1. Introduction
Background of Malware. Malware presents significant challenges to the security of network services and data assets and causes substantial economic losses to enterprises and individuals. An explosive growth trend is being observed in various types of high-risk malware, including spyware, botnets, ransomware, rootkits, and mining programs [
1]. In the first quarter of 2021 alone, McAfee reported that more than 87 million new malicious samples were captured, involving about 930,000 new maliciously signed binary files [
2]. Over one million suspicious files are uploaded to VirusTotal on a daily basis [
3]. The explosive growth in the number of new variants and malware samples presents a serious challenge to the existing detection methods. It is difficult to cope with it through detection methods that simply use manual signatures [
4] and feature code matching [
5].
Background of Dynamic Analysis. Malware analysis methods can be classified into static and dynamic malware analysis [
6]. Static analysis methods are seriously challenged when they face obfuscation techniques [
7,
8] and zero-day or polymorphic malware. Static analysis approaches tend to be low-cost but unreliable. Dynamic analysis refers to the execution and analysis of malicious samples in a controlled environment. Malicious behaviors must be implemented through underlying system API calls [
9]. System APIs are usually called to obtain the relevant system permissions, modify the registry, establish network communication, monitor GUI operations, and detect sandboxes. Dynamic analysis methods are widely considered to be more resistant to interference by monitoring these sensitive operations [
10]. The existing dynamic analysis methods commonly trace these sensitive system API call behaviors, establish API call sequences, or directed behavioral graphs, and then analyze them by machine learning or deep learning methods [
11,
12].
Limitation of Existing Works. In recent decades, deep learning models, including CNN, RNN, LSTM, and BiLSTM, have been widely used to automatically obtain sequence features and locate malicious behaviors. However, recent studies [
13,
14,
15] revealed that these models can be deceived through packing and black-box attacking technologies for both static and dynamic features.
There are two reasons for this issue. Firstly, simply mapping APIs to numerical values ignores the inherent semantic features of a function. An API function may perform a query or modification operation, and it may be related to network communication, the file system, or other factors. Simple numerical values cannot reflect these features. Secondly, existing models cannot reflect the sequential characteristics well. These models are not well equipped to handle large datasets. There is a universal decrease in model performance when these models are presented with a dataset containing excessive types of APIs, oversize feature sets, and overlong sequences. Therefore, the API call sequences are usually modified in such a way that key API information is ignored, resulting in degraded detection performance.
Goals and Approaches. It is considered that the sequence context and implicit semantics of functions play a crucial role in the classification of API call sequences. The function name of APIs implies several semantics, indicating various actions such as reading, writing, searching, and downloading, as well as various associated resources such as system privileges, networks, registry, and GUI interfaces. Encoding the API call sequence with one-hot vectors not only results in high-dimensional vectors but also leads to the loss of key semantic information. Techniques such as processing text sequences [
16] and word embedding in natural language processing [
17] can be employed to aid in dimension reduction and semantic representation.
As a deep learning-based malicious malware detection method, feature selection is not required. Starting from the sequence of API functions, the goal of this paper is to map each function into different operation types and resource-associated types according to its textual name, encode the API sequence into a high-dimensional matrix in the preprocessing stage, reduce matrix dimension through API embedding operations, obtain fused sequence features based on BiLSTM and TextRNN models, and perform classification output at last. By integrating the sequential features of API sequences and the semantic features of functions, this method can achieve better classification performance.
Contributions. Focusing on dynamic features, we proposed a malicious code detection model based on API-Sequence-Semantic Fusion (Mal-ASSF). We utilize various technologies, including API2Vec, TextRNN, BiLSTM, and self-attention mechanisms, to enhance the model. Our research has made the following contributions:
API2Vec is a class of neural network models that can produce a corresponding vector for each unique API element in a continuous space in which the linguistic contexts of APIs can be observed. It is used to obtain the dimensionality reduction representation of the API call sequences. When establishing the correlation between APIs, we use a bidirectional long short-term memory network (BiLSTM) to capture the behavioral features of segments of different lengths.
