1. Introduction
As deep learning is widely used in various IoT (Internet-of-Things) services [
1,
2], the demand for AI (artificial intelligence) technologies in the mobile edge environment is continuously increasing [
3,
4]. Specifically, there is an increasing trend to run deep learning workloads using virtualized environments such as virtual machines and containers. This is because virtualization has the effect of improving computational elasticity and efficiency, which are important considerations in deep learning workloads [
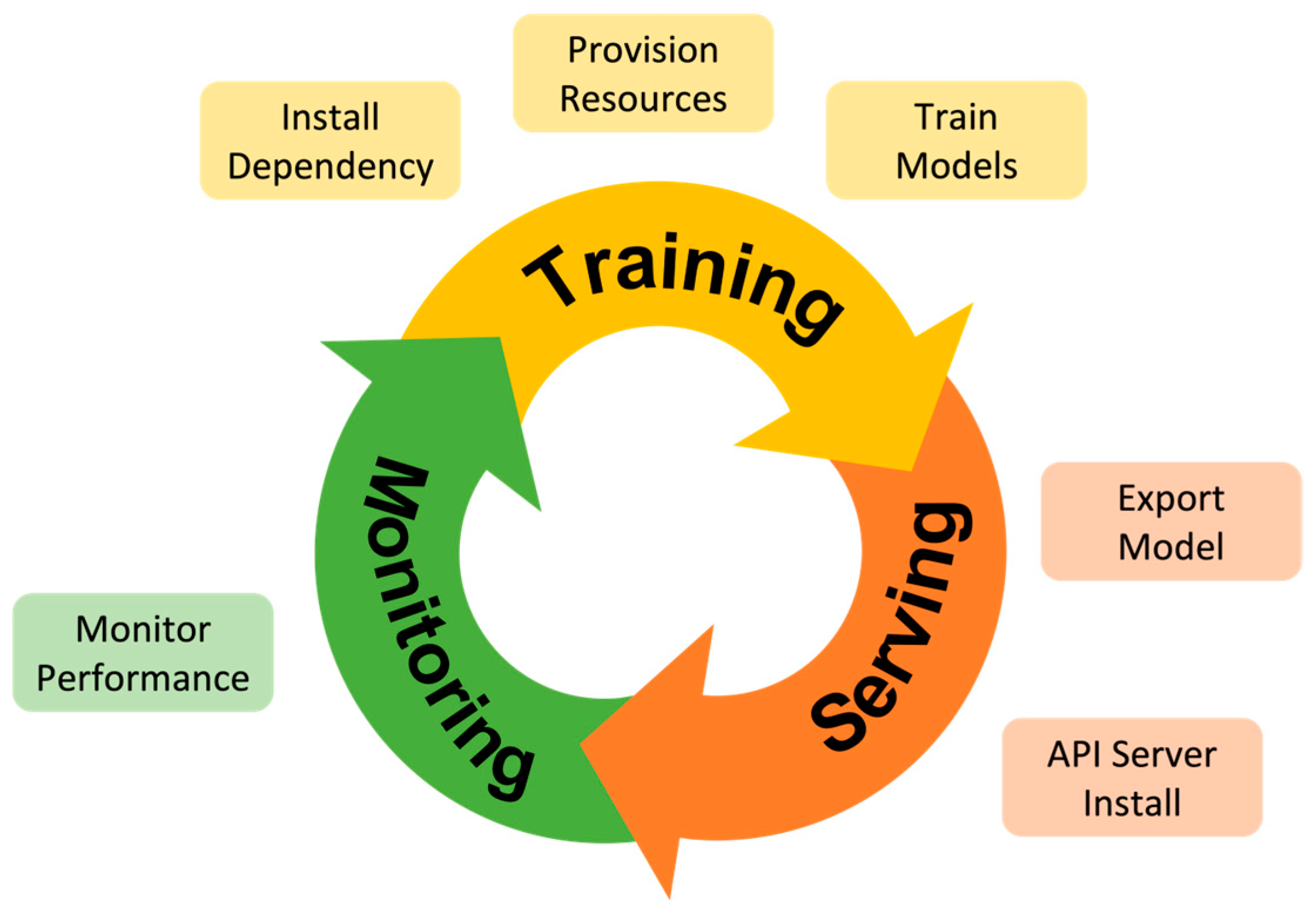
3]. The execution cycle of a deep learning workload can be divided into three phases: training, servicing, and monitoring, as shown in
Figure 1. During the training phase, users need to install the configuration for the framework, provision the required computing resources, and then proceed with training. When training is complete, the model is exported and the API server is installed. The model is then deployed for service. In the service phase, users should monitor the model’s performance to determine whether the model is overfitting or underfitting the training data. When the model’s performance degrades, the user must train the model again. Therefore, configuring and managing deep learning infrastructure is a complicated and time-consuming task. All of these steps can be performed in the data center or cloud, but some tasks such as data collection and post-training monitoring are increasingly shifted to the edge side. Reducing energy consumption and privacy risks is important in mobile edge as continuous training is performed by using data collected from mobile devices and sensors [
5]. Container-based deep learning has been introduced to provide such features in a managed service [
6,
7].
