1. Introduction
With the advancement of information technology, many complex systems in real life can often be described and represented in the form of complex networks, such as social networks, citation networks, scientist collaboration networks, and protein interaction networks. The majority of these real-life networks typically exhibit distinct community structures, where a network consists of multiple communities, and the connections between nodes within a community are highly dense, while connections between nodes of different communities are relatively sparse [
1]. Community detection is a fundamental task in the analysis of complex networks, aiming to partition the entire network into several communities. This process holds significant importance for studying and analyzing the organizational structure and functionality of networks, as well as uncovering latent patterns within them.
There has been a great deal of research in detecting and evaluating community structures in complex networks. In pursuit of this fundamental task of community detection, researchers have proposed numerous community detection algorithms based on various methods such as graph partitioning, statistical inference, clustering, modularity optimization, dynamics, and deep learning. More detailed reviews of community detection can be available through several more extensive review articles [
2,
3,
4,
5,
6]. Among many methods, dynamics-based methods constitute a significant branch of community detection algorithms, which reveal the community structure by modeling the interactions between nodes in a network. Currently, some of the mainstream dynamic-based community detection algorithms include label propagation, random walk, Markov clustering, dynamic distance, and particle competition [
7].
To further improve the accuracy and stability of community detection algorithms, competitive learning is applied to the field of community detection. Competition is a natural process observed in the natural world and many social systems with limited resources. Competitive learning, as a crucial machine learning strategy, has been widely applied in artificial neural networks for achieving unsupervised learning. Early developments include Adaptive Resonance Theory networks [
8], Self-Organizing Feature Map networks [
9], Learning Vector Quantization neural networks [
10], Dual Propagation neural networks [
11], and Differential Competitive Learning [
12]. The competition among particles in complex networks can generate intricate patterns formed by predefined interactions among individuals within a system. The simple interactions between particles in a network can construct the complex behaviors of the entire network, enabling functions like community detection and node classification. Particle competition-based community detection methods were first proposed by Quiles and Zhao [
13]. In this approach, a set of particles is initially placed randomly in the network. These particles engage in random walks and compete with each other based on predefined rules to occupy nodes. When each community is dominated by only one particle, the process reaches dynamic equilibrium, thus accomplishing the community detection task. Silva et al. [
14] introduced the Stochastic Competitive Learning (SCL) algorithm for unsupervised learning, refining the walk rules of the particle competition model. Particles move in the network based on a convex combination of random walk and preferential walk rules. After entering a silent state due to energy depletion, particles execute a jump resurrection step. The final attribution of nodes to communities is determined based on the relative control abilities of particles, achieving the community detection task. The SCL algorithm represents a nonlinear stochastic dynamical system, characterized by adaptability, local motion reflecting the whole, and has contributed to the advancement of complex network dynamics. Subsequently, stochastic competitive learning has found extensive application in various fields such as label noise detection [
15], overlapping community detection [
16], prediction of the number of sentiment evolution communities [
17], graph anomaly detection [
18], image segmentation [
19], and assisting the visually impaired [
20]. These applications have demonstrated the feasibility, rationality, and effectiveness of applying stochastic competitive learning to the domain of complex network community detection.
Despite the commendable effectiveness of the stochastic competitive learning algorithm in various fields, it has been found that the algorithm still has some shortcomings in the community detection task. Firstly, the random selection of initial positions for particles in stochastic competitive learning leads to unstable community detection outcomes. This randomness might result in an overly concentrated placement of different particles, affecting convergence speed and subsequently diminishing the quality of community detection. Secondly, the stochastic nature of the preferential walk process of particles and the uncertainty in selecting resurrection positions upon energy depletion contribute to suboptimal final results. Lastly, the constant increment in particle control ability leads to potential misjudgments in affiliating boundary nodes between communities of varying scales. The above issues make stochastic competitive learning underperform on community discovery tasks.
