1. Introduction
Supervised machine learning is an extensively studied and applied topic in the artificial intelligence field [
1,
2,
3]. This learning paradigm is a powerful tool for data classification using machine language. However, supervised learning requires the availability of accurately labeled datasets to infer learning models [
4]. Despite the learning capability of the state-of-the-art supervised machine learning algorithms, the continuously growing size of the datasets used to train the models has made the labeling an even more costly process in terms of time and effort. In contrast, when only a relatively small dataset is available, it typically becomes prone to overfitting the training set. This disadvantage of supervised learning has promoted research on unsupervised machine learning which does not require labeled data for the training stage. In fact, unsupervised machine learning can cope better with a huge amount of unlabeled data as it eliminates the requirement of carefully annotating the training sets. Clustering is an unsupervised learning technique that is meant to draw conclusions and discover the hidden patterns in unlabeled datasets.
Clustering has been adapted to address various problems in many areas, such as data mining, pattern recognition, and computer vision [
5]. In many fields, there are obvious benefits to be acquired from grouping instances that share similar properties into different clusters in an unsupervised manner [
6]. Clustering algorithms have been extensively studied, as a descriptive data mining tool, from various aspects including similarity measures, feature selection, and grouping methods [
7]. Among the well-known and widely used clustering algorithms, one can cite k-means [
8], hierarchical clustering [
9], and Density-Based Spatial Clustering of Applications with Noise (DBSCAN) [
10]. The main concept of DBSCAN is that for a data object to belong to a cluster, the density in a neighborhood for that data object should be high enough, satisfying a user-specified density threshold [
11]. This threshold is represented by two hyper-parameters; the radius of the neighborhood (eps) and the minimum number of points required to from the neighborhood (MinPts). Despite DBSCAN algorithm’s robustness to outliers and capability of handling irregularly shaped clusters, it deteriorates when dealing with high dimensional data and is sensitive to the input parameters [
12].
The typical goal of clustering is to group sets of data objects together in a way that instances assigned to the same cluster are more similar to each other compared to those belonging to other clusters. In fact, grouping similar data entities together is intended to discover the data partition and provide insights on the patterns underlying the different categories. Commonly, for a clustering algorithm to achieve the data mining goal, it should be preceded by a feature extraction stage that is intended to encode and extract the data properties that can better discriminate between the hidden clusters. However, this feature extraction phase may yield a highly dimensional data representation and a curse of dimensionality problem [
13].
To meet the curse of dimensionality challenges, several dimensionality reduction methods [
14,
15] have been introduced to transform the data from the original feature space into a new feature space with fewer dimensions. However, despite these contributions, the data that exhibit a highly complex latent structure remain challenging to cluster using the existing clustering methods [
5].
The emergence and rapid development of deep neural networks (DNNs) has triggered revisiting the clustering-related research. The rationale was to exploit the deep neural networks’ ability to automatically determine the most relevant features and relax the need for feature handcrafting and engineering [
5,
16]. Moreover, the researchers’ interest in deep clustering paradigms was intended to address challenges such as the inability to handle datasets that lie on nonlinear manifolds, the curse of dimensionality, and the sensitivity to noise [
17,
18]. Basically, the earliest deep clustering works [
19,
20] focused on feature transformation and clustering as two independent processes. In other words, the data were first mapped into a new feature space and then fed into a clustering algorithm. Recently, deep clustering has been adapted to jointly perform feature learning, transformation, and the clustering of data that exhibit a highly complex latent structure [
5]. The fundamental component of deep clustering approaches relies on deep neural network architectures such as autoencoders [
21], the network loss, and the clustering loss optimization [
7].
Deep clustering potentials were mainly explored in the context of entirely unsupervised learning. However, the datasets are naturally weak or poorly labeled in the real world [
22]. This boosted the researchers’ efforts to exploit this knowledge to inject some supervision to guide the clustering process, i.e., introduce the semi-supervised learning paradigm. Semi-supervised learning uses both labeled and unlabeled data to train a model. Moreover, semi-supervised learning exploits prior knowledge and formulates it as constraints to ease the learning process. Despite researchers’ efforts, the state-of-the-art, semi-supervised, deep clustering approaches remain far below expectations compared to the fully unsupervised approaches. In particular, the use of fuzzy logic was not investigated to represent the data partition in the context of semi-supervised deep learning. Moreover, the existing semi-supervised clustering methods only proposed the integration of the supervision information as crisp pairwise constraints rather than soft ones.
In this research, we propose a novel semi-supervised deep clustering approach, named Soft Constrained Deep Clustering (SC-DEC), to overcome the limitations in current approaches. The proposed approach leverages a deep neural network architecture for feature learning and performs clustering with fuzzy membership degrees to better represent the true partition of the data. Specifically, we formulated the deep clustering problem as an optimization of a novel objective function. This function is designed to simultaneously discover the hidden data clusters and optimize the deep neural network. Moreover, soft pairwise constraints were incorporated within the objective function to represent the available supervision knowledge. These constraints were formulated in a relaxing way in which the compliance to a constraint is not strictly obligated, which makes the proposed approach more suitable for real-world data clustering applications where the available side information is not mature enough to be strictly imposed. Additionally, the fuzzy-based representation of data partition was adopted in the proposed method to reflect the grouping of data in a more accurate way.
The main contributions of this research can be summarized as follows: (i) We formulated the proposed semi-supervised deep clustering approach as an optimization problem and designed the objective functions that carry the proposed tasks to simultaneously learn a discriminative embedded representation of the original data along with the optimal data clusters. (ii) We solved the formulated optimization problem and derived updated equations of the respective parameters. (iii) We designed and implemented a novel deep semi-supervised clustering algorithm using state-of-the-art technology, platforms, and tools. (iv) We evaluated the performance of the proposed approach using real datasets and standard performance measures in addition to an objective comparison with relevant state-of-the-art approaches.
The rest of this paper is organized as follows:
Section 2 presents the related works while
Section 3 introduces the proposed method. The experimental settings as well as the analysis and discussion of the results are presented in
Section 4. Finally, the conclusion and future work are discussed in
Section 5.
