1. Introduction
Water is the foundation of human existence and the driving force for social stability and a nation’s prosperity. However, water resource management has been ignored and forgotten for a long time. It was not until the mid-19th century that, due to the rapid development of industry, water pollution became increasingly serious and water resource management became increasingly prominent. [
1]. Since then, the declining water quality of rivers, lakes and groundwater has become a global problem. Although an increasing number of countries has begun to attach importance to water resources and implement a series of protection measures for the sustainable development of water resources, the water resources environment is still deteriorating, with increasing pollution and waste caused by economic development, the acceleration of urbanization and population growth.
The river pollution situation is serious. The water quality level has fallen to IV or worse in 31.4% of the more than 208,000 km of managed river sections in China and below class V in 14.9% of managed sections, indicating that water resources have completely lost their potential for daily use [
2]. Of the ten major river basins in China, only some in the southwest and northwest have moderate water quality (categories I to III), and the major river systems in the north, such as the Yellow River, Liao River and Huai River, are rated IV or V. The declining self-purification ability of rivers and deteriorating industrial wastewater management have further worsened the water quality of small tributaries flowing into the major rivers of our country.
Lakes are also heavily polluted. The water quality of nearly half of the 62 key lakes in the country is of grades IV and V or inferior. The three major lakes in China, Taihu Lake, Chaohu Lake and Dianchi Lake, are polluted to varying degrees, in states of mild, moderate and severe pollution, respectively, with total phosphorus and chemical oxygen demand representing the main pollutants.
