

Multi-Agent Collaborative Target Search Based on the Multi-Agent Deep Deterministic Policy Gradient with Emotional Intrinsic Motivation


Abstract
:1. Introduction
2. Background
- The optimal policy obtained by learning only needs to use the local information to take the optimal action.
- The environment and special communication requirements are not needed.
- The algorithm can be used not only in a cooperative environment but also in a competitive environment.
3. Methods
3.1. The MADDPG-E Algorithm Framework
- is the set of the state space, represents the k-th state of the agent, and m represents the state number of the agent. All agents share the same state space.
- is the set of the multi-agent observation space, and N is the agent’s number. In each episode, every agent observes the state of the environment through perception, and the agent can obtain the position of obstacles, its own position, the position of other agents, and the position of the target within its detectable range.
- is the set of the multi-agent action space, is the action of the agent N, and it is mainly related to speed and direction. Then, the action of the agent N at time is expressed aswhere is the movement angle of the agent at time , is the change rate of the agent’s motion angle, is the movement speed of the agent at time , and is the acceleration.
- is the set of environmental rewards. All agents share the same environment rewards set. The agent is rewarded for moving to the target location and punished for colliding with the obstacles or bounds. A dynamic penalty function is set for the collision between agents, which can prevent the occurrence of unsafe states to the greatest extent. By setting environmental rewards, agents can learn to move toward the direction with the largest reward value and adopt the search strategy with the largest cumulative reward to help agents search for the target faster. At each time step, the agent changes its state and receives a reward from the environment. The environmental reward function in this paper is designed as follows:
- , if the agent has searched the target.
- , if the agent collides with an obstacle.
- , if an agent collides with another agent. is the collision penalty factor, and is the positions of the agent i at time t.
- , if , which represents the agent colliding with the bounds.
- is the average value of the rewards obtained by N agents at the time t and is the overall reward of the multi-agent system in the collaborative target search process. The formula is as follows:where is the location of the target at the time t. is the emotional intrinsic motivation reward of agent i. is the environmental reward of agent i at the time t.
- M stands for the memory module, which stores the collected experience with an experience playback array, each of which is a quadruplet as follows:where is the observed state of agent N at time t. is the action chosen by the agent N at time t.
3.2. Emotional Intrinsic Motivation Module
- State 1: It means that the agents search the target;
- State 2: It means that the agents do not search the target;
- State 3: It means that the agents are in danger, such as a collision.
4. Simulation Experiment
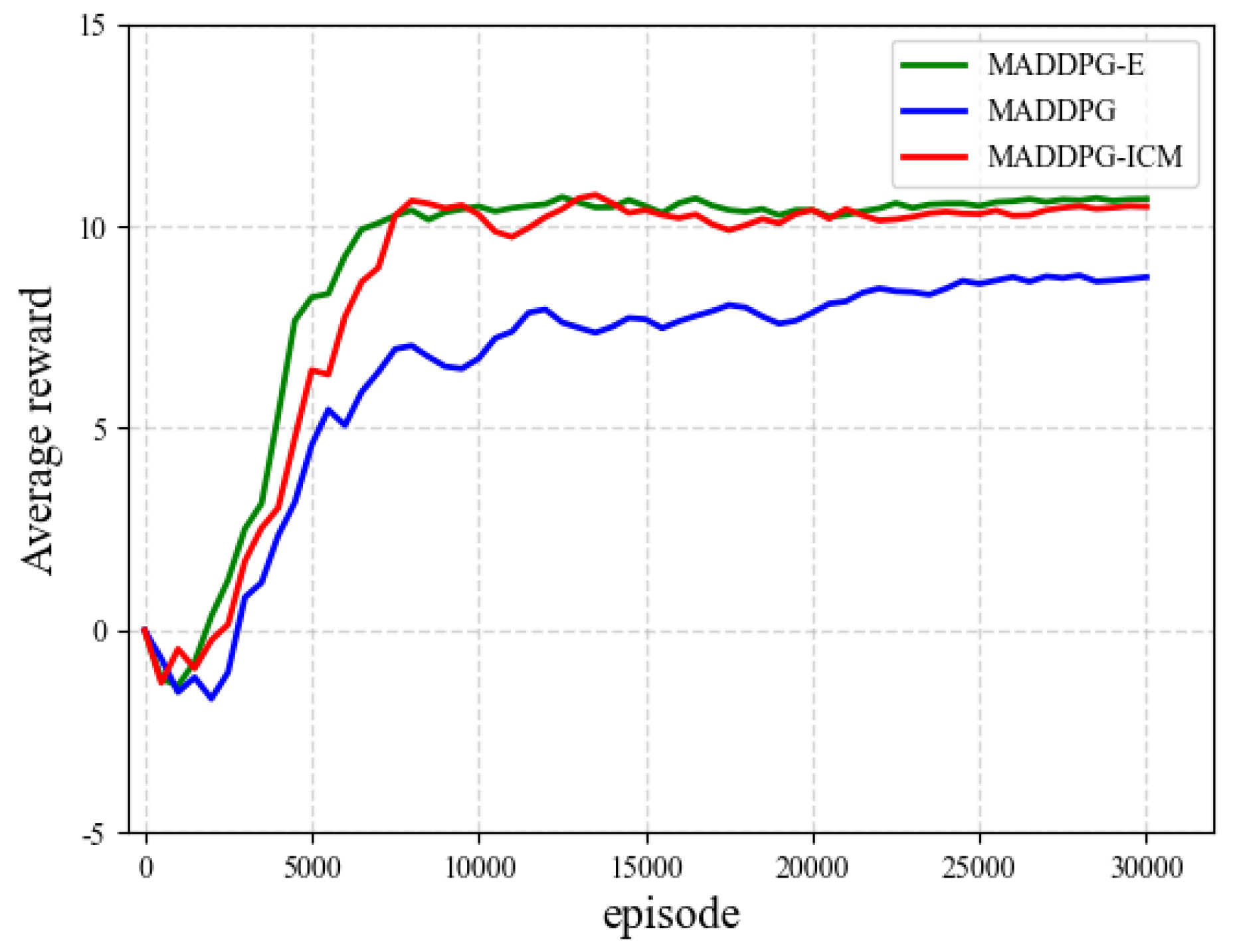
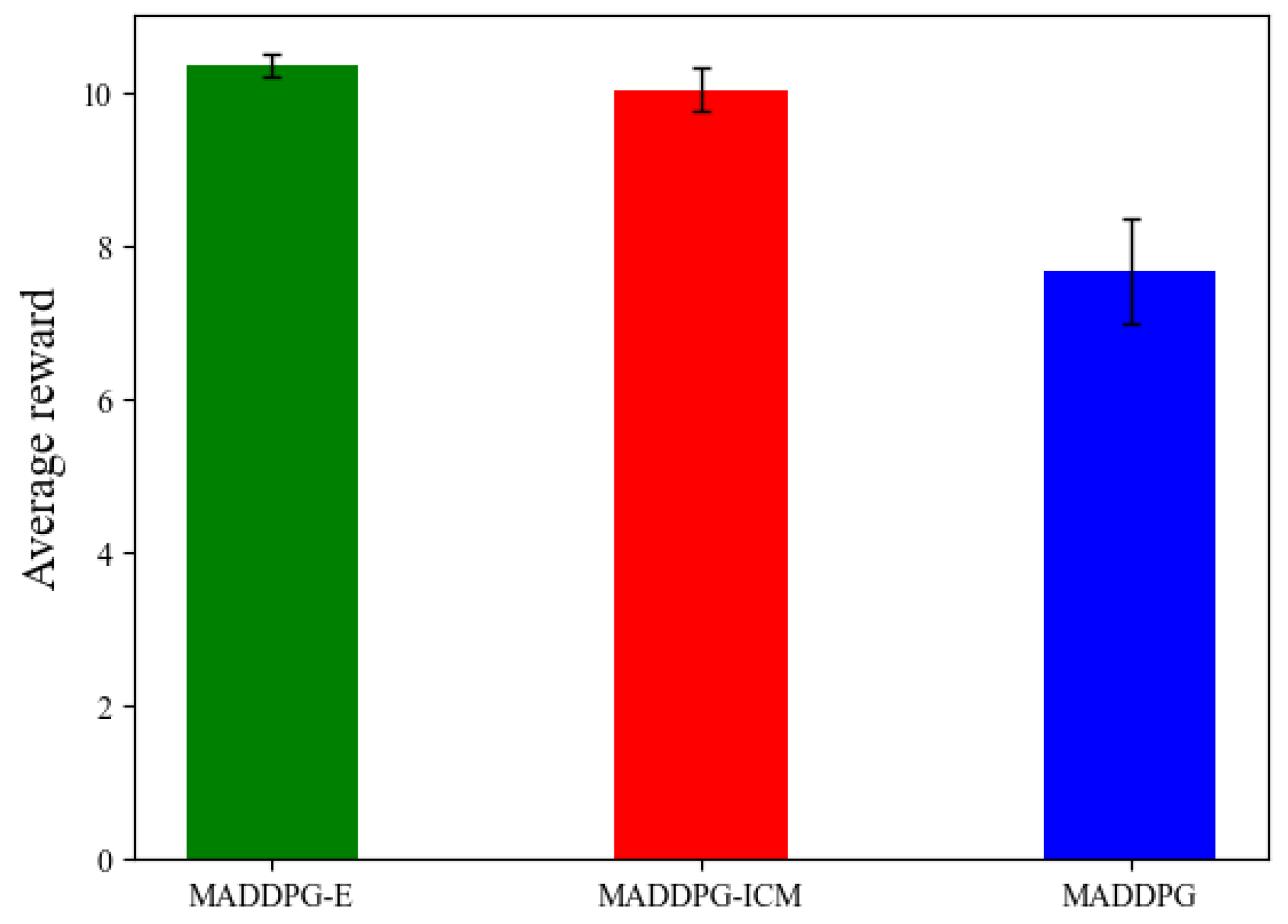
4.1. Experiment 1: Fixed Initial Position
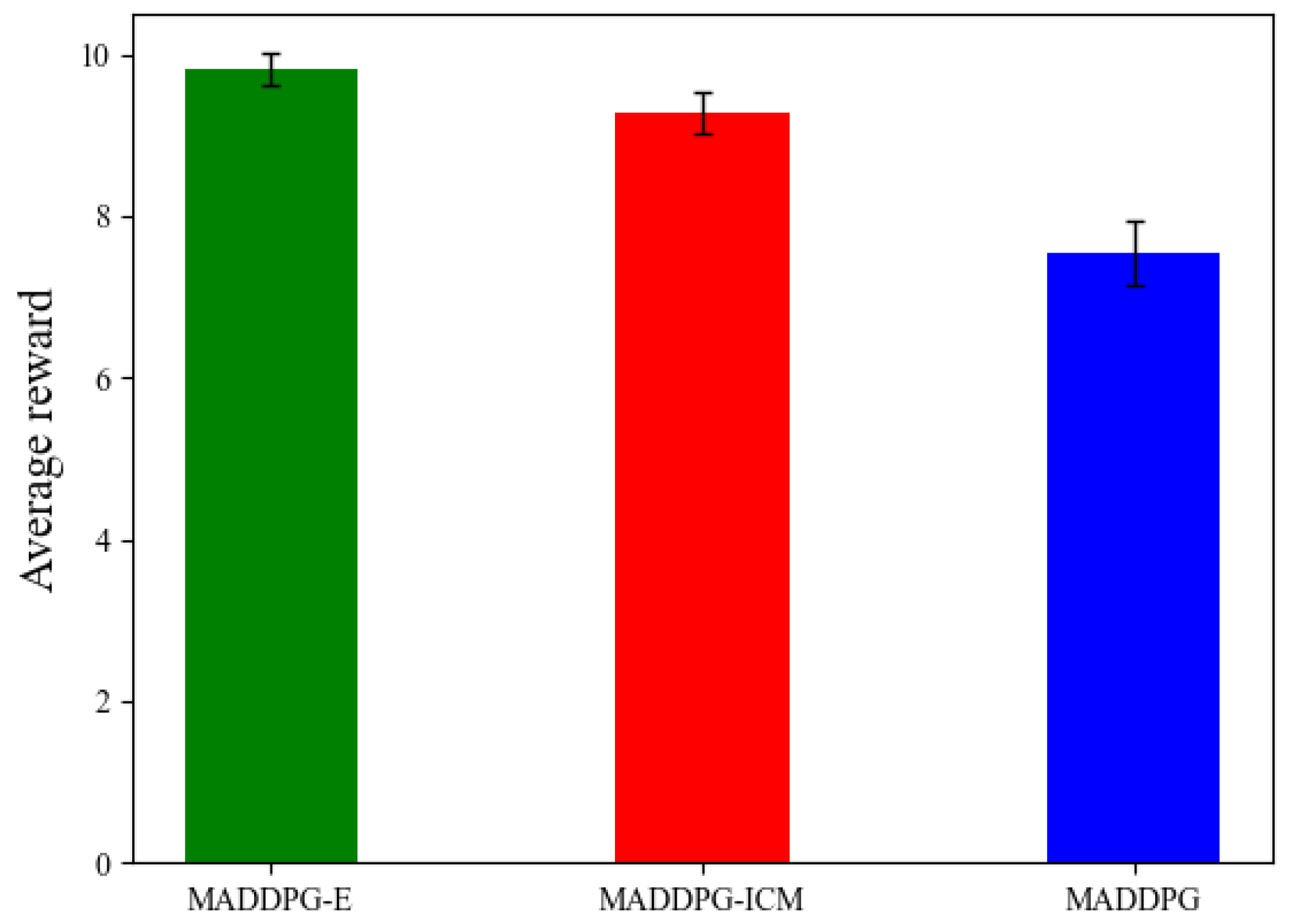
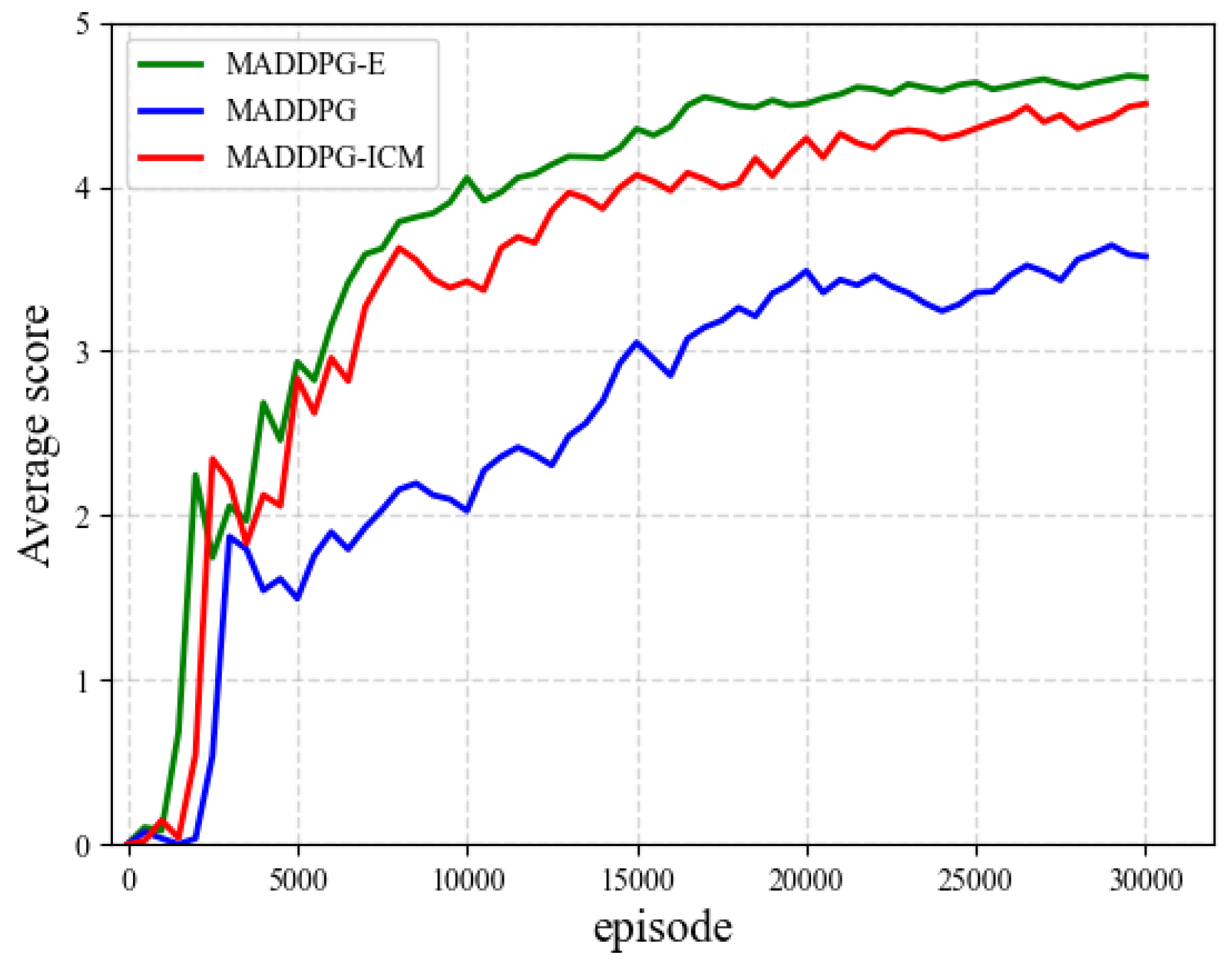
4.2. Experiment 2: Random Initial Position
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Amirkhani, A.; Barshooi, A.H. Consensus in multi-agent systems: A review. Artif. Intell. Rev. 2022, 55, 3897–3935. [Google Scholar] [CrossRef]
- Li, Y.; Xu, F.; Xie, G.; Huang, X. Survey of development and application of multi-agent technology. Comput. Eng. Appl. 2018, 54, 13–21. [Google Scholar]