In order to address the aforementioned issues, this paper proposes the Local Node Similarity-Integrated Stochastic Competitive Learning algorithm LNSSCL for unsupervised community detection. The algorithm first integrates the node degree and Salton metrics to determine the starting point of particle walk in the network. During the particle walk process, the wandering direction is guided by the walk rule that incorporates the local similarity of nodes. At the same time, the control ability of the particle is dynamically adjusted according to its current control range. When a particle runs out of energy, it is assigned a unique resurrection position. After the wandering is completed, the community label is adjusted through the node affiliation selection step to obtain the final community discovery result. The main objectives and contributions of this study are as follows:
- (1)
Determining the initial positions of particles based on node degrees and the Salton similarity index, ensuring fixed and dispersed particle placements to mitigate intense early-stage competition and subsequently accelerate convergence speed;
- (2)
Incorporating the proposed node similarity measure to enhance the deterministic and directional aspects of particle preferential walk rules; refining the rules for selecting particle resurrection positions; introducing a node affiliation selection step to refine the final community detection results and enhance algorithm stability;
- (3)
Dynamically adapting the increment of particle control ability according to the particle’s current control range, thereby improving the effectiveness of detecting communities of varying sizes within the network;
- (4)
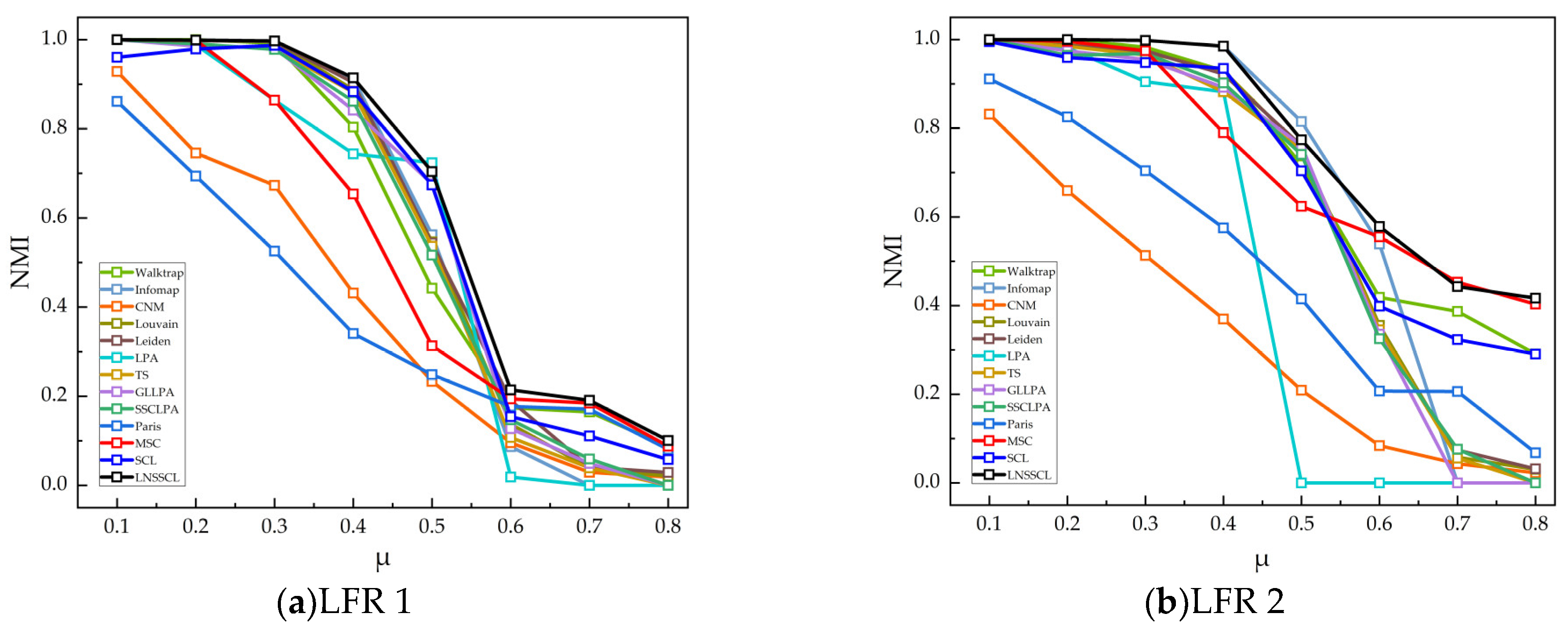
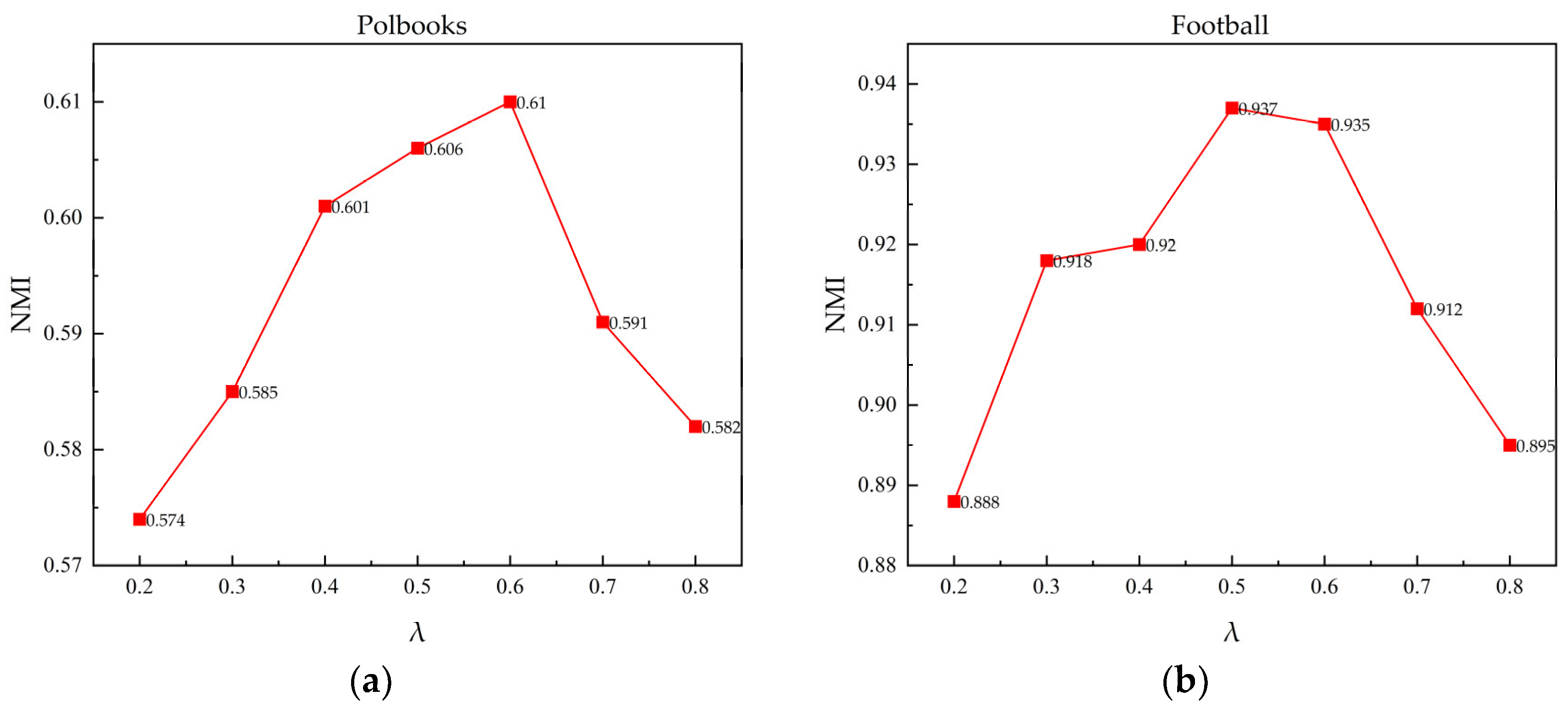
The LNSSCL algorithm is experimentally compared with 12 representative algorithms on real network datasets and synthetic networks. The results demonstrate that the proposed algorithm enhances the community detection performance of stochastic competitive learning and, overall, outperforms other algorithms.
The remainder of this paper is organized as follows.
Section 2 presents related work.
Section 3 introduces some related preliminary knowledge.
Section 4 describes the details and main framework of the proposed LNSSCL algorithm. The experiments are shown and discussed in
Section 5.
Section 6 gives the conclusions of this paper.
2. Related Work
Complex networks can model various relationships and internal operating mechanisms between entities and objects in the real world. Detecting the community structure present in the network can help us further reveal aspects of the real world. Therefore, community detection in complex networks has received attention from many fields and is rapidly evolving. Among the many methods proposed, Dynamics-based methods utilize the dynamic properties of complex networks. Most of these algorithms have linear time complexity and can be better scaled to large-scale networks. Since it is impractical to review all previously proposed algorithms for community detection, this section mentions only some representative algorithms from recent years.
