
Event Knowledge Graph: A Review Based on Scientometric Analysis

Abstract
:1. Introduction
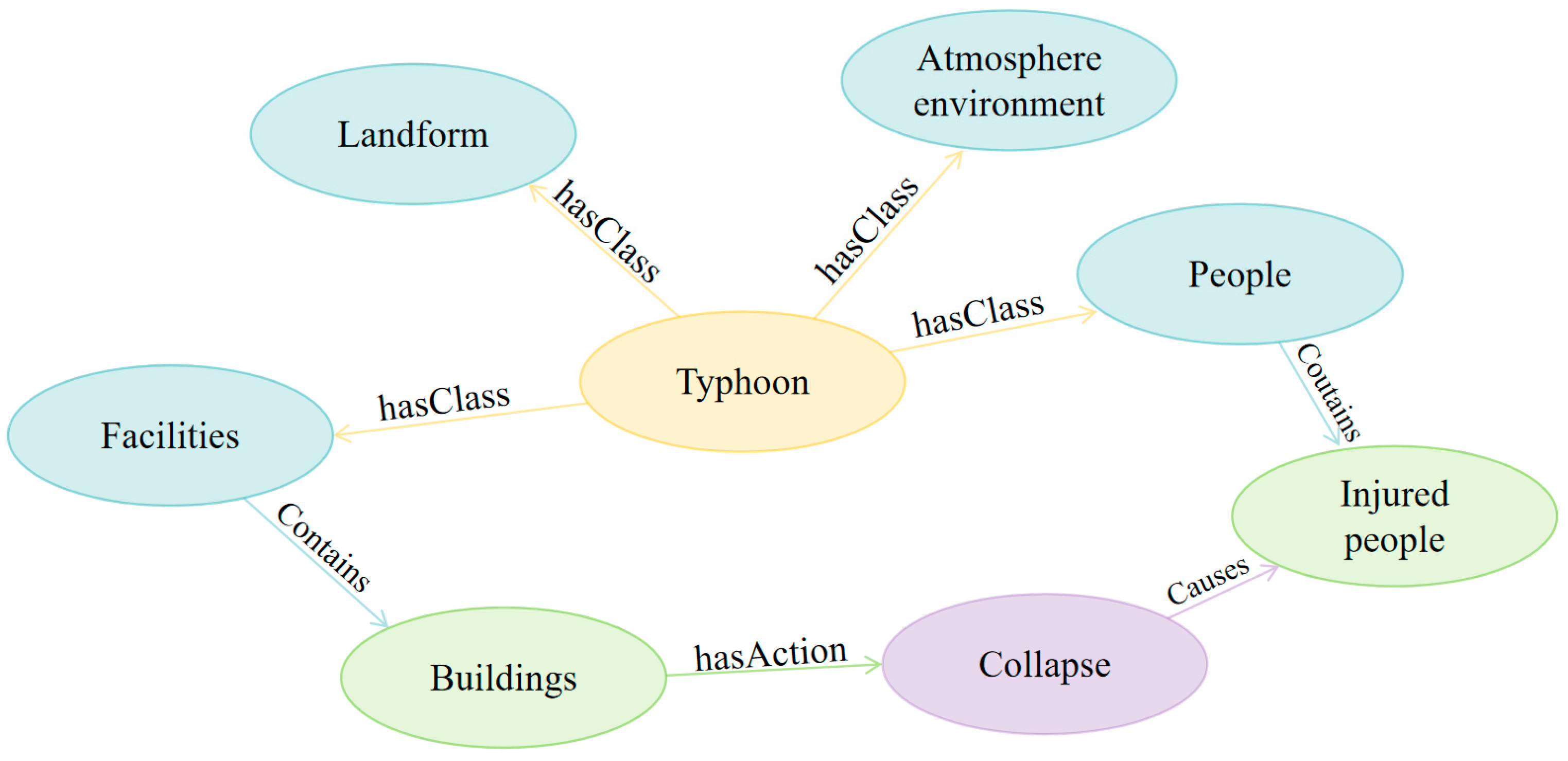
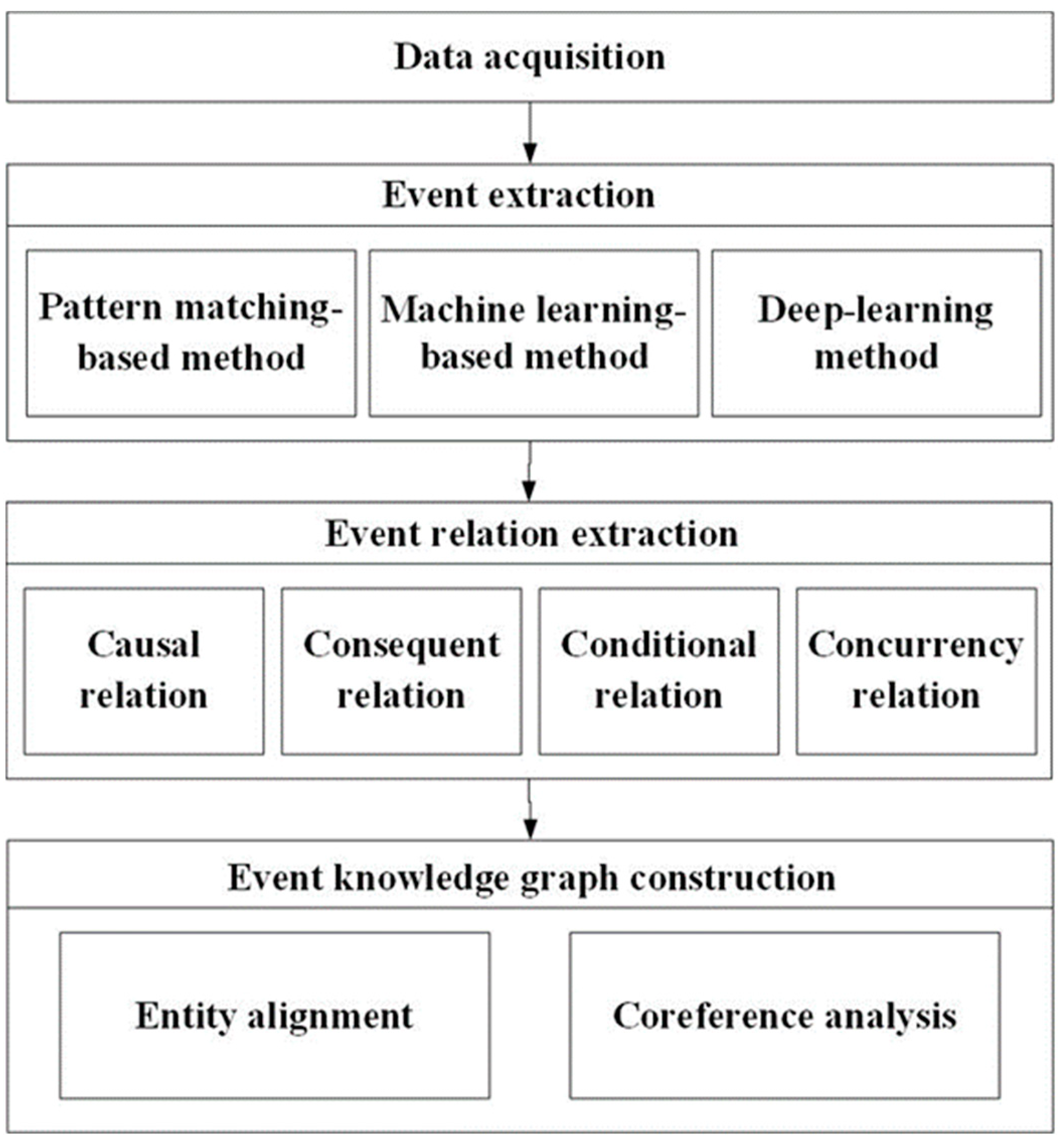
2. Background Knowledge
2.1. Data Acquisition
2.2. Event Extraction
2.3. Event Relation Extraction
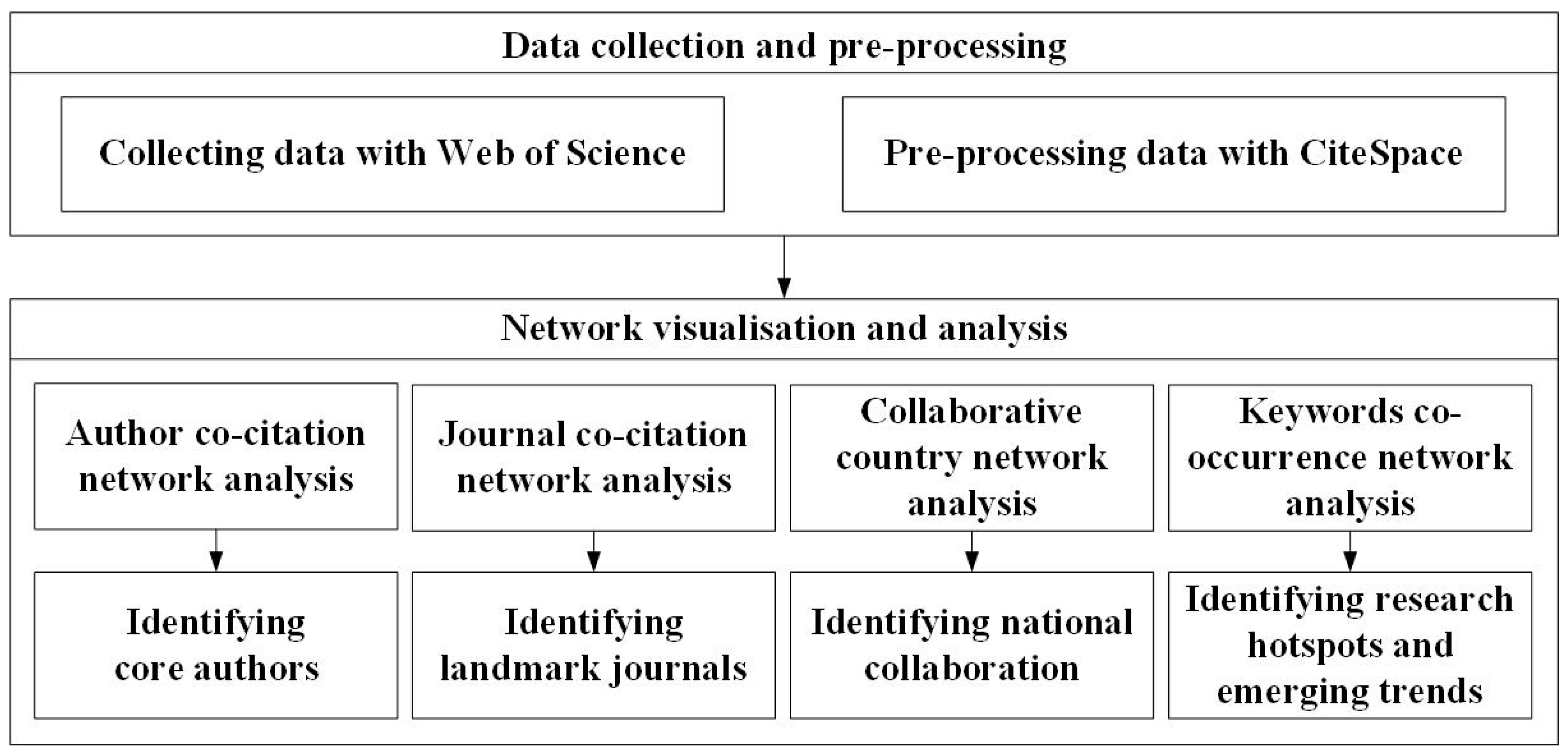
3. Methodology
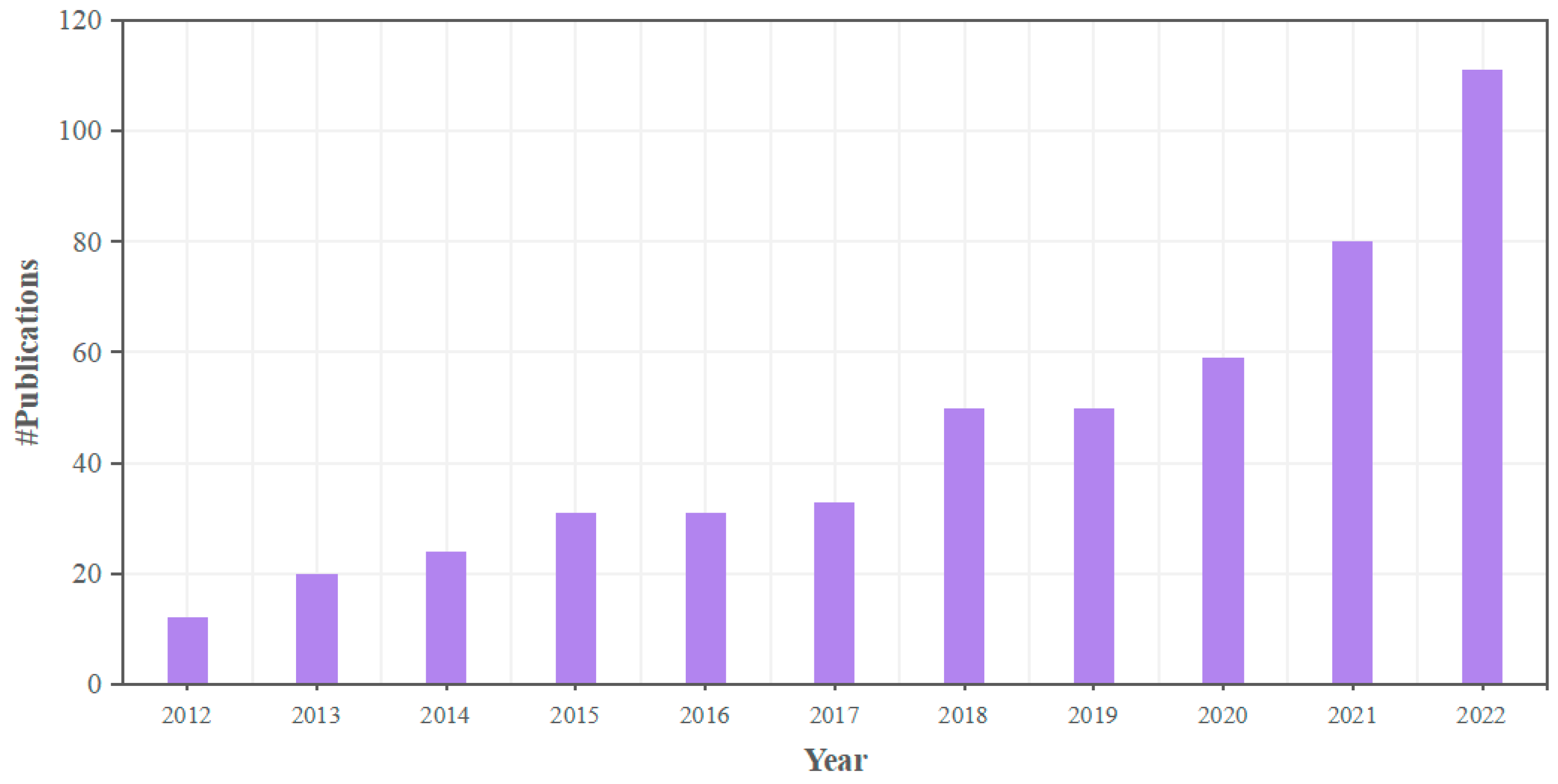
3.1. Data Collection
3.2. CiteSpace Tool for Scientometric Analysis
4. Results and Discussion
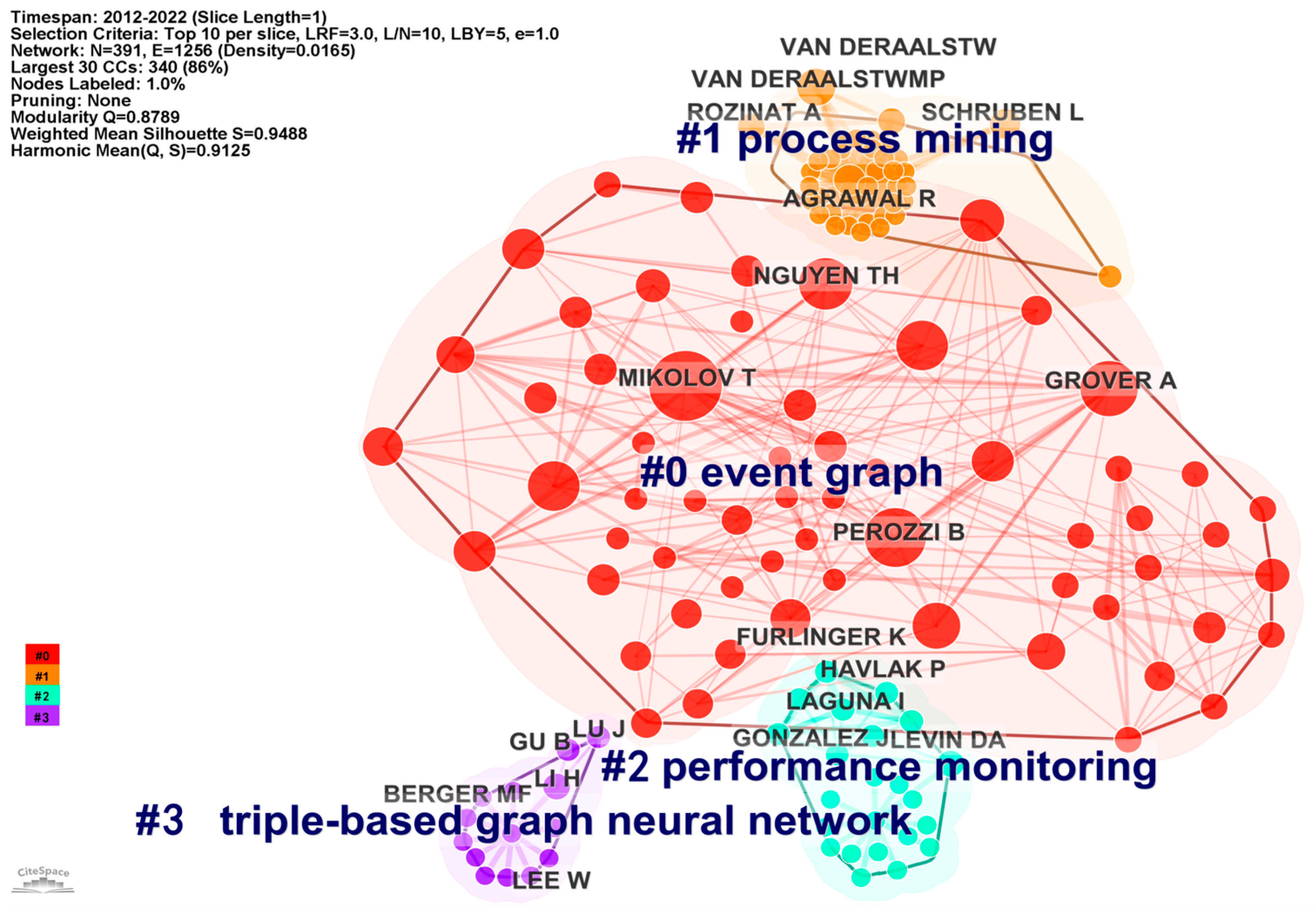
4.1. Author Co-Citation Network Analysis
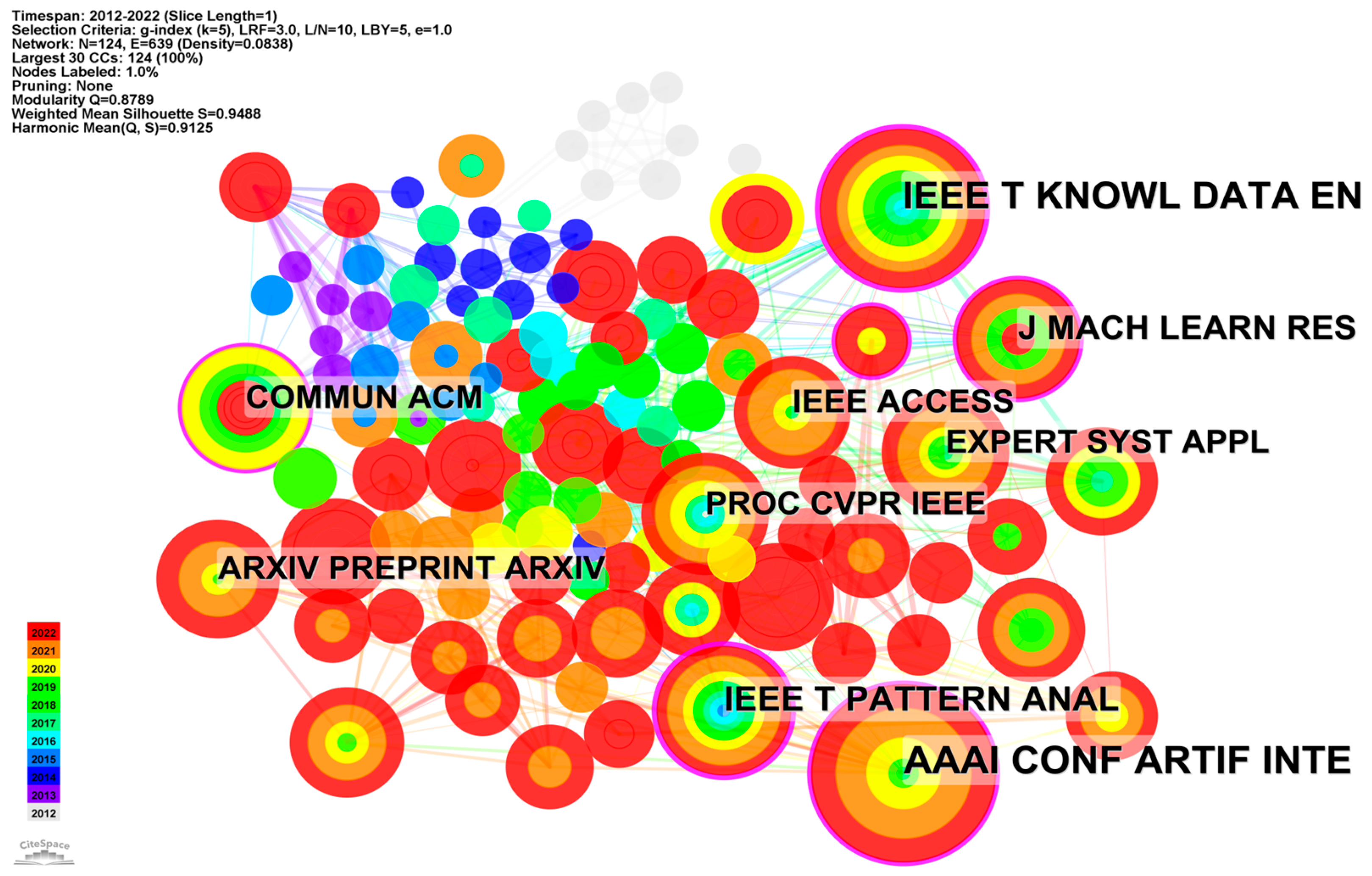
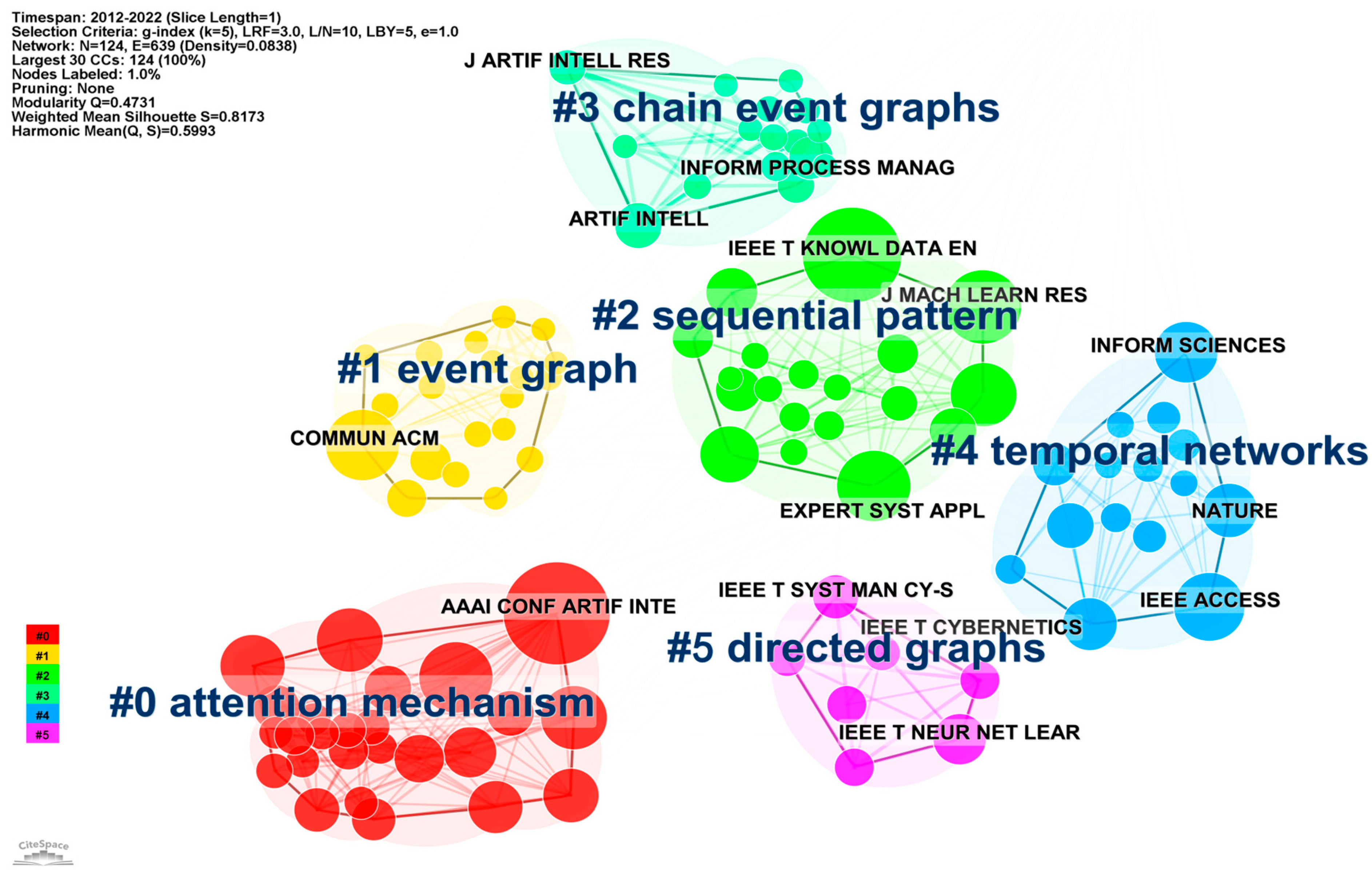
