1. Introduction
Emotion recognition in conversations (ERC) has attracted more and more attention because of the prevalence of dialogue behavior in various fields. The primary purpose of ERC is to recognize the emotion of each utterance in the dialogue. The recognized emotion can be used for opinion mining on social media, such as Facebook and Instagram, building conversational assistants, and conducting medical psychoanalysis [
1,
2,
3,
4]. However, ERC, especially emotion recognition in multi-party conversations (ERMC), often exhibits more difficulties than traditional text sentiment analysis due to the emotional dynamics of dialogue [
4]. There are two kinds of emotional dependencies among the participants in a dialogue—inter-dependency and self-dependency. Self-dependency is the influence of what the speaker says on the current utterance. Inter-dependency is the influence of what others say on what the current speaker says. Therefore, identifying the emotion of an utterance in a multi-party dialogue depends not only on the utterance itself and its context, but also on the speaker’s self-dependence and the inter-dependency [
5,
6].
Existing work on emotion recognition in conversations can be roughly divided into two categories: that based on recurrent neural networks and that based on graph neural networks. Some recent works based on recurrent neural networks [
3,
7,
8,
9,
10,
11,
12,
13] began to focus on conversational context modeling and speaker-specific modeling, and some works [
14] have even carried out multi-task learning for speaker-specific modeling on this basis. They tried to deal with speaker-dependent influences through speaker-specific modeling and conversational context modeling, but they could use other speakers’ utterances to influence the current utterance well. Meanwhile, some works based on graph neural networks [
5,
6,
15,
16,
17,
18] have used relational graph convolutional networks (RGCNs) [
19] to distinguish among different speaker dependencies, and some have even used conversational discourse structure [
6] or commonsense knowledge [
18] to extend relationships among utterances. These models are intended to establish more perfect utterance relations and then aggregate according to the relations to form the influence of the surrounding utterances on the current utterance. However, the performance of such models is affected by the type and quantity of inter-utterance relations. Moreover, an emotional change in a speaker may be caused by the joint influence of multiple utterances of multiple speakers. This influence may also be caused by the interactions of utterances in different relationships. So, inter-dependency is more complex than self-dependency. We believe that it is necessary to build a graph network alone to model inter-dependency, especially for multi-dialogue, and this can allow better identification of the problem of emotional shifts between consecutive utterances of the same speaker.
Conventional graph neural networks focus on pairwise relationships between objects in the constructed graphs. In many real-world scenarios, however, relationships among objects are not dyadic (pairwise), but rather triadic, tetradic, or higher. Squeezing the high-order relations into pairwise ones leads to information loss and impedes expressiveness [
20]. So, we used a hypergraph neural network [
21] to deal with two kinds of speaker dependencies instead of using a conventional graph neural network. According to the hypergraph [
21] structure, we know that a hyperedge may contain multiple utterances, and an utterance may belong to multiple hyperedges. We let each utterance generate a hyperedge. The nodes on the hyperedge are the corresponding current utterance and the specific context of the current utterance. Hypergraph neural networks [
21] can use the structure of a hypergraph to deal with the influences of multiple utterances from multiple speakers on an utterance, that is, they use multiple surrounding utterances to produce an influence on the current utterance. By performing a node–edge–node transformation, the underlying data relationship can be better represented [
21], and more complex and high-level relationships can be established among nodes [
22]. Previous work has shown that speaker-specific information is very important for ERMC [
3,
6]. Therefore, the way of using hypergraphs for speaker-specific modeling of ERMC is a very important issue. Second, the current utterance may be influenced by utterances from different speakers. Therefore, the way of using hypergraphs for non-speaker-specific modeling of ERMC is also a very important issue.
