
A Robust Adversarial Example Attack Based on Video Augmentation


Abstract
:1. Introduction
2. Materials
3. Methodology
3.1. Problem Formulation
3.2. Adversarial Video Attack
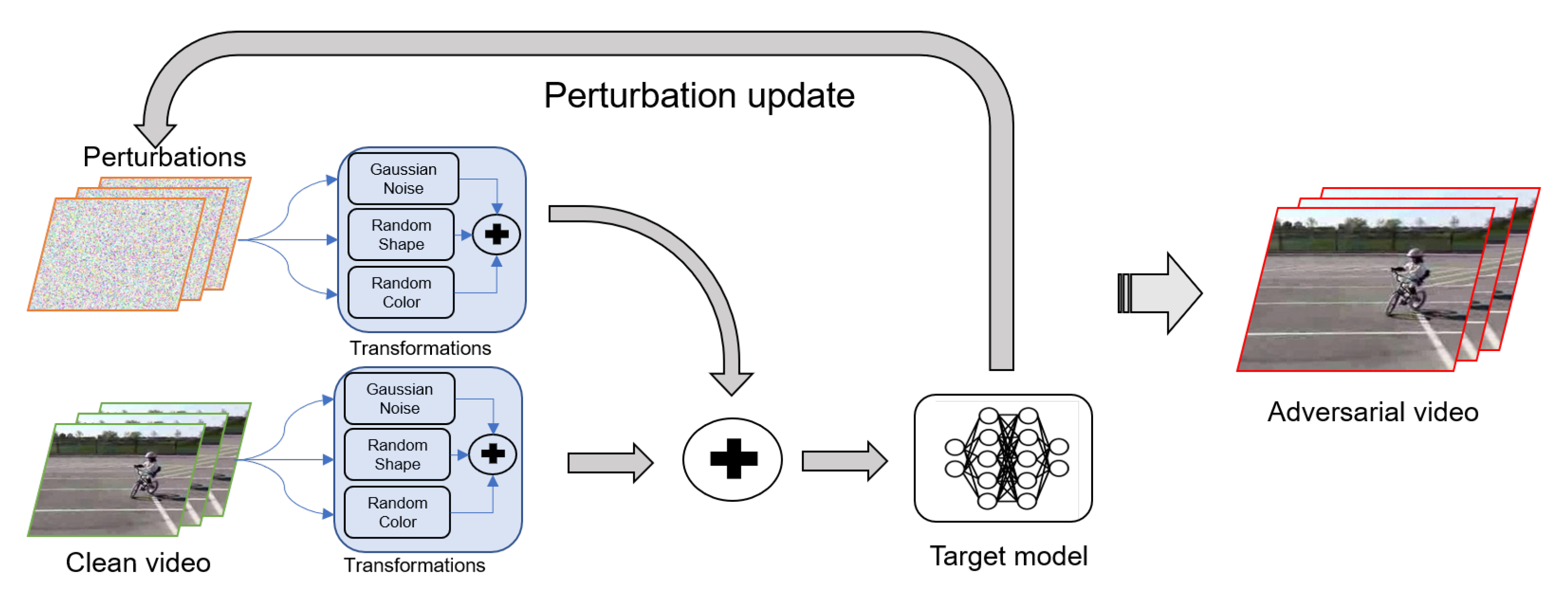
3.3. Video Augmentations Based Adversarial Attack
- Before iterations. By performing once-transformation before the attack, the robustness of adversarial examples can be improved to some degree. This method is fast but limited because it does not consider the effect of the perturbation.
- During iterations. By performing transformation in each iteration, the robustness of adversarial examples can be greatly enhanced. However, repeated transformations can make attacks more difficult or even fail, as the original examples transform multiple times. At the same time, the size of the perturbation will keep increasing with iterations, which leads to weaker concealment.
- During iterations but only for perturbations. By performing once-transformation before the attack and transforming the adversarial perturbations in each iteration, the robustness of adversarial examples is effectively improved and the difficulty of the attacks does not increase significantly. This approach thus meets the comprehensive needs.
| Algorithm 1: v3a: video-augmentation-based adversarial attack. |
 |
4. Experimental Results
4.1. Experimental Methodology
4.2. Performance Comparison
4.2.1. Performance Comparison of White-Box Attacks
4.2.2. Performance Comparison of Black-Box Attacks
4.2.3. Impact on MAP
- The generation process of adversarial examples is the primary focus of existing methods for conducting video adversarial attacks; as a result, the robustness of video adversarial examples has not been investigated. Because video data contain more complex temporal and spatial structures than image data, even relatively minor transformations carried out on the video frames can have a significant effect on the semantic information of the adversarial perturbations. This renders previously developed methods of attack less applicable to the real-world setting in which they are intended to be used.
