1. Introduction
Online mobile services are evolving from traditional information searching and retrieval towards innovative artificial intelligence (AI)-based services. This transformative shift encompasses a spectrum of functionalities, including language translation, image recognition, autonomous driving, artificial intelligence of things (AIoT), and augmented reality/virtual reality [
1,
2]. The advent of these advanced services not only necessitates substantial computing power and data but also demands the swift delivery of results to end users. The prevalent cloud computing service paradigm has been instrumental in supporting computationally intensive services [
3,
4]. However, a common challenge arises due to the considerable distance between end users and cloud servers. Furthermore, the escalating volume of service requests contributes to heightened congestion levels in the backhaul network. Consequently, while the cloud computing service paradigm provides significant computing power and extensive storage to end users, it encounters challenges in meeting the service delay requirements of AI-based services [
5,
6]. In response to this challenge, the Multi-Access Edge Computing (MEC) system has emerged [
7,
8]. In the MEC system, a cluster of MEC servers (MECSs) strategically positions itself in proximity to end users. This strategic placement enables users to offload computing-intensive and delay-sensitive tasks to the nearest MECS. Subsequently, the MECS processes these tasks and transmits the results back to the users. By bringing servers into close proximity to users, the MEC system effectively mitigates service delays and alleviates the strain on the backhaul network.
In the realm of MEC system design, a pivotal challenge lies in the task offloading decision problem. Various task offloading methods have been proposed [
9,
10], generally falling into two primary categories. The first group involves users making intelligent offloading decisions, aiming to optimize service delay and the energy required for service completion [
11,
12]. Conversely, another research strand focuses on MEC system operators striving to optimize the utilization of computing and communication resources while ensuring users experience reasonable service delays [
13,
14]. However, these approaches often overlook the crucial aspect of service availability for the offloaded tasks. Essentially, they assume that services requested by tasks offloaded from users to the MECS are always available at the MECS. However, due to the inherent limitations of MECS in terms of computing power and storage compared to cloud servers, it can only accommodate a subset of the services available on cloud servers. Consequently, if MECS lacks the service requested by the offloaded task, it must fetch the service from the cloud server. Given that the installation and loading of services on MECS entail time, the effective management of service caching emerges as a critical factor in mitigating service delays within the MEC system.
Ensuring the inclusion of the most popular services in each MECS cache is important in achieving a higher cache hit rate. The popularity of services within MECS is intricately linked to the service preferences of users in the respective MECS service area. The dynamic nature of user mobility causes changes in the set of users within the MECS service area over time. Moreover, user service preferences evolve over time as well. Consequently, determining the optimal service set to be cached in a specific MECS within the MEC system presents a significant challenge. To address this challenge, popularity prediction methods have been proposed [
15,
16]. These methods delve into diverse metrics for each service, scrutinize their changing patterns, and extrapolate the future popularity of each service. By leveraging these identified patterns, they make estimates about the future popularity of each service. However, these methods primarily rely on the temporal relationships among services within individual MECS to forecast service popularity. Since users change locations over time, not only the users currently residing in the service area of a MECS but also the users served by the neighboring MECSs affect the future service popularity in the MECS. Consequently, integrating the spatial–temporal correlations between MECS enhances the accuracy of service popularity predictions. From an implementation standpoint, the number of predictors required in these popularity prediction methods escalates with the expansion of services and MECSs. Thus, concerns about scalability may surface as the MEC system grows.
In response to the identified challenges, we propose a proactive service caching methodology inspired by the Convolutional Long Short-Term Memory (ConvLSTM) model, recognized for its efficacy in video frame prediction [
17,
18]. Our approach seeks to exploit the inherent spatio-temporal relationships among service popularity within a MEC system. To operationalize the ConvLSTM model for this purpose, we discretize time into time slots and construct a heatmap that collectively depicts the distribution of service popularity in each MECS during a given time slot. Treating each heatmap in a time slot as a frame, we conceptualize the sequence of heatmaps as a video. Subsequently, we train a ConvLSTM model to predict the upcoming heatmap based on a few recent heatmaps. At the beginning of each time slot, we leverage the trained model to identify the most popular services from the predicted heatmap. These services are then selected to be cached on each MECS for the ensuing time slot. Utilizing a heatmap containing the popularity of each service across MECS as input enables us to comprehensively predict the popularity of all services in all MECS simultaneously. This holistic approach contributes to an enhanced service cache hit rate in each MECS. In addition, our methodology stands out by requiring only a single predictor model, as opposed to conventional methods necessitating separate prediction models for each service and MECS. This consolidation not only streamlines the predictive process but also significantly improves the scalability of a MEC system. Our main contributions can be summarized as follows.
We propose a framework for proactive service caching by taking a deep learning approach. Inspired by the ConvLSTM model that successfully predicts video frames by exploiting the hidden spatio-temporal relationships in the frames, we incorporate the ConvLSTM model as a fundamental element in our proactive service caching methodology.
We propose a procedure that utilizes ConvLSTM model for accurately predicting service popularity for each MECS over time. We construct heatmaps collectively representing the distribution of service popularity in a MEC system during each time slot. Treating each heatmap in a time slot as a frame, we conceptualize the sequence of heatmaps as a video. We predict the next heatmap by using the ConvLSTM model and identify the most popular services for the upcoming time slot from the predicted heatmap.
Through simulation studies using real-world datasets, we verify that our method outperforms conventional LSTM-based method in terms of the cache hit rate and the amount of model parameters required to predict service popularity in a MEC system.
