1. Introduction
Binary code similarity detection (BCSD) is a pivotal technique in the spheres of computer security and software engineering. Given an unknown binary file, the BCSD tools extract features of binary code and search corresponding similar code in the repositories. Its broad applications span various field of software analysis, including software plagiarism [
1], malware analysis [
2,
3,
4,
5,
6], and bug search [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18].
Given the significance of BCSD techniques, numerous approaches have been proposed to work on a variety of BCSD scenarios. Traditional BCSD approaches [
8,
18,
19,
20,
21,
22], which predate the incorporation of machine learning (ML) into BCSD tasks, depend heavily on specific features such as control flow graphs (CFGs), raw bytes, instructions, basic block counts, and strings for detecting similarities in binary code. For example, CFG-based approaches [
20] transfer binary code into CFGs and calculate their similarities based on their graph structure, nodes, and edges. These approaches necessitate rich experience and expert knowledge to determine feature weights and are also sensitive to code alterations. Even minor changes in binary code can cause substantial changes in these features, thereby challenging traditional BCSD methods.
In recent years, researchers have gravitated towards machine learning-based solutions to perform the BCSD tasks. Current state-of-the-art BCSD approaches [
10,
13,
15,
23,
24,
25] leverage machine learning (ML) techniques and utilize trained neural networks to comprehend the semantics of functions based on their instructions. These semantics are embedded onto normalized high-dimensional embeddings within a hyper-sphere, and we measure the similarities of binary code according to the proximity of their embeddings within the hyper-sphere. Approaches such as Genius [
26] and Gemini [
27] manually select the statistical features of basic blocks and employ graph neural networks (GNNs) to generate function embeddings for function matching, while jTrans [
13], VulHawk [
10], and SAFE [
25] treat instructions of function as a language and employ Natural Language Processing (NLP) techniques to automatically extract semantics and generate function embeddings to compute function similarity.
Presently, BCSD approaches mainly focus on function-level BCSD tasks. However, due to the fact that binary functions are typically composed of many basic blocks, identifying corresponding basic blocks or code snippets in two similar functions still requires a significant amount of work, making it a challenging problem.
In binary files, basic blocks refer to sequences of instructions that have a single entry point and a single exit point. A function with complex functionality usually consists of a large number of basic blocks.
Figure 1 illustrates three functions sourced from the same source code (function
register_state in the
gawk project) but different compilation options. Despite these functions being homologous, matching similar basic blocks or code snippets among them remains a time-consuming and challenging problem, considering their complex CFGs and numerous basic blocks. Thus, a fine-grained BCSD approach at the basic block level becomes urgent to solve the last-mile problem of BCSD tasks regarding matching among numerous basic blocks. When conducting BCSD at the basic block level, the following challenges need to be addressed.
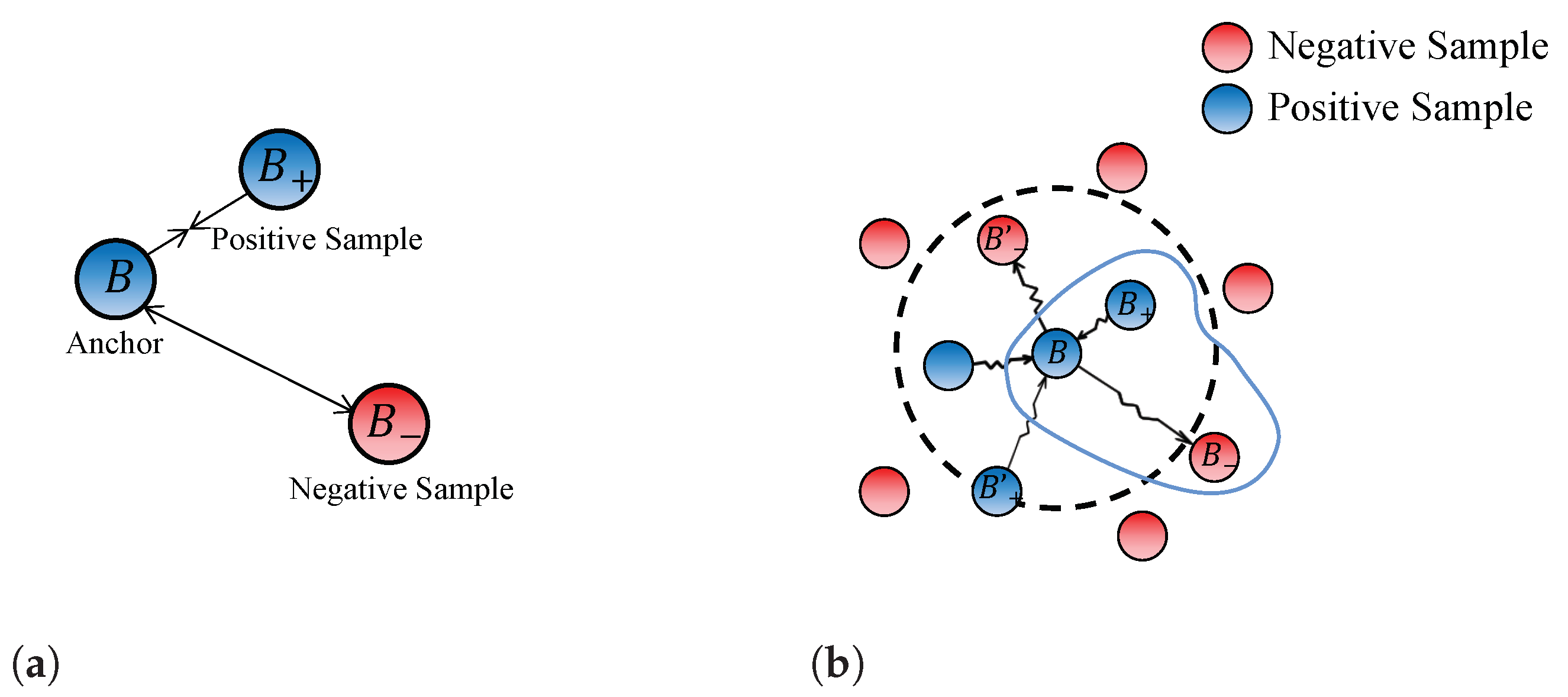
The existing BCSD approaches employ Triplet Loss [
28] to optimize the parameters of models based on partial samples [
13,
29]. However, this way has potential drawbacks as it may lead to suboptimal optimization and overlook better models. Triplet loss is a widely-used training objective function, aiming to minimize the distance between embeddings of similar binary code while maximizing the distance for dissimilar ones. As shown in
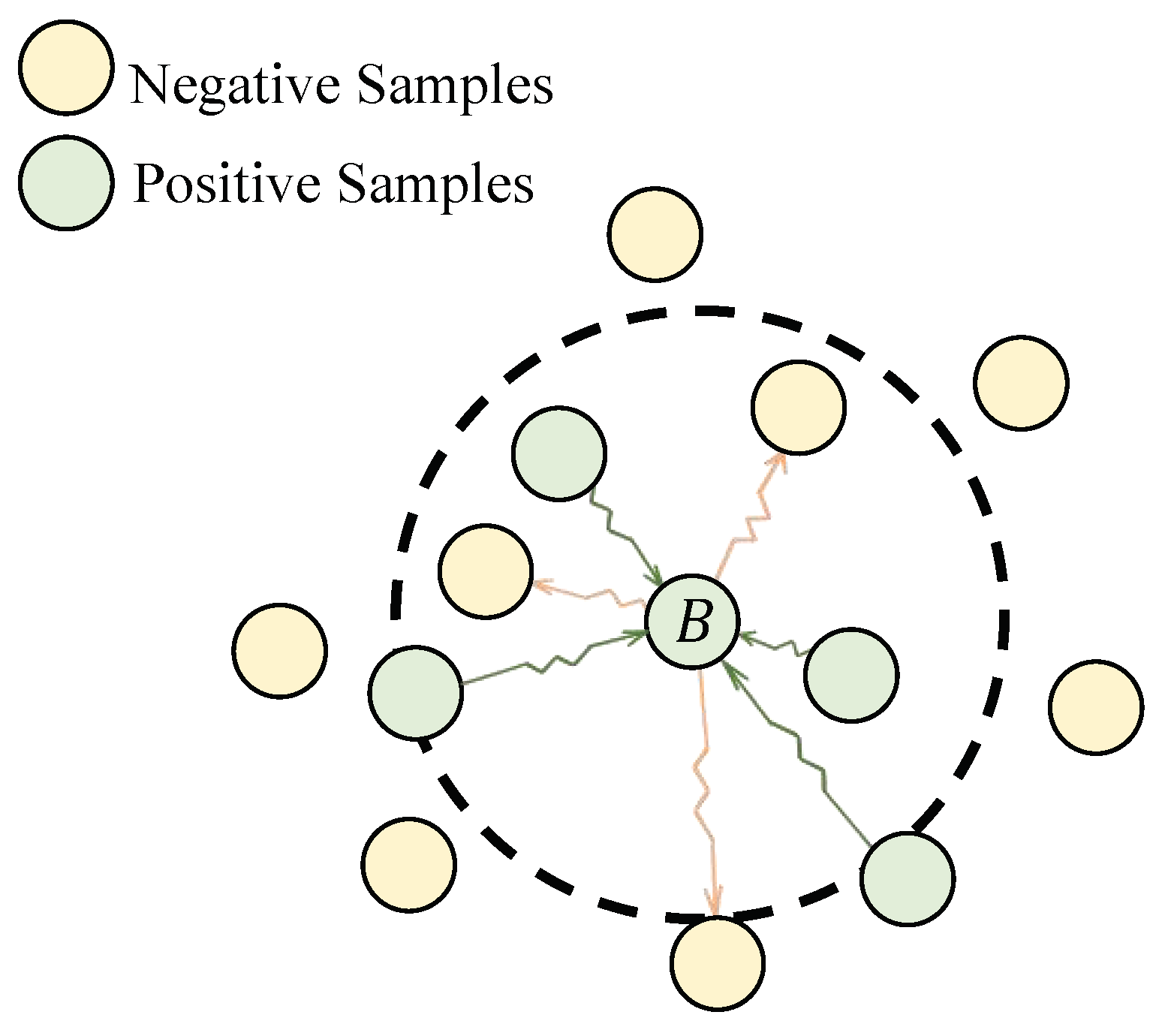
Figure 2a, an anchor represents an input basic block
B, a positive sample
denotes a similar block to the anchor, and a negative sample
represents a dissimilar one. During the training, the triplet loss objective brings the embeddings of block
B and block
closer in the hyper-sphere, while ensuring a distinct separation between
B and
. Nevertheless, in real-world BCSD tasks, given an anchor basic block, there are numerous similar basic blocks and dissimilar basic blocks. As shown in
Figure 2b, the triplet loss function focuses primarily on the local positive/negative samples and lacks a more comprehensive optimization, resulting in slow convergence and even difficulty in converging to the desired parameters.
Furthermore, selecting representative positive/negative samples from a large number of basic blocks is challenging, and the quality of the positive/negative samples seriously affects the effectiveness of model training. In BCSD tasks, easy samples represent basic blocks with distinguishable features that facilitate accurate predictions or classifications, while hard samples present challenges and complexities for the model predictions. In
Figure 2b, with
B as the anchor sample,
and
are an easy positive sample and an easy negative one, while
and
are a hard positive sample and a hard negative one, respectively. As depicted in