- Performing transformation during the generation process of video adversarial examples is a practicable solution for enhancing the robustness of adversarial examples. However, repeated transformations can make attacks more difficult or even fail. At the same time, it will also lead to weaker concealment.
- The resilience of video adversarial instances was considerably improved by v3a thanks to the once-transformation that was performed before the attack and the transformation of adversarial perturbations that was performed throughout each iteration. In the meantime, v3a can be effectively integrated with other video adversarial attack methods, which in turn increases the rate of successful attacks.
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| x | The original input video |
| The distortion to the original audio | |
| F | The target video classification model |
| y | The classification result |
| The target label for targeted attack | |
| The parameters for controlling perturbations | |
| M | The key frame mask for sparse adversarial attack |
| L | The loss function |
| The parameters of the target model | |
| The estimated gradient | |
| N | The number of directions sampled in the gradient estimation process |
| The smoothing parameter for gradient estimation | |
| The directions obtained by random sampling from a Gaussian distribution | |
| s | The step size for the perturbation update |
| d | The distance evaluation function of the boundary attack |
| k | The iteration count of the boundary attack |
| The smoothing parameter for the boundary attack | |
| T | The transform function, which performs three different transformations |
| The weights of three transformations |
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Liu, X.; Du, X.; Zhang, X.; Zhu, Q.; Wang, H.; Guizani, M. Adversarial Samples on Android Malware Detection Systems for IoT Systems. Sensors 2019, 19, 974. [Google Scholar] [CrossRef] [PubMed]
- Ding, K.; Liu, X.; Niu, W.; Hu, T.; Wang, Y.; Zhang, X. A low-query black-box adversarial attack based on transferability. Knowl.-Based Syst. 2021, 226, 107102. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096-2030. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Shafahi, A.; Najibi, M.; Xu, Z.; Dickerson, J.; Davis, L.S.; Goldstein, T. Universal adversarial training. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5636–5643. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), Paris, France, 29–30 April 2017; pp. 39–57. [Google Scholar]
- Liu, X.; Hu, T.; Ding, K.; Bai, Y.; Niu, W.; Lu, J. A black-box attack on neural networks based on swarm evolutionary algorithm. In Proceedings of the Australasian Conference on Information Security and Privacy, Perth, WA, Australia, 30 November–2 December 2020; pp. 268–284. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Chen, P.Y.; Sharma, Y.; Zhang, H.; Yi, J.; Hsieh, C.J. EAD: Elastic-net attacks to deep neural networks via adversarial examples. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Carlini, N.; Wagner, D. Audio adversarial examples: Targeted attacks on speech-to-text. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 1–7. [Google Scholar]
- Kreuk, F.; Adi, Y.; Cisse, M.; Keshet, J. Fooling end-to-end speaker verification with adversarial examples. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1962–1966. [Google Scholar]
- Yuan, X.; Chen, Y.; Zhao, Y.; Long, Y.; Liu, X.; Chen, K.; Zhang, S.; Huang, H.; Wang, X.; Gunter, C.A. Commandersong: A systematic approach for practical adversarial voice recognition. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Montreal, QC, Canada, 10–14 August 2018; pp. 49–64. [Google Scholar]
- Qin, Y.; Carlini, N.; Goodfellow, I.; Cottrell, G.; Raffel, C. Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition. arXiv 2019, arXiv:1903.10346. [Google Scholar]
- Liu, X.; Wan, K.; Ding, Y.; Zhang, X.; Zhu, Q. Weighted-sampling audio adversarial example attack. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4908–4915. [Google Scholar]