The rest of the paper is organized as follows. In
Section 2, we discuss the related works. We explain the system model and formalize the problem in
Section 3. In
Section 4, we present our proactive caching strategy. In
Section 5, we verify the proposed method by comparing its performance with that of the conventional method through simulation studies using real-world datasets. We conclude the paper with future research directions in
Section 6. Before we proceed, in
Table 1, we present the notations used in this paper.
3. System Model
We consider a MEC system composed of
M MECSs and a remote server hosting a controller. We denote the set of MECSs in the system as
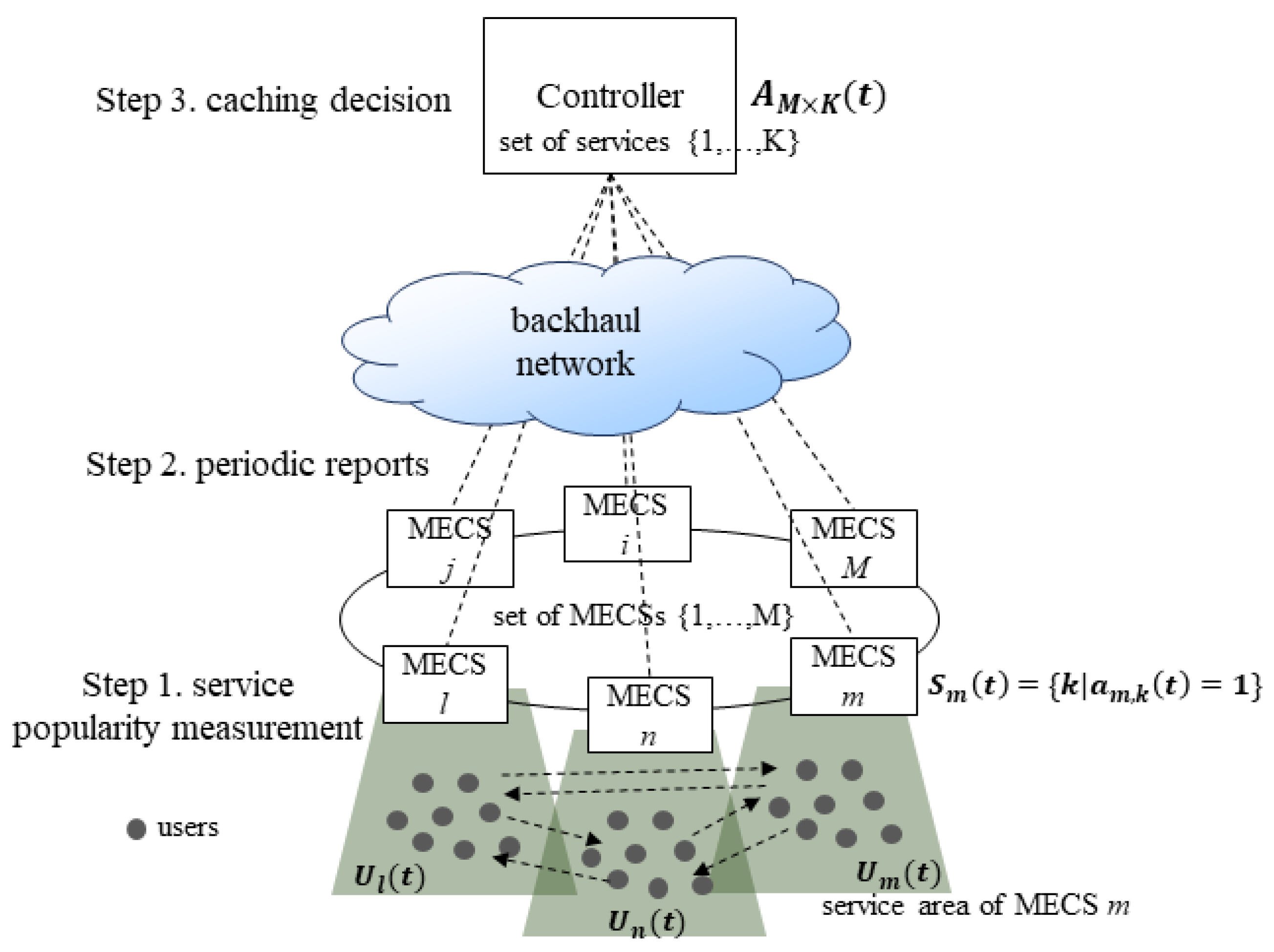
. We depict the system model in
Figure 2, which also shows the overall process flow. We assume that each MECS
is colocated with a base station, and a server is connected to all the MECSs through a backhaul network. Periodically, the controller collects the service popularity information from each MECS and makes a caching decision for all
. We denote the set of services that a MEC system provides as
and
, where
is the cardinarity of a set
. Each user asks for a service by offloading its tasks to the nearest MECS by using a wireless link between the user and the base station colocated with the MECS. If an user
u offloads its task to a MECS
m and the task is processed by
m, the MECS
m is called the serving MECS of a user
u. We consider a discrete time controller by dividing time into slots of length
.
A server can provide all the services in
while a MECS
m can serve a subset of
depending on its service cache size
and a caching decision made by a controller. We introduce a variable
to represent the service cache state of a MECS
m during a time slot
t. Specifically,
indicates that a MECS
m contains the service
k in its service cache during a time slot
t. Otherwise,
. Then, the service cache state of a MECS
m during a time slot
t is represented by the following service cache vector.