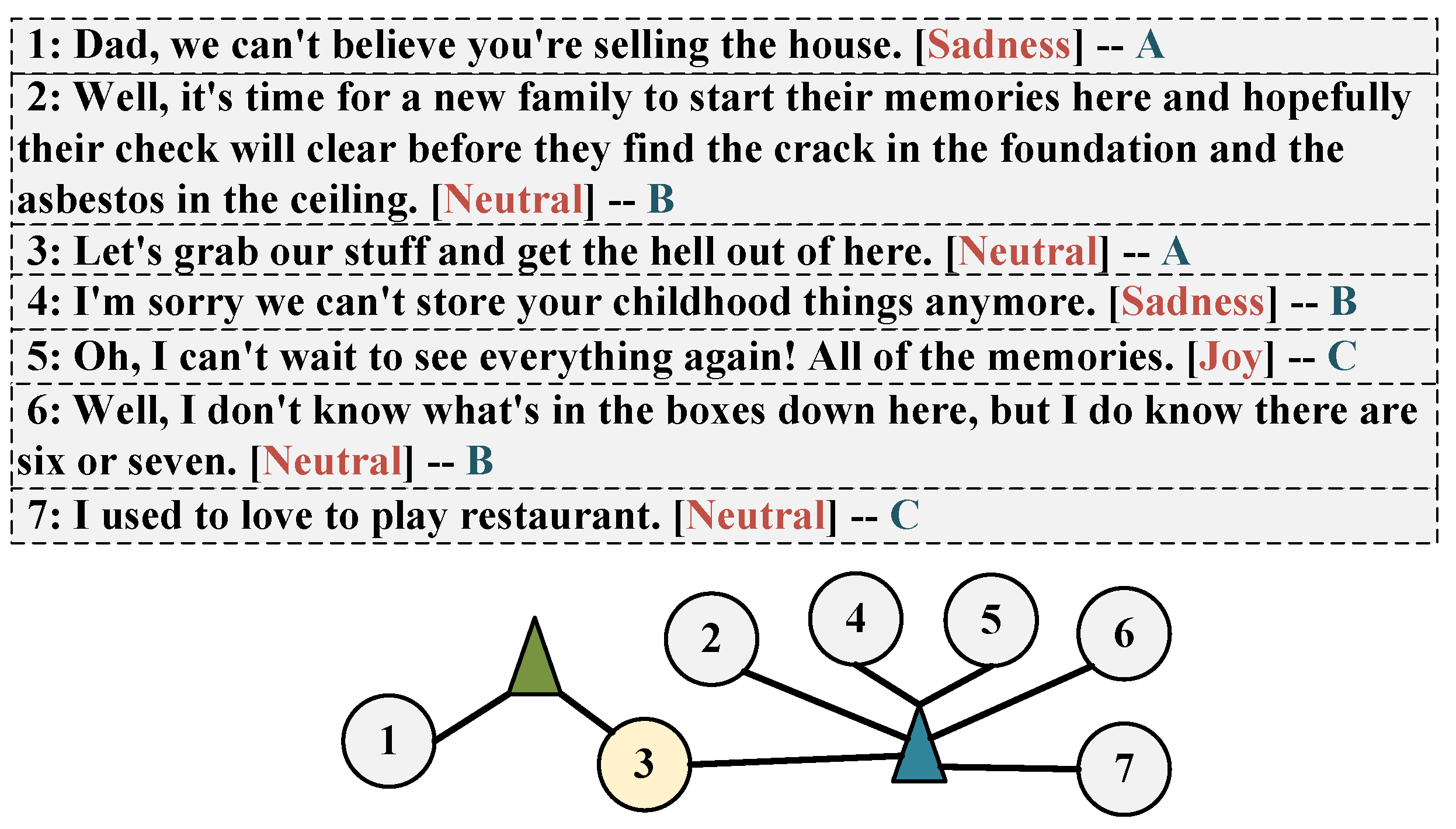
In this paper, we construct two hypergraphs for speaker-specific and non-speaker-specific modeling, respectively. The hyperedges in the two hypergraphs are different. The hypergraph for speaker-specific modeling, where the nodes on the hyperedge are from the speaker of the current utterance, mainly deals with self-dependency. The hypergraph for non-speaker-specific modeling, where nodes on a hyperedge contain the current utterance and utterances from other speakers, is primarily used to handle inter-dependency. In
Figure 1, we construct two kinds of hyperedges for the third utterance. The hyperedge of the green triangle indicates that the node of the hyperedge is from speaker B of the third utterance. The hyperedge of the blue triangle indicates that the nodes of the hyperedge are from speakers other than speaker B. Note that this hyperedge needs to contain the current utterance so that the nodes within the hyperedge have an effect on the current utterance. We use the location information and node features to aggregate to generate hyperedge features. Here, we use the location information to obtain the weight of the average aggregation, use the node features to perform the attention aggregation to obtain the attention weight, and combine the two weights to obtain the hyperedge features. Then, the hyperedge features are used to model the conversational context by using a recurrent neural network. Finally, the hyperedge features are used to aggregate to obtain new node features. The hypergraph convolution of the two hypergraphs can be used to model specific speakers and non-specific speakers so as to deal with inter-dependency and self-dependency among participants.
