
Sentiment Analysis of Students’ Feedback on E-Learning Using a Hybrid Fuzzy Model

Abstract
:1. Introduction
- A dataset is built from Twitter, and it includes the opinions of Saudi students about e-learning; these opinions are manually annotated as positive or negative.
- The collected dataset is related to e-learning, which is an important field that researchers in different disciplines are currently studying, so the dataset is helpful for reuse by other research works.
- An efficient hybrid model that combines fuzzy logic with BiLSTM is developed, and it is able to achieve good results. No previous studies have considered using this type of advanced integration in Arabic Sentiment Analysis.
- A comprehensive comparison of the performance of the proposed model with those of baseline models is provided.
- Generally, this study contributes to Arabic NLP tasks in terms of providing labeled data and developing a hybrid model aimed at handling aspects of uncertainty and ambiguity in Arabic texts.
2. Preliminaries
2.1. Deep Neural Networks
2.1.1. Recurrent Neural Networks (RNNs)
- Sequential Processing: LSTMs are well-suited for tasks involving sequential data, making them effective for sentiment analysis, where the order of words in a sentence can be crucial [30].
- Capturing Temporal Dependencies: LSTMs can capture long-term dependencies in sequences, which can be beneficial for understanding the context and sentiment in a sentence [30].
- Interpretability: LSTMs process input sequentially, which can make it easier to interpret the model’s decision-making process, as you can trace the flow of information through the time steps [29].
- Smaller Datasets: LSTMs can perform reasonably well with smaller datasets, which is advantageous when labeled sentiment analysis datasets are limited [31].
- Limited Parallelization: LSTMs process sequences sequentially, limiting parallelization during training, which can result in longer training times [29].
- Difficulty with Long-Range Dependencies: While LSTMs are designed to capture long-term dependencies, they may still struggle with very long-range dependencies in sequences [30].
2.1.2. Transformers
- Attention Mechanism: Transformers, with their attention mechanisms, can capture the global dependencies in the input sequence, allowing them to consider the entire context simultaneously [32].
- Parallelization: Transformers can efficiently parallelize computations during training, leading to faster training times, especially on hardware that supports parallel processing [32].
- Transfer Learning: Pre-trained transformer models, such as BERT, can be fine-tuned for sentiment analysis tasks. Transfer learning often leads to improved performance, especially when labeled data is limited [32].
- Effective for Various Sequence Lengths: Transformers can handle input sequences of varying lengths without the need for padding, which is beneficial for sentiment analysis tasks with variable-length texts [32].
- Computational Resources: Transformers, especially large pre-trained models, can be computationally intensive and may require significant resources, both in terms of memory and processing power [33].
- Interpretability: Transformers may be seen as less interpretable than LSTMs due to their parallel processing and attention mechanisms, making it challenging to trace the flow of information through the model [33].
2.1.3. Comparison between LSTM-Based Models and Transformers
2.2. Fuzzy Logic
- Fuzzy set: This is set A and is defined by the membership function MA (Equation (1)), and each element x in the set has a certain degree of membership between 0 and 1.
- Membership function: This function computes how each element in the fuzzy sets is mapped to its degree of membership, which is a value from a range within [0,1]. There are several kinds of membership functions, and they are selected depending on the condition of the problem. In general, the most commonly used functions are trapezoidal, Gaussian, and triangular functions.
- Fuzzification: This step uses a membership function to transform a crisp value into a fuzzy value that expresses the degree of membership of an element to different fuzzy sets.
- Fuzzy inference: This step applies some of the if-then rules on the results of the membership functions to obtain the fuzzy output.
- Defuzzification: This step converts the fuzzy output into a crisp value.