Figure 2b, with
B as the anchor sample,
and
represent easy positive and easy negative samples, respectively, while
and
represent hard positive and hard negative samples. Easy samples are typically associated with low prediction errors and contribute less to the overall loss calculations, while hard samples tend to result in higher prediction errors and have a greater impact on the overall loss calculations.
In this paper, we introduce a novel approach called
BlockMatchfor fine-grained Binary Code Similarity Detection (BCSD) that utilizes Natural Language Processing (NLP) and contrastive learning techniques to match similar basic blocks between complex functions for the last-mile problem of BCSD tasks. Basic blocks in binary files consist of various instructions. We first treat binary code as a language and use a DeBERTa model to capture position relations and contextual semantics for instruction sequence encoding. We then use a mean pooling layer to generate basic block embeddings for binary code similarity detection. To solve the aforementioned challenges, we propose a training framework based on contrastive learning [
30,
31]. We adopt NT-Xent loss [
31] as our objective functions for model training to address the aforementioned challenges. The NT-Xent loss function supports larger sample sizes for model training, which mitigates slow convergence optimization-less problems caused by local limited positive/negative samples. We also propose a block augmentation model to generate high-quality samples for training effectiveness improvements.
In summary, we have made the following contributions:
We propose a novel fine-grained BCSD approach based on NLP technique for basic block matching, namely BlockMatch. It first uses an NLP model to capture position relations and contextual semantics for instruction sequence encoding. Then, we use a mean pooling layer to generate basic block embeddings for binary code similarity detection. BlockMatch can be used to solve the last-mile problem of BCSD tasks regarding matching among basic blocks.
We propose a training framework based on contrastive learning resolving the small sample size training problem in BCSD tasks, which uses a block augmentation model to generate multiple contrastive positive/negative samples for model training and uses the NT-Xent loss objective function for parameter optimization.
We implement BlockMatch and evaluate it with extensive experiments. The experiments show that BlockMatch outperforms the state-of-the-art approaches PalmTree and SAFE. The Ablation study shows the NT-Xent loss benefit and that our model achieves better performance than the triplet loss.
2. Related Work
This section offers a concise overview of additional related work concerning binary code similarity detection.
Generally, BCSD is geared towards quantifying the similarity of two binary code snippets extracted from executable files. As outlined in the BCSD literature [
15,
32,
33], there are four types of binary code similarity, (1) literal identity, (2) syntactic equivalence, (3) functional equivalence, and (4) identical or logically similar source code. The current approaches [
10,
15,
17,
23,
25,
29,
34,
35,
36,
37] are focused on the fourth type to identify whether given binary code snippets are from the same or logic similar source code.
Significant research has been conducted in the field of binary code similarity detection. Traditional approaches, such as those proposed by Luo et al. [
1], Ming et al. [
2], Myles et al. [
38], Jang et al. [
39], and Pewny et al. [
22], utilize statistical, syntax, and structural features to identify similar binary code fragments. However, these approaches require extensive expertise and knowledge to effectively select features and assign appropriate weights for BCSD tasks. DiscovRE [
40], Genius [
26], and GitZ [
19] employ features that are robust to small changes derived from statistical, syntactic, and structural analysis to calculate binary code similarity. Trex [
24] introduces a transformer-based model that utilizes micro-traces comprising instructions and dynamic values to capture function execution semantics for BCSD tasks. Drawing inspiration from NLP techniques, many researchers [
10,
13,
15,
23,
37,
41,
42] introduce language models to automatically extract semantic features of binary code for BCSD tasks. For example, Ding et al. [
15] propose Asm2Vec using the Distributed Memory Model of Paragraph Vectors (PV-DM) model [
43] to represent binary functions as high-dimensional numerical embeddings to detect similar binary code. PalmTree [
23] applies a transformer-based NLP model, BERT [
44], for assembly instructions to measure similarity of binary code. Wang et al. [
13] propose a transformer-based approach, named jTrans, to capture CFG structures using jump-aware representation for binary code similarity detection. These approaches are mainly working for functions of binary files. However, matching corresponding code snippets/basic blocks in two similar functions still requires a significant amount of effort, considering the complexity of their CFGs and the abundance of basic blocks involved. Thus, a fine-grained BCSD approach at basic block level becomes urgent to solve the last-mile problem of BCSD tasks regarding matching among numerous basic blocks.