2. Related Works
Research work on deep clustering includes deep embedded clustering and semi-supervised deep embedded clustering (SS-DEC) approaches. For deep embedded clustering, Deep Neural Networks (DNNs) have been used for dimensionality reduction to learn a clustering-oriented representation that favors the clustering tasks. In fact, different deep clustering frameworks were created on top of various DNN architectures. Namely, autoencoders (AEs), Deep Belief Networks (DBNs) [
23], Convolutional Neural Networks (CNNs) [
24,
25], and Generative Adversarial Networks (GANs) [
26] have been introduced and used in various deep clustering applications. In particular, autoencoders have been widely adapted to address challenges relevant to the deep clustering architectures [
21,
27,
28,
29]. A recent survey [
30] distinguishes deep clustering methods in terms of methodology, prior knowledge, and architecture. Specifically, the authors listed semi-supervised deep clustering as one of the main four categories of deep clustering methods.
For AE-based deep clustering approaches, the encoder layers of the trained autoencoder are the ones leveraged for feature transformation into a lower-dimensional space, which serves as the input for the clustering algorithm. Recently, an AE-based deep clustering architecture, deep embedded clustering (DEC) [
21], was proposed, which was then followed by a number of variants [
19,
27,
28,
29,
31,
32,
33,
34,
35,
36] that used DEC as the basis for their framework. From then, deep clustering has become a growing research field, with DEC [
21] being the experimental benchmark for many deep clustering approaches [
29,
34].
For DEC [
21], the DNN architecture consists mainly of an autoencoder that is used to automatically learn the feature representations via nonlinear embedding into a lower-dimensional feature space. After the autoencoder is trained and its parameters are initialized, it is finetuned further to minimize the reconstruction loss. Only the encoder layers are kept and used as the initial mapping function between the data space and the embedded feature space. To initialize the cluster centers, the original data are passed through the initialized encoder to obtain the embedded data points and perform standard k-means clustering in the embedded feature space to obtain
k initial centroids and memberships. After that, DEC updates its parameters by iterating between computing an auxiliary target distribution and minimizing the following objective function in form of the Kullback–Leibler (KL) divergence from the computed soft assignments to the computed auxiliary target distribution:
where
Q is the soft assignments of the data points and
P is the computed auxiliary distribution.
In the above equation, is a centroid-based probability distribution (i.e., soft assignment) that represents the probability of assigning sample i to cluster j, and it is computed using the Student’s t-distribution. Moreover, in Equation (1) is the auxiliary target distribution that is matched to by minimizing a KL divergence metric between the two distributions. Further elaboration on the computation of and can be found in Equations (3) and (4) below.
This objective function in Equation (1) is minimized using a Stochastic Gradient Descent (SGD) to learn cluster centers and DNN parameters from the embedded space Z. Lastly, a cluster assignment hardening loss is applied to obtain the soft assignment probabilities of the embedded points. DEC reported an 84.3% clustering accuracy on the MNIST images dataset and 75.63% on the REUTERS text dataset, outperforming several state-of-the-art spectral clustering-based algorithms.
Motivated by the need to address certain limitations, other deep clustering works were proposed to incorporate improvements to the DEC [
21] framework. Specifically, the IDEC model [
37] extended DEC by preserving the local structure of data in the feature space through keeping the decoder layers to avoid feature space distortion by the clustering loss. Another model introduced in [
27] extended IDEC by adopting a convolutional autoencoder (CAE) as the deep network. Later, several deep clustering works based on (CAE) were suggested [
32]. Data augmentation was also associated with DEC in [
28] to improve the model’s generalization by making the DNN learn more representative features. Moreover, a k-means based DEC framework was presented in [
19]. In particular, a cost function that consists of dimensionality reduction, data reconstruction, and a k-means clustering structure promoting regularization loss terms was introduced. Another related DEC-based work [
33] leverages symmetry-based distances within the DEC framework as a powerful tool to distinguish symmetric shapes.
The authors in [
38] observed the fact that DEC [
21] does not make use of prior knowledge to guide the learning process. They extended DEC [
21] and proposed a new scheme of Semi-Supervised Deep Embedded Clustering (SDEC) to overcome this limitation. SDEC’s best performance was reported as an 86.11% clustering accuracy and 82.89% NMI on the MNIST image dataset. Since then, Semi-Supervised Deep Embedded Clustering (SS-DEC) became a growing field. Actually, most of the SS-DEC literature addresses general clustering purposes [
39,
40,
41,
42]. On the other hand, some works targeted anomaly detection [
43], software fault proneness classification (fault prediction) [
44], image classification and segmentation [
45], and deep generative purposes [
46,
47]. The supervision injected in SS-DEC models takes several forms. The researchers in [
41] imposed standard must-link and cannot-link pairwise constraints to their model, while the authors in [
31] extended the encoding of standard pairwise constraints to more complex constraints such as continuous values (triplet constraints), instance difficulty constraints, and cluster-level balancing constraints. Triplet constraints are useful in the cases where no strong pairwise guidance is available. As for the instance difficulty constraints, it allows the user to a priori specify which instances are easier to cluster (i.e., they belong strongly to only one cluster), whereas the cluster-level balancing constraints enable the experts to guide the clustering process via the prior cardinality information. Another approach, Ts2DEC, outlined in [
48], used triplet constraints.
In [
49], the pairwise constraints are self-generating from a mutual KNN graph which makes the clustering approach unsupervised. The method then extends it to semi-supervised clustering by including human intervention to finetune these self-generating constraints by analyzing the losses associated with the pairs to form a set of false positive candidates. ClusterNet [
50] also uses pairwise semantic constraints from very few labeled data samples (<5% of total data) and exploits the abundant unlabeled data to drive the clustering. The network is optimized by minimizing a combination of k-means-based clustering loss and pairwise KL-divergence loss where the two are regularized via an autoencoder’s reconstruction loss and each are defined for both the labeled as well as unlabeled data. A different approach to include supervision information was outlined in [
47] where a small, labeled dataset is used to assign classes to components of Gaussian mixtures. The resulting mixture describes the distribution of the whole data.
The authors in [
39] extended deep embedded clustering approaches to Electronic Health Record (I) patient cohorts. Specifically, supervision was applied by modifying the latent representation according to known patient subgroups through applying transfer learning of the encoder and fine-tuning of layers.
One should note that most DEC-based works [
38,
39,
45,
48] use k-means clustering algorithms to initialize the cluster centers, followed by cluster assignment hardening in the form of clustering loss. However, the authors in [
40] used a graph-based clustering method, while in [
49], the mutual
k nearest neighbor (MKNN) neighborhood method was employed to automatically extract appropriate pairs for clustering, and these pairs were used as must-link constraints. On the other hand, in [
51], the researchers replaced the classical k-means clustering with a density-based clustering approach to cluster the learned low-dimensional embedded features. The concept of soft constraints was introduced in SS-DEC models by the authors in [
42]. They extended a previous work [
52] to neural networks with instance-level constraints. In [
52], soft constraints were introduced by allowing the constraints to be violated with violation costs.
