1. Introduction
Accurate extraction of urban buildings is significant for urban planning, disaster assessment, building area estimation, 3D urban modeling, and so on [
1,
2,
3,
4]. Compared with urban buildings, rural buildings have their own characteristics: rural buildings have smaller scales, lower floors, scattered distributions in villages, and higher dispersion degrees; second, building materials, designs and construction times vary greatly, leading to larger internal differences [
5]. Therefore, extracting rural buildings is more challenging, and related research is relatively scarce. In addition, the high cloud cover in rural areas increases the extraction difficulty [
6]. Accurately identifying rural building roof types is of great importance for rural revitalization, environmental planning, energy assessment and disaster management [
7,
8,
9,
10]. Most previous rural building identification studies have focused on some local areas without considering the sparse distribution and differential features of buildings across regions, resulting in limited generalization capabilities [
11]. Therefore, it is imperative to develop rural building extraction methods applicable to large areas.
Traditional manual measurement methods conduct field surveys on buildings, which are inefficient and costly. The complex rural topography increases the workload, making it difficult to meet modern requirements [
12]. In recent years, the spatial resolution of high-resolution remote sensing images has significantly improved to submeter levels, providing richer texture and contour details [
13]. Therefore, an increasing number of scholars use high-resolution remote sensing images to extract building information [
14]. Traditional simple classifiers mostly rely on spectral and texture features to extract buildings from remote sensing images. Faced with increasingly complex high-resolution remote sensing images with abundant information and details, traditional extraction methods are no longer applicable [
15]. Object-oriented and machine learning methods are widely used to identify features, such as buildings, in complex images [
16]. Chen and colleagues used classifiers such as AdaBoost, Random Forest and support vector machine (SVM) to identify buildings from remote sensing images by segmenting images and removing shadows and vegetation. The newly introduced features of the edge regularity index (ERI) and shadow line index (SLI) significantly improved the accuracy [
17]. Related studies also adopt the morphological building index (MBI) to detect potential building areas and use an SVM for training and self-correction to remove falsely detected buildings [
18]. However, object-oriented methods rely on image segmentation results. Machine learning methods such as SVMs require large sample sets, and their simple structures cannot acquire in-depth information on building details [
19], leading to poor extraction effects on rural buildings with large internal differences.
Deep learning technologies based on big data and computer technology have been widely used in image recognition fields and are particularly suitable for analyzing high-resolution remote sensing images. Typical convolutional neural networks (CNNs), such as FCNs, UNet, and VGG16, can autonomously learn complex spectral and texture features to achieve automatic extraction of buildings, roads and other targets [
20]. Many scholars have improved classic semantic segmentation network frameworks to adapt to the feature extraction of different land cover types. Yu et al. [
21] integrated attention mechanism modules in the building extraction model AGs-UNet. By optimizing feature selection and focusing on small-scale building feature expression, the quality of building contour extraction in high-resolution remote sensing images has been significantly improved. Transfer learning is an effective method to overcome overfitting in neural network training with small data volumes. Smail et al. [
22] adopted the idea of transfer learning, combining the UNet basic architecture with ResNet101 and ResNet152 weights. By applying the feature parameters trained on large datasets to new classification tasks, the efficiency and accuracy of small data classification problems improved, reducing data requirements and improving the building extraction capabilities of basic models on remote sensing images. Gong et al. [
23] designed context collaboration networks using self-attention mechanisms to capture long-range dependency between buildings, providing complementary semantic and positional information. The above studies show that introducing attention and other feature learning modules can effectively reduce category confusion in semantic segmentation networks and enhance the recognition capability of complex building types.
Although improved deep learning methods have achieved good performance in urban building recognition, their applications in rural scenes are still limited [
24]. Difficulties exist in recognizing complex and diverse rural building types. Additionally, the high cloud cover in rural areas affects satellite image quality [
6]. To solve this problem, low-altitude remote sensing technologies have advantages, such as low cost and high-quality data acquisition, which can effectively improve the accuracy of rural building recognition. For example, Zhou et al. [
25] used UAV oblique photography to construct rural building datasets and generate digital surface models to realize building contour extraction and area measurement. Deng et al. [
26] designed a fully convolutional network based on attention mechanisms to extract multiscale features of rural buildings. However, the above studies mainly focus on local regions and have limited generalization ability.
In summary, to solve the problems of insufficient rural building samples and large regional differences, this study constructs a dataset of building images from typical rural areas across China to train deep learning models and improve their generalization ability. Considering the limitations of existing methods, which tend to confuse buildings with objects such as vegetation and roads that have similar spectral features when extracting complex architectural features of rural buildings [
27], this paper proposes an improved remote sensing rural building extraction network called AGSC-Net. Experiments show that the network can effectively extract semantic information from different building types and significantly improve the identification between buildings and backgrounds. The main sections of this paper are arranged as follows.
Section 2 introduces the study area and dataset construction and processing.
Section 3 presents the main experimental methods, including the improvements and implementation of the AGSC-Net model.
Section 4 shows the results of rural building recognition experiments and provides an analysis.
Section 5 discusses the effects of different feature combinations on the training results. Finally,
Section 6 summarizes the study.