Accordingly, the service cache state of a MEC system during a time slot
t is represented by a
matrix
We denote the set of services in the service cache of a MECS
m during a time slot
t as
Our goal is to devise a controller that determines an optimal
(i.e., an optimal
) at the beginning of a time slot
t, so that the cache hit rate in a MEC system during the time slot is maximized. We denote the set of users in the service area of a MECS
m during a time slot
t as
. We introduce an indicator function
. When
, it represents the situation where a task offloaded from a user
u to a MECS
m during a time slot
t requests for a service
k. Otherwise,
. Then, our problem is formally stated as follows.
An optimal
is determined by the popularity of each service in each MECS during a time slot
t. In other words, if we know the popularity of each service within the service area of each MECS during a time slot, the optimal
, which we denote as
, can be determined by selecting the top
services with the highest popularity in each MECS
m. Then, the element
in the optimal
denoted by
is determined as
and the optimal
becomes
. If we denote the popularity of a service
k in a MECS
m during a time slot
t as
, it is determined by the service preference of the users in
, which is quantified as
. However, in terms of implementation, a controller cannot know
at the beginning of a time slot
t, which makes it difficult to find an optimal
at the beginning of each time slot.
To resolve these issues, we take a measurement-based approach inspired by a deep learning model for a sequence forecasting problem. The popularity of a service
k in a MECS
m is affected by
. User service preferences (
) vary in space and time because both
and the service preferences in
change in time and space. For example, the services used by users during daytime at the workplace differ from those utilized in the evening at home. Specifically, since a user can move from a MECS
n to its neighboring MECS
m during a time slot and vice versa,
is influenced not only by
,
, ..., but also by
,
, ..., where
. Therefore, the service popularity distribution in a MECS
m and that in MECS
n during a time slot exert mutual influence on each other. In other words,
is affected by the spatio-temporal correlation among the MECSs in terms of the set of users (
and
) and their service preferences (
and (
)). Therefore, we transform the problem in Equation (
5) into a spatio-temporal sequence forecasting problem as follows. We denote the service popularity matrix of a MEC system during a time slot
t as
matrix
, where
. Then, we convert the problem in Equation (
5) into finding an optimal
at the end of each time slot as follows.
where
is the number of the most recent service popularity matrix used for predicting
, and the notation
represents the probability of
X. Hereafter, we will call
as a window size. Once
is determined, the optimal service cache in each MECS
m is constructed by selecting the top
services with the highest popularity in
. To fast resolve the popularity prediction problem in Equation (
7) at the beginning of each time slot, we propose a deep learning approach, which will be detailed in
Section 4.
4. Proactive Service Caching Method
In
Figure 3, we show the overall procedure of our proactive service caching scheme. Our method is composed of two main modules. The first module is responsible for collectively representing the popularity distribution of each service within the MEC system. A controller periodically collects
from each MECS
and builds a
heatmap image to collectively represent the service popularity of each service in each MECS. The second module collectively determines the services to be cached by each MECS for the next time slot with the ConvLSTM model. In the second module, a controller takes the recent
consecutive heatmap images and predicts the next heatmap image. By using the estimated service popularity of each service in each MECS contained in the predicted heatmap image, a controller simultaneously determines the services to be cached by each MECS for the next time slot. We will detail the operation of each module in
Section 4.1 and
Section 4.2.
4.1. Collective Service Popularity Representation
When a sequence of video frames is given, the ConvLSTM model can predict the next frame. Specifically, the ConvLSTM model predicts the value of each pixel in the next frame by considering the spatio-temporal correlation in a set of past video frames. To take advantage of this feature of the ConvLSTM model, we construct a heatmap representing the service popularity distribution over a MEC system during a time slot and use it as an input to the ConvLSTM model. Specifically, each MECS
m maintains a set
during a time slot, where
. At the end of each time slot, a controller collects
from each MECS
. Then, a controller calculates
s for all
and
at the end of each time slot as follows.
By considering each as the -th pixel in the heatmap image, a controller constructs a grayscale heatmap image with the set of s.
Since each
in general, it is not suitable to directly use
s for training a ConvLSTM model. To enhance the model training performance, we normalize
s in each MECS
m as follows. At the end of each time slot, a controller derives the popularity of the most popular service in each MECS
m,
. Then, the controller normalizes
with
as
Then, a controller obtains a normalized service popularity vector for a MECS
m during a time slot
t as follows.
Therefore, at the end of a time slot
t, a controller constructs a heatmap image for a MEC system as follows.
4.2. Service Cache Decision
Given a sequence of s, we construct a training set and a validation set. We group a set of consecutive images as an input to the ConvLSTM model and use as a label for . Once a ConvLSTM model is trained, it predicts when is given. We denote the predicted as . For each MECS , a controller sorts the elements in in a descending order and makes a sorted set . We denote the sorted as , where .
Since the cache size of a MECS
m is
, a controller determines the services for
by selecting the most popular
services according to
. In other words,
is composed of the services whose predicted popularity is larger than or equal to
. We summarize the service cache decision algorithm in Algorithm 1.
