
Dichotomy Graph Sketch: Summarizing Graph Streams with High Accuracy Based on Deep Learning †
 , ,
, ,
Abstract
:1. Introduction
- As a novel method for summarizing graph streams, we propose Dichotomy Graph Sketch (DGS). It is capable of distinguishing heavy edges from light edges during edge updating.
- We adopt deep learning techniques in our graph sketch design. In particular, we design a novel neural network architecture to detect heavy edges during the edge updating process, which allows us to store heavy edges and light edges in two separate matrices.
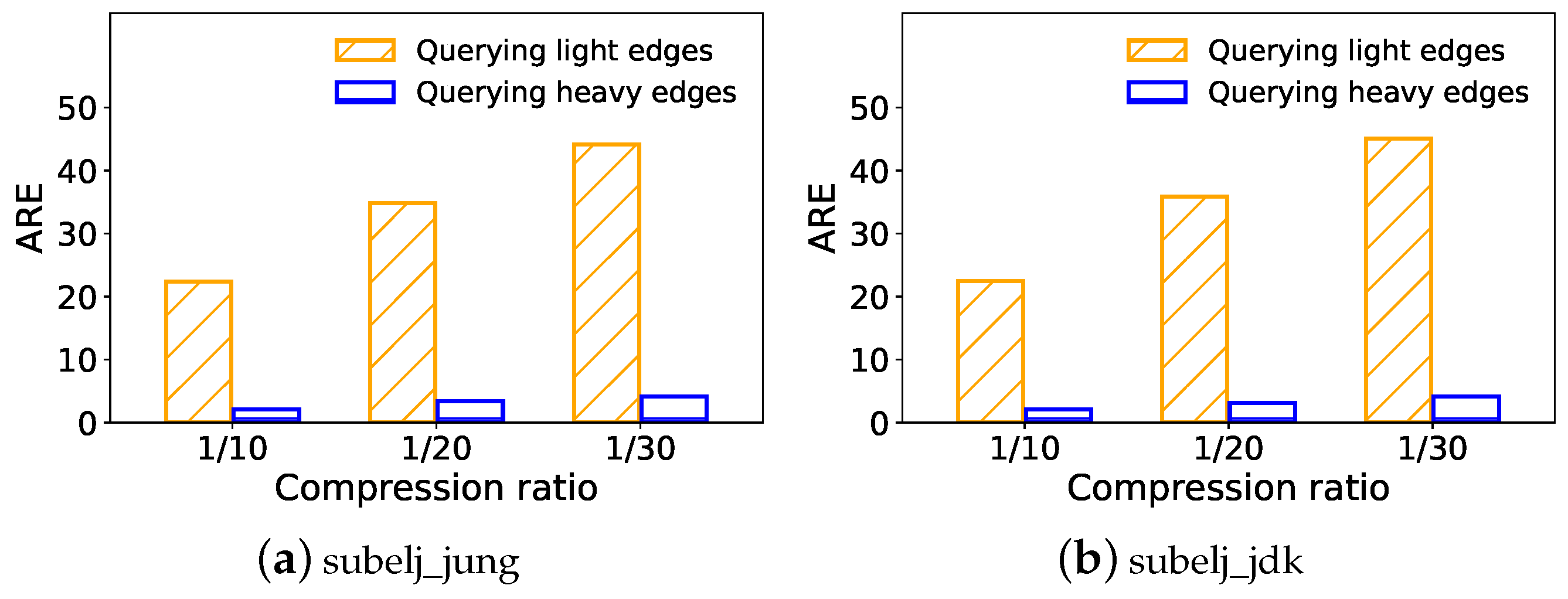
- A comprehensive evaluation of the performance of DGS is conducted using three real-world graph streams. According to the experimental results, DGS outperforms state-of-the-art graph sketches in a variety of graph query tasks.
2. Related Work
2.1. Data Stream Sketches
2.2. Graph Stream Sketch
3. Preliminaries
- Edge update: Each graph sketch calculates the hash values for each edge in graph stream S. Afterwards, it locates the corresponding position in the adjacency matrix and adds the value there by w.
- Edge query: The purpose of edge query is to return the estimated weight of an given edge . The first step in answering the query is to determine the weight of e in each graph sketch. To be more specific, we locate the corresponding position on each graph sketch , and return its value as an estimated weight. As a result, we can obtain a set of weights . Based on the count-min sketch principle [5], we return for the edge query.