Roghani et al. [
21] introduced a community detection algorithm based on local balance label diffusion. They assigned importance scores to each node using a novel local similarity measure, selected initial core nodes, and expanded communities by balancing the diffusion of labels from core to boundary nodes, achieving rapid convergence in large-scale networks with stable and accurate results. Toth et al. [
22] proposed the Synwalk algorithm, which incorporates the concept of random blocks into random walk-based community detection algorithms, combining the strengths of representative algorithms like Walktrap [
23] and Infomap [
24], yielding promising results. Yang et al. [
25] introduced a method of enhancing Markov similarity, which utilizes the steady-state Markov transition of the initial network to derive an enhanced Markov similarity matrix. By partitioning the network into initial community structures based on the Markov similarity index and subsequently merging small communities, tightly connected communities are obtained. Jokar et al. [
26] proposed a community discovery algorithm based on the synergy of label propagation and simulated annealing, which achieved good results. You et al. [
27] proposed a three-stage community discovery algorithm TS, which obtained good results through central node identification, label propagation, and community combination. Fahimeh et al. [
28] proposed a community detection algorithm that utilizes both local and global network information. The algorithm consists of four components: preprocessing, master community composition, community merging, and optimal community structure selection. Zhang et al. [
29] propose a graph layout-based label propagation algorithm to reveal communities in a network, using multiple graph layout information to detect accurate communities and improve stability. Chin et al. [
30] proposed the semi synchronization constrained label propagation algorithm SSCLPA, which implements various constraints to improve the stability of LPA. Fei et al. [
31] proposed a novel network core structure extraction algorithm for community detection (CSEA) using variational autoencoders to discover community structures more accurately. Li et al. [
32] developed a new community detection method and proposed a new relaxation formulation with a low-rank double stochastic matrix factorization and a corresponding multiplicative optimization-minimization algorithm for efficient optimization.
4. LNSSCL Algorithm
To enhance the stability and accuracy of community detection results, improvements have been made in various aspects such as particle initialization positions, particle preferential walking rules, particle control ability increments, particle resurrection position selection, and the introduction of node affiliation selection. In light of these enhancements, we propose the Unsupervised Community Detection Algorithm with Stochastic Competitive Learning Incorporating Local Node Similarity, which integrates local node similarity into the stochastic competitive learning framework.
4.1. Determining Particle Initialization Positions
The Stochastic Competitive Learning algorithm stipulates that each particle randomly selects a different node in the network as its starting position for walking. The random uncertainty in particle initialization can lead to unstable community detection outcomes. Additionally, this initialization approach might result in particles’ starting positions clustering within a single community, intensifying the competitive relationships among particles during their walks. This situation requires a considerable amount of time for convergence. Addressing these concerns, the random placement for initialization is abandoned. Instead, each particle’s initial position is determined based on the node’s degree and the Salton similarity index between nodes. This approach aims to distribute particles across different communities as much as possible, accelerating the convergence rate of particle walks and enhancing the stability of community detection outcomes.
Node degree is commonly used to measure the importance of a node within the entire network, while the Salton similarity index is often employed to gauge the similarity between a node and its neighboring nodes. It is defined as follows:
Combining the two aforementioned metrics, the rules for determining particle initialization positions are as follows. Firstly, arrange all nodes in the network in descending order based on their degree values. Select the node with the highest degree value as the starting position for the first particle’s walk. Next, calculate the average Salton similarity index between the node where the already determined starting-position particle is located and all other nodes in the network. Choose the node with the smallest average Salton similarity index as the starting position for the next particle. This process is then repeated iteratively to progressively determine the starting positions for the remaining particles. Finally, when the starting position for each particle is determined, the particle initialization process is completed.