A pair of operation and type, separately representing the verb and the objective in the function name, is designed to represent the API functions. To fully discover the implicit semantic information of API functions, we construct the core model based on TextRNN and the self-attention mechanism, where the sequence feature and semantic feature of API are fused, and the suspected malicious segments of the sequences are focused on adaptively.
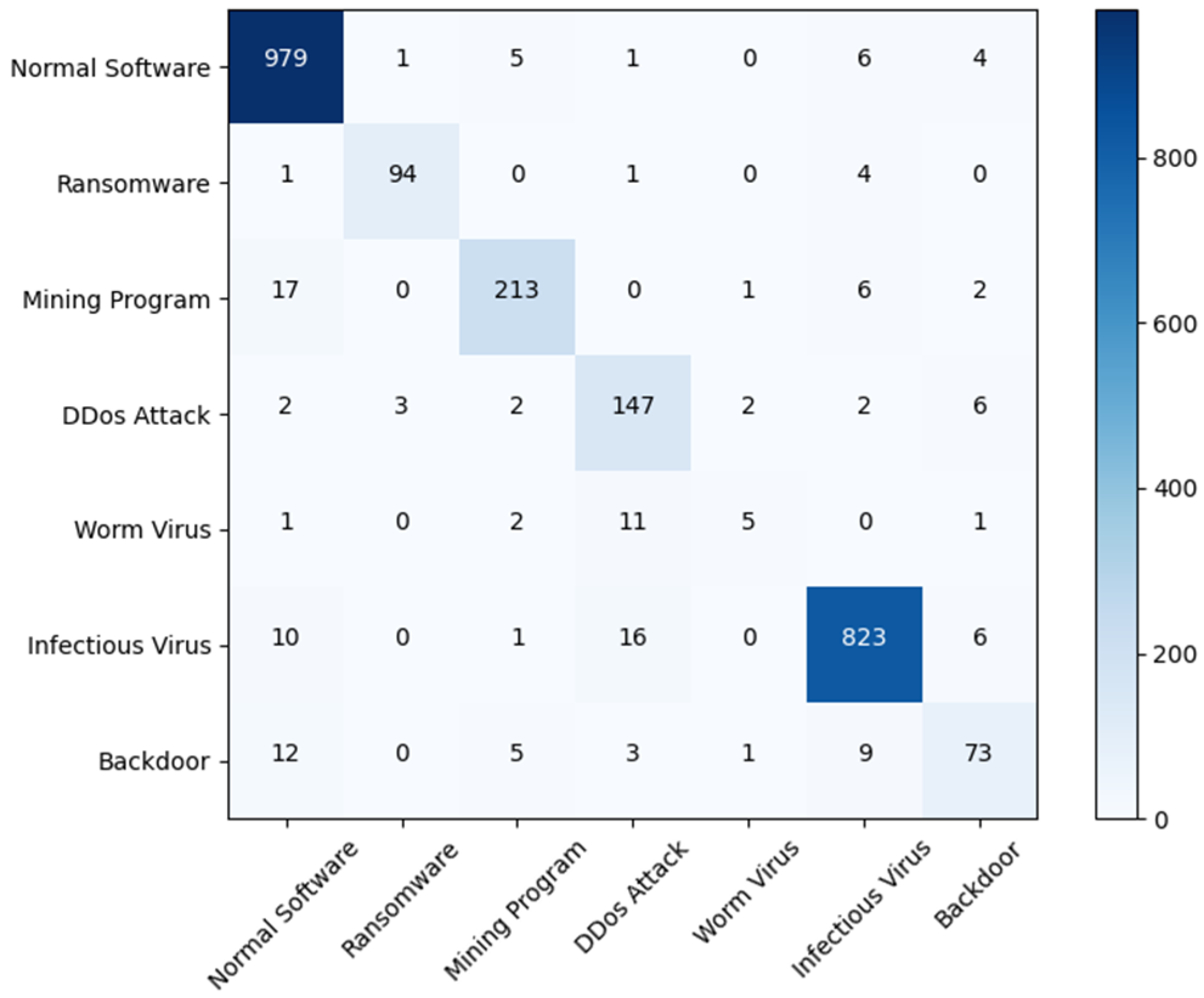
To evaluate the effectiveness of Mal-ASSF, we applied a systematic experiment to a large dataset of malware families. We build up a confusion matrix to analyze the performance of Mal-ASSF under different classification tasks. We perform experimental comparisons of different sequence lengths and determine whether to deduplicate. We compare Mal-ASSF with machine learning and other deep learning methods for classifying malicious code. We conduct ablation experiments to verify the effectiveness of each module in Mal-ASSF. The experimental results show that it achieves higher detection accuracy than related work, especially in the case of malware family classification and newer malware samples.