| Algorithm 1 Service Cache Decision Algorithm |
- 1:
Initial State: - 2:
At the end of a time slot t: - 3:
Collect s from all . - 4:
Calculate in Equation ( 8), and . - 5:
Normalize s to make in Equation ( 10). - 6:
Construct a heatmap in Equation ( 11). - 7:
Build an input sequence . - 8:
Predict : = ConvLSTM (). - 9:
for do - 10:
Build by sorting in a descending order - 11:
- 12:
- 13:
while do - 14:
Get service id k corresponding to the i-th element of - 15:
- 16:
|
5. Performance Evaluation
In this section, we evaluate the performance of our method through simulation studies using real-world datasets. We compare our method with an LSTM method in terms of the service popularity prediction behavior and the cache hit rate. In the LSTM method, each MECS has an LSTM predictor that estimates the popularity of each service during the next time slot. After predicting the popularity of all services, the LSTM method determines
by choosing the top
services with the highest predicted popularity. We use the publicly known default values of the ConvLSM model and LSTM model for configuring their hyperparameters. Specifically, we use the hyperparameters in [
40] to configure the hyperparameters of the ConvLSTM model and employ the hyperparameters in [
41] to configure the LSTM model. We summarize the parameters used for each model in
Table 4. For our simulation study, we use a computer equipped with an Intel i9-10980XE CPU and four Nvidia GeForce RTX 3080. The size of the random access memory is 128 GB, and its operating system is Window 10. When we run the ConvLSTM model, we use Python version 3.8.3, TensorFlow 2.5.0, and TensorFlow-gpu 2.5.0. To run the LSTM model, we use Python 3.8.3, TensorFlow 2.10.0, and Tensorflow-gpu 2.10.0.
5.1. Simulation Setup
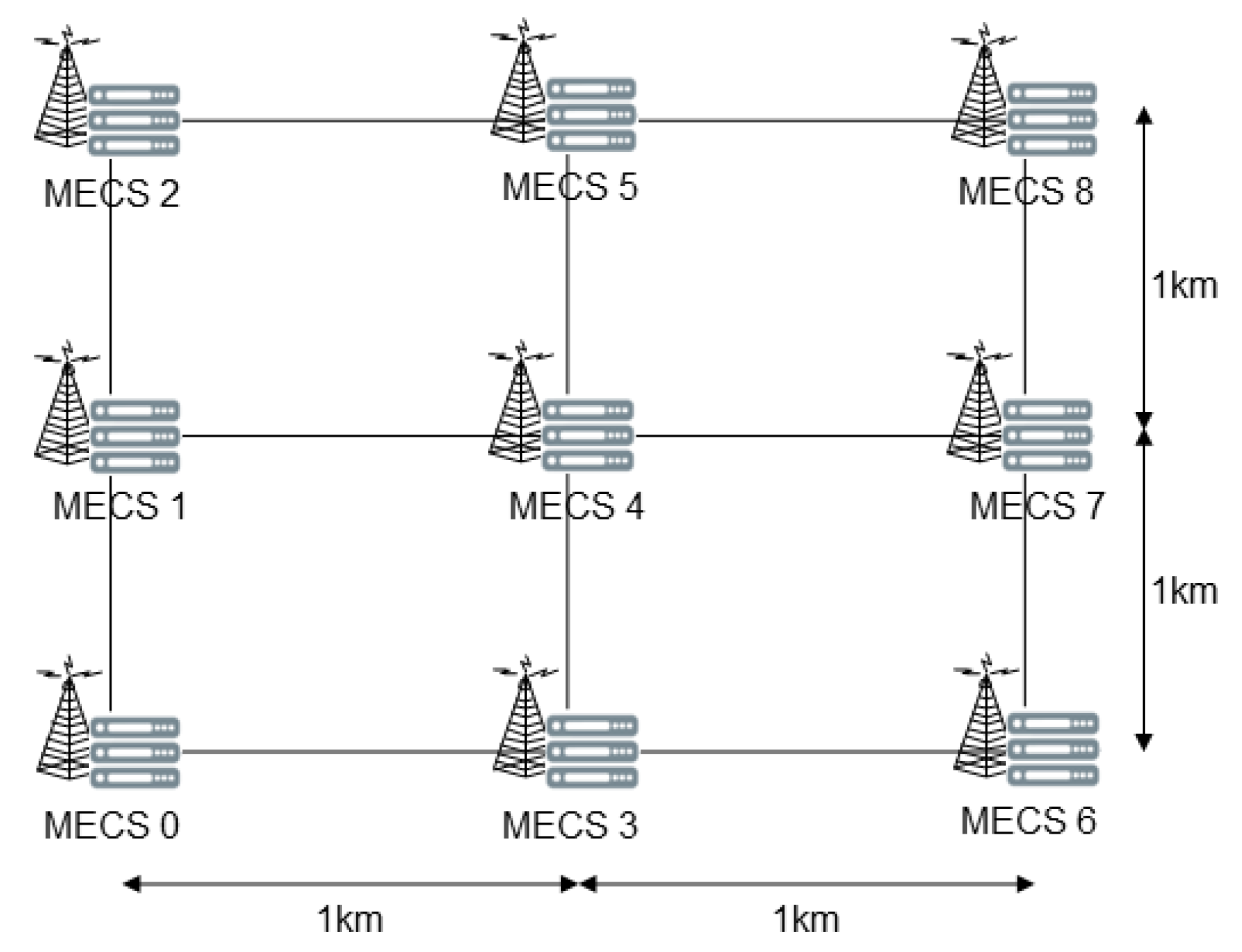
In
Figure 4, we show the topology of a MEC system we configured for simulation studies. We evenly deploy
MECSs in a
grid, which ranges from (0, 0) to (2 km, 2 km). We locate each MECS at each grid point. We set the number of services that a MEC system provides to 64 (
) and the cache size of each MECS to
.
