
Automatic Detection of Multilevel Communities: Scalable, Selective and Resolution-Limit-Free †

Abstract
:1. Introduction
2. Method
2.1. Community Fitness Function
2.2. Heuristic Optimization Algorithm
- Initialize communities. At the very beginning, each node of the network is designated to an individual community. A network consisting of N nodes is then divided into N communities of size 1.
- Optimize communities of the lowest level. Sequentially consider each node of the network and scan its neighboring communities (i.e., communities sharing at least one edge with the node in focus). Calculate the potential gains of if the node in focus was moved out of its original community and put into each of the neighboring communities. Place the node in focus into the community that leads to a maximum value of .
- Iterate until convergence. Repeat step 2 until a maximum value of Formula (3) is reached where no more moves of any node may further increase this value. During this process, the sequence of node orders is randomized every time a new round of iteration is started.
- Merge communities to build a higher community level. Consider each community obtained at the convergence of step 3 as a fixed module; hereafter, all its members (nodes) must be moved together. Repeat the above steps 2 and 3 by taking each fixed module as a node. During this process, connected modules gradually condense into communities of higher levels, until a maximum value of Formula (3) is reached.
- Iterate until convergence at the highest level. Repeat step 4 and detect communities of all levels, until the highest level is detected where no further merging of any communities can increase .
- Output communities. Communities of all levels detected by the above steps 1 to 5 form a hierarchical structure; each level can be independently outputted. Customarily, only the output of the highest level is adopted since it has a maximum value of among all levels.
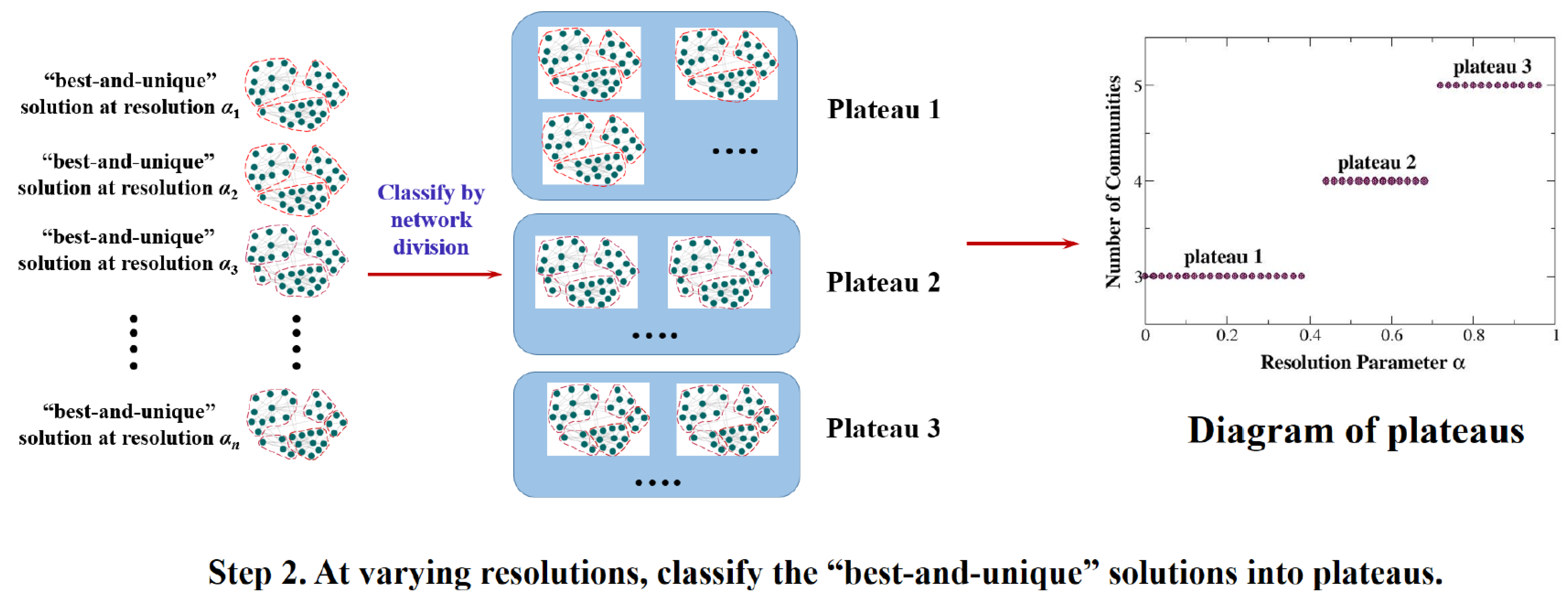
2.3. Strategy to Filter the Output
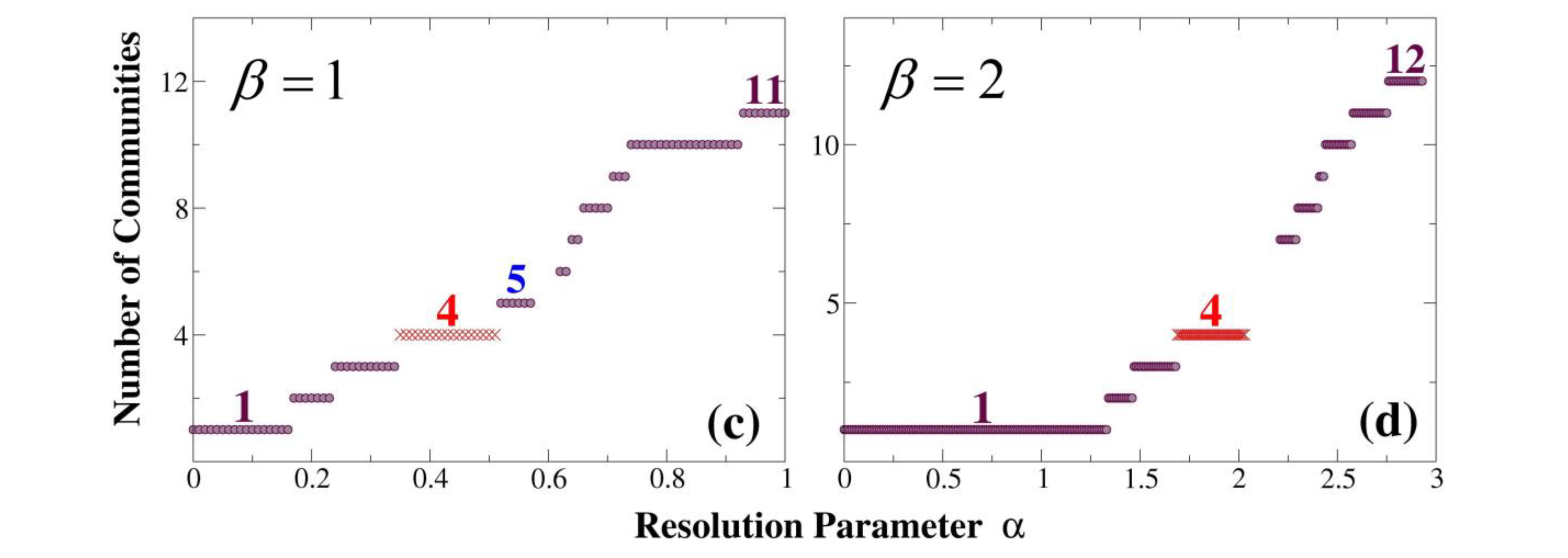
- At each fixed resolution (i.e., with fixed values of parameters α and β), we implement the Louvain algorithm on the same network in multiple realizations. Among the outputs of all realizations, we adopt the ones with the highest value of as our best solutions obtained at this resolution. In addition, we require the topology of these best solutions to be unique: in case two or more solutions have equally highest values of , but represent different topological structures of community, all solutions obtained at this resolution will be abandoned, and the corresponding resolution will be considered “irrelevant” and not contributing to any potential plateau.
