
Experimental Study of Morphological Analyzers for Topic Categorization in News Articles

1
School of Electronics Engineering, Kyungpook National University, Daegu 41566, Republic of Korea
2
School of Electronic and Electrical Engineering, Kyungpook National University, Daegu 41566, Republic of Korea
Appl. Sci. 2023, 13(19), 10572; https://doi.org/10.3390/app131910572
Submission received: 18 August 2023
/
Revised: 20 September 2023
/
Accepted: 21 September 2023
/
Published: 22 September 2023
(This article belongs to the Special Issue New Technologies and Applications of Natural Language Processing)
Abstract
:Natural language processing refers to the ability of computers to understand text and spoken words similar to humans. Recently, various machine learning techniques have been used to encode a large amount of text and decode feature vectors of text successfully. However, understanding low-resource languages is in the early stages of research. In particular, Korean, which is an agglutinative language, needs sophisticated preprocessing steps, such as morphological analysis. Since morphological analysis in preprocessing significantly influences classification results, ideal and optimized morphological analyzers must be used. This study explored five state-of-the-art morphological analyzers for Korean news articles and categorized their topics into seven classes using term frequency–inverse document frequency and light gradient boosting machine frameworks. It was found that a morphological analyzer based on unsupervised learning achieved a computation time of 6 s in 500,899 tokens, which is 72 times faster than the slowest analyzer (432 s). In addition, a morphological analyzer using dynamic programming achieved a topic categorization accuracy of 82.5%, which is 9.4% higher than achieve when using the hidden Markov model (73.1%) and 13.4% higher compared to the baseline (69.1%) without any morphological analyzer in news articles. This study can provide insight into how each morphological analyzer extracts morphemes in sentences and affects categorizing topics in news articles.
1. Introduction
Natural language processing (NLP) enables computers to understand text and spoken words similar to humans [1]. Historically, rule- and statistics-based methods have been used to understand natural languages [2]. In the 2010s, representation learning and machine learning, including deep learning methods, became widespread in NLP, demonstrating high performance [3]. These methods achieved state-of-the-art results in many NLP tasks, such as text classification, named entity recognition, machine translation, sentiment analysis, text summarization, question answering, and text generation. This successful transition changed the research paradigm in the field, and researchers have been developing large and complex language models.
Text classification involves categorizing text documents into predefined classes or categories. It can be used for tasks such as sentiment analysis, spam detection, and topic categorization. In particular, news topic categorization plays a crucial role in the world of journalism and information dissemination. News outlets produce large amounts of content daily. Categorization helps organize this information, making it easier for readers to find articles of interest quickly. Also, readers often prefer specific news topics or sections. Categorization allows news websites to provide tailored content recommendations, increasing user engagement and retention; effective topic categorization also enhances search functionality on news websites. Users can search for news articles by topic, improving their ability to access relevant information. By analyzing users’ preferences and behavior, news websites can personalize the content they display, increasing user satisfaction. In summary, news topic categorization is a vital NLP task that enhances the accessibility, relevance, and user experience of news content. It also has broader implications for content personalization, trend analysis, and the efficient operation of news organizations.
News articles can be generated by different countries in different languages; it is essential to investigate the characteristics of each language to understand the explicit and implicit contexts. However, most previous studies have focused on developing models to categorize news articles in English, and these models have been used for other languages. Without considering each language’s characteristics and applying appropriate preprocessing methods, categorizing news topics is poorly performed. In particular, the Korean language (Hangul) is an agglutinative language that includes a set of morphemes with affixes. Agglutinative languages have the following characteristics. A formal morpheme conjunction is combined with the root of the real morpheme to derive each word or show a grammatical relationship. In Korean, the vocabulary is combined with prefixes and suffixes, resulting in complex and varying forms. Morphological analysis is the first step in the process of structuring natural language sentences. Therefore, morphological analysis is a necessary process for understanding Korean. Although several morphological analyzers have been used to extract essential morphemes to understand the Korean language, it is still unknown how each morphological analyzer extracts meaningful morphemes, considering both computational time and performance.
To bridge such a research gap, the aim of this study was to investigate five different morphological analyzers and use them as a preprocessing step for topic categorization in news articles. Further, this study investigated the computational time of extracting morphemes by using the morphological analyzers from text and the accuracy of news topic categorization in a large corpus. To do this, term frequency–inverse document frequency [4] and light gradient boosting machine [5] were used for feature extraction and classification, respectively. The results revealed that a morphological analyzer based on unsupervised learning achieved the lowest computation time for preprocessing, and a dynamic programming-based morphological analyzer achieved the highest performance for topic categorization in news articles. The analysis in this study may help better understand the Korean language and how each morphological analyzer extracts part-of-speech (POS) tags. The remaining parts of this paper are structured as follows. First, a survey of related works in topic classification is provided in Section 2. In Section 3, the dataset and methods of the study are described. In Section 4, the findings of the study are presented. Finally, the discussion and conclusions of this study are summarized in Section 5 and Section 6, respectively.