To configure the popularity of each service in each MECS, we use the MovieLens 25 M dataset
measured from 1 January 2019 to 21 November 2019 by GroupLens Research [
42]. The dataset contains 1,202,602 ratings for 41,440 movies by 10,619 users. Assuming the patterns that the users rate the movies are similar to the patterns that they request for the MEC services, we configure the popularity of each service according to the popularity of movies in the dataset. Specifically, we define the popularity of a movie
i in
as
, where
is the number of times that a movie
i is rated in the dataset. We sort
in a descending order and investigate its distribution. We find that the popularity distribution follows the Pareto principle in that the top
popular movies take
of the total movies. Assuming that the popularity of a service in a MEC system will also follow the Pareto principle, we configure the popularity of a service
in a MECS
m by setting its popularity to that of the set of movies as follows. We denote the set of movies belonging to the top
popular movies as
. Without loss of generality, we assume that both the elements in
and those in
are sorted in a descending order according to
. We set
and divide the elements in
evenly into
subsets
. We also divide the elements in
evenly into
subsets
. To determine the popularity of each service in each MECS, we randomly assign a service identification number
to each subset
without duplication. Therefore, if a number
k is assigned to
, the popularity of the service
k in a MECS
m becomes
.
We denote the service popularity distribution in a MECS
m during a time slot
t as
. For each MECS
, we set
by randomly assigning a number
to each subset
without duplication. In other words, we set
if
. In the beginning of the simulation, we randomly deploy
U = 1000 users in the grid according to the Poisson point process and number them from 0 to 999. As time elapses,
changes because of the mobility of users in the MEC system. We set the mobility pattern of each user by using a real-world dataset. Specifically, we use the Divvy historical trip dataset, which records the trip start day and time, trip end day and time, trip start station, and trip end station [
43]. Among the historical trip data, we use the dataset
containing 767,650 trip history in Chicago during July 2023. We set the
x-th record in the dataset as the mobility pattern of the user
x U in the MEC system. Therefore, the service popularity distribution in the MEC system changes in time and space.
To configure the service request of each user in the MEC system, we use the records in
. For instance, let us consider the
a-th record in
, which says that a movie
is rated at time
c. If a MECS
m is the nearest MECS of a user
U and
k is assigned to
in the MECS
m, we set that the user
u requests the MECS
m for a service
k at time
c. Since there are average
U ratings during six hours in
, we set the duration of a time slot
to 6 h so that the average number of service requests by each user in the MEC system is one during a time slot. We set the window size
for both our method and the LSTM method. By using the datasets
and
, we measure
at the end of each time slot. We shuffle all
s and randomly select 90% of them as a training dataset and use the rest as a validation dataset. We use the last 10% of the total
s as a test dataset. We summarize the parameters used for the simulation study in
Table 5.
5.2. Prediction Accuracy
We denote the error involved in predicting the popularity of each service
k in a MECS
m during a time slot
t as
and compare the distribution of
for all
in different MECSs in
Figure 5. In this figure, we illustrate the results for four different cases based on the applied methods and MECSs. In each subfigure, the x-axis is the service index
and the y-axis is the prediction error. Thus, for each service
k, each subfigure shows the distribution of
in a MECS
m as a box plot. We observe in the figure that regardless of the true popularity of a service, the 75th percentile of
obtained by our method is smaller than that resulting from the LSTM method. For example, in MECS 4, the 75th percentile of
is 0.054 when our method is used, while it is 0.11 when the LSTM method is used. In addition, when the LSTM method is used, there are services whose median
s are much higher than those obtained by our method. For example, the
of the service
k = 33 in MECS 4 obtained by our method is 0.080, while it is 0.90 when the LSTM method is used. We also observe that the interquartile range (IQR), which is the difference between the 75th percentile and the 25th percentile, is smaller when our method is applied compared to when the LSTM method is used. For example, in MECS 4, the average IQR acquired by our method is 0.034, while it is 0.046 when the LSTM method is applied. The results are attributed to the manner that each method predicts the service popularity. When the LSTM method is used, each MECS predicts the popularity of each service within its service range, regardless of the service popularity distributions in the other MECSs. On the contrary, our method predicts the popularity of each service in each MECS at the same time by comprehensively considering the service popularity distributions all over the MECSs. Therefore, our method reduces the amount of error in predicting the popularity of each service in each MECS. We obtain the same results in all the other MECSs.
To investigate the influence of the service popularity prediction error on the service caching decision, we inspect the difference between the true
and the predicted
in each MECS
m. We note that the true
is composed of the top
popular services during a time slot
t, which can be known at the end of a time slot
t. On the contrary, the predicted
comprises the top
popular services whose popularities are estimated by a predictor at the beginning of a time slot
t. We denote the true
as
and the predicted
as
. To quantify the similarity between
and
, we calculate
and show the results in
Figure 6 with different
s. In the figure, we draw the ranges of the y-axis to be the same on purpose to make comparison easier. This figure has four subfigures. In each subfigure, the x-axis is a MECS index
m and the y-axis is
. Each subfigure shows the distribution of
in each MECS as a box plot.