The main contributions of this work are summarized as follows:
We construct hypergraphs for two different dependencies among participants and design a multi-hypergraph neural network for emotion recognition in multi-party conversations. To the best of our knowledge, this is the first attempt to build graphs for inter-dependency alone.
We combine average aggregation and attention aggregation to generate hyperedge features that can allow better utilization of the information of utterances.
We conducted experiments on two public benchmark datasets. The results consistently demonstrate the effectiveness and superiority of the proposed model. In addition, we achieved good results on the emotional shift issue.
3. Methodology
3.1. Hypergraph Definition
A hypergraph is defined as
, where
is a node set, and
is a collection of hyperedges. A hyperedge
is a subset of the node set
V, that is, the node set belonging to hyperedge
is a subset of
V. The structure of a hypergraph HG can also be represented by an incidence matrix A, with entries defined as in Equation (
1):
We use to denote the attribute vector of nodes in the hypergraph. So, the hypergraph can also be represented by . In this paper, we use matrix M to store the relative position weight of an utterance in the hypergraph. The structure of matrix M is similar to that of the incidence matrix A. Each row in M corresponds to a hyperedge, and the non-zero items in each row represent the utterance node in this hyperedge. The size of the non-zero items is related to the positions between nodes in the hyperedge. In the following, we use to represent the hypergraph.
Vertices. Each utterance in a conversation is represented as a node . Each node is initialized with the utterance embeddings . We update the embedding representations of vertices via hypergraph convolution.
Hyperedge. Since each hyperedge is generated based on a specific current utterance, we need to calculate the influences of other utterances on the current utterance, and these influences will be weakened according to the relative position between the utterances. We set the position weight of the current utterance to 1, and the position weight of the remaining utterances gradually decreases with the relative distance. See Algorithm 1 for the specific process of hypergraph and hyperedge construction.
| Algorithm 1 Constructing a Hypergraph |
- Input:
the dialogue , speaker identity , and context window w. - Output:
. - 1:
- 2:
- 3:
for alldo - 4:
, N zero in total - 5:
, count ←, , 0 - 6:
← 1 - 7:
for; ; do - 8:
if then - 9:
- 10:
count++ - 11:
else if and then - 12:
- 13:
end if - 14:
end for - 15:
end for - 16:
- 17:
- 18:
return
|
We designed two kinds of hypergraphs—one is speaker-specific hypergraph (SSHG), and the other is a non-speaker-specific hypergraph (NSHG). The hyperedges in the SSHG are speaker-specific hyperedges (SSHEs). We selected some utterances in the context window to add to the SSHEs, and the speaker of these utterances was the same as the speaker of the current utterance. The hyperedges in the NSHG were non-speaker-specific hyperedges (NSHEs). We take the past utterance of the speaker of the current utterance as a selective constraint and selected some utterances in the context window to add to the NSHEs. The speakers of these utterances were different from the speaker of the current utterance.
3.2. Problem Definition
Given the conversation record and the speaker information for each utterance, the ERC task is that of identifying the emotional label of each utterance. More specifically, an input sequence containing N utterances is given, and it is annotated with a sequence of emotion labels . Each utterance is spoken by . The task of ERC aims the prediction of the emotion label for each utterance .
3.3. Model
An overview of our proposed model is shown in
Figure 2, which consists of a feature extraction module, a hypergraph convolution layer module, and an emotion classification module. Hyperedges are generated according to the third, fourth, and fifth utterances.
