
Reinforcement Learning as a Path to Autonomous Intelligent Cyber-Defense Agents in Vehicle Platforms


Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Overview
3.2. AICA Concept
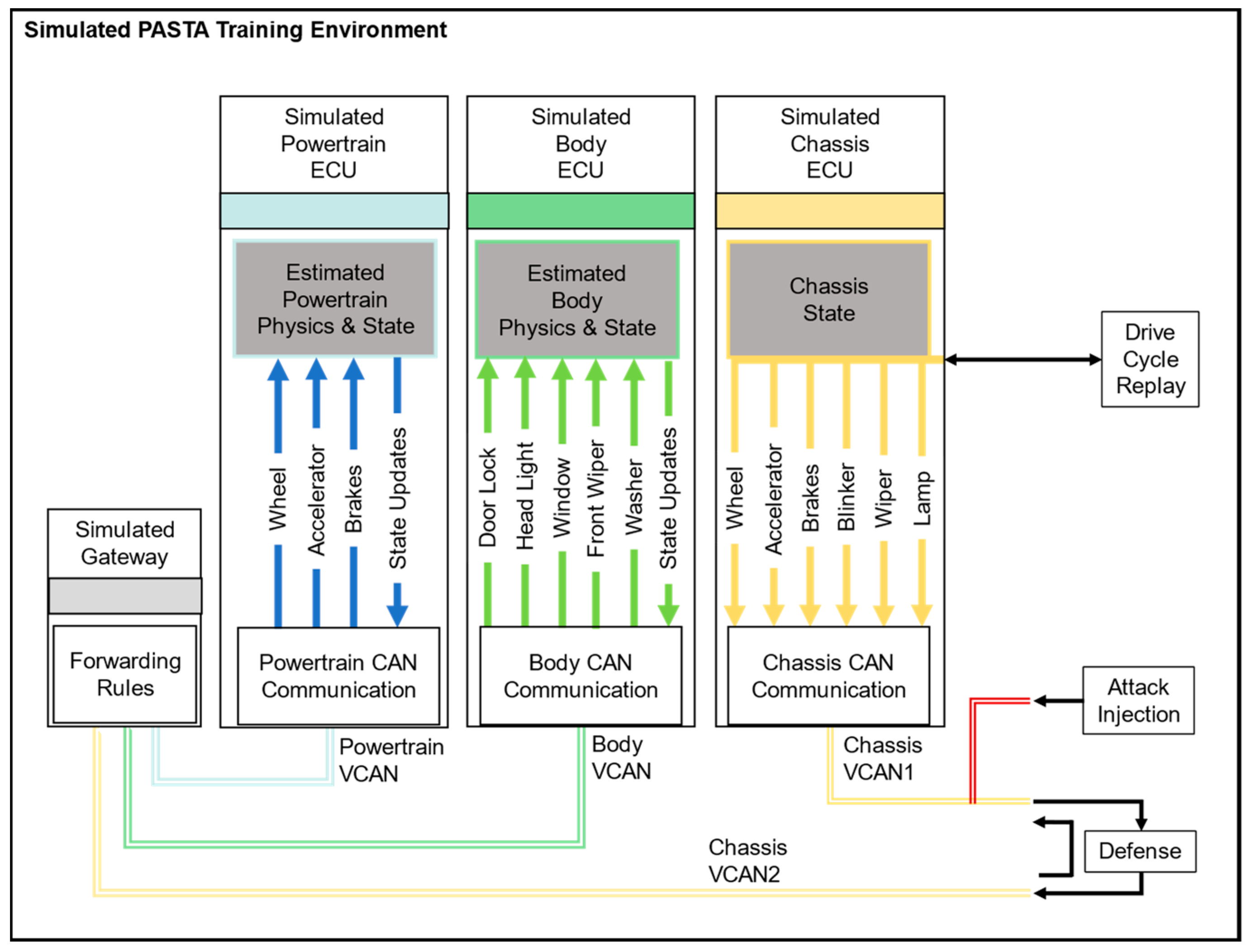
3.3. Agent Environment
3.4. Agent Design and Training Using Reinforcement Learning
3.5. Defenses for Comparison
3.6. Quantitative Measurement of Cyber Resilience
4. Results and Discussion
5. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Russell, W.W. Weapon Systems Cybersecurity: Guidance Would Help DOD Programs Better Communicate Requirements to Contractors. 2021. Available online: https://www.gao.gov/products/gao-21-179 (accessed on 31 July 2023).
