
A Novel Method for Multistage Degradation Predicting the Remaining Useful Life of Wind Turbine Generator Bearings Based on Domain Adaptation


Abstract
:1. Introduction
- (1)
- RUL prediction methods for WT generator bearings under composite working conditions are proposed, which utilizes TCN with local enhanced residual module to extract temporal features and unsupervised K-means to partition the degradation status of generator bearings.
- (2)
- Aiming at the problem that the prediction accuracy of the full life data of WT generator bearings is affected by the cross-fusion working conditions, the MDSDM module is proposed, which can reduce the influence of composite working conditions on the model and help the model learn the degradation features independent of working conditions.
- (3)
- In view of the different degradation trends of WT generator bearings caused by working conditions, fault types, and other reasons, the DA module is added to the model to improve the prediction accuracy of the model in the target domain bearings.
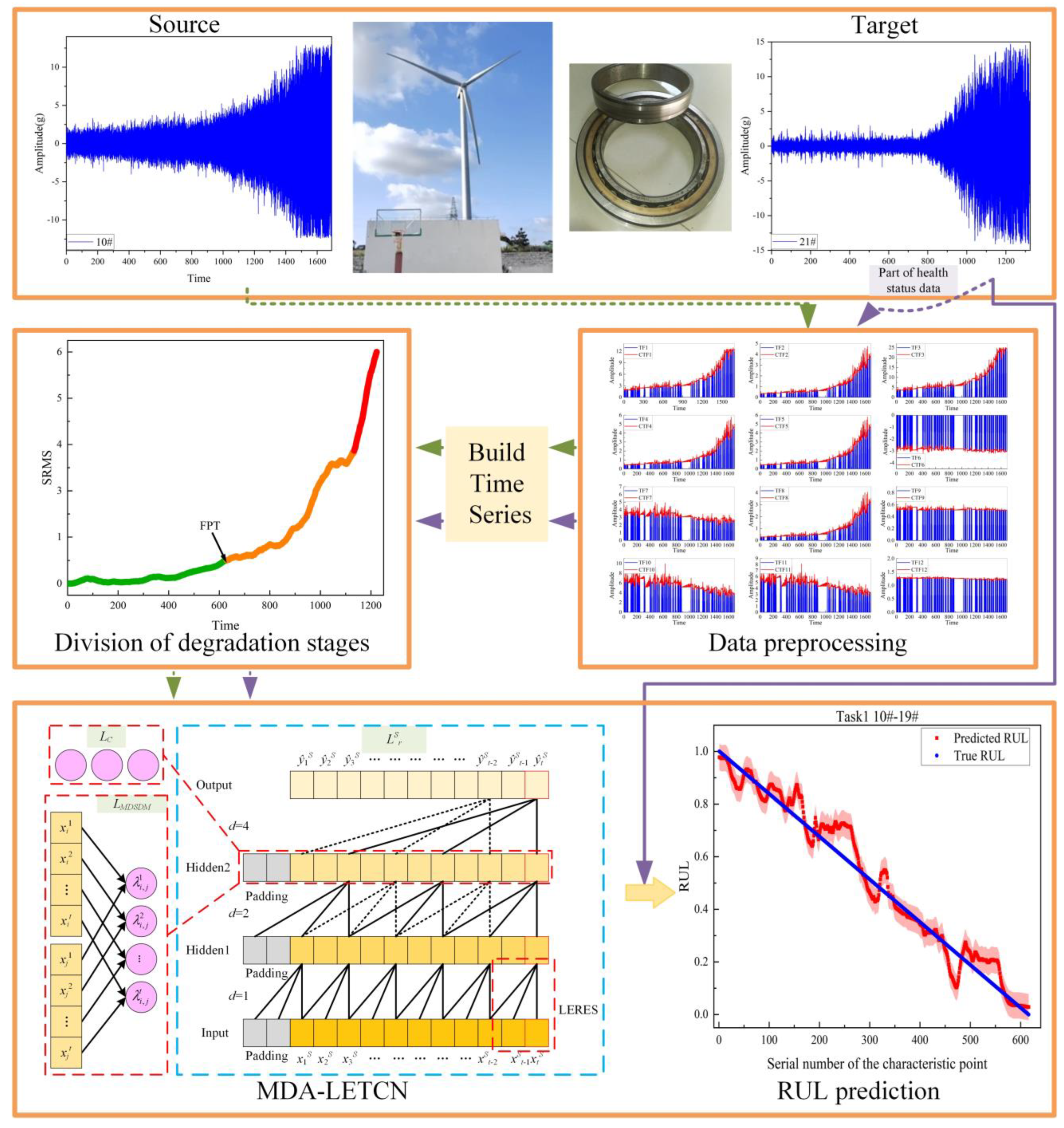
2. Description of the Datasets and Data Preprocessing
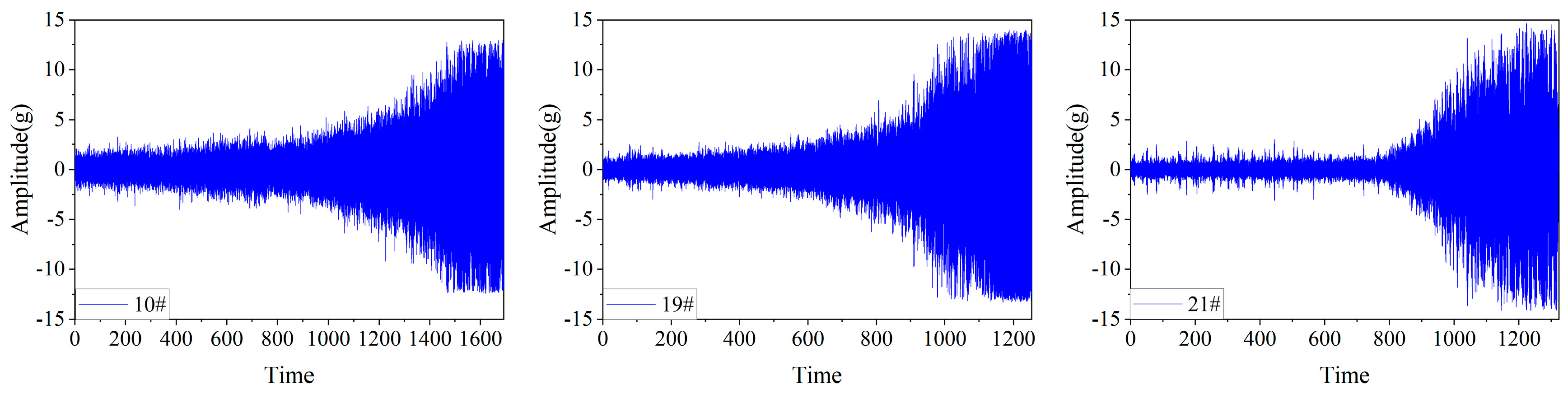
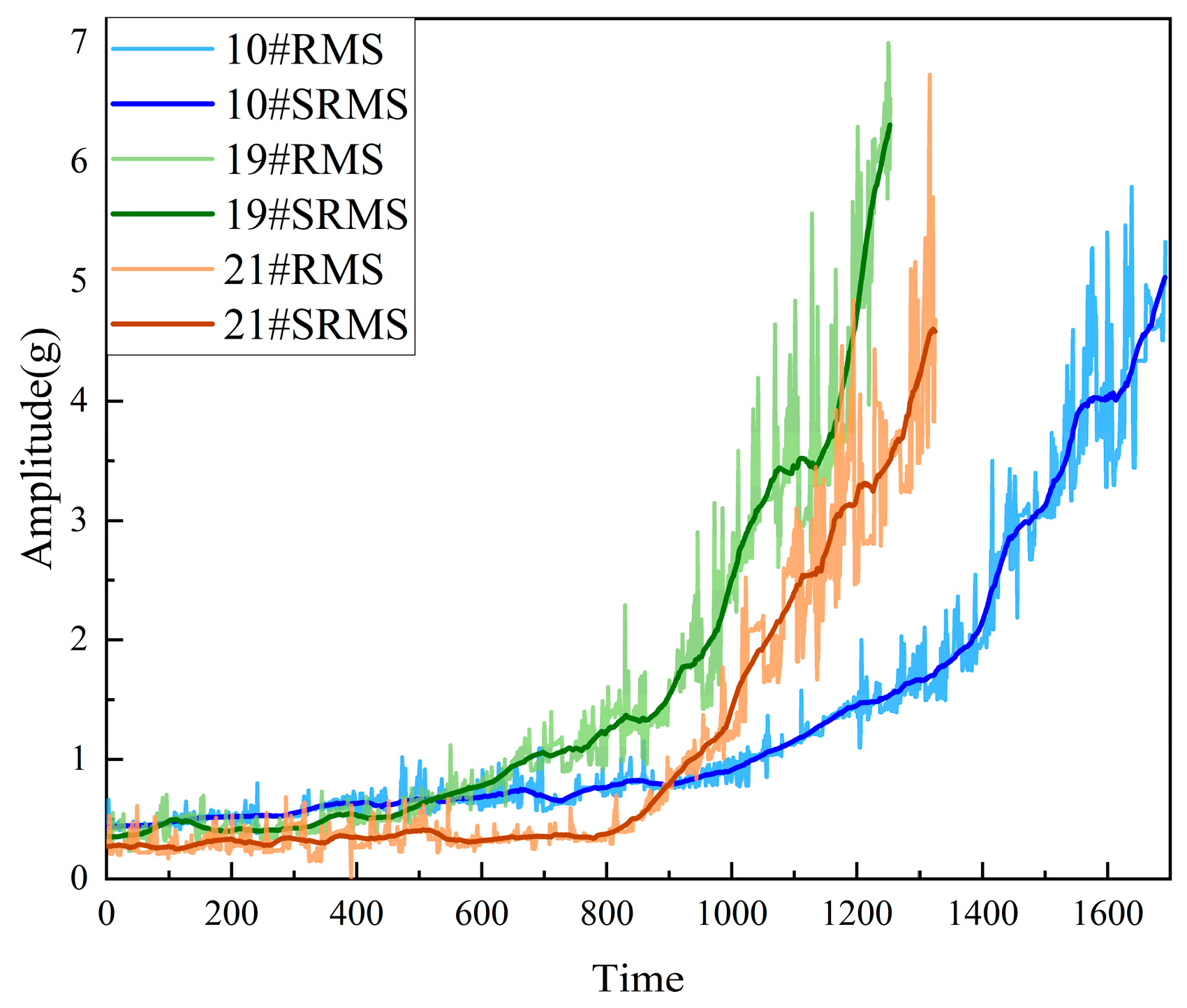
2.1. Description of the Datasets
2.2. Data Preprocessing
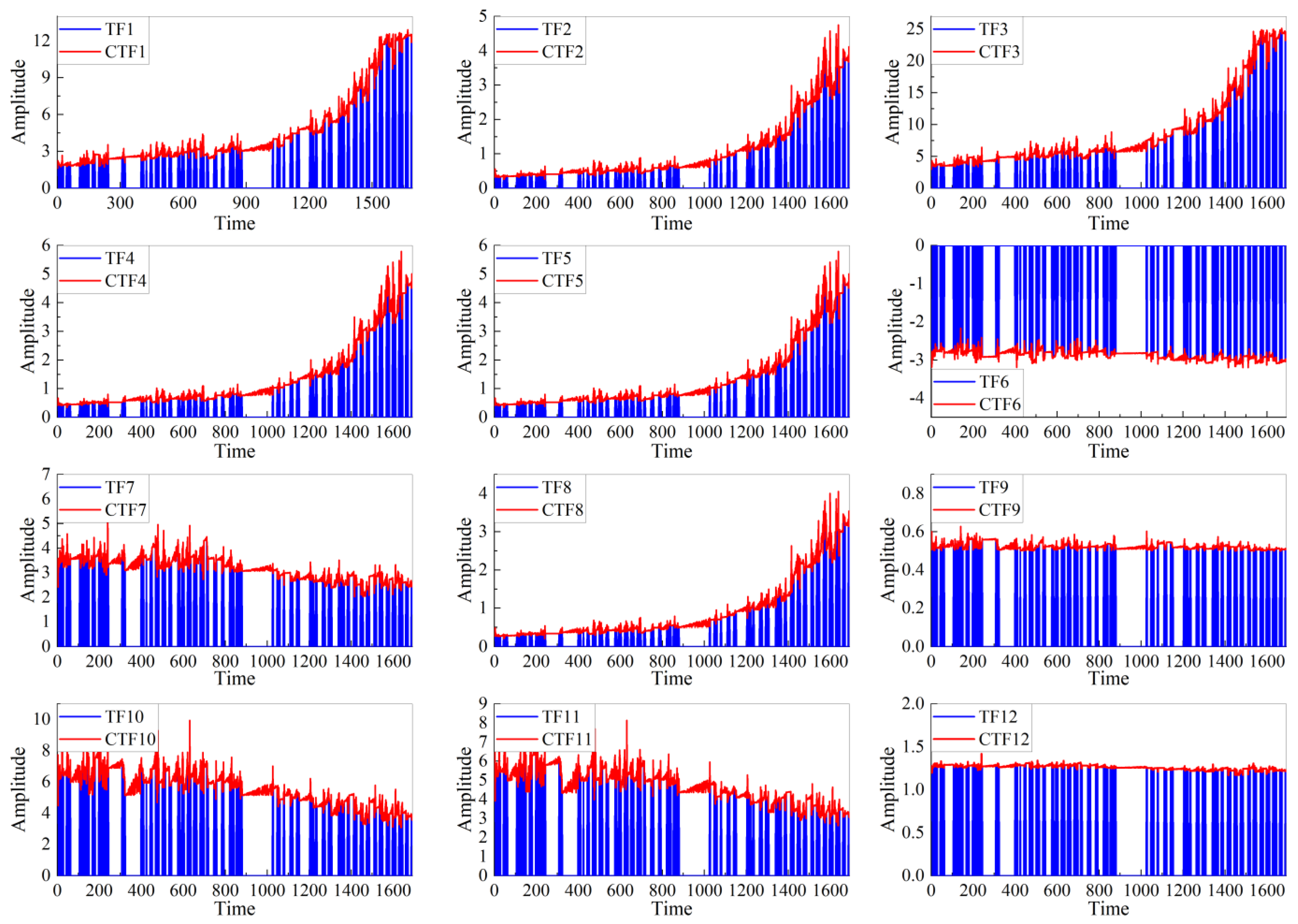
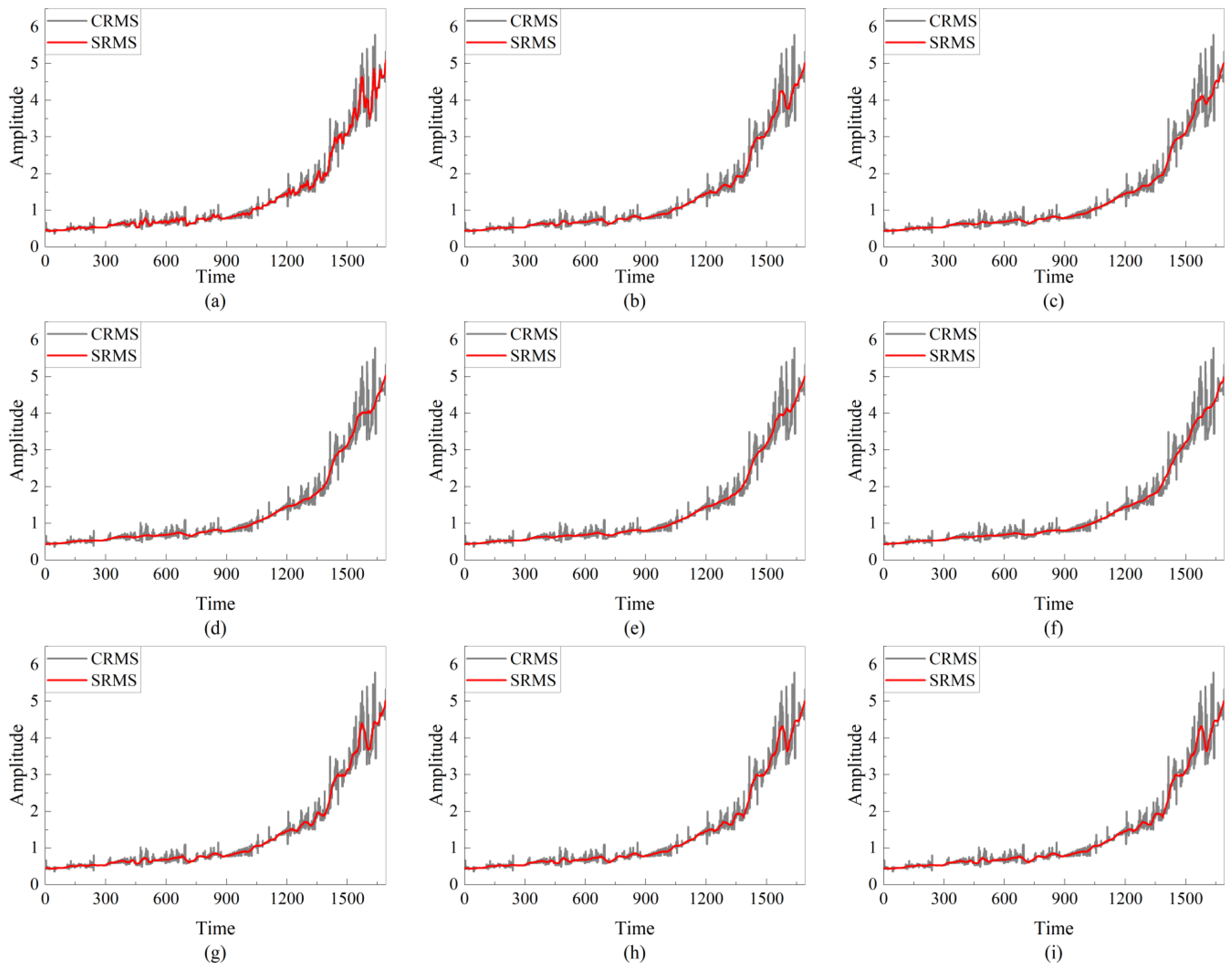