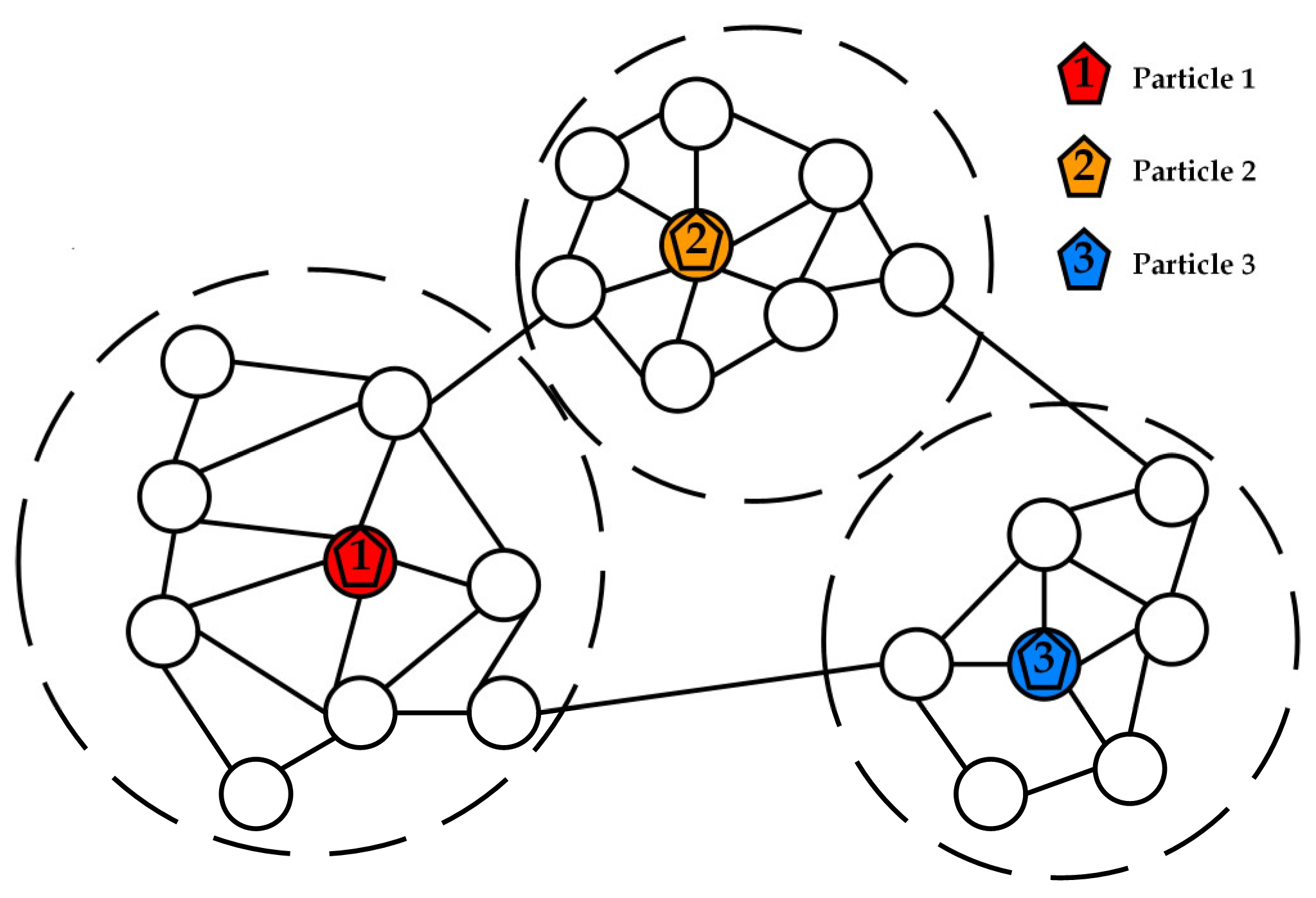
Figure 1 depicts the particle initialization position under the condition of three particles. As can be seen from the figure, particles 1, 2, and 3 are dispersed and placed in the network after the position initialization step.
denotes the starting position of particle
. The rules for determining particle initialization positions can be expressed as follows:
4.2. Incorporating Node Local Similarity into Particle Preferential Movement Rule
The stochastic competitive learning algorithm stipulates that particles navigate through the network based on a convex combination of random walk and preferential walk rules. The preferential walk rule ensures that particles preferentially access nodes under their control, reflecting the deterministic nature of particle traversal, and numerically equivalent to the particle’s control ability ratio. However, this rule solely focuses on the particle’s control ability over nodes, without considering the influence of node local similarity indicators. This may lead to a relatively high degree of randomness and weak inclination in the initial direction of preferential walk, thereby affecting the stability and accuracy of community detection results. To address these issues, an enhancement to the particle preferential walk rule is introduced by incorporating node similarity, enabling nodes with greater similarity to be more likely visited by particles. This modification enhances the directionality and determinism of particle traversal during the walk.
The improved node similarity for the enhanced particle preferential walk rule not only considers cases where nodes share common neighbors, but also accounts for situations where nodes lack common neighbors. When there are shared neighbors between nodes, a similarity index considering both common neighbors and degree difference is employed to measure the degree of similarity between two nodes, as defined below:
For nodes
and
, if
, then
is set to
, and
is set to
; if
, then
is set to
, and
is set to
. When there are no shared neighbors between nodes, further consideration is needed for nodes with a degree value of 1. For nodes without shared neighbors and with a degree value of 1, since their behavior is solely related to their unique first-order neighbor, their similarity value is set to 1. For nodes without shared neighbors and with a degree value greater than 1, their similarity is associated with the node’s degree value. Based on the negative correlation between node degree and the unfavorable Hub Depressed Index, the degree value is inversely related to its similarity. The equation for calculating the similarity between nodes without shared neighbors is defined as follows:
Building upon this, the equation for the particle’s preferential walk rule incorporating node similarity is provided:
where
represents the similarity index between nodes
and
, and
represents the control capacity of particle
over node
. The improved preferential walk rule takes into account both the particle’s control capacity over nodes and the similarity index between nodes as equally significant factors. This approach avoids the issue of randomness in the preferential walk direction that arises after particle initialization, thereby enhancing the inclination and certainty of particle movement throughout the entire preferential walk process.