- Cai, Y.; Shen, Y. An integrated localization and control framework for multi-agent formation. IEEE Trans. Signal Process. 2019, 67, 1941–1956. [Google Scholar] [CrossRef]
- Han, W.; Zhang, B.; Wang, Q.; Luo, J.; Ran, W.; Xu, Y. A multi-agent based intelligent training system for unmanned surface vehicles. Appl. Sci. 2019, 9, 1089. [Google Scholar] [CrossRef]
- Liu, X.; Yu, J.; Feng, Z.; Gao, Y. Multi-agent reinforcement learning for resource allocation in IoT networks with edge computing. China Commun. 2020, 17, 220–236. [Google Scholar] [CrossRef]
- He, Z.; Dong, L.; Song, C.; Sun, C. Multiagent Soft Actor-Critic Based Hybrid Motion Planner for Mobile Robots. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Zhou, X.; Zhou, S.; Mou, X.; He, Y. Multirobot Collaborative Pursuit Target Robot by Improved MADDPG. Comput. Intell. Neurosci. 2022, 2022, 4757394. [Google Scholar] [CrossRef]
- Senanayake, M.; Senthooran, I.; Barca, J.C.; Chung, H.; Kamruzzaman, J.; Murshed, M. Search and tracking algorithms for swarms of robots: A survey. Robot. Auton. Syst. 2016, 75, 422–434. [Google Scholar] [CrossRef]
- Hazra, T.; Kumar, C.S.; Nene, M. Multi-agent target searching with time constraints using game-theoretic approaches. Kybernetes 2017, 46, 1278–1302. [Google Scholar] [CrossRef]
- Cooper, J.R. Optimal multi-agent search and rescue using potential field theory. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 0879. [Google Scholar]
- Tang, H.; Sun, W.; Yu, H.; Lin, A.; Xue, M. A multirobot target searching method based on bat algorithm in unknown environments. Expert Syst. Appl. 2020, 141, 112945. [Google Scholar] [CrossRef]
- Wu, Z.; Xie, Z. A multi-objective lion swarm optimization based on multi-agent. J. Ind. Manag. Optim. 2023, 19, 1447–1458. [Google Scholar] [CrossRef]
- Shapero, S.A.; Hughes, H.; Tuuk, P. Adaptive semi-greedy search for multidimensional track assignment. In Proceedings of the 2016 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016; pp. 409–415. [Google Scholar]