2.3. The Fusion of Fuzzy Logic and a Deep Neural Network
2.3.1. Cooperative Structure
2.3.2. Sequential Structure
2.3.3. Parallel Structure
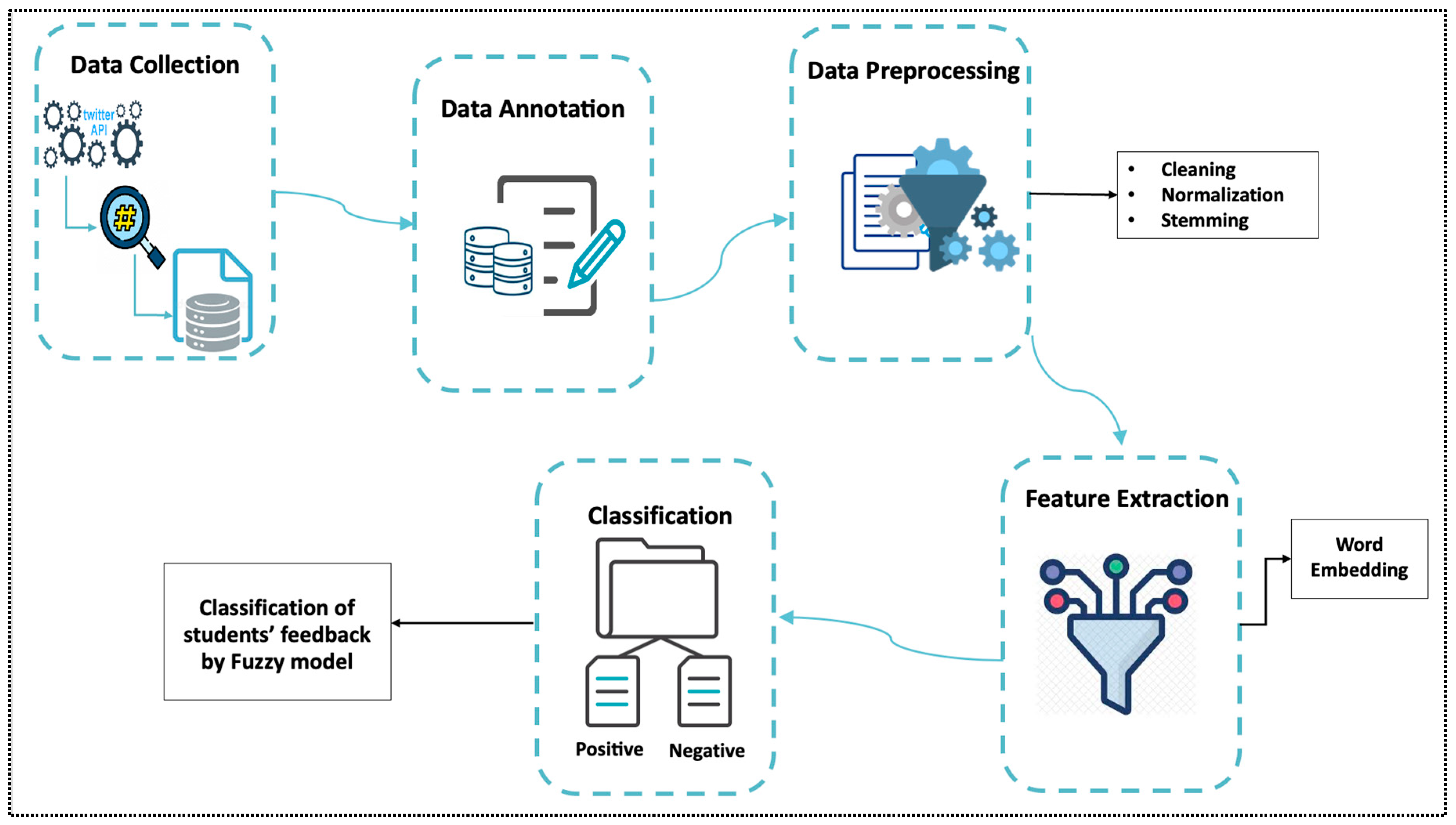
3. Methodology
3.1. Data Collection
3.2. Data Annotation
- A tweet had a positive label when the student agreed with e-learning by expressing a positive opinion.
- A tweet had a negative label when the student disagreed with e-learning by expressing a negative opinion.
