

Coarse-to-Fine Structure-Aware Artistic Style Transfer


Abstract
:1. Introduction
- We introduce a novel style transfer model that can be used to synthesize appealing structure-aware stylization results. This model consists of a coarse network and a fine network. The former roughly transfers style patterns that include holistic structural information and color distribution information, and then the latter enhances the details of the style patterns by fusing multiscale features.
- We propose a SSF module for fusing the reconstructed features to the content features in a fine network. This module can help the fine network select essential structural information for feature fusion on the basis of the channel attention mechanism. As a result, the color distribution of the style images can be accurately transferred.
- It is demonstrated through experiments that our method can be used to synthesize high-quality stylizations, where the main structures of the content image are preserved and the local structures of the style image are transferred. These stylization results can maintain the same artistic expression as style images by discarding trivial content details and injecting key local style structures.
2. Related Work
2.1. Style Transfer
2.2. Style Transfer Based on Multiscale Learning
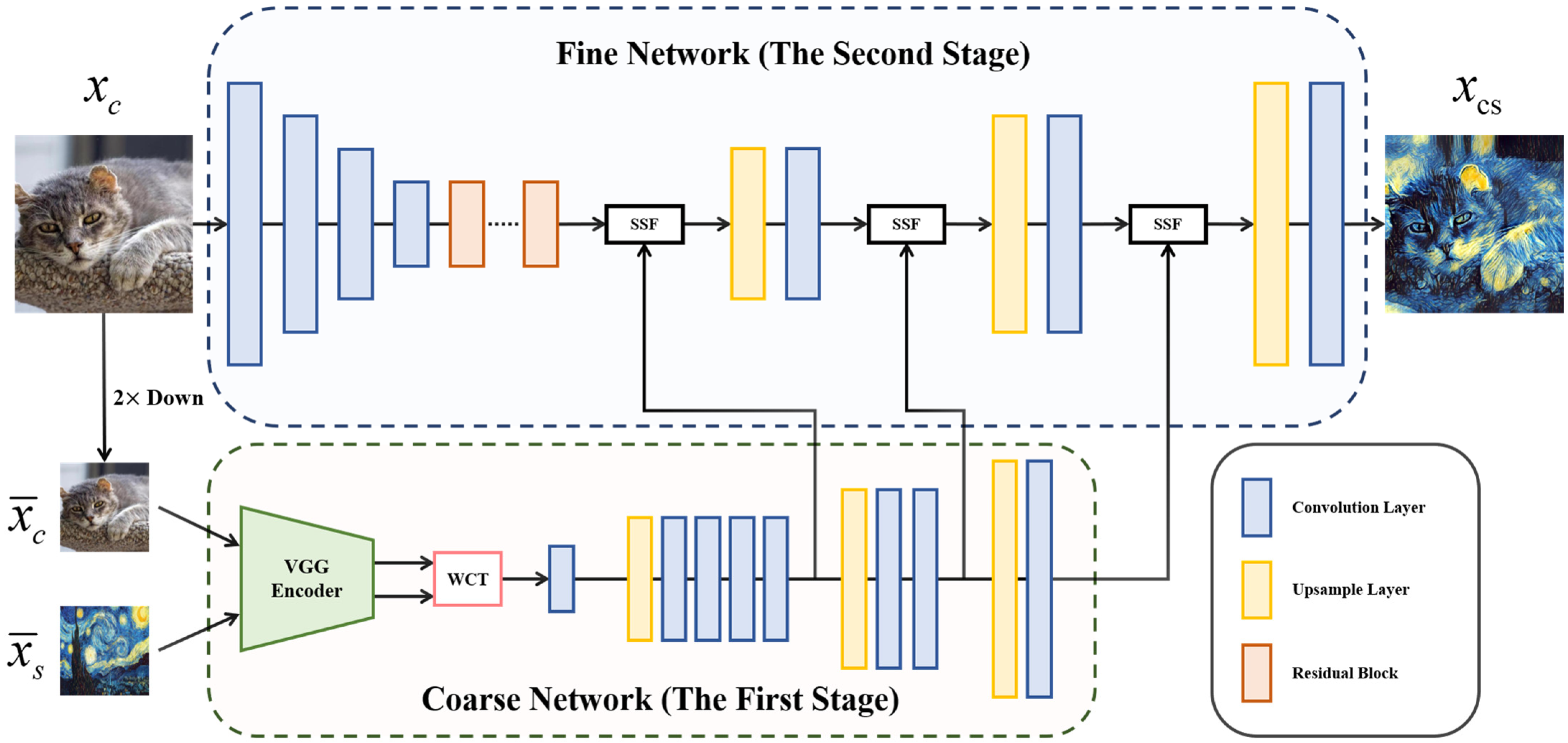
3. Proposed Method
3.1. Framework Overview
3.2. Coarse Network
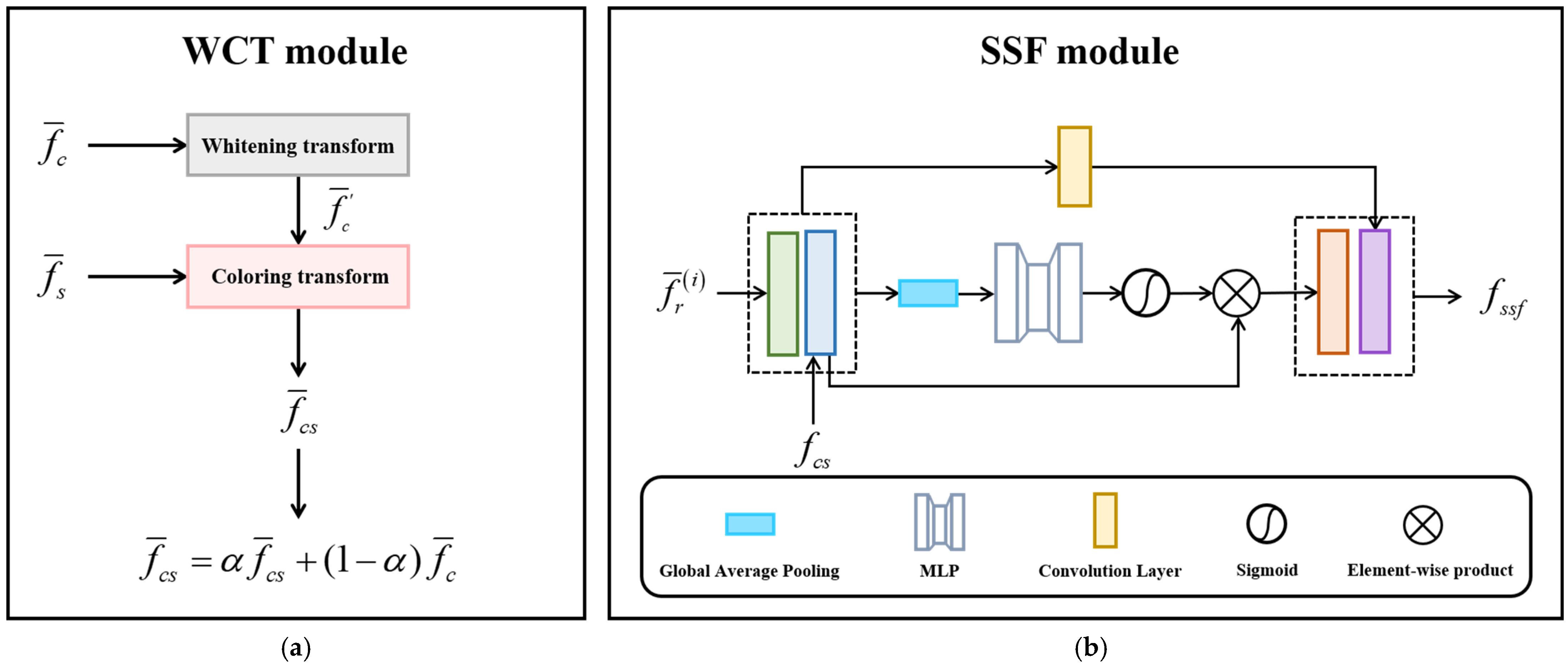
3.2.1. WCT Module
3.2.2. Architecture of Coarse Network
3.3. Fine Network
3.3.1. SSF Module
3.3.2. Architecture of Fine Network
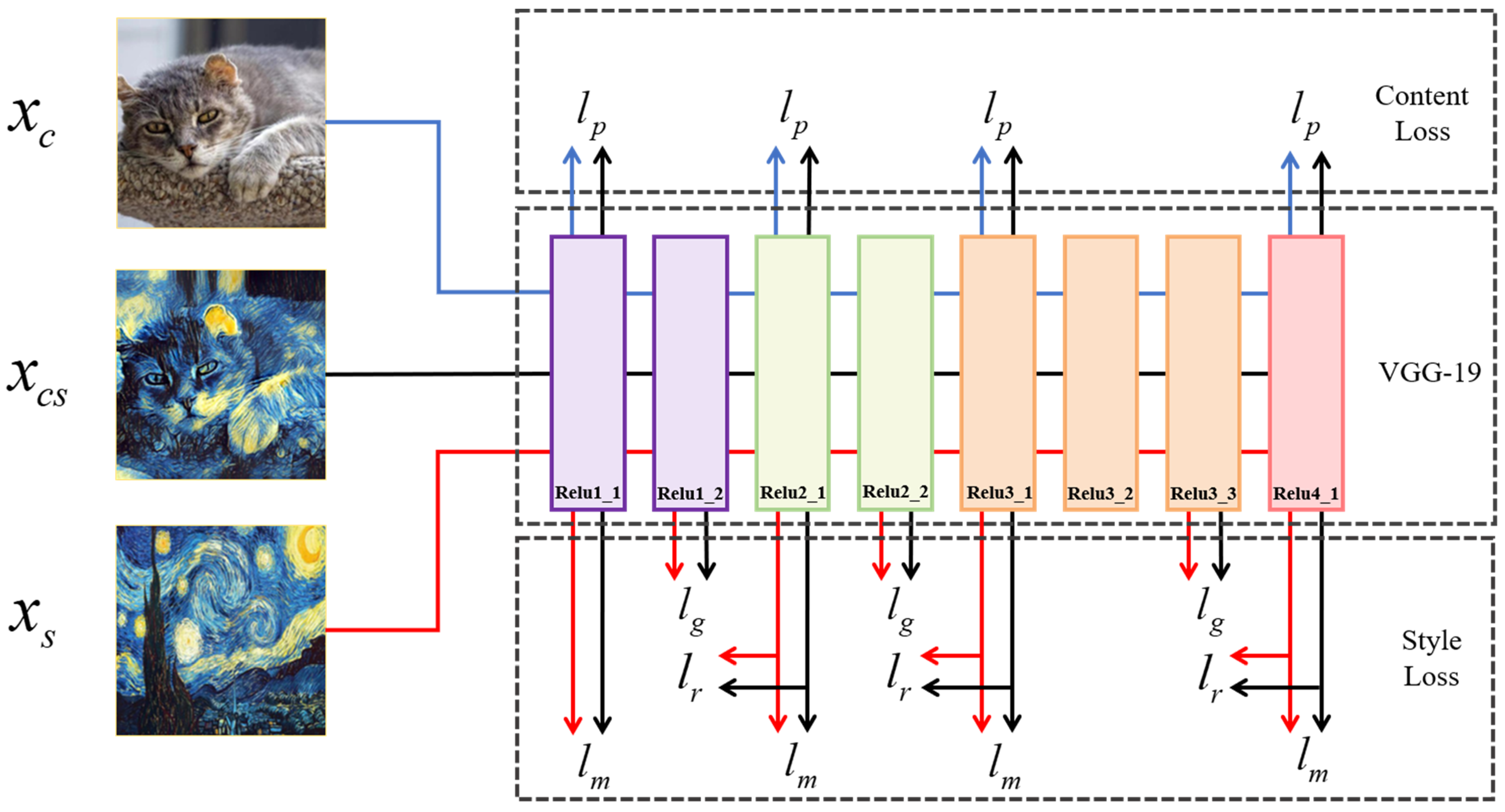
3.4. Loss Function
4. Experimental Results and Analysis
4.1. Experimental Dataset and Implementation Details
4.2. Qualitative Comparisons with Methods in Prior Works
4.3. Quantitative Comparisons with Methods in Prior Works
4.4. Comparisons of Time Efficiency with Methods in Prior Works