- Teatro, T.A.; Eklund, J.M.; Milman, R. Nonlinear model predictive control for omnidirectional robot motion planning and tracking with avoidance of moving obstacles. Can. J. Electr. Comput. Eng. 2014, 37, 151–156. [Google Scholar] [CrossRef]
- Sun, L.; Chang, Y.C.; Lyu, C.; Shi, Y.; Shi, Y.; Lin, C.T. Toward multi-target self-organizing pursuit in a partially observable Markov game. arXiv 2022, arXiv:2206.12330. [Google Scholar] [CrossRef]
- Wang, G.; Wei, F.; Jiang, Y.; Zhao, M.; Wang, K.; Qi, H. A Multi-AUV Maritime Target Search Method for Moving and Invisible Objects Based on Multi-Agent Deep Reinforcement Learning. Sensors 2022, 22, 8562. [Google Scholar] [CrossRef]
- Gupta, J.K.; Egorov, M.; Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. In Proceedings of the Autonomous Agents and Multiagent Systems: AAMAS 2017 Workshops, Best Papers, São Paulo, Brazil, 8–12 May 2017; Revised Selected Papers 16. Springer: Berlin/Heidelberg, Germany, 2017; pp. 66–83. [Google Scholar]
- Cao, X.; Lu, T.; Cai, Y. Intrinsic Motivation for Deep Deterministic Policy Gradient in Multi-Agent Environments. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 1628–1633. [Google Scholar]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Tampuu, A.; Matiisen, T.; Kodelja, D.; Kuzovkin, I.; Korjus, K.; Aru, J.; Aru, J.; Vicente, R. Multiagent cooperation and competition with deep reinforcement learning. PLoS ONE 2017, 12, e0172395. [Google Scholar] [CrossRef] [PubMed]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30, 6379–6390. [Google Scholar]
- Song, J.; Ren, H.; Sadigh, D.; Ermon, S. Multi-Agent Generative Adversarial Imitation Learning. arXiv 2018, arXiv:1807.09936. [Google Scholar]
- Parisi, S.; Tateo, D.; Hensel, M.; D’eramo, C.; Peters, J.; Pajarinen, J. Long-Term Visitation Value for Deep Exploration in Sparse-Reward Reinforcement Learning. Algorithms 2022, 15, 81. [Google Scholar] [CrossRef]