4.2. Journal Co-Citation Network Analysis
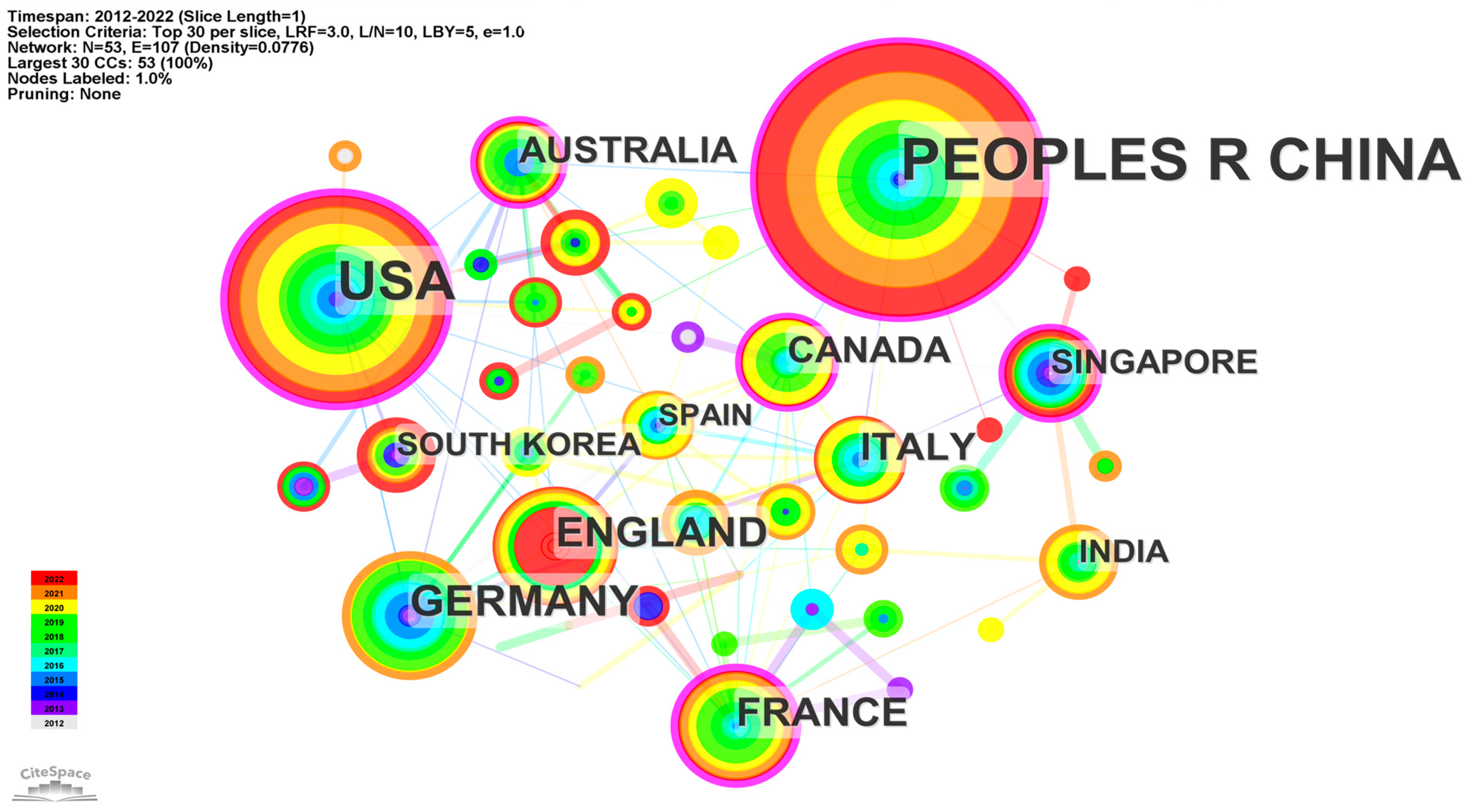
4.3. Collaborative Country Network Analysis
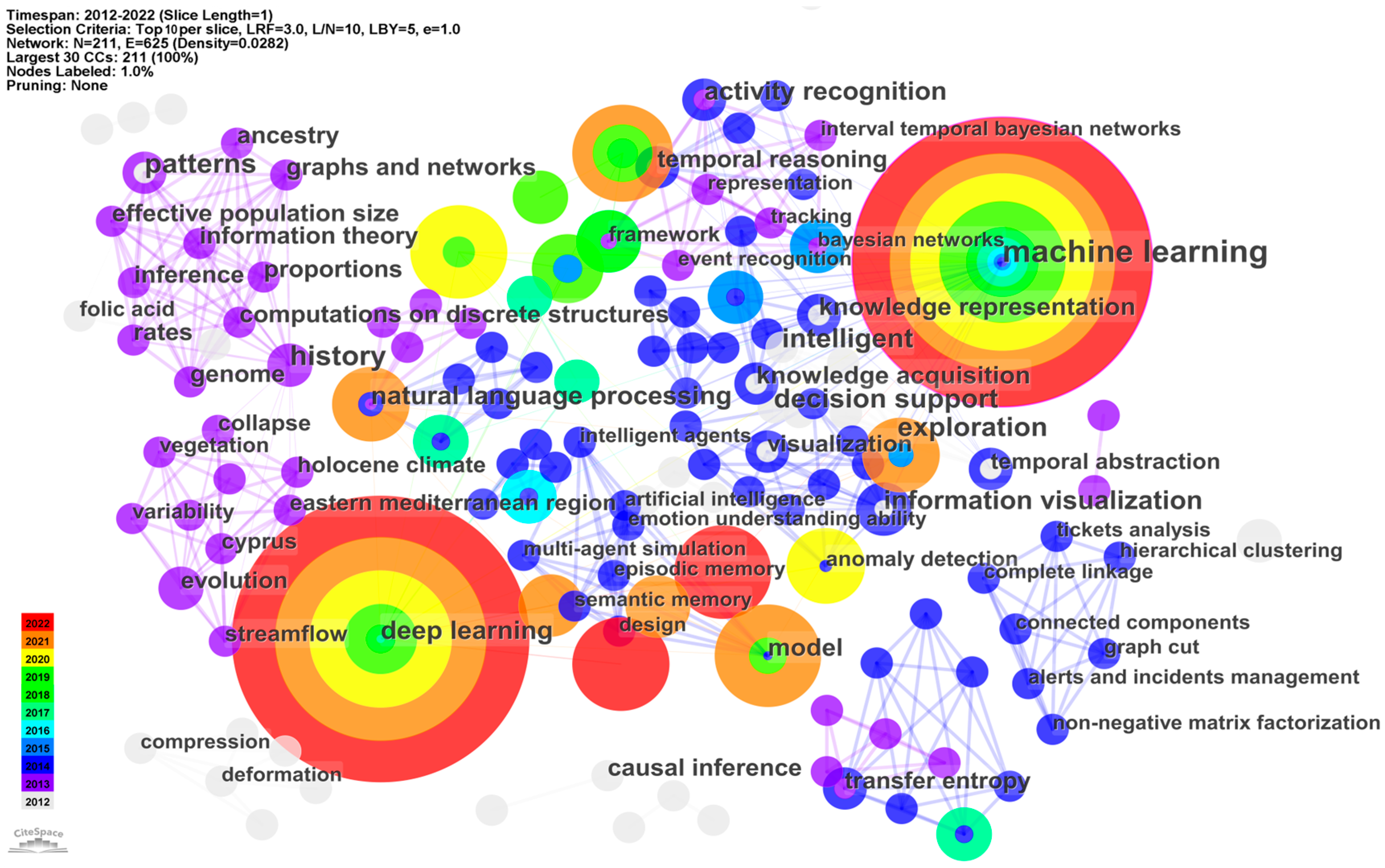
4.4. Keyword Co-Occurrence Network Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, J.; Liu, K.; He, S.; Chen, Y. Knowledge Graph; Higher Education Press: Beijing, China, 2018. [Google Scholar]
- Xiang, W. Reviews on Event Knowledge Graph Construction Techniques and Application. Comput. Mod. 2020, 10, 10–16. [Google Scholar] [CrossRef]
- Xiao, L.; Yue, S. Event extraction technology review and application. Softw. Guide 2023, 22, 7. [Google Scholar]