3.3.1. Utterance Feature Extraction
Following COSMIC [
13], we employed RoBERTa-Large [
43] as a feature extractor. The pre-trained model was first fine-tuned on each ERC dataset, and its parameters were then frozen while training our model. More specifically, a special token [CLS] was appended at the beginning of the utterance to create the input sequence for the model. Then, we used the [CLS]’s pooled embedding at the last layer as the feature representation
of
.
3.3.2. Hypergraph Convolution (HGC) Layer
We utilized the two hypergraphs to perform separate hypergraph convolutions, and then obtained different utterance representations. The process of performing hypergraph convolution for each graph can be divided into the following three steps.
Node-to-Edge Aggregation. The first step was the aggregation from the nodes to the hyperedges. Here, we used the position weight
to calculate the weight
of the weighted average aggregation. Since some nodes on a hyperedge are informative, but others may not be, we should pay varying attention to the information from these nodes while aggregating them together. We utilized an attention mechanism to model the significance of different nodes. Here, we used a function
to calculate the attention weights
. Function
was derived from the scaled dot-product attention formula [
23]. Then, the obtained weight
, attention weight
, and node information
were aggregated to obtain the hyperedge feature
. The specific process is shown in Equations (
2)–(
5).
where
is the j-th hyperedge resulting from the
j-th utterance.
is stored in the association matrix M, which represents the size of the position weight of the
i-th node in the
j-th hyperedge.
represents the features of the utterance node.
represents a trainable node-level context vector for the
l-th HGC layer.
and
is a trainable parameter matrix. D is the dimension size.
Edge-to-Edge Aggregation. The second step was to transfer information between hyperedges. In order to make the current utterance have a better interaction with the context, we used the hyperedge generated by each utterance to model the conversation context. We used BiLSTM to complete the information transfer. The specific process is shown in Equation (
6).
where
is the
j-th hidden state of the LSTM, and
represents the hyperedge feature obtained after the information is passed by the hyperedge.
Edge-to-Node Aggregation. To update the feature for a node, we needed to aggregate the information from all of its connected hyperedges. We also used
to calculate the similarity between the node and hyperedge features. The specific process is shown in Equations (
7) and (8).
where
is the set of hyperedges containing the i-th node.
,
, and
denote trainable parameters, and
is the same as in Equation (
5).
3.4. Classifier
We concatenated the hidden states of the two hypergraphs in all HGC layers and passed them through a feedforward neural network to obtain the predicted emotion. The specific process is shown in Equations (
9)–(
11).
where
represents the result of the hypergraph convolution performed on the hypergraph,
can be SSHG and NSHG, and
is the number of layers for the hypergraph convolution of the corresponding hypergraph.
For the training of ERMC-MHGNN, we employed the standard cross-entropy loss as an objective function. The specific function is shown in Equation (
12).
where
C is the number of training conversations,
is the number of utterances in the
i-th conversation,
is the ground-truth label, and
is the collection of trainable parameters of ERMC-MHGNN.
6. Conclusions
In this paper, two different hypergraphs were constructed for two speaker dependencies for the first time, and a multi-hypergraph neural network—namely, ERMC-MHGNN—was designed for multi-party conversation emotion recognition to better handle speaker dependencies. The experimental results show that ERMC-MHGNN has good performance. Furthermore, through comprehensive evaluation and ablation studies, we can confirm the advantages of ERMC-MHGNN and the impacts of its modules on performance. Several conclusions can be drawn from the experimental results. First, our approach to non-speaker-specific modeling of utterances from other speakers is feasible. Second, combining average aggregation with attention aggregation can allow better hyperedge features to be obtained. Finally, although the model achieved certain results on the emotional shift issue, the ability of the model to recognize similar emotions still needs to be enhanced.
In the future, we plan to build a hierarchical hypergraph neural network based on the existing hypergraph network to deal with interactions within a single modality and interactions among multiple modalities. We believe that hierarchical hypergraph neural networks can not only handle high-order relationships between utterances, but can also alleviate the deficiencies of single-mode features.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}