The groundwater quality situation is also worrying. In China’s major cities, 27 percent of centralized drinking water sources do not meet official standards. Among the 5118 groundwater monitoring points in various provinces and cities across the country, the proportion of poor and extremely poor water quality is more than half, threatening people’s daily water use [
3,
4].
Water environmental problems have become a major factor hindering the sustainable development of China’s economy and society, and the effective treatment of water pollution and the rational management of water resources are urgent problems to be solved. The accurate prediction of water quality indicators and the reliable evaluation of water quality grades are the basis for understanding the current water quality status and taking corresponding protection measures, so water quality prediction and evaluation have great practical significance.
In this paper, we take the water quality of Lanzhou Xincheng Bridge section in Yellow River Basin and Longdong section in Yangtze River Basin as the research object, establish a water quality evaluation model and propose a new water quality prediction model.
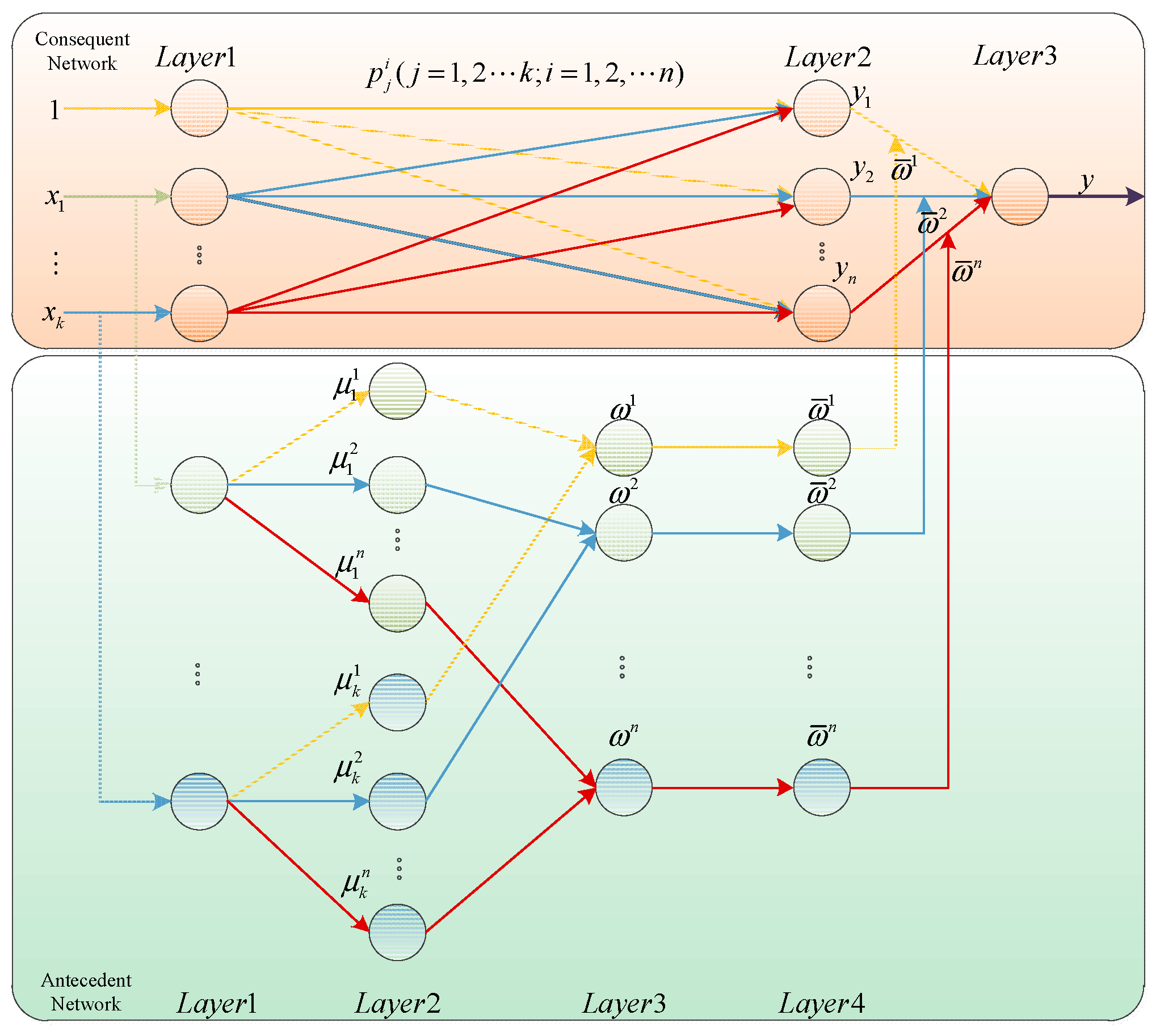
A T-S fuzzy neural network was used to establish the evaluation model combined with the relevant water quality information of the two basins. In the process of model training, an innovative method of interpolating water quality index data with equal intervals and uniform distribution was adopted to construct research samples, and the method of stratified sampling was used to construct training samples. The trained model was applied to water quality evaluation of Lanzhou Xincheng Bridge section in the Yellow River Basin and Longdong section in the Yangtze River Basin. A total of 52 groups were randomly selected from the real water quality index data from 2004 to 2015, and the results of water quality status were output and compared with the real water quality grade to prove the effectiveness and generalizability of the evaluation model.