Basic block similarity matching, as a fine-grained BCSD scenario, is more specific in identifying which basic blocks are similar compared to a function-level BCSD scenarios. At the same time, it also faces a larger number of matching samples. Current approaches represent binary code as high-dimensional embeddings on a hyper-sphere, facilitating the search for similar binary code based on cosine distance. Consequently, the primary training objective is to minimize the distance between embeddings of similar binary code while maximizing the distance between embeddings of dissimilar binary code. The existing approaches [
13,
29] utilize Triplet Loss [
28] to optimize the parameters of models based on triplet samples (i.e., anchor sample, positive sample, and negative sample). The quality of these samples profoundly affect the effectiveness of model training. However, BCSD at the basic blocks is a multi-class problem with thousands (or even more) of different basic blocks, and the different basic blocks are not completely different from each other, which makes it difficult to select representative samples to compute triplet loss for optimization. SimCLR [
31] proposes a NT-Xent loss for the large-batch contrastive learning of visual representations and shows high performance for multi-class prediction in image classification. It support multiple negative samples and positive samples to calculate training loss, avoiding bias from local samples.
Compared with the above approaches, our proposed
BlockMatch is a fine-grained approach for BCSD tasks at the basic block level, which uses an NLP model based on DeBERTa [
45] to automatically capture position relations and contextual semantics for basic block embeddings. Considering the thousands of different basic blocks, we propose a contrastive training framework for BCSD tasks. It first uses a basic block augmentation model to generate multiple high-quality samples, and then adopts NT-Xent loss [
31] as our objective functions to train our model with large-sized samples, allowing it to converge faster and achieve superior performance in BCSD tasks.
3. Design
To mitigate the problems discussed in
Section 1, we propose a novel Binary Code Similarity Detection (BCSD) approach called
BlockMatch to solve the last-mile problem of BCSD tasks regarding matching among basic blocks.
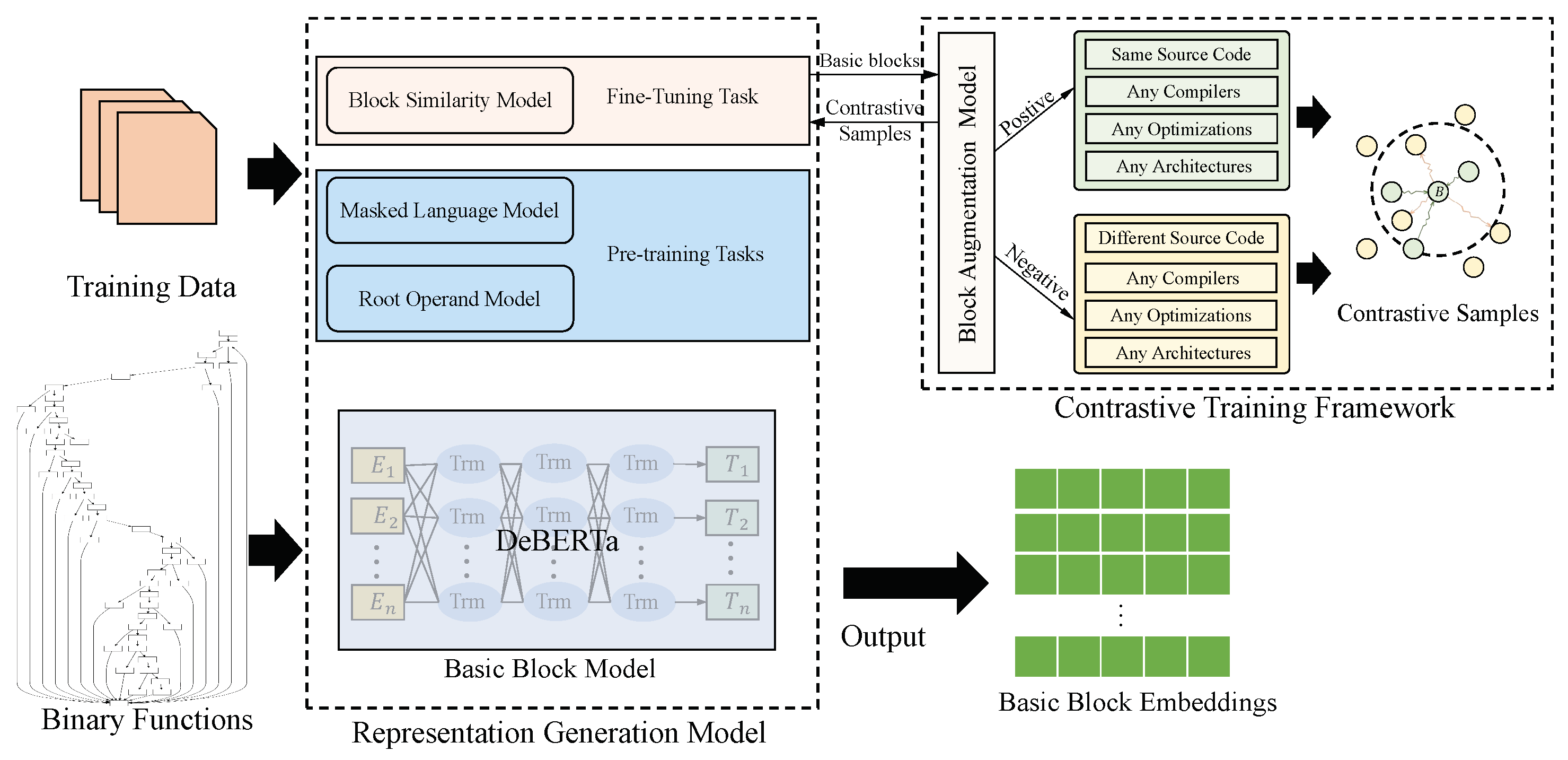
Figure 3 illustrates the overall architecture of
BlockMatch, encompassing two key modules that enable its functionality:
Representation Generation Model. This module is responsible for generating embeddings for each basic block present in the input functions. Initially, we extract basic blocks from the input functions and employ disassembly tools to convert machine code into instruction sequences for each basic block. Subsequently, we utilize a basic block model based on DeBEATa [
45] to capture the semantics of these basic blocks, thereby producing corresponding embeddings. To train our model, we employ a masked language model and a novel root operand model for pre-training. We then use a block similarity model to fine-tune our model, ensuring that similar basic block embeddings are closer together.
Contrastive Training Framework. This module aims to generate diverse and high-quality samples for training the model, employing the NT-Xent loss objective function [
31] to optimize the model parameters. During the training phase, given training basic blocks, we propose a block augmentation model to generate positive samples and negative samples based on their metadata. Specifically, for positive samples, the block augmentation model generates basic blocks originating from the same source code lines, but compiled using different compilers, architectures, and optimizations compared to the anchor basic block. Conversely, for negative samples, the block augmentation model generates basic blocks with different I/O emulation results from different source code lines in relation to the anchor function. Subsequently, we utilize the NT-Xent loss objective function to optimize the representation generation model by considering their block similarities between large-batch samples.
3.1. Representation Generation Model
The representation generation model aims to generate basic block embeddings that capture relative positions, contextual information, and instruction semantics. To accomplish this, we consider basic blocks as language sentences, where their instructions are treated as words within these sentences. We leverage a customized transformer-based language model with disentangled attention [
45] to capture these features and construct comprehensive representations for BCSD tasks.
The first step in the process is raw feature extraction. We extract the basic blocks from the provided binaries and employ IDA Pro [
46], a disassembly tool, to convert machine code into microcode instruction sequences for these basic blocks. It is worth noting that alternative disassembly tools and intermediate representations also work.
3.1.1. Basic Block Model
To automatically generate semantic features for each basic block, we employ a basic block model based on DeBEATa [
45] to capture the semantics of the instruction sequences in basic blocks. DeBERTa [
45] is a member of the BERT family [
44] and distinguishes itself from the conventional BERT model by employing disentangled attentions within each transformer encoder layer. Compared with BERT [
44] and RoBERTa [
47], DeBERTa utilizes disentangled attentions to effectively capture both the relative relations between positions and the content being analyzed, which helps our model better understand the connections between instructions in the basic blocks.