4.3. Dynamically Adjusting Particle Control Capacity Increment
In the Stochastic Competitive Learning algorithm, the control capacity of particles is quantified as the proportion of node visits, thereby the number of times a particle visits a node determines its control capacity over that node. When particle
visits node
, the equation for the change in the particle’s visit count to that node is given by:
According to Equation (14), it can be observed that the increment of particle control capacity remains constant at 1. This would lead to particles having the same level of competitive increment during the walking process. This uniform competitive increment among different particles could potentially result in similar community sizes controlled by different particles. Consequently, this might lead to instances where representative particles of smaller communities erroneously compete for nodes at the boundaries of larger communities. However, many real-life complex systems, represented as complex networks, often encompass communities of varying sizes. The constant increment in particle control capacity could potentially yield suboptimal results in the final community detection outcome.
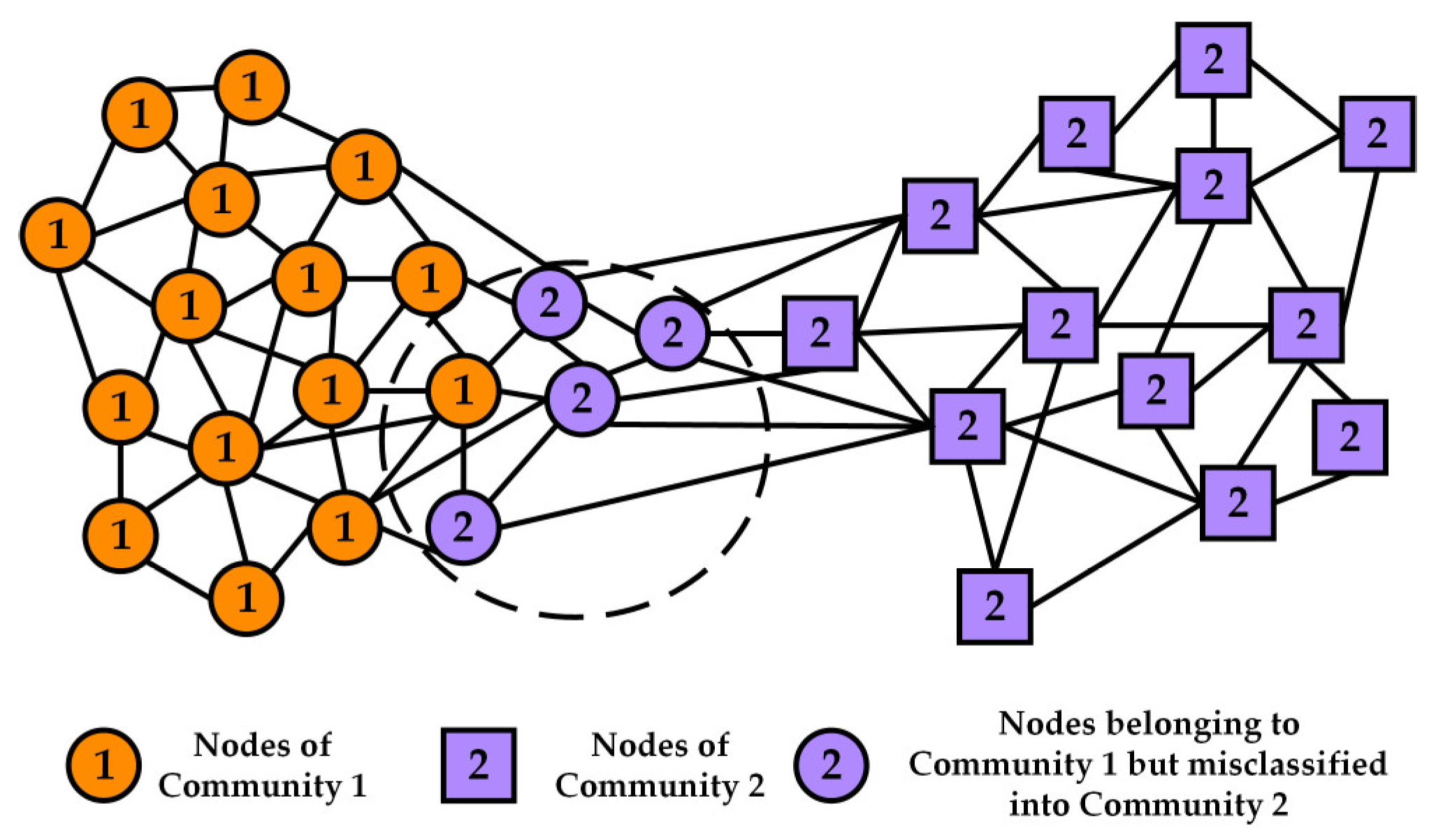
Figure 2 depicts the possible encroachment of a small community into a large community node when the particle control capacity increment is constant. The size of community 1 in the figure is actually larger than that of community 2. However, because of the constant particle control capacity increment, it makes it possible for the range of communities controlled by each particle to converge to the same size. This then causes nodes that should belong to community 2 to be misclassified to community 2.