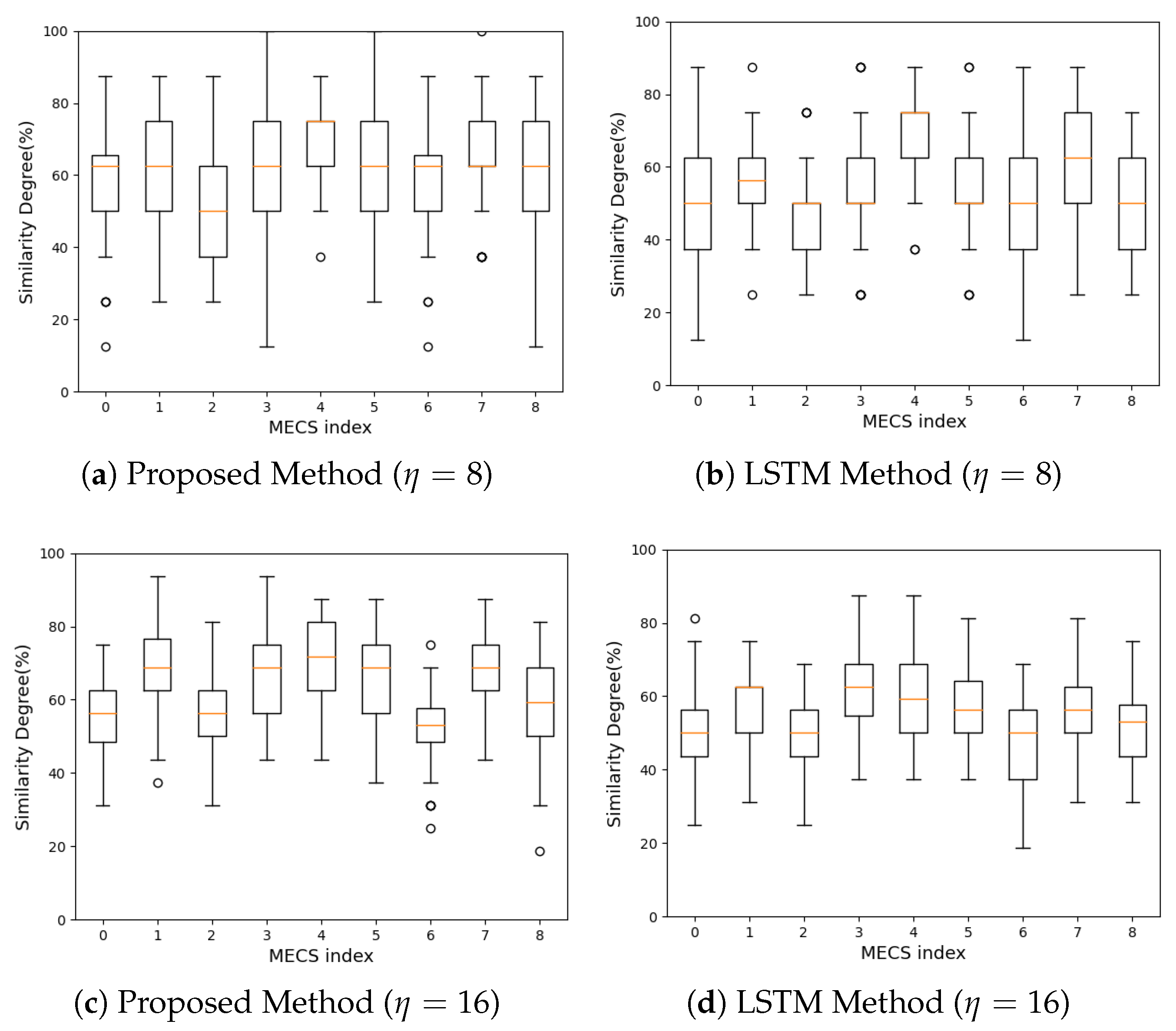
In
Figure 6, we observe that our method improves the similarity of the service cache regardless of the MECS position in the grid and the cache size. When
, compared with the LSTM model, our method achieves an
increase in the cache similarity. Specifically, the average
is
when the LSTM method is used. The average
increases to
when our method replaces the LSTM method. The standard deviation of
is
when our method is used, while it is
when the LSTM method is used. When
, the proposed method improves the average service cache similarity by
. When the LSTM method is used, the average