3. Methodology
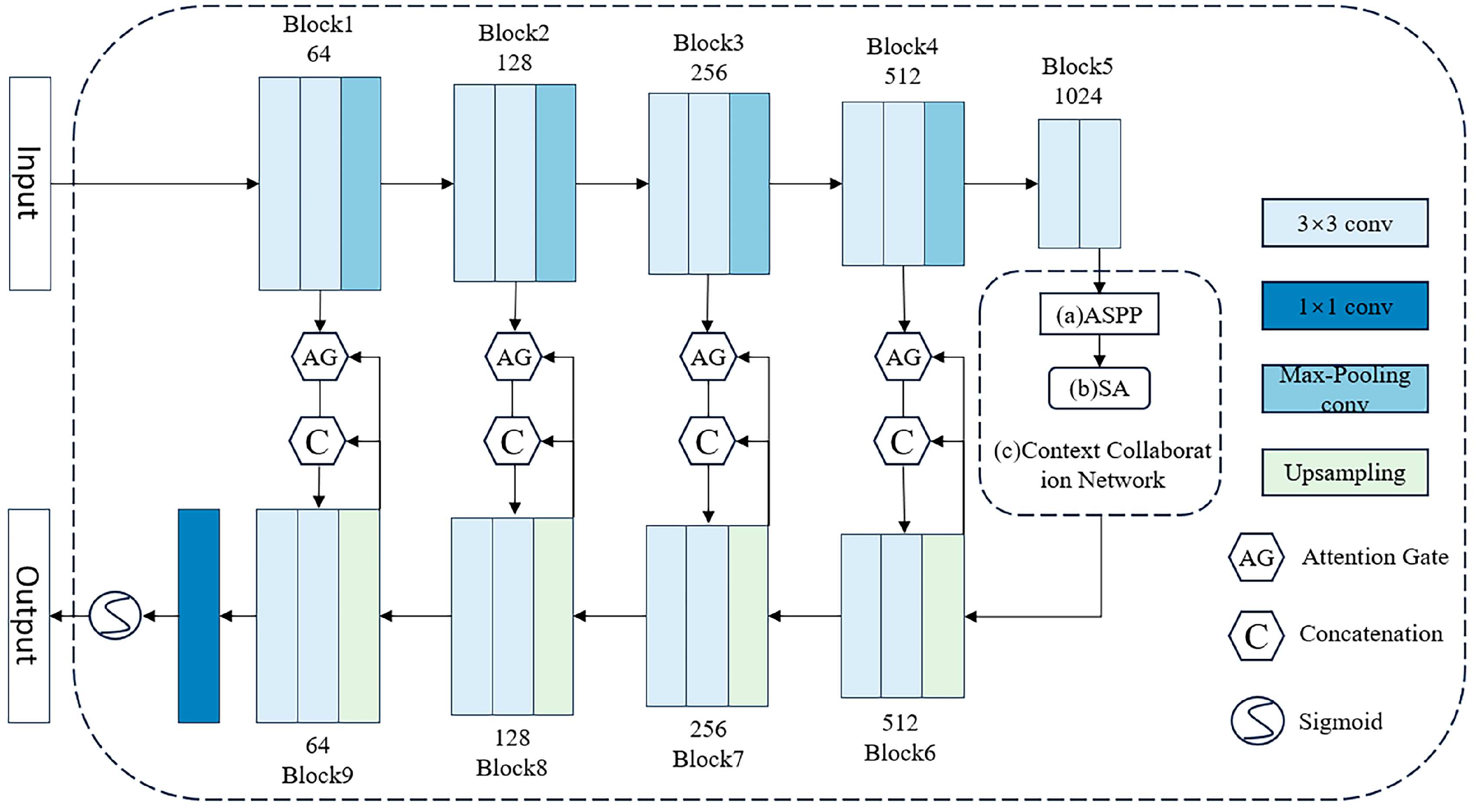
As presented in
Figure 3, as an attention control mechanism-based remote sensing image building extraction network, the main structure of AGSC-Net is as follows. An encoder–decoder structure based on the U-Net model is adopted to achieve end-to-end building extraction. The encoder gradually obtains semantically richer feature representations through convolution and pooling, while the decoder gradually restores spatial resolution to output prediction results consistent with the input image size [
35]. This structure ensures the end-to-end trainability of the entire model. The encoder consists of 4 convolutional blocks, each containing 2 convolutional layers, 2 normalization layers and 2 ReLU activation function layers. The max-pooling layers in the model can extract the maximum values from local regions of the feature maps and reorganize them into new feature maps. The converter consists of 4 AG and Context Collaboration Network (CC-Net) modules from the “skip connections”. Traditional FCNs take the global context of the entire input image but cannot distinguish features that are more important for building extraction [
36]. Attention modules are introduced between the encoder and decoder to explicitly model building features. The AG module in AGSC-Net can reweight each feature map to enhance the feature response related to buildings and suppress irrelevant feature responses, thereby improving the representation capability for buildings [
37].
The jump connections directly pass the features of each encoder layer to the decoder. This connection allows the decoder end to obtain image features at different levels, which helps restore detailed information and mitigate the vanishing gradient problem in deep networks, making the model easier to optimize [
38]. To obtain multiscale building features, AGSC-Net not only uses image pyramid pooling modules but also designs context collaboration networks to learn long-range dependencies between different building instances for more accurate localization. By constructing the feature converter with AG and CC-Net modules, the encoder features are converted before being passed to the decoder, which further enhances the representation capability of building features at the decoder end. Fully convolutional networks are utilized to achieve end-to-end training and prediction. Compared with the segmented processing flow in traditional methods, this end-to-end approach makes feature extraction more tailored to the final goal of building extraction and facilitates model training and deployment [