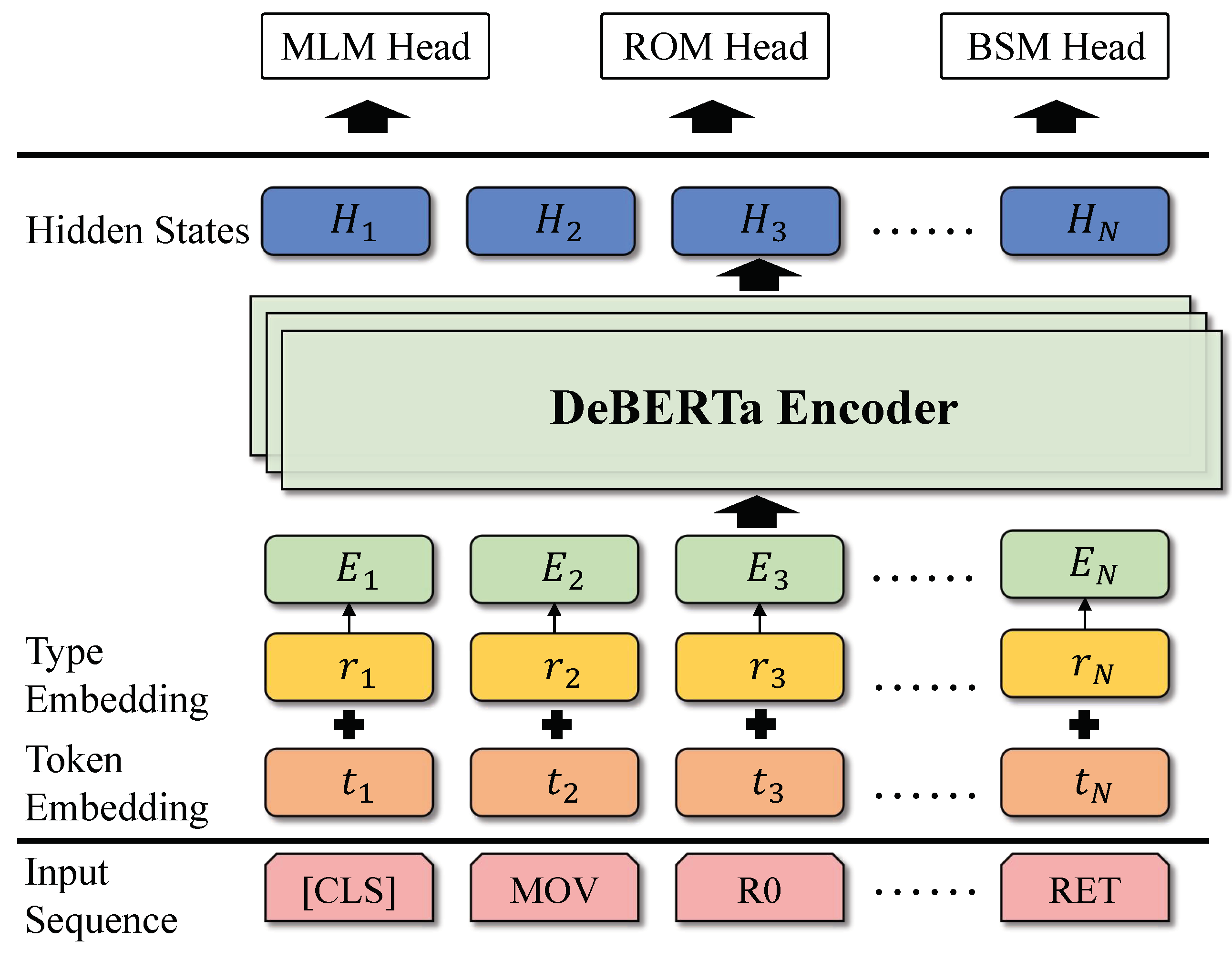
Figure 4 illustrates the architecture of our basic block model, which is composed of stacked DeBERTa encoders to build embeddings. For each input sequence, we consider it as a language sentence and tokenize it into token objects. These tokens are then mapped to corresponding token embeddings. Subsequently, we feed these token embeddings into the stack of the DeBERTa encoder to generate hidden states, with the last hidden states representing the instruction semantics. Finally, we use a mean pooling on the last hidden states to generate the embedding of the basic blocks. During training, we feed the last hidden states into various training task heads to optimize our model.
3.1.2. Pre-Training Tasks
To facilitate the large-scale training of our model, we employ two self-supervised pre-training tasks: the Masked Language Model (MLM) [
44] and the Root Operand Model (ROM).
Masked Language Model. The MLM task involves completing fill-in-the-blank tasks, enabling the model to learn how to predict masked tokens based on the surrounding context tokens. By performing the MLM task, the model gains a deeper understanding of the relations between instructions and positions. In MLM training, given a token sequence
, 15% of the tokens in each input sequence are randomly masked. Among the masked tokens, 80% of them are replaced with a special
[MASK] token, 10% of them are replaced with other tokens, and the remaining 10% remain unchanged. This is carried out to create a masked sequence denoted as
. We then input
into the basic block model and feed the output into an MLM head to reconstruct
by predicting the masked tokens
conditioned on
. The loss function for the MLM task is defined as follows:
Here,
and
correspond to the parameters of the basic block model and the MLM head, respectively. The pre-training task is considered complete when the training loss decreases to a stable interval, indicating convergence.
Root Operand Model. The ROM task aims at summarizing the root semantics of each operand, allowing the model to mitigate missing semantics for Out-of-Vocabulary words. OOV words are those that are absent from the language model’s vocabulary. These are the words that are unknown to the model and bring challenges to semantic extraction. Through the ROM task, we enable the model to comprehend the intrinsic semantics of operands. When dealing with OOV operands, the model replace OOV operands with their root operands rather than completely losing their semantics. In ROM training, given a token sequence
, we generate its root operand sequence denoted as
. We then input
into the basic block model and feed the output into an ROM head to predict their root operand
. The loss function for the ROM task is defined as follows:
Here,
and
correspond to the parameters of the basic block model and the ROM head, respectively. The pre-training task is considered complete when the training loss decreases to a stable interval, indicating convergence.
The pre-training loss function of the block semantic model is the combination of loss functions:
3.2. Contrastive Training Framework
To fine-tune our basic block model, we propose a contrastive training framework, which is to generate diverse and high-quality samples for large-batch training. We first utilize the block augmentation model to generate diverse and high-quality positive samples and negative samples, and then construct large contrastive batches for the fine-tuning task Block Similarity Model (BSM) using the NT-Xent loss objective function to optimize the model parameters, ensuring that similar basic block embeddings are closer together.
3.2.1. Block Augmentation Model
To automatically generate diverse samples for given basic blocks, we use a block augmentation model to randomly construct similar basic blocks and dissimilar basic blocks. We first label our similar basic blocks and dissimilar basic blocks, and then perform block augmentation on the given anchor samples to generate their training samples.