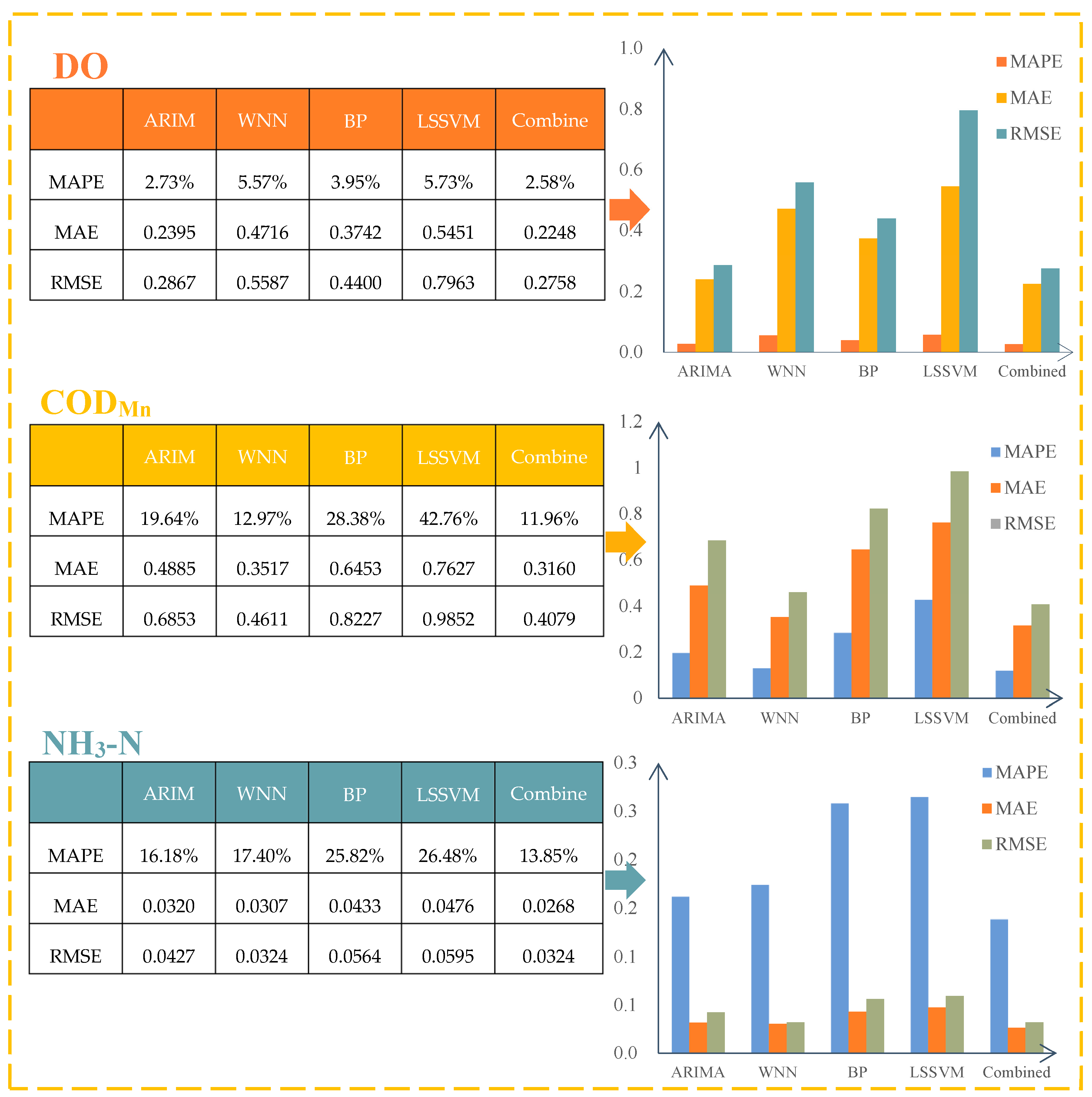
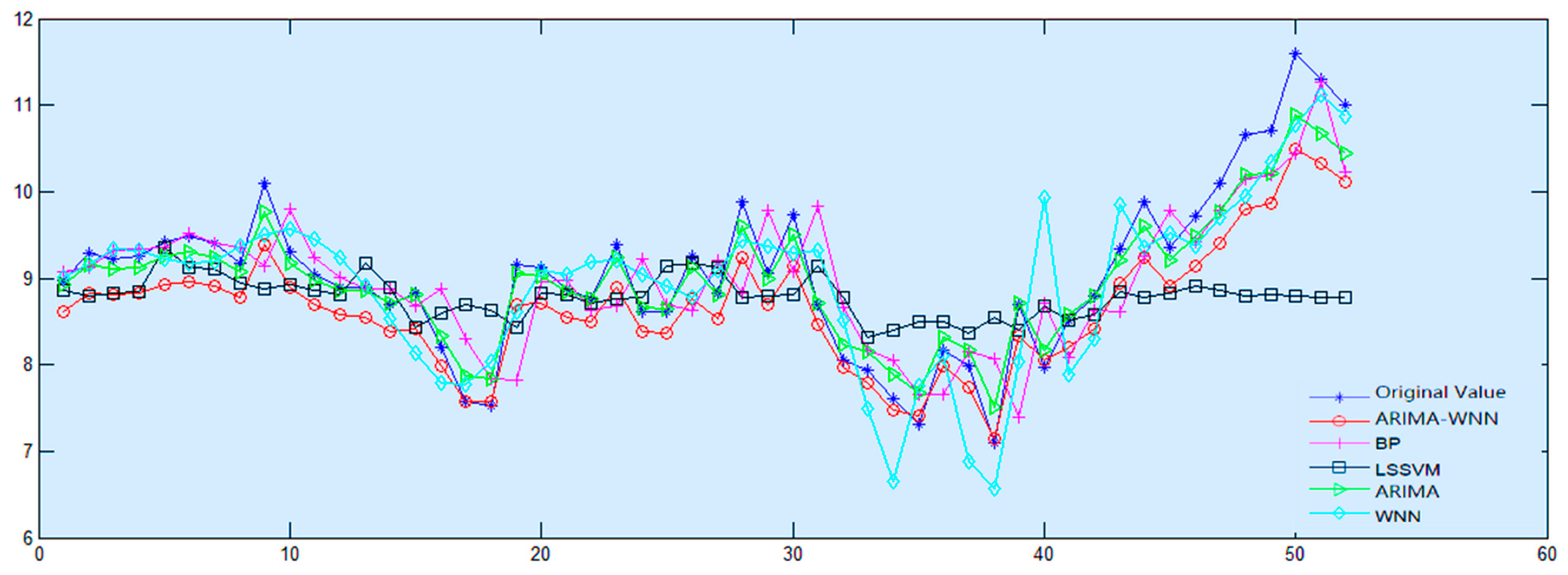
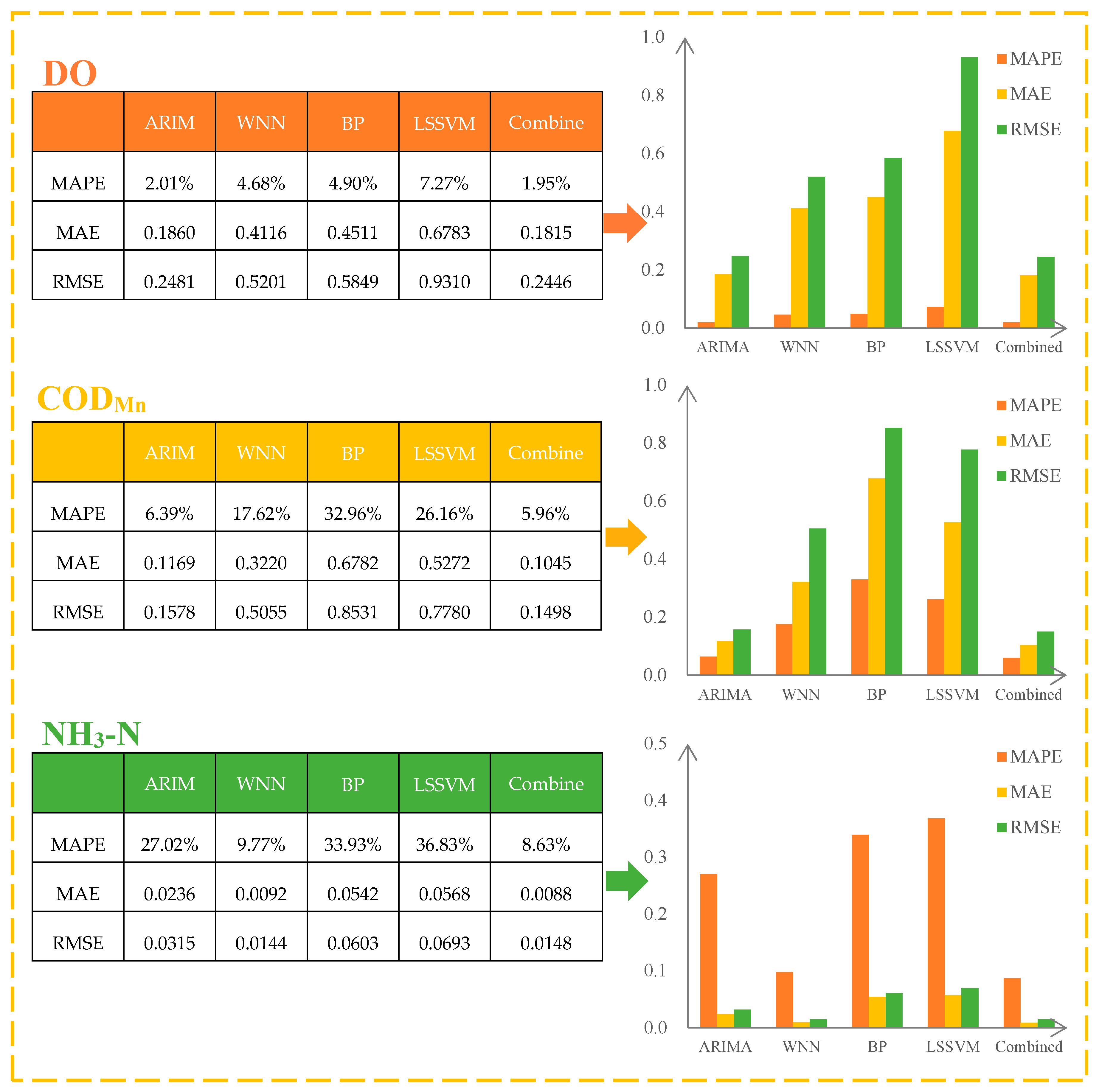
Furthermore, a new model is proposed for water quality prediction, which combines the autoregressive integrated moving average (ARIMA) model and the wavelet neural network (WNN) mode with the bat algorithm to determine the optimal weight of each individual model. The combined model was used to predict the water quality indices of Lanzhou Xincheng Bridge section in the Yellow River Basin and Longdong section in the Yangtze River Basin. First, 624 weekly monitoring data points of each indicator from 2004 to 2015 were used as the training set, and 52 data points from 2016 were used as the validation set. ARIMA and WNN were used for prediction. The empirical mode decomposition (EMD) algorithm was used to denoise the data before WNN prediction [