39]. In summary, AGSC-Net integrates the advantages of encoder–decoder, attention mechanisms, multiscale context extraction and other modules to form an efficient network structure for remote sensing image building extraction. This structure retains the stable and efficient basic framework of UNet and significantly improves the expression capability of rural building features through attention mechanisms and multiscale fusion. The specific parameters of AGSC-Net are shown in
Table 1.
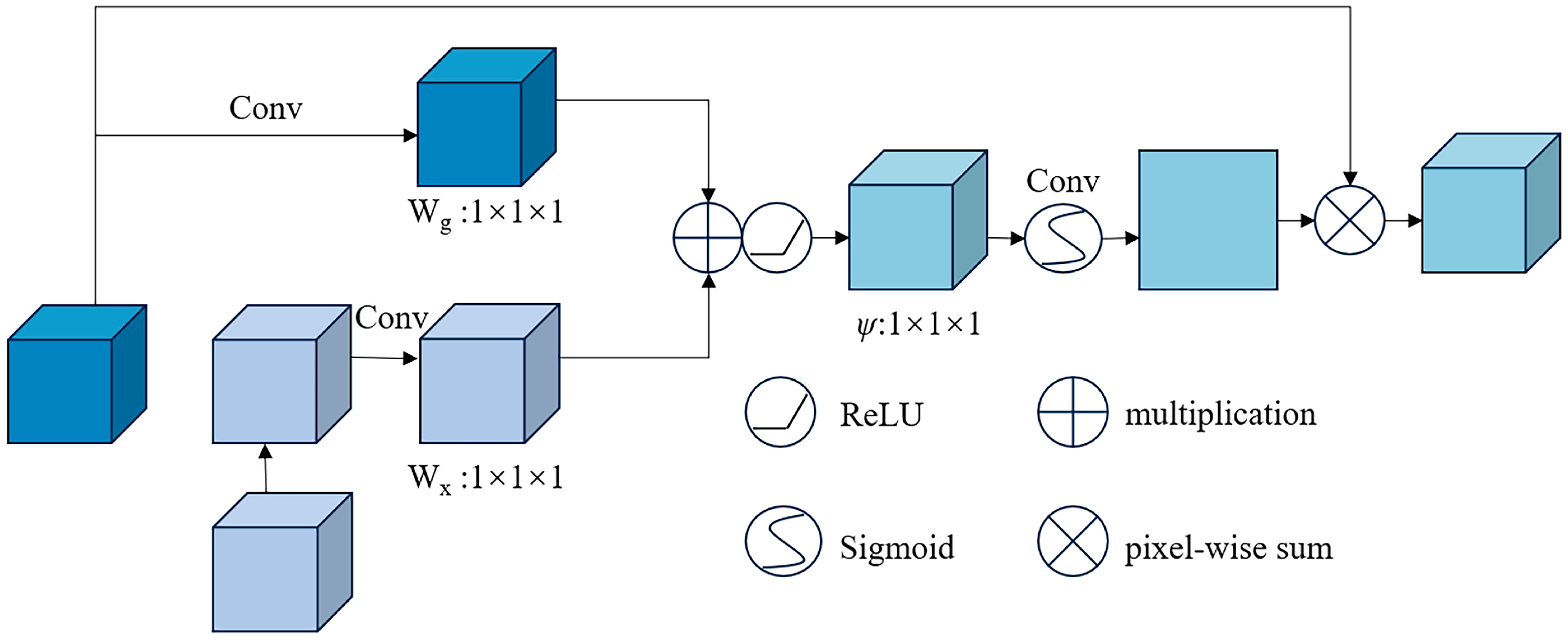
3.1. AG Module
For the building extraction task from high-resolution remote sensing images, the attention gate (AG), as a spatial attention mechanism, enables the model to selectively focus on different spatial regions of the image to accurately extract building contours in remote sensing images, which can significantly improve segmentation model performance [
40]. AG contains two branches for different feature processing. These two branches are fused at the pixel level, which can better integrate the multidimensional information of the input image. AG uses two different activation functions: ReLU for feature normalization and Sigmoid for generating attention coefficients. The combination of these two activation functions introduces nonlinearity to AG. Second, AG contains three sets of trainable parameters that control the gate coefficients W
g, attention coefficients W
x, and output adjustment parameters, making AG more adaptable to specific segmentation tasks. Additionally, its behavior can be controlled by adjusting the parameters. AG is an efficient, controllable and scalable spatial attention mechanism that is well-suited for fine-grained building segmentation tasks from high-resolution remote sensing images. It improves the model’s ability to identify key target areas by dual-branch feature fusion, adjustable parameters, and suppressing irrelevant regions. Integrating AG into standard convolutional networks can significantly improve the extraction accuracy of small and densely distributed buildings [
41]. The AG module structure is illustrated in
Figure 4.
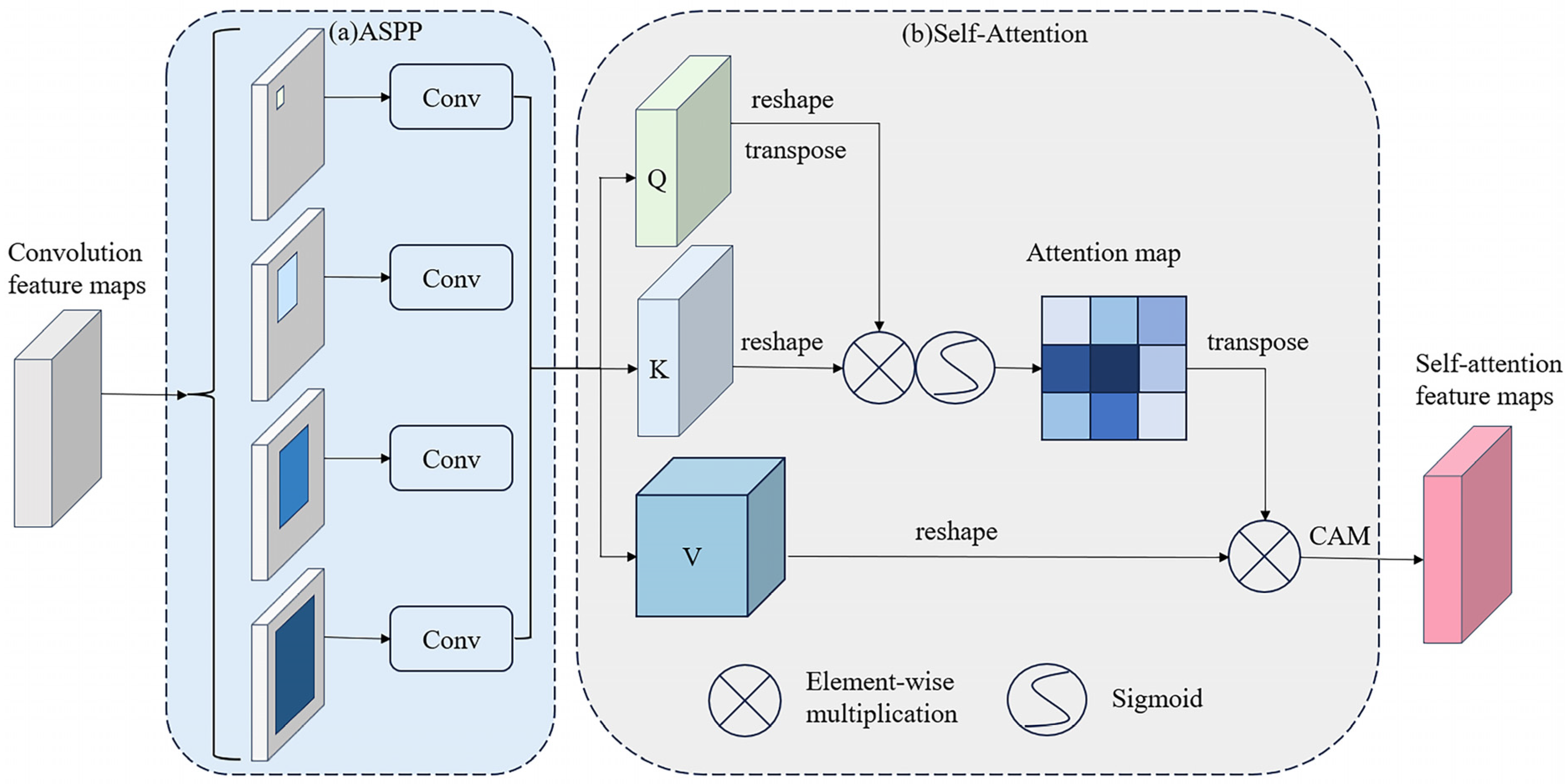
3.2. Context Collaboration Network (CC-Net)
Atrous convolution can effectively expand the receptive field by using dilated convolutional kernels [
42], thereby capturing multiscale information. Based on this, ASPP uses multiple parallel dilated convolutional branches with different dilation rates to extract feature maps and then fuse multiscale features. This multibranch structure can efficiently encode multiscale contexts to improve segmentation performance [
43]. Self-attention mechanisms compute correlations between different positions in a sequence to achieve self-attention and context modeling. It can effectively capture long-range dependencies and provide global contextual clues [
44]. The structure of our context collaboration network (CC-Net) is illustrated in
Figure 5.