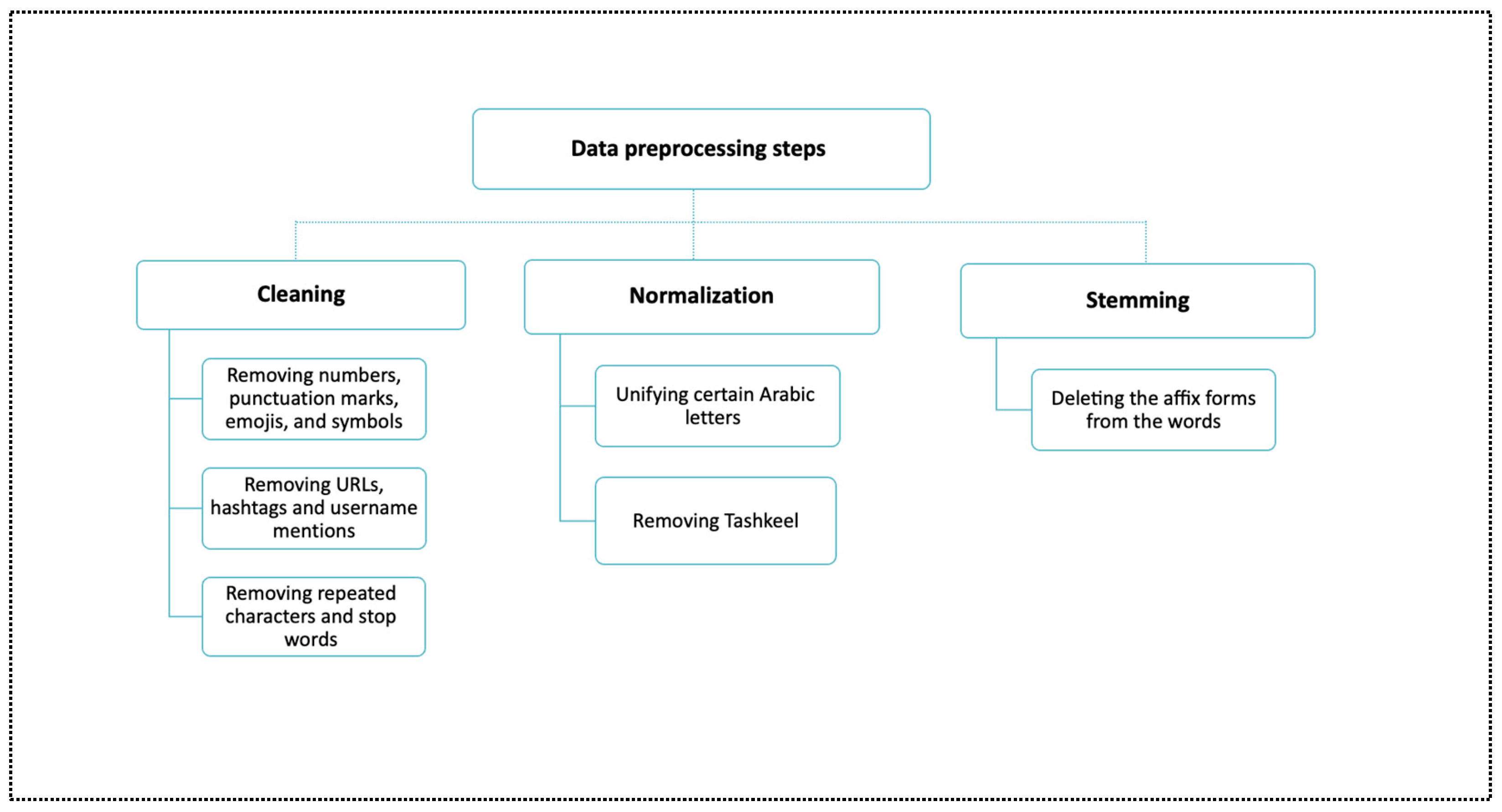
3.3. Data Preprocessing
3.3.1. Data Cleaning
3.3.2. Normalization
3.3.3. Stemming
3.4. Feature Extraction
- Input dimension: This is the number of all unique words in textual data, usually called the vocabulary size.
- Output dimension: The dimension of the generated vector is determined empirically, and it is usually set from 100 to 300.
- Input length: This is the number of words in each input sequence that has the maximum length.
- We applied tokenization to each input sequence; this is the process of splitting a text sequence into separate words or tokens.
- We built an indicating dictionary using all the vocabulary from the whole input dataset to be assigned into unique indices. As a result, we obtained a known vocabulary size that defines the input dimension parameter of the embedding layer.
- We applied the padding method, as the length of each input sequence in the dataset was expected to differ. For consistency, we padded certain additional tokens at the end of each input sequence to unify their lengths to the maximum length. As a result, the lengths of all input sequences were equal to the maximum length that defines the input length parameter of the embedding layer.