- Node query: The purpose of node query is to return the aggregated edge weight for a given node n. The answer is obtained by finding the row corresponding to node n (i.e., the th row) in the adjacency matrix M, and then summing the values in that row. In the same manner, we obtain a set of sums , and return the minimum value for the node query.
- Top-k node query: The purpose of top-k node query is to return the list of top-k nodes whose aggregated weights are the highest in graph stream S. In order to respond to this query, we maintain a min-heap with size k to hold the top-k nodes. Following the update of each edge , we conduct a node query for node s and obtain its aggregated weight . In the next step, we push the tuple into the min-heap. The lowest-weight tuple will be popped out if the min-heap is full. We return the nodes in the min-heap as the answer to top-k node queries after all edge updates have been completed.
4. Dichotomy Graph Sketch Mechanism
4.1. Heavy Sketch and Light Sketch
4.2. Sample Generator
4.3. Edge Classifier
4.3.1. Node Embeddings Using a Graph Auto-Encoder
4.3.2. Architecture of the Edge Classifier
4.4. Implementation of Graph Query Tasks
4.4.1. Dealing with Edge Query and Node Query
4.4.2. Dealing with Top-k Node Query
4.5. Time and Space Complexity Analysis
5. Performance Evaluation
5.1. Datasets
- wiki_talk_cy: The first dataset consists of the Welsh Wikipedia’s communication network (http://konect.cc/networks/wiki_talk_cy/). Users are represented by nodes, and an edge from user A to user B indicates that user A posted a message on the talk page of user B at a specific time. It contains 2233 users (nodes) and 10,740 messages (edges).
- subelj_jung: The second dataset is the software class dependency network of the JUNG 2.0.1 and javax 1.6.0.7 libraries, namespaces edu.uci.ics.jung and java/javax (http://konect.cc/networks/subelj_jung-j/). A node represents a class, and an edge between two nodes indicates that these classes are dependent on one another. It contains 6210 classes (nodes) and 138,706 dependencies (edges).
- facebook-wosn-wall: The third dataset is the directed network of a small subset of posts to other user’s wall on Facebook (http://konect.cc/networks/facebook-wosn-wall/). A node in the network represents a Facebook user, and a directed edge represents a post, connecting the user writing a post with the user whose wall the post appears on. It contains 46,952 users (nodes) and 876,993 posts (edges).
- slashdot: The fourth dataset is the reply network of technology website Slashdot (http://konect.cc/networks/slashdot-threads/). Nodes are users and edges are replies. The edges are directed and start from the responding user. Edges are annotated with the timestamp of the reply. It contains 51,083 users (nodes) and 140,778 replies (edges).
5.2. Performance Metrics
5.2.1. Average Relative Error (ARE)
5.2.2. Intersection Accuracy (IA)
5.2.3. Normalized Discounted Cumulative Gain (NDCG)
5.3. Numerical Results
5.3.1. Edge Query
5.3.2. Top-k Heavy Node Query
5.3.3. Memory Usage Comparison on Different Datasets
5.3.4. Hyperparameter Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, N.; Chen, Q.; Mitra, P. Graph Stream Summarization: From Big Bang to Big Crunch. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD’16), San Francisco, CA, USA, 26 June–1 July 2016; pp. 1481–1496. [Google Scholar]
- Gou, X.; Zou, L.; Zhao, C.; Yang, T. Fast and Accurate Graph Stream Summarization. In Proceedings of the 35th IEEE International Conference on Data Engineering (ICDE’19), Macao, China, 8–11 April 2019; pp. 1118–1129. [Google Scholar]