2. Related Works
2.1. Machine Learning–Based Topic Categorization
News topic categorization involves classifying or distinguishing news, in textual data format, into a particular category based on information contained in news articles. In general, a machine learning–based approach was used to identify differences between topics [6]. The Latent Dirichlet allocation (LDA) is a probability-based method (Bayesian network); LDA assumes that each document in a collection is a mixture of a small number of topics and that each word in a document is attributable to one of the document’s topics [7]. Topic categorization using LDA is computationally fast, and it generates simple and comprehensible topics that are close to what the human mind assigns when reading a text. Another study also used LDA with a sparse representation classifier (SRC) [8]. The authors used LDA as the feature learning method, and extracted features were stacked to perform SRC-based categorization. The authors showed that the combination of LDA and SRC outperformed conventional methods. One drawback of LDA is that it may disregard lexical semantics; thus, it is not sufficiently robust for variations in words. For this reason, a study proposed an unsupervised method, probabilistic latent semantic analysis (pLSA), to extract concepts and documents semantically [9]. The authors argued that text categorization using pLSA can address the shortcomings of term-based representations. Another study used mutual information as a feature selector to provide relevant features for the Bayesian network classifier [10]. The authors found an improvement in classification accuracy using mutual information, as compared to without using it, in terms of micro-average F1 score. Another study used different machine learning techniques, including support vector machine (SVM), gradient descent, random forest, logistic regression, and k-nearest neighbor, and compared their classification accuracies for news topic categorization [11]. The study found that an optimized SVM outperformed the other conventional machine learning approaches.
2.2. Deep Learning–Based Topic Categorization
Although machine learning–based approaches that extract semantic and lexical features from sentences for categorizing topics are widely used, one of their limitations is that the performance of topic categorization varies according to how and what feature extraction methods are applied. Also, the generalization performance could be poor because the applied feature extraction methods on a specific domain or topic may not work well on a different domain or topic. For these reasons, deep learning–based approaches have received much attention in recent years. Bengio and colleagues introduced the first neural language model [12], employing a feed-forward neural network trained on a corpus of 14 million words. A transformative shift in approach emerged with the advent of significantly larger embedding models trained on extensive datasets. A method for computing continuous vector representations of words from very large datasets was subsequently introduced [13]. This word2vec method gained popularity across various NLP tasks, including topic categorization. ELMO, which uses a three-layer bidirectional LSTM with 93 million parameters and trained on 1 billion words [14], was then introduced, and BERT, a transformer-based embedding model that uses attention mechanisms, significantly enhanced the performance of understanding natural languages in general [15]. In particular, for topic categorization, a study used recurrent neural networks to capture contextual information and the semantics of words when learning word representations [16]. The study found that the proposed method outperformed state-of-the-art methods. A review paper demonstrated that optimization techniques for LDA, which is used for topic classification, often yield inaccurate results [17].
2.3. Morphological Analysis in News Topic Categorization
Since morphological analysis plays a crucial role in extracting explicit and implicit contexts from sentences, previous studies attempted to use various morphological analyzers for topic categorization in news articles. In particular, the Korean language is known for its complex morphological structure. Words often change forms based on grammatical rules, making it challenging to identify the root or base form of a word. Morphological analysis helps in breaking down words into their constituent morphemes, providing a clear understanding of word structure.
Lee et al. [18] used a keyword extraction technique designed for tracking topics over time, particularly in the context of online news data. The authors proposed a two-stage keyword extraction system. They first extracted candidate keywords from documents and then removed meaningless words by comparing candidate keywords in terms of ranking results, which were based on the number of appearances. The results revealed that the keyword-extracting technique using cross-domain filtering can be applied to documents, but the study did not evaluate the effectiveness or performance. Cho et al. [19] investigated topic category analysis in news articles, excluded special characters and numbers, and applied stemming for morpheme analysis. Finally, only nouns were used for topic categorization. For topic categorization, they used LDA and TF-IDF and found a categorization accuracy of approximately 80% in different configurations. They performed conventional morpheme analysis and did not evaluate its effectiveness. An et al. [20] characterized news items at four levels by using computational techniques, including topic modeling and the vector representation of words and news items. They applied simple keyword extraction for morphological analysis and applied News2Vec, a hierarchical clustering method, to construct a matrix to cluster news items. They found that differences in news-reading behavior across different demographic groups are the most noticeable at the subtopic level but are not prominent at the section or topic levels. Suh et al. [21] investigated different oversampling methods, which are used to overcome the problem of imbalanced data, for topic categorization in news articles. For morphological analysis, they applied noun extraction. They found oversampling methods generally improve the performance of imbalanced and resampled data. Chuluunsaikhan et al. [22] investigated forecasting pork prices using topic modeling in news articles. They utilized news articles and retail price data and applied a topic modeling technique to obtain relevant keywords that can express price fluctuations. In this keyword extraction, they applied tokenization and removed punctuation and stop-words for morphological analysis. They found that there was a strong relationship between the meaning of news articles and the price of pork. Morpheme analyses, strengths, and weaknesses in these studies are summarized in Table 1.
Several previous studies attempted to apply morphological analysis and categorize topics in news articles, but the effectiveness of using morphological analyzers remained unknown, and categorization performance differed across the studies. Because news articles are generally written in various international languages, the suitability of morphological analyzers can influence the performance. Also, there are few studies on how such a morphological analyzers influence the categorization accuracy of news articles. For these reasons, this study investigated the effects of using morphological analyzers for topic categorization in terms of computational cost and performance.
3. Materials and Methods
3.1. Dataset
To train the model, the topic classification (TC) dataset in the Korean Language Understanding Evaluation benchmark [23] was used. The TC dataset consists of news headlines and their categories: politics, economy, society, culture, world, information technology/science, and sports. The headlines were collected from online articles published from January 2016 to December 2020 by the Yonhap News Agency. During the annotation process, toxic content such as expressions of racism were removed. In addition, to disincentivize potential biases when collecting text data, examples were proactively removed both manually and automatically, from both unlabeled and labeled corpora, that reflect social biases, contain toxic content, and have personally identifiable information. Social biases are defined as overgeneralized judgments on certain individuals or groups based on social attributes (e.g., gender, ethnicity, and religion). Toxic content includes insults, sexual harassment, and offensive expressions. The TC dataset contains headlines, and the distribution of the dataset is presented in Figure 1. In total, 54,785 headlines were used across seven categories. The total number of tokens was 600,709 (500,899 for training and 99,810 for testing). The “World” category, which consists of international news headlines, had the most datasets, while the “IT/Science” category, which consists of technology or research-related news headlines, had the lowest number of datasets. The average number of news headlines was 7826.
