https://doi.org/10.3390/app13031999