- Smith, S. Towards a scientific definition of cyber resilience. In Proceedings of the International Conference on Cyber Warfare and Security, Towson, MD, USA, 9–10 March 2023; Volume 18. [Google Scholar]
- Theron, P.; Kott, A.; Drašar, M.; Rzadca, K.; LeBlanc, B.; Pihelgas, M.; Mancini, L.; Panico, A. Towards an active, autonomous and intelligent cyber defense of military systems: The NATO AICA reference architecture. In Proceedings of the 2018 International Conference on Military Communications and Information Systems (ICMCIS), Warsaw, Poland, 22–23 May 2018; IEEE: New York, NY, USA, 2018. [Google Scholar]
- Kott, A.; Théron, P.; Drašar, M.; Dushku, E.; LeBlanc, B.; Losiewicz, P.; Guarino, A.; Mancini, L.; Panico, A.; Pihelgas, M.; et al. Autonomous intelligent cyber-defense agent (AICA) reference architecture. Release 2.0. arXiv 2018, arXiv:1803.10664. [Google Scholar]
- Kott, A.; Weisman, M.J.; Vandekerckhove, J. Mathematical modeling of cyber resilience. In Proceedings of the MILCOM 2022-2022 IEEE Military Communications Conference (MILCOM), Rockville, MD, USA, 28 November–2 December 2022; IEEE: New York, NY, USA, 2022. [Google Scholar]
- Marchetti, M.; Stabili, D. Anomaly detection of CAN bus messages through analysis of ID sequences. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Levy, E.; Shabtai, A.; Groza, B.; Murvay, P.S.; Elovici, Y. CAN-LOC: Spoofing detection and physical intrusion localization on an in-vehicle CAN bus based on deep features of voltage signals. arXiv 2021, arXiv:2106.07895. [Google Scholar] [CrossRef]
- Cho, K.T.; Shin, K.G. Fingerprinting electronic control units for vehicle intrusion detection. In Proceedings of the USENIX Security Symposium, Austin, TX, USA, 10–12 August 2016; Volume 40. [Google Scholar]
- Moore, M.R.; Bridges, R.A.; Combs, F.L.; Starr, M.S.; Prowell, S.J. Modeling inter-signal arrival times for accurate detection of can bus signal injection attacks: A data-driven approach to in-vehicle intrusion detection. In Proceedings of the 12th Annual Conference on Cyber and Information Security Research, Oak Ridge, TN, USA, 4 April 2017. [Google Scholar]
- Lokman, S.-F.; Othman, A.T.; Abu-Bakar, M.-H. Intrusion detection system for automotive controller area network (CAN) bus system: A review. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 184. [Google Scholar] [CrossRef]
- Minawi, O.; Whelan, J.; Almehmadi, A.; El-Khatib, K. Machine learning-based intrusion detection system for controller area networks. In Proceedings of the 10th ACM Symposium on Design and Analysis of Intelligent Vehicular Networks and Applications, Alicante, Spain, 16–20 November 2020. [Google Scholar]
- Purohit, S.; Govindarasu, M. ML-based Anomaly Detection for Intra-Vehicular CAN-bus Networks. In Proceedings of the 2022 IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 27–29 July 2022; IEEE: New York, NY, USA, 2022. [Google Scholar]
- Gundu, R.; Maleki, M. Securing CAN bus in connected and autonomous vehicles using supervised machine learning approaches. In Proceedings of the 2022 IEEE International Conference on Electro Information Technology (eIT), Mankato, MN, USA, 19–21 May 2022; IEEE: New York, NY, USA, 2022. [Google Scholar]