The rest of this paper is organized as follows:
Section 2 reviews related work on malware detection based on dynamic analysis;
Section 3 describes our proposed model in detail;
Section 4 presents our experimental setup and results;
Section 5 discusses the advantages and limitations of our approach, and concludes this paper and suggests future work.
2. Related Work
Dynamic Malware Analysis. API call sequences are considered a representative technique for understanding the behavioral characteristics of malware. To obtain API call sequences, the malicious code is executed within a regulated environment such as Cuckoo or Virmon sandboxes [
18]. Throughout the execution process, dynamic behaviors are continuously observed and subsequently traced. Typically, malware requires the launch of multiple processes to accomplish specific behaviors. The process may additionally entail the utilization of multiple threads. From the perspective of the API sequence of a single thread, it may be benign, but the API sequence of all threads as a whole may pose risks. Dynamic analysis considers the API calls of all related threads as a whole. The report generated from dynamic analysis outlines the conduct of malicious executables during their operation on affected hosts. This behavior can encompass downloading infected files from the Internet, performing harmful OS tasks, altering or erasing files, configuring or modifying system registries, remotely extracting vulnerable data, preventing authorized users from accessing resources, and slowing down the network, among other potential activities.
Dynamic Malware Analysis Based on Feature Engineering and Machine Learning. From these dynamic features, machine learning models, including K-Nearest Neighbors (KNN), Naive Bayes (NB), Decision Trees (DT), and Support Vector Machines (SVM), are utilized to classify the samples. [
19,
20,
21,
22,
23]. Based on the sequence of API calls, a C4.5 decision tree was applied to build a supervised learning model that distinguishes malware from benign files [
19]. Singh et al. [
22] extracted API calls as well as other behaviors such as file operations, registry modifications, and network activities and used a random forest (RF) method for classification. AL Ahmadi [
23] built a supervised malware classifier based on KNN and RF by mining features from network flow sequences. Despite their efficacy on the test set, these approaches heavily depend on feature engineering and necessitate the expertise of practitioners to select and refine suitable features. With the evolution of malicious code and the improvement of resistance capabilities, the refinement of feature engineering becomes an ongoing necessity.
Dynamic malware analysis based on deep learning. Deep learning has the capability to detect sequence features and autonomously identify malicious behaviors [
24]. Therefore, it is an effective tool for tackling the issue of malware classification [
6,
25,
26].
Vinayakumar et al. [
25] proposed a DNN-based model to develop a flexible and effective IDS to detect and classify unforeseen and unpredictable cyberattacks. Their research paper has been widely cited as it introduced deep learning techniques to the field of dynamic malware analysis. However, the model is insufficient for representing the sequential dependencies among the API calls made by malware. Jha et al. [
27] used RNN and word2vec to identify malware instances. The experimental outcomes demonstrated that optimal classification accuracy is attainable when utilizing relatively short sequence features (50–500). Conversely, inadequate classification performance was observed with long sequences. Catak et al. [
28] used word embeddings and a two-tier LSTM model to capture the correlation among API calls in sequences. To carry out a control experiment, they employed the TF-IDF method and vectorized the textual dataset using term frequency and inverse document frequency techniques. The experimental outcomes demonstrated that LSTM-based malware classification performed better than conventional machine learning algorithms, such as TF-IDF-based classification. However, this approach employs a unidirectional LSTM and only considers historical API relationships while ignoring API information in the future. Abusnaina et al. [
29] investigated the behavioral features of Windows APIs invoked by malware during runtime. They introduced the BiLSTM network and utilized it to model the sequential dependencies between API calls of malware in both forward and backward directions. The model presented demonstrated favorable effectiveness in classifying malware families and exhibits the capability to combat heuristic-based malware that leverages uncorrelated API sequence embedding. However, the sequence length of the dataset in this method is too short to objectively describe the API calls in the real world. All these methods above directly use the sequence information of the API for behavior modeling and do not take the semantic relationship between APIs into consideration.
