
Improving Abstractive Dialogue Summarization Using Keyword Extraction

Abstract
:1. Introduction
- We propose a novel keyword-aware abstractive summarization system that efficiently leverages the key information in a dialogue.
- We demonstrate that our proposed keyword-aware method outperforms baseline methods in three benchmark datasets.
- We explore the usage of various keyword extractors for dialogue summarization tasks to find the best usage.
- We demonstrate the effectiveness of the proposed keyword-aware method in low-resource conditions.
2. Related Works
2.1. Dialogue Summarization
2.2. Keyword-Aware Summarization
2.3. Keyword Extractor
2.3.1. KeyBERT
2.3.2. RaKUn
2.3.3. RAKE
2.3.4. YAKE
2.3.5. PKE
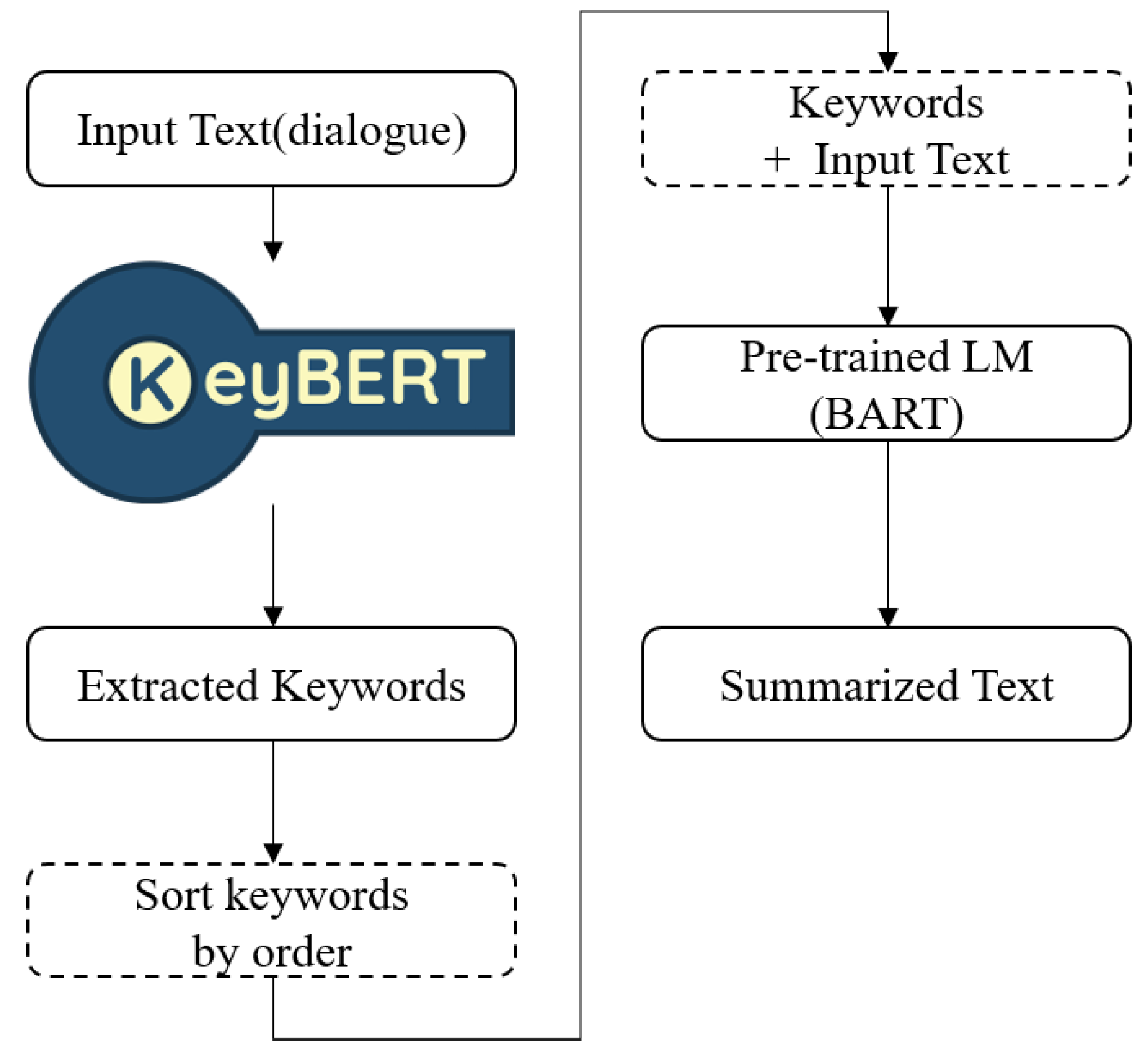
3. Method
3.1. Problem Formulation
| Algorithm 1: Flow of keyword aggregation algorithm |
 |
3.2. Pre-Trained Language Models
3.3. Keyword-Aware Summarizer
| Algorithm 2: Flow of keyword order algorithm |
 |
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Performance Comparison
4.4. Ablations
4.4.1. Keyword Extractor
4.4.2. Keyword Selection Strategy
4.4.3. Keyword Order
4.5. Analysis
4.5.1. Experiments on Other Dataset
4.5.2. Computation Cost
4.5.3. Keyword Verification on KADS
4.5.4. Low-Resource Conditions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| KADS | Keyword-Aware Dialogue Summarization system |
| BERT | Bidirectional Encoder Representations from Transformer |
| LM | Language Model |
| RaKUn | Rank-based Keyword extraction via Unsupervised learning and meta vertex aggregation |
| RAKE | Rapid Automatic Keyword Extraction |
| PKE | Python-based Keyphrase Extraction |
| BART | Bidirectional Auto-Regressive Transformers |
| T5 | Text-To-Text Transfer Transformer |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
References
- Pratama, H.; Azman, M.N.A.; Kassymova, G.K.; Duisenbayeva, S.S. The Trend in using online meeting applications for learning during the period of pandemic COVID-19: A literature review. J. Innov. Educ. Cult. Res. 2020, 1, 58–68. [Google Scholar] [CrossRef]
- Zhong, M.; Liu, Y.; Xu, Y.; Zhu, C.; Zeng, M. Dialoglm: Pre-trained model for long dialogue understanding and summarization. arXiv 2021, arXiv:2109.02492. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. Dialogpt: Large-scale generative pre-training for conversational response generation. arXiv 2019, arXiv:1911.00536. [Google Scholar]
- Nallapati, R.; Zhou, B.; dos Santos, C.; Gulçehre, Ç.; Xiang, B. Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 280–290. [Google Scholar] [CrossRef]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 1797–1807. [Google Scholar] [CrossRef]