3.5. Proposed Model
3.5.1. The Fuzzify Layer
3.5.2. The Defuzzify Layer
4. Experiments
4.1. Hardware and Software Requirements
4.2. Implementation and Hyperparameter Setting
4.3. Training Procedures
5. Results
5.1. Experimental Results
5.2. Comparative Results
5.3. Additional Results
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment analysis and topic modeling on tweets about online education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Arambepola, N. Analysing the Tweets about Distance Learning during COVID-19 Pandemic using Sentiment Analysis. In Proceedings of the International Conference on Advances in Computing and Technology (ICACT–2020) Proceedings, Kelaniya, Sri Lanka, November 2020. [Google Scholar]
- Kastrati, Z.; Dalipi, F.; Imran, A.S.; Pireva Nuci, K.; Wani, M.A. Sentiment analysis of students’ feedback with nlp and deep learning: A systematic mapping study. Appl. Sci. 2021, 11, 3986. [Google Scholar] [CrossRef]
- Almalki, J. A machine learning-based approach for sentiment analysis on distance learning from Arabic Tweets. PeerJ Comput. Sci. 2022, 8, e1047. [Google Scholar] [CrossRef] [PubMed]
- Ulfa, S.; Bringula, R.; Kurniawan, C.; Fadhli, M. Student Feedback on Online Learning by Using Sentiment Analysis: A Literature Review. In Proceedings of the 2020 6th International Conference on Education and Technology, ICET 2020, Malang, Indonesia, 17 October 2020. [Google Scholar] [CrossRef]
- Nasim, Z.; Rajput, Q.; Haider, S. Sentiment Analysis of Student Feedback Using Machine Learning and Lexicon Based Approaches. In Proceedings of the International Conference on Research and Innovation in Information Systems, ICRIIS, 2017, Langkawi, Malaysia, 16–17 July 2017. [Google Scholar] [CrossRef]
- Al-Bayati, A.Q.; Al-Araji, A.S.; Ameen, S.H. Arabic Sentiment Analysis (ASA) Using Deep Learning Approach. J. Eng. 2020, 26, 85–93. [Google Scholar] [CrossRef]
- Subhashini, L.; Li, Y.; Zhang, J.; Atukorale, A.S. Integration of Fuzzy and Deep Learning in Three-Way Decisions. In Proceedings of the IEEE International Conference on Data Mining Workshops, ICDMW, Sorrento, Italy, 17–20 November 2020. [Google Scholar] [CrossRef]
- Bedi, P.; Khurana, P. Sentiment Analysis Using Fuzzy-Deep Learning. In Lecture Notes in Electrical Engineering; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Ali, M.M. Arabic sentiment analysis about online learning to mitigate COVID-19. J. Intell. Syst. 2021, 30, 524–540. [Google Scholar] [CrossRef]
- Althagafi, A.; Althobaiti, G.; Alhakami, H.; Alsubait, T. Arabic Tweets Sentiment Analysis about Online Learning during COVID-19 in Saudi Arabia. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 234147349. [Google Scholar] [CrossRef]
- Aljabri, M.; Chrouf, S.M.B.; Alzahrani, N.A.; Alghamdi, L.; Alfehaid, R.; Alqarawi, R.; Alhuthayfi, J.; Alduhailan, N. Sentiment analysis of arabic tweets regarding distance learning in Saudi Arabia during the COVID-19 Pandemic. Sensors 2021, 21, 5431. [Google Scholar] [CrossRef] [PubMed]
- Alkhaldi, S.; Alzuabi, S.; Alqahtani, R.; Alshammari, A.; Alyousif, F.; Alboaneen, D.A.; Almelihi, M. Twitter Sentiment Analysis on Activities of Saudi General Entertainment Authority. In Proceedings of the ICCAIS 2020—3rd International Conference on Computer Applications and Information Security, Riyadh, Saudi Arabia, 19–21 March 2020. [Google Scholar] [CrossRef]
- Alhuri, L.A.; Aljohani, H.R.; Almutairi, R.M.; Haron, F. Sentiment Analysis of COVID-19 on Saudi Trending Hashtags Using Recurrent Neural Network. In Proceedings of the International Conference on Developments in eSystems Engineering, DeSE, Liverpool, UK, 14–17 December 2020. [Google Scholar] [CrossRef]
- Alqarni, A.; Rahman, A. Arabic Tweets-Based Sentiment Analysis to Investigate the Impact of COVID-19 in KSA: A Deep Learning Approach. Big Data Cogn. Comput. 2023, 7, 16. [Google Scholar] [CrossRef]
- Deng, Y.; Ren, Z.; Kong, Y.; Bao, F.; Dai, Q. A Hierarchical Fused Fuzzy Deep Neural Network for Data Classification. IEEE Trans. Fuzzy Syst. 2017, 25, 1006–1012. [Google Scholar] [CrossRef]
- Elfaik, H.; Nfaoui, E.H. Deep Bidirectional LSTM Network Learning-Based Sentiment Analysis for Arabic Text. J. Intell. Syst. 2021, 30, 395–412. [Google Scholar] [CrossRef]
- Heikal, M.; Torki, M.; El-Makky, N. Sentiment Analysis of Arabic Tweets Using Deep Learning. Procedia Comput. Sci. 2018, 142, 114–122. [Google Scholar] [CrossRef]
- Biltawi, M.; Etaiwi, W.; Tedmori, S.; Shaout, A. Fuzzy Based Sentiment Classification in the Arabic Language. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Rattrout, A.; Ateeq, A. Sentiment Analysis on Arabic Content in Social Media; ACM International Conference Proceeding Series. In Proceedings of the 3rd International Conference on Future Networks and Distributed Systems, New York, NY, USA, 1–2 July 2019. [Google Scholar] [CrossRef]
- Vidyapeetham, A.V. Fuzzy Based Machine Learning: A Promising Approach. 2012. Available online: www.csi-india.org (accessed on 1 November 2023).