Amer et al. [
30] used word embedding to capture the contextual relationship that exists between API functions in malware call sequences. Based on the contextual similarity, related APIs are clustered, and a simple behavioral graph is constructed to characterize malware. To detect such malware, they utilized a Markov chain model. Their work is instructive in proposing a technique for representing the semantic characteristics of API functions within a contextual framework. Kang et al. [
17] proposed a word2vec-driven technique for word embedding to evaluate opcodes and API function names with fewer dimensions. Every API incorporates a substantial amount of semantic information, including but not limited to categories, operations, parameters, and return values. This information can facilitate detection models comprehension of API sequences with greater precision. Zhang et al. [
30] proposed a predefined method to transform the API call semantic vector. This technique employs a hash method, which is capable of extracting information pertaining to the API call’s name, category, and parameters. The latest research has been conducted by Daeef et al. [
31] to implement deep graph convolutional neural networks (DGCNNs) for malware analysis. However, the result showed that it performed quite similarly to the traditional method of RF. All these methods are inadequate in terms of extracting API features as well as including excessive superfluous information, ultimately resulting in ineffective identification and the learning of implicit data pertaining to function APIs.
Dynamic malware detection based on semantic and sequential features of API call sequences. Chen et al. [
32] present a deep neural network-based malware detection approach where API call sequences are augmented with parameters. Clustering-based classification is employed to select malicious behavior-sensitive parameters. Through this method, the semantic relationship of APIs in terms of security is presented. Furthermore, Li et al. [
33] extract semantic features from API names and arguments and adopt an API call graph to convert the relationship between API calls into the structural information of the graph. Balan et al. [
34] present an ANN-based model focusing on sequence-pattern feature mining. Their experimental results show that the sequence pattern of OS API-related call sequences plays an important role in malware detection. Nawa et al. [
35] also explore the sequential pattern of API call sequences, and maximal and closed frequent API call patterns are utilized for malware classification. Compared to these works, in this paper we not only focus on exploring the semantic features of API functions but also integrate sequential features to obtain better performance with the classification of families of malware.
In summary, current work on dynamic feature analysis using functional calls of API sequences is inadequate for accurately representing the behavior patterns of malicious families. The performance of the existing classification approach fails to fulfill the requirements for accurately classifying various families of malicious codes. In Mal-ASSF, we fuse the semantic and sequence features and adopt a self-attention mechanism to enhance the effectiveness of malware family detection in the case of an excessive number of API types, oversized feature sets, and excessively long sequences. The experimental results reveal that Mal-ASSF has achieved a detection enhancement of approximately 3% to 5% in comparison to contemporary methods for dynamic analysis.
3. Methodology
In this section, we introduce the key design of Mal-ASSF to determine the API behavior for dynamic malware analysis.