Containers provide several merits compared to traditional virtual machines for running deep learning workloads. That is, containers are lightweight and portable, so it is easy to deploy and manage containerized deep learning workloads. Containers also share the host OS, thereby minimizing the virtualization overhead. Thus, containers are efficient for compute-intensive deep learning workloads that require heavy resources. Another important merit of a container is that it provides easy management for configuration settings. In a virtual machine platform, each guest machine should have its own configuration files, thus keeping track of changes and ensuring the configurations are difficult. Moreover, in container environments, it is easy to recreate the same environments and dependencies used to train and deploy models. In contrast, in virtual machine environments, each guest machine has a set of dependencies, so recreating the same environment on another machine is not simple [
8].
Despite these advantages, using containers to run deep learning workloads also presents some challenges. One of the biggest challenges is that containers are less isolated than virtual machines. This means that performance degradation is more likely to occur due to resource conflicts [
9]. For example, if two containers try to access the same resource, a performance conflict may occur. Since containers share the host OS, they compete for system resources and need careful resource management techniques to prevent performance degradation. Fortunately, the overhead of containerization is not significant in traditional workloads. For example, running multiplayer gaming and video streaming workloads in a containerized edge environment incurs only a small amount of Docker overhead without affecting data processing in each container [
10]. Also, as containers are frequently used for application deployment, network resources become a major bottleneck due to the large amount of data transfer between nodes [
11]. However, this is not the case for deep learning workloads, which are resource-intensive and require more computation than communication [
12]. Thus, containerization may introduce other resource bottlenecks such as CPU, memory, and storage. As deep learning is increasingly used in image processing in various service fields such as manufacturing and medicine, the importance of efficient resource management in containerized deep learning continues to grow [
13,
14].
Moreover, deep learning workloads have different resource usage patterns from traditional workloads, making efficient resource management more difficult [
15,
16]. Traditional workloads often have consistent resource usage patterns. For example, web servers or database servers repeatedly process the same tasks, such as http requests or query processing, so the number of requests varies, but the characteristics of the workload are uniform, making it relatively easy to cope with resource requirements [
17]. In contrast, deep learning workloads are known to have very different resource usage patterns during the training and inference phases [
18]. In the training phase, the model is learned on the data set, and the parameters are updated. During this process, resource usage may show sudden spiky patterns. On the other hand, the inference phase uses models to predict new data and resource usage is not high and is relatively uniform.
It has been reported that deep learning workloads temporarily cause excessive memory usage during the training phase and that the bias in data accessed is weaker than traditional workloads because they rely less on hot data [
19]. These characteristics make resource management more difficult compared to traditional workloads. Specifically, due to the spiky and bursty nature of memory usage in deep learning workloads, performance can rapidly deteriorate if insufficient memory space is allocated. However, equipping a large memory capacity to handle such situations will waste resources in the remaining time. So resource allocation that allows each container to run smoothly without over-allocation is a challenging issue. In addition, weak bias in data access makes it more difficult to design efficient caching mechanisms and limits performance gains through caching. Comprehensively monitoring data access patterns can be helpful in identifying and remediating resource usage issues. In particular, extracting and analyzing system traces from the host layer provides precise resource usage for each container, allowing for better resource allocation by accurately characterizing container workloads.
In this article, we investigate the resource requirements in the context of containerized deep learning workloads and aim to find performance implications for such environments. To do this, we extract and analyze the event traces of deep learning workloads in container environments and compare them to traces collected by running the same workloads on host systems. By doing so, we can see the impact of containerization in deep learning with respect to resource contention and performance overhead. We also investigate the impact of multi-tenancy by running deep learning workloads simultaneously in different containers to highlight challenges in resource management issues.