- Cheng, Z.; Lu, R.; Wang, Z.; Zhang, H.; Chen, B.; Meng, Z.; Yuan, X. BIRNAT: Bidirectional recurrent neural networks with adversarial training for video snapshot compressive imaging. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 258–275. [Google Scholar]
- Zajac, M.; Zołna, K.; Rostamzadeh, N.; Pinheiro, P.O. Adversarial framing for image and video classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 10077–10078. [Google Scholar]
- Wei, Z.; Chen, J.; Wu, Z.; Jiang, Y.G. Cross-Modal Transferable Adversarial Attacks from Images to Videos. arXiv 2021, arXiv:2112.05379. [Google Scholar]
- Wei, X.; Guo, Y.; Li, B. Black-box adversarial attacks by manipulating image attributes. Inf. Sci. 2021, 550, 285–296. [Google Scholar] [CrossRef]
- Wei, X.; Zhu, J.; Yuan, S.; Su, H. Sparse Adversarial Perturbations for Videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8973–8980. [Google Scholar]
- Wei, Z.; Chen, J.; Wei, X.; Jiang, L.; Chua, T.S.; Zhou, F.; Jiang, Y.G. Heuristic black-box adversarial attacks on video recognition models. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12338–12345. [Google Scholar]
- Xu, Y.; Liu, X.; Yin, M.; Hu, T.; Ding, K. Sparse Adversarial Attack For Video Via Gradient-Based Keyframe Selection. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 2874–2878. [Google Scholar]
- Jiang, L.; Ma, X.; Chen, S.; Bailey, J.; Jiang, Y.G. Black-Box Adversarial Attacks on Video Recognition Models. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 864–872. [Google Scholar]
- Yan, H.; Wei, X.; Li, B. Sparse black-box video attack with reinforcement learning. arXiv 2020, arXiv:2001.03754. [Google Scholar]
- Li, S.; Aich, A.; Zhu, S.; Asif, S.; Song, C.; Roy-Chowdhury, A.; Krishnamurthy, S. Adversarial attacks on black box video classifiers: Leveraging the power of geometric transformations. Adv. Neural Inf. Process. Syst. 2021, 34, 2085–2096. [Google Scholar]
- Zhang, H.; Zhu, L.; Zhu, Y.; Yang, Y. Motion-excited sampler: Video adversarial attack with sparked prior. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 240–256. [Google Scholar]
- Luo, B.; Liu, Y.; Wei, L.; Xu, Q. Towards Imperceptible and Robust Adversarial Example Attacks Against Neural Networks. In Proceedings of the AAAI, New Orleans, LO, USA, 2–7 February 2018; pp. 1652–1659. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing Robust Adversarial Examples. In Proceedings of the ICML, Stockholm, Sweden, 10–15 July 2018; pp. 284–293. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Visual Classification. In Proceedings of the CVPR. Computer Vision Foundation/IEEE Computer Society, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1625–1634. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv 2017, arXiv:1712.04248. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transformations | Method | FR Untargeted | FR Targeted |
|---|---|---|---|
| Benign | SA | 100% | 100% |
| v3a | 100% | 100% | |
| Gaussian Noise | SA | 72.28% | 65.35% |
| v3a | 97.03% | 93.07% | |
| Random Shape | SA | 81.19% | 76.24% |
| v3a | 95.05% | 91.09% | |
| Random Color | SA | 85.70% | 80.20% |
| v3a | 98.02% | 96.40% | |
| Assemble | SA | 57.14% | 49.50% |
| v3a | 89.11% | 84.16% |
| Transformations | Method | FR Untargeted | FR Targeted |
|---|---|---|---|
| Benign | HA | 100% | 100% |
| v3a | 100% | 100% | |
| Gaussian Noise | HA | 89.11% | 84.16% |
| v3a | 94.06% | 90.10% | |
| Random Shape | HA | 91.09% | 88.12% |
| v3a | 96.04% | 94.06% | |
| Random Color | HA | 87.13% | 87.13% |
| v3a | 98.02% | 93.07% | |
| Assemble | HA | 80.20% | 75.25% |
| v3a | 93.07% | 87.13% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, M.; Xu, Y.; Hu, T.; Liu, X. A Robust Adversarial Example Attack Based on Video Augmentation. Appl. Sci. 2023, 13, 1914. https://doi.org/10.3390/app13031914
Yin M, Xu Y, Hu T, Liu X. A Robust Adversarial Example Attack Based on Video Augmentation. Applied Sciences. 2023; 13(3):1914. https://doi.org/10.3390/app13031914
Chicago/Turabian StyleYin, Mingyong, Yixiao Xu, Teng Hu, and Xiaolei Liu. 2023. "A Robust Adversarial Example Attack Based on Video Augmentation" Applied Sciences 13, no. 3: 1914. https://doi.org/10.3390/app13031914