3.2. Morphological Analyzers
To investigate the effect of morphological analyzers on news article topic categorization, five different morphological analyzers for Korean were adopted. The details of each morphological analyzer are described as follows.
3.2.1. Okt
The open-source Korean text processor (Okt) is an open-source Korean morphological analyzer developed by Twitter, providing normalization, tokenization, stemming, and phrase extraction. Through normalization, unstructured data, such as abbreviations, were processed. In tokenization, each morpheme was analyzed, and POS tagging was performed on a sentence. In stemming, the stem for each sentence was extracted, and phrase extraction was performed to identify words representing the subject of the sentence.
3.2.2. Mecab
Mecab [24] is a conditional random field model that performs unsupervised learning using a bigram and the scores of each word for tokenization. For input sentences, Mecab constructs a combination of possible words in the dictionary. To find the best combination, the scores of nodes and edges are output from the learning data. Words with high frequency within the learning data and frequent neighboring tag pairs have high scores. Scores are measured using the conditional random field model, and the Viterbi algorithm [25] is used to determine the best combination.
3.2.3. KKma
Kkma [26] is a Korean morphological analyzer for NLP, developed by Seoul National University (Intelligent Data Systems Laboratory, Seoul, South Korea), that is robust to spacing errors. All possible morphological analysis candidates are generated using dynamic programming, and the morpheme candidates are sorted in order of appropriateness. An adjacent condition inspection method in the precompiled dictionary is used to speed up the analysis, and several heuristic and hidden Markov models are used to improve the quality of the analysis.
3.2.4. Hannanum
Hannanum [27] is an open-source morphological analyzer developed by the Korea Advanced Institute of Science and Technology (Computational Intelligence Laboratory, Daejeon, South Korea). The analyzer consists of two parts: the main module and the submodules. The main module uses MorphAnalyzer and HMMtagger, and the submodule uses WebInputFilter, SentenceSplitter, UnknownProcessor, and USNProcessor. The analysis is performed as follows. First, when the input comes in, the input stream is divided into sentence units. The divided sentences enter MorphAnalyzer to perform morphological analysis on a given sentence. Unknown tags are processed using the UnknownProcessor, and exceptions arising from the rule-based morphological analysis are postprocessed using USNProcessor. Finally, the most likely candidate is selected using hidden Markov models. The detailed structure is presented in Figure 2.
3.2.5. Komoran
Komoran is a Korean morphological analyzer with the advantage of no dependence on an external library by using only a self-produced library. It is also very light to operate, with about 50 MB of memory. It is composed of a plain text file, so it is highly readable and can be edited immediately. In addition, it focuses on segmenting Korean text into its basic morphemes, such as words and particles, in order to provide a detailed analysis of the linguistic structure of the text. Komoran includes the following features: tokenization, POS tagging, compound word recognition, and unknown word handling. Tokenization breaks down sentences into meaningful morphemes such as nouns, verbs, adjectives, and particles. This tokenization identifies the root forms of words and the grammatical features of individual morphemes. POS tagging tags each morpheme, indicating the grammatical role and syntactic category of the word in a sentence. This information is used for understanding the sentence’s structure and meaning. In compound word recognition, Komoran can accurately recognize and segment compound words, which are common in Korean and can have unique meanings compared to their individual components. Komoran can handle unknown or out-of-vocabulary words by employing statistical methods and contextual analysis, improving its robustness in real-world applications. On the basis of these features, Komoran can effectively analyze morphemes in a sentence.
3.3. Term Frequency–Inverse Document Frequency (TF–IDF)
Term frequency–inverse document frequency (TF–IDF) is a statistical measure that evaluates how relevant a word is to a document in a collection. The TF–IDF method works by determining the relative frequency of words in a specific document compared to the inverse proportion of that word over the entire document corpus. The overall approach works as follows: given a sentence collection , a token , and an individual sentence , we calculate the following:
where is the number of times appears in is the size of the corpus, and is the number of sentences in which t appears in [4]. In this experiment, a set of sentences is the news topic dataset after the morphological analysis, where represents each title, and the token is finally extracted. Term frequency and inverse document frequency are calculated as described earlier, and the TF–IDF for document is calculated by multiplying the two. The dataset that has undergone the TF–IDF operation appears as a vector value (the number of vocabularies and the number of news topic data). Therefore, for each headline, it indicates how important the word is in the news topic dataset and how close it is to the main subject.
3.4. Light Gradient Boosting Machine
The gradient boosting machine (GBM) is a machine learning technique for regression or classification, producing a prediction model [5]. In GBM, a gradient-boosting decision tree (GBDT) is used extensively, but the GBDT, which must scan all data and determine all split points due to the emergence of big data, is less efficient. Light GBM (LGBM) was introduced to solve these problems [28]. LGBM solves the problems in the GBDT by reducing the number of instances and features of the data. The LGBM uses the gradient-based one-side sampling (GOSS) technique of reducing the number of data instances. The GOSS technique increases the number of large gradients and reduces small gradients of data. Then, the small gradient part of the data is amplified to reduce the number of overall data. The portion of small gradients is ignored, assuming that the data were trained well. Therefore, GOSS is an operation of ignoring fewer data to determine the best split. In addition, LGBM uses a technique called exclusive feature bundling, which reduces the number of features using the greedy bundling technique, merging exclusive features. First, for each feature, the greedy bundling technique determines which features must be bundled. Features allow each characteristic to bundle into a new one as independently as possible, not overlapping each other. Then, new feature sets are configured by merging expensive features. In this way, LGBM reduces the number and features of the data, performing much faster and more accurately than the conventional GBDT. In this experiment, the data entering the LGBM were the news topic data vectorized using the TF–IDF method. Each set of vocabularies was considered a feature. Of the total datasets, 80% was used as the training set, and the rest was used as the testing set. Each dataset was classified using the LGBM classifier.