- Perovic, G.; Li, N. Curiosity driven deep reinforcement learning for motion planning in multi-agent environment. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 375–380. [Google Scholar]
- Loyola, O.; Kern, J.; Urrea, C. Novel Algorithm for Agent Navigation Based on Intrinsic Motivation Due to Boredom. Inf. Technol. Control 2021, 50, 485–494. [Google Scholar] [CrossRef]
- Sequeira, P.; Melo, F.S.; Paiva, A. Emotion-based intrinsic motivation for reinforcement learning agents. In Proceedings of the Affective Computing and Intelligent Interaction: 4th International Conference, ACII 2011, Memphis, TN, USA, 9–12 October 2011; Proceedings, Part I 4. Springer: Berlin/Heidelberg, Germany, 2011; pp. 326–336. [Google Scholar]
- Starzyk, J.A. Motivation in Embodied Intelligence; INTECH Open Access Publisher: London, UK, 2008. [Google Scholar]
- Barto, A.G.; Singh, S.; Chentanez, N. Intrinsically motivated learning of hierarchical collections of skills. In Proceedings of the 3rd International Conference on Development and Learning, La Jolla, CA, USA, 20–22 October 2004; Volume 112, p. 19. [Google Scholar]
- Oudeyer, P.Y.; Kaplan, F.; Hafner, V.V. Intrinsic motivation systems for autonomous mental development. IEEE Trans. Evol. Comput. 2007, 11, 265–286. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-driven exploration by self-supervised prediction. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2778–2787. [Google Scholar]
- Barrett, L.F.; Lindquist, K.A. The embodiment of emotion. In Embodied Grounding: Social, Cognitive, Affective, and Neuroscientific Approaches; Cambridge University Press: Cambridge, UK, 2008; pp. 237–262. [Google Scholar]
- Duffy, E. Is emotion a mere term of convenience? Psychol. Rev. 1934, 41, 103. [Google Scholar] [CrossRef]
- Young, P.T. Emotion in Man and Animal; Its Nature and Relation to Attitude and Motive; APA PsycInfo: Washington, DC, USA, 1943. [Google Scholar]