- Das, R.; Sen, S.; Maulik, U. A Survey on Fuzzy Deep Neural Networks. ACM Comput. Surv. 2020, 53, 54. [Google Scholar] [CrossRef]
- Tomer, M.; Kumar, M. Improving Text Summarization Using Ensembled Approach Based on Fuzzy with LSTM. Arab. J. Sci. Eng. 2020, 45, 10743–10754. [Google Scholar] [CrossRef]
- Nguyen, T.-L.; Kavuri, S.; Lee, M. A fuzzy convolutional neural network for text sentiment analysis. J. Intell. Fuzzy Syst. 2018, 35, 6025–6034. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Subhan, F.; Ahmad, H.; Khan, W.Z.; Hakak, S.; Gadekallu, T.R.; Alazab, M. Senti-eSystem: A sentiment-based eSystem-using hybridized fuzzy and deep neural network for measuring customer satisfaction. Softw. Pract. Exp. 2021, 51, 571–594. [Google Scholar] [CrossRef]
- Sivakumar, M.; Uyyala, S.R. Aspect-based sentiment analysis of mobile phone reviews using LSTM and fuzzy logic. Int. J. Data Sci. Anal. 2021, 12, 355–367. [Google Scholar] [CrossRef]
- Es-Sabery, F.; Hair, A.; Qadir, J.; Sainz-De-Abajo, B.; Garcia-Zapirain, B.; Torre-Diez, I. Sentence-Level Classification Using Parallel Fuzzy Deep Learning Classifier. IEEE Access 2021, 9, 17943–17985. [Google Scholar] [CrossRef]
- Alhumoud, S.O.; Al Wazrah, A.A. Arabic sentiment analysis using recurrent neural networks: A review. Artif. Intell. Rev. 2022, 55, 707–748. [Google Scholar] [CrossRef]
- Wahdan, A.; AL Hantoobi, S.; Salloum, S.A.; Shaalan, K. A systematic review of text classification research based on deep learning models in Arabic language. Int. J. Electr. Comput. Eng. (IJECE) 2020, 10, 6629–6643. [Google Scholar] [CrossRef]
- Seo, S.; Kim, C.; Kim, H.; Mo, K.; Kang, P. Comparative Study of Deep Learning-Based Sentiment Classification. IEEE Access 2020, 8, 6861–6875. [Google Scholar] [CrossRef]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment analysis of comment texts based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Advances in Neural Information Processing Systems; NIPS Foundation: La Jolla, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS’20), Virtual, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020; pp. 1877–1901. [Google Scholar]
- Jesse, V.; Ali, M.; Lav, V.; Caiming, X.; Richard, S.; Nazneen, R. BERTology Meets Biology: Interpreting Attention in Protein Language Models. In Proceedings of the 9th International Conference on Learning Representations, (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Tashtoush, Y.M.; Orabi, D.A.A.A. Tweets Emotion Prediction by Using Fuzzy Logic System. In Proceedings of the 2019 6th International Conference on Social Networks Analysis, Management and Security, SNAMS, Granada, Spain, 22–25 October 2019. [Google Scholar] [CrossRef]