5]. Secondly, the bat algorithm was used to determine the optimal weight; the final prediction result was the weighted sum of the prediction results of ARIMA and WNN. Then, the prediction results of the combined model were compared and analyzed relative to the prediction results of three individual models (backpropagation (BP), neural network and least squares support vector machine (LSSVM)) to prove the ability of the proposed combined model for water quality prediction [
6,
7]. Finally, the prediction results of each index in 2016 were substituted into the previously established water quality evaluation model, and the output results had a high coincidence rate with the real water quality grade, which further verified the effectiveness of the evaluation model.
5. Conclusions
Water quality evaluation and prediction are not two completely independent procedures. On the contrary, they form a mutually dependent system and complement each other. Accordingly, in this study, we established a water quality evaluation–prediction system, established a water quality evaluation model using a T-S fuzzy neural network and constructed research samples by interpolating water quality index data evenly distributed on the basis of each index grading standard stipulated in the Environmental Quality Standards for Surface Water. A stratified sampling method is used to construct training samples. The trained T-S fuzzy neural network was applied to the water quality evaluation of the Lanzhou Xincheng Bridge section in the Yellow River Basin and the Longdong section in the Sichuan Panzhihua section in the Yangtze River Basin, with total positive water quality grade evaluation rates of 90.38% and 88.46%, respectively, indicating the positive water quality evaluation effect and generalizability of the model.