4. Results
4.1. Morphological Analysis and Computational Time
To investigate how each morphological analyzer was used to perform POS tagging in the dataset, a sample text was extracted before and after using each morphological analyzer (Table 2). The results of each morphological analyzer are described as follows in detail.
In the Okt morphological analyzer, common and proper nouns were primarily tagged as “Noun”, and undefined morphemes were tagged as “Foreign”. Any morphemes that included numbers were tagged as “Number”. Because the titles of news articles generally consist of several words, most of the words in the sample were tagged as nouns. It seems that the advantage of the Okt morphological analyzer is to extract nouns clearly, and the potential problem might be unclassified types of nouns, such as proper and common nouns.
In the Mecab morphological analyzer, nouns were categorized into two types: common and proper nouns. In the sample text, common and proper nouns were tagged separately as “NNG” and “NNP”, respectively. In addition, numbers and units were separately tagged as “SN” and “NNBC”, respectively. Prepositions and postpositions were tagged as “JX”. One key difference between the Mecab morphological analyzer and the Okt morphological analyzer is that nouns were categorized into two distinct types, i.e., common and proper nouns. This phenomenon is an advantage of the Mecab morphological analyzer, since understanding the meaning of each noun could be crucial for topic categorization. One potential problem is that the Mecab morphological analyzer might not understand homonyms.
In the Kkma morphological analyzer, even proper nouns were tagged as multiple common nouns for detailed tagging. All proper nouns were split into common nouns as much as possible. For example, “Youtube” is a proper noun, but the Kkma morphological analyzer split it into “You” as one common noun and “Tube” as another common noun. This might be a potential problem in understanding the meaning of proper nouns that play a key role in topic categorization. One advantage of the Kkma morphological analyzer is that it is robust for word spacing, as shown in the sample text.
In the Hannanum morphological analyzer, if a sentence has no word spacing, tagging was poorly performed. Also, there was no detailed split for nouns; thus, any nouns were tagged as “N”. Interestingly, numbers and units were tagged as nouns, and this phenomenon may hinder understanding of the meaning of nouns in a sentence.
In the Komoran morphological analyzer, tagging was similar to that in the Mecab morphological analyzer, which separately tags common and proper nouns. These results indicate that even in the same sentence, each morphological analyzer tags the POS differently. Thus, there may be a need to confirm how a morphological analyzer performs tagging by inspecting the tagged units.
To investigate which morphological analyzer is effective in real-time NLP tasks, the computational time for the entire dataset for each morphological analyzer was calculated (Figure 3). The following system configurations were used: Intel i7-10700K processor, NVIDIA RTX 3070 GPU, 16 GB RAM, and 1 TB SSD. Among all the morphological analyzers, the Mecab morphological analyzer is the fastest because it uses unsupervised learning. In contrast, the Kkma morphological analyzer is the slowest due to its use of heuristic and hidden Markov models. In addition, because the Kkma morphological analyzer tends to split words as much as possible, it slows the tagging in sentences. These findings indicate that Mecab could be a good candidate for real-time NLP tasks.
4.2. Categorization Accuracy
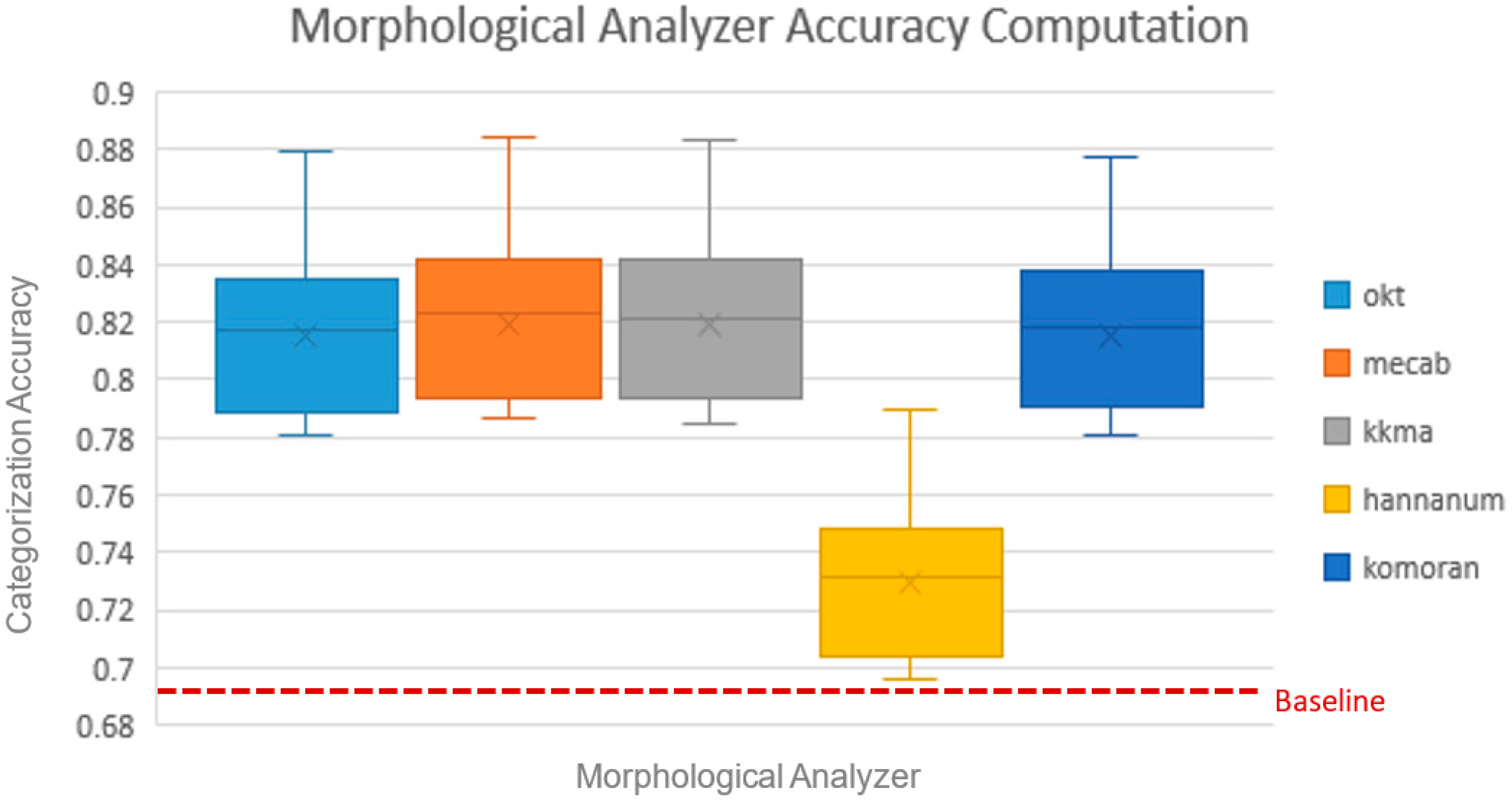