- Talpur, N.; Abdulkadir, S.J.; Alhussian, H.; Hasan, M.H.; Aziz, N.; Bamhdi, A. Deep Neuro-Fuzzy System application trends, challenges, and future perspectives: A systematic survey. Artif. Intell. Rev. 2023, 56, 865–913. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Xu, Z.; Wang, X. The Fusion of Deep Learning and Fuzzy Systems: A State-of-the-Art Survey. IEEE Trans. Fuzzy Syst. 2022, 30, 2783–2799. [Google Scholar] [CrossRef]
- Talpur, N.; Abdulkadir, S.J.; Alhussian, H.; Hasan, H.; Aziz, N.; Bamhdi, A. A comprehensive review of deep neuro-fuzzy system architectures and their optimization methods. Neural Comput. Appl. 2022, 34, 1837–1875. [Google Scholar] [CrossRef]
- Alqurashi, T. Stance Analysis of Distance Education in the Kingdom of Saudi Arabia during the COVID-19 Pandemic Using Arabic Twitter Data. Sensors 2022, 22, 1006. [Google Scholar] [CrossRef] [PubMed]
- Hadwan, M.; Al-Sarem, M.; Saeed, F.; Al-Hagery, M.A. An Improved Sentiment Classification Approach for Measuring User Satisfaction toward Governmental Services’ Mobile Apps Using Machine Learning Methods with Feature Engineering and SMOTE Technique. Appl. Sci. 2022, 12, 5547. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.-Z.; Lahcen, A.A.; Belfkih, S. ASA: A framework for Arabic sentiment analysis. J. Inf. Sci. 2020, 46, 544–559. [Google Scholar] [CrossRef]
- Alassaf, M.; Qamar, A.M. Improving Sentiment Analysis of Arabic Tweets by One-way ANOVA. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 2849–2859. [Google Scholar] [CrossRef]
- Bahamdain, A.; Alharbi, Z.H.; Alhammad, M.M.; Alqurashi, T. Analysis of Logistics Service Quality and Customer Satisfaction during COVID-19 Pandemic in Saudi Arabia. Int. J. Adv. Comput. Sci. Appl. 2022, 13. [Google Scholar] [CrossRef]
- Almazrua, A.; Almazrua, M.; Alkhalifa, H. Comparative Analysis of Nine Arabic Stemmers on Microblog Information Retrieval. In Proceedings of the 2020 International Conference on Asian Language Processing, IALP 2020, Kuala Lumpur, Malaysia, 4–6 December 2020. [Google Scholar] [CrossRef]
- Abdelali, A.; Darwish, K.; Durrani, N.; Mubarak, H. Farasa: A Fast and Furious Segmenter for Arabic. In Proceedings of the NAACL-HLT 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Demonstrations Session, San Diego, CA, USA, June 2016. [Google Scholar] [CrossRef]
- Oueslati, O.; Cambria, E.; Ben HajHmida, M.; Ounelli, H. A review of sentiment analysis research in Arabic language. Futur. Gener. Comput. Syst. 2020, 112, 408–430. [Google Scholar] [CrossRef]