- Merchant, A.; Mathioudakis, M.; Wang, Y. Graph Summarization via Node Grouping: A Spectral Algorithm. In Proceedings of the WSDM’23: Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, Singapore, 27 February–3 March 2023; pp. 742–750. [Google Scholar]
- Hajiabadi, M.; Singh, J.; Srinivasan, V.; Thomo, A. Graph Summarization with Controlled Utility Loss. In Proceedings of the KDD’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual, Singapore, 14–18 August 2021; pp. 536–546. [Google Scholar]
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: The count-min sketch and its applications. J. Algorithms 2005, 55, 58–75. [Google Scholar] [CrossRef]
- Gou, X.; Zou, L.; Zhao, C.; Yang, T. Graph Stream Sketch: Summarizing Graph Streams with High Speed and Accuracy. IEEE Trans. Knowl. Data Eng. 2022, 35, 5901–5914. [Google Scholar] [CrossRef]
- Li, D.; Li, W.; Chen, Y.; Zhong, X.; Lin, M.; Lu, S. Learning-Based Dichotomy Graph Sketch for Summarizing Graph Streams with High Accuracy. In Proceedings of the KSEM’23: The 16th International Conference on Knowledge Science, Engineering and Management, Guangzhou, China, 16–18 August 2023; pp. 47–59. [Google Scholar]
- Charikar, M.; Chen, K.C.; Farach-Colton, M. Finding Frequent Items in Data Streams. In Proceedings of the 29th International Colloquium on Automata, Languages and Programming, Málaga, Spain, 8–13 July 2002; pp. 693–703. [Google Scholar]
- Estan, C.; Varghese, G. New directions in traffic measurement and accounting: Focusing on the elephants, ignoring the mice. ACM Trans. Comput. Syst. 2003, 21, 270–313. [Google Scholar] [CrossRef]
- Giroire, F.; Chandrashekar, J.; Taft, N.; Schooler, E.M.; Papagiannaki, D. Exploiting Temporal Persistence to Detect Covert Botnet Channels. In Proceedings of the Recent Advances in Intrusion Detection, 12th International Symposium, RAID 2009, Saint-Malo, France, 23–25 September 2009; Volume 5758, pp. 326–345. [Google Scholar]
- Li, J.; Li, Z.; Xu, Y.; Jiang, S.; Yang, T.; Cui, B.; Dai, Y.; Zhang, G. WavingSketch: An Unbiased and Generic Sketch for Finding Top-k Items in Data Streams. In Proceedings of the KDD’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 6–10 July 2020; pp. 1574–1584. [Google Scholar]
- Zhang, Y.; Li, J.; Lei, Y.; Yang, T.; Li, Z.; Zhang, G.; Cui, B. On-Off Sketch: A Fast and Accurate Sketch on Persistence. Proc. VLDB Endow. 2020, 14, 128–140. [Google Scholar] [CrossRef]
- Zhong, Z.; Yan, S.; Li, Z.; Tan, D.; Yang, T.; Cui, B. BurstSketch: Finding Bursts in Data Streams. In Proceedings of the SIGMOD’21: International Conference on Management of Data, Virtual, 20–25 June 2021; pp. 2375–2383. [Google Scholar]
- Liu, Z.; Kong, C.; Yang, K.; Yang, T.; Miao, R. HyperCalm Sketch: One-Pass Mining Periodic Batches in Data Streams. In Proceedings of the ICDE’23: 39th IEEE International Conference on Data Engineering, Anaheim, CA, USA, 3–7 April 2023. [Google Scholar]
- Zhao, Y.; Han, W.; Zhong, Z.; Zhang, Y.; Yang, T.; Cui, B. Double-Anonymous Sketch: Achieving Fairness for Finding Global Top-K Frequent Items. In Proceedings of the SIGMOD’23: International Conference on Management of Data, Seattle, WA, USA, 18–23 June 2023. [Google Scholar]
- Ben-Basat, R.; Einziger, G.; Friedman, R.; Kassner, Y. Randomized admission policy for efficient top-k and frequency estimation. In Proceedings of the INFOCOM’17: IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Fan, D.; Rafiei, D. New Estimation Algorithms for Streaming Data: Count-Min Can Do More. 2014. Available online: https://www.researchgate.net/publication/228531010_New_estimation_algorithms_for_streaming_data_Count-min_can_do_more (accessed on 10 December 2023).