Generally, deep clustering approaches’ potential was mainly explored in the context of entirely unsupervised learning. The resulting approaches are still prone to the local minima due to the NP-hardness of the clustering problem. On the other hand, most real-world datasets are naturally weakly labeled. Therefore, exploiting some prior knowledge as supervision information for the cluster analysis was later investigated to carry the clustering process away from the local minima. This conforms with the assumption that feeding the learning algorithm with some supervision in the form of a reward would improve the learning. A semi-supervised learning paradigm has produced a considerable impact on various machine learning-based applications [
53]. Despite these achievements, the efforts made to extend and improve the existing semi-supervised deep clustering approaches remain far below expectations compared to the researchers’ contributions to enhance fully unsupervised approaches. Several potentials for improvements can be investigated in this domain. Specifically, incorporating supervision information in a relaxed way was not investigated in previous works. In particular, such supervision can be softly expressed within the models’ objective using “should-link” pairwise constraints to determine whether the pairs of data instances should be assigned to the same or different cluster(s). Moreover, the use of fuzzy logic [
53] was not explored to represent the data partition in the context of the existing semi-supervised deep learning approaches. Thus, we introduce a novel, semi-supervised, deep clustering algorithm that incorporates the abovementioned aspects that we believe would fill several gaps and upscale the deep clustering performance.
3. Proposed Soft Constrained Deep Clustering (SC-DEC)
The proposed semi-supervised deep clustering approach, named Soft Constrained Deep Clustering (SC-DEC), leverages a deep neural network architecture for feature learning and performs clustering with fuzzy membership degrees. Specifically, the deep clustering problem is formulated as an optimization of a novel objective function that is designed to simultaneously discover the hidden data clusters and optimize the deep neural network. Furthermore, the available supervision knowledge is incorporated as soft pairwise constraints within the objective function in a soft way such that the compliance to a constraint is not strictly obligated. Moreover, data partition is represented in a fuzzy manner within the objective to accurately reflect the grouping of data.
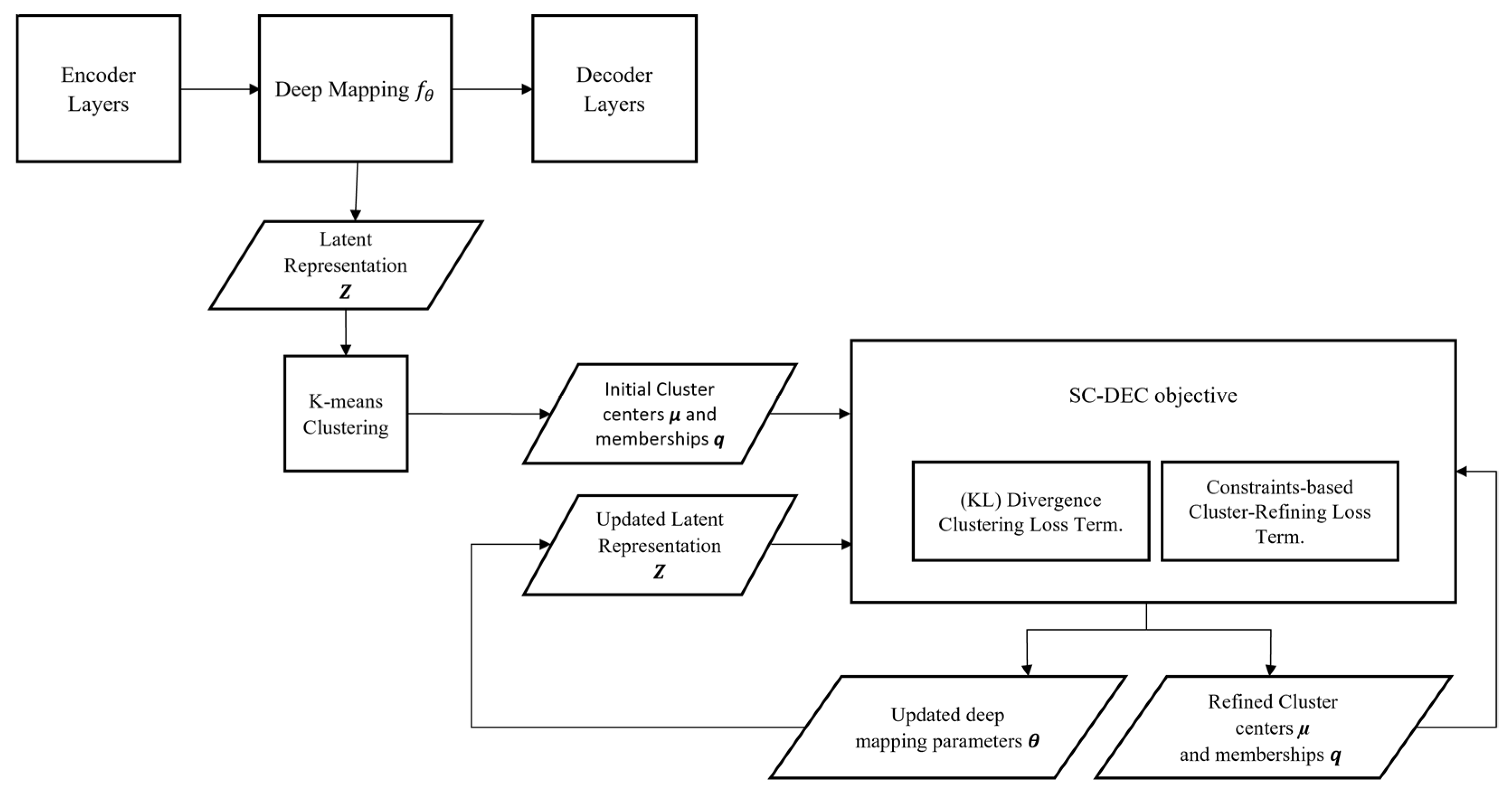
This section introduces the design details of the proposed SC-DEC approach. The block diagram of SC-DEC is depicted in
Figure 1. The proposed semi-supervised deep embedded clustering approach relies on two main components: (i) an objective function that carries out the clustering tasks as proposed, and (ii) an autoencoder AE network that learns the discriminative embedded representation of the original data.