- Abdelminaam, D.S.; Neggaz, N.; Gomaa, I.A.E.; Ismail, F.H.; Elsawy, A.A. ArabicDialects: An efficient framework for arabic dialects opinion mining on twitter using optimized deep neural networks. IEEE Access 2021, 9, 97079–97099. [Google Scholar] [CrossRef]
- Zahidi, Y.; El Younoussi, Y.; Al-Amrani, Y. A powerful comparison of deep learning frameworks for Arabic sentiment analysis. Int. J. Electr. Comput. Eng. 2021, 11, 745–752. [Google Scholar] [CrossRef]
- Bahuguna, A.; Yadav, D.; Senapati, A.; Saha, B.N. A unified deep neuro-fuzzy approach for COVID-19 twitter sentiment classification. J. Intell. Fuzzy Syst. 2022, 42, 4587–4597. [Google Scholar] [CrossRef]
- Liu, H.; Burnap, P.; Alorainy, W.; Williams, M.L. A Fuzzy Approach to Text Classification With Two-Stage Training for Ambiguous Instances. IEEE Trans. Comput. Soc. Syst. 2019, 6, 227–240. [Google Scholar] [CrossRef]
- Fkih, F.; Moulahi, T.; Alabdulatif, A. Machine Learning Model for Offensive Speech Detection in Online Social Networks Slang Content. WSEAS Trans. Inf. Sci. Appl. 2023, 20, 7–15. [Google Scholar] [CrossRef]
- Haddad, O.; Fkih, F.; Omri, M.N. Toward a prediction approach based on deep learning in Big Data analytics. Neural Comput. Appl. 2023, 35, 6043–6063. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Machine Learning Techniques | Feature Extraction Methods | Type of Dataset Annotation | Language of Dataset |
|---|---|---|---|---|
| [4] | Logistic Regression, Support Vector Machine | Bag of words | N/A | Arabic |
| [10] | Logistic Regression, K-Nearest Neighbor, Naive Bayes, Multinomial Naive Bayes, Support Vector Machine | N/A | Automatic | Arabic |
| [11] | Naive Bayes, Random Forest, K-Nearest Neighbor | N/A | Automatic | Arabic in Saudi dialect |
| [12] | Support Vector Machine, Random Forest, K-Nearest Neighbor Naive Bayes, Logistic Regression, XGBoost | N-Gram, TF-IDF | Manual | Arabic in Saudi dialect |
| Ref | Method | Source of Dataset | Language of Dataset | Best Accuracy Result |
|---|---|---|---|---|
| [24] | Fuzzy with BiLSTM | Twitter-based dataset | English | 92.86% |
| [25] | Fuzzy with LSTM | Three Amazon review datasets | English | 96.93% |
| [26] | Fuzzy with CNN | Two Twitter-based datasets | English | 99.97% |
| [9] | Fuzzy with LSTM | Movie review dataset | English | 88.91% |
| [19] | Fuzzy with CNN | Two Twitter-based datasets, three movie review datasets | English | 78.85% |
| Hashtags and Keywords | English Translation |
|---|---|
| التعلم ـ الإلكتروني# التعلم الإلكتروني | E-learning |
| التعليم ـ الإلكتروني# التعليم الإلكتروني | E-teaching |