3.1. Overview
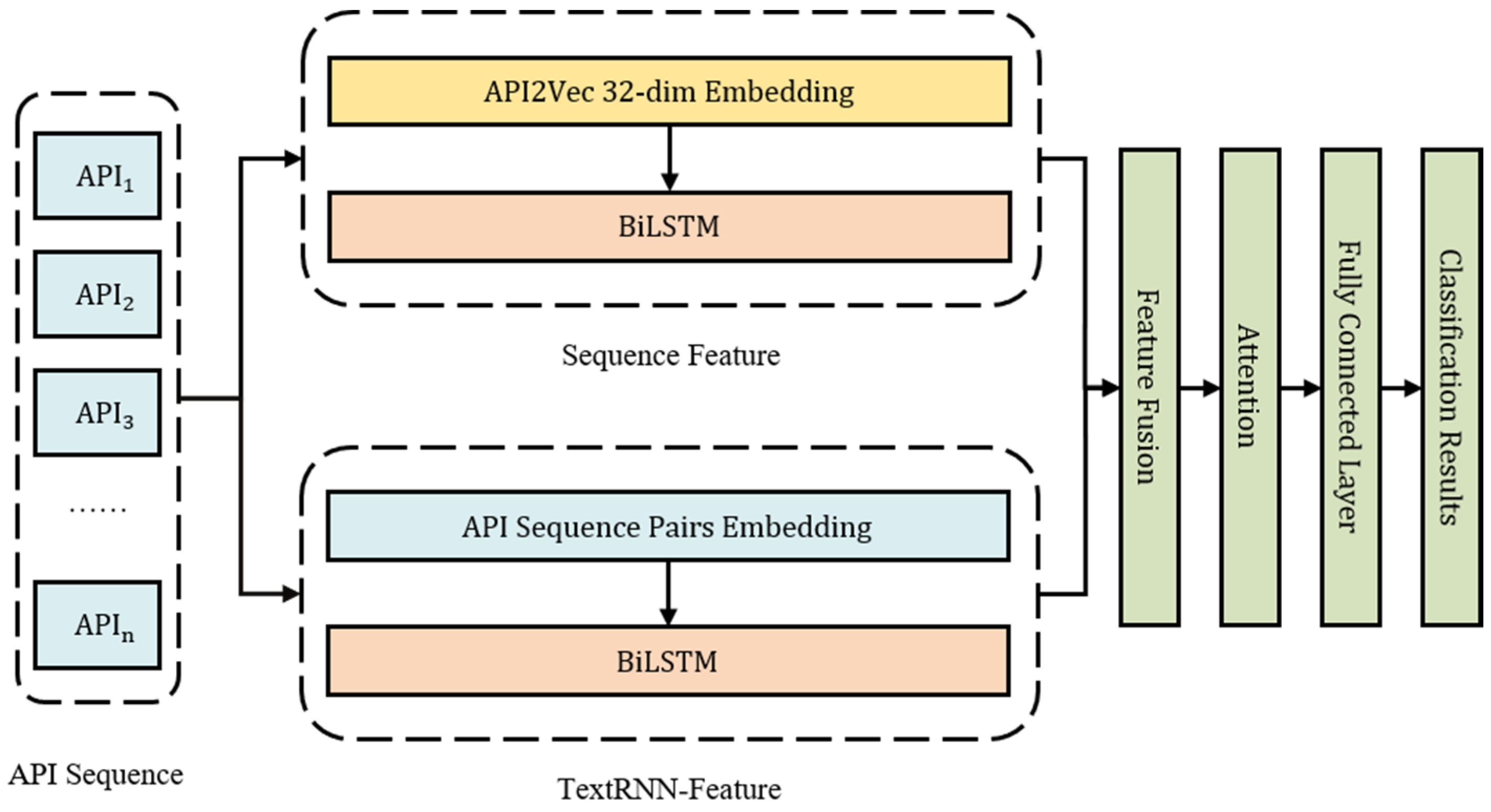
The overall structure of the Mal-ASSF model is shown in
Figure 1. The input of the Mal-ASSF framework is a well-labeled API sequence (for the stage where the trained model is used) or an unknown sample (for the stage where the trained model is used for classification). API sequences are extracted from the operation analysis report of executable file samples. API sequences are processed in parallel by the sequence feature module and the TextRNN feature module. The API sequence is converted into two-dimensionally reduced sequences. Then, the classification results will be drawn through the fusion module, the attention module, and the final MLP classifier module.