- Guan, S.; Cheng, X.; Bai, L.; Zhang, F.; Li, Z.; Zeng, Y.; Jin, X.; Guo, J. What is Event Knowledge Graph: A Survey. IEEE Trans. Knowl. Data Eng. 2022, 35, 7569–7589. [Google Scholar] [CrossRef]
- Schauer, M. Narrative Exposure Therapy. In International Encyclopedia of Social & Behavioral Sciences; Elsevier: Amsterdam, The Netherlands, 2015; Volume 16. [Google Scholar] [CrossRef]
- Fortunato, S.; Bergstrom, C.T.; Börner, K.; Evans, J.A.; Helbing, D.; Milojevic, S.; Petersen, A.M.; Radicchi, F.; Sinatra, R.; Uzzi, B.; et al. The Science of Science. Nature 2018, 138, 237. [Google Scholar] [CrossRef]
- Kim, J.-T.; Moldovan, D.I. Acquisition of Linguistic Patterns for Knowledge-Based Information Extraction. IEEE Trans. Knowl. Data Eng. 1995, 7, 713–724. [Google Scholar] [CrossRef]
- Riloff, E. Automatically constructing a dictionary for information extraction tasks. In Proceedings of the National Conference on Artificial Intelligence, Washington, DC, USA, 11–15 July 1993; pp. 811–816. Available online: https://api.semanticscholar.org/CorpusID:2257053 (accessed on 1 November 2023).
- Jiang, J. Event IE pattern acquisition method. Jisuanji Gongcheng/Comput. Eng. 2005, 31, 96–98. Available online: https://api.semanticscholar.org/CorpusID:62948118 (accessed on 1 November 2023).