To investigate which morphological analyzer is effective for topic categorization, the categorization accuracy for the entire dataset for each morphological analyzer was calculated (Figure 4). To calculate categorization accuracy for each morphological analyzer, the feature vectors containing each token and its probability extracted by TF–IDF (described in Section 3.3) were used as input LGBM with parameters (maximum number of leaves: 31; number of boosted trees: 100). The total dataset was divided by 10; eight were used for training the LGBM, and two were used for calculating test accuracies with the trained LGBM. Also, the baseline categorization accuracy was computed without applying a morphological analyzer, to investigate the effects of each morphological analyzer. Categorization accuracies and F1 score for the morphological analyzers and baseline are tabulated in Table 3.
Most morphological analyzers perform well, with more than 80% accuracy for categorizing news topics. Hannanum has 73.26% accuracy, which is the lowest. Hannanum is sensitive to the input format, such as the spacing of the words and abbreviations. The news articles contain several abbreviations; thus, the morphological analysis might not work well. In contrast, the Kkma morphological analyzer achieved the highest performance, which may come from its detailed POS tagging process. These results indicate that Hannanum is not a good candidate and that Kkma could be an ideal analyzer for news article topic categorization.
To investigate how each morphological analyzer performs for each topic category, the classification accuracy for each topic for each morphological analyzer was calculated (Figure 5). In terms of the average across the topics, the classification accuracy of Sports was the highest because the topic includes several keywords, such as “basketball” and “soccer”. The topics with the second highest accuracy were Politics and World, which also contain technical terms. In contrast, for Economy and Society, there tended to be few keywords; thus, the accuracy was low for these topics for all morphological analyzers. By inspecting each morphological analyzer, it was found that Hannanum had significantly low accuracy for all topics except for Society. This outcome might be due to the mentioned problem with the input format of abbreviations or the spacing of words. These findings indicate that Hannanum poorly categorizes all news topics and that the sports topic is well categorized by most morphological analyzers.
5. Discussion
In this study, five different morphological analyzers were investigated to categorize topics in news articles. Interestingly, the Mecab morphological analyzer achieved the best categorization accuracy compared to the others, including the baseline (Figure 4 and Table 3). The Mecab morphological analyzer is known for its robust tokenization accuracy. It efficiently breaks down Korean text into meaningful tokens, which is essential for accurate categorization. Its dictionary-based approach and sophisticated algorithms enable it to handle various types of Korean text effectively. Also, the Mecab morphological analyzer provides detailed POS tagging, which can be valuable for text categorization. These characteristics may be a reason for achieving the best performance for news topic categorization. In contrast, the Hannanum morphological analyzer achieved the worst categorization accuracy among the five morphological analyzers. It has been criticized for its relatively weaker tokenization performance. It may struggle with certain complex or irregular word forms in Korean, leading to inaccuracies in tokenization. This can result in a less informative input representation for text categorization tasks, leading to lower accuracy. In addition, in terms of the computation time, Mecab and the Kkma achieved the fastest and slowest, respectively. Mecab employs a dictionary-based tokenization algorithm; this data structure allows for very efficient lookups and splitting of words based on dictionary entries. It prioritizes speed and simplicity, making it a popular choice for morphological analysis. In contrast, Kkma uses a more complex and computationally intensive approach based on recursiveness. This method involves recursively breaking down a sentence into its constituent morphemes, which can be a more time-consuming process.