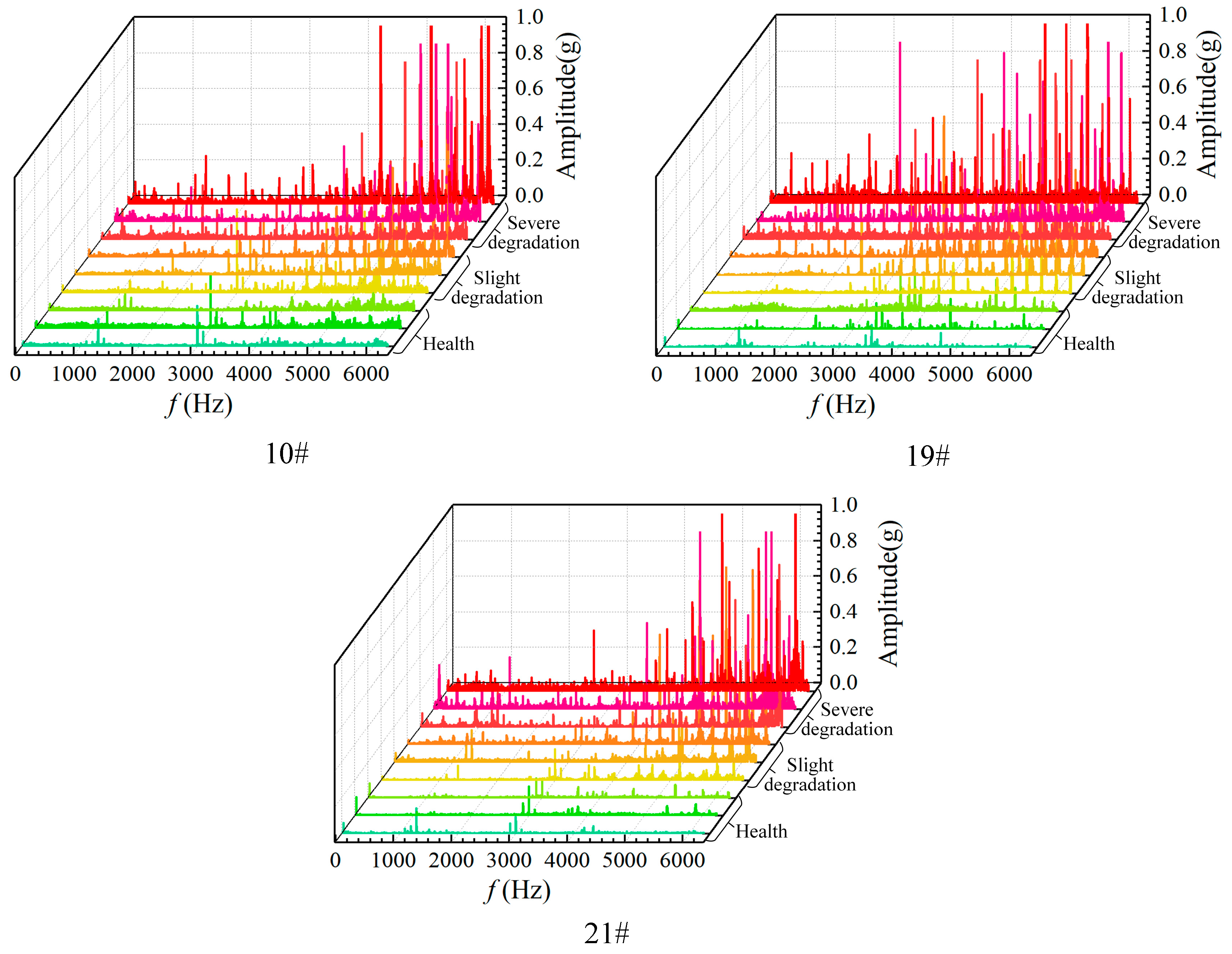
2.3. HI Construction
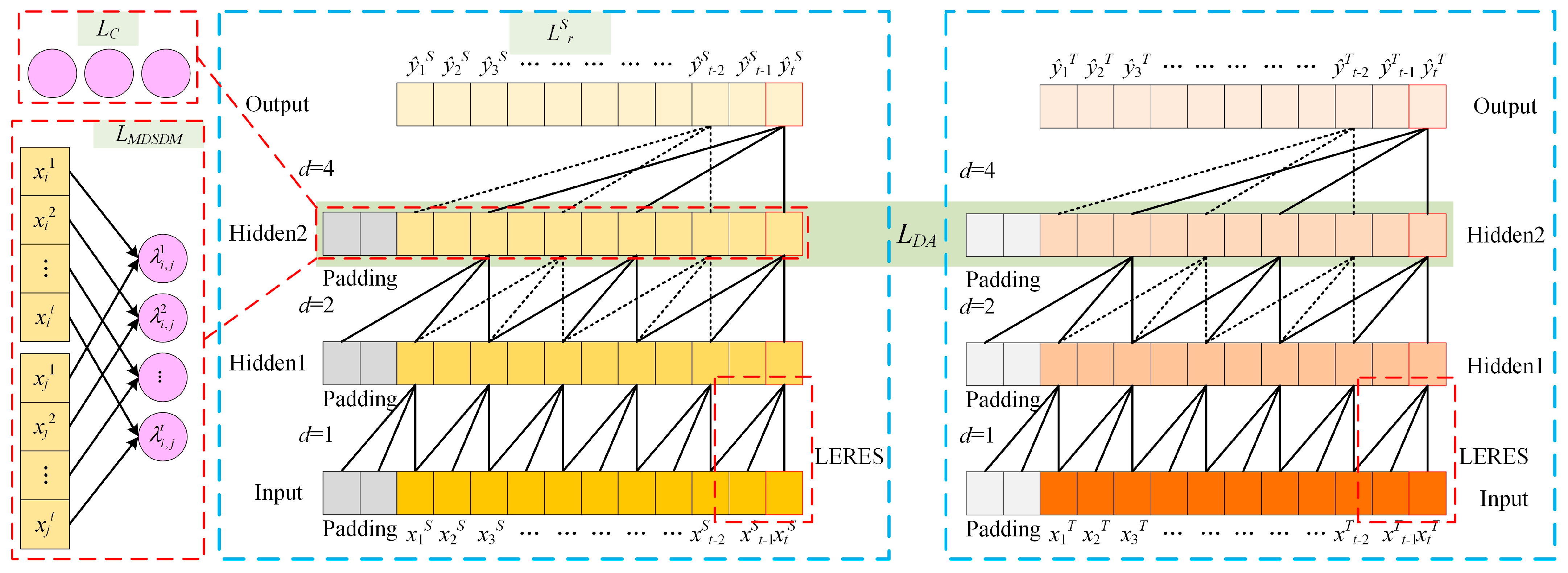
3. The Proposed New Method MDA-LETCN
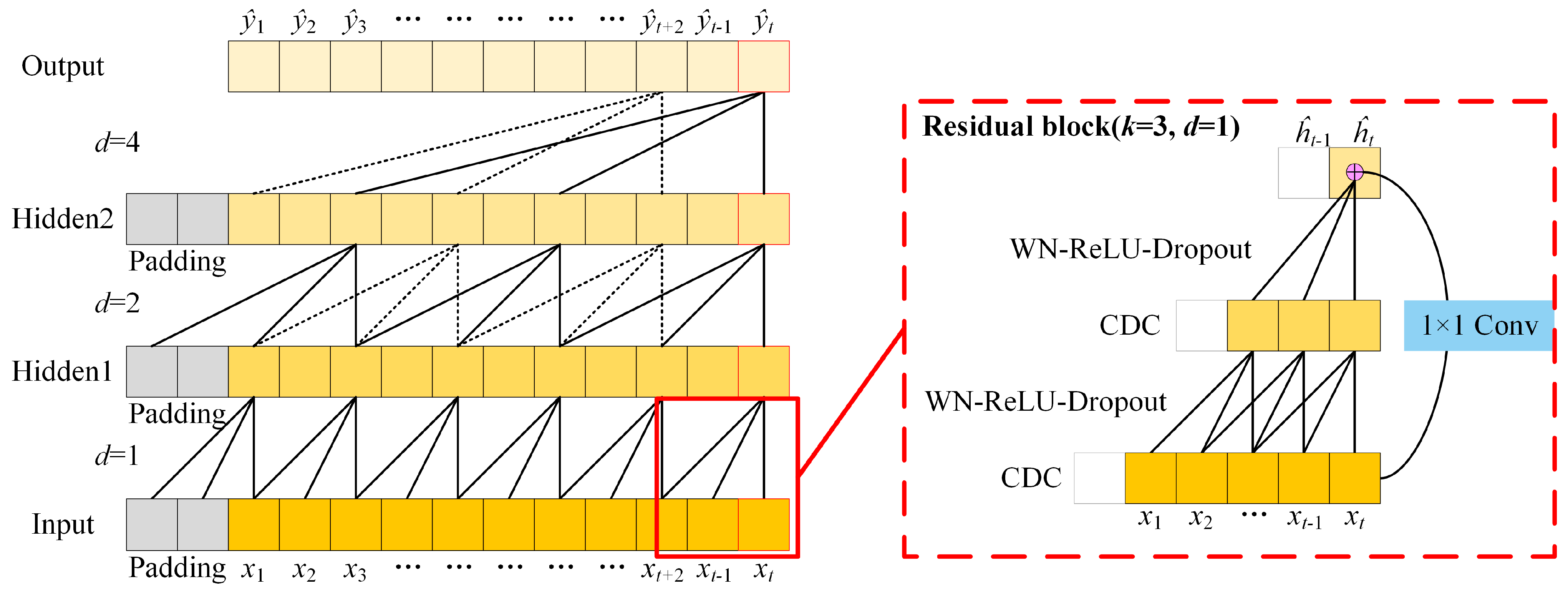
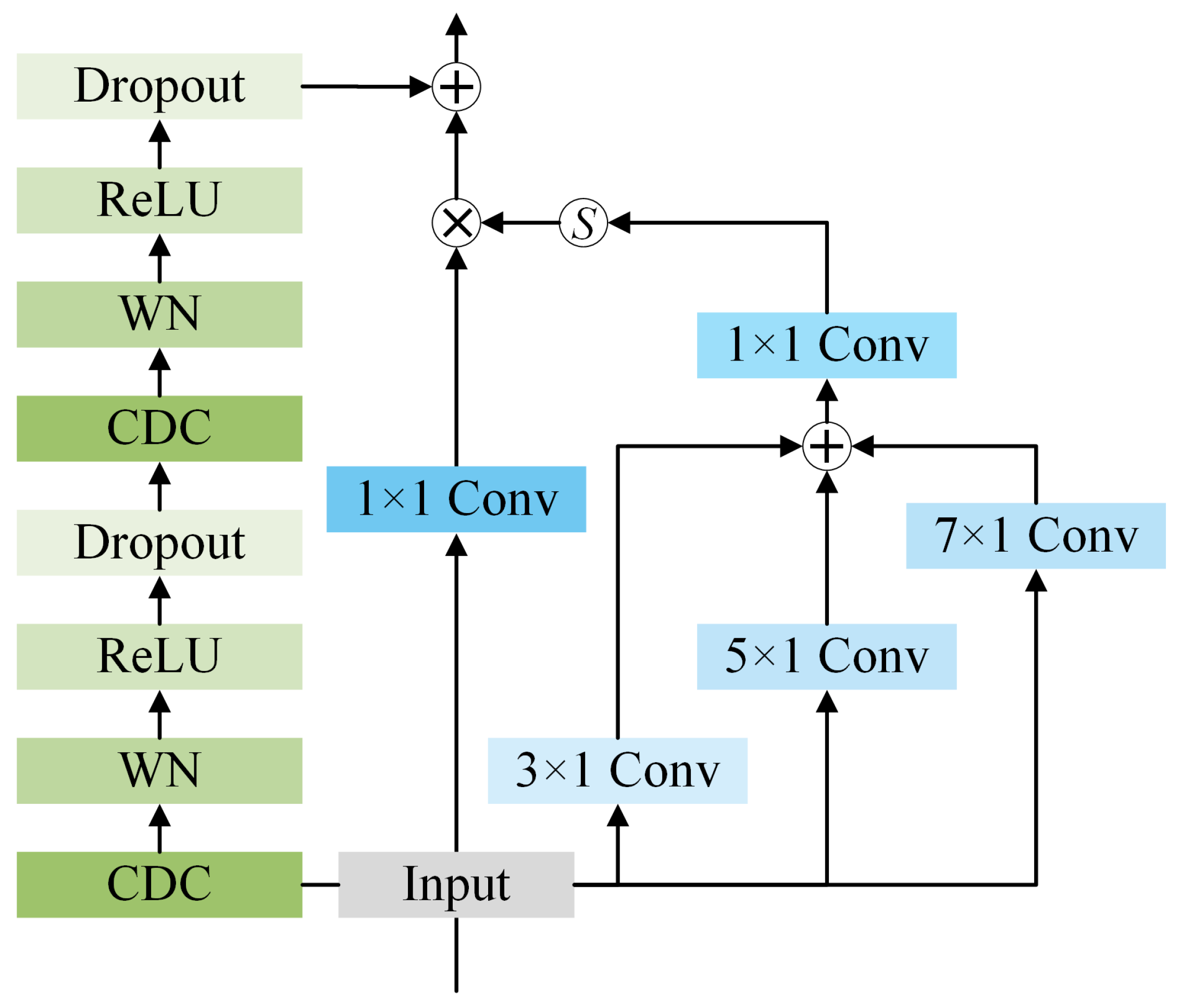
3.1. Temporal Feature Extraction Module
- Causal dilated convolutions
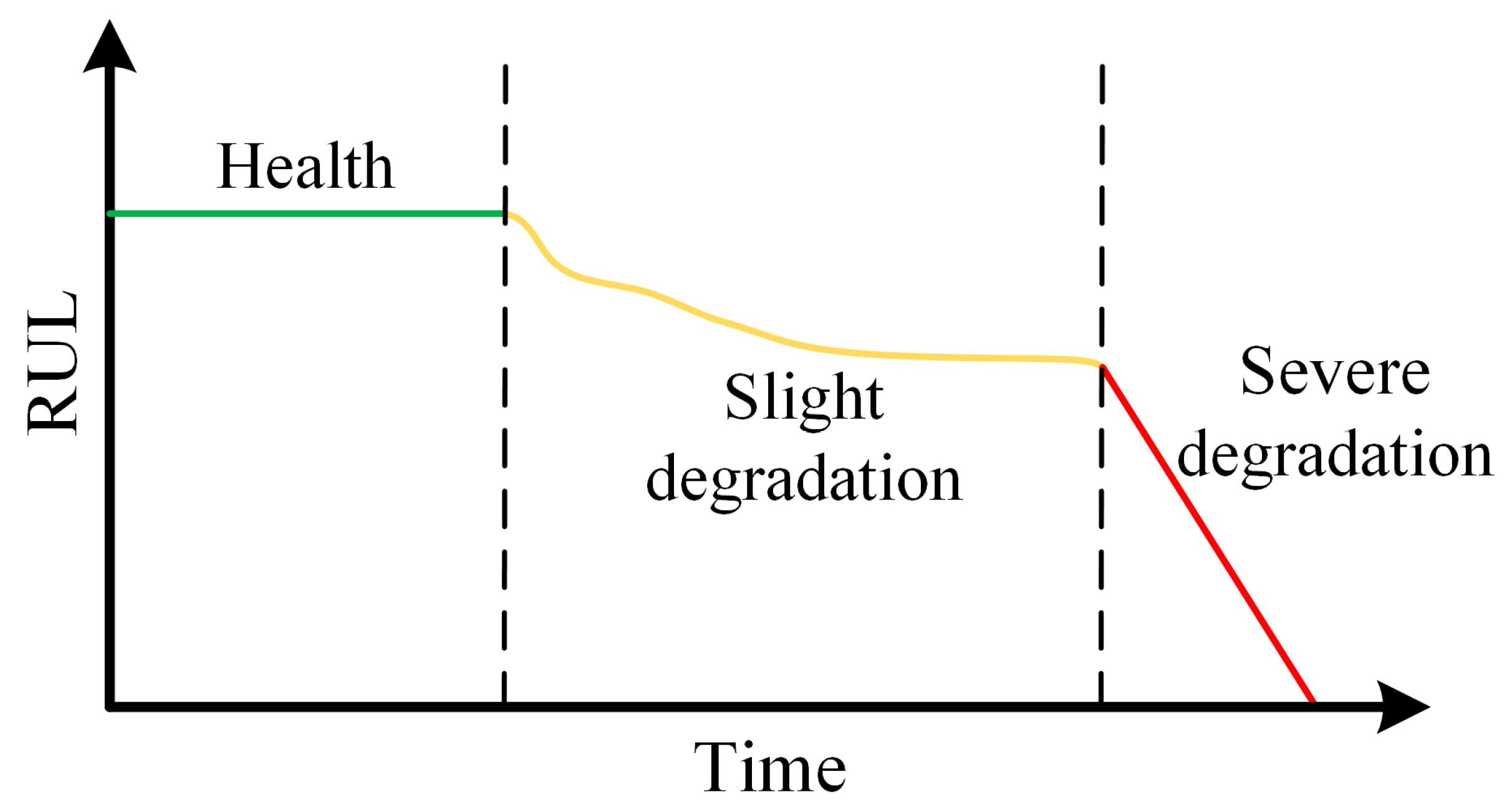
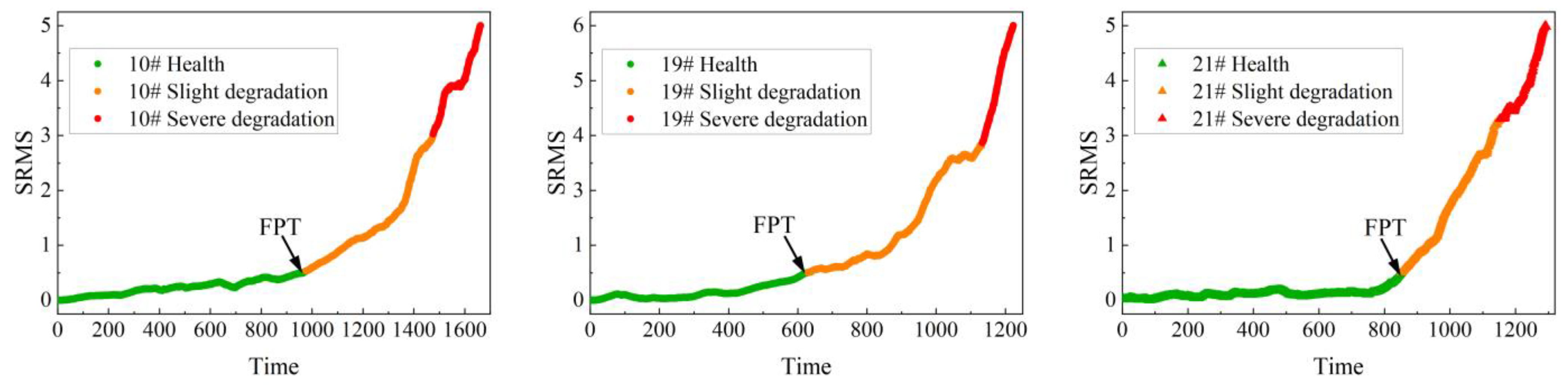
3.2. Multistage Degradation State Division