- Yangarber, R. Scenario Customization for Information Extraction. 2001. Available online: https://api.semanticscholar.org/CorpusID:61015755 (accessed on 1 November 2023).
- Riloff, E.; Shoen, J. Automatically aquiring conceptual patterns without an annotated corpus. In Proceedings of the Third Workshop on Very Large Corpora, Cambridge, MA, USA, 30 June 1995; Available online: https://api.semanticscholar.org/CorpusID:10779824 (accessed on 1 November 2023).
- Chieu, H.L.; Ng, H.T. A maximum entropy approach to information extraction from semi-structured and free text. In Proceedings of the National Conference on Artificial Intelligence, Edmont, AB, Canada, 28 July–1 August 2002; pp. 786–791. [Google Scholar]
- Li, Q.; Ji, H.; Huang, L. Joint Event Extraction via Structured Prediction with Global Features. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; Available online: https://api.semanticscholar.org/CorpusID:2114517 (accessed on 1 November 2023).
- Llorens, H.; Saquete, E.; Navarro-Colorado, B. TimeML events recognition and classification: Learning CRF models with semantic roles. In Proceedings of the Coling 2010—23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; Volume 2, pp. 725–733. Available online: https://api.semanticscholar.org/CorpusID:14170243 (accessed on 1 November 2023).
