
Swin-YOLO for Concealed Object Detection in Millimeter Wave Images

Abstract
:1. Introduction
- More comprehensive contextual information is utilized through improved Swin Transformer. The Local Perception Swin Transformer Layers are added to the neck network of YOLOv5, which enhances the network’s ability to model feature context through the introduction of a window self-attention mechanism and Local Perception Module.
- The features of small targets are sufficiently extracted through more refined feature extraction and fusion networks. Additional feature fusion layers and prediction heads for small concealed objects are added to YOLOv5, enhancing the network’s detection performance for MMW targets. BiFPN is introduced to strengthen the network’s feature fusion ability.
- The key features of the concealed object are fully used. The lightweight Coordinate Attention Modules are added to the connection between the neck and detection heads of YOLOv5, which improves the extraction and utilization of critical features.
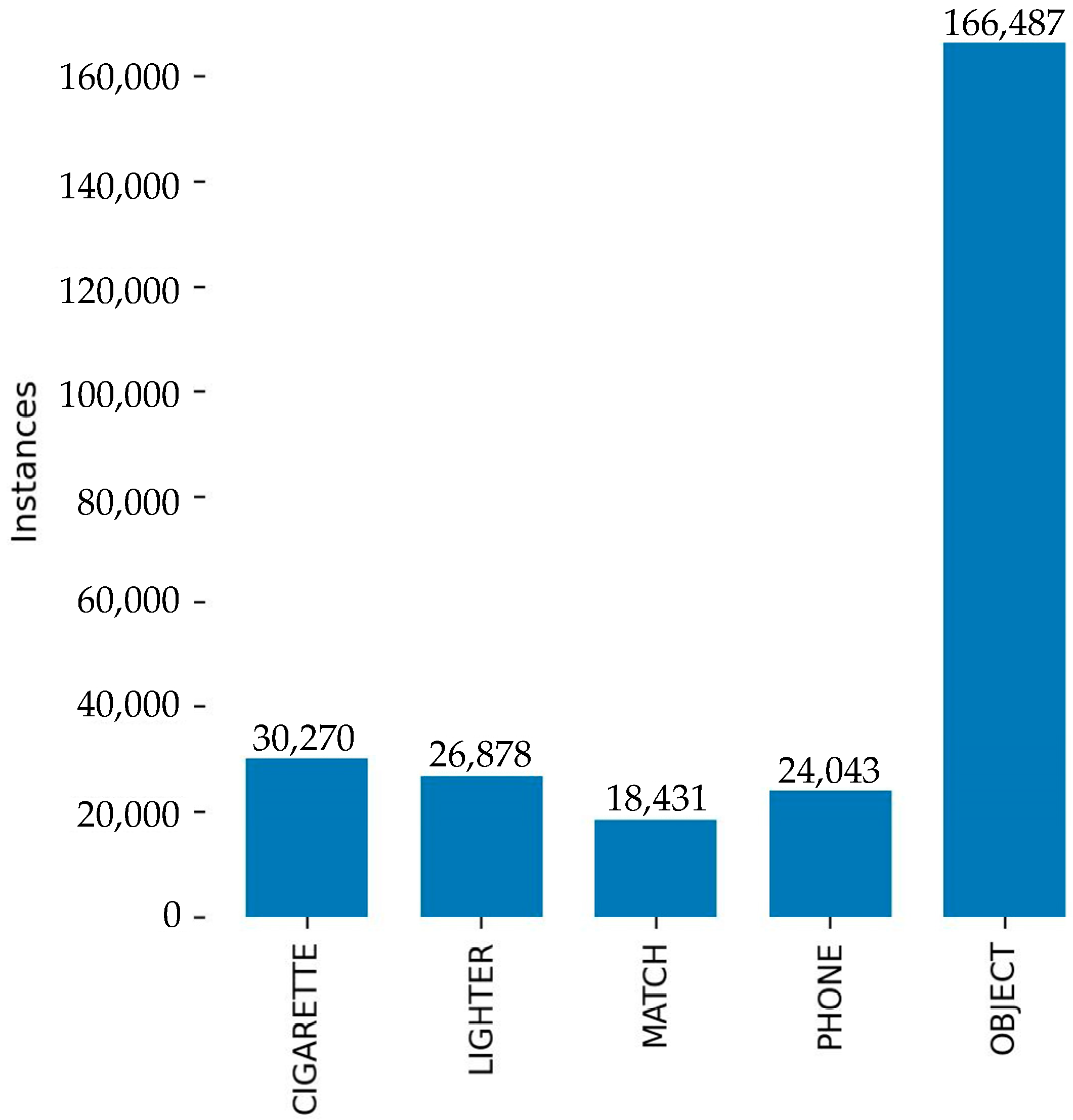
- We collected an MMW concealed object image dataset to support the training of different network models and test the detection performance of concealed objects. The dataset includes five classes of suspicious items and a total of 82,014 MMW images.