3.3. Multistage Degradation Stage Distribution Matching (MDSDM)
3.4. Domain Adaptation
3.5. RUL Prediction
4. Case Studies
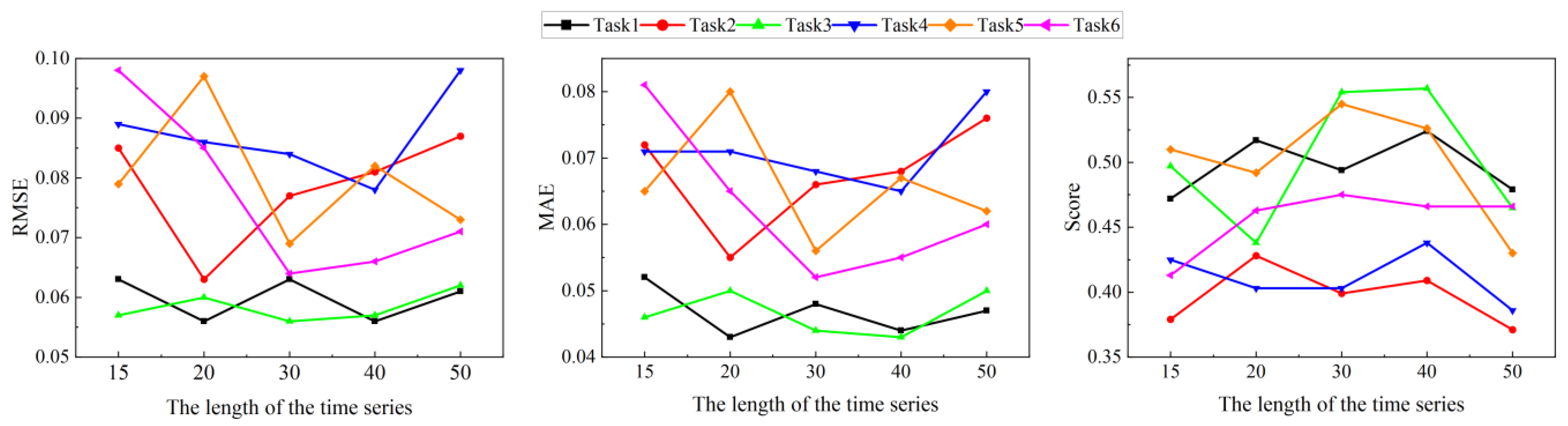
4.1. Parameter Settings
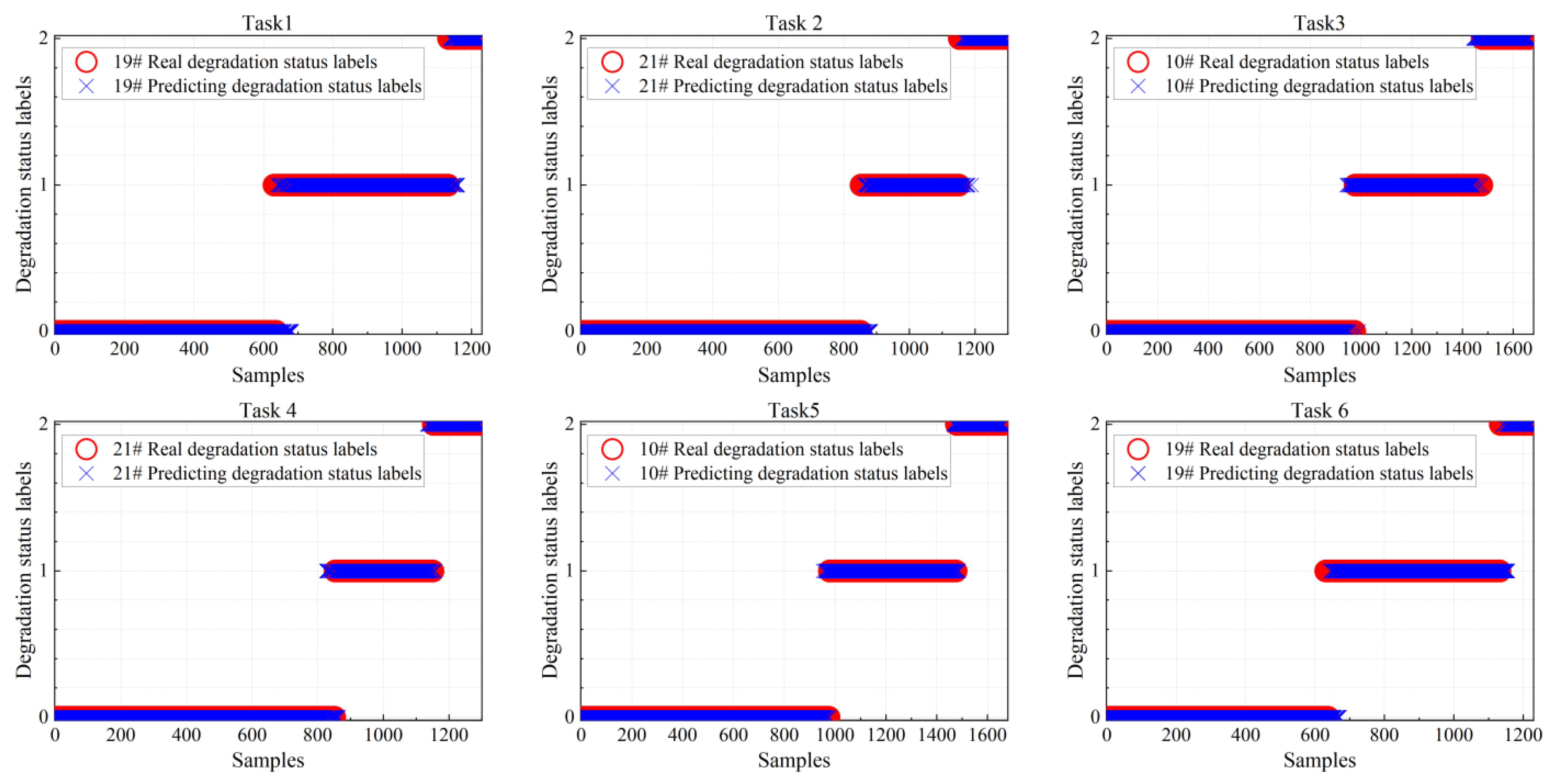
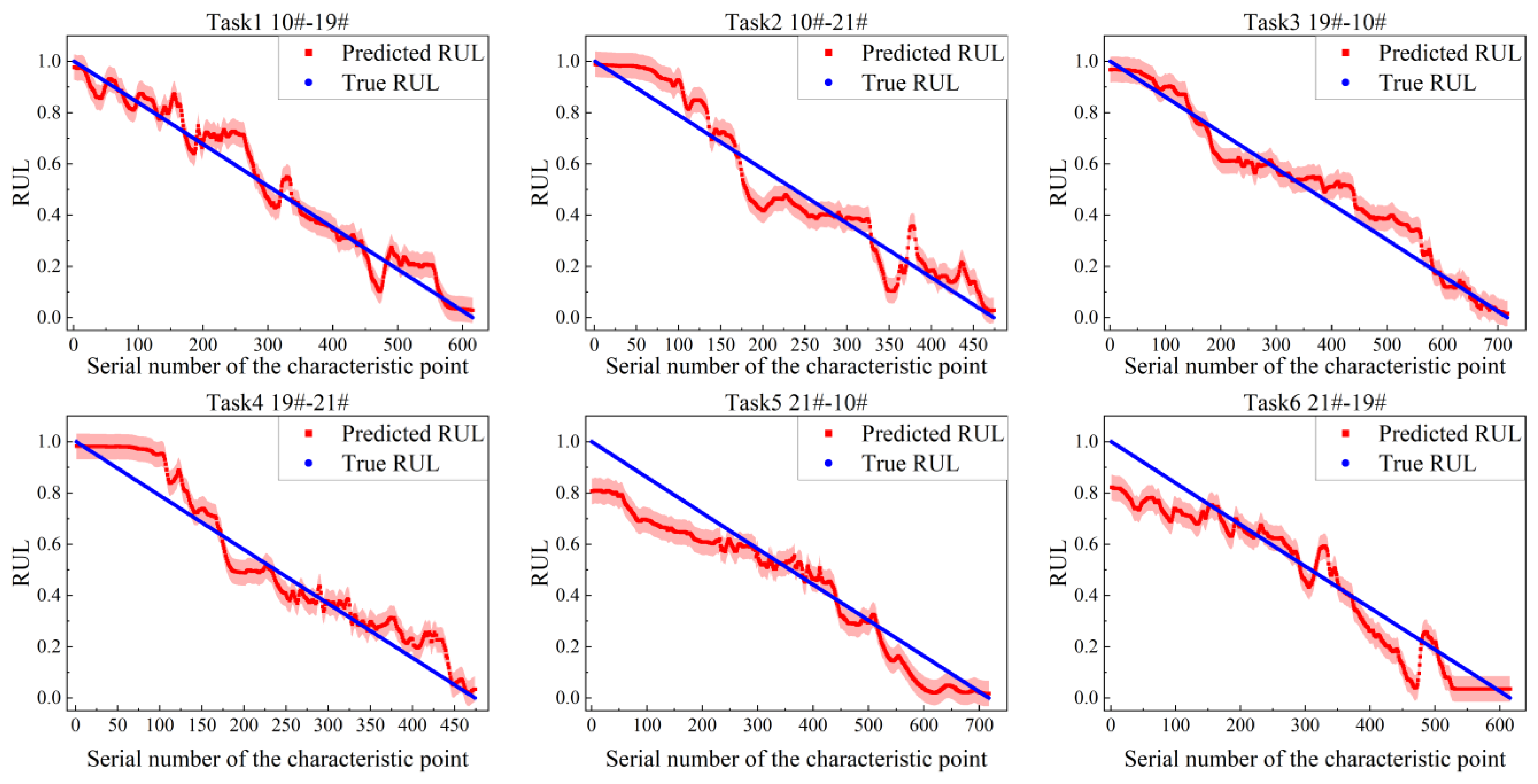
4.2. Results of Degradation State Divided and Prediction RUL
4.3. Ablation Experiment
4.4. Comparison with Other Methods
5. Conclusions
- (1)
- MDA-LETCN can effectively extract the degradation features of WT generator bearings from the run-to-failure data under composite working conditions and introduce DA to effectively improve the model’s prediction performance of target bearing RUL based on the differences in the degradation processes of each bearing. Through comparative experiments on the generator bearing data of WTs, the methods proposed in this paper, RMS, and MAE have the smallest and the highest scores, which are superior to the comparative methods.