- Ahn, D. The stages of event extraction. In Proceedings of the Workshop on Annotating and Reasoning about Time and Events, Sydney, NSW, Australia, 23 July 2006; pp. 1–8. [Google Scholar]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the ACL-IJCNLP 2015—53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 167–176. [Google Scholar] [CrossRef]
- Ding, N.; Li, Z.; Liu, Z.; Zheng, H.T.; Lin, Z. Event detection with trigger-aware lattice neural network. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 347–356. [Google Scholar] [CrossRef]
- Satyapanich, T.; Ferraro, F.; Finin, T. Casie: Extracting cybersecurity event information from text. In Proceedings of the AAAI 2020—34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8749–8757. [Google Scholar] [CrossRef]
- Yang, S.; Feng, D.; Qiao, L.; Kan, Z.; Li, D. Exploring pre-trained language models for event extraction and generation. In Proceedings of the ACL 2019—57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2020; pp. 5284–5294. [Google Scholar] [CrossRef]
- Zeng, Y.; Yang, H.; Feng, Y.; Wang, Z.; Zhao, D. A convolution BiLSTM neural network model for chinese event extraction. In Natural Language Understanding and Intelligent Applications; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016; Volume 10102, pp. 275–287. [Google Scholar] [CrossRef]
- Zheng, G.; Mukherjee, S.; Dong, X.L.; Li, F. OpenTag: Open aribute value extraction from product profiles. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 1049–1058. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Grishman, R. Graph convolutional networks with argument-aware pooling for event detection. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence—AAAI 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 5900–5907. [Google Scholar] [CrossRef]
- Cui, S.; Yu, B.; Liu, T.; Zhang, Z.; Wang, X.; Shi, J. Edge-enhanced graph convolution networks for event detection with syntactic relation. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2329–2339. [Google Scholar] [CrossRef]
- Ben Veyseh, A.P.; Nguyen, T.N.; Nguyen, T.H. Graph transformer networks with syntactic and semantic structures for event argument extraction. In Findings of the Association for Computational Linguistics: EMNLP 2020; abs/2010.1; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3651–3661. [Google Scholar] [CrossRef]
- Huang, K.H.; Yang, M.; Peng, N. Biomedical event extraction with hierarchical knowledge graphs. In Findings of the Association for Computational Linguistics Findings of ACL: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1277–1285. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint event extraction via recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—NAACL HLT 2016, San Diego, CA, USA, 12–17 June 2016; pp. 300–309. [Google Scholar] [CrossRef]
- Shen, S.; Qi, G.; Li, Z.; Bi, S.; Wang, L. Hierarchical Chinese Legal event extraction via Pedal Attention Mechanism. In Proceedings of the COLING 2020—28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 100–113. [Google Scholar] [CrossRef]
- Sheng, J.; Guo, S.; Yu, B.; Li, Q.; Hei, Y.; Wang, L.; Liu, T.; Xu, H. CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 164–174. [Google Scholar] [CrossRef]
- Du, X.; Cardie, C. Document-level event role filler extraction using multi-granularity contextualized encoding. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2020; pp. 8010–8020. [Google Scholar] [CrossRef]
- Huang, K.-H.; Peng, N. Document-level Event Extraction with Efficient End-to-end Learning of Cross-event Dependencies. In Proceedings of the Third Workshop on Narrative Understanding, Virtual, 11 June 2021; pp. 36–47. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Zhao, J. Knowledge enhanced event causality identification with mention masking generalizations. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3608–3614. [Google Scholar] [CrossRef]
- Liu, H.; Singh, P. ConceptNet—A Practical Commonsense Reasoning Tool-Kit. BT Technol. J. 2004, 22, 211–226. [Google Scholar] [CrossRef]
- Cheng, F.; Miyao, Y. Classifying temporal relations by bidirectional LSTM over dependency paths. In Proceedings of the ACL 2017—55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 2, pp. 1–6. [Google Scholar] [CrossRef]
- Han, R.; Ning, Q.; Peng, N. Joint event and temporal relation extraction with shared representations and structured prediction. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 434–444. [Google Scholar] [CrossRef]
- Han, R.; Zhou, Y.; Peng, N. Domain knowledge empowered structured neural net for end-to-end event temporal relation extraction. In Proceedings of the EMNLP 2020—2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 5717–5729. [Google Scholar] [CrossRef]
- Chen, C. CiteSpace II: Detecting visualizing emerging trends transient patterns in scientific literature. J. Assoc. Inf. Sci. Technol. 2006, 57, 359–377. [Google Scholar] [CrossRef]
- De Nooy, W.; Mrvar, A.; Batagelj, V. Exploratory Social Network Analysis with Pajek; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar] [CrossRef]
- Chen, C. The CiteSpace Manual. Scientometrics 2015, 103, 1003–1022. [Google Scholar]
- Kleinberg, J.M. Bursty and Hierarchical Structure in Streams. Data Min. Knowl. Discov. 2002, 7, 373–397. [Google Scholar] [CrossRef]
- Li, J.; Chen, C. CiteSpace: Text Mining and Visualization in Scientific Literature; Capital University of Economics and Business Press: Beijing, China, 2016. (In Chinese) [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
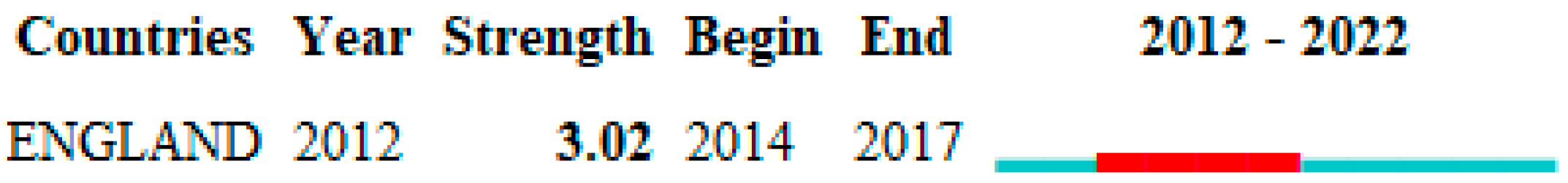{kind=link}
{kind=link}
| Dataset | Year | Field | Language | Description |
|---|---|---|---|---|
| MUC-4 https://www-nlpir.nist.gov/related_projects/muc/muc_data/muc_data_index.html (accessed on 1 November 2023) | 1996 | General | English | It contains 1700 documents. |
| ACE 2005 https://catalog.ldc.upenn.edu/byproject (accessed on 1 November 2023) | 2005 | General | English, Chinese, and Arabic | It contains 8 categories and 33 sub-categories of events. |
| CEC https://github.com/shijiebei2009/CEC-Corpus (accessed on 1 November 2023) | 2009 | Disaster | Chinese | It contains 322 documents covering earthquakes, fires, traffic accidents, terrorist attacks, and food poisoning emergencies. |
| TAC KBP 2017 https://tac.nist.gov/2017/KBP/Event/index.html (accessed on 1 November 2023) | 2017 | General | English, Chinese, and Spanish | It contains 202 documents collected from news and forums. |