Let be a set of unlabeled data that serves as the input to our proposed clustering method, where each sample and d is the dimensions of the input space. Instead of performing the clustering task directly in the original data space, we define a nonlinear mapping function to transform the original input data into a latent feature space ; , where represents the learnable parameters. The dimensionality of the latent space is much lower than the original space dimensionality. The main goal of the proposed SC-DEC method is to output an appropriate clustering of data in the embedded feature space by utilizing the unlabeled data and the injected supervision. Specifically, it aims to partition the data input into clusters, where each cluster is defined by a centroid and . Specifically, for k-means algorithms, the number of clusters k is based on the related literature and the considered benchmark datasets. Basically, we aim to find a cluster-friendly such that the learned parameters are biased towards the clustering task and the available knowledge.
To initialize the parameters of the
, a deep autoencoder network [
54] is built and trained in an unsupervised manner. Later, only the encoder layers are used within our model to receive the input data and transform it to the embedded space. The supervision knowledge are defined in the proposed approach as a set of should-link soft constraints and denoted by
. These soft constraint sets are pre-defined and randomly generated from the dataset and generally, the supervision information should be available for a subset of the dataset only. In the Experiments section, we vary its ratio and investigate the performance.
We introduce our algorithm as an improvement to deep embedded clustering algorithms. Specifically, we propose to integrate should-link constraints into the clustering loss objective of DEC [
21] to find clustering-friendly representations. Consequently, we tackle the proposed optimization problem by defining the following objective function and obtaining the partial derivatives of the parameters to be updated via minimization, as shown below:
where
n is the number of data points,
C is the number of clusters,
m is the fuzziness parameter that reflects the fuzzy-based representation of the data clusters, and
is the set of should-link constraints as shown above.
The first term is the deep embedded clustering term of DEC [
21], while the second term is designed to learn the compact, fuzzy-based clusters given the supervision soft constraints. The second term basically rewards the model for correctly clustering, i.e., having a high membership value of a should-link pair of points to a certain cluster. In (2),
and
are computed as shown below [
21]:
where
are soft cluster frequencies;
=
(
) is the embedded representation of
;
is the
cluster centroid in the embedded space; and
denotes the L2-norm.
Note that in the above equation is a predefined trade-off parameter that balances the influence of the supervision soft constraints. It balances the amount of penalty imposed on the data batch for misclustering.
Minimizing the above objective function is preceded by the training of an autoencoder AE for DNN parameter initialization. This AE training is performed by minimizing the following objective function:
where
is the squared Euclidean distance between data point
and its embedding
.
The proposed algorithm would minimize the objective function in (2) iteratively and converge towards the clustering results under specific criteria (tolerance threshold %). Concretely, the clustering process carried out via our proposed approach follows DEC [
21] in its two phases: 1. model parameter initialization. In this phase, the deep embedding parameters are initialized by training a deep autoencoder network. Then, the k-means clustering algorithm [
55] is applied to the embedded space
Z to initialize the
k cluster center
. 2. Model parameter optimization, i.e., updating the deep mapping
and refining the cluster centers
. In phase 2, the proposed objective loss is minimized to learn from the current high confidence predictions by iterating between computing an auxiliary target distribution and minimizing the Kullback–Leibler (KL) divergence to it.
To guide the learning process away from the local minima, some side information is adopted within our approach as a set of pairwise constraints. Basically, such information is incorporated to reward or penalize the traditional clustering objective as well as to adapt the distance measure to each cluster. Specifically, soft pairwise constraints are introduced and incorporated to represent the available prior knowledge where we formulate the second term of the model’s objective according to these constraints. These pairwise constraints are randomly generated with a size equal to , where is the number (ratio) of pairwise constraints and is the dataset size. Specifically, for each randomly selected data point, we check the corresponding ground-truth labels of the whole dataset. If the ground-truth labels of the two points are similar, a “should-link” pairwise link is formed between these points and represented by 1. Otherwise, the pairwise link is represented by 0.
Unlike the constraints referred to as “must-link” and “cannot-link”, the constraints in our formulation are soft and not obligated. They can be viewed as a reward for correctly clustering a point, which is suitable for the poorly labeled knowledge available in the real world. The soft constraint term of the objective function governs the consistency between the learned representation and clustering with the side information provided.
One should note that the Adam optimizer [
56] was used to jointly optimize our objective in (2) with respect to its parameters, the cluster centers
, and the DNN parameters. The following algorithm (Algorithm 1) depicts the steps designed and implemented to solve the clustering task of the proposed SC-DEC approach.
| Algorithm 1 Soft Constrained Deep Clustering |
INPUT: Dataset X; number of clusters K; update interval T; stopping threshold tol%; maximum number of training iterations maxIter; : the constraint term weight; fuzzifier ; AE pretrain epochs; β: number of pairwise constraints; data batch size.
OUTPUT: Cluster centers ; deep mapping weights ; cluster label assignments . |
| 1: | STEP1: Pretrain the deep network (AE) on input X and according to the input hyper-parameters to obtain initial deep mapping weights and the data in latent space . |
| 2: | STEP2: Initialize the values of cluster centers and cluster assignments by running k-means in from step1. |
| 3: | STEP3: Begin model fitting: |
| 4: | → Create pairwise constraints set according to the input parameters X, β. |
| 5: | → for iter do |
| 6: | → if update_interval T is reached then |
| 7: | → Compute embedded points on all dataset X using . |
| 8: | → Compute soft assignments q and target distribution p using and formulas in Equations (3) and (4). |
| 9: | → Update label assignments . |
| 10: | → Compute cluster performance metrics. |
| 11: | → Save old label assignments. |
| 12: | → Compute change in label assignment and stop training if it is < tol%. |
| 13: | → end if |
| 14: | → Begin custom training on sequential data batches . |
| 15: | → Compute constraint term per batch using Equation (2) and according to and to the input hyper-parameters , . |
| 16: | → Add the constraint term to the custom loss in Equation (2). |
| 17: | → Train the model by minimizing Equation (2) using the selected optimizer. |
| 18: | → Update cluster centers and deep mapping weights on S via the respective update equations. |
| 19: | end for |
4. Experiments
The performance of the proposed SC-DEC was validated through several experimental scenarios using benchmark datasets. Moreover, the obtained results were compared with those achieved via relevant state-of-the-art approaches. Below are the hypotheses tested via the experiments:
- -
Null hypothesis: introducing supervision to relevant unsupervised learning approaches, as described in
Section 3, does not improve the clustering results.