- Wang, F.; Chen, Q.; Li, Y.; Yang, T.; Tu, Y.; Yu, L.; Cui, B. JoinSketch: A Sketch Algorithm for Accurate and Unbiased Inner-Product Estimation. In Proceedings of the SIGMOD’23: International Conference on Management of Data, Washington, DC, USA, 18–23 June 2023. [Google Scholar]
- Li, X.; Fan, Z.; Li, H.; Zhong, Z.; Guo, J.; Long, S. SteadySketch: Finding Steady Flows in Data Streams. In Proceedings of the IWQoS’23: IEEE/ACM International Symposium on Quality of Service, Anaheim, CA, USA, 3–7 April 2023. [Google Scholar]
- Fan, Z.; Hu, Z.; Wu, Y.; Guo, J.; Liu, W.; Yang, T.; Wang, H.; Xu, Y.; Uhlig, S.; Tu, Y. PISketch: Finding persistent and infrequent flows. In Proceedings of the FFSPIN ’22: The ACM SIGCOMM Workshop on Formal Foundations and Security of Programmable Network Infrastructures, Amsterdam, The Netherlands, 11–25 May 2022; pp. 8–14. [Google Scholar]
- Fan, Z.; Hu, Z.; Wu, Y.; Guo, J.; Wang, S.; Liu, W.; Yang, T.; Tu, Y.; Uhlig, S. PISketch: Finding Persistent and Infrequent Flows. IEEE/ACM Trans. Netw. 2023. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, Y.; Yi, P.; Yang, T.; Cui, B.; Uhlig, S. The Stair Sketch: Bringing more Clarity to Memorize Recent Events. In Proceedings of the ICDE’22: 38th IEEE International Conference on Data Engineering, Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 164–177. [Google Scholar]
- Gou, X.; Zhang, Y.; Hu, Z.; He, L.; Wang, K.; Liu, X.; Yang, T.; Wang, Y.; Cui, B. A Sketch Framework for Approximate Data Stream Processing in Sliding Windows. IEEE Trans. Knowl. Data Eng. 2022, 35, 4411–4424. [Google Scholar] [CrossRef]
- Fan, Z.; Zhang, Y.; Dong, S.; Zhou, Y.; Liu, F.; Yang, T.; Uhlig, S.; Cui, B. HoppingSketch: More Accurate Temporal Membership Query and Frequency Query. IEEE Trans. Knowl. Data Eng. 2022, 35, 9067–9072. [Google Scholar] [CrossRef]
- Peng, Y.; Guo, J.; Li, F.; Qian, W.; Zhou, A. Persistent Bloom Filter: Membership Testing for the Entire History. In Proceedings of the SIGMOD’18: Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 1037–1052. [Google Scholar]
- Liu, L.; Shen, Y.; Yan, Y.; Yang, T.; Shahzad, M.; Cui, B.; Xie, G. SF-Sketch: A Two-Stage Sketch for Data Streams. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2263–2276. [Google Scholar] [CrossRef]
- Miao, R.; Dong, F.; Zhao, Y.; Zhao, Y.; Wu, Y.; Yang, K.; Yang, T.; Cui, B. SketchConf: A Framework for Automatic Sketch Configuration. In Proceedings of the ICDE’23: 39th IEEE International Conference on Data Engineering, Anaheim, CA, USA, 3–7 April 2023. [Google Scholar]
- Li, H.; Chen, Q.; Zhang, Y.; Yang, T.; Cui, B. Stingy Sketch: A Sketch Framework for Accurate and Fast Frequency Estimation. Proc. VLDB Endow. 2022, 15, 1426–1438. [Google Scholar] [CrossRef]
- Yang, T.; Xu, J.; Liu, X.; Liu, P.; Wang, L.; Bi, J.; Li, X. A generic technique for sketches to adapt to different counting ranges. In Proceedings of the INFOCOM’19: IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2017–2025. [Google Scholar]
- Liu, X.; Xu, Y.; Liu, P.; Yang, T.; Xu, J.; Wang, L.; Xie, G.; Li, X.; Uhlig, S. SEAD counter: Self-adaptive counters with different counting ranges. IEEE/ACM Trans. Netw. 2021, 30, 90–106. [Google Scholar] [CrossRef]
- Liu, Z.; Manousis, A.; Vorsanger, G.; Sekar, V.; Braverman, V. One sketch to rule them all: Rethinking network flow monitoring with univmon. In Proceedings of the SIGCOMM’16: The Annual Conference of the ACM Special Interest Group on Data Communication, Florianopolis, Brazil, 22–26 August 2016; pp. 101–114. [Google Scholar]
- Huang, Q.; Jin, X.; Lee, P.P.; Li, R.; Tang, L.; Chen, Y.C.; Zhang, G. Sketchvisor: Robust network measurement for software packet processing. In Proceedings of the SIGCOMM’17: The Annual Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 113–126. [Google Scholar]