is
%. Our method increases the average
to
. The standard deviation of
is
when our method is used, and it is
when the LSTM method is used.
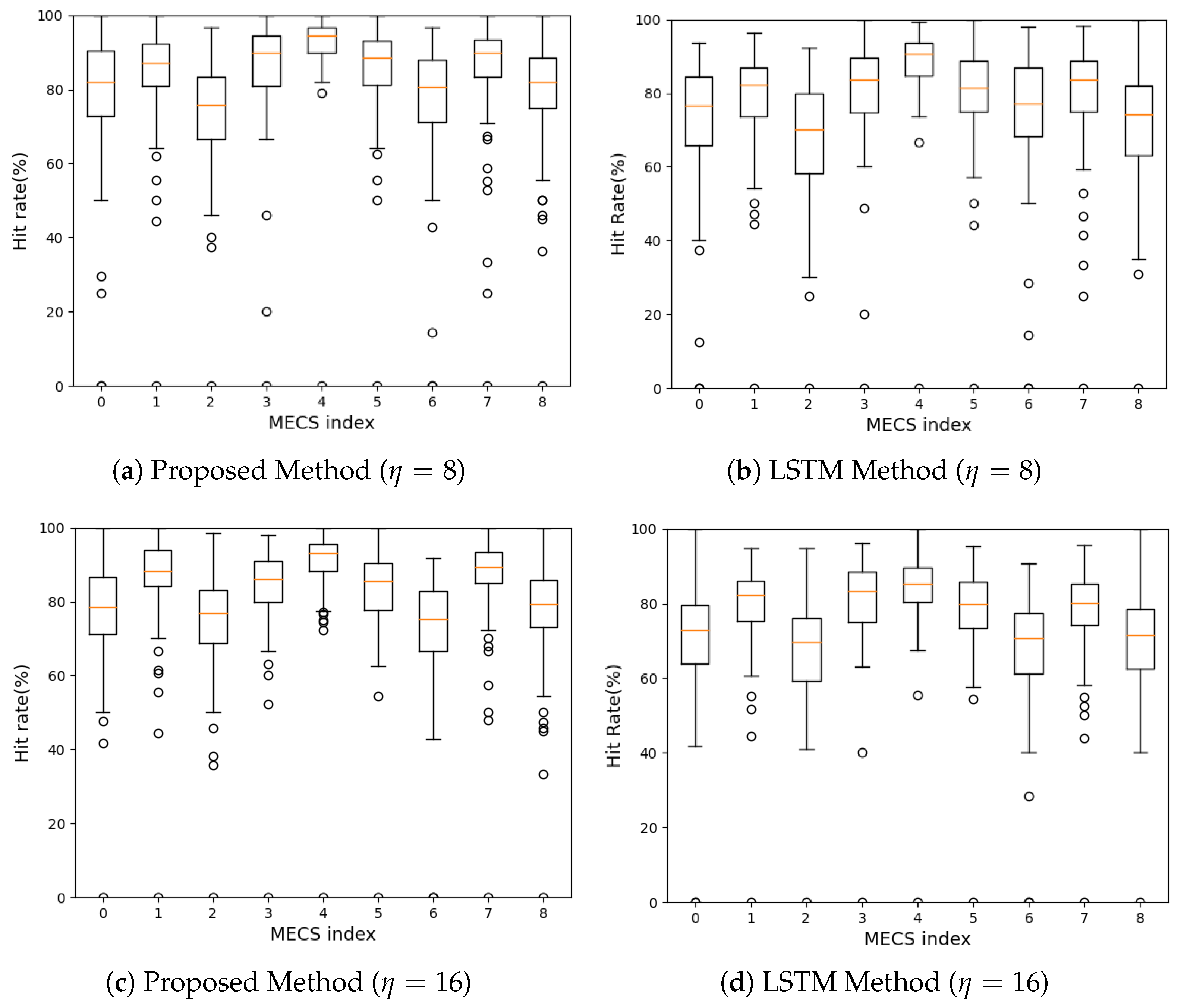
5.3. Hit Rate Comparison
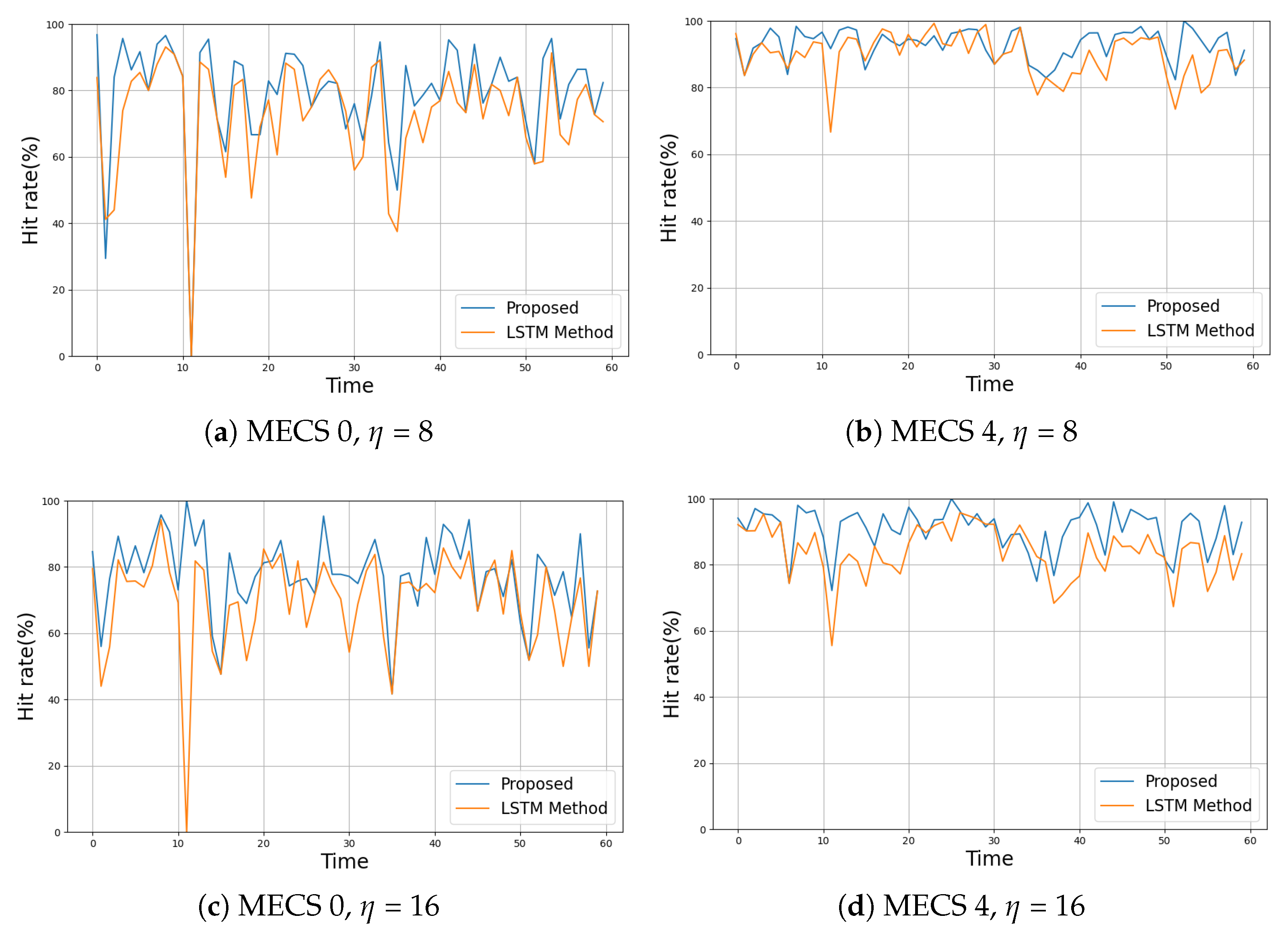
In
Figure 7, we show the variations of a cache hit rate in different MECSs with different cache sizes over time. To facilitate the comparison, the ranges of the y-axis in all subfigures are shown to be the same. We observe that the hit rates obtained by our method are higher than those acquired by the LSTM method, regardless of the MECS locations and
.