CC-Net organically integrates ASPP and Self-Attention. ASPP obtains multiscale feature expressions, and self-attention encodes global contexts and models positional relationships, complementing each other to form a context-collaborative structure. In the decoder, the self-attention features of the encoder output are inputted through skip connections, passing rich global context and localization information. In addition, CC-Net uses channel attention to focus on relevant semantic features. This structure considers both localization information and multiscale features, which can accurately segment buildings in remote sensing images. Through end-to-end training, the multiscale features of ASPP, the global context modeling and positioning information of self-attention, and the collaborative connection between them enable CC-Net to form an efficient building segmentation network with strong capabilities in complex scene understanding, achieving excellent localization and multiscale capabilities.
The convolutional feature maps are generated as the output from the Block5 section of the encoder, and these maps serve as the input for the atrous spatial pyramid pooling. The ASPP module contains 4 parallel branches using dilated convolutions with different dilation rates (1, 6, 12, 18) to obtain feature information at different scales. The 4 groups of feature maps after 1 × 1 convolution are concatenated to obtain feature expressions sensitive to multiscale features. The SA module contains query, key, and value 1 × 1 convolutions to generate query, key, and value feature maps. The attention map is generated by calculating the correlations between the query and key feature maps. Then, the value feature map is weighted by the attention map to obtain a new feature map fused with global context information. Finally, the CAM unit reweights the feature channels. The multiscale feature maps provided by ASPP are input into the SA module to fuse global context information. The output of SA will contain rich localization and multiscale features. By extracting multiscale features through ASPP and providing global context and localization information through SA, the combination and connection of the two in the encoder–decoder structure enable CC-Net to consider both localization information and integrate multiscale features, achieving excellent effects in segmenting buildings in complex rural scenes.
4. Experimental Datasets and Evaluation
4.1. Datasets
4.1.1. Building Image Dataset of Typical Rural Areas in China