- Lee, S.; Yang, K.; Park, C.; Sedoc, J.; Lim, H. Who speaks like a style of Vitamin: Towards Syntax-Aware DialogueSummarization using Multi-task Learning. IEEE Access 2021, 9, 168889–168898. [Google Scholar] [CrossRef]
- Gliwa, B.; Mochol, I.; Biesek, M.; Wawer, A. SAMSum corpus: A human-annotated dialogue dataset for abstractive summarization. arXiv 2019, arXiv:1911.12237. [Google Scholar]
- Chen, Y.; Liu, Y.; Chen, L.; Zhang, Y. DialogSumm: A Real-Life Scenario Dialogue Summarization Dataset. arXiv 2021, arXiv:arXiv:2105.06762. [Google Scholar]
- Lee, D.; Lim, J.; Whang, T.; Lee, C.; Cho, S.; Park, M.; Lim, H.S. Capturing Speaker Incorrectness: Speaker-Focused Post-Correction for Abstractive Dialogue Summarization. In Proceedings of the Third Workshop on New Frontiers in Summarization, Online, 10 November 2021; pp. 65–73. [Google Scholar]
- Grootendorst, M. KeyBERT: Minimal Keyword Extraction with BERT. Available online: https://maartengr.github.io/KeyBERT/ (accessed on 28 August 2023).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Moratanch, N.; Chitrakala, S. A survey on abstractive text summarization. In Proceedings of the 2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 18–19 March 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Fu, X.; Zhang, Y.; Wang, T.; Liu, X.; Sun, C.; Yang, Z. RepSum: Unsupervised Dialogue Summarization based on Replacement Strategy. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 6042–6051. [Google Scholar] [CrossRef]
- Liu, J.; Hughes, D.J.D.; Yang, Y. Unsupervised Extractive Text Summarization with Distance-Augmented Sentence Graphs. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2313–2317. [Google Scholar]
- Collins, E.; Augenstein, I.; Riedel, S. A Supervised Approach to Extractive Summarisation of Scientific Papers. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, BC, Canada, 3–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 195–205. [Google Scholar] [CrossRef]
- He, R.; Zhao, L.; Liu, H. TWEETSUM: Event oriented Social Summarization Dataset. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 5731–5736. [Google Scholar] [CrossRef]
- Feng, X.; Feng, X.; Qin, B. Incorporating commonsense knowledge into abstractive dialogue summarization via heterogeneous graph networks. In China National Conference on Chinese Computational Linguistics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 127–142. [Google Scholar]
- Qu, C.; Lu, L.; Wang, A.; Yang, W.; Chen, Y. Novel multi-domain attention for abstractive summarisation. CAAI Trans. Intell. Technol. 2022. [Google Scholar] [CrossRef]
- Zhao, L.; Yang, Z.; Xu, W.; Gao, S.; Guo, J. Improving Abstractive Dialogue Summarization with Conversational Structure and Factual Knowledge. Available online: https://openreview.net/forum?id=uFk038O5wZ (accessed on 28 August 2023).