- Huang, X.; Wu, W.; Qiao, H. Computational modeling of emotion-motivated decisions for continuous control of mobile robots. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 31–44. [Google Scholar] [CrossRef]
- Feldmaier, J.; Diepold, K. Path-finding using reinforcement learning and affective states. In Proceedings of the The 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, Scotland, 25–29 August 2014; pp. 543–548. [Google Scholar]
- Fang, B.; Guo, X.; Wang, Z.; Li, Y.; Elhoseny, M.; Yuan, X. Collaborative task assignment of interconnected, affective robots towards autonomous healthcare assistant. Future Gener. Comput. Syst. 2019, 92, 241–251. [Google Scholar] [CrossRef]
- Guzzi, J.; Giusti, A.; Gambardella, L.M.; Di Caro, G.A. Artificial emotions as dynamic modulators of individual and group behavior in multi-robot system. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, Stockholm, Sweden, 10–15 July 2018; pp. 2189–2191. [Google Scholar]
- Achiam, J.; Sastry, S. Surprise-based intrinsic motivation for deep reinforcement learning. arXiv 2017, arXiv:1703.01732. [Google Scholar]
- Yu, H.; Yang, P. An emotion-based approach to reinforcement learning reward design. In Proceedings of the 2019 IEEE 16th International Conference on Networking, Sensing and Control (ICNSC), Banff, AB, Canada, 9–11 May 2019; pp. 346–351. [Google Scholar]
- Ekman, P. Basic emotions. In Handbook of Cognition and Emotion; John Wiley & Sons: Hoboken, NJ, USA, 1999; Volume 98, p. 16. [Google Scholar]
- Frijda, N.H.; Kuipers, P.; Ter Schure, E. Relations among emotion, appraisal, and emotional action readiness. J. Personal. Soc. Psychol. 1989, 57, 212. [Google Scholar] [CrossRef]
- pzhokhov. Multiagent-Particle-Envs. 2017. Available online: https://github.com/openai/multiagent-particle-envs (accessed on 11 September 2023).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Emotional Motivation |
|---|---|
| The agents search the target | Joy |