By analyzing system calls and event traces generated by container-based deep learning workloads, we provide implications for resource management in a containerized environment. Specifically, we observe that write-back operations to storage can be a major cause of performance bottlenecks. We also show that resource contention is significant in multi-tenant environments. To cope with this situation, we introduce a preliminary solution that adopts an intermediate non-volatile flushing layer to alleviate the performance bottleneck of storage write-backs. Instead of flushing to traditional storage, our solution effectively hides the write-back overhead by absorbing hot data in fast NVM media, improving I/O latency by 82% on average.
The remainder of this article is organized as follows.
Section 2 briefly summarizes previous studies related to this article. In
Section 3, we describe the experimental configurations of deep learning workloads to investigate the performance effect of container platforms.
Section 4 analyzes the event traces captured and discusses their implications. In
Section 5, we introduce our solution to cope with the performance bottleneck of containerized deep learning. Finally,
Section 6 concludes this article.
2. Related Work
In this section, we briefly summarize previous research on deep learning workload characterization and container-based systems. We also review techniques proposed to improve the performance of such systems.
Recently, research has been conducted to characterize deep learning workloads in terms of reference patterns and resource usage. Park et al. comprehensively analyze memory reference patterns for neural network workloads and observe that they are significantly different from traditional workloads [
19]. In particular, their analysis shows that the heap and data regions account for most memory references in deep learning workloads, but the memory reference bias is weaker than in traditional workloads, especially for write operations.
Berral et al. explored resource usage characteristics of containers used to train deep learning models [
12]. They identify recurring patterns and similarities across containers and suggest the potential to optimize resource allocation in a dedicated deep-learning cluster. Specifically, they utilize clustering techniques and conditional restricted Boltzmann machines to discover action steps during deep learning training. They also optimize resource allocation by dynamically adjusting container resources based on phase-specific statistical information. However, their approach only addresses resource allocation and overlooks communication considerations. Also, their methods are only effective for deep learning workloads with repetitive resource usage patterns and require sufficient historical data and clustering training.
Xu et al. investigated the effectiveness of Docker containers as a means to simplify the deployment and management of deep learning workloads [
20]. In particular, they evaluate the impact of Docker containers on the performance of deep learning workloads. Their findings indicate that both CPU- and GPU-intensive tasks exhibit minimal overhead when running inside Docker containers. This means that Docker containers can be used for deep learning workloads without significant performance degradation. However, it is important to note that their study only evaluates the performance of Docker containers on specific hardware types, so different hardware configurations are likely to produce different performance results. As a result, further research is needed to evaluate Docker container performance across different hardware types and deep learning frameworks [
20].
Bae et al. investigated the performance of Intel-Caffe, a distributed deep learning framework, on the Nurion supercomputers. Specifically, they focus on identifying the file I/O factors that affect the performance of Intel-Caffe in a container-based environment [
21]. They observed that although the training phase of deep learning in a container-based environment has minimal overhead, page cache has a significant impact on the performance of deep learning frameworks.
Janecek et al. analyzed container workload characteristics by collecting system trace data from host systems [
22]. Specifically, they classified containers based on their resource usage and behavior and identified idle containers in order to efficiently manage container clusters. However, their experiments use benchmarking tools to generate test data, which may not be representative of real AI workloads.
Zhang et al. explored resource consumption of containerized workloads on edge servers, with a particular focus on CPU resources, which are heavily consumed by container management and inter-container communication by daemon processes [
23]. They present custom containers to improve CPU efficiency and evaluate the effectiveness of the algorithm based on specific metrics such as inter-container transfers, number of container starts, and application execution duration. Since their research focuses on CPU resources for network communication, additional considerations will be needed for deep learning workloads, where memory is another important bottleneck.
Avino et al. also performed a similar analysis to quantify the overhead of containerization in edge environments [
10]. They showed that containerization incurs small CPU overhead without affecting the data processing of each container. However, their target workload is multimedia streaming and is not related to deep learning.
Recently, Rauschmayr et al. proposed a profiling tool that correlates system utilization metrics with framework operations in deep learning workloads [
18]. Specifically, they deploy the profiling functionality as an add-on to Amazon SageMaker Debugger and identify resource usage patterns during the training and inference phases of deep learning.