Agglutinative languages are characterized by their tendency to form words and convey grammatical information through the addition of discrete affixes [29]. In Korean, this phenomenon is observed in the structure of verbs and adjectives [30]. For instance, verb conjugations in Korean involve the attachment of suffixes to the verb stem to indicate tense, mood, aspect, and honorifics. This highly modular approach to morphological construction is a hallmark of agglutinative languages. The agglutinativeness of Korean is evident not only in its morphological structure but also in its syntax. The Korean language exhibits a consistent tendency to separate different grammatical elements within a sentence, with a clear demarcation between subject, object, verb, and modifiers. The use of postpositions to indicate grammatical relationships further underscores this agglutinative quality. In contrast to fusional languages, where multiple grammatical meanings may be compressed into a single morpheme, Korean employs a more transparent approach by adding discrete elements to convey distinct syntactic and semantic nuances. Therefore, morphological analysis for Korean plays a key role in enhancing the accuracy and effectiveness of topic categorization. This study explored how each morphological analyzer influences the performance of the topic categorization of news articles, and this study could provide new insight into the understanding of agglutinative languages.
Topic categorization, a fundamental task in NLP, assumes a key role in the analysis and comprehension of news articles [31]. News articles encompass a vast array of subjects, from politics and economics to sports and entertainment. Efficient topic categorization acts as a navigational aid, enabling readers to access articles of interest. By categorizing news articles into distinct topics, users can easily locate and access relevant information, streamlining the process of information retrieval amidst the influx of available content. In addition, topic categorization offers a structured framework for organizing news articles, enabling media outlets and platforms to present content in an organized and coherent manner. Thus, analyzing trends and patterns within news articles is essential for understanding public sentiments, societal shifts, and emerging issues. Recently, machine and deep learning–based approaches for topic categorization have been widely used, and their performance is comparable to that of human understanding [32]. This study used machine learning approaches rather than deep learning–based ones to understand how each morphological analyzer extracts meaningful information step by step. This study also investigated how each morphological analyzer affects the categorization performance for news articles. The results revealed relatively comparable performance for the categorization of news articles across the five different morphological analyzers, and it was determined which morphological analyzer works best for topic categorization in news articles, especially for those written in Korean.
As with any scientific study, this study has limitations. First, only the KLUE dataset was tested for the topic categorization task; thus, future work should consider different datasets to verify the findings of this study. Second, only the classification task was performed; thus, other NLP tasks, such as text summarization or question and answer, should be tested in future work. Third, this study focused on the dataset of Korean news articles. Such a narrow scope can limit the generalization to a broader range. In future work multiple languages will be incorporated into the research to facilitate a more comprehensive understanding of linguistic features and cultural differences. Overall, this study suggests how each morphological analyzer is used for Korean text and what news topics are classified well, regardless of the morphological analyzer.
6. Conclusions
This study explored how morphological analyzers perform POS tagging and determined the categorization accuracy for news articles for each morphological analyzer. The Hannanum morphological analyzer achieved poor performance due to its sensitivity to abbreviations and word spacing, while the other analyzers achieved comparable performance. When considering the computational time, the Mecab morphological analyzer could be an ideal case. In addition, news topics that contain several keywords were classified well across all analyzers, while news topics with few keywords, such as Society and Economy, were classified poorly. Therefore, the findings of this study can provide insight into how each morphological analyzer extracts meaningful information and performs POS tagging and how different morphological analyzers influence the categorization performance for news articles.
Funding
This work was supported by the National Research Foundation of Korea (NRF) Grant funded by the Korea government (MSIT) (No. NRF-2022R1A4A1023248 and No. RS-2023-00209794).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this study is publicly available.
Conflicts of Interest
The author declares no conflict of interest.
References
- Chowdhury, G.G. Natural Language Processing. Annu. Rev. Inf. Sci. Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef]
- Jones, K.S. Natural Language Processing: A Historical Review. In Current Issues in Computational Linguistics: In Honour of Don Walker; Springer: Berlin/Heidelberg, Germany, 1994; pp. 3–16. [Google Scholar] [CrossRef]
- Goldberg, Y. A Primer on Neural Network Models for Natural Language Processing. J. Artif. Intell. Res. 2015, 57, 345–420. [Google Scholar] [CrossRef]
- Ramos, J. Using TF-IDF to Determine Word Relevance in Document Queries. In Proceedings of the First Instructional Conference on Machine Learning, Los Angeles, CA, USA, 23–24 June 2003. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Statist. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Li, Z.; Shang, W.; Yan, M. News Text Classification Model Based on Topic Model. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science, ICIS 2016, Okayama, Japan, 26–29 June 2016. [Google Scholar] [CrossRef]