| The agents do not search the target | Sadness |
| The agents are in danger, such as a collision | Fear |
| Training Parameter | Values |
|---|---|
| Total number of episodes | 30,000 |
| Maximum episode length | 50 |
| Discount factor | 0.98 |
| Actor network learning rate | 0.01 |
| Critic network learning rate | 0.01 |
| Batch size | 1024 |
| Size of replay buffer M |
| Elements | Initial Positions 1 | Initial Positions 2 |
|---|---|---|
| Agent1 | [−0.60, 0.30] | [0.45, −0.15] |
| Agent2 | [0.00, 0.50] | [0.60, 0.60] |
| Agent3 | [0.50, −0.20] | [0.65, −0.52] |
| Target | [0.00, 0.10] | [0.65, 0.00] |
| Obstacle1 | [−0.10, −0.15] | [0.40, 0.45] |
| Obstacles2 | [0.55, 0.55] | [0.40, −0.55] |
| Algorithm | Average Reward | Average Score | Target Search Time |
|---|---|---|---|
| MADDPG-E | 8.94 | 3.67 | 3.84 |
| MADDPG-ICM | 8.55 | 3.59 | 4.28 |
| MADDPG | 6.45 | 2.68 | 4.73 |
| Algorithm | Average Reward | Average Score | Target Search Time |
|---|---|---|---|
| MADDPG-E | 9.26 | 3.79 | 3.68 |
| MADDPG-ICM | 8.63 | 3.46 | 4.12 |
| MADDPG | 6.83 | 2.54 | 4.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zheng, Y.; Wang, L.; Abdulali, A.; Iida, F. Multi-Agent Collaborative Target Search Based on the Multi-Agent Deep Deterministic Policy Gradient with Emotional Intrinsic Motivation. Appl. Sci. 2023, 13, 11951. https://doi.org/10.3390/app132111951
Zhang X, Zheng Y, Wang L, Abdulali A, Iida F. Multi-Agent Collaborative Target Search Based on the Multi-Agent Deep Deterministic Policy Gradient with Emotional Intrinsic Motivation. Applied Sciences. 2023; 13(21):11951. https://doi.org/10.3390/app132111951
Chicago/Turabian StyleZhang, Xiaoping, Yuanpeng Zheng, Li Wang, Arsen Abdulali, and Fumiya Iida. 2023. "Multi-Agent Collaborative Target Search Based on the Multi-Agent Deep Deterministic Policy Gradient with Emotional Intrinsic Motivation" Applied Sciences 13, no. 21: 11951. https://doi.org/10.3390/app132111951