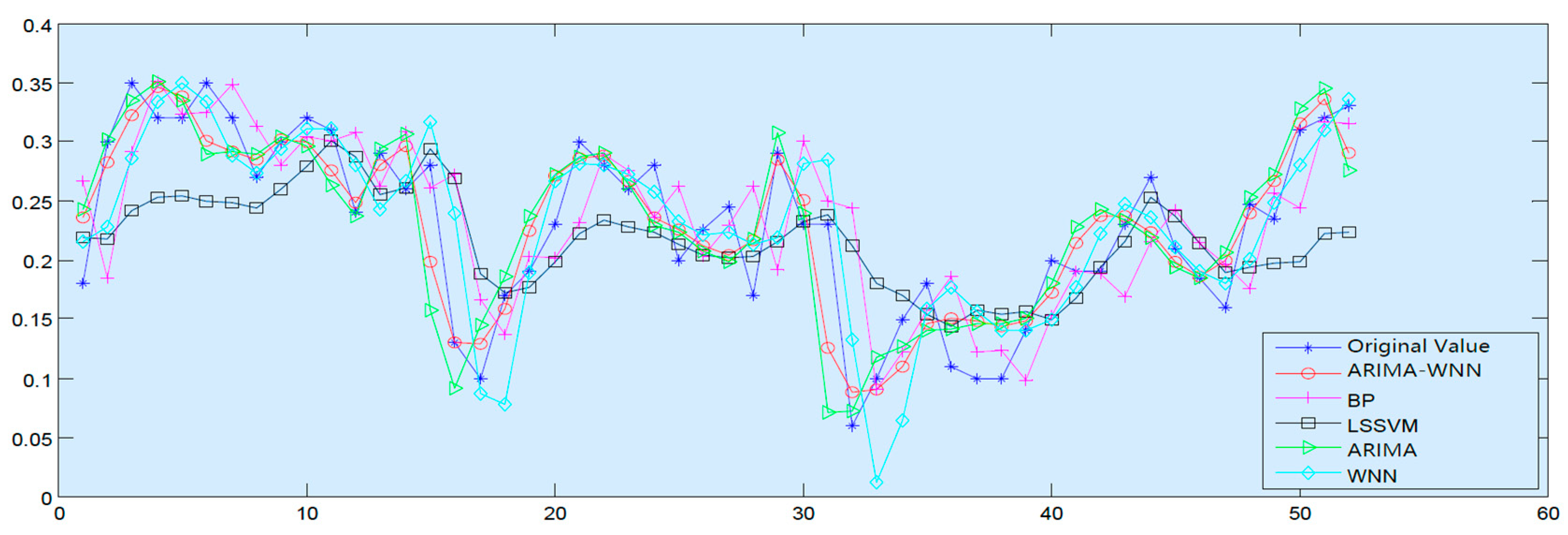
For the prediction of water quality, in this paper, we proposed a new combined model, ARIMA-WNN, which establishes the combined prediction model for each water quality index of the two basins and compares the prediction results with the combined model. The results show that compared with the single model, the combined model (ARIMA-WNN) has a higher prediction accuracy, and the prediction ability can be improved by up to 68.06%. Compared with commonly used water quality prediction models (BP neural network and LSSVM), we found that the MAPE, MAE and RMSE of the combined model are significantly lower, which demonstrates the excellent water quality prediction ability of the combined model.
Determining reasonable weight coefficients for each single model in the combined model is the basis for obtaining accurate prediction results, and in this study, we used the bat algorithm to achieve this process. Swarm intelligence optimization algorithms have developed rapidly in recent years, and a variety of new methods have emerged in succession [
41]. Determining the optimal weight is a subject that can be studied in depth, and additional methods should be proposed and tested in subsequent work [
42].


 ,
, 























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}