| الدراسة ـ عن ـ بعد# الدراسة عن بعد | Distance learning |
| الدراسة—أونلاين# الدراسة أونلاين | Online learning |
| Tweet Text | English Translation | Label |
|---|---|---|
| الدراسة عن بعد حلوه وممتعه ولله الحمد مثابرين بكل جد واجتهاد | Distance learning is nice and enjoyable, and thank God, we are continuing with interest. | Positive |
| دراستنا اونلاين فكرة فاشلة جداً للأسف ضاعت درجاتي | Our online study was a very unsuccessful idea, unfortunately, my grades were lost. | Negative |
| مستواي تحسن مع استخدام التعلم الالكتروني يكفي سهولة البحث | My studying level has improved with the use of e-learning, it is enough that searching for information has been easy. | Positive |
| أنا أعترف أني مليت من الدراسة عن بعد سيئة وجداً متعبة | I admit that I am tired of distance learning, it is bad and very tiring. | Negative |
| Shape of the Letter | Normalized to |
|---|---|
| أ،إ،آ | ا |
| ؤ | و |
| ى،ئ | ي |
| ة | ه |
| Parameters. | Optimal Value |
|---|---|
| Number of neurons in BiLSTM | 32 |
| Dropout rate | 0.5 |
| Optimizer | ADAM |
| Learning rate | 0.0001 |
| Loss function | Binary_crossentropy |
| Activation function | Sigmoid |
| Experiment | Accuracy | F1-Score | Recall | Precision | |
|---|---|---|---|---|---|
| Five-fold cross-validation | 0.840 | 0.826 | 0.821 | 0.832 | |
| Train/test split | (60–40%) | 0.853 | 0.845 | 0.861 | 0.831 |
| (70–30%) | 0.852 | 0.846 | 0.851 | 0.842 | |
| (80–20%) | 0.861 | 0.851 | 0.870 | 0.834 | |
| Model | Accuracy | F1-Score | Recall | Precision |
|---|---|---|---|---|
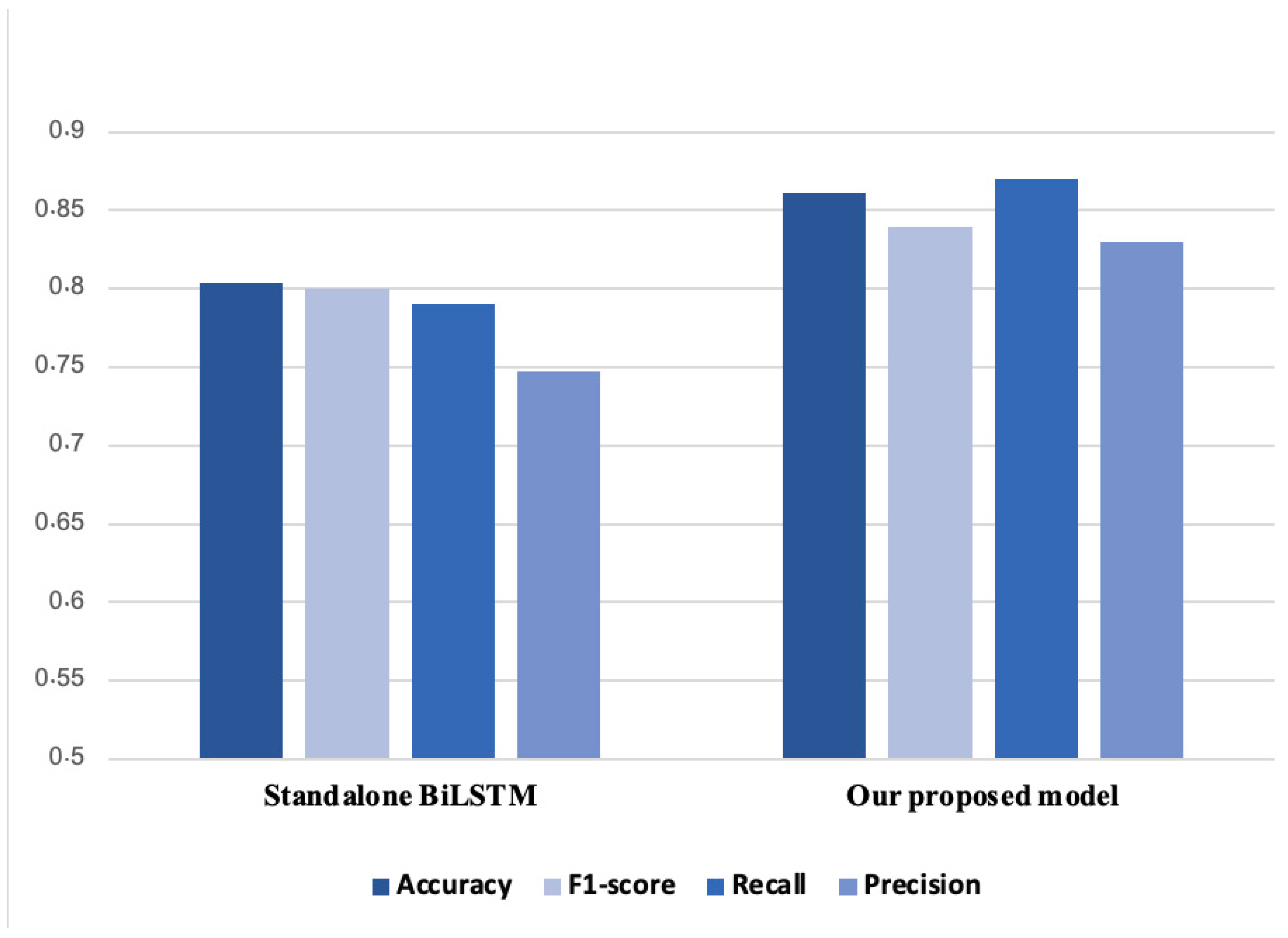
| Standalone BiLSTM | 0.804 | 0.767 | 0.790 | 0.747 |
| Our Proposed Model | 0.861 | 0.851 | 0.870 | 0.834 |
| Model | Accuracy | F1-Score | Recall | Precision |
|---|---|---|---|---|
| NB | 0.76 | 0.75 | 0.76 | 0.75 |
| RF | 0.76 | 0.75 | 0.71 | 0.80 |
| LR | 0.79 | 0.77 | 0.74 | 0.81 |
| KNN | 0.78 | 0.76 | 0.77 | 0.76 |
| DT | 0.72 | 0.70 | 0.70 | 0.71 |
| FDT | 0.77 | 0.75 | 0.75 | 0.76 |
| Our proposed model | 0.86 | 0.85 | 0.87 | 0.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzaid, M.; Fkih, F. Sentiment Analysis of Students’ Feedback on E-Learning Using a Hybrid Fuzzy Model. Appl. Sci. 2023, 13, 12956. https://doi.org/10.3390/app132312956
Alzaid M, Fkih F. Sentiment Analysis of Students’ Feedback on E-Learning Using a Hybrid Fuzzy Model. Applied Sciences. 2023; 13(23):12956. https://doi.org/10.3390/app132312956
Chicago/Turabian StyleAlzaid, Maryam, and Fethi Fkih. 2023. "Sentiment Analysis of Students’ Feedback on E-Learning Using a Hybrid Fuzzy Model" Applied Sciences 13, no. 23: 12956. https://doi.org/10.3390/app132312956