Addressing the aforementioned issues, an improvement is made to the particle control capacity increment in order to enhance the effectiveness of discovering communities of varying sizes within the network. The enhanced particle control capacity increment is dynamically adjusted based on the current control range of the particle, and the specific equation is provided below:
where
represents the current control range of particle
, which indicates the number of nodes currently under the control of particle
. From Equation (15), it can be observed that the particle’s control capacity increment is positively correlated with its current control range. This relationship can unveil community structures of different sizes within the network and prevent particles from erroneously encroaching upon nodes located at the boundaries of communities.
4.4. Determining Particle Resurrection Locations and Node Affiliation Selection
In stochastic competitive learning, when a particle visits a node under its control, its energy increases. On the other hand, when it visits a node controlled by a competing particle, its energy decreases. This energy manipulation serves to constrain the particle’s walking range, thus reducing long-range and redundant accesses in the network. If a particle frequently visits nodes controlled by competing particles, its energy will continuously decrease until it is exhausted and enters a dormant state. Subsequently, the particle will randomly jump to a node within its control range to revive and recharge.
Clearly, the choice of the particle’s revival location has a high degree of randomness, which can lead to unstable community detection results. To address this issue, based on the particle’s control over nodes, we select the node with the highest control capability as the unique revival location among the nodes it already controls, eliminating the uncertainty in location selection. If a particle currently doesn’t control any nodes, it will randomly choose any node in the network for revival. The improved particle revival location selection is shown in
Figure 3, where the energy of particle 1 is depleted due to its traversal into the control region of particle 3. After the improvement, particle 1 will no longer randomly jump to any controlled node within the dashed box, but will instead jump to the node indicated by the dashed arrow (assuming that node has the highest control capability value for particle 1).
Once the algorithm reaches the convergence criterion, particles will cease their walks. Based on the control capabilities of each particle over nodes, all nodes in the network are assigned to the corresponding communities represented by particles. However, due to the potential randomness and potential misclassifications in the steps executed by particles before stopping their walks, a node membership selection step is introduced. By considering the frequency of community labels among neighboring nodes, this step ensures that each node is correctly assigned to its appropriate community, further optimizing the community detection outcomes. Specifically, for each node, the occurrence frequency of community labels among its neighboring nodes is observed. If the most frequent neighboring community label is unique, it is selected as the community label for that node. If the most frequent neighboring community label is not unique, an influence score is computed for each community, and the community label with the highest influence score is selected. The influence score
for a community is calculated as shown in the equation below:
where
is one of the most frequent communities, and
represents the set of neighboring nodes of node
.
4.5. Algorithm Description
Algorithm 1 describes the method of the LNSSCL algorithm; the pseudocode is shown below.