To further verify our method, we compare the distribution of a cache hit rate in each MECS. Specifically, for each MECS, we investigate the difference between the maximum cache hit rate that can be obtained when
is used and that acquired when
is used. We denote the cache hit rate when
is used as
. We also denote the cache hit rate obtained by a popularity prediction method as
. For each time slot, we calculate the relative hit rate
and show its distribution in
Figure 8. This figure has four subfigures. In each subfigure, the x-axis is a MECS index
m and the y-axis is
. Each subfigure shows the distribution of
in each MECS as a box plot.
In this figure, we observe that the proposed method outperforms the LSTM method in terms of in all MECSs and s. When , the average is 82.13% when our method is used, while it is 76.78% when the LSTM method is used. In other words, our method improves the average cache hit rate by 6.97%. In the case of , the proposed method enhances the average cache hit rate by 8.48%. The average is 81.08% when our method is used, while the average obtained by the LSTM method is 74.74%. We also observe that our method decreases the variance in the cache hit rate. When , the average IQR resulted by the proposed method is 14.19%, while the LSTM method produces an average IQR of 15.88%. In the case of , the proposed method achieves an average IQR of 11.76%, while it is 13.55% when the LSTM method is used. By decreasing the average IQR by more than 10%, our method makes the cache hit rate in a MEC system stabler than the LSTM method.
We also note that the proposed method needs only one ConvLSTM model to predict the popularity of each service in each MECS. On the contrary, since each MECS needs at least one LSTM model to predict the popularity of each service within only its service area, the LSTM method needs the
M LSTM model to predict the service popularity in a MEC system. As we show in
Table 4, we use a total of 746,689 parameters for the ConvLSTM model and 121,301 parameters for a single LSTM model. Since the LSTM method uses a total of
model parameters, the proposed method reduces the total model parameters by
. Therefore, when we consider these facts along with the results observed in
Figure 8 in an integrated manner, our method can achieve a higher cache hit rate with a smaller amount of model parameters compared to the LSTM method.
5.4. Caching Behavior
We also scrutinize the caching behavior of each method. Instead of predicting the exact order of the service popularity in each MECS, we aim to predict a set of
services whose popularity is relatively higher than those of the rest of the services. To quantify the service caching behavior, for each time slot, we calculate
and
and plot them in
Figure 9 for different
m and
.
We observe that both our method and the LSTM method are conservative in that they do not change the elements in the service cache abruptly. In addition, we observe that the changing pattern of is more similar to that of when the LSTM method is used compared to when our method is used. This difference in the caching behavior comes from the manner that each method predicts the service popularity. The LSTM method uses only the history of when it predicts without considering the history of s . On the contrary, when our method predicts the service popularity, our method collectively considers not only the temporal correlation but also the spatial correlation. Consequently, compared with the LSTM method, our method responds less sensitively to the instant changes in the service popularity at a single MECS.
5.5. Effect of User Mobility
To inspect the effect of user mobility on the service cache performance, we conducted the same simulation but with a change in the user mobility model from the previous one to a random mobility model, while maintaining the same experimental environment. In a random mobility model, a user changes its moving direction from and speed from at each time slot according to the Uniform random distribution. Considering the size of the simulation topology, we conduct simulations for the cases where the is 0.2 km and 0.5 km.
In
Figure 10, we show the distribution of the relative cache hit rate
with different
when the cache size is
. In this figure, we observe that the cache hit rate decreases as
increases. This is attributed to the fact that the increased mobility speed leads to a larger change in the service popularity distribution across each MECS. As a result, the popularity prediction accuracy decreases. In this figure, we also observe that for all the moving speeds, the median
at all MECS is higher when using the proposed method compared to using the LSTM method. When
km, the average cache hit rate rate across all MECS (
) is 85.32% when using the proposed method, while it is 80.88% when using the LSTM method. When
km, the average
obtained through the proposed method is 80.92%, while the average
is 74.79% when the LSTM method is used.
5.6. Effect of Service Popularity Variation
To assess the impact of the degree of service popularity change at each MECS on the caching performance, we conduct the following simulations. We extend the topology by deploying MECSs in a grid, which ranges from (0,0) to (3 km,3 km). We locate each MECS at each grid point. We also increase the number of services from 64 to 128 and set to 16. For each service k and each MECS m, we randomly change the popularity of a service k at a MECS m at each time slot. To control the degree of service popularity change at each MECS, at the beginning of each time slot, we randomly configure (), where is determined with a probability of to be either 1 or −1. We randomly select from according to the Uniform distribution.
In
Figure 11, we show the distribution of the cache similarity degree (
) with different
. We oberve that as the degree of service popularity change at each MECS (i.e.,
) increases, the cache similarity degree decreases. In the case of the proposed method, the average
is 98.47% when
, while is is 96.19% when
. We also observe in this figure that the proposed method outperforms the LSTM method. For all MECSs and
s, the cache similarity degree is higher when using the proposed method than when using the LSTM method.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}