- Taylor, A.; Japkowicz, N.; Leblanc, S. Frequency-based anomaly detection for the automotive CAN bus. In Proceedings of the 2015 World Congress on Industrial Control Systems Security (WCICSS), London, UK, 14–16 December 2015. [Google Scholar]
- Kang, M.-J.; Kang, J.-W. Intrusion detection system using deep neural network for in-vehicle network security. PLoS ONE 2016, 11, e0155781. [Google Scholar] [CrossRef] [PubMed]
- Song, H.M.; Woo, J.; Kim, H.K. In-vehicle network intrusion detection using deep convolutional neural network. Veh. Commun. 2020, 21, 100198. [Google Scholar] [CrossRef]
- Qin, H.; Yan, M.; Ji, H. Application of controller area network (CAN) bus anomaly detection based on time series prediction. Veh. Commun. 2021, 27, 100291. [Google Scholar] [CrossRef]
- Seo, E.; Song, H.M.; Kim, H.K. GIDS: GAN based intrusion detection system for in-vehicle network. In Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, UK, 28–30 August 2018; IEEE: New York, NY, USA, 2018. [Google Scholar]
- Wang, Z.; Kim, S.; Joe, I. An Improved LSTM-Based Failure Classification Model for Financial Companies Using Natural Language Processing. Appl. Sci. 2023, 13, 7884. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, Y.; Xie, G.; Li, R.; Liu, S.; Yang, L.T. TCE-IDS: Time interval conditional entropy-based intrusion detection system for automotive controller area networks. IEEE Trans. Ind. Informatics 2022, 19, 1185–1195. [Google Scholar] [CrossRef]
- Song, H.M.; Kim, H.R.; Kim, H.K. Intrusion detection system based on the analysis of time intervals of CAN messages for in-vehicle network. In Proceedings of the 2016 International Conference on Information Networking (ICOIN), Kota Kinabalu, Malaysia, 13–15 January 2016; IEEE: New York, NY, USA, 2016. [Google Scholar]
- Ji, H.; Wang, Y.; Qin, H.; Wang, Y.; Li, H. Comparative performance evaluation of intrusion detection methods for in-vehicle networks. EEE Access 2018, 6, 37523–37532. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Reddi, V.J. Deep reinforcement learning for cyber security. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 3779–3795. [Google Scholar] [CrossRef] [PubMed]
- Sewak, M.; Sahay, S.K.; Rathore, H. Deep reinforcement learning for cybersecurity threat detection and protection: A review. In Proceedings of the International Conference on Secure Knowledge Management in Artificial Intelligence Era, San Antonio, TX, USA, 8–9 October 2021; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A. Application of deep reinforcement learning to intrusion detection for supervised problems. Expert Syst. Appl. 2020, 141, 112963. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; IEEE: New York, NY, USA, 2009. [Google Scholar]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, S. Intrusion detection in 802.11 networks: Empirical evaluation of threats and a public dataset. IEEE Commun. Surv. Tutor. 2015, 18, 184–208. [Google Scholar] [CrossRef]
- Xiao, L.; Lu, X.; Xu, T.; Zhuang, W.; Dai, H. Reinforcement learning-based physical-layer authentication for controller area networks. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2535–2547. [Google Scholar] [CrossRef]
- Portable Automotive Security Testbed with Adaptability. Ver.1.0. Japan. Toyota. 2018. Available online: https://www.chip1stop.com/sp/products/toyota-pasta_en. (accessed on 31 July 2023).