2. Related Work
2.1. Object Detection
2.2. The Attention Mechanism
2.3. Concealed Object Detection on Millimeter Wave Images
3. Theoretical Model
3.1. Overview of the YOLOv5 Method
3.2. The Proposed Object Detection Network
3.2.1. Feature Representation Layers and Prediction Head for Small Objects
3.2.2. Coordinate Attention Module
3.2.3. Local Perception Swin Transformer (LPST) Layer
3.2.4. Improvement of Multi-Scale Feature Fusion Network
4. Experiments
4.1. Dataset and Evaluation Metrics
4.2. Implementation Details
4.3. Experimental Results
4.4. Ablation Experiments
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gao, J.; Qin, Y.; Deng, B.; Wang, H.; Li, X. A novel method for 3-D millimeter-wave holographic reconstruction based on frequency interferometry techniques. IEEE Trans. Microw. Theory Tech. 2017, 66, 1579–1596. [Google Scholar] [CrossRef]
- Haraz, O.M.; Ashraf, M.A.; Sebak, A.R.; Alshebeili, S.A. Detection of metallic and nonmetallic concealed targets based on millimeter-wave inverse scattering approach. Int. J. RF Microw. Comput.-Aided Eng. 2020, 30, e22290. [Google Scholar] [CrossRef]
- Yeom, S.; Lee, D.S.; Son, J.Y.; Kim, S.H. Concealed object detection using passive millimeter wave imaging. In Proceedings of the IEEE 2010 4th International Universal Communication Symposium, Beijing, China, 18–19 October 2010; pp. 383–386. [Google Scholar]
- Lee, D.S.; Yeom, S.; Son, J.Y.; Kim, S.H. Automatic image segmentation for concealed object detection using the expectation-maximization algorithm. Opt. Express 2010, 18, 10659–10667. [Google Scholar] [CrossRef] [PubMed]
- Pang, L.; Liu, H.; Chen, Y.; Miao, J. Real-time concealed object detection from passive millimeter wave images based on the YOLOv3 algorithm. Sensors 2020, 20, 1678. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, C.; Liu, X.; Wang, L.; Dai, C.; Cui, J.; Li, Y.; Kinar, N. The Development of Frequency Multipliers for Terahertz Remote Sensing System. Remote Sens. 2022, 14, 2486. [Google Scholar] [CrossRef]
- Yeom, S.; Lee, D.S. Multi-level segmentation for concealed object detection with multi-channel passive millimeter wave imaging. In Proceedings of the 2013 International Conference on IT Convergence and Security (ICITCS), Macau, China, 16–18 December 2013; pp. 1–4. [Google Scholar]
- Yang, X.; Wei, Z.; Wang, N.; Song, B.; Gao, X. A novel deformable body partition model for MMW suspicious object detection and dynamic tracking. Signal Process. 2020, 174, 107627. [Google Scholar] [CrossRef]
- Meng, Z.; Zhang, M.; Wang, H. CNN with pose segmentation for suspicious object detection in MMW security images. Sensors 2020, 20, 4974. [Google Scholar] [CrossRef] [PubMed]
- He, W.; Zhang, B.; Wang, B.; Sun, X.; Yang, M.; Wu, X. Concealed Object Detection in Millimeter Wave Image Based on Global Correlation of Multi-level Features in Cross-section Sequence. J. Infrared Millim. Waves 2021, 40, 738–748. [Google Scholar]
- Zhang, K.S. Detection of Contraband Based on Millimeter Wave Image. Master’s Thesis, Hangzhou Dianzi University, Hangzhou, China, May 2022. [Google Scholar]
- Ultralytics. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 9 June 2020).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Berlin, Germany, 11–14 March 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2022; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017; pp. 6517–6525. [Google Scholar]
- Joseph, R.; Ali, F. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Ultralytics. Yolov8. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 2204–2212. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2021. [Google Scholar]
- Shen, X.; Dietlein, C.R.; Grossman, E.; Popovic, Z.; Meyer, F.G. Detection and segmentation of concealed objects in terahertz images. IEEE Trans. Image Process. 2008, 17, 2465–2475. [Google Scholar] [CrossRef] [PubMed]
- Yeom, S.; Lee, D.S.; Chang, Y.S.; Lee, M.K.; Jung, S.W. Concealed object recognition based on geometric feature descriptors. Passiv. Act. Millim.-Wave Imaging XV 2012, 8362, 135–140. [Google Scholar]