- Li, H.; Zhu, J.; Zhang, J.; Zong, C.; He, X. Keywords-guided abstractive sentence summarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8196–8203. [Google Scholar]
- Zhong, N.; Liu, J.; Yao, Y. Web Intelligence; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Bharti, S.K.; Babu, K.S. Automatic keyword extraction for text summarization: A survey. arXiv 2017, arXiv:1704.03242. [Google Scholar]
- Li, C.; Xu, W.; Li, S.; Gao, S. Guiding generation for abstractive text summarization based on key information guide network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 2, (Short Papers). pp. 55–60. [Google Scholar]
- Liu, Y.; Jia, Q.; Zhu, K. Keyword-Aware Abstractive Summarization by Extracting Set-Level Intermediate Summaries. In Proceedings of the Web Conference 2021, Virtual Event, 12–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021. WWW ’21. pp. 3042–3054. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; (Long and Short Papers) Association for Computational Linguistics. Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Skrlj, B.; Repar, A.; Pollak, S. RaKUn: Rank-based Keyword extraction via Unsupervised learning and Meta vertex aggregation. In Statistical Language and Speech Processing: 7th International Conference, SLSP 2019, Ljubljana, Slovenia, 14–16 October 2019; Proceedings 7; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 311–323. [Google Scholar]
- Martinc, M.; Škrlj, B.; Pollak, S. TNT-KID: Transformer-based neural tagger for keyword identification. Nat. Lang. Eng. 2022, 28, 409–448. [Google Scholar] [CrossRef]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic keyword extraction from individual documents. Text Min. Appl. Theory 2010, 1, 1–20. [Google Scholar]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.; Nunes, C.; Jatowt, A. YAKE! Keyword extraction from single documents using multiple local features. Inf. Sci. 2020, 509, 257–289. [Google Scholar] [CrossRef]
- Yujian, L.; Bo, L. A normalized Levenshtein distance metric. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1091–1095. [Google Scholar] [CrossRef] [PubMed]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. 1990. Available online: https://eric.ed.gov/?id=ED325505 (accessed on 28 August 2023).
- Boudin, F. pke: An open source python-based keyphrase extraction toolkit. In Proceedings of the COLING, Osaka, Japan, 11–16 December 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Feng, X.; Feng, X.; Qin, B. A Survey on Dialogue Summarization: Recent Advances and New Frontiers. arXiv 2021, arXiv:2107.03175. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Werner, T. A Linear Programming Approach to Max-Sum Problem: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1165–1179. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Sanner, S. Probabilistic latent maximal marginal relevance. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; pp. 833–834. [Google Scholar]
- Bennani-Smires, K.; Musat, C.; Hossmann, A.; Baeriswyl, M.; Jaggi, M. Simple Unsupervised Keyphrase Extraction using Sentence Embeddings. In Proceedings of the 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 31 October–1 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 221–229. [Google Scholar] [CrossRef]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Kan, M.Y.; McKeown, K. Information Extraction and Summarization: Domain Independence through Focus Types. 1999. Available online: http://www.cs.columbia.edu/nlp/papers/1999/kan_mckeown_99.pdf (accessed on 28 August 2023).