In the preparation process, we run the executable file samples in a security sandbox environment to obtain the operation analysis report in JSON format. We extract the API call information, which is recorded in order, from the report.
In the sequence feature module, to represent API behavior, we adopt API2Vec embedding and BiLSTM. Through dimensionality reduction and convolution operations, functional behavior with different lengths can be captured. The APIs are then converted into a sequential chain.
In the TextRNN feature module, the API semantic chain of function names is transferred into a vectorized representation containing operation type encoding and operation object encoding by the embedding layer, and the implicit semantic features are extracted by the BiLSTM layer.
In the fusion module, the outputs of the API embedding module and the API implicit semantic extraction module are concatenated together to obtain all the features of the API sequences.
In the attention module, the attention mechanism is used to calculate the weight corresponding to each positioning element so that the model can focus on some malicious segments.
In the MLP classifier module, we apply a fully connected layer MLP for classification. Dropout is adopted to reduce overfitting. Softmax is used to calculate the probability of malware classification. The module uses an Adam optimizer with binary cross-entropy as the loss function.
The subsequent paragraphs of this section will provide a detailed account of the data processing mechanism.
3.2. Detailed Archetecture
3.2.1. Data Preparation
In the preparation process, the API call information is extracted from the operation analysis report. However, the API call information should be preprocessed. To evade existing feature detection, malicious code is often inserted into benign code or obfuscated with a considerable number of APIs with no actual function. Therefore, the API call sequence obtained by sandbox sampling must be of sufficient length (thousands at least), which means the length of the API call information samples far exceeds common sequence length for classification problems such as emotion recognition and comment classification. Additionally, there are some short-call sequence samples for classification.
Therefore, truncation and padding operations should be performed for the API sequences to be trimmed to the same length. The data preparation provides convenience for the subsequent process.
3.2.2. Vectorized Representation Based on API2Vec
To express the relationship between functions in API sequences and reduce the amount of computation, we map the API call sequences from strings into vectors.
One-hot encoding is well known as a traditional method for vectorization. However, this method is associated with several problems. Firstly, the relationship between APIs is independent through one-hot encoding, which means that the lack of contextual connections is evident. Additionally, the feature vectors will be quite sparse and bring challenges to the subsequent process. To address this problem, we use an API2Vec vectorization method based on Word2Vec to perform word embedding operations on APIs.
In the API2Vec vectorization method, we vectorize string data through a shallow neural network, and the semantic information of the words is represented in the form of word vectors. Through this approach, we reduce the dimensionality of word vectors, and the word vectors corresponding to APIs with similar semantics are also similar. For example, the system functions NtOpenFile and NtReadFile both belong to file operations. NtOpenFile is used to open a file, and NtReadFile is used to read a file, which means the two functions are semantically similar. Then, in the new multi-dimensional space, the expressed word vector should also be relatively close. On the contrary, the RegOpenKeyEx function is used to open a specified registry key, which is different from the former file operation functions, and the distance of the word vectors is relatively far.
The training process of API2Vec is shown in
Figure 2. The detailed illustrations are as follows:
We first encode the API information through one-hot encoding to obtain a high-dimensional sparse feature vector.
We then train a shallow neural network to obtain the hidden layer weight of each API. The input layer and the hidden layer weights are jointly calculated to obtain the output vector, which is also the word vector form of the API and can uniquely identify each API. We use the Skip-Gram model for weight training due to the relatively small association between APIs. Assuming that an API is represented by a 32-dimensional vector feature, for 295 kinds of APIs, compared to the 295-dimensional one-hot encoding form, the API2Vec method can be used to reduce the dimension of the word vector to 32 dimensions.
The word vector representation of each API name with a fixed dimension is finally calculated and stored in the form of a dictionary.
Through the vectorization of the name of each function in API sequences, the distance relationship between functions can be better expressed, and the amount of computation is reduced through moderate dimensionality reduction, which facilitates the model to efficiently learn features in a specific functional sequence.