Similar Basic Block Labeling. In binary files, basic blocks do not have names (like function names) to indicate whether or not two basic blocks are similar. Manual labeling basic block similarities requires a significant amount of time and effort, so we propose a method based on Debugging with Attributed Record Formats (DWARF) information for automatically labeling basic block similarities. DWARF is a debugging file format used by many compilers and debuggers to support source-level debugging [
48], designed to describe compiled procedural languages such as
C and
C++. The DWARF provides information to indicate the source files and lines of basic blocks, which helps us to identify the basic block similarity. As shown in
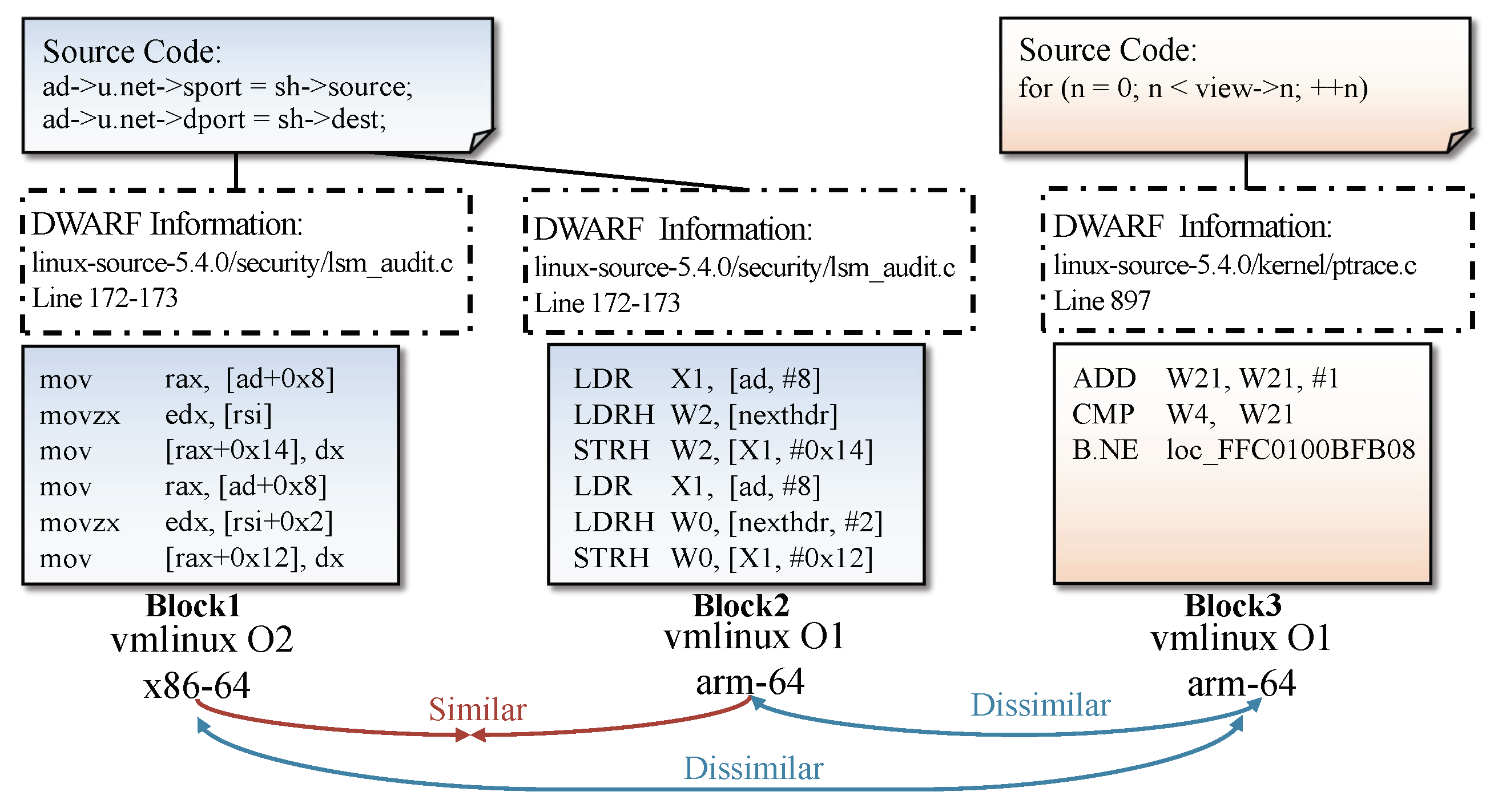
Figure 5, the basic block
Block1 is from the binary
vmlinux compiled with optimization option
O2 on the
x86-64 architecture. Its DWARF information indicates
Block1 compiled from lines 172–173 of the source code file
lsm_audit.c. The basic block
Block2 shares the same source code lines with
Block1, so they are similar basic blocks with similar semantics.
Dissimilar Basic Block Labeling. One problem arises when dealing with dissimilar basic blocks: two basic blocks from different source code have a probability of being semantically similar. In other words, different source code lines are a necessary but not sufficient condition for dissimilar basic blocks. Incorrectly labeled data will poison the dataset and impact the accuracy of the trained model. To address this problem, we use strict rules to identify dissimilar basic block pairs. Given two basic blocks, we label them as dissimilar pairs if they come from different source codes and their I/O emulation results are different. We use
Unicorn, a multi-architecture CPU emulator framework, to emulate instructions of basic blocks. Given two basic blocks from the same architectures (e.g.,
Block2 and
Block3 in
Figure 5), we randomly generate their initial emulation environments (i.e., registers and stacks). For the same initial environments, the emulations of two blocks get different final environments, which indicates they have different operations on data, reflecting semantic differences in the binary code. Thus, we label
Block2 and
Block3 as dissimilar basic block pairs. Since
Block2 and
Block3 are dissimilar, considering the similarity between
Block1 and
Block2, it can be inferred that
Block1 and
Block3 are also dissimilar. One emulation result may be accidental equivalence, so we emulate blocks multiple times with different emulation environments.
Block Augmentation. We perform block augmentation on given anchor samples in the following four aspects: source code, compiler, optimization options, and architecture. Algorithm 1 shows the details of our block augmentation model.
| Algorithm 1: Block Augmentation Algorithm |
![Applsci 13 12751 i001]() |
To generate positive and negative samples for a given basic block B, we employ the function. The parameters of determine the quantity of positive and negative samples generated. When generating positive samples, our objective is to produce basic blocks that share the same semantics as basic block B, while exhibiting distinct instruction sequences. To this end, we maintain the source code lines without alteration (as shown in Line 5 of Algorithm 1), and introduce variations in the compiler, optimization techniques, and architecture employed, ensuring that the augmented basic block differs from the original basic block B. Consequently, the augmented basic blocks possess identical semantics to basic block B, but display different instructions. These augmented basic blocks pose challenges for the representation generation model, contributing significantly to the loss calculations during model training and resulting in accelerated convergence. When generating negative samples, we randomly pick basic blocks with distinct source code lines and I/O emulation results in comparison to the anchor basic block B. Subsequently, contrastive samples are constructed for model training.
3.2.2. Training Objective
The objective of the fine-tuning task Block Similarity Model (BSM) is to make similar basic block embeddings closer together. Here, we use the NT-Xent loss objective function to optimize the model parameters. Given a large batch of samples, we embed them into a hyper-sphere and use cosine distance to measure their similarity scores.
Figure 6 provides an illustrative example of large batch contrastive training. During the training phase, the objective is to maximize the cosine similarity scores between embeddings from similar function samples and simultaneously minimize the cosine similarity scores between embeddings from dissimilar function pairs. The batch is arranged in the order of the anchor sample, positive samples, and negative samples. We utilize the normalized temperature-scaled cross-entropy loss (NT-Xent) [
31] as the training objective to compute the loss.
Here,
and
are the numbers of positive and negative samples, respectively. The function
denotes the cosine similarity score calculation, while
is an indicator function that indicates 1 when its condition is true and 0 otherwise. In the NT-Xent loss function, the number of samples
N consists of one anchor sample,
positive samples, and
negative samples. In loss
, the numerator of the fraction computes the exponential of the similarities between different positive sample embeddings
and
. The denominator sums up the exponentials of the cosine similarities between positive sample embeddings
and negative sample embeddings
, where
k ranges from
to
N. The hyper-parameter
plays a crucial role in controlling the temperature to help the model learn from hard negatives. We compute the gradient based on the loss
and use the Adam optimizer to optimize the model parameters.