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Oh, J.; Guo, X.; Lee, H.; Lewis, R.L.; Singh, S. Action-conditional video prediction using deep networks in atari games. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Red Hook, NY, USA, 2015. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Koray, D.S.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning (PMLR), New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Hanselmann, M.; Strauss, T.; Dormann, K.; Ulmer, H. CANet: An unsupervised intrusion detection system for high dimensional CAN bus data. IEEE Access 2020, 8, 58194–58205. [Google Scholar] [CrossRef]
- Kott, A.; Weisman, M.J.; Ellis, J.E.; Parker, T.W.; Murphy, B.J.; Smith, S. A Methodology for Quantitative Measurement of Cyber Resilience (QMOCR); Apr. Report No.: ARL-TR-9672; Army Research Laboratory (US): Adelphi, MD, USA, 2023. [Google Scholar]
- Avatefipour, O.; Hafeez, A.; Tayyab, M.; Malik, H. Linking received packet to the transmitter through physical-fingerprinting of controller area network. In Proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), Rennes France, 4–7 December 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Giannopoulos, H.; Wyglinski, A.M.; Chapman, J. Securing vehicular controller area networks: An approach to active bus-level countermeasures. IEEE Veh. Technol. Mag. 2017, 12, 60–68. [Google Scholar] [CrossRef]
- Kaspar, M.; Osorio, J.D.M.; Bock, J. Sim2real transfer for reinforcement learning without dynamics randomization. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: New York, NY, USA, 2020. [Google Scholar]
- Baker, B.; Kanitscheider, I.; Markov, T.; Wu, Y.; Powell, G.; McGrew, B.; Mordatch, I. Emergent tool use from multi-agent autocurricula. arXiv 2019, arXiv:1909.07528. [Google Scholar]
- Lee, H.; Jeong, S.H.; Kim, H.K. OTIDS: A novel intrusion detection system for in-vehicle network by using remote frame. In Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST), Calgary, AB, Canada, 28–30 August 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Allow | Block | |
|---|---|---|
| Real | 1.0 | −1.0 |
| Malicious | −1.5 | 1.5 |
| Selection Option | Option Probability |
|---|---|
| No injections | 5% |
| Single message type injection | 22% |
| Add message type to prior message injection list | 73% |
| Message Type | Type Probability |
|---|---|
| Brake, acceleration, steering | ~15% |
| Remaining 12 message types | ~5% |
| Defense | QMoCR Measurement | Traditional Performance Measures | ||||||
|---|---|---|---|---|---|---|---|---|
| AUC | Defense/Baseline AUC Ratio | Accuracy | Precision | Recall | F-Score | Sensitivity | Specificity | |
| Baseline | 9615 | … | … | … | … | … | … | … |
| No Defense | 4 | 0% | … | … | … | … | … | … |
| Static Timing | 3976 | 41% | 0.9325 | 0.9251 | 0.9300 | 0.9275 | 0.9300 | 0.9346 |
| RL Model | 8606 | 90% | 0.9341 | 0.943 | 0.913 | 0.9277 | 0.913 | 0.9523 |
| Static Timing w/Frequency | 9430 | 98% | 0.9433 | 0.9345 | 0.9443 | 0.9393 | 0.9443 | 0.9425 |
| CNN Model | 109 | 1% | 0.7009 | 0.7592 | 0.518 | 0.6158 | 0.518 | 0.8585 |
| LSTM Model | 0 | 0% | 0.6995 | 0.7697 | 0.4998 | 0.6061 | 0.4998 | 0.8714 |
| Defense | Accuracy | |||
|---|---|---|---|---|
| No Injections | With Injections | |||
| Mean | Std Dev | Mean | Std Dev | |
| CNN Classifier drop/drop | 0.986131 | 0.009274 | 0.745306 | 0.010356 |
| CNN Classifier no_drop/no_drop | 0.985406 | 0.009316 | 0.709558 | 0.012134 |
| LSTM drop | 0.938945 | 0.079128 | 0.686017 | 0.027225 |
| LSTM no_drop | 0.954807 | 0.057592 | 0.685402 | 0.025105 |
| RL drop/drop | 0.997037 | 0.004194 | 0.951322 | 0.014763 |
| RL no_drop/no_drop | 0.965619 | 0.008333 | 0.889717 | 0.013051 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raio, S.; Corder, K.; Parker, T.W.; Shearer, G.G.; Edwards, J.S.; Thogaripally, M.R.; Park, S.J.; Nelson, F.F. Reinforcement Learning as a Path to Autonomous Intelligent Cyber-Defense Agents in Vehicle Platforms. Appl. Sci. 2023, 13, 11621. https://doi.org/10.3390/app132111621
Raio S, Corder K, Parker TW, Shearer GG, Edwards JS, Thogaripally MR, Park SJ, Nelson FF. Reinforcement Learning as a Path to Autonomous Intelligent Cyber-Defense Agents in Vehicle Platforms. Applied Sciences. 2023; 13(21):11621. https://doi.org/10.3390/app132111621
Chicago/Turabian StyleRaio, Stephen, Kevin Corder, Travis W. Parker, Gregory G. Shearer, Joshua S. Edwards, Manik R. Thogaripally, Song J. Park, and Frederica F. Nelson. 2023. "Reinforcement Learning as a Path to Autonomous Intelligent Cyber-Defense Agents in Vehicle Platforms" Applied Sciences 13, no. 21: 11621. https://doi.org/10.3390/app132111621