3.2.3. API Implicit Semantic Sequence Feature Extraction
To capture the implicit information behind APIs, we use triples for descriptions. Assuming that
is a pair representation of the
i-th API in the sequence, then the representation of
can be shown in Equation (1).
where
stands for
operation and
stands for
type.
Operation refers to the actions of APIs. According to the analysis of common functions, we extracted about 50 verbs from common API names to establish the operation set shown in
Table 1. Elements of the set basically outline the core operations of API function calls. The operations can be extracted and stored in the form of a dictionary through a string extraction algorithm.
Type refers to the API classification given in the Cuckoo sandbox. The APIs can be divided into over 10 types, including system, network, process, registry, interface, and others. The detailed type list is shown in
Table 2.
According to the descriptions above, each function of the API sequence can be described as a pair
, according to the implicit information. Examples are shown in
Table 3.
The pairs formed by each API are connected in sequence to form a pair sequence to generate an implicit semantic chain of sequence information. The process of converting each sample into a semantic chain and performing feature mapping is shown in
Figure 3.
3.2.4. Sequence Feature Extraction Based on BiLSTM
Mal-ASSF adopts BiLSTM [
36] to capture the complex calling relationship between APIs. The two LSTMs are connected, and each input API sequence feature will be trained and learned by the network in both forward and reverse directions. The network weights of BiLSTM are shared, which can accurately reflect the sequence features of malicious code families.
Figure 4 shows the schematic diagram of BiLSTM unfolding at time
according to the time axis, where
is the input,
is the hidden layer state, and
is the current output.
The two directions of BiLSTM at time
can be calculated as shown in Equations (2) and (3).
After processing the features of API sequences and implicit semantics by embedding operations, these vectorized data can be input into the BiLSTM networks.
The API embedding and BILSTM convolution operations within two parallel modules actually extract the sequence features and TextRNN features of API sequences, respectively. While learning API sequential relationships and semantic features, Mal-ASSF can also pay attention to the calling sequence. Certain types of malicious code families have distinct sequence features, so using the BiLSTM network to capture the sequence features of API calls is helpful for the identification of malicious code family features.
3.2.5. Key API Sequence Recognition Based on the Attention Mechanism
Mal-ASSF applies an attention module for the recognition of key API sequences. The module consists of three computational stages, as follows:
- (1)
The dot product is used to calculate the correlation between the two sides, as shown in Equation (4).
- (2)
The Softmax function is introduced to numerically transform the scores calculated in the first stage. As shown in Equation (5), normalization is performed, and important factor weights are highlighted.
- (3)
The calculated in the second stage is the weight coefficient corresponding to . The attention value can be calculated by weighted summation. In this way, the attention value of each element can be calculated. as shown in Formula (6).
Mal-ASSF regards the constituent elements in the data as a series of
data pairs. Given an element
in the target, by calculating the similarity between
and each
, the weight coefficient of each
Key corresponding to the value can be calculated. After the weighted summation of the values, the final attention value can be obtained.
Figure 5 is a computational process diagram of the attention mechanism.
5. Conclusions
To address the problem that the dynamic feature set is too large to discover the key hidden information, we propose a dynamic malware detection model, Mal-ASSF, based on the fusion of sequential features and semantic features of API call sequences. In Mal-ASSF, the API functions are represented by dimensionality reduction through word embedding. The sequential behavioral features of different length segments are captured by multiple convolution kernels. The information of the function API is depicted by a triplet of action, type, category, and other information.
Mal-ASSF has advantages in the semantic representation and key sequence recognition abilities of API call sequences. Compared with traditional machine learning methods such as KNN, SVM, DT, RF, and XGB, the detection performance of Mal-ASSF is improved by three to eight percentage points; compared with deep learning models such as TextCNN, CNN + LSTM, and TextCNN + LSTM, the performance of the Mal-ASSF model is also improved by two to five percentage points. However, through the ablation experiment, it can be concluded that the improvement of the BiLSTM module is not particularly obvious. Further studies can be conducted to obtain a better representation of semantic features using pre-trained models.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}