5. Discussion
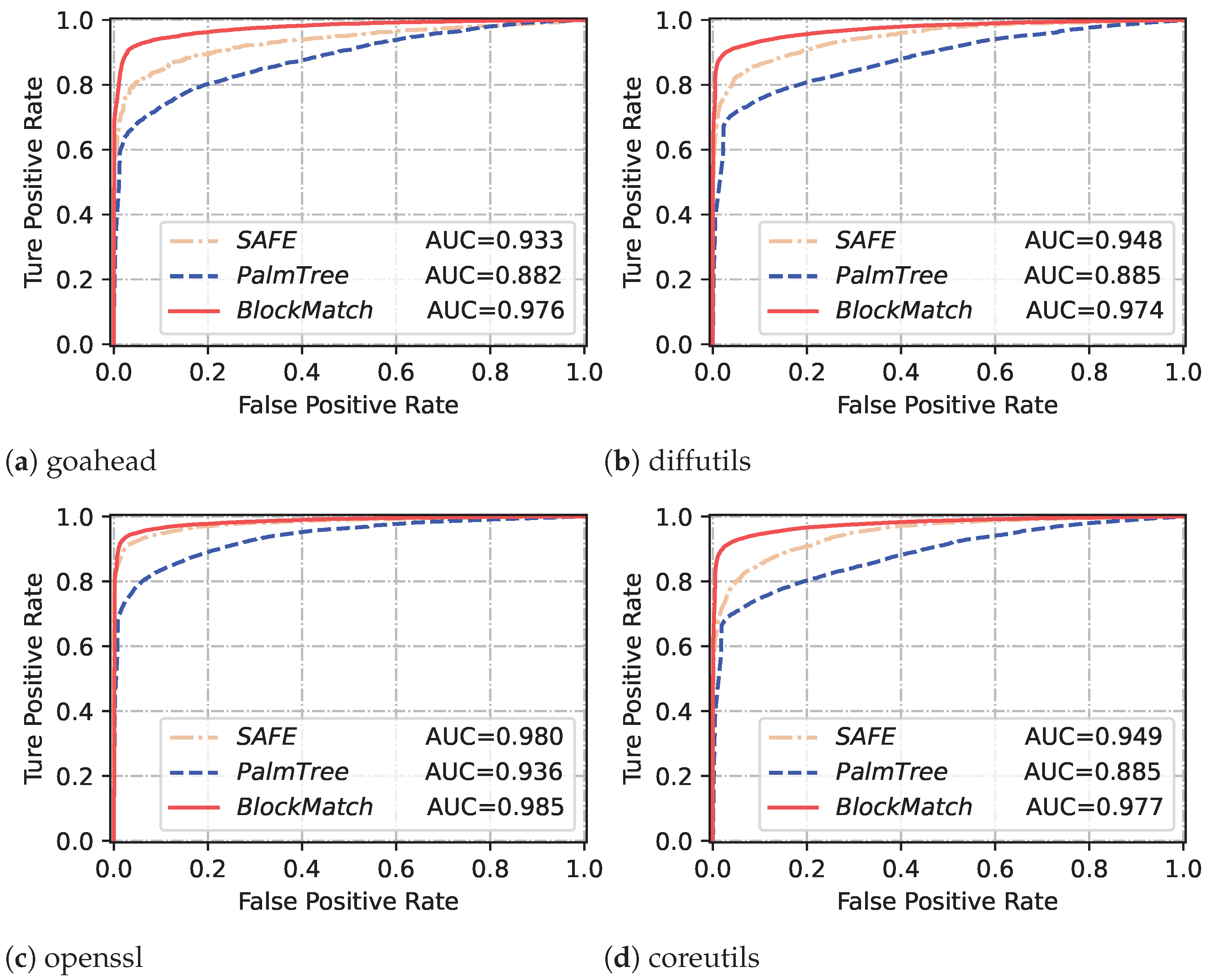
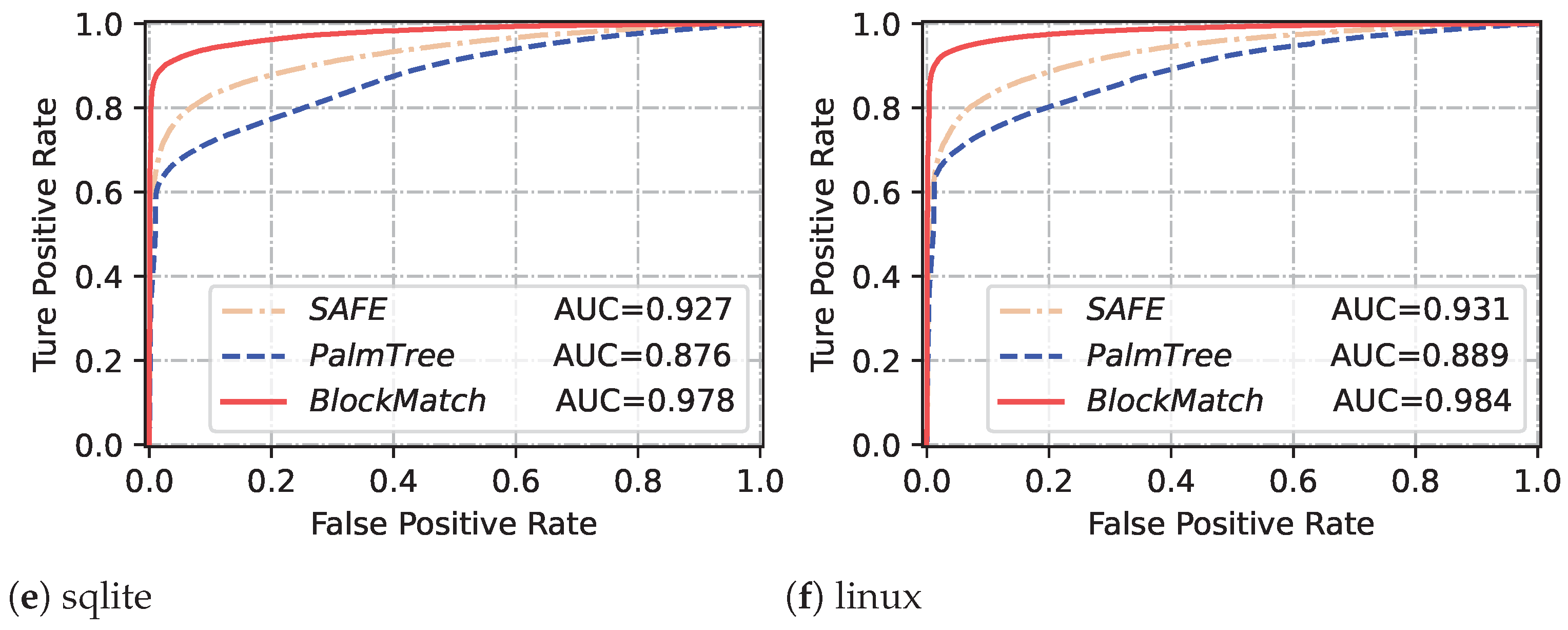
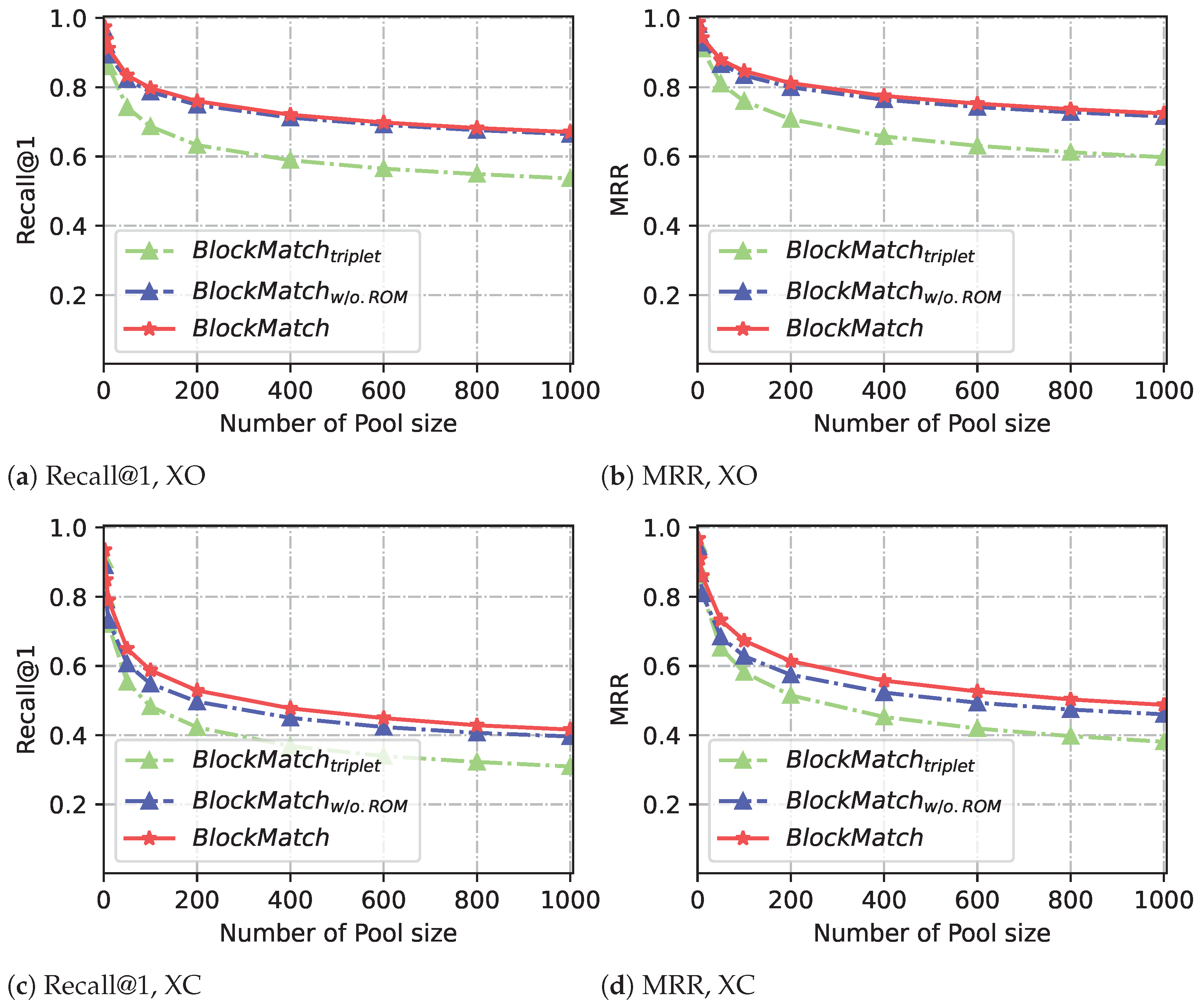
In this paper, we propose a novel fine-grained BCSD approach, named BlockMatch, using NLP techniques for basic block matching. The experiments show that BlockMatch outperforms the state-of-the-art methods PalmTree and SAFE. Here, we discuss the following questions:
Why does BlockMatch achieve good performance in basic block matching? The basic block matching in BCSD tasks belongs to fine-grained tasks. Compared with function-level BCSD methods, it specifically identifies which basic blocks are similar in binary files, while also facing a larger number of comparison examples. Experimental results have shown that the contrastive training framework plays a significant role in achieving high performance for
BlockMatch. The contrastive training framework leverages DWARF debug information to automatically generate a large number of high-quality contrastive samples, facilitating the fine-tuning of
BlockMatch, which enables
BlockMatch to converge faster and handle hard samples effectively.
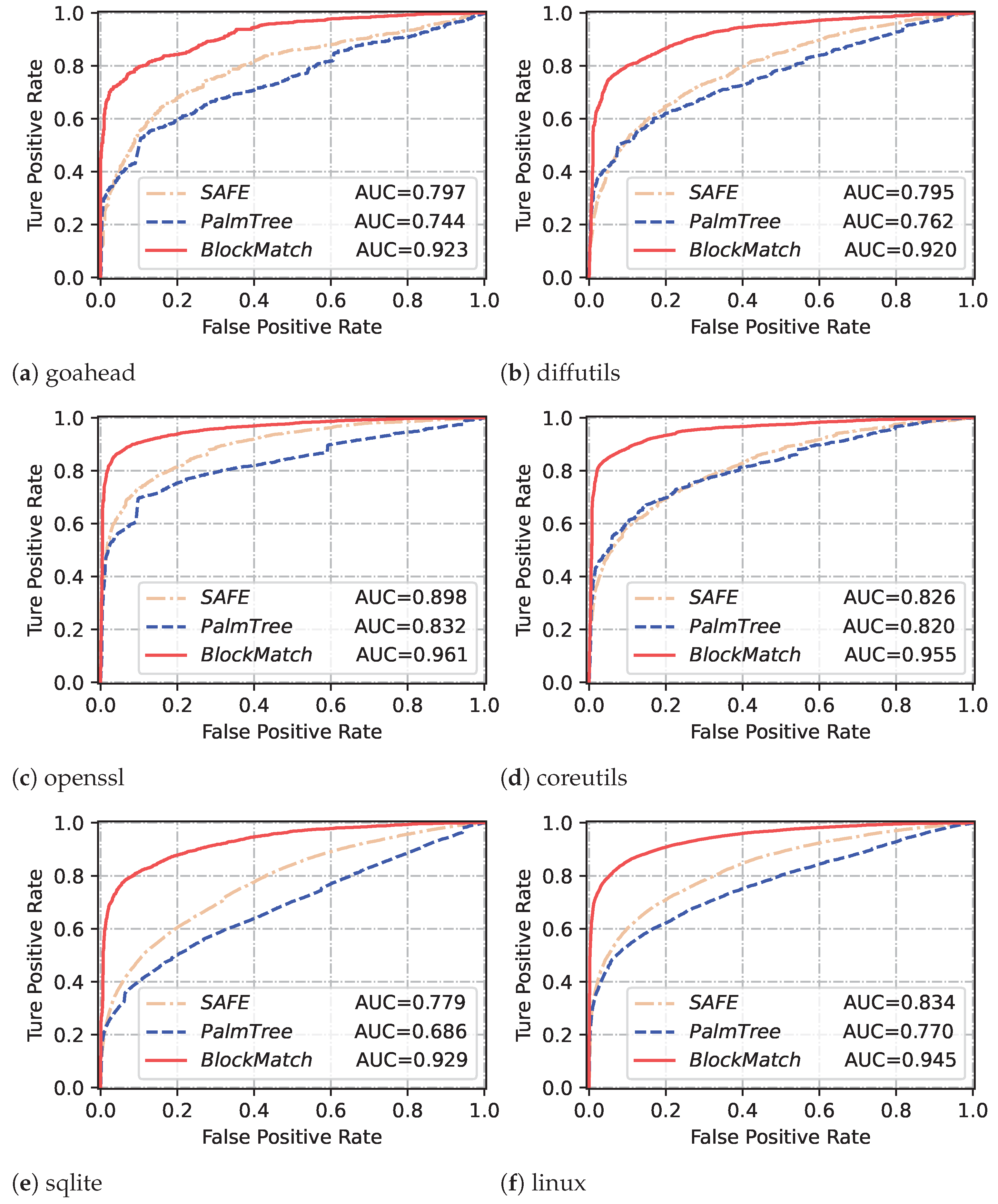
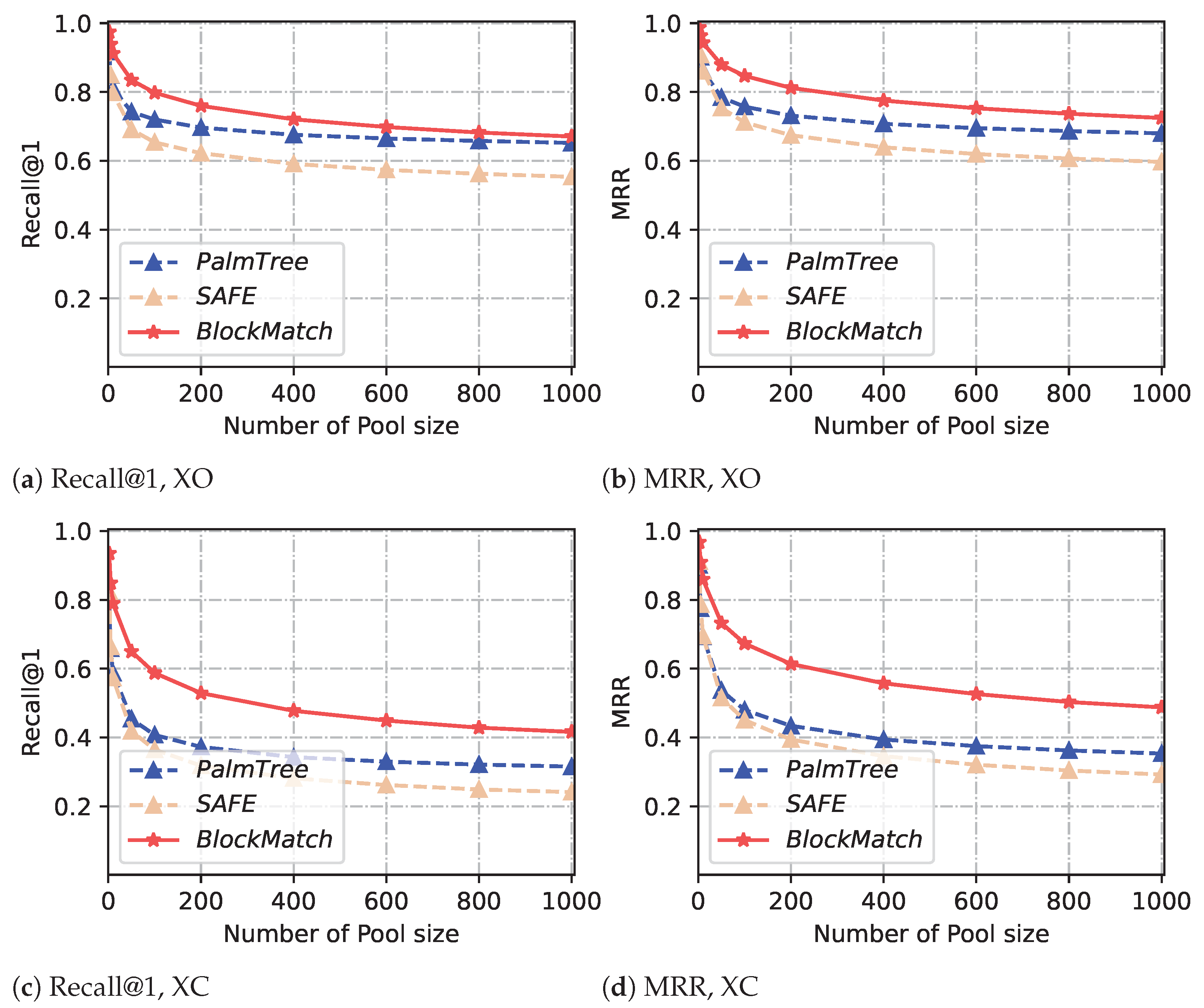
Table 5 shows the average results of