- Baker, S.G. The summary test tradeoff: A new measure of the value of an additional risk prediction marker. Stat. Med. 2017, 36, 4491. [Google Scholar] [CrossRef] [PubMed]
- Carnegie, N.B.; Wu, J. Variable Selection and Parameter Tuning for BART Modeling in the Fragile Families Challenge. Socius 2019, 5, 2378023119825886. [Google Scholar] [CrossRef]
- Zou, Y.; Zhu, B.; Hu, X.; Gui, T.; Zhang, Q. Low-Resource Dialogue Summarization with Domain-Agnostic Multi-Source Pretraining. arXiv 2021, arXiv:2109.04080. [Google Scholar]



{kind=link}
{kind=link}
| Dialogue |
|---|
| Person1: What makes you think you are able to do the job? |
| Person2: My major is Automobile Designing and I have received |
| my master’s degree in science. I think I can do it well. |
| Person1: What kind of work were you responsible for the past employment? |
| Person2: I am a student engineer who mainly took charge of understanding |
| the corrosion resistance of various materials. |
| Summary |
| Person1 is interviewing Person2 about Person2’s ability and previous experience. |
| Summary Without Keyword (Baseline) |
| Person1 interviews Person2. |
| Summary With Keyword (KADS) |
| Person1 asks Person2’s major, the past work, and the reason to do the job. |
| Datasets | Style | Scenario | Dialogues | # of Examples |
|---|---|---|---|---|
| DialogSum | spoken | daily life | 13,460 | 1.8 M |
| SAMSum | written | online | 16,369 | 1.5 M |
| TweetSumm | written | online | 1100 | 1.8 M |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Baseline | |||
| BART-base | 44.8874 | 19.6440 | 37.0678 |
| BART-large | 46.1996 | 21.0814 | 38.8086 |
| T5-base | 41.5242 | 16.4631 | 33.6254 |
| T5-large | 42.1325 | 17.3326 | 34.4822 |
| KADS | |||
| BART-base | 45.9874 | 20.9440 | 38.1678 |
| BART-large | 47.2237 | 22.1353 | 39.8665 |
| T5-base | 44.2605 | 18.8368 | 36.2043 |
| T5-large | 45.2232 | 18.9618 | 37.7235 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| KADS | |||
| KeyBERT | 47.2237 | 22.1353 | 39.8665 |
| RAKUN | 45.8668 | 20.9832 | 38.3474 |
| RAKE | 46.2899 | 21.0008 | 38.9808 |
| YAKE | 46.2077 | 20.9943 | 38.5658 |
| PKE | 45.8123 | 20.7648 | 38.3878 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| KADS | |||
| KeyBERT-MaxSum | 47.2237 | 22.1353 | 39.8665 |
| KeyBERT-MMR | 46.6064 | 21.4615 | 38.9653 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L | BERTScore |
|---|---|---|---|---|
| KADS | ||||
| Appearance | 47.2237 | 22.1353 | 39.8665 | 0.9192 |
| Accuracy | 46.8676 | 21.9106 | 39.1413 | 0.9190 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| SAMSum | |||
| Baseline | 51.9170 | 27.6903 | 43.3052 |
| KADS | 52.0063 | 27.9083 | 43.4162 |
| TweetSumm | |||
| Baseline | 42.2314 | 19.2241 | 35.5624 |
| KADS | 42.3342 | 19.3244 | 35.7624 |
| Model | Total Time | Step per Second |
|---|---|---|
| Baseline | 1574.0059 | 2.4750 |
| KADS | 2556.2950 | 3.0470 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Baseline | 46.1996 | 21.0814 | 38.8086 |
| Random | 44.3636 | 20.0146 | 37.1262 |
| KADS | 47.2237 | 22.1353 | 39.8665 |
| Dialogue |
|---|
| Person1: What makes you think you are able to do the job? |
| Person2: My major is Automobile Designing and I have received |
| my master’s degree in science. I think I can do it well. |
| Person1: What kind of work were you responsible for the past employment? |
| Person2: I am a student engineer who mainly took charge of understanding |
| the corrosion resistance of various materials. |
| Reference Summary |
| Person1 is interviewing Person2 about Person2’s |
| ability and previous experience. |
| Baseline |
| Person1 interviews Person2. |
| KADS |
| Person1 asks Person2’s major, the past work, and |
| the reason to do the job. |
| Random keyword |
| Person2 says I am a student engineer who mainly |
| took charge of understanding of the mechanical |
| strength and corrosion resistance of various materials. |
| I think I can do it well. |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Baseline | |||
| 100% | 46.1996 | 21.0814 | 38.8086 |
| 75% | 44.8136 | 20.6273 | 38.0324 |
| 50% | 44.0717 | 20.1916 | 36.6705 |
| 25% | 43.8293 | 20.0013 | 36.0213 |
| 10% | 41.2341 | 18.7535 | 34.3425 |
| KADS | |||
| 100% | 47.2237 (+1.0241) | 22.1353 (+1.0539) | 39.8665 (+1.0579) |
| 75% | 46.2476 (+1.4340) | 21.2876 (+0.6603) | 39.2494 (+1.2170) |
| 50% | 45.2720 (+1.2003) | 20.5406 (+0.3490) | 38.1776 (+1.5071) |
| 25% | 45.9331 (+2.1038) | 20.9613 (+0.9600) | 37.7504 (+1.7291) |
| 10% | 43.2545 (+2.0204) | 19.6724 (+0.9189) | 36.0252 (+1.6827) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, C.; Lee, H. Improving Abstractive Dialogue Summarization Using Keyword Extraction. Appl. Sci. 2023, 13, 9771. https://doi.org/10.3390/app13179771
Yoo C, Lee H. Improving Abstractive Dialogue Summarization Using Keyword Extraction. Applied Sciences. 2023; 13(17):9771. https://doi.org/10.3390/app13179771
Chicago/Turabian StyleYoo, Chongjae, and Hwanhee Lee. 2023. "Improving Abstractive Dialogue Summarization Using Keyword Extraction" Applied Sciences 13, no. 17: 9771. https://doi.org/10.3390/app13179771