- -
Alternate hypothesis: introducing supervision to relevant unsupervised learning approaches improves the clustering results. This means that the proposed SC-DEC yields higher accuracy than the relevant existing methods.
In the following subsections, we will outline the experiments including the datasets and performance measures, the implementation details, the experimental scenarios, parameter settings, and lastly, the results and discussion of the experiments.
4.1. Datasets and Performance Measures
The proposed approach was mainly assessed using multiple benchmarking datasets that are widely used by the deep clustering research community. The MNIST dataset [
57], which consists of 70,000 images of handwritten digits, was used. One should note that the MNIST digits are size-normalized and centered in a fixed-size image. Each digit in MNIST is represented using a gray image with a size of 28
28 pixels. This results in a 784-dimensional vector for each image. In addition, the USPS dataset [
58] that contains 9298 gray-scale, handwritten, 16
16 pixel digit images was also used. Moreover, the STL-10 dataset [
59] that includes 13,000 color images, categorized into 10 classes, was considered for the experiments. Each STL-10 image is a 96
96 pixel size.
Table 1 details these datasets and depicts the relevant ground-truth information for the clustering task.
The performance of the proposed approach was evaluated using standard metrics that are widely used by the clustering research community: the classification accuracy (ACC), which indicates the percentage of the correctly clustered samples, and the Normalized Mutual Information (NMI) measure which represents the normalized similarity between the true and predicted labels for the data records. Both ACC and NMI values range between 0 and 1.
4.2. Implementation Details
Python language, along with the required libraries, were associated with high-performance resources to implement the intended experiments. For the non-linear transformation
, we select a fully connected autoencoder deep network with d–500–500–2000–10 dimensions for all datasets, where d is the data-space dimension. All internal layers of the autoencoder are activated via a ReLU nonlinearity function [
60] except for the input, output, and embedding layers.
The autoencoder weights were initialized using greedy layer-wise pretraining. The optimization method for the pretraining was Stochastic gradient descent (SGD) with a learning rate of 0.01 and a momentum of 0.9 across all datasets. To initialize the cluster centers , we ran k-means 20 times and selected the best solution. In the parameter optimization phase, we trained our (SC-DEC) model using the Adam optimizer with a default learning rate of 0.001. The stopping threshold was set to 0.001.
4.3. Experimental Scenarios
After conducting preliminary investigations and experiments using the proposed approach, it was observed that higher numbers of training epochs can result in a poor clustering performance. Moreover, the clustering results are sensitive to the initialization. Furthermore, the Adam optimizer outperformed the other optimizers, with a significant accuracy advantage. Accordingly, a lower range of training epochs was set for all datasets. Moreover, random seeds were fixed for all implementation libraries. Specifically, the seeds values were set based on the performances recorded in three trial runs.
During the preliminary experimentation on model optimizers, the hyper-parameters used for all datasets were set as follows: batch size = 256,
γ and
β = 1, and
m = 1.2 (hyper-parameters are defined in
Section 3). As for the number of pretraining epochs, 1000 was used for USPS, 2000 for MNIST, and 20 for STL-10.
Table 2 shows the accuracy values resulting from using the different model optimizers and optimizers properties. It is noticeable from
Table 2 that the Adam optimizer outperformed the other optimizers for all datasets and with a large margin in the STL-10 dataset.
After setting Adam as the model optimizer for our proposed approach, we performed other preliminary experiments to investigate the proper range for tuning the number of AE pretraining epochs.
Table 3 shows the settings adopted to cluster the datasets using the proposed approach along with the Adam optimizer.
Regarding the settings in
Table 3, some of the experiments had specific settings. For USPS, in the 50-epoch case,
γ = −100,
β = 0.5, and
m = 1.5. In the 100-epoch case,
γ = 1 and
m = 2. For the MNIST dataset,
m = 1.5 in the 300-epoch case and
m = 2 in the 400-epoch case.
Table 4 shows the preliminary experiment results in terms of the accuracy values over the number of AE pretraining epochs. For the STL-10 dataset, a smaller number of epochs led to better clustering accuracy. Moreover, for all datasets, a higher number of pretraining epochs was not correlated with the increasing clustering accuracy. Based on that, we selected the range for tuning the number of AE pretraining epochs to be within smaller values that are relative to the size of the dataset.
It should also be mentioned that as the Adam optimizer was used, the tuning scenario dedicated for the setting of the (optimizer) hyper-parameter was excluded. For all experiments conducted using the different datasets, the relevant hyper-parameters were tuned for a better initialization and setting, as shown in
Table 5.
In
Table 5, since it is the first parameter to be tuned, the number of pretraining epochs does not require default value initialization. As for the batch size’s default value, it was initialized according to the value that is widely used by the clustering research community. Regarding
and
default values, they were initialized with neutral values. As for the initialization of the Fuzzifier m default value, the most frequently used and accepted value in various applications is
m = 2 [
61]. However, when datasets have significant uneven distributions in the cluster sizes, a smaller fuzzifier value has been suggested for the FCM-based clustering algorithms [
62].
Next, a set of experiments for tuning the hyper-parameters were conducted to target the optimal solution in terms of clustering accuracy. Namely, we investigated the number of pretraining epochs, the amount of supervision (number of constraints
), the fuzziness parameter
m, the trade-off parameter (i.e., the constraint term weight)
, and the data batch size. The applicable range for these hyper-parameters is as follows:
ϵ {
|
,
},
ϵ {
|
}, and the data batch size ϵ {
|
,
}. The latter values used to tune the data batch size are based on the related literature and the considered benchmark datasets. On the other hand, according to [
63], the fuzzifier
m is recommended to be within the interval [2, 3.5], while the authors in [
61] suggested the interval [1.5, 2.5] for
m. Based on that, we set the range of values {1.2, 1.5, 1.7, 2, 3} to tune the fuzzifier
m for SC-DEC. Specifically, the tuning process was performed by dedicating and running one experiment for each hyper-parameter as reported in Algorithm 2. This sequential tuning strategy was intended to select the hyper-parameter value that yields the highest clustering accuracy using SC-DEC.
| Algorithm 2 Hyper-parameter tuning strategy |
INPUT: Dataset X; hyper-parameter set considered for tuning: {number of AE pretraining epochs; : the constraint term weight; : the fuzzifier; β: number of pairwise constraints; data batch size}; default values of the hyper-parameters from Table 5; random sets of seed values.