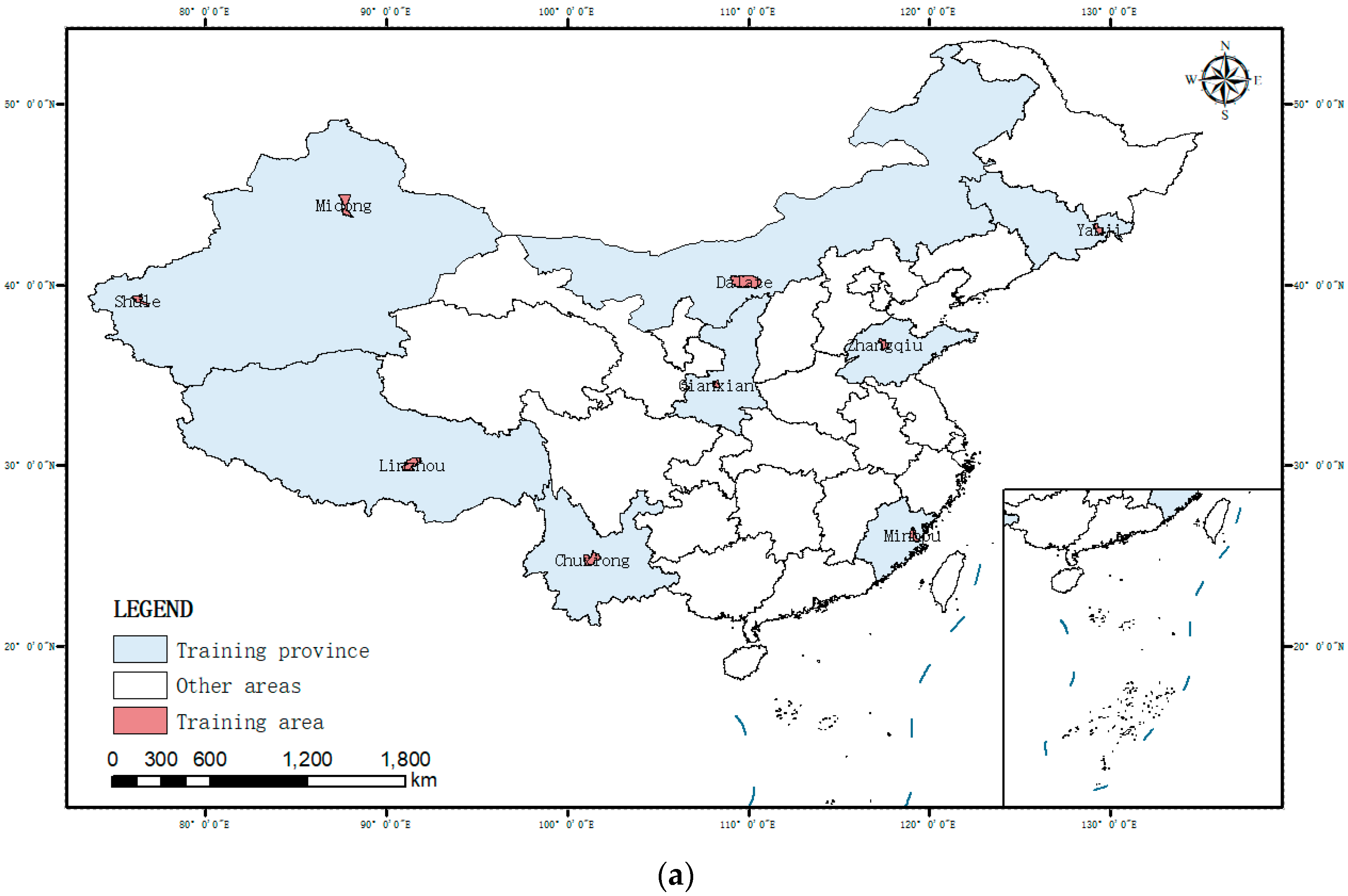
To solve the problems of insufficient sample data and large regional differences in rural buildings, this study constructed an open-source dataset of typical rural buildings in China for training rural building automatic extraction models based on deep learning. Considering the vast territory and complex diverse landforms in China, rural buildings in different regions have significant differences. This dataset selected sample images from nine geographical regions, including the Northeast Plain, North China Plain, and Yungui Plateau, representing the main geomorphological types, climate characteristics and regional architectural styles in China, ensuring the comprehensiveness and representativeness of the samples [
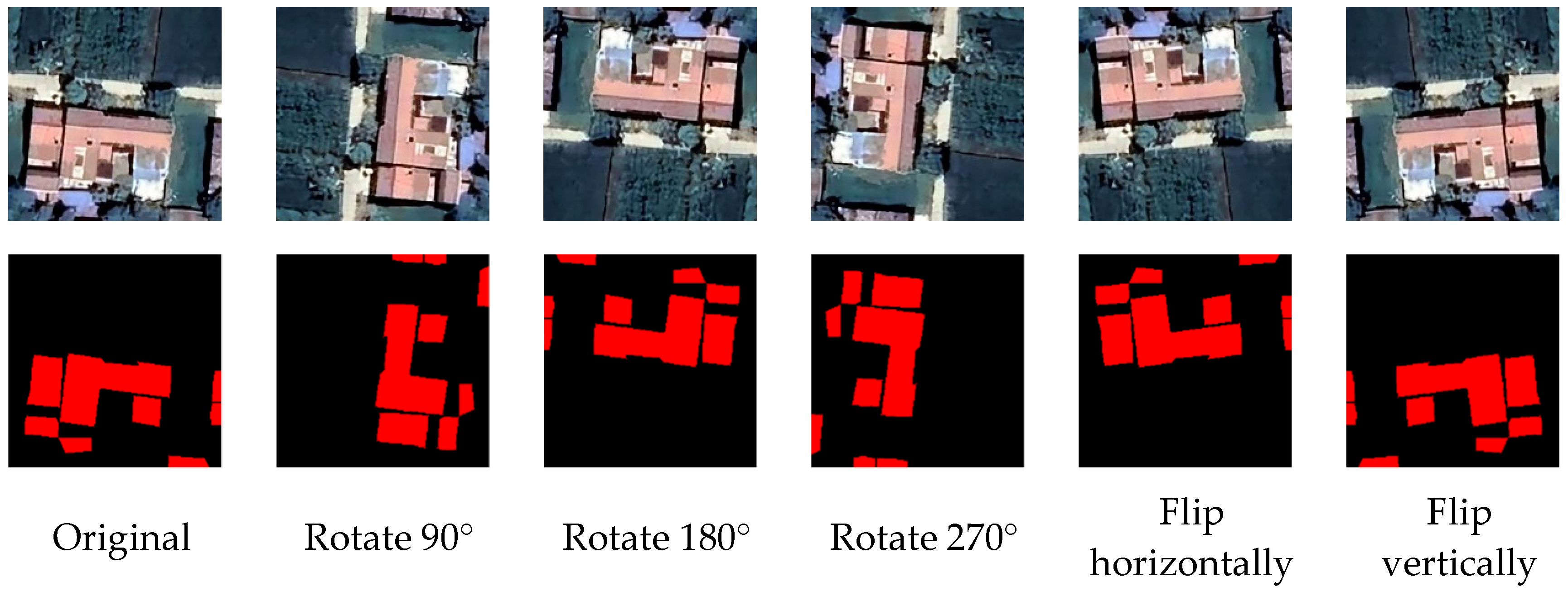
31]. All samples of this dataset come from 2020 Google remote sensing images with a resolution of 0.29 m, clearly reflecting the details of rural buildings. Based on the manual drawing of fine annotations containing building outlines and categories, the diversity of samples is enriched through rotation, flipping and other augmentation means, which can effectively enhance the robustness of models and prevent overfitting problems [
34], making up for the overall shortage of rural building samples. This dataset contains 13,428 images and annotations, of which 10,742 were randomly selected for model training and 2686 for testing.
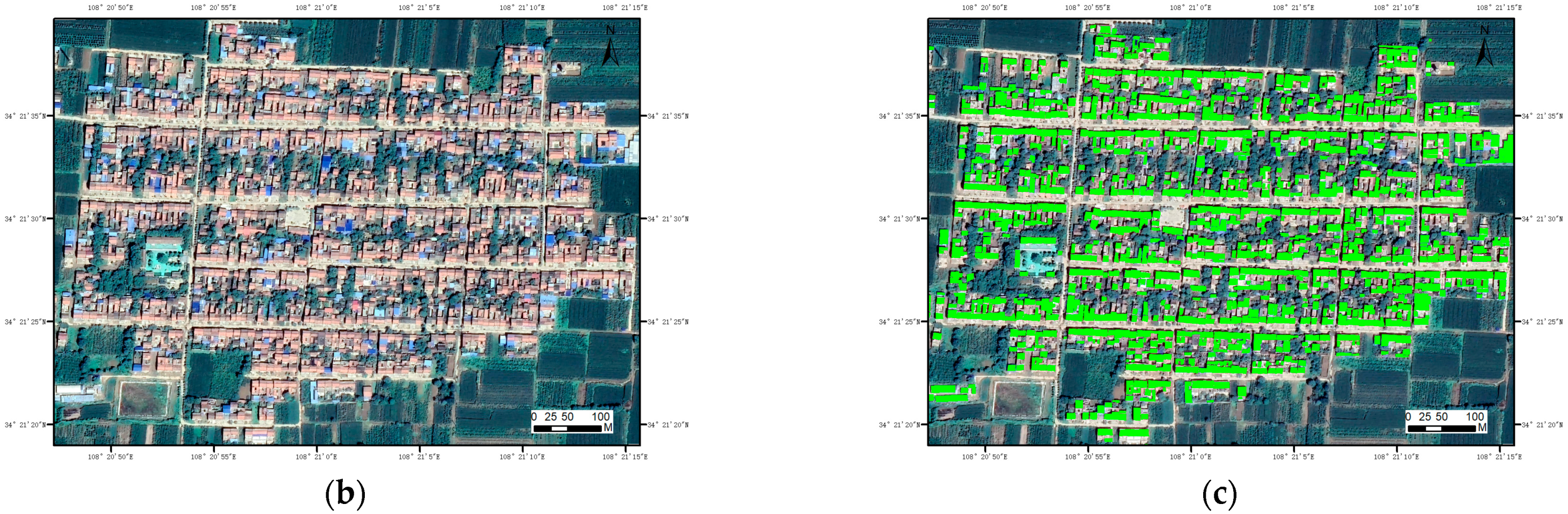
Figure 6 shows an original image and its corresponding label, where black represents the background and red represents the building.
4.1.2. China Rural Building UAV Imagery Dataset
This dataset uses UAV images obtained by DJI Inspire2 with a spatial resolution of up to 0.1 m, clearly capturing building boundary features and providing delicate visual information to meet the requirements of deep learning for high-quality image samples. It covers sample images from provinces, including Shaanxi, Jiangsu and Sichuan, with extensive geographical distributions. The images cover common rural building types in China, including masonry, stone and brick, with strong representativeness [
45]. The dataset contains 6060 original images and annotated samples, 4848 of which were selected for model training and 1212 for testing. An example of an input image and its corresponding label are presented in
Figure 7. The dataset has been made public, and the data service system website is
https://www.scidb.cn/en/detail?dataSetId=807518619180204032&version=V1 (accessed on 8 May 2023).