- At different resolutions, with varying values of α (during which the value of β is still fixed), we run the above step 1 and obtain the best-and-unique solutions at all relevant resolutions. Then we compare the topologies of these best-and-unique solutions, and classify them into different plateaus; solutions classified to the same plateau must represent exactly the same topological structure of community.
3. Results
3.1. On the Hierarchical Ravasz-Barabasi (RB) Networks
3.2. On the Heterogeneous Lancichinetti-Fortunato-Radicchi (LFR) Benchmark Networks
3.3. Applications to Real-World Networks
3.4. Tests on Extremely Large Networks with Ground Truth Communities
4. Discussion
4.1. Scalability of the Community Fitness Function
4.2. Stability of the Outputs
4.3. Multilevel Communities in Real-World Networks
4.4. Computational Complexity of Our Approach
- For each group of fixed parameters (α, β), we run the algorithm in 1000 realizations to make sure there are always some realizations converging to a best solution. In practice, this is usually not necessary; 100 realizations will be sufficient for most practical purposes.
- For some networks whose fitness landscape is really complex, involving large numbers of local maxima [42], it is sometimes difficult to filter out unstable solutions within finite realizations. Then, a little trick may help to reduce the computational burden. We can run our computations in multiple batches. Each batch consists of a certain number of realizations, and produces an independent set of plateaus by the strategy proposed in Section 2.3. Next, we take an intersection over all sets of plateaus obtained in different batches: if at a certain resolution different batches yield different network divisions, this resolution will be considered irrelevant and knocked out from the plateaus in the final output. Namely, by such an intersection we are requiring not only “one plateau one topology,” but also the uniqueness of this topology over multiple batches of computations. We tested on all the synthetic and real-world networks studied in this paper. By 20 batches of 100 realizations of computations, we can efficiently remove unstable results that may sometimes require almost 10,000~20,000 realizations in a single batch to remove them. Yet, for most networks, running multiple batches is not necessary for practical purposes.
- For each fixed β, we vary α from 0 to 2β − 1 with a stepwise increment Δα = 0.01, in order to search every inches of the resolution scales and discover all potential plateaus. In practice, to reduce the computational burden, we suggest to firstly use a relatively larger value of increment Δα for a global and coarse-grained search, and then use smaller values for detailed searches in the focused regions found in the global search.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Relevant Range of the Resolution Parameter α
Appendix A.1. Upper Bound of α: Splitting a Random Graph
Appendix A.2. Lower Bound of α: Merging Complete Graphs
References
- Arenas, A.; Díaz-Guilera, A.; Pérez-Vicente, C.J. Synchronization Reveals Topological Scales in Complex Networks. Phys. Rev. Lett. 2006, 96, 114102.1–114102.4. [Google Scholar] [CrossRef] [Green Version]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fortunato, S.; Barthelemy, M. Resolution limit in community detection. Proc. Natl. Acad. Sci. USA 2007, 104, 36–41. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Fushing, H. Multiscale community geometry in a network and its application. Phys. Rev. E 2012, 86, 041120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arenas, A.; Fernández, A.; Gómez, S. Analysis of the structure of complex networks at different resolution levels. New J. Phys. 2007, 10, 053039. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Detecting community structure in networks. Eur. Phys. J. B 2004, 38, 321–330. [Google Scholar] [CrossRef]