OUTPUT: Hyper-parameters values that achieve the highest accuracy, per dataset. |
1:
2:
3:
4:
5:
6:
7: | STEP1: Tuning of the (number of pretraining epochs) hyper-parameter.
- a.
Other hyper-parameters are set to the default values. - b.
Tuning values per dataset:
- -
USPS: {50, 100, 150, 200}; - -
MNIST: {100, 200, 300, 400, 500}; - -
STL-10: {20, 50, 70, 100, 150, 200},
- c.
Run the model for each value 3 times, with different seeds per run. - d.
Save the pretraining epochs number and the seeds that resulted in the highest accuracy among runs. - e.
Update the default value for the number of pretraining epochs according to (d). - f.
Use the seeds in (d) for the rest of the experiments.
|
8:
9:
10:
11:
12:
13: | STEP2: Tuning of the (fuzzifier ) hyper-parameter.
- a.
Other hyper-parameters are set to the default values. - b.
Tuning values for all datasets: {1.2, 1.5, 1.7, 2, 3}. - c.
Run the model for each value. - d.
Save and use the value that resulted in the highest accuracy for the rest of the experiments. - e.
Update the default value according to (d).
|
14:
15:
16:
17:
18:
19: | STEP3: Tuning of () hyper-parameter.
- a.
Other hyper-parameters are set to the default values. - b.
Tuning values for all datasets: {+1, +10, +100, +1000, −1, −10, −100, −1000}. - c.
Run the model for each value. - d.
Save and use the value that resulted in the highest accuracy for the rest of the experiments. - e.
Update the default value according to (d).
|
20:
21:
22:
23:
24:
25: | STEP4: Tuning of the (β) hyper-parameter.
- a.
Other hyper-parameters are set to the default values. - b.
Tuning values for all datasets: {0.1, 0.3, 0.5, 0.7, 0.9, 1, 1.2, 1.5, 2}. - c.
Run the model for each value. - d.
Save and use the β value that resulted in the highest accuracy for the rest of the experiments. - e.
Update the default β value according to (d).
|
26:
27:
28:
29:
30:
31: | STEP5: Tuning of the (data batch size) hyper-parameter.
- a.
Other hyper-parameters are set to the default values. - b.
Tuning values for all datasets: {64, 128, 256, 512}. - c.
Run the model for each value. - d.
Save and use the batch size value that resulted in the highest accuracy for the rest of the experiments. - e.
Update the default batch size value according to (d).
|
4.4. Results and Discussion
As outlined above, extensive experiments were conducted to assess the performance of the proposed approach, SC-DEC. The results were quantitatively analyzed, visualized, and compared to those achieved using relevant unsupervised and semi-supervised deep clustering algorithms. Namely, the proposed approach was compared with DEC [
21], Semi-Supervised Deep Embedded Clustering (SDEC) [
38], and Improved Deep Embedded Clustering with Local Structure Preservation (IDEC) [
37]. Additionally, we added the results of applying simple k-means [
8] for clustering the deep embeddings of the respective datasets (called DL + k-means).
After hyper-parameter tuning, detailed in Algorithm 2, we ran 20 experiments using the hyper-parameter values that achieved the best accuracy.
Table 6 reports the results achieved using the proposed approach along with the state-of-the-art methods on the MNIST, USPS, and STL-10 datasets. As can be seen in
Table 6, the results mainly showed the positive impact of utilizing minimal prior knowledge about the data on the clustering performance. According to
Table 6, the most notable improvement was obtained using the STL-10 dataset, with a clustering accuracy of 91.65%, which represents a drastic improvement compared to DEC [