4.1.3. Varied Drone Dataset (VDD)
The Varied Drone Dataset (VDD) comprises 400 high-resolution aerial photographic images captured utilizing DJI MAVIC AIR II unmanned aerial vehicles from 23 geographical locations within Nanjing, China. It incorporates pixel-level semantic annotations across seven categories, labeled utilizing LabelMe software. In contrast to other datasets focused solely on urban environments, VDD incorporates diverse rural and natural landscapes, encompassing agricultural lands, villages, forests, hills, and bodies of water. With its large-scale annotated imagery spanning urban, industrial, rural, and natural areas captured from varying angles and conditions, VDD furnishes rich semantic details. VDD is freely available on the website
https://vddvdd.com/download/ (accessed on 13 November 2023) [
46]. We extracted the portion of the VDD dataset belonging to rural buildings to enrich our China Rural Building Unmanned Aerial Vehicle Imagery Dataset to verify the extraction potential for rural buildings within the unmanned aerial vehicle image dataset utilizing the model.
Figure 8 illustrates an example of input images and their corresponding labels in the VDD dataset.
4.2. Evaluation Metrics
In this study, five metrics, including overall accuracy (OA), precision, recall, F1 score and intersection over union (IoU), were adopted to evaluate the building extraction effects of different models. Among them, OA refers to the ratio of the number of correctly classified pixels to the total number of test pixels: precision reflects the ratio of true positives in all predicted positives, recall represents the ratio of true positives correctly identified, F1 score is the harmonic average of precision and recall, and IoU calculates the ratio of the intersection and union between the predicted and true targets, reflecting the segmentation accuracy. The definitions of the above metrics are as follows:
where TP, TN, FP and FN represent the number of pixels of true positives, true negatives, false positives and false negatives, respectively. These metrics reflect the building extraction performance of models from different perspectives. OA focuses on overall classification results, precision and recall focus on identification capabilities, F1 score combines precision and recall, and IoU directly examines segmentation accuracy. This study will use the above metrics to evaluate the building extraction results of different models and determine the pros and cons of models based on quantitative results.
4.3. Model Comparisons
To evaluate our rural building extraction method, we selected the typical encoder–decoder architecture extraction model SegNet, AGs-UNet with a structure similar to our building extraction model, C3Net, and CSA-UNet, also applied to rural building extraction for comparative experiments. A brief introduction of these models is as follows:
(1) SegNet is an image semantic segmentation network based on the encoder–decoder architecture proposed by Badrinarayanan et al. in 2015 [
47]. Compared with FCNs, the difference is that the decoder end reuses the max-pooling indices of the encoder pooling layers to help restore segmentation results with rich details [
48]. SegNet shows good real-time processing capabilities and semantic segmentation accuracy and is especially suitable for accurate pixel-level building extraction, so it is selected as the benchmark model.
(2) AGs-UNet is an improved version of UNet with multiple AG modules embedded to achieve enhanced representation of building-related features [
21]. Its attention mechanism can suppress irrelevant features, thereby improving the model’s ability to identify key building areas [
49]. AGs-UNet has verified the improvement of extraction performance on multiple high-resolution urban remote sensing image datasets and is selected to evaluate the effect of the attention module on this task.
(3) C
3Net adopts an encoder–decoder structure. The decoder integrates context-aware and edge residual refinement modules to achieve a balance between extraction accuracy and integrity [
23]. This model has been proven to make progress on multiple open datasets and is considered to provide comprehensive comparative extraction capabilities for this task.
(4) CSA-UNet is based on the encoder–decoder structure, using channel spatial attention mechanisms to focus on key building features [
50]. Compared with other datasets, its specifically constructed rural building sample dataset using UAV images is more consistent with the research objectives of this study. Considering the impact of dataset differences on model generalization capabilities, CSA-UNet is selected to evaluate the adaptability of models under new sample distributions.
In summary, these models have different focuses on building extraction tasks and can serve as comparative benchmarks to analyze the strengths and weaknesses of the AGSC-Net model in the application of extracting buildings in typical rural areas of China, evaluating the extraction capabilities of the model. To evaluate the extraction capabilities of the proposed model, all networks are tested on two datasets: the Building Image Dataset of Typical Rural Areas in China and the complementary China Rural Building UAV Imagery Dataset. The experimental results from these datasets are utilized to verify the extraction potential of the AGSC-Net model. The empirical results of these comparative experiments are detailed in the subsequent sections.