Overall, previous research has focused on the potential to improve the performance of deep learning workloads using containers. However, further research is needed to evaluate the performance of these systems on different hardware configurations and AI workloads. Additionally, there are still challenges to be solved, such as resource allocation, communication, and memory usage optimization.
Table 1 lists a brief summary of previous studies related to this article including their strengths and limitations.
3. Experimental Setup
This section describes an experimental configuration set up to quantify the performance of deep learning workloads running in Docker containers compared to running directly on the host system. The Docker framework we experiment with is composed of two images: a training image and a deployment image as shown in
Figure 2. The training image does the work of loading the data, training the model, and storing the trained model outside the container. The deployment image runs the saved model and handles inference requests. To compare the performance of running deep learning workloads in Docker containers and directly on the host system, we construct two experimental sets. The first set runs training and deployment directly on the host machine, while the second set runs inside a Docker container. We run deep learning workloads on a single physical machine, and each workload is executed on a separate container. 4 containers are used in order to see the effect of multi-tenant environments. The hardware configuration of our experiment consists of Intel i7-12700 CPU, Samsung DDR4 3200 16GB memory, Galax GeForce RTX 3060 GPU, Hynix Gold P31 SSD 2TB, and WD Blue 7200 HDD 2TB as listed in
Table 2. We measure the performance of each set of experiments using a variety of metrics, including CPU usage, memory usage, and execution time.
We leverage Ftrace, a kernel tracing framework, to evaluate the performance differences between the execution of the same task in a Docker container and the host system. Ftrace supports debugging and performance analysis by tracing a variety of events, including function calls, system calls, and interrupts. To ensure a fair and unbiased comparison, we control for various configurations that could potentially affect performance, such as the programming language and software library versions used. Details of software configurations we consider are listed in
Table 3. All experiments are performed on the same system and the results reported are averages from five independent runs.
We collect event traces using the Ftrace utility while executing deep learning workloads consisting of two well-known datasets: the Wikipedia dataset [
24] and the ImageNet dataset [
25]. For the Wikipedia dataset, we perform preprocessing by using the Kakao morpheme analyzer (
https://github.com/kakao/khaiii, accessed on 23 September 2023) to separate samples into morphemes and generate word sets. The lengths of all samples are matched such that short samples are padded with trailing zeros. For the ImageNet dataset, the size of the training images was adjusted to 256 × 256 for image classification, and the shorter width and height were fixed to 256. As training models, we use PyTorch, the most widely used machine learning framework. Specifically, two large-scale models for text processing and two small-scale models for image analysis are used. Details of these models and their corresponding datasets are listed in
Table 4. For model training, we first load the datasets, preprocess them, and repeat them for 10 epochs. The extracted event traces are categorized into four stages of deep learning: data load, model load, training, and inference.
5. Flushing Dirty Pages to Secondary Storage
In the previous section, we traced the statistics of dirty pages that were flushed to storage by kernel write-back calls while executing deep learning workloads. In this section, we further analyze the details of storage flush events. Specifically, we analyze the write-back activities as time progresses and the ratio of write-back triggering reasons (e.g., periodic, background, and sync). The most common cause of write-backs is “periodic,” which is activated periodically on a schedule. These periodic write-backs ensure that dirty pages are flushed to storage within a certain time window regardless of the situation of the system. Another common cause of write-backs is “background,” which is triggered when the ratio of dirty pages in memory exceeds a certain threshold. Note that periodic and background write-backs are not explicitly requested by a user space process but are performed by the kernel. In contrast, “sync” can be requested explicitly by a user process to flush all dirty data to storage, regardless of the reason for the write-back operation. Frequent invocation of “sync” may slow down the entire system so it should only be used if we need to flush all dirty data to storage.
Table 9 and
Table 10 show the frequency and ratio of write-backs based on call reasons in single and multiple Docker environments, respectively. As shown in
Table 9, “periodic” accounts for the majority of write-backs (68.1–81.5%) in single Docker environments, but there is also a certain portion of “background” write-backs of 18.4–31.6%. Note that “background” write-backs are difficult to estimate, so they may degrade the performance of the entire system. Note also that the ratio of “background” write-backs grows even more in multi-tenant environments (by up to 42.1%) as shown in
Table 10. This is because multi-tenants use more memory space, so “background” write-backs are triggered more frequently to reduce dirty pages in memory. Based on this result, we can conclude that multi-tenants incur more unpredictable write-backs, causing efficient management of flush I/Os difficult. Also, the differences observed between the two environments suggest that each requires a customized approach to manage the write-back process.