- (2)
- In MDA-LETCN, unsupervised clustering is carried out on the extracted temporal features to adaptively classify the degradation state of generator bearings under composite working conditions, which can effectively improve the prediction effect of the model.
- (3)
- The MDSDM module measures and minimizes the distribution differences in different degradation stages, which can help the model learn the domain-invariant time-dependent features in different degradation stages. Ablation experiments have proved that the MDSDM module can effectively improve the prediction accuracy of the model under composite working conditions.
- (1)
- MDA-LETCN is a data-driven black-box model and, in our future work, we plan to introduce the mechanism model into the network to enhance the interpretability of the model.
- (2)
- Due to data reasons, this paper only studies the transfer learning prediction between NU1030M bearings. In future work, transfer learning tasks between different types of bearings will be studied to improve the robustness of the model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Sun, W.; Liu, L.; Wang, B.; Bao, S.; Jiang, R. Fault Diagnosis of Wind Turbine Planetary Gear Based on a Digital Twin. Appl. Sci. 2023, 13, 4776. [Google Scholar] [CrossRef]
- Wan, X.; Sun, W.; Chen, K.; Zhang, X. State Degradation Evaluation and Early Fault Identification of Wind Turbine Bearings. Fuel 2022, 311, 122348. [Google Scholar] [CrossRef]
- Tian, M.; Su, X.; Chen, C.; Luo, Y.; Sun, X. Bearing Fault Diagnosis of Wind Turbines Based on Dynamic Multi-Adversarial Adaptive Network. J. Mech. Sci. Technol. 2023, 37, 1637–1651. [Google Scholar] [CrossRef]
- Cao, L.; Zhang, H.; Meng, Z.; Wang, X. A Parallel GRU with Dual-Stage Attention Mechanism Model Integrating Uncertainty Quantification for Probabilistic RUL Prediction of Wind Turbine Bearings. Reliab. Eng. Syst. Saf. 2023, 235, 109197. [Google Scholar] [CrossRef]
- Wang, P.; Long, Z.; Wang, G. A Hybrid Prognostics Approach for Estimating Remaining Useful Life of Wind Turbine Bearings. Energy Rep. 2020, 6, 173–182. [Google Scholar] [CrossRef]
- Pandit, R.K.; Astolfi, D.; Durazo Cardenas, I. A Review of Predictive Techniques Used to Support Decision Making for Maintenance Operations of Wind Turbines. Energies 2023, 16, 1654. [Google Scholar] [CrossRef]
- Xu, L.; Pennacchi, P.; Chatterton, S. A New Method for the Estimation of Bearing Health State and Remaining Useful Life Based on the Moving Average Cross-Correlation of Power Spectral Density. Mech. Syst. Signal Process. 2020, 139, 106617. [Google Scholar] [CrossRef]
- Zhang, S.; Zhai, Q.; Li, Y. Degradation Modeling and RUL Prediction with Wiener Process Considering Measurable and Unobservable External Impacts. Reliab. Eng. Syst. Saf. 2023, 231, 109021. [Google Scholar] [CrossRef]
- Zhu, G.; Zhu, Z.; Xiang, L.; Hu, A.; Xu, Y. Prediction of Bearing Remaining Useful Life Based on DACN-ConvLSTM Model. Measurement 2023, 211, 112600. [Google Scholar] [CrossRef]
- Xiang, S.; Qin, Y.; Luo, J.; Wu, F.; Gryllias, K. A Concise Self-Adapting Deep Learning Network for Machine Remaining Useful Life Prediction. Mech. Syst. Signal Process. 2023, 191, 110187. [Google Scholar] [CrossRef]
- Qin, Y.; Yang, J.; Zhou, J.; Pu, H.; Mao, Y. A New Supervised Multi-Head Self-Attention Autoencoder for Health Indicator Construction and Similarity-Based Machinery RUL Prediction. Adv. Eng. Inform. 2023, 56, 101973. [Google Scholar] [CrossRef]
- Cheng, H.; Kong, X.; Wang, Q.; Ma, H.; Yang, S. The Two-Stage RUL Prediction across Operation Conditions Using Deep Transfer Learning and Insufficient Degradation Data. Reliab. Eng. Syst. Saf. 2022, 225, 108581. [Google Scholar] [CrossRef]
- Ranaldi, L.; Pucci, G. Knowing Knowledge: Epistemological Study of Knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]
- Xiang, S.; Zhou, J.; Luo, J.; Liu, F.; Qin, Y. Cocktail LSTM and Its Application Into Machine Remaining Useful Life Prediction. IEEE/ASME Trans. Mechatron. 2023, 28, 2425–2436. [Google Scholar] [CrossRef]
- Ni, Q.; Ji, J.C.; Feng, K. Data-Driven Prognostic Scheme for Bearings Based on a Novel Health Indicator and Gated Recurrent Unit Network. IEEE Trans. Ind. Inf. 2023, 19, 1301–1311. [Google Scholar] [CrossRef]
- Yang, L.; Liao, Y.; Duan, R.; Kang, T.; Xue, J. A Bidirectional Recursive Gated Dual Attention Unit Based RUL Prediction Approach. Eng. Appl. Artif. Intell. 2023, 120, 105885. [Google Scholar] [CrossRef]
- Deng, F.; Bi, Y.; Liu, Y.; Yang, S. Remaining Useful Life Prediction of Machinery: A New Multiscale Temporal Convolutional Network Framework. IEEE Trans. Instrum. Meas. 2022, 71, 2516913. [Google Scholar] [CrossRef]
- Qiu, H.; Niu, Y.; Shang, J.; Gao, L.; Xu, D. A Piecewise Method for Bearing Remaining Useful Life Estimation Using Temporal Convolutional Networks. J. Manuf. Syst. 2023, 68, 227–241. [Google Scholar] [CrossRef]
- Wang, W.; Zhou, G.; Ma, G.; Yan, X.; Zhou, P.; He, Z.; Ma, T. A Novel Competitive Temporal Convolutional Network for Remaining Useful Life Prediction of Rolling Bearings. IEEE Trans. Instrum. Meas. 2023, 72, 3523612. [Google Scholar] [CrossRef]
- Peng, H.; Jiang, B.; Mao, Z.; Liu, S. Local Enhancing Transformer with Temporal Convolutional Attention Mechanism for Bearings Remaining Useful Life Prediction. IEEE Trans. Instrum. Meas. 2023, 72, 3522312. [Google Scholar] [CrossRef]
- Li, N.; Xu, P.; Lei, Y.; Cai, X.; Kong, D. A Self-Data-Driven Method for Remaining Useful Life Prediction of Wind Turbines Considering Continuously Varying Speeds. Mech. Syst. Signal Process. 2022, 165, 108315. [Google Scholar] [CrossRef]
- Chen, J.; Huang, R.; Chen, Z.; Mao, W.; Li, W. Transfer Learning Algorithms for Bearing Remaining Useful Life Prediction: A Comprehensive Review from an Industrial Application Perspective. Mech. Syst. Signal Process. 2023, 193, 110239. [Google Scholar] [CrossRef]
- Ding, N.; Li, H.; Yin, Z.; Jiang, F. A Novel Method for Journal Bearing Degradation Evaluation and Remaining Useful Life Prediction under Different Working Conditions. Measurement 2021, 177, 109273. [Google Scholar] [CrossRef]
- Hu, T.; Guo, Y.; Gu, L.; Zhou, Y.; Zhang, Z.; Zhou, Z. Remaining Useful Life Estimation of Bearings under Different Working Conditions via Wasserstein Distance-Based Weighted Domain Adaptation. Reliab. Eng. Syst. Saf. 2022, 224, 108526. [Google Scholar] [CrossRef]