- Arenas, A.; Danon, L.; Díaz-Guilera, A.; Gleiser, P.M.; Guimera, R. Community analysis in social networks. Eur. Phys. J. B 2004, 38, 373–380. [Google Scholar] [CrossRef] [Green Version]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Moody, J.; White, D.R. Structural Cohesion and Embeddedness: A Hierarchical Concept of Social Groups. Am. Sociol. Rev. 2003, 68, 103–127. [Google Scholar] [CrossRef] [Green Version]
- Rice, S.A. The Identification of Blocs in Small Political Bodies. Am. Politi-Sci. Rev. 1927, 21, 619–627. [Google Scholar] [CrossRef]
- Weiss, R.S.; Jacobson, E. A Method for the Analysis of the Structure of Complex Organizations. Am. Sociol. Rev. 1955, 20, 661–668. [Google Scholar] [CrossRef]
- Funke, T.; Becker, T. Stochastic block models: A comparison of variants and inference methods. PLoS ONE 2019, 14, e0215296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [Green Version]
- Ramirez-Marquez, J.E.; Rocco, C.M.; Barker, K.; Moronta, J. Quantifying the resilience of community structures in networks. Reliab. Eng. Syst. Saf. 2018, 169, 466–474. [Google Scholar] [CrossRef]
- Chen, G.; Zhou, S.; Li, M.; Zhang, H. Evaluation of community vulnerability based on communicability and structural dissimilarity. Phys. A Stat. Mech. Its Appl. 2022, 606, 128079. [Google Scholar] [CrossRef]
- Lu, L.; Wang, X.; Ouyang, Y.; Roningen, J.; Myers, N.; Calfas, G. Vulnerability of Interdependent Urban Infrastructure Networks: Equilibrium after Failure Propagation and Cascading Impacts. Comput. Civ. Infrastruct. Eng. 2018, 33, 300–315. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W. H. Freeman: San Francisco, CA, USA, 1979. [Google Scholar]
- Scott, J. Social Network Analysis: A Handbook, 2nd ed.; Sage Publications: London, UK, 2000. [Google Scholar]
- Homans, G.C. The Human Groups; Harcourt, Brace & Co.: New York, NY, USA, 1950. [Google Scholar]
- Ravasz, E.; Barabasi, A. Hierarchical organization in complex networks. Phys. Rev. E 2003, 67, 026112. [Google Scholar] [CrossRef] [Green Version]
- Leskovec, J.; Lang, K.J.; Dasgupta, A.; Mahoney, M.W. Statistical properties of community structure in large social and information networks. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; ACM: New York, NY, USA; pp. 695–704. [Google Scholar]
- Donath, W.E.; Hoffman, A.J. Lower Bounds for the Partitioning of Graphs. IBM J. Res. Dev. 1973, 17, 420–425. [Google Scholar] [CrossRef]
- Spielman, D.A.; Teng, S.-H. Spectral partitioning works: Planar graphs and finite element meshes. In Proceedings of the IEEE Symposium on Foundations of Computer Science, Burlington, VT, USA, 14–16 October 1996; pp. 96–105. [Google Scholar] [CrossRef] [Green Version]
- von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2004, 17, 395–416. [Google Scholar] [CrossRef]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Soc. Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Peixot, T.P. Hierarchical block structures and high-resolution model selection in large networks. Phys. Rev. X 2014, 4, 011047. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Analysis of weighted networks. Phys. Rev. E 2004, 70, 056131. [Google Scholar] [CrossRef] [Green Version]
- Clauset, A. Finding local community structure in networks. Phys. Rev. E 2005, 72, 026132. [Google Scholar] [CrossRef] [Green Version]
- Luo, F.; Wang, J.Z.; Promislow, E. Exploring Local Community Structures in Large Networks. In Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2006 Main Conference Proceedings) (WI′06) 0-7695-2747-7/06, Washington, DC, USA, 18–22 December 2006. [Google Scholar]