4.5. User Study
4.6. Ablation Study on Loss Function
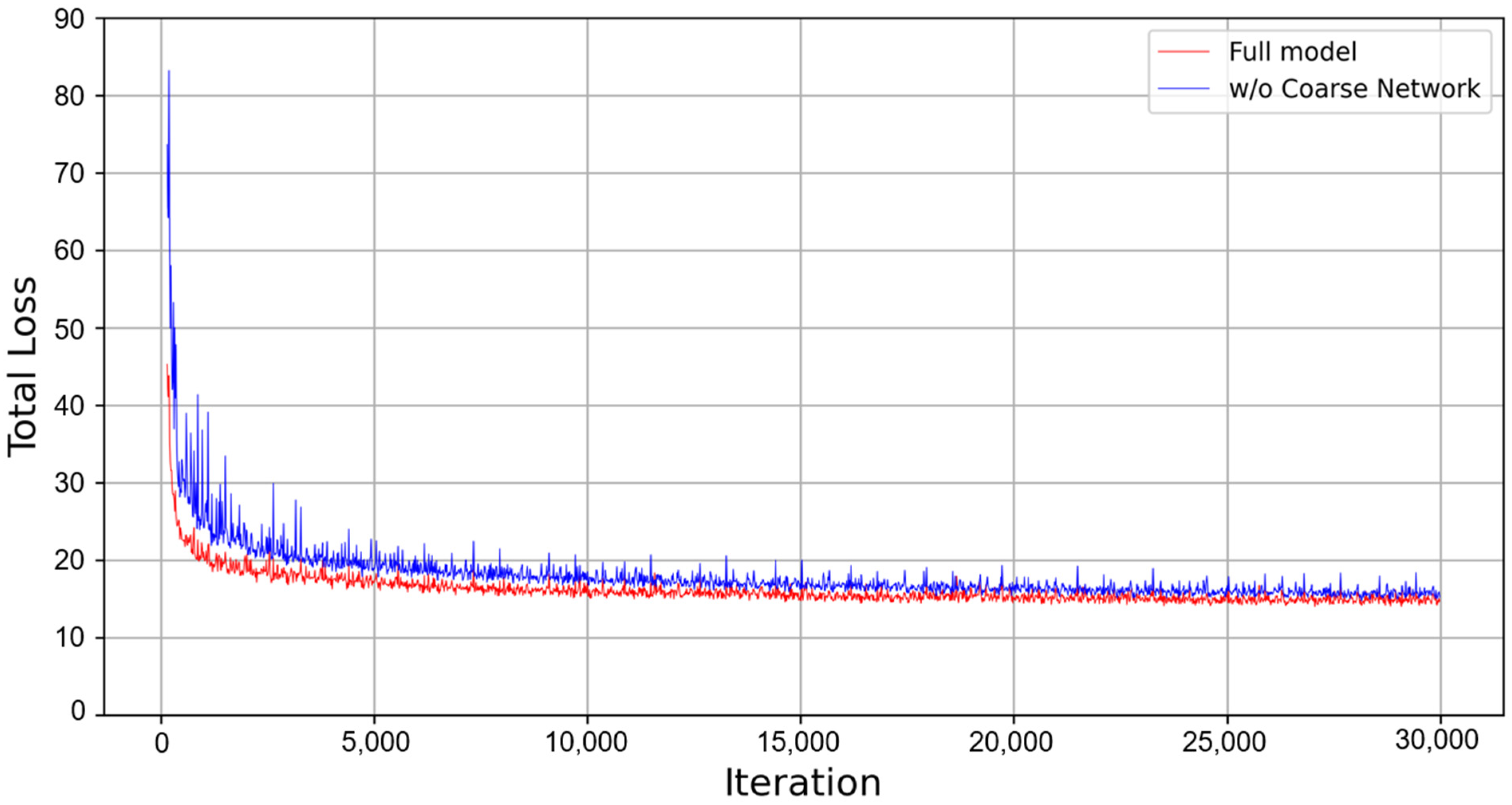
4.7. Effectiveness of Coarse Network
4.8. Effectiveness of Fine Network
4.9. Effectiveness of the SSF Modules
4.10. Additional Experiments
5. Conclusions
- We proposed a novel feed-forward style transfer algorithm that fuses the local style structure into the global content structure. Different from most style transfer methods that work at the same scale, our model can integrate richer information from features from different scales and then synthesize high-quality structure-aware stylized images.