4.4. Experimental Settings
The model training and testing in this study are based on the PyTorch deep learning framework and use open-source image processing modules, including TorchVision, Skimage and Matplotlib. To accelerate the calculation, the computing device used in this study is the NVIDIA GeForce GTX 3090 graphics processing unit, with a memory capacity of 24 GB, and CUDA 11.0 has been installed for GPU acceleration. Considering the constraint of GPU memory resources, all image samples are randomly cropped to 256 × 256 pixels to meet the memory requirements for model training and cross-validation in each round. In the hyper-parameter configuration of the model, we performed multiple comparative experiments to determine the optimal settings for each model. The Adam optimization algorithm [
51] is used for model training, with an initial learning rate set to 0.0001. To suppress overfitting, L2 regularization is introduced in all convolutional layers, and the weight decay coefficient [
52] is set to 0.0001. Additionally, considering the limitation of the GPU memory of the computing device, the training of each model takes batches of 18 images as input and iterates 200 epochs on each dataset. To ensure the fairness of comparative experiments between different models, all comparison models are trained under the same software and hardware environment. The training accuracy and loss profiles [
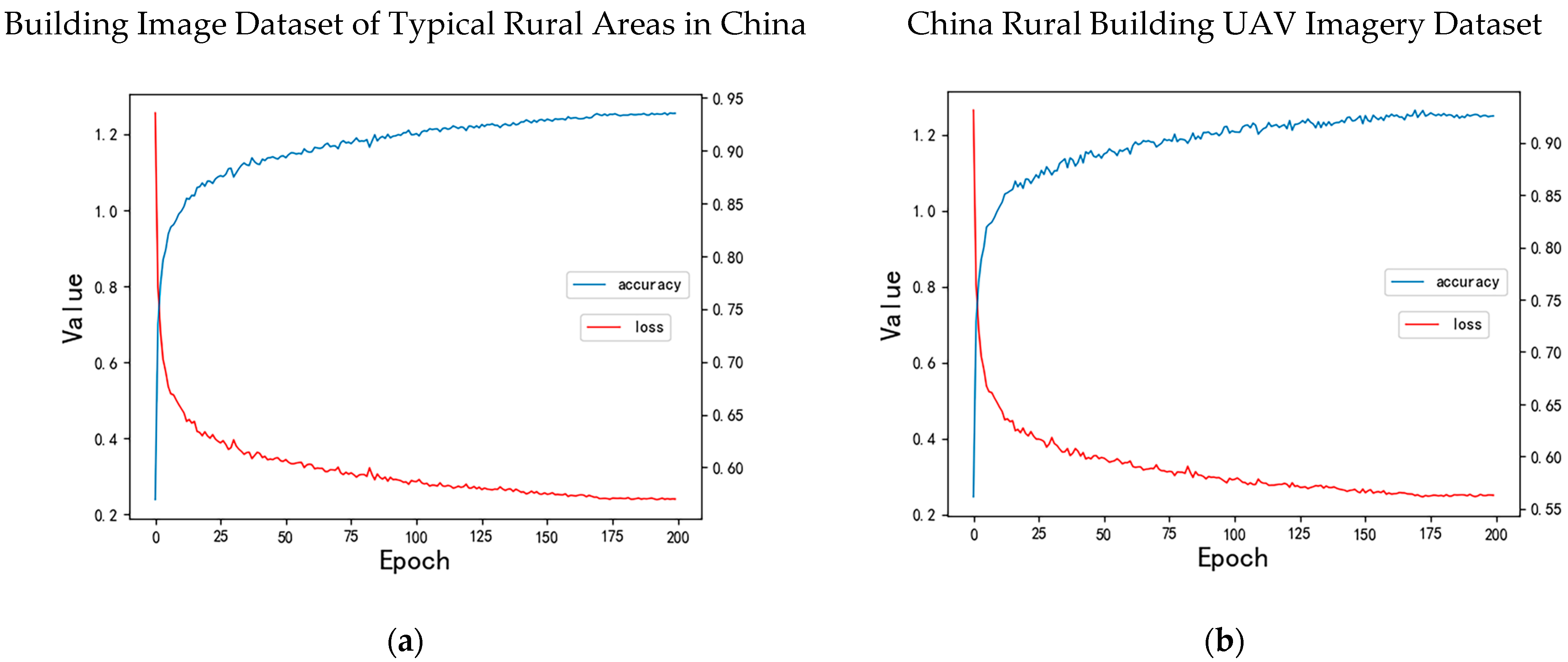
53] of the proposed AGSC-Net architecture on both datasets are presented in
Figure 9. As shown, the model accuracy consistently improves over training iterations and eventually converges to approximately 0.94 with minor fluctuations. Concurrently, the loss monotonically decreases and reaches a plateau, indicating effective optimization of the AGSC-Net model. Unless otherwise specified, all comparative models were trained under the same hardware and software configuration detailed previously to enable fair benchmarking against the proposed AGSC-Net.
4.5. Results
To validate the superiority of our self-constructed datasets for rural building extraction model training, we will train and test the proposed model on the self-constructed Building Image Dataset of Typical Rural Areas in China and the open China Rural Building UAV Image Dataset respectively. Test data from four geographic regions with distinct characteristics were selected from each dataset to assess the proposed model’s building extraction capabilities. Representative sample images were chosen from each image set for qualitative analysis. The proposed rural building extraction network AGSC-Net was compared to models such as SegNet, AGs-UNet, C
3Net and CSA-UNet. As shown in
Figure 10 and
Figure 11, the original remote sensing images and corresponding ground truths occupy the first two rows, while rows 3–7 exhibit the building extraction outputs of the different models. The green and black pixels in the extraction results denote regions classified by the models as buildings and non-buildings, respectively.
In
Figure 10, the red and purple rectangles in the first two columns contain small buildings. The extraction results of SegNet and AGs-UNet display varying degrees of internal structural deficiencies. C
3Net exhibits more complete internal information but insufficiently defined edges. CSA-UNet has sharper yet less smooth and natural edges. By contrast, AGSC-Net accurately and seamlessly extracts small building edges, contours and internal structures. The yellow rectangle in the third column encapsulates a densely populated large-scale building area. All models misdetect or omit some regions, but AGSC-Net has fewer missed detections, uniquely and accurately extracting even the buildings inside the yellow box. The blue rectangle area in the fourth column suffers from vegetation interference. AGs-UNet and C
3Net display localized contour deficiencies. SegNet and CSA-UNet also contain some misdetections. Comparatively, AGSC-Net obtained more precise extraction results. Overall, the AGSC-Net model demonstrates superior performance across diverse complex scenarios, validating the efficacy of its designed modules and network architecture.
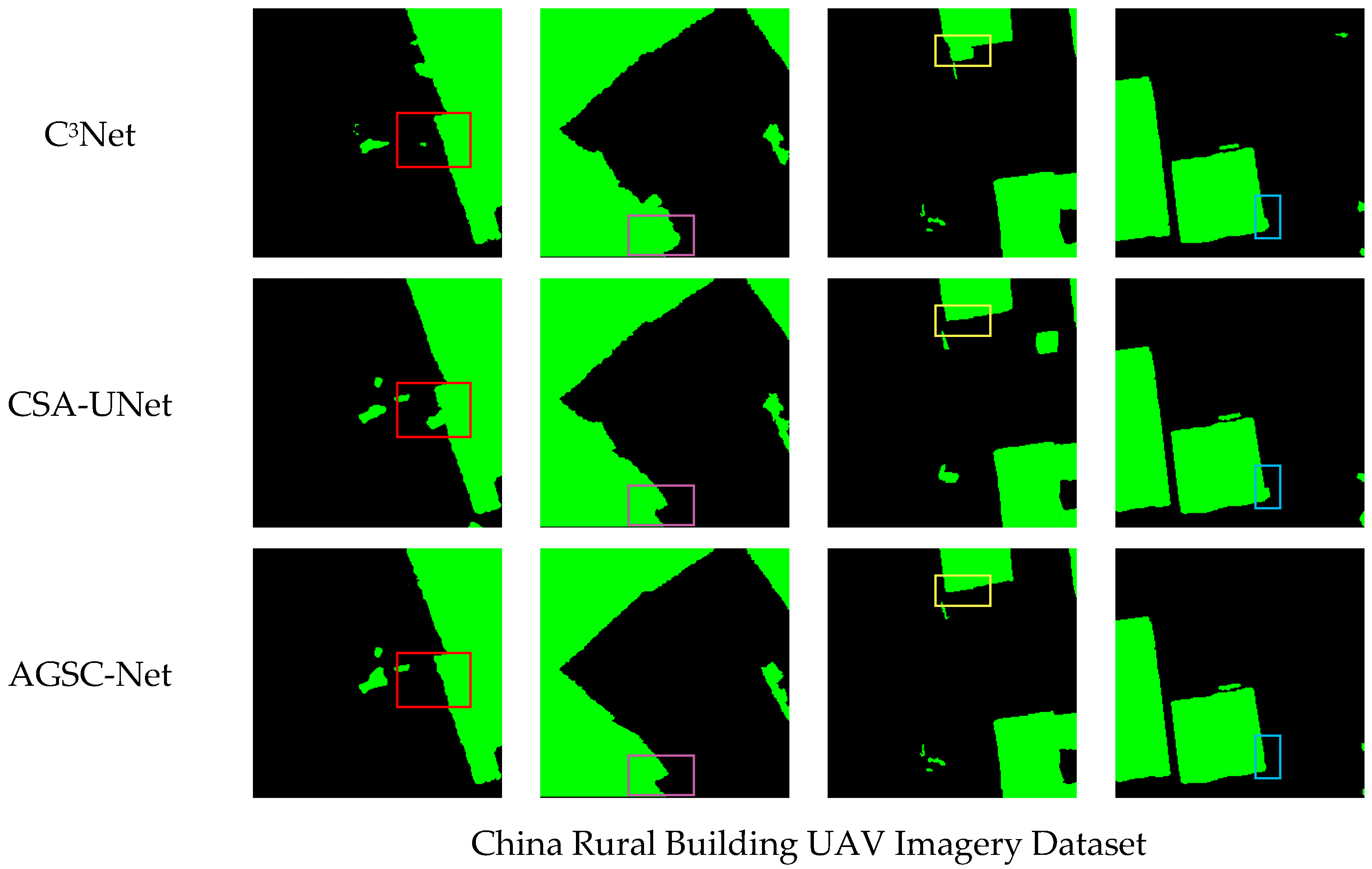
Figure 11 exhibits the extraction outputs on the UAV image dataset. With higher resolution, this dataset harbors more complex spectral and texture traits alongside profound detail. Moreover, with a smaller volume, it poses greater difficulty for extraction. When processing the sharper building contours, SegNet and AGs-UNet’s outlines show noticeable deficiencies and misclassifications. The contours from C
3Net and CSA-UNet appear more complete yet risk false positives with higher predictive values due to vegetation. Accounting for improvements conferred by the AG module and Contextual Correlation Network (CC-Net) module, AGSC-Net surpasses the other models, extracting building edges more accurately with fewer internal gaps.
From the quantitative evaluation, compared with other models, AGSC-Net achieved the best performance in all metrics. From the quantitative results of the first dataset, as illustrated in