21] and SDEC [
38].
One can notice from
Table 6 that the SC-DEC performance exceeded that of DL + k-means on all three datasets. Moreover, we can see that SC-DEC outperformed the non-constrained approach DEC [
21] on the MNIST and STL-10 datasets. This proves the importance of the proposed semi-supervision information formulated as pairwise constraints in guiding the deep clustering process. Moreover, the results confirmed the importance of the fuzzy membership representations in improving the clustering partition. Furthermore, the proposed approach outperformed the non-fuzzy approach SDEC [
38] in terms of clustering accuracy for all datasets.
In addition, we retested the IDEC model in [
37] using the settings reported in the paper: SGD optimizer with a 0.01 learning rate and 0.9 momentum, with the set of pretrained AE weights used for the implementation available online. The results in
Table 6 show that the proposed SC-DEC outperformed the IDEC results in terms of clustering accuracy and NMI metrics.
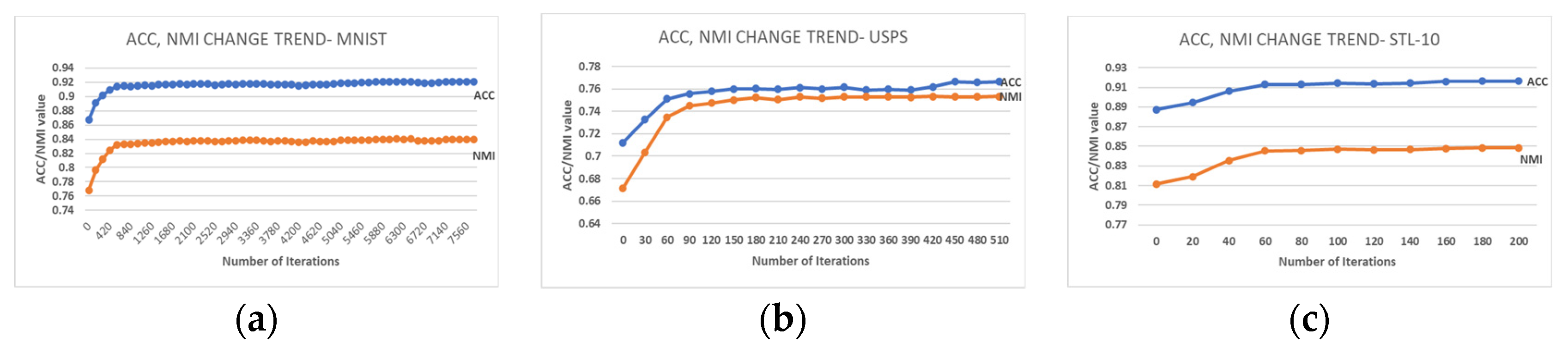
Moreover,
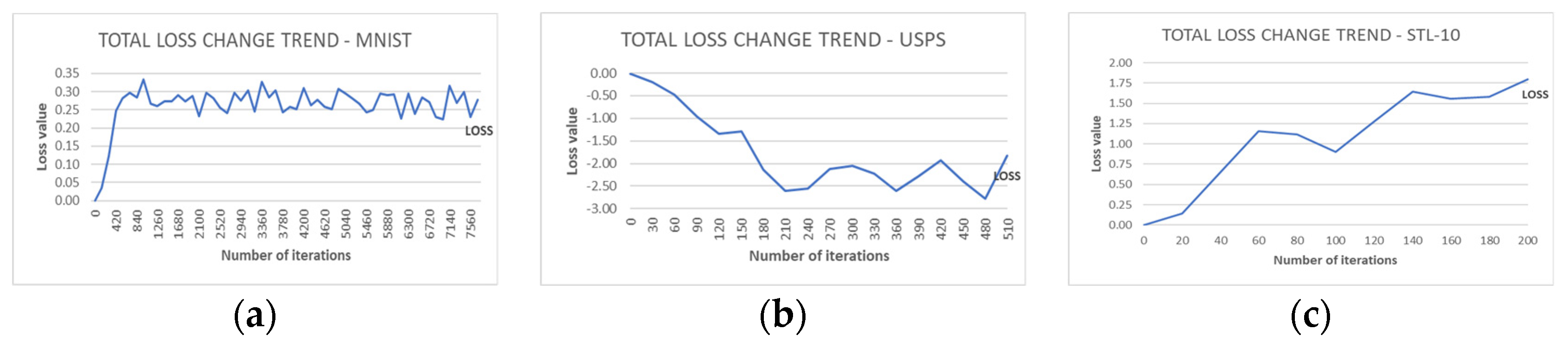
Figure 2 plots the change trends of the ACC and NMI metrics for the best run on the three datasets. For all datasets, one can observe that the improvement in both metrics stabilized after roughly 30% of the total training time. Then, a slight improvement occurred later that led the model into convergence. Additionally,
Figure 3 shows the loss change trend (learning curve) of the run that resulted in the best accuracy for the three datasets.
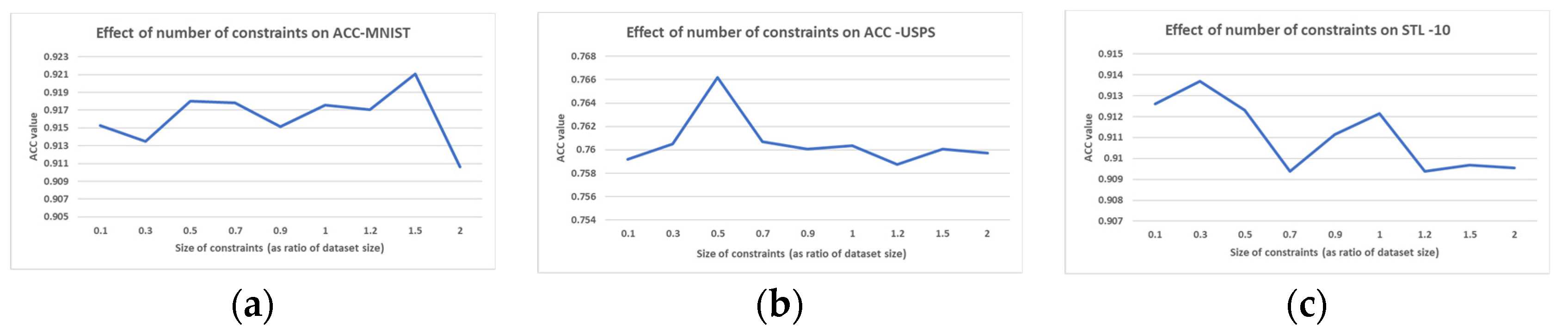
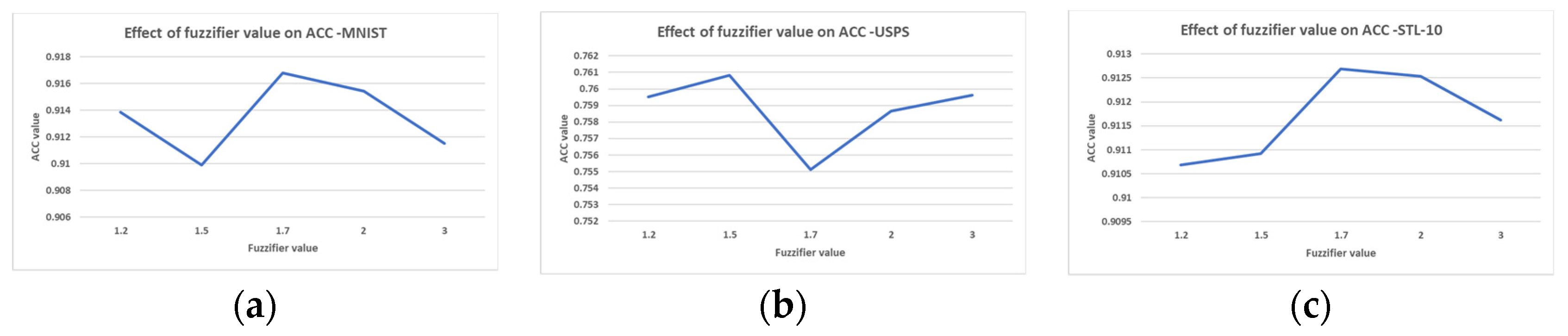
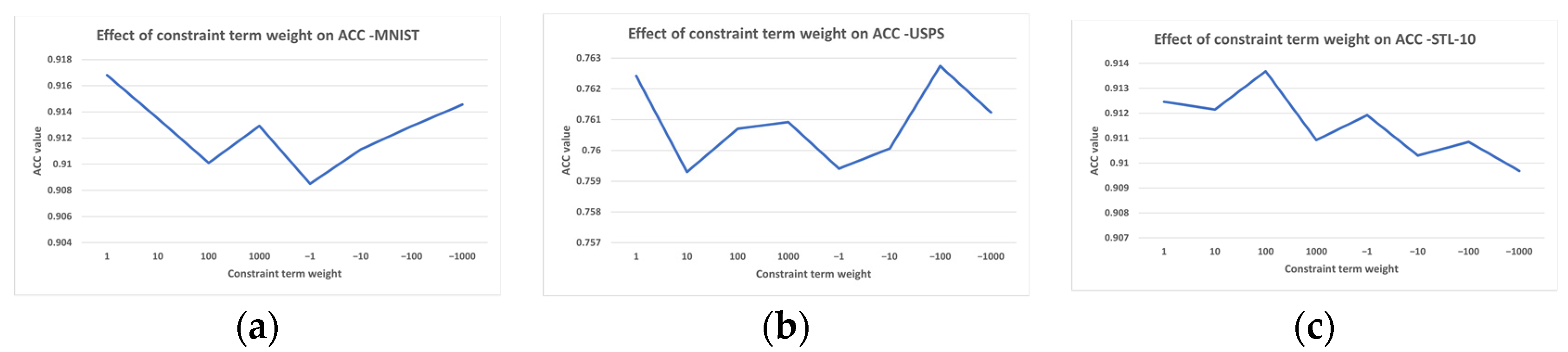
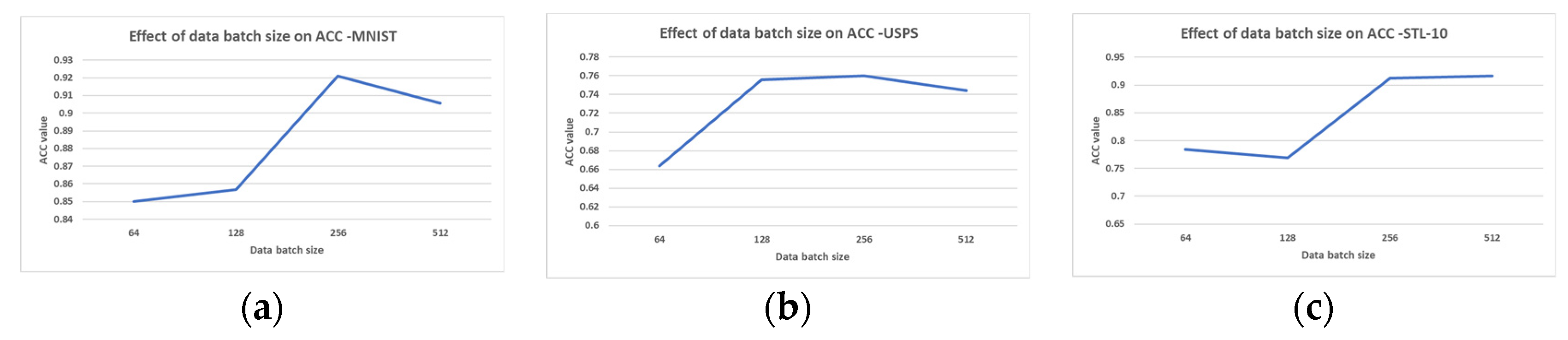
The results of the hyper-parameter tuning presented earlier are shown in
Table 7. Specifically, this table shows the hyper-parameter values that yielded the best accuracy for the proposed model when associated with each of the datasets. Moreover,
Figure 4,
Figure 5,
Figure 6 and
Figure 7 plot the trends in accuracy changes achieved via SC-DEC according to the different hyper-parameter values on the three datasets.
We can notice from
Table 7 and
Figure 4 that the number of pairwise constraints (
hyper-parameter) was correlated with the dataset size. In the largest dataset, MNIST, the best value was
, compared to
and
for the STL-10 and USPS datasets, respectively. However, the change in accuracy in response to the increased
value was not substantial, as the difference between the highest and lowest accuracy equaled 1.05% (MNIST), 0.43% (STL-10), and 0.74% (USPS). This is consistent with the findings in the SDEC paper [
38] that the initial introduction of pairwise constraints into deep embedded clustering will lead to a significant increase in performance, and then the performance becomes stable, indicating that enough prior information has been captured. According to SDEC, this observation is generally consistent with the semi-supervised learning literature.
Moreover, the effect of the number of constraints
on the performance of the proposed approach may be subject to the pairwise constraints generated, as the generation is random for each new value of the hyper-parameter
. This would explain the relative randomness that characterizes the results shown in
Figure 4.
Furthermore,
Table 7 and
Figure 5 show that the highest accuracy values for the fuzzy parameter