- We first proposed a coarse network to generate reconstructed coarse stylized features at low resolution, which can capture the main structure of the content image and transfer the holistic color distribution of the style image. Then, we proposed a fine network to enhance local style patterns and three SSF modules to selectively fuse the reconstructed stylized features to reconstructed content features at different levels.
- Through comparative experiments, it was demonstrated that our method was effective in synthesizing appealing high-quality stylized images, and these stylization results outperformed the results generated by current state-of-the-art style transfer methods. The experimental results also demonstrated the effectiveness of the coarse network, the fine network, and the SSF module.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SSF | Structural selective fusion |
| NPR | Nonphotorealistic rendering |
| STROTSS | Style transfer by relaxed optimal transport and self-similarity |
| rEMD | Relaxed earth mover’s distance |
| AdaIN | Adaptive instance normalization |
| WCT | Whitening and coloring transforms |
| VGG | Visual geometry group |
| DualStyleGAN | Dual style generative adversarial network |
| POFMakeup | Peking Opera face makeup |
| SANet | Style-attentional network |
| LapStyle | Laplacian pyramid style network |
| ReLU | Rectified linear unit |
| GPU | Graphics processing unit |
| LPIPS | Learned perceptual image patch similarity |
| SSIM | Structural similarity index measurement |
Symbol
| Content image | |
| Style image | |
| Stylized image | |
| The result of downsampling by 2 | |
| The result of downsampling by 2 | |
| Restructured coarse stylized features | |
| Channels of | |
| Height of | |
| Width of | |
| Content feature extracted from VGG network | |
| Style feature extracted from VGG network | |
| The result of linearly transforming | |
| Stylized feature generated by WCT module | |
| Reconstructed content features | |
| The input of SSF module | |
| Attention map of | |
| The result of refining | |
| The result of refining | |
| The output of SSF module | |
| Reconstruction loss | |
| Input image | |
| Output image | |
| VGG encoder that extracts features at ReLU_X_1 | |
| Weight term of | |
| Content feature extracted at ReLU_ | |
| Style feature extracted at ReLU_ | |
| Stylized feature extracted at ReLU_ | |
| Perceptual loss | |
| Relaxed earth mover’s distance (rEMD) loss | |
| Cost matrix | |
| Cosine distance | |
| Gram matrix loss | |
| Calculation of the Gram matrix | |
| Mean-variance loss | |
| Mean | |
| Covariance | |
| Overall optimization objective | |
| Weight term of | |
| Weight term of | |
| Weight term of | |
| Weight term of |
References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar] [CrossRef]
- Kolkin, N.; Salavon, J.; Shakhnarovich, G. Style Transfer by Relaxed Optimal Transport and Self-Similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10043–10052. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the Computer Vision—ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar] [CrossRef] [Green Version]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V. Texture Networks: Feed-forward Synthesis of Textures and Stylized Images. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar] [CrossRef]
- Huang, X.; Belongie, S. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1510–1519. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.J.; Fang, C.; Yang, J.M.; Wang, Z.W.; Lu, X.; Yang, M.H. Universal Style Transfer via Feature Transforms. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014. [Google Scholar] [CrossRef]
- Li, C.; Wand, M. Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, 8–16 October 2016; pp. 702–716. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Wand, M. Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 2479–2486. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Oxholm, G.; Zhang, D.; Wang, Y.F. Multimodal Transfer: A Hierarchical Deep Convolutional Neural Network for Fast Artistic Style Transfer. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7178–7186. [Google Scholar] [CrossRef] [Green Version]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Improved Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4105–4113. [Google Scholar] [CrossRef]