- Kumaran, G.; Allan, J. Text Classification and Named Entities for New Event Detection. In Proceedings of the Sheffield SIGIR—Twenty-Seventh Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 297–304. [Google Scholar] [CrossRef]
- Lee, Y.S.; Lo, R.; Chen, C.Y.; Lin, P.C.; Wang, J.C. News Topics Categorization Using Latent Dirichlet Allocation and Sparse Representation Classifier. In Proceedings of the 2015 IEEE International Conference on Consumer Electronics—Taiwan, ICCE-TW, Taipei, Taiwan, 6–8 June 2015; pp. 136–137. [Google Scholar] [CrossRef]
- Cai, L.; Hofmann, T. Text Categorization by Boosting Automatically Extracted Concepts. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 182–189. [Google Scholar] [CrossRef]
- Nurfikri, F.S.; Mubarok, M.S.; Adiwijaya. News Topic Classification Using Mutual Information and Bayesian Network. In Proceedings of the 2018 6th International Conference on Information and Communication Technology, ICoICT, Bandung, Indonesia, 3–5 May 2018; pp. 162–166. [Google Scholar] [CrossRef]
- Daud, S.; Ullah, M.; Rehman, A.; Saba, T.; Damaševičius, R.; Sattar, A. Topic Classification of Online News Articles Using Optimized Machine Learning Models. Computers 2023, 12, 16. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C.; Ca, J.U.; Kandola, J.; Hofmann, T.; Poggio, T.; Shawe-Taylor, J. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the NAACL HLT 2018—2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Lancichinetti, A.; Irmak Sirer, M.; Wang, J.X.; Acuna, D.; Körding, K.; Amaral, L.A. A High-Reproducibility and High-Accuracy Method for Automated Topic Classification. Phys. Rev. X 2014, 5, 011007. [Google Scholar] [CrossRef]
- Lee, S.; Kim, H. News Keyword Extraction for Topic Tracking. In Proceedings of the 2008 Fourth International Conference on Networked Computing and Advanced Information Management, Gyeongju, Republic of Korea, 2–4 September 2008; Volume 2, pp. 554–559. [Google Scholar]
- Cho, S.W.; Cha, M.; Sohn, K.-A. Topic Category Analysis on Twitter via Cross-Media Strategy. Multimed. Tools Appl. 2016, 75, 12879–12899. [Google Scholar] [CrossRef]
- An, J.; Kwak, H. Multidimensional Analysis of the News Consumption of Different Demographic Groups on a Nationwide Scale. In Proceedings of the Social Informatics: 9th International Conference, SocInfo 2017, Oxford, UK, 13–15 September 2017; Proceedings, Part I 9. Springer: Berlin/Heidelberg, Germany, 2017; pp. 124–142. [Google Scholar]
- Suh, Y.; Yu, J.; Mo, J.; Song, L.; Kim, C. A Comparison of Oversampling Methods on Imbalanced Topic Classification of Korean News Articles. J. Cogn. Sci. 2017, 18, 391–437. [Google Scholar]
- Chuluunsaikhan, T.; Ryu, G.A.; Yoo, K.H.; Rah, H.; Nasridinov, A. Incorporating Deep Learning and News Topic Modeling for Forecasting Pork Prices: The Case of South Korea. Agriculture 2020, 10, 513. [Google Scholar] [CrossRef]
- Park, S.; Moon, J.; Kim, S.; Cho, W.I.; Han, J.; Park, J.; Song, C.; Kim, J.; Song, Y.; Oh, T.; et al. KLUE: Korean Language Understanding Evaluation. arXiv 2021, arXiv:2105.09680. [Google Scholar] [CrossRef]
- Wumaier, A.; Yibulayin, T.; Kadeer, Z.; Tian, S. Conditional Random Fields Combined FSM Stemming Method for Uyghur. In Proceedings of the 2009 2nd IEEE International Conference on Computer Science and Information Technology, ICCSIT 2009, Beijing, China, 8–11 August 2009; pp. 295–299. [Google Scholar] [CrossRef]
- Forney, G.D. The Viterbi Algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Lee, D.; Yeon, J.; Hwang, I.; Lee, S. KKMA : A Tool for Utilizing Sejong Corpus Based on Relational Database. J. KIISE:Comput. Pract. Lett. 2010, 16, 1046–1050. [Google Scholar]
- Park, E.L.; Cho, S. KoNLPy: Korean Natural Language Processing in Python. In Proceedings of the Annual Conference on Human and Language Technology, Chuncheon, Republic of Korea, 10–11 October 2014; pp. 133–136. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 2017, 3147–3155. [Google Scholar]
- Dhanalakshmi, V.; Anandkumar, M.; Rekha, R.U.; Arunkumar, C.; Soman, K.P.; Rajendran, S. Morphological Analyzer for Agglutinative Languages Using Machine Learning Approaches. In Proceedings of the ARTCom 2009–International Conference on Advances in Recent Technologies in Communication and Computing, Kottayam, India, 27–28 October 2009; pp. 433–435. [Google Scholar] [CrossRef]
- Kim, Y.-B.; Chae, H.; Snyder, B.; Kim, Y.-S. Training a Korean Srl System with Rich Morphological Features. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 637–642. [Google Scholar]
- Ramraj, S.; Arthi, R.; Murugan, S.; Julie, M.S. Topic Categorization of Tamil News Articles Using Pretrained Word2vec Embeddings with Convolutional Neural Network. In Proceedings of the 2020 International Conference on Computational Intelligence for Smart Power System and Sustainable Energy (CISPSSE), Keonjhar, India, 29–31 July 2020; pp. 1–4. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning—Based Text Classification: A Comprehensive Review. ACM Comput. Surv. CSUR 2021, 54, 1–40. [Google Scholar] [CrossRef]
Figure 1.
Distribution of the number of headlines within seven news topic categories: IT/Science, Economy, Society, Culture, World, Sports, and Politics.
Figure 1.
Distribution of the number of headlines within seven news topic categories: IT/Science, Economy, Society, Culture, World, Sports, and Politics.

Figure 2.
Structure of the Hannanum morphological analyzer.

Figure 3.
Computational time of each morphological analyzer in the dataset.

Figure 4.
Categorization accuracy across morphological analyzers. The boxplots indicate maximum, minimum, third quartile, first quartile, median (horizontal line in the box), and mean (symbol ×) values for each morphological analyzer. Baseline indicates categorization accuracy without applying a morphological analyzer.
Figure 4.
Categorization accuracy across morphological analyzers. The boxplots indicate maximum, minimum, third quartile, first quartile, median (horizontal line in the box), and mean (symbol ×) values for each morphological analyzer. Baseline indicates categorization accuracy without applying a morphological analyzer.

Figure 5.
Bar plot of categorization performance for each morphological analyzer in seven categories. Note that each category has a different number datasets and this may affect the categorization performance.
Figure 5.