Reducing the number of write-backs can be achieved by appropriately setting the write-back parameters or using a file system that supports asynchronous writing. However, setting appropriate parameters in deep learning varies depending on the model and the number of tenants (i.e., single or multi-tenant).
To investigate the characteristics of write-back activities over time, we plot in
Figure 4 the number of write-backs that occur for each memory page as time progresses. As shown in the figure, dirty pages that are being written back are evenly distributed across all pages in the early stages of deep learning, but after a certain time point, some limited pages are consistently flushed. This means that some limited data in deep learning is constantly modified, and it is necessary to efficiently manage these data flushes for stable performance of the deep learning training process. In the early stages of deep learning training, data is loaded, models are initialized, and weights are changed frequently. This means that there are a variety of dirty pages that need to be flushed back into storage [
33]. However, as the model learns and the weights converge over time, the number of dirty pages decreases. That is, after a certain time point, the model repeatedly updates some limited data, which generates certain pages increasingly hotter as shown in
Figure 4. Note that these hot dirty pages can cause performance issues as they should essentially be flushed to storage frequently, wasting CPU and memory resources.
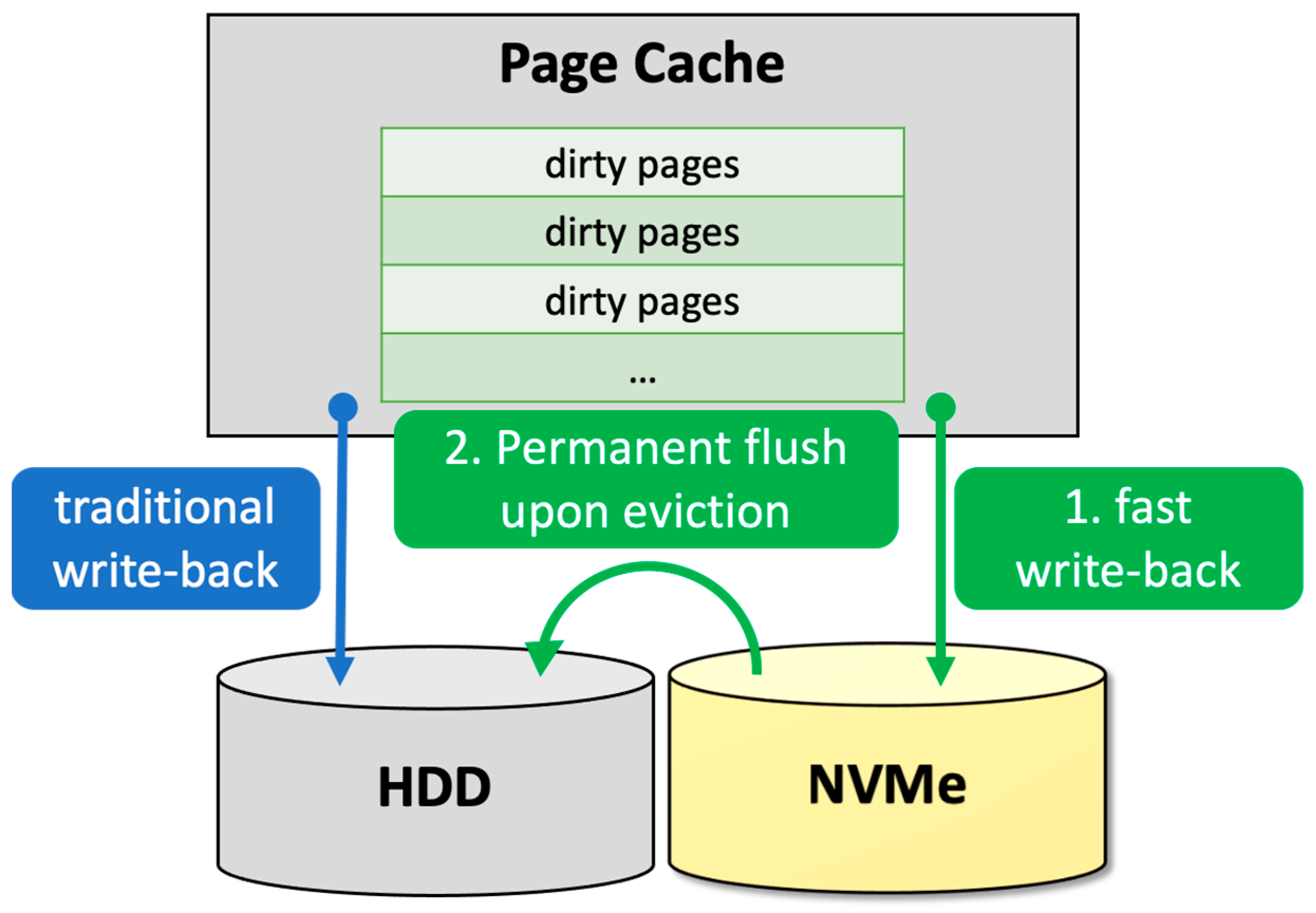
To handle this situation, we suggest an intermediate non-volatile flushing layer residing between the main memory and the storage. Our architecture shown in
Figure 5 has the mission of improving the write-back performance by making use of NVM as the front-end cache of secondary storage, leading to reduced I/O traffic and frequency of flush operations to slow disk storage. Specifically, our preliminary architecture utilizes NVMe as a secondary storage buffer to accelerate the write-back performances. As NVM is also a non-volatile medium like hard disks, we can eliminate storage flushing operations. To assess the effectiveness of this system architecture, we conduct simulation experiments for write-back activities in container-based deep learning workloads and compare the results of the original system and those with our NVM-added architecture. We use the parameters of a Toshiba DT01ACA1 hard disk drive (HDD) with a read/write access latency of 8 milliseconds for secondary storage. For NVM media, we use the parameters of a phase change memory (PCM) with a write latency of 350 nanoseconds. Note that PCM is a well-known NVM media that can be placed in front of slow storage to accelerate I/O performances [
16].