- Lancichinetti, A.; Fortunato, S.; Kertész, J. Detecting the overlapping and hierarchical community structure in complex networks. New J. Phys. 2009, 11, 033015. [Google Scholar] [CrossRef]
- Reichardt, J.; Bornholdt, S. Partitioning and modularity of graphs with arbitrary degree distribution. Phys. Rev. E 2007, 76, 015102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reichardt, J.; Bornholdt, S. Detecting Fuzzy Community Structures in Complex Networks with a Potts Model. Phys. Rev. Lett. 2004, 93, 218701. [Google Scholar] [CrossRef] [Green Version]
- Reichardt, J.; Bornholdt, S. Statistical mechanics of community detection. Phys. Rev. E 2006, 74, 016110. [Google Scholar] [CrossRef] [Green Version]
- Hastings, M.B. Community Detection as an Inference Problem. Phys. Rev. E 2006, 74, 035102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronhovde, P.; Nussinov, Z. Multiresolution community detection for megascale networks by information-based replica correlations. Phys. Rev. E 2009, 80, 016109. [Google Scholar] [CrossRef]
- Ronhovde, P.; Nussinov, Z. Local resolution-limit-free Potts model for community detection. Phys. Rev. E 2010, 81, 046114. [Google Scholar] [CrossRef] [Green Version]
- Rosvall, M.; Bergstrom, C.T. Maps of random walks on complex networks reveal community structure. Proc. Natl. Acad. Sci. USA 2008, 105, 1118–1123. [Google Scholar] [CrossRef] [Green Version]
- Kumpula, J.M.; Saramaki, J.; Kaski, K.; Kertesz, J. Resolution limit in complex network community detection with Potts model approach. Eur. Phys. J. B 2007, 56, 41–45. [Google Scholar] [CrossRef] [Green Version]
- Guimerà, R.; Sales-Pardo, M.; Amaral, L.A.N. Modularity from fluctuations in random graphs and complex networks. Phys. Rev. E 2004, 70, 025101. [Google Scholar] [CrossRef] [Green Version]
- Guimera, R.; Nunes Amaral, L.A. Functional cartography of complex metabolic networks. Nature 2005, 433, 895–900. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Traag, V.A.; Dooren, P.V.; Nesterov, Y. Narrow scope for resolution-limit-free community detection. Phys. Rev. E 2011, 84, 016114. [Google Scholar] [CrossRef] [Green Version]
- Lancichinetti, A.; Fortunato, S. Limits of modularity maximization in community detection. Phys. Rev. E 2011, 84, 066122. [Google Scholar] [CrossRef] [Green Version]
- Clauset, A.; Newman, M.E.J.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Good, B.H.; Montjoye, Y.D.; Clauset, A. Performance of modularity maximization in practical contexts. Phys. Rev. E 2009, 81, 046106. [Google Scholar] [CrossRef] [Green Version]
- Le Martelot, E.; Hankin, C. Multi-scale community detection using stability optimisation. Int. J. Web Based Communities 2013, 9, 323–348. [Google Scholar] [CrossRef]
- Xiang, J.; Tang, Y.N.; Gao, Y.Y.; Zhang, Y.; Deng, K.; Xu, X.K.; Hu, K. Multi-resolution community detection based on generalized self-loop rescaling strategy. Phys. A Stat. Mech. Its Appl. 2015, 432, 127–139. [Google Scholar] [CrossRef] [Green Version]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saha, S.; Ghrera, S.P. Nearest Neighbor search in Complex Network for Community Detection. Information 2015, 7, 17. [Google Scholar] [CrossRef] [Green Version]
- Radicchi, F.; Castellano, C.; Cecconi, F.; Loreto, V.; Parisi, D. Defining and identifying communities in networks. Proc. Natl. Acad. Sci. USA 2004, 101, 2658–2663. [Google Scholar] [CrossRef] [Green Version]
- Fortunato, S.; Newman, M.E.J. 20 years of network community detection. Nat. Phys. 2022, 18, 848–850. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Chen, H.; Zhang, P.; Li, M.; Di, Z.; Fan, Y. A New Comparative Definition of Community and Corresponding Identifying Algorithm. Phys. Rev. E 2008, 78, 026121. [Google Scholar] [CrossRef] [Green Version]