- Tang, L.; Huang, Q.; Lee, P.P.C. MV-Sketch: A Fast and Compact Invertible Sketch for Heavy Flow Detection in Network Data Streams. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM’19), Paris, France, 29 April–2 May 2019; pp. 2026–2034. [Google Scholar]
- Yang, T.; Jiang, J.; Liu, P.; Huang, Q.; Gong, J.; Zhou, Y.; Miao, R.; Li, X.; Uhlig, S. Elastic sketch: Adaptive and fast network-wide measurements. In Proceedings of the SIGCOMM’18: The Auunal Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 561–575. [Google Scholar]
- Yang, T.; Jiang, J.; Liu, P.; Huang, Q.; Gong, J.; Zhou, Y.; Miao, R.; Li, X.; Uhlig, S. Adaptive measurements using one elastic sketch. IEEE/ACM Trans. Netw. 2019, 27, 2236–2251. [Google Scholar] [CrossRef]
- Liu, Z.; Ben-Basat, R.; Einziger, G.; Kassner, Y.; Braverman, V.; Friedman, R.; Sekar, V. Nitrosketch: Robust and general sketch-based monitoring in software switches. In Proceedings of the SIGCOMM’19: The annual ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 334–350. [Google Scholar]
- Zhao, P.; Aggarwal, C.C.; Wang, M. gSketch: On Query Estimation in Graph Streams. Proc. VLDB Endow. 2011, 5, 193–204. [Google Scholar] [CrossRef]
- Khan, A.; Aggarwal, C.C. Query-friendly compression of graph streams. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM’16), Davis, CA, USA, 18–21 August 2016; Kumar, R., Caverlee, J., Tong, H., Eds.; pp. 130–137. [Google Scholar]
- Li, D.; Li, W.; Chen, Y.; Lin, M.; Lu, S. Learning-Based Dynamic Graph Stream Sketch. In Proceedings of the PAKDD’21: Advances in Knowledge Discovery and Data Mining—25th Pacific-Asia Conference, Virtual, 11–14 May 2021; Volume 12712, pp. 383–394. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational Graph Auto-Encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Hamilton, W.L.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the NeurIPS’17: Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the ICLR’17: 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS’19), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Järvelin, K.; Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Neurons in Fully Connected Layer | Compression Ratio |
|---|---|
| 32 |
| Method | Total ARE | ARE of Light Edges | ARE of Heavy Edges |
|---|---|---|---|
| TCM | 10.388 | 10.436 | 0.274 |
| GSS | 10.038 | 10.083 | 0.622 |
| DGS | 7.875 | 7.909 | 0.202 |
| Method | Total ARE | ARE of Light Edges | ARE of Heavy Edges |
|---|---|---|---|
| TCM | 22.359 | 22.399 | 2.079 |
| GSS | 39.386 | 39.458 | 3.320 |
| DGS | 17.264 | 17.295 | 1.433 |
| Method | Total ARE | ARE of Light Edges | ARE of Heavy Edges |
|---|---|---|---|
| TCM | 2.261 | 2.262 | 0.015 |
| GSS | 5.256 | 5.258 | 0.340 |
| DGS | 2.056 | 2.057 | 0.212 |
| Method | Total ARE | ARE of Light Edges | ARE of Heavy Edges |
|---|---|---|---|
| TCM | 5.345 | 5.349 | 0.923 |
| GSS | 8.909 | 8.915 | 1.499 |
| DGS | 5.188 | 5.192 | 0.643 |
| Dataset | Wiki_talk_cy | Subelj_jung | Facebook-Wosn-Wall | Slashdot |
|---|---|---|---|---|
| Memory usage | 4.19 KB | 54.18 KB | 342.57 KB | 54.99 KB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Li, W.; Zhang, G.; Chen, Y.; Zhong, X.; Lin, M.; Lu, S. Dichotomy Graph Sketch: Summarizing Graph Streams with High Accuracy Based on Deep Learning. Appl. Sci. 2023, 13, 13306. https://doi.org/10.3390/app132413306
Li D, Li W, Zhang G, Chen Y, Zhong X, Lin M, Lu S. Dichotomy Graph Sketch: Summarizing Graph Streams with High Accuracy Based on Deep Learning. Applied Sciences. 2023; 13(24):13306. https://doi.org/10.3390/app132413306
Chicago/Turabian StyleLi, Ding, Wenzhong Li, Guoqiang Zhang, Yizhou Chen, Xu Zhong, Mingkai Lin, and Sanglu Lu. 2023. "Dichotomy Graph Sketch: Summarizing Graph Streams with High Accuracy Based on Deep Learning" Applied Sciences 13, no. 24: 13306. https://doi.org/10.3390/app132413306