m among the three datasets are within the interval suggested by [
61] as a heuristic for selecting the m value for FCM-based clustering. The calculation in [
61] suggests that the best choice for m is probably in the interval of [1.5, 2.5]. Interestingly, training our model on the STL-10 dataset using a 512-batch size yielded better results than using the default 256-batch size.
5. Conclusions and Future Work
Most real-world datasets are weakly labeled by nature, which inspired the utilization of the available prior knowledge as supervision information by clustering algorithms to carry the clustering process away from the local minima. This led to the introduction of semi-supervised learning within the clustering paradigm. However, the state-of-the-art semi-supervised deep clustering approaches remain below expectations compared to the fully unsupervised approaches, with several potentials to be explored. In this paper, we propose a novel semi-supervised deep clustering approach (named Soft Constrained Deep Clustering, SC-DEC) to overcome the limitations in the existing semi-supervised clustering approaches. Specifically, the proposed approach leverages a deep neural network architecture and generates fuzzy membership degrees that better reflect the true partition of the data. Furthermore, the scarcely available prior knowledge was used as side information and formulated as a set of soft pairwise constraints to direct the machine learning process into clustering unlabeled data. This clustering task was formulated as an optimization problem where a novel objective function was minimized to simultaneously discover the hidden data clusters and optimize the deep neural network. The proposed approach was assessed using standard datasets and performance measures. The experiments proved that the proposed approach can automatically learn the partitioning of data. Moreover, various calibrations of the model’s hyper-parameters were investigated during the experiments. The experimental results showed that the size of the pairwise constraints was positively correlated with the dataset size. However, after enough prior information has been captured via the initial insertion of the pairwise constraints into the proposed model, the model performance became stable. Furthermore, when compared to the state-of-the-art approaches, SC-DEC produced competitive results on the STL-10 dataset and outperformed the other models on MNIST and USPS.
Some limitations of the proposed approach should be stated, which include 1. sensitivity issues toward the presetting of the number of clusters and 2. the trial-and-error approach in selecting some of the hyper-parameter values for tuning. However, to address these limitations as well as to investigate new potentials, some directions are suggested for future studies. Specifically, we suggest researching the following approaches: 1. developing an automatic determination of the number of clusters through designing an additional term to the proposed objective; 2. researching robust heuristics to guide the selection process for hyper-parameters β and γ; 3.dropping the noise points and considering only the points with membership values over a certain threshold for the constraint term formulation; 4. investigating the effect of “should-not-link” pairwise constraints; and 5. studying the proposed method using text datasets.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}