- Sanakoyeu, A.; Kotovenko, D.; Lang, S.; Ommer, B. A Style-Aware Content Loss for Real-Time HD Style Transfer. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 715–731. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Jiang, L.M.; Liu, Z.W.; Loy, C.C. Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7683–7692. [Google Scholar] [CrossRef]
- Zhang, F.C.; Liang, X.M.; Sun, Y.Q.; Lin, M.G.; Xiang, J.; Zhao, H.H. POFMakeup: A style transfer method for Peking Opera makeup. Comput. Electr. Eng. 2022, 104, 108459. [Google Scholar] [CrossRef]
- Lin, C.C.; Hsu, C.B.; Lee, J.C.; Chen, C.H.; Tu, T.M.; Huang, H.C. A Variety of Choice Methods for Image-Based Artistic Rendering. Appl. Sci. 2022, 12, 6710. [Google Scholar] [CrossRef]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. arXiv 2016. [Google Scholar] [CrossRef]
- Zhang, H.; Dana, K. Multi-style Generative Network for Real-Time Transfer. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 349–365. [Google Scholar] [CrossRef] [Green Version]
- Ye, W.J.; Liu, C.J.; Chen, Y.H.; Liu, Y.J.; Liu, C.M.; Zhou, H.H. Multi-style transfer and fusion of image’s regions based on attention mechanism and instance segmentation. Signal Process.-Image Commun. 2023, 110, 116871. [Google Scholar] [CrossRef]
- Alexandru, I.; Nicula, C.; Prodan, C.; Rotaru, R.P.; Tarba, N.; Boiangiu, C.A. Image Style Transfer via Multi-Style Geometry Warping. Appl. Sci. 2022, 12, 6055. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, L.; Chen, H.; Qiu, L.; Mo, Q.; Lin, S.; Xing, W.; Lu, D. Diversified arbitrary style transfer via deep feature perturbation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7789–7798. [Google Scholar]
- Wang, H.; Li, Y.J.; Wang, Y.H.; Hu, H.J.; Yang, M.H. Collaborative Distillation for Ultra-Resolution Universal Style Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electro Network, Seattle, WA, USA, 14–19 June 2020; pp. 1857–1866. [Google Scholar] [CrossRef]
- Park, D.Y.; Lee, K.H. Arbitrary Style Transfer with Style-Attentional Networks. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5873–5881. [Google Scholar] [CrossRef]
- Sheng, L.; Lin, Z.Y.; Shao, J.; Wang, X.G. Avatar-Net: Multi-scale Zero-shot Style Transfer by Feature Decoration. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8242–8250. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Jiang, L.M.; Liu, Z.W.; Loy, C.C. VToonify: Controllable High-Resolution Portrait Video Style Transfer. ACM Trans. Graph. 2022, 41, 15. [Google Scholar] [CrossRef]
- Lin, T.W.; Ma, Z.Q.; Li, F.; He, D.L.; Li, X.; Ding, E.R.; Wang, N.N.; Li, J.; Gao, X.B. Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electro Network, Nashville, TN, USA, 19–25 June 2021; pp. 5137–5146. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M.; Hertzmann, A.; Shechtman, E. Controlling Perceptual Factors in Neural Style Transfer. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3730–3738. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Image-Optimization | Model-Optimization | Single Style | Multiple Style | Arbitrary Style |
|---|---|---|---|---|---|
| Ours | √ | √ | |||
| [1,2] | √ | √ | |||
| [3,4,8,9,10,11,12,13,14,15,24,25] | √ | √ | |||
| [16,17,18,19] | √ | √ | |||
| [5,6,20,21,22,23] | √ | √ |
| Designation | Information |
|---|---|
| Operating system | Windows 10 |
| System configuration | CPU: AMD Ryzen 9 5900X |
| GPU: NVIDIA GeForce RTX 3090 | |
| Software | PyCharm 2021.3.1 (Community Edition) |
| Python 3.8.12 | |
| Python library | Cuda 11.7 |
| Pytorch 1.8 | |
| Torchvision 0.9 | |
| Numpy 1.21 Matplotlib 3.5.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, K.; Yuan, G.; Wu, H.; Qian, W. Coarse-to-Fine Structure-Aware Artistic Style Transfer. Appl. Sci. 2023, 13, 952. https://doi.org/10.3390/app13020952
Liu K, Yuan G, Wu H, Qian W. Coarse-to-Fine Structure-Aware Artistic Style Transfer. Applied Sciences. 2023; 13(2):952. https://doi.org/10.3390/app13020952
Chicago/Turabian StyleLiu, Kunxiao, Guowu Yuan, Hao Wu, and Wenhua Qian. 2023. "Coarse-to-Fine Structure-Aware Artistic Style Transfer" Applied Sciences 13, no. 2: 952. https://doi.org/10.3390/app13020952