- Miao, M.; Yu, J. A Deep Domain Adaptative Network for Remaining Useful Life Prediction of Machines Under Different Working Conditions and Fault Modes. IEEE Trans. Instrum. Meas. 2021, 70, 3518214. [Google Scholar] [CrossRef]
- Hu, T.; Guo, Y.; Gu, L.; Zhou, Y.; Zhang, Z.; Zhou, Z. Remaining Useful Life Prediction of Bearings under Different Working Conditions Using a Deep Feature Disentanglement Based Transfer Learning Method. Reliab. Eng. Syst. Saf. 2022, 219, 108265. [Google Scholar] [CrossRef]
- Singh Rathore, M.; Harsha, S.P. Rolling Bearing Prognostic Analysis for Domain Adaptation under Different Operating Conditions. Eng. Fail. Anal. 2022, 139, 106414. [Google Scholar] [CrossRef]
- Li, X.; Teng, W.; Peng, D.; Ma, T.; Wu, X.; Liu, Y. Feature Fusion Model Based Health Indicator Construction and Self-Constraint State-Space Estimator for Remaining Useful Life Prediction of Bearings in Wind Turbines. Reliab. Eng. Syst. Saf. 2023, 233, 109124. [Google Scholar] [CrossRef]
- Cheng, Y.; Hu, K.; Wu, J.; Zhu, H.; Lee, C.K.M. A Deep Learning-Based Two-Stage Prognostic Approach for Remaining Useful Life of Rolling Bearing. Appl. Intell. 2022, 52, 5880–5895. [Google Scholar] [CrossRef]
- Qin, Y.; Zhou, J.; Chen, D. Unsupervised Health Indicator Construction by a Novel Degradation-Trend-Constrained Variational Autoencoder and Its Applications. IEEE/ASME Trans. Mechatron. 2022, 27, 1447–1456. [Google Scholar] [CrossRef]
- Ouyang, J.; Chi, C. The Prediction of Residual Electrical Life in Alternating Current Circuit Breakers Based on Savitzky-Golay-Long Short-Term. Appl. Sci. 2023, 23, 6860. [Google Scholar] [CrossRef]
- Ge, Y.; Ma, H.; Wang, L. On the smoothing explosion pressure curves using Savitzky-Golay method. J. Loss. Prev. Proc. 2022, 80, 104929. [Google Scholar] [CrossRef]
- Wan, S.; Li, X.; Zhang, Y.; Liu, S.; Hong, J.; Wang, D. Bearing Remaining Useful Life Prediction with Convolutional Long Short-Term Memory Fusion Networks. Reliab. Eng. Syst. Saf. 2022, 224, 108528. [Google Scholar] [CrossRef]
- Zhang, J.; Li, X.; Tian, J.; Jiang, Y.; Luo, H.; Yin, S. A Variational Local Weighted Deep Sub-Domain Adaptation Network for Remaining Useful Life Prediction Facing Cross-Domain Condition. Reliab. Eng. Syst. Saf. 2023, 231, 108986. [Google Scholar] [CrossRef]
- Zhang, H.-B.; Cheng, D.-J.; Zhou, K.-L.; Zhang, S.-W. Deep Transfer Learning-Based Hierarchical Adaptive Remaining Useful Life Prediction of Bearings Considering the Correlation of Multistage Degradation. Knowl. Based Syst. 2023, 266, 110391. [Google Scholar] [CrossRef]
- Li, H.; Cao, P.; Wang, X.; Yi, B.; Huang, M.; Sun, Q.; Zhang, Y. Multi-Task Spatio-Temporal Augmented Net for Industry Equipment Remaining Useful Life Prediction. Adv. Eng. Inform. 2023, 55, 101898. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Equations | Features | Equations |
|---|---|---|---|
| Peak | Kurtosis | ||
| Mean absolute value | Square root amplitude | ||
| Peak to peak | Crest factor | ||
| Root mean square(RMS) | Clearance factor | ||
| Standard deviation | Impulse factor | ||
| Skewness | Shape factor |
| Task | Source | Target |
|---|---|---|
| Task1 | 10# | 19# |
| Task2 | 10# | 21# |
| Task3 | 19# | 10# |
| Task4 | 19# | 21# |
| Task5 | 21# | 10# |
| Task6 | 21# | 19# |
| LETCN + MDSDM | LETCN + DA | TCN + MDSDM + DA | MDA-LETCN | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | Score | RMSE | MAE | Score | RMSE | MAE | Score | RMSE | MAE | Score | |
| Task1 | 0.154 | 0.145 | 0.307 | 0.148 | 0.127 | 0.238 | 0.122 | 0.108 | 0.304 | 0.063 | 0.048 | 0.494 |
| Task2 | 0.127 | 0.118 | 0.275 | 0.176 | 0.143 | 0.201 | 0.127 | 0.114 | 0.353 | 0.077 | 0.066 | 0.399 |
| Task3 | 0.177 | 0.159 | 0.278 | 0.139 | 0.124 | 0.256 | 0.119 | 0.095 | 0.411 | 0.056 | 0.044 | 0.554 |
| Task4 | 0.167 | 0.144 | 0.233 | 0.181 | 0.169 | 0.198 | 0.164 | 0.137 | 0.301 | 0.084 | 0.068 | 0.403 |
| Task5 | 0.159 | 0.136 | 0.254 | 0.172 | 0.158 | 0.224 | 0.157 | 0.135 | 0.396 | 0.069 | 0.056 | 0.545 |
| Task6 | 0.154 | 0.139 | 0.273 | 0.153 | 0.136 | 0.191 | 0.124 | 0.123 | 0.388 | 0.064 | 0.052 | 0.475 |
| Average | 0.154 | 0.145 | 0.307 | 0.162 | 0.143 | 0.218 | 0.136 | 0.119 | 0.359 | 0.069 | 0.056 | 0.478 |
| CLSTM | VLSTM-LWSAN | TLHAM | MTSTAN | MDA-LETCN | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | Score | RMSE | MAE | Score | RMSE | MAE | Score | RMSE | MAE | Score | RMSE | MAE | Score | |
| Task1 | 0.247 | 0.229 | 0.105 | 0.202 | 0.184 | 0.208 | 0.181 | 0.165 | 0.234 | 0.231 | 0.217 | 0.138 | 0.063 | 0.048 | 0.494 |
| Task2 | 0.243 | 0.212 | 0.112 | 0.165 | 0.143 | 0.243 | 0.169 | 0.147 | 0.282 | 0.194 | 0.177 | 0.194 | 0.077 | 0.066 | 0.399 |
| Task3 | 0.233 | 0.209 | 0.147 | 0.191 | 0.177 | 0.258 | 0.172 | 0.153 | 0.279 | 0.205 | 0.195 | 0.151 | 0.056 | 0.044 | 0.554 |
| Task4 | 0.227 | 0.201 | 0.162 | 0.142 | 0.136 | 0.267 | 0.155 | 0.140 | 0.301 | 0.166 | 0.152 | 0.216 | 0.084 | 0.068 | 0.403 |
| Task5 | 0.235 | 0.214 | 0.131 | 0.189 | 0.168 | 0.242 | 0.176 | 0.144 | 0.265 | 0.186 | 0.163 | 0.180 | 0.069 | 0.056 | 0.545 |
| Task6 | 0.215 | 0.199 | 0.188 | 0.137 | 0.119 | 0.261 | 0.164 | 0.151 | 0.299 | 0.178 | 0.154 | 0.234 | 0.064 | 0.052 | 0.475 |
| Average | 0.233 | 0.211 | 0.141 | 0.171 | 0.155 | 0.247 | 0.170 | 0.150 | 0.277 | 0.193 | 0.176 | 0.186 | 0.069 | 0.056 | 0.478 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, M.; Su, X.; Chen, C.; An, W. A Novel Method for Multistage Degradation Predicting the Remaining Useful Life of Wind Turbine Generator Bearings Based on Domain Adaptation. Appl. Sci. 2023, 13, 12332. https://doi.org/10.3390/app132212332
Tian M, Su X, Chen C, An W. A Novel Method for Multistage Degradation Predicting the Remaining Useful Life of Wind Turbine Generator Bearings Based on Domain Adaptation. Applied Sciences. 2023; 13(22):12332. https://doi.org/10.3390/app132212332
Chicago/Turabian StyleTian, Miao, Xiaoming Su, Changzheng Chen, and Wenjie An. 2023. "A Novel Method for Multistage Degradation Predicting the Remaining Useful Life of Wind Turbine Generator Bearings Based on Domain Adaptation" Applied Sciences 13, no. 22: 12332. https://doi.org/10.3390/app132212332