- Lee, D.S.; Yeom, S.; Chang, Y.S.; Lee, M.K.; Sang-Won Jung, S.W. Real-time computational processing and implementation for concealed object detection. Opt. Eng. 2012, 51, 071405. [Google Scholar] [CrossRef]
- Liu, T.; Zhao, Y.; Wei, Y.; Zhao, Y.; Wei, S. Concealed object detection for activate millimeter wave image. IEEE Trans. Ind. Electron. 2019, 66, 9909–9917. [Google Scholar] [CrossRef]
- Li, X.; Yang, K.; Fan, X.; Hu, L.; Li, J. Fast and accurate concealed dangerous object detection. J. Electron. Imaging 2022, 31, 023021. [Google Scholar]
- Zhang, B.; Wang, B.; Wu, X.; Zhang, L.; Yang, M.; Sun, X. Domain adaptive detection system for concealed objects using millimeter wave images. Neural Comput. Appl. 2021, 33, 11573–11588. [Google Scholar] [CrossRef]
- Yuan, M.; Zhang, Q.; Li, Y.; Yan, Y.; Zhu, Y. A Suspicious Multi-Object Detection and Recognition Method for Millimeter Wave SAR Security Inspection Images Based on Multi-Path Extraction Network. Remote Sens. 2021, 13, 4978. [Google Scholar]
- Wang, C.; Shi, J.; Zhou, Z.; Li, L.; Zhou, Y.; Yang, X. Concealed object detection for millimeter-wave images with normalized accumulation map. IEEE Sens. J. 2021, 21, 6468–6475. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. Cspnet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Sun, Z.; Li, P.; Meng, Q.; Sun, Y.; Bi, Y. An Improved YOLOv5 Method to Detect Tailings Ponds from High-Resolution Remote Sensing Images. Remote Sensing 2023, 15, 1796. [Google Scholar] [CrossRef]
- Bao, W.; Du, X.; Wang, N.; Yuan, M.; Yang, X. A Defect Detection Method Based on BC-YOLO for Transmission Line Components in UAV Remote Sensing Images. Remote Sensing 2022, 14, 5176. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-iouloss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone- captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 19–25 June 2021; pp. 2778–2788. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Model/Method | AP (%) | Inference Time (FPS) |
|---|---|---|---|
| Shen et al. [34] | Denoised Image Histogram + Internal Temperature Distribution + Isocontours | / | / |
| Yeom et al. [35] | Preprocessing + PCA + Size Normalization | / | / |
| Lee et al. [36] | EM | / | / |
| Liu et al. [37] | ZF-Net + High-Resolution Features + Context Embedded Module | 84.65 | / |
| Yang et al. [8] | Darknet-53 + Deformable Body Partition Model | 80.1 | 25 |
| Meng et al. [9] | Convolution Pose Machine | / | / |
| Li et al. [38] | ResNet50 + FPN | 82 | / |
| Zhang et al. [39] | SSD + Bottom-Up Manner + Top-Down Manner + K-means | 88.26 | 15 |
| Yuan et al. [40] | Residual Block + MPFP | 82.39 | 24.2 |
| Wang et al. [41] | YOLOv2 + NAM | 69.67 | / |
| Dataset | 0~32 × 32 Pixels | 32 × 32~64 × 64 Pixels | >64 × 64 Pixels |
|---|---|---|---|
| MMW Dataset | 66% | 33% | 1% |
| Method | P | R | mAP |
|---|---|---|---|
| YOLOv5 | 88.7 | 82 | 87.3 |
| YOLOv8 | 91.5 | 82.3 | 88.4 |
| Faster-RCNN | 90.4 | 83.8 | 89.1 |
| TPH-YOLOv5 | 90.6 | 86.1 | 90.7 |
| STPH-YOLOv5 | 90.3 | 85.8 | 90.5 |
| Swin-YOLO | 91.8 | 87.3 | 92.0 |
| Method | Model Size (MB) | Inference Time (Per Picture) |
|---|---|---|
| YOLOv5 | 92.8 | 10.6 ms |
| TPH-YOLOv5 | 121.8 | 20.6 ms |
| Swin-YOLO | 110.5 | 16.7 ms |
| Method | P | R | mAP |
|---|---|---|---|
| YOLOv5 | 88.7 | 82 | 87.3 |
| YOLOv5 + P2 | 91.3 | 82.5 | 88 |
| YOLOv5 + P2 + CA | 89.5 | 84.5 | 89.7 |
| YOLOv5 + P2 + LPST | 90.9 | 85.9 | 90.8 |
| YOLOv5 + P2 + CA + Swin Transformer | 91.7 | 85.6 | 91.2 |
| YOLOv5 + P2 + CA + LPST | 91.4 | 87.1 | 91.8 |
| Swin-YOLO | 91.8 | 87.3 | 92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, P.; Wei, R.; Su, Y.; Tan, W. Swin-YOLO for Concealed Object Detection in Millimeter Wave Images. Appl. Sci. 2023, 13, 9793. https://doi.org/10.3390/app13179793
Huang P, Wei R, Su Y, Tan W. Swin-YOLO for Concealed Object Detection in Millimeter Wave Images. Applied Sciences. 2023; 13(17):9793. https://doi.org/10.3390/app13179793
Chicago/Turabian StyleHuang, Pingping, Ran Wei, Yun Su, and Weixian Tan. 2023. "Swin-YOLO for Concealed Object Detection in Millimeter Wave Images" Applied Sciences 13, no. 17: 9793. https://doi.org/10.3390/app13179793