- Fred, A.L.N.; Jain, A.K. Robust data clustering. In Proceedings of the IEEE Computer Society Conference on Computer Vision Pattern Recognition (Computer Society, Toronto, 2003), Madison, WI, USA, 18–20 June 2003; 2003; Volume 2, p. 128. [Google Scholar]
- Peel, L.; Larremore, D.B.; Clauset, A. The ground truth about metadata and community detection in networks. Sci. Adv. 2017, 3, e1602548. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Lusseau, D. The emergent properties of a dolphin social network. Proc. R. Soc. B Boil. Sci. 2003, 270, S186–S188. [Google Scholar] [CrossRef] [Green Version]
- Ghasemian, A.; Hosseinmardi, H.; Clauset, A. Evaluating Overfit and Underfit in Models of Network Community Structure. IEEE Trans. Knowl. Data Eng. 2019, 32, 1722–1735. [Google Scholar] [CrossRef] [Green Version]
- Medus, A.; Acuña, G.; Dorso, C. Detection of community structures in networks via global optimization. Phys. A Stat. Mech. Appl. 2005, 358, 593–604. [Google Scholar] [CrossRef]
- Zhou, H. Distance, dissimilarity index, and network community structure. Phys. Rev. E 2003, 67, 061901. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Sun, H.; Liu, Y.; Song, Q.; Weninge, T. Towards Online Multiresolution Community Detection in Large-Scale Net-works. PLoS ONE 2011, 6, e23829. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Hu, Y.; Di, Z. Community detection with cellular automata. J. Beijing Norm. Univ. 2008, 44, 153–156. [Google Scholar]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Lusseau, D.; Newman, M.E.J. Identifying the role that animals play in their social networks. Proc. R. Soc. B Boil. Sci. 2004, 271 (Suppl. 6), S477–S481. [Google Scholar] [CrossRef] [Green Version]
- Lusseau, D. Evidence for social role in a dolphin social network. Evol. Ecol. 2007, 21, 357–366. [Google Scholar] [CrossRef] [Green Version]
- Evans, T. Clique graphs and overlapping communities. J. Stat. Mech. Theory Exp. 2010, 2010, P12037. [Google Scholar] [CrossRef]
- Yang, J.; Leskovec, J. Defining and Evaluating Network Communities Based on Ground-Truth. In Proceedings of the 12th IEEE International Conferences on Data Mining (ICDM 2012), Brussels, Belgium, 10–13 December 2012; pp. 745–754. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RB5n Networks | Community Levels (m) | |||||
|---|---|---|---|---|---|---|
| 1 (Lowest) | 2 | 3 | 4 | 5 | 6 | |
| RB25 (n = 2) | 6 | 1 | / | / | / | / |
| RB125 (n = 3) | 30 | 10 | 1 | / | / | / |
| RB625 (n = 4) | 150 | 50 | 14 | 1 | / | / |
| RB3125 (n = 5) | 750 | 250 | 70 | 18 | 1 | / |
| RB15625 (n = 6) | 3750 | 1250 (undetectable) | 350 | 90 | 22 (undetectable) | 1 |
| Network | Size | Number of Edges | Numbers of Communities Suggested by | |||
|---|---|---|---|---|---|---|
| “Ground Truth” 1 | Q | Infomap | ||||
| Amazon | 334,863 | 925,872 | 4097 | 243 | 141,557 | 3373 |
| DBLP | 317,080 | 1,049,866 | 12,878 | 213 | 302,402 | 114,049 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, K.; Ren, X.; Zhou, L.; Zhu, J. Automatic Detection of Multilevel Communities: Scalable, Selective and Resolution-Limit-Free. Appl. Sci. 2023, 13, 1774. https://doi.org/10.3390/app13031774
Gao K, Ren X, Zhou L, Zhu J. Automatic Detection of Multilevel Communities: Scalable, Selective and Resolution-Limit-Free. Applied Sciences. 2023; 13(3):1774. https://doi.org/10.3390/app13031774
Chicago/Turabian StyleGao, Kun, Xuezao Ren, Lei Zhou, and Junfang Zhu. 2023. "Automatic Detection of Multilevel Communities: Scalable, Selective and Resolution-Limit-Free" Applied Sciences 13, no. 3: 1774. https://doi.org/10.3390/app13031774