Figure 6 shows the I/O latency of the proposed NVM-added architecture in comparison with the traditional system that does not use NVM as workloads and system situations are varied. As shown in the figure, our preliminary architecture improves the I/O latency significantly in all cases. Specifically, the improvements for SqeezeNet, Mobile-BERT, AlexNet, and LSTM, are 83%, 90%, 84%, and 77%, respectively, in single Docker and 78%, 77%, 86%, and 83%, respectively, in multi-tenant Docker environments. The improvement is the largest in the single Docker Mobile-BERT dataset. Note that Mobile-BERT is the smallest text dataset so most flush operations can be eliminated even with a small NVM capacity. We also observe that the improvement is large in multi-tenant environments with relatively heavy models such as Alexnet and LSTM because an increased number of write-backs in such models puts more strain on the HDD. In summary, our architecture has the effect of significantly improving I/O latency in containerized deep learning by absorbing storage flushing into an intermediate buffer between the container and slow HDD storage.
6. Conclusions
In this article, we quantified the resource requirements of containerized deep learning workloads through measurements and trace-based analysis. Specifically, we extracted and investigated the system event trace of container-based deep learning and compared it to traces collected by running the same workload on host systems to identify the overhead of containerization and potential performance penalties. Based on our analysis, we observed that memory management, especially write-backs of dirty pages to storage, can be the main bottleneck in container-based deep learning. This is because containers share the host kernel and file systems, which can cause contention, and each container may have different synchronization intervals. By analyzing system calls and event traces generated by container-based deep learning, we provided implications for resource management in a containerized environment. We also introduced a preliminary solution that adopts an intermediate non-volatile flushing layer to alleviate the performance bottleneck of storage write-backs. Instead of flushing to traditional storage, our solution effectively hid the write-back overhead by absorbing hot data in fast NVM media, improving I/O latency by 82% on average.
In this article, we focused on analyzing the overhead of containerization in deep learning workloads executed in IoT environments that have limited resource capacities. Thus, we selected workloads that are relatively lightweight and suitable for deployment on edge devices rather than huge workloads where trace extraction imposes significant overhead on the system. In the future, we will extend our target architecture to high-performance systems that can support more complicated deep learning workloads, such as ResNet, NASNet, or GoogLeNet, to analyze resource usage patterns of containerized deep learning.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}