| WIKIEVENTS https://github.com/231sm/Low_Resource_KBP (accessed on 1 November 2023) | 2020 | General | English | It contains 246 documents, 6132 sentences, and 3951 events obtained from Wikipedia. |
| CySecED https://aclanthology.org/2020.emnlp-main.433.pdf (accessed on 1 November 2023) | 2020 | Network security | English | It contains 292 documents covering 30 types of network security incidents. |
| MAVEN https://github.com/THU-KEG/MAVEN-dataset (accessed on 1 November 2023) | 2020 | General | English | It contains 4480 documents collected from Wikipedia covering 118,732 events that can be categorized into 168 types. |
| FewEvent https://github.com/231sm/Low_Resource_KBP (accessed on 1 November 2023) | 2020 | General | English | It expanded ACE2005 and TACKBP 2017 by importing new events from FreeBase and Wikipedia, including music, movies, sports, education, etc. |
| Relation | Meaning | Extraction Templates |
|---|---|---|
| Causal relation | One event (cause) causes another event (effect) to occur. | because, due to, because of, therefore, thus, result in, lead to, thereby, lie in, since, thanks to, due to the fact that |
| Consequent relation | Partial order relation in which two events occur one after another in time. | then, before, after, earlier, later, accordingly, subsequently, in consequence, consequently |
| Conditional relation | One event is the condition for another event. | unless, “if … then…”, otherwise, “provided/given/assuming/supposing/in the event/on the condition that…”, as long as |
| Concurrency relation | The two events happen side by side. | “not only … but also”, at the same time, simultaneously, “either … or”, alongside, together with |
| Author | Full Name | Betweenness Centrality | Average Year |
|---|---|---|---|
| Schruben L | Schruben Lee | 0.10 | 2012 |
| Liu Y | Liu Yu | 0.08 | 2014 |
| Mikolov T | Mikolov Tomas | 0.05 | 2018 |
| Levin DA | Levin David Asher | 0.05 | 2012 |
| Li H | Li Huaqing | 0.04 | 2012 |
| Author | Full Name | Citation Burst | Begin (Year) |
|---|---|---|---|
| Mikolov T | Mikolov Tomas | 9.51 | 2018 |
| Perozzi B | Perozzi Bryan | 6.42 | 2020 |
| Grover A | Grover Aditya | 5.6 | 2018 |
| Nguyen TH | Nguyen Thien Huu | 5.42 | 2019 |
| Tang J | Tang Jian | 4.92 | 2018 |
| Cluster ID | Size | Silhouette | Mean (Year) | Label (LLR) |
|---|---|---|---|---|
| 0 | 62 | 0.978 | 2017 | flow graph analysis; data flow; online analysis |
| 1 | 39 | 0.979 | 2012 | dependency; domain-specific modeling; business process simulation |
| 6 | 23 | 0.993 | 2013 | automatic loop detection; application structure detection; performance monitoring |
| 10 | 14 | 0.994 | 2012 | causality-associated graph neural network; bio-event extraction; news event |
| Abbreviation | Full Name | Impact Factor | Frequency of Publications | Average Year |
|---|---|---|---|---|
| AAAI CONF ARTIF INTE | AAAI Conference on Artificial Intelligence | Conference journal | 61 | 2018 |
| IEEE T KNOWL DATA EN | IEEE Transactions on Knowledge and Data Engineering | 8.9 | 52 | 2015 |
| IEEE T PATTERN ANAL | IEEE Transactions on Pattern Analysis and Machine Intelligence | 23.6 | 35 | 2013 |
| J MACH LEARN RES | Journal of Machine Learning Research | 6.0 | 31 | 2014 |
| COMMUN ACM | Communications of the ACM | 22.7 | 29 | 2012 |
| Abbreviation | Full Name | Impact Factor | Betweenness Centrality | Average Year |
|---|---|---|---|---|
| COMMUN ACM | Communications of the ACM | 22.7 | 0.23 | 2012 |
| IEEE T KNOWL DATA EN | IEEE Transactions on Knowledge and Data Engineering | 8.9 | 0.22 | 2015 |
| IEEE T PATTERN ANAL | IEEE Transactions on Pattern Analysis and Machine Intelligence | 23.6 | 0.19 | 2013 |
| IEEE T SYST MAN CY-S | IEEE Transactions on Systems, Man, and Cybernetics: Systems | 8.7 | 0.14 | 2020 |
| J MACH LEARN RES | Journal of Machine Learning Research | 6.0 | 0.13 | 2014 |
| Abbreviation | Full Name | Impact Factor | Burst | Begin (Year) | End (Year) |
|---|---|---|---|---|---|
| PLOS ONE | Plos One | 3.7 | 5.38 | 2018 | 2020 |
| SCIENCE | Science | 56.9 | 5.24 | 2018 | 2019 |
| ARTIF INTELL | Artificial Intelligence | 14.4 | 5.22 | 2013 | 2017 |
| PROC VLDB ENDOW | Proceedings of the VLDB Endowment | 2.5 | 5.16 | 2016 | 2019 |
| NATURE | Nature | 64.8 | 4.34 | 2015 | 2018 |
| Cluster ID | Size | Silhouette | Mean (Year) | Label (LLR) |
|---|---|---|---|---|
| 0 | 29 | 0.818 | 2020 | attention mechanism; semantics; feature extraction; knowledge engineering; event extraction |
| 1 | 25 | 0.923 | 2013 | event graph; process mining; logical process; model transformation; directed graphs |
| 2 | 24 | 0.794 | 2016 | sequential pattern; event sequence; bridge event; big data; cognition graph |
| 3 | 24 | 0.857 | 2014 | chain event graphs; Bayesian model selection; chain event graph; causality; event summarization |
| 4 | 19 | 0.818 | 2017 | temporal networks; graph entropy; random walk with restart; spike-based; targeted event detection |
| 6 | 7 | 0.996 | 2021 | directed graphs; topology; multi-agent systems; eigenvalues and eigenfunctions; protocols |
| Country | Publication Frequency | Percentage | Average Year |
|---|---|---|---|
| CHINA | 143 | 26.384% | 2012 |
| USA | 82 | 15.129% | 2012 |
| GERMANY | 36 | 6.642% | 2012 |
| ENGLAND | 28 | 5.166% | 2013 |
| FRANCE | 24 | 4.428% | 2013 |
| Country | Betweenness Centrality | Degree Centrality | Average Year |
|---|---|---|---|
| FRANCE | 0.35 | 18 | 2013 |
| USA | 0.20 | 13 | 2012 |
| CHINA | 0.18 | 12 | 2012 |
| AUSTRALIA | 0.16 | 12 | 2013 |
| NETHERLANDS | 0.15 | 9 | 2016 |
| Keywords | Betweenness Centrality | Average Year |
|---|---|---|
| Machine learning | 0.2 | 2013 |
| Model | 0.06 | 2014 |
| Deep learning | 0.05 | 2016 |
| Information visualization | 0.05 | 2012 |
| Activity recognition | 0.05 | 2013 |
| Keywords | Burst | Begin (Year) | End (Year) |
|---|---|---|---|
| Deep learning | 20.81 | 2018 | 2022 |
| Machine learning | 9.4 | 2016 | 2020 |
| Neural networks | 4.62 | 2019 | 2020 |
| Knowledge graph | 3.54 | 2018 | 2022 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Liu, S.; Jing, C.; Li, S. Event Knowledge Graph: A Review Based on Scientometric Analysis. Appl. Sci. 2023, 13, 12338. https://doi.org/10.3390/app132212338
Xu S, Liu S, Jing C, Li S. Event Knowledge Graph: A Review Based on Scientometric Analysis. Applied Sciences. 2023; 13(22):12338. https://doi.org/10.3390/app132212338
Chicago/Turabian StyleXu, Shishuo, Sirui Liu, Changfeng Jing, and Songnian Li. 2023. "Event Knowledge Graph: A Review Based on Scientometric Analysis" Applied Sciences 13, no. 22: 12338. https://doi.org/10.3390/app132212338