BlockMatch and other baselines, which demonstrates that
BlockMatch generally outperforms PalmTree and SAFE in basic block similarity detection. Comparative results against other baselines demonstrate that this improvement is particularly pronounced in cross-compiler scenarios. For example, in the cross-compilers experiment (pool size = 10),
BlockMatch achieves a recall@ of 0.790, while SAFE and PalmTree achieve recalls of 0.573 and 0.587, respectively.
Why does BlockMatch show a slight decrease in performance when used for cross-compiler basic block matching? Based on the results obtained from one-to-one and one-to-many basic block matching, it is evident that
BlockMatch demonstrates slightly lower performance in cross-compiler basic block matching compared to cross-optimization basic block matching. Actually, the same issue also occurs in other approaches like SAFE and PalmTree. Analyzing this issue will help us make further improvements to our approaches in the future. We compare binary snippets compiled by Clang and GCC using -O0 option without any compiler optimization intervention and differences in the preferred instructions they generate. For example, in binary files compiled with GCC, there are numerous
endbr64 instructions. These instructions are part of Intel’s Control-Flow Enforcement Technology, which provides protection against Return-oriented Programming (ROP) attacks. However, in binary files compiled with Clang, the frequency of the
endbr64 instruction is much lower. Similar issues have also been mentioned in other literature [
58]. When the differences exceed the tolerance threshold of the model, it leads to the misidentification of similar basic blocks by the model. Although using a contrastive training framework can partially mitigate this issue, it is still challenging to completely eliminate the impact of these differences. We notice that the control flow graphs remain relatively consistent across different compilers, so we can consider using graph node alignment based on control flow graphs in future work to help overcome this issue.
Can BlockMatch work for binary files from other architectures? In this paper, we primarily focus on evaluating the performance of BlockMatch and other baselines on the x86 architecture. Since our approach is architecture-agnostic, by training with binary files from other architectures, it can also be applied to other architectures. This is also a direction for our future research.

















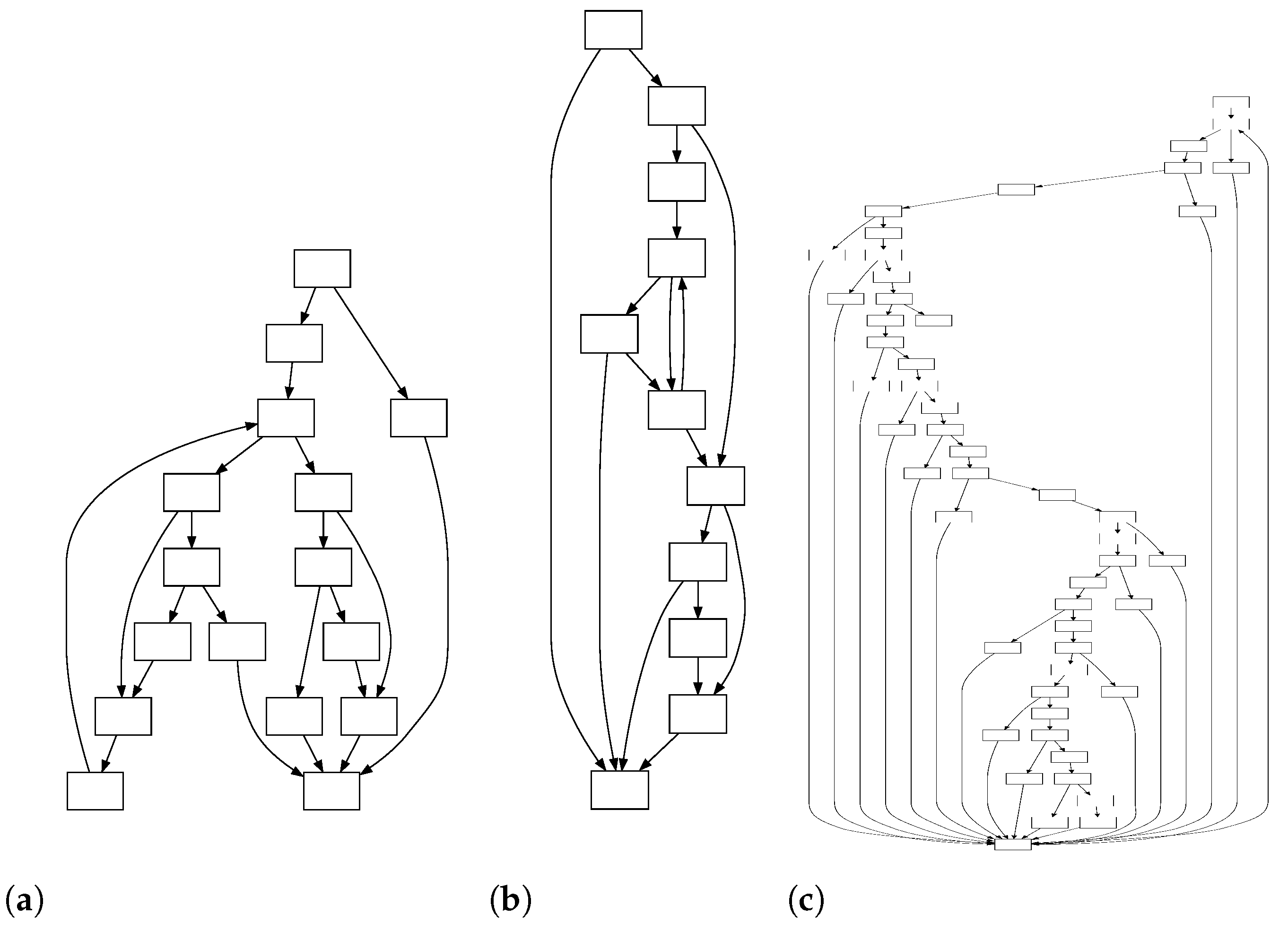{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}