Table 2, it can be seen that AGSC-Net outperforms the other models in all metrics. Specifically, compared with other models, AGSC-Net improved the OA metric by 0.3–3 percentage points and the IoU metric by 1–2.8 percentage points. This indicates that AGSC-Net can identify building pixels more accurately and provide finer building segmentation results. On the second dataset, as delineated in
Table 3, AGSC-Net improved the OA metric by 0.2–0.5 percentage points and the IoU metric by 0.6–1 percentage points compared to other models, maintaining significant performance advantages. Although C
3Net has the highest precision P on the first dataset, AGSC-Net has a higher F1 score by balancing precision and recall, evaluating the overall effect of the model more comprehensively. In addition, the IoU metric combines accuracy and recall metrics, and the IoU metric of AGSC-Net is significantly higher than that of the other models, indirectly verifying that its extraction results are more accurate and complete.
AGSC-Net has stronger adaptability to different types of rural buildings. It can be seen from the comparison of the two datasets that the metrics of all models on the second dataset are generally slightly lower than those on the first dataset. This is because the second dataset covers samples from the main terrain types in China, including masonry, stone, brick and other building types, but has fewer data samples than the first dataset, and the building styles are more complex, increasing the extraction difficulty. However, the performance decline in the AGSC-Net model is smaller than that of the other models, proving its stronger adaptability to different types of rural buildings. Specifically, although the P, R, and F1 metrics of all models decreased slightly on the second dataset compared to the first dataset, the decline in AGSC-Net is the smallest, and the R metric even increased slightly, indicating that its extraction results are more comprehensive and complete. At the same time, the IoU metric of AGSC-Net only dropped from 0.717 to 0.747, a decrease of less than 0.5%, significantly better than the 1–2% decrease in other models. Compared with other models using similar improvements, e.g., attention mechanisms such as CSA-UNet, the AGSC-Net model goes further by simultaneously utilizing the AG and context collaboration network (CC-Net), improving the representation capability and modeling capability of building features, thus achieving optimal performance. In summary, by achieving the best extraction results on two representative rural building datasets, the AGSC-Net model has proven its stronger generalization adaptability to extracting different building types in complex rural scenes.
5. Ablation Experiments
The following three ablation experiments are set up: (a) only containing the U-shaped convolutional neural network (UNet) architecture, (b) an improved network (UNet + AG) with AG modules based on UNet, and (c) the complete model (AGSC-Net) with both AG and context collaboration (CC-Net) modules. Under the same computer software and hardware environment and hyperparameter settings, the above three models were trained for 200 epochs. After training, we selected the same images from the validation set of the Building Image Dataset of Typical Rural Areas in China for model effect verification to ensure fair comparison under the same conditions for each experiment.
Figure 12 displays the visualization results of the three models on test sets of three different scenarios. The first row is a scene with sparse small building targets. The UNet model has significant building omission problems, while the UNet + AG model has some commission errors regarding small, scattered buildings. The second row is a complex rural building scene. The UNet model has many omissions of building edges, while the building edges extracted by the AGSC-Net model are smoother, indicating that the AG module effectively enhances the ability to identify building edges. The third row shows a scene with considerable vegetation interference. In this case, the detection effects of UNet and UNet + AG are poor, resulting in many misjudgments. The AGSC-Net model correctly excludes vegetation interference and accurately extracts buildings. The results prove that AGSC-Net can effectively suppress background interference and accurately extract buildings through the multilevel attention mechanism of the AG and CC-Net modules and the extracted multidimensional features.
This study also verified the positive effects of the AG and CC-Net modules on building extraction through quantitative analysis, providing references for constructing more accurate building extraction models. As indicated in
Table 4, compared with the baseline UNet model, the UNet + AG model with AG modules improved the detection precision (P) by 0.17 percentage points, mainly because the AG module enhanced the model’s ability to identify building edges. Compared with the UNet + AG model, the complete AGSC-Net model improved the detection precision (P) by 0.64 percentage points, and recall and other metrics were further improved. Especially in complex scenes with rich background interference, AGSC-Net significantly reduced commission errors. This proves that, under the synergistic effect of the AG and CC modules, the multilevel attention mechanism can effectively improve the extraction accuracy of buildings by enhancing building-related features and eliminating background interference.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}