| Algorithm 1 LNSSCL algorithm |
Input: Graph
The probability of preferential walk for particles , |
| Particle energy increment , Convergence factor |
| Output: The number of communities , The set of communities |
| 1:
|
| 2:
|
| 3:
repeat |
| 1: for each particle do: |
| 5: calculate the initial positions of particles using Equation (10) |
| 6:
end for |
| 7:
repeat |
| 8: for to do: |
| 9: calculate the particle’s random walk probability using Equation (4) |
| 10: calculate the particle’s preferential walk probability using Equation (11), (12), and (13) |
| 11: calculate the particle’s walk probability using Equation (3) |
| 12: particles walk based on the walk probability and dynamically adjust the particle’s control increment using Equation (15) |
| 13: if : |
| 14: particle performs the revival step by jumping to the node within their control range that possesses the maximum control capability for revival and re-energization. |
| 15:
end if |
| 16:
end for |
| 17: update , , , |
| 18:
|
| 19: until Equation (7) is satisfied |
| 20: calculating and record the average maximum control capability indicator for particles using Equation (8). |
| 21:
|
| 22: until reaches its maximum value |
| 23: assign the number of particles corresponding to step 22 to |
| 24: for each node do: |
| 25: Assign the corresponding community label to node based on the mag- nitude relationship of |
| 26:
end for |
| 27: for each node do: |
| 28: get the set of neighboring nodes for node and count the frequen- cy of appearance of community labels for each neighboring node |
| 29: if the most frequently occurring neighboring community label is unique: |
| 30: the label of node is updated to the most frequently occurring community label. |
| 31: else: |
| 32: calculate the power score of each most frequent community using Equation (16) |
| 33: the label of node is updated to the community label with the highest community effectiveness score |
| 34:
end if |
| 35:
end for |
| 36: return , |
4.6. Time Complexity Analysis
For a complex network , assuming the average degree of nodes is , the number of nodes is , the number of edges is , and the common neighbors between two nodes is . The determination of particle starting positions involves calculating node degrees and the Salton similarity index between nodes, with a time complexity of . Active particles wandering in the network require calculating the probability for each particle to move from the current node to neighboring nodes. The random walk probability for each particle only requires computing node degrees, while the preferential walk probability needs to calculate the similarity index between the current node and its neighbors, with a time complexity of . When a particle’s energy is exhausted, the revival step involves maintaining a hash table to store each particle’s control nodes and their corresponding control capability values. Finding the node with the maximum control capability for jumping has a time complexity of . Updating the particle control matrix has a time complexity of . Since each node in the network is visited at least once by a particle, the total time complexity of particle wandering is . To determine the optimal number of particles, the algorithm needs to gradually change the particle count from 2 to , where is a constant slightly larger than the actual number of communities in the network. Therefore, the entire particle wandering process of the LNSSCL algorithm has a time complexity of . After the particle wandering process concludes, assigning community labels to all nodes based on their control capability values requires a time complexity of . The node membership selection step involves each node selecting its community label based on the frequency of community labels among its neighboring nodes, with a time complexity of . Since complex networks are usually sparse networks, . In summary, the time complexity of the LNSSCL algorithm is , where is a constant. The time complexity of the LNSSCL algorithm is linearly related to the sum of the number of nodes and edges in the network, making the algorithm highly scalable on large-scale networks.
6. Conclusions and Future Work
This paper introduces a novel unsupervised community detection algorithm named LNSSCL, which incorporates node local similarity into the process of stochastic competitive learning. Firstly, the algorithm determines the starting position of particles’ walks by calculating the degree value of nodes as well as the Salton similarity index. At the same time, the fusion of node similarity optimizes the particle preferential walk rule. During the particle wandering process, the particle control capacity increment is dynamically adjusted according to the control range of each particle. When a particle runs out of energy, the particle selects the node with the largest control power within its control range for resurrection. After the particle stops wandering, the nodes in the network are selected for affiliation based on the frequency of occurrence of community labels of neighboring nodes and the effectiveness score of neighboring communities, and the community detection results are finally obtained. Comparative experiments on real network datasets and synthetic networks show that the LNSSCL algorithm is effective in improving the SCL algorithm. Compared with other representative algorithms, the LNSSCL algorithm has better quality of community detection and is able to reveal a more reasonable community structure.
Nevertheless, the LNSSCL algorithm also has some defects. Compared with the SCL algorithm, the algorithm performs multiple node local similarity calculations during the community detection process, which requires more computational cost and complexity, and may have a larger time overhead on ultra-large networks. In the selection of some hyperparameters of the algorithm, no special parameter tuning method is used; the parameters are tuned manually. Further, the networks studied in this paper are simple undirected networks and not complex networks that are closer to the real world, such as directed, weighted, or attribute. In the next step of this study, we can consider optimizing the similarity calculation to further reduce the time overhead, adopting a dynamic adaptive hyper-parameter tuning strategy instead of traditional parameter tuning. GNN is introduced to fuse attribute information and structural features to obtain node representations and calculate node representation similarity to study the community detection strategy for attribute networks.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}