Bar plot of categorization performance for each morphological analyzer in seven categories. Note that each category has a different number datasets and this may affect the categorization performance.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Studies on morphological analysis for news topic categorization.
| References | Morphological Analysis | Strengths | Weaknesses |
|---|---|---|---|
| Lee et al. [18] | Keyword extraction | Categorization can be applied to any news domain using cross-domain filtering | Words that have less probability of appearance can be ignored |
| Cho et al. [19] | Noun extraction | Topic categorization over time can be analyzed using the time information | Other meaningful morphemes can be ignored |
| An et al. [20] | Keyword extraction | Categorization can be divided into multiple levels of topics | Words that have less probability of appearance can be ignored |
| Suh et al. [21] | Noun extraction | Oversampling is used to overcome the problem of imbalanced data | Other meaningful morphemes can be ignored |
| Chuluunsaikhan et al. [22] | Tokenization and removing punctuation and stop-words | Price over time can be predicted using deep learning | Other meaningful morphemes can be ignored |
Table 2.
Part-of-speech tagging for each morphological analyzer. Notes: NNP: proper noun; NNG: common noun; SN: number; NNBC: measure noun; JX: postposition; NR: number; NNM: unit dependent noun; JKM: adverbial case marker; MDT: general determiner; N: noun; J: postposition.
Table 2.
Part-of-speech tagging for each morphological analyzer. Notes: NNP: proper noun; NNG: common noun; SN: number; NNBC: measure noun; JX: postposition; NR: number; NNM: unit dependent noun; JKM: adverbial case marker; MDT: general determiner; N: noun; J: postposition.
| Korean | Translated into English | |
|---|---|---|
| Sample text | [유튜브 내달 2일까지 크리에이터 지원 공간 운영] | YouTube Organizes Space Support for Creators Until 2nd Day Upcoming Month |
| Okt | [(‘유튜브’, ‘Noun’), (‘내달’, ‘Noun’), (‘2일’, ‘Number’), (‘까지’, ‘Foreign’), (‘크리에이터’, ‘Noun’), (‘지원’, ‘Noun’), (‘공간’, ‘Noun’), (‘운영’, ‘Noun’)] | ‘Youtube.’ ‘Upcoming Month,’ ‘2nd day’, ‘Until,’ ‘Creator,’ ‘Support,’ ‘Space,’ ‘Organizes’ |
| Mecab | [(‘유튜브’, ‘NNP’), (‘내달’, ‘NNG’), (‘2’, ‘SN’), (‘일’, ‘NNBC’), (‘까지’, ‘JX’), (‘크리에이터’, ‘NNP’), (‘지원’, ‘NNG’), (‘공간’, ‘NNG’), (‘운영’, ‘NNG’)] | ‘Youtube,’ ‘Upcoming Month,’ ‘2nd, day’, ‘Until,’ ‘Creators,’ ‘Support,’ ‘Spaces,’ ‘Organizes’ |
| Kkma | [(‘유’, ‘NNG’), (‘튜브’, ‘NNG’), (‘내달’, ‘NNG’), (‘2’, ‘NR’), (‘일’, ‘NNM’), (‘까지’, ‘JX’), (‘크리’, ‘NNG’), (‘에’, ‘JKM’), (‘이’, ‘MDT’), (‘터’, ‘NNG’), (‘지원’, ‘NNG’), (‘공간’, ‘NNG’), (‘운영’, ‘NNG’)] | ‘You,’’Tube,’ ‘Upcoming Month,’ ‘2′, ‘Day,’ ‘Until,’ ‘Cr,’ ‘e,’ ‘a’, ‘tor,’ ‘Support,’ ‘Space,’ ‘Organizes’ |
| Hannanum | [(‘유튜브’, ‘N’), (‘내달’, ‘N’), (‘2일’, ‘N’), (‘까지’, ‘J’), (‘크리에이터’, ‘N’), (‘지원’, ‘N’), (‘공간’, ‘N’), (‘운영’, ‘N’)] | ‘Youtube,’ ‘Upcoming Month,’ ‘2nd day’, ‘Until,’ ‘Creator,’ ‘Support,’ ‘Space,’ ‘Organizes’ |
| Komoran | [(‘유튜브’, ‘NNP’), (‘내달’, ‘NNG’), (‘2’, ‘SN’), (‘일’, ‘NNB’), (‘까지’, ‘JX’), (‘크리에이터’, ‘NNP’), (‘지원’, ‘NNG’), (‘공간’, ‘NNG’), (‘운영’, ‘NNG’)] | ‘Youtube,’ ‘Upcoming Month,’ ‘2nd’, ‘day,’ ‘Until,’ ‘Creator,’ ‘Support,’ ‘Space,’ ‘Organizes’ |
Table 3.
Averaged categorization accuracy and F1 score for the baseline and morphological analyzers.
Table 3.
Averaged categorization accuracy and F1 score for the baseline and morphological analyzers.
| Accuracy | F1 Score | |
|---|---|---|
| Baseline | 69.1% | 0.667 |
| Okt | 81.7% | 0.812 |
| Mecab | 82.5% | 0.824 |
| KKma | 82.1% | 0.817 |
| Hannanum | 73.1% | 0.724 |
| Komoran | 81.8% | 0.809 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ahn, S. Experimental Study of Morphological Analyzers for Topic Categorization in News Articles. Appl. Sci. 2023, 13, 10572. https://doi.org/10.3390/app131910572
AMA Style
Ahn S. Experimental Study of Morphological Analyzers for Topic Categorization in News Articles. Applied Sciences. 2023; 13(19):10572. https://doi.org/10.3390/app131910572
Chicago/Turabian StyleAhn, Sangtae. 2023. "Experimental Study of Morphological Analyzers for Topic Categorization in News Articles" Applied Sciences 13, no. 19: 10